#550 5.6.0 M2MCVT. StorageError; storage in content conversion error #.
Hello
We use ios with 9.2 ios devices
recently, we noticed that when we create a new event in the calendar and invite someone outside of our company, we receive an error message:
The e-mail system had a problem processing this message. It won't try to deliver this message again
and the exchange Server Diagnostics information:
#550 5.6.0 M2MCVT. StorageError; storage in content conversion error #.
that it happens with ios 9.2
have you ever had a response to this
We suffer the same way in Israel.
When we change the time zone on the iphone in the United States for example, it works well!
If it has to do with the zone, but I can't figure out how to solve this problem.
He comes up with the previous version of the IOS, but not with android and not outlook on the computer. If you install outlook on iOS app, it works well in this regard.
Help!
Tags: iPhone
Similar Questions
-
TDMS of MDF time stamp conversion error / storage date time change
I fought it for a while, I thought I'd throw it out there...
Let's say I have a file TDMS which has a channel of labview time stamp and thermocouple 2.
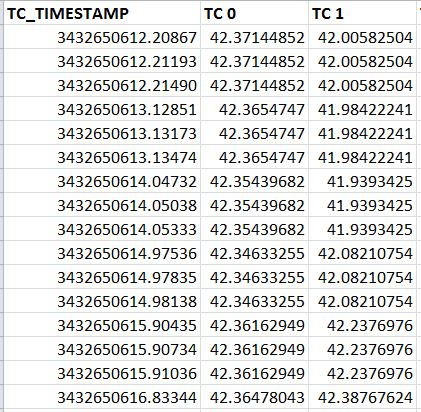
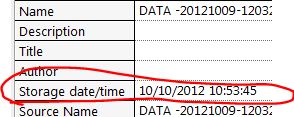
I load in DIADEM, I get this:
Perfect! But now let's say I want to save the PDM as a MDF file so I can see him in Vector sofa. I right click and save as MDF, perfect. I started couch and get this:
The year 2121, yes I take data on a star boat! It seems to be taking the stamp of date/time storage TDMS as starting point and adding the TC_Timestamp channel.
If I change the channel of TC_Timestamp to 1, 2, 3, 4, 5, 6, 7 etc... and save as MDF, I get this:
Very close, 2012! But what I really want is what to show of the time, it was recorded what would be the 10/09/2012.
The problem is whenever I do like recording, date storage time is updated right now, then the MDF plugin seems to use it as a starting point.
is it possible to stop this update in TIARA?
Thank you
Ben
Hi Ben,
You got it right that the MDF use written the time of storage to start MDF that is updated by DIAdem when writing time. We are working on this and will return to you, if there is no progress.
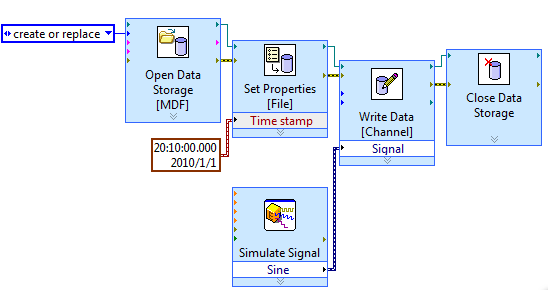
To work around the problem, you can try convert TDMS MDF in LabVIEW storage vis.
Something like the following, you can write your start time of measurement to the MDF file.
Hope this helps,
Mavis
-
Server 2012 - storage server repair file error volume system
Hey guys,.
I'm up late panic hoping someone might have an answer.
We have a file server, 2012 running storage server. One of the volumes reported an error so I have planned some time tonight to perform a repair on it.
After reading good things about 2012 chkdsk I thought it would be a quick process, however after some further reading, it seems you need to run chkdsk from the command line by specifying the option spotfix for the quickest fix.
I stupidly he run from Server Manager by clicking with the right button on the volume and selecting the option "repair the file system error.
It is on a volume of 5.5 to data that is accessed by a large number of users that will start to connect to 6 hours time.
Managed server showed the repair had obtained 13% after about an hour, but has not changed for some time, so I guess that Server Manager had frozen, so I closed and opened again. I can see the process is still ongoing, but the Server Manager no longer shows a progress bar (just a red bar to show the volume is locked.
