A Mac, two Capsules of time with different backups
I have a second gen Time Capsule, which contains my Time Machine backup. I recently bought a 5th generation Time Capsule with the intention to create a new backup, but also be able to keep intact the first.
I need to be able to release all the space of my MacBook Pro, but also want to be able to access it on the backup of the second generation of TC, but have the 5th generation TC be my new backup every day.
I was wondering how to fix this without screwing up my current data?
Any ideas would be appreciated.
You can do what you want.
Copy the sparsebundle to the old TC to the new... and rename it so it does not interfere with the backup.
Our experience has been to advise against it. Especially it wastes just space.
I need to be able to release all the space of my MacBook Pro, but also want to be able to access it on the backup of the second generation of TC, but have the 5th generation TC be my new backup every day.
If you move files to the TC 2nd Gen, they will be totally lost when the TC fails, which could be tomorrow... it should have been 5 years ago. They proved unreliable due to the overheating and poor diet.
Strongly recommend against it doing so.
Copy your files on a USB connected directly to the laptop. You can then run a backup through TM to the new TC.
The old TC is not worth including somehow.
Tags: Wireless
Similar Questions
-
Mr President.
My worm jdev is 12.2.1
How to enter two rows at the same time with different default values that only the first line to use see?
Suppose I have a table with four fields as below
"DEBIT" VARCHAR2(7) , "DRNAME" VARCHAR2(50), "CREDIT" VARCHAR2(7) , "CRNAME" VARCHAR2(50),
Now I want that when I click on a button (create an insert) to create the first line with the default values below

So if I click on the button and then validate the second row with different values is also inserted on commit.
The value of the second row are like the picture below

But the second row should be invisible. It could be achieved by adding vc in the vo.
The difficult part in my question is therefore, to add the second row with the new default values.
Because I already added default values in the first row.
Now how to add second time default values.
Concerning
Mr President
I change the code given by expensive Sameh Nassar and get my results.
Thanks once again dear Sameh Nassar .
My code to get my goal is
First line of code is
protected void doDML(int operation, TransactionEvent e) { if(operation != DML_DELETE) { setAmount(getPurqty().multiply(getUnitpurprice())); } if (operation == DML_INSERT ) { System.out.println("I am in Insert with vid= " + getVid()); insertSecondRowInDatabase(getVid(),getLineitem(),"6010010","SALES TAX PAYABLE", (getPurqty().multiply(getUnitpurprice()).multiply(getStaxrate())).divide(100)); } if(operation == DML_UPDATE) { System.out.println("I am in Update with vid= " + getVid()); updateSecondRowInDatabase(getVid(), (getPurqty().multiply(getUnitpurprice()).multiply(getStaxrate())).divide(100)); } super.doDML(operation, e); } private void insertSecondRowInDatabase(Object value1, Object value2, Object value3, Object value4, Object value5) { PreparedStatement stat = null; try { String sql = "Insert into vdet (VID,LINEITEM,DEBIT,DRNAME,AMOUNT) values " + "('" + value1 + "','" + value2 + "','" + value3 + "','" + value4 + "','" + value5 + "')"; stat = getDBTransaction().createPreparedStatement(sql, 1); stat.executeUpdate(); } catch (Exception e) { e.printStackTrace(); } finally { try { stat.close(); } catch (Exception e) { e.printStackTrace(); } } } private void updateSecondRowInDatabase(Object value1, Object value5) { PreparedStatement stat = null; try { String sql = "update vdet set AMOUNT='"+ value5+"' where VID='" + value1 + "'"; stat = getDBTransaction().createPreparedStatement(sql, 1); stat.executeUpdate(); } catch (Exception e) { e.printStackTrace(); } finally { try { stat.close(); } catch (Exception e) { e.printStackTrace(); } } }Second line code is inside a bean method