Anyone has an idea how I can get up again the progress bar, or know any way to show the status of the repair running?
Thank you
Dave
Hello
Post your question in the TechNet Server Forums, as your question kindly is beyond the scope of these Forums.
http://social.technet.Microsoft.com/forums/WindowsServer/en-us/home?category=WindowsServer
See you soon.
-
USB Mass Storage Device show me error Code 10
I have problem: USB Mass Storage Device Error 10 Code. I tried to uninstall all devices under USB controller then I restart my computer. The problem is still exist. I tried to find and remove UpperFilters and LowerFilters in the registry but I they are did not exist in the HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Class\ (36FC9E60-C465-11CF-8056-444553540000). My laptop: Toshiba Portege R705-P25 Type powered by Windows 7 Home Premium. Is there a solution to my problem?
Concerning
Leo MS
Hello Leo,
Thanks for joining us.
The Code 10 error applies mainly to the problems of hardware driver and devices or compatibility problems between the drivers of equipment and additional software that is installed in Windows. Therefore, we recommend that solve you these problems with emphasis on device drivers, configuration of device problems and hardware compatibility issues.
See the article mentioned below.
Description of errors related to the 10 Code that generates the Device Manager in Windows on computers
http://support.Microsoft.com/kb/943104Method 1: You can run the below mentioned link Microsoft fixit and check.
Hardware devices do not work or are not detected in Windows
http://support.Microsoft.com/mats/hardware_device_problems/en-us
Method 2: Remove and reinstall all USB controllers:
To remove and reinstall all USB controllers, follow these steps:
a. click Start, click run, type sysdm.cpl in the Open box and then click OK.
b. click on the hardware tab.
c. click the Device Manager button.
d. expand Bus USB controllers.
e. right-click every device under the USB Bus controllers node, and then click Uninstall to remove one at a time.
f. restart the computer and reinstall the USB controllers.
g. plug in the removable USB storage device and perform a test to ensure that the problem is solved.
Let us know if this can help, we will be happy to help you.
-
I have a Seagate Barracuda 1.5 TB drive that I add to storage, it breaks down to add with the above error.
As a regular player, it works fine...
Thank you
Nick
I hit it constantly on two of my stocks when you try to add a disc through the user interface. It seems to be specific to the pool rather than drive, that I get the same error for any physical drive, I'm trying to reach.
On a whim, I tried adding a drive via PowerShell and it worked only. A lot of details here, but here's the bit of criticism that has worked for me:
PS C:\ > $PDToAdd = disc-Get physical - CanPool $TruePS
C:\ > add physical disk StoragePoolFriendlyName-'Attachment 2' - PhysicalDisks $PDToAdd
Note that this attaches to all the available physical disks, which can be grouped, then you'll want to confirm the list before actually calling Add-physical disk.
-
Storage VMotion - a general error occurred: could not wait for the data. Error bad0007.
People,
I searched through this forum and have not found an answer that works in many positions out there, I say to myself that I would ask him once again.
Here's the context:
We have 12 identical Dell M600 blades in 2 chassis with 16 GB of Ram, 2 x Xeon E5430, they are all connected to an Equallogic PS 5000XV iSCSI SAN on a separate iSCSI (vswitch1) with 2 cards network dedicated network and dedicated switch, console svc iscsi dedicated, dedicated VMkernel port for iscsi access. Net access (vswitch0) contains port groups VM for our various networks and a console port and vmkernel svc for VMotion with 2 separate NETWORK cards as well.
We are running ESX 3.5 U3 and VCenter 2.5 U3 on Win2k3 R2
VMotion works between all servers, Storage Vmotion works for most machines, HA works and the value 2 host failurs with no monitoring of vm, DRS is set to manual for now I have a few machines on the local stores that I complete my rebuilt LUN, there is no set of rules for DRS and VMware EVC is enabled for guests of the Intel. However, I'll just describe one machine to do svmotion below.
Here's the problem:
I'm trying to Svmotion via svmotion.pl - interactive, a Machine to Windows 2000 with a virtual disk and a virtual RDM. I am aware of the requirements for the RDM and required parameters for svmotion, independent is not selected for the RDM, and I also have svmotioned several machines linux and win2k3 with the same configuration without problem. In the interactive session, I choose to individually place the disks and I chose the virtual disk to only the virtual machine to be moved, essentially, as I saw it move vdisk virtual machine and then copy to the pointer of the RDM.
The use of the processor in this machine is about 25% average. but I try to run migrations at the time the lowest. and The Host it itself shows only about 5.5 GB of the 16 GB of RAM used. so I think we're good on the RAM. the volume/datastore that I'm migrating from has 485 GB free and the volume/datastore I migration towards a 145 GB free. the VM virtual disk is only about 33 GB.
I run the script the windows version of the RCLI svmotion. and when to begin the process, I get the following error at around 2 percent of the progress:
"Since the server has encountered an error: a general error occurred: could not wait for the data." Error bad0007. Invalid parameter. »
After searching around, I found the following hotfixes to the U2 release notes
Migrate.PageInTimeoutResetOnProgress: Set the value to 1.
Migrate.PageInProgress: The value 30, if you get an error even after the setting of the Migrate.PageInTimeoutResetOnProgress variable.
I've made these changes, and I still get the same error.
When I dig in the newspaper, I see these entries in the journal of vmkwarning:
(Feb 24 00:17:32 vmkernel iq-virt-c2-b6: 82:04:13:56.794 cpu4:1394) WARNING: bunch: 1397: migHeap0 already at its maximumSize bunch. Cannot extend.
(Feb 24 00:17:32 vmkernel iq-virt-c2-b6: 82:04:13:56.794 cpu4:1394) WARNING: bunch: 1522: Heap_Align (migHeap0, 1030120338/1030120338 bytes, 4 align) failed. calling: 0x988f61
(Feb 24 00:17:32 vmkernel iq-virt-c2-b6: 82:04:13:56.794 cpu4:1394) WARNING: migrate: 1243: 1235452646235015: failure: out of memory (0xbad0014) @0x98da8b
(Feb 24 00:17:32 vmkernel iq-virt-c2-b6: 82:04:13:56.794 cpu2:1395) WARNING: MigrateNet: 309: 1235452646235015: 5 - 0xa023818: sent only 4096 bytes of data in message 0: Broken pipe
(Feb 24 00:17:32 vmkernel iq-virt-c2-b6: 82:04:13:56.794 cpu6:1396) WARNING: migrate: 1243: 1235452646235015: failed: Migration protocol error (0xbad003e) @0x98da8b
(Feb 24 00:17:32 vmkernel iq-virt-c2-b6: 82:04:13:56.794 cpu2:1395) WARNING: migrate: 6776: 1235452646235015: could not send data for 56486: Broken pipe
At this point, I'm stuck... What is Windows RCLI? the vcenter Server? or the service console with not enough of RAM? We have already increased all our consoles service 512 MB...
Any help would be greatly appreciated...
Thanks in advance.
Alvin
The vmkernel on out of memory error, I had that before. And vmware support recommends setting 800M Max service console memory. And I did it and have no problems after that.
See if that helps the issue.
Mike
-
Only occurs with the e-mail program
Try upgrading to Firefox 33.0.1 - there have been updates to performance, and some users claimed to have a better browsing experience.
Or go to:
- Help (or

>

) > about Firefox
Or download a new copy to:
- https://www.Mozilla.org/en-us/Firefox/new/
- (for a different location) https://www.Mozilla.org/en-us/Firefox/all/
If this does not help, I wonder if it's just a slow script on the page. If that were the case there is no much you can do. You can try to download a NoScripttype extension, allow scripts globally, and then turn off one by one to make sure that you maintain the functionality of the page. But it is a funny way to do that is a single project (I guess you only encounter this problem only on this site does not).
- Help (or
-
Storage VI SetProperty causes error - 2500 (internal error storage screws)
Hello!
As mentioned above the VI of Strorage Advanced "SetProperty" always results in the error Code - 2500 and I don't know why this is the case.
I'm under LabView2013.
I have already received a few messages about this error but they all problems within the LabView8.
Attached is an example that should produce the error when running with the default values.
Hello world
I finally found the source of the problem: you can't name a property 'group '. If someone encounters this weird error sometimes, try another name of the property. In my view, the Error Message that appears is really poor in this case.
Have a nice weekend
Moritz
-
Keithley 6485 error 800, "not consistent with active storage."
Hello
I use a Keithley 6485 to acquire a buffer of 40 measures, triggered via triggerlink.