public void addNewPurchaseVoucher(ActionEvent actionEvent) { // Add event code here... BindingContainer bindings = BindingContext.getCurrent().getCurrentBindingsEntry(); DCIteratorBinding dciter = (DCIteratorBinding) bindings.get("VoucherView1Iterator"); RowSetIterator rsi = dciter.getRowSetIterator(); Row lastRow = rsi.last(); int lastRowIndex = rsi.getRangeIndexOf(lastRow); Row newRow = rsi.createRow(); newRow.setNewRowState(Row.STATUS_NEW); rsi.insertRowAtRangeIndex(lastRowIndex +1, newRow); rsi.setCurrentRow(newRow); BindingContainer bindings1 = BindingContext.getCurrent().getCurrentBindingsEntry(); DCIteratorBinding dciter1 = (DCIteratorBinding) bindings1.get("VdetView1Iterator"); RowSetIterator rsi1 = dciter1.getRowSetIterator(); Row lastRow1 = rsi1.last(); int lastRowIndex1 = rsi1.getRangeIndexOf(lastRow1); Row newRow1 = rsi1.createRow(); newRow1.setNewRowState(Row.STATUS_NEW); rsi1.insertRowAtRangeIndex(lastRowIndex1 +1, newRow1); rsi1.setCurrentRow(newRow1); }And final saveUpdate method is
public void saveUpdateButton(ActionEvent actionEvent) { // Add event code here... BindingContainer bindingsBC = BindingContext.getCurrent().getCurrentBindingsEntry(); OperationBinding commit = bindingsBC.getOperationBinding("Commit"); commit.execute(); OperationBinding operationBinding = BindingContext.getCurrent().getCurrentBindingsEntry().getOperationBinding("Commit"); operationBinding.execute(); DCIteratorBinding iter = (DCIteratorBinding) BindingContext.getCurrent().getCurrentBindingsEntry().get("VdetView1Iterator");// write iterator name from pageDef. iter.getViewObject().executeQuery(); }Thanks for all the cooperation to obtain the desired results.
Concerning
-
How many user take RDP at the same time with different user login ID in Server R2 2012
How many user take RDP at the same time with different user login ID in Server R2 2012?
How many user take RDP at the same time with different user login ID in Server 2008 R2?
How many user take RDP at the same time with different user login ID in Server 2012 starndard?
How many user take RDP at the same time with different user login ID in Server 2008 standard?
This issue is beyond the scope of this site (for consumers) and to make sure you get the best answer, we need to ask either on Technet (for IT Pro) or MSDN (for developers)
If you give us a link to the new thread we can point to some resources it -
Please forgive me for not knowing how to use this forum, I am an old man and not good at computers, I called Adobe, they said it was my only hope!
Sorry to repeat
Everything was fine until my Windows 10, lost the start feature, so I had to go back to Windows 7, in this process, I lost my Adobe Reader software, I tried about ten times with different versions and different locations, all with the same error message that is download "the feature you are trying to use is on an unavailable network resource"... are looking for It seems that it does not find when I search there, and I no longer seem to have the AcroRead.msi... the most difficult file, I try, I get deeper and deeper into things I don't know... I am looking for a simple solution!
When it gets to this point, it is probably better to start from scratch.
First of all, download, install and run Adobe Reader cleaning tool to get rid of all remains little. Here is a link to the tool: Download Adobe Reader and Acrobat tool - Adobe Labs
Then go to the following link to download the full installer for the reader.
-
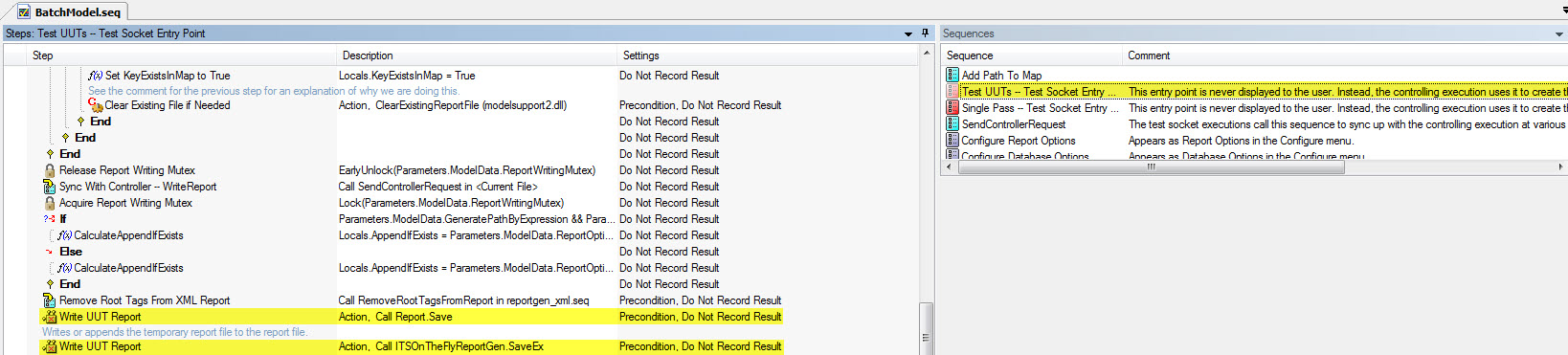
Change the sequence of commands to generate two reports by USE with different names.