The VI works well, but
 of course, what happens if no trigger is to send to the device?
of course, what happens if no trigger is to send to the device?So, after a timeout, the unit is configured again (reset and configuration commands).
This is then the error produced responses from the instrument: '800, 'noncompliant with active storage' '.
The source is that there is always an active storage (visible on the screen) and I try to reconfigure the buffer.
Here: http://torque.oncloud8.com/archives/cat_keithley_6430.html
I found a way to leave the mode of storage of the façade:
When debugging of labview for the 6430 programs, you could get stuck with a "noncompliant with active storage" error This occurs when the aircraft is expected store data, but you try to give orders that change, for example, the size of the buffer. I have to admit, when I first stumbled across this, I am frustrated and rebooted the machine. The "Asterix" in the upper right corner indicates use it is in storage mode, where the error. Out of this, you must not turn off the machine. Simply tap LOCAL (to get out of the remote control) and then the STORE and then LEAVE. Phew.
Can someone help me on how to do that through SCPI commands?
I've tried Keithley support of the Netherlands, but they don't have an idea.
THX,
Ben Engelen
Support of the keithley guys gave me a work around the problem: use the controls of the SCPI to push buttons.
so before you send the reset command is send to the following:
 YST:KEY 28; -store the button
YST:KEY 28; -store the button
YST:KEY 32; -exit button: * RST; -reset
-
Help for laptop Toshiba can not find mass storage controller?
Hi all
Could someone help me please. I have a toshiba A100/400 PSAARA-054007 model laptop comes with vista Home premium 32-bit.
Today I installed windows 7 premium 32-bit, and as looked in Device Manager I noticed the mass storage controller not found error...So, I hope that someone could send me a download link for this problem, as all other devices found bar this one and would really like to keep win 7...
Concerning
GT4UHi GT4U
(1) what devices do not work?
My first suggestion would be to load the disc of restoration/Driver Toshiba came with your laptop. Load the drivers for the SD card reader and card reader TI from the set of recovery disks.
Also, you can view the links to update the drivers.
Updated a hardware driver that is not working properly
http://Windows.Microsoft.com/en-us/Windows7/update-a-driver-for-hardware-that-isn ' t-work correctly
Update drivers: recommended links
http://Windows.Microsoft.com/en-us/Windows7/update-drivers-recommended-links
If the card reader does not work, try TI Card Reader Driver for Windows XP/Vista/7 (32/64) from the link below.
http://www.CSD.Toshiba.com/cgi-bin/TAIS/support/JSP/download.jsp?CT=DL&soID=1713025&ref=EV
Let me know for any other help.
Varun j: MICROSOFT SUPPORT
Visit our Microsoft answers feedback Forum
http://social.answers.Microsoft.com/forums/en-us/answersfeedback/threads/If this post can help solve your problem, please click the 'Mark as answer' or 'Useful' at the top of this message. Marking a post as answer, or relatively useful, you help others find the answer more quickly.
-
Hello, im a little new for VDI. VDI is already in place and im picking up things. Currently there is only one still deployed and we want to start using storage levels
What we have
5.5 vCenter
Hosts Esxi 5.5 (5 guests)
VMware View 6
Storage
Table of NetApp - there are 3 Flash SSD storage, each 1 TB LUN. There are two 500 GB LUNS each of 15 k SAS Drives. And three LUN 1 to each Sata storage. We also have lots of Sata storage, we can add, if necessary, might be able to add more SAS is necessary.
Ive been going about things and he uses is not Sata or SAS storage. Here using only the SSD storage that worries me, because we rely on the addition of several pools and SSD is at a premium.
We use linked Clones and currently, there are two pools. Each cluster is a floating pool so no need to keep the data of the user and they refresh overnight. A swimming pool is only 15 desktop computers and the other is 120 workstations.
The two pools were a little Proof of Concept pools and its actually affected the production now.
Moving forward the plan is to add more pools, maybe another VM 400, as of this moment the new VM would float pools so no need to keep the data of the user.
I want to Storage Tiering as there is no budget to buy more storage SSD.
I know that I can split the storage so that the replica on the SSD storage and the BONES and the other files are on a slower storage.
So now, a few questions
1. my understanding is replica should be on tier-1 (ssd), the operating system and other files can be on the slower storage, but it would take on SAS 15 k disk storage or can it be the slower storage Sata? I hope that Sata
2 lets say, I find myself with 5 swimming pools. IM assuming that I can have multiple replicas can on the same logical unit number? or should I be split my LUN by Replica? This means that I have to cut my LUN differently
3. There is a limit of about 128 VM per LUN, how it works during the introduction of Storage Tiering? IM assuming that it is not serious, the replica would be on the SSD LUN and then the rest would go to the SATA or SAS LUN disks, and I could have up to 128 VMS on the Sata/SAS LUN?
4. the VM per LUN 128 means that I could use the LUN more? I currently have 5, but do not know if we will use the SAS LUN. So I need to add a couple more Sata Lun?
5. If best practices says 128 VM per LUN. Currently my LUN is all the same Raid Volume. Is how important it? What is VMware says to split up the LUN because its assuming the LUNS will be on separate Volumes of Raid or just because of filesystem VMFS itself?
Im going to be read allot more on VDI but I thought ide goto the forums first to see what think
Thank you
You need not split by replica LUNS. I would put all of your replicas on SSD, and yes they can share a LUN through many swimming pools.
You'll just want to have multiple LUNS that helps to balance the pool (s) on. Create as many LUNS you want to spread things, but really thinking about time zones and IOPS / s. 128 is a guideline, but not a rule lasts. It's all about having enough IOPS / s to serve requests you will get during peak usage.
I'd go with SAS if you can, but SATA is acceptable - just all this affects the user experience. Consider using SATA for task workers or people that do not generate a lot of use of storage. Trial and error and acceptance by the user would be good to come through here if you do not yet have.
-
How to increase the size of the block of local storage
Hi all
We have installed Esx 4.0 with 500 GB storage, it does increase the block size default of 1 MB to 2 MB. We need to assign a virtual disk 450 GB for a virtual computer.
We tried to remove the storage, we get the error "the disk is currently in use". PL share us the command to run from the console.
Thanks in advance
Centhil
Hello.
I used an installation based on the script to trackle this problem of disk split into two partitions
Create disk configuration
Cat < < EOFdisk > >/tmp/diskconfig
clearpart - alldrives - overwritevmfs
part/boot - fstype = ext3 - size = 1100 - onfirstdisk
No part - fstype = vmkcore - size = 110 - onfirstdisk
part $: esxconsole - fstype = vmfs3 - size = 40000 - maxsize = 40000 onfirstdisk - part $: local - fstype = vmfs3 - size = 40000 - grow - onfirstdisk
VirtualDisk esxconsole - size = 16607 - onvmfs = $: esxconsole
party swap - fstype = swap - size = 1600 - maxsize = 1600 - onvirtualdisk = "esxconsole".
part/var - fstype = ext3 - size = 4000 - maxsize = 4000 - onvirtualdisk = "esxconsole".
part/home - fstype = ext3 - size = 2000 - maxsize = 2000 - onvirtualdisk = "esxconsole".
part / opt - fstype = ext3 - size = 2000 - maxsize = 2000 - onvirtualdisk = "esxconsole".
part/tmp - fstype = ext3 - size = 2000 - maxsize = 2000 - onvirtualdisk = "esxconsole".
part / - fstype = ext3 - size = 5000 - push - onvirtualdisk = "esxconsole".
EOFdisk
In the post installation, you can format the secondary drive
vimsh - not hostsvc/storage/refreshment
sleep 5
/ usr/sbin/vmkfstools - c b 2 M s $ESXHOSTNAME vmfs3: local /vmfs/devices/disks/mpx.vmhba0:C0:T0:L0:6 > > /var/log/PostInstall.log
See you soon,.
Mary
-
The Macbook Pro 13 "is good for making movies
Hi all
I would like to know wheter or not the MacBook Pro 13 "is strong enoughfor film making, I want to use movie making applications and all... I aspire to edit videos short and simple I will upload later on social media. I saw the presentation of the MacBook Pro on the Apple site and I noticed that when talking about the film to do things, they only mention the 15 "... and I had a few doubght.
To say, I want to buy the MacBook Pro 13 "retina, i7, 16 GB, ssd 550 with a 256 GB of storage.
Thank you for your help.
It depends on this kind of filmmaking. Model 15-inch more expensive is the only one with an independent graphics card and will be able to manage better than all other models rendering tasks. If your movie is CGI intensive, you can consider the 15-inch model. If your film is essentially practical, 13 inches could possibly do with simplest post-editing and CGI, but may take longer. If you make a great movie, you can also consider a larger storage capacity as videos tend to take place. View a comparison of the two products on the Apple website here.
-
ESXi 6.0 U1 U2 upgrade, iSCSI questions
Hello
First post, so I'll try and summarize my thoughts and what I did with troubleshooting. Please let me know if I left anything out or more information is required.
I use the free ESXi 6.0 on a Board with a CPU Intel Xeon E3-1231v3 and 32 GB of DDR3 ECC UDIMM mATX to Supermicro X10SLL-F. I use a 4G USB FlashDrive for start-up, 75 GB 2.5 "SATA to local storage (i.e. /scratch) and part of a 120 GB SSD for the cache of the host, as well as local storage. The main data store for virtual machines are located on a target (current running FreeNAS 9.3.x). iSCSI This Setup worked great since installing ESXi 6.0 (June 2015), then 6.0 U1 (September 2015) and I recently made the leap to 6.0 U2. I thought everything should be business as usual for the upgrade...
However, after upgrading to 6.0 U2 none of the iSCSI volumes are "seen" by ESXi- vmhba38:C0:T0 & vmhba38:C0:T1, although I can confirm that I can ping the iSCSI target and the NIC (vmnic1) vSwitch and VMware iSCSI Software adapter are loaded - I did not bring any changes to ESXi and iSCSI host before the upgrade to 6.0 U2. It was all work beforehand.
I went then to dig in the newspapers; VMkernel.log and vobd.log all report that there is not able to contact the storage through a network issue. I also made a few standard network troubleshooting (see VMware KB 1008083); everything going on, with the exception of jumbo frame test.
[root@vmware6:~] tail - f /var/log/vmkernel.log | grep iscsi
[ ... ]
(2016 03-31 T 05: 05:48.217Z cpu0:33248) WARNING: iscsi_vmk: iscsivmk_StopConnection: vmhba38:CH:0 T: 0 CN:0: iSCSI connection is being marked "OFFLINE" (event: 5)
(2016 03-31 T 05: 05:48.217Z cpu0:33248) WARNING: iscsi_vmk: iscsivmk_StopConnection: Sess [ISID: TARGET: TPGT (null): TSIH 0: 0]
(2016 03-31 T 05: 05:48.217Z cpu0:33248) WARNING: iscsi_vmk: iscsivmk_StopConnection: Conn [CID: 10.xxx.yyy.195:41620 r L: 0: 10.xxx.yyy.109:3260]
(2016 03-31 T 05: 05:48.218Z cpu4:33248) WARNING: iscsi_vmk: iscsivmk_StopConnection: vmhba38:CH:0 T:1 CN:0: connection iSCSI is being marked "OFFLINE" (event: 5)
(2016 03-31 T 05: 05:48.218Z cpu4:33248) WARNING: iscsi_vmk: iscsivmk_StopConnection: Sess [ISID: TARGET: TPGT (null): TSIH 0: 0]
(2016 03-31 T 05: 05:48.218Z cpu4:33248) WARNING: iscsi_vmk: iscsivmk_StopConnection: Conn [CID: 10.xxx.yyy.195:32715 r L: 0: 10.xxx.yyy.109:3260]
[root@vmware6:~] tail - f /var/log/vobd.log
[ ... ]
2016 03-31 T 05: 05:48.217Z: [iscsiCorrelator] 1622023006us: [vob.iscsi.connection.stopped] iScsi connection 0 arrested for vmhba38:C0:T0
2016 03-31 T 05: 05:48.217Z: [iscsiCorrelator] 1622023183us: [vob.iscsi.target.connect.error] vmhba38 @ vmk1 could not connect to iqn.2005 - 10.org.freenas.ctl:vmware - iscsi because of a network connection failure.
2016 03-31 T 05: 05:48.217Z: [iscsiCorrelator] 1622002451us: [esx.problem.storage.iscsi.target.connect.error] connection iSCSI target iqn.2005 - 10.org.freenas.ctl:vmware - iscsi on vmhba38 @ vmk1 failed. The iSCSI Initiator failed to establish a network connection to the target.
2016 03-31 T 05: 05:48.218Z: [iscsiCorrelator] 1622023640us: [vob.iscsi.connection.stopped] iScsi connection 0 arrested for vmhba38:C0:T1
2016 03-31 T 05: 05:48.218Z: [iscsiCorrelator] 1622023703us: [vob.iscsi.target.connect.error] vmhba38 @ vmk1 could not connect to
[root@vmware6:~] ping 10.xxx.yyy.109
PING 10.xxx.yyy.109 (10.xxx.yyy.109): 56 bytes
64 bytes from 10. xxx.yyy. 109: icmp_seq = 0 ttl = 64 time = 0,174 ms
64 bytes from 10. xxx.yyy. 109: icmp_seq = 1 ttl = 64 time = 0,238 ms
64 bytes from 10. xxx.yyy. 109: icmp_seq = 2 ttl = 64 time = 0,309 ms
-10. ping.109 xxx.yyystats-
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.174/0.240/0.309 ms
vmkping [root@vmware6:~] 10. xxx.yyy.109
PING 10.xxx.yyy.109 (10. xxx.yyy. 109): 56 bytes
64 bytes from 10. xxx.yyy. 109: icmp_seq = 0 ttl = 64 time = 0,179 ms
64 bytes from 10. xxx.yyy. 109: icmp_seq = 1 ttl = 64 time = 0,337 ms
64 bytes from 10. xxx.yyy. 109: icmp_seq = 2 ttl = 64 time = 0.382 ms
-10. ping.109 xxx.yyystats-
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.179/0.299/0.382 ms
[root@vmware6:~] NF - z 10. xxx.yyy3260.109
Connection to 10. xxx.yyy3260.109 port [tcp / *] succeeded!
[root@vmware6:~] vmkping 8972 10 s. xxx.yyy.109 - d
PING 10.xxx.yyy.109 (10. xxx.yyy. 109): 8972 data bytes
-10. ping.109 xxx.yyystats-
3 packets transmitted, 0 packets received, 100% packet loss
I began to watch the drivers NIC thinking maybe something got screwed up during the upgrade; not the first time I saw problems with the out-of-box drivers supplied by VMware. I checked VMware HCL for IO devices; the physical NIC used on that host are Intel I217-LM (nic e1000e), Intel I210 (nic - igb) and Intel® 82574 L (nic-e1000e). Lists HCL from VMware that the driver for the I217-LM & 82574L should be version 2.5.4 - I210 and 6vmw should be 5.0.5.1.1 - 5vmw. When I went to check, I noticed that he was using a different version of the e1000e driver (I210 driver version was correct).
[root@vmware6:~] esxcli list vib software | e1000e grep
Name Version Date seller installation acceptance level
----------------------------- ------------------------------------ ------ ---------------- ------------
NET-e1000e 3.2.2.1 - 1vmw.600.1.26.3380124 VMware VMwareCertified 2016-03-31
esxupgrade.log seems to indicate that e1000e 2.5.4 - VMware 6vmw should have been loaded...
[root@esxi6-lab: ~] grep e1000e /var/log/esxupdate.log
[ ... ]
# ESXi 6.0 U1 upgrade
2015-09 - 29 T 22: 20:29Z esxupdate: BootBankInstaller.pyc: DEBUG: about to write payload "net-e100" of VIB VMware_bootbank_net - e1000e_2.5.4 - 6vmw.600.0.0.2494585 to "/ tmp/stagebootbank".
[ … ]
# ESXi 6.0 U2 upgrade
2016-03 - 31 T 03: 47:24Z esxupdate: BootBankInstaller.pyc: DEBUG: about to write to payload "net-e100" of VIB VMware_bootbank_net - e1000e_2.5.4 - 6vmw.600.0.0.2494585 to ' / tmp/stagebootbank '
3.2.2.1 - 1vmw e1000e is recommended for 5.5 U3 and not 6.0 U2 ESXi ESXi driver! As these drivers are listed as "Inbox", I don't know if there is an easy way to download the drivers supplied by seller (vib) for him, or even if they exist. I found an article online to manually update drivers on an ESXi host using esxcli; I tried check and install the new e1000e drivers.
[root@vmware6:~] esxcli software update net-e1000e-n-d vib https://hostupdate.VMware.com/software/VUM/production/main/VMW-Depot-index.XML
Result of the installation
Message: The update completed successfully, but the system must be restarted for the changes to be effective.
Restart required: true
VIBs installed: VMware_bootbank_net - e1000e_3.2.2.1 - 2vmw.550.3.78.3248547
VIBs removed: VMware_bootbank_net - e1000e_3.2.2.1 - 1vmw.600.1.26.3380124
VIBs ignored:
As you can see there is a newer version and installed it. However after restarting it still did not fix the issue. I even went so far as to force the CHAP password used to authenticate to reset and update on both sides (iSCSI initiator and target). At this point, I wonder if I should somehow downgrade and use the driver of 2.5.4 - 6vmw (how?) or if there is another issue at play here. I'm going down a rabbit hole with my idea that it is a NETWORK card driver problem?
Thanks in advance.
--G

I found [a | the?] solution: downgrade for 2.5.4 drivers - Intel e1000e 6.0 U1 6vmw. For the file name, see VMware KB 2124715 .
Steps to follow:
- Sign in to https://my.vmware.com/group/vmware/patch#search
- Select ' ESXi (Embedded and Installable) ' and '6.0.0 '. Click on the Search button.
- Look for the update of the release name - of - esxi6.0 - 6.0_update01 (released 10/09/2015). Place a check next to it and then download the button to the right.

- Save the file somewhere locally. Open archive ZIP once downloaded.
- Navigate to the directory "vib20". Extract from the record of the net-e1000e. In East drivers Intel e1000e ESXi 6.0 U1: VMware_bootbank_net - e1000e_2.5.4 - 6vmw.600.0.0.2494585.vib

- This transfer to your ESXi Server (be it via SCP or even the file within the vSphere Client browser). Save it somewhere you will remember (c.-a-d./tmp).
- Connect via SSH on the ESXi 6.0 host.
- Issue the command to install it: software esxcli vib install v - /tmp/VMware_bootbank_net-e1000e_2.5.4-6vmw.600.0.0.2494585.vib

- Restart the ESXi host. Once it comes back online your datastore (s) iSCSI / volumes should return. You can check by issuing h df or the list of devices storage core esxcli at the CLI prompt. vSphere Client also works

It took some time to find the correct file (s), the steps and commands to use. I hope someone else can benefit from this. I love that VMware can provide for virtualization, but lately, it seems that their QA department was out to lunch.
Do not always have a definitive explanation as to why Intel e1000e ESXi 5.5 U3 drivers were used when ESXi 6.0 U1 U2. Maybe someone with more insight or VMware Support person can.
& out
--G
-
I have a z640 and I used the Intel RAID controller integrated to create a mirrored pair. It works well, but I would like to monitor the readers so I don't know if it has failed and must be replaced. Is it possible I can do this, say via SNMP or monitor the Windows event logs?
If you install Intel Rapid Storage Technology (RST):
When you run the GUI, click on Preferences, there are e-mail settings to send emails on the system of storage of information/warnings/errors. In addition, you will get the balloon messages that appear down by the systray. You can choose to always display the icon iastor on the windows taskbar. A green check mark is good, yellow triangle is deteriorating, the Red is down.
If you prefer the Windows event logs, you can monitor the event logs applications for events of the event IAStorDataMgrSvc source (IAStorDataMgrSvc is a service that is installed by the Intel RST). You need to filter the event data for the failure or degraded refine storage system errors only.
I hope this helps.







Maybe you are looking for
-
is it possible to add extra memory for HP model p2-1334
-
According to http://support.mozilla.com/en-us/kb/keyboard+shortcuts,.'Ctrl + End' should move the active tab to the end of the list of tabs. But the shortcut does not work. Only, it scrolls to the end of the current page as if only "End" is pressed.
-
Why can't code when deploying exe?
Hello I wonder what is the reason for blocking user wfom coding when the program is compiled into the exe? Wouldn't be good to allow the work of the user while the process, sometimes it takes a long time at the end and look in the brogress bar...
-
I have lost the CD for my Deskjet 1050, how can I download this printer for use on computer again y?
-
Live Photo Gallery Windows in Windows 7 PUE as a way to e-mail photos. Is there a method similar to the option ' send to ' used in XP?