I have a special situation for the model of batch processing.
Each DUT consist of two distinct products that need to be tested as a single unit.
I can run every USE and generate a test for each report. -aka. The standard use case works very well.
However, we would like the records using this method. So I need a copy with a different name for each series.
The idea behind this is that we have a story running for each half of the UUT. Given that the two halves will probably never meet.
I looked at the BatchModel.seq and read some of the documentation, but I'm having a hard time to understand what is happening.
I guess the items highlighted above are where the object to measure reports are generated. However, I don't know the mechanism for giving them the names among the Options report-> report menu Pathname file or how to change between these two points in time. Also are there tricks to get the report in duplicate with a different path in this configuration.
All links to the relevant information would be useful. Thank you
Just copy these two steps and between them and the copies have another step that is just a statement. There, you can change the path of the report by setting parameters. TestSocket.ReportFilePath the new path.
Ideally what you would do, is that the client using a callback. So, your code would look like this:
Write the object to measure report
Write the report of the object to be measured (on the fly)
Define report path reminder (override in customer OR statement step)
Write the object to measure report
Write the report of the object to be measured (on the fly)
Hope this helps,
-
Make the same comp several times with different text
Hello!
I'm looking for a way to make my 100 + times with a different text in two layers. I thought batch replicate this model and then batch change text layers, but I've been Googling autour and found no solutions.
I need is ready solution, just a direction on an approach I take to perform this task. Told me on another forum to ask here and there are a few scripts that are just what I need assistance excellent file as data. You could point me to them?
Thank you!
This is an old thread from Creative Cow that deals with a way to do what you want using a file text and Expressions:
There are also some commercial script tools that automate the process very well:
CompsFromSpreadsheet 5 - aescripts + aeplugins - aescripts.com
-
two queries against aud$ with different results
Hi guys
I'm not so good with queries and it is the reason for my question:
We have active audit and we want to get the following information (monthly):
- -How many times the logon user to the database.
- -each logon to each user in a month.
For the first (1) obligation for us to have the following query:
select USERID "Cuenta", USERHOST, TERMINAL, nombres||' '||PRIMER_APELLIDO||' '||SEGUNDO_APELLIDO "WhiteList" , count(*) "TOTAL" from aud$, ab.usuarios where (ACTION# = 100) and (NTIMESTAMP# between (to_date(to_char('01092013 00:00:00'),'ddmmyyyy HH24:MI:SS')) and (to_date(to_char('30092013 23:59:00'),'ddmmyyyy HH24:MI:SS'))) and USERID = CODIGO_USUARIO(+) and USERID not in ('DBSNMP','SYSMAN') group by USERID, USERHOST, TERMINAL, nombres||' '||PRIMER_APELLIDO||' '||SEGUNDO_APELLIDO order by USERID, USERHOST, TERMINAL;the result of this query shows like this:
Header 1 Cuenta USERHOST TERMINAL WhiteList TOTAL
-------------------- ------------------------- --------------- ---------------------------------------- ----------
ASEGUR MAQUINADIAB\SSSSS IUOOO PEPITO GARCIA GARCIA Y SOCIED 10
ASEGUR POSADASDE\MNNN4550094 MNNN4550094 PEPITO GARCIA GARCIA Y SOCIED 1
ASEGUR POSADASDE\YUMI YUMI PEPITO GARCIA GARCIA Y SOCIED 10
ASEGUR YUH PEPITO GARCIA GARCIA Y SOCIED 20
ASEGUR SDFRG PEPITO GARCIA GARCIA Y SOCIED 13
ASEGUR signy PEPITO GARCIA Y GARCIA SOCIED 29
Sigurd ASEGUR PEPITO GARCIA Y GARCIA SOCIED 32
ASEGUR valhalla-Legacy PEPITO GARCIA Y GARCIA SOCIED 12
ADMIN MAQUINADIAB\SSSSS IUOOO USER ADMINISTRATOR NETWORKING 3
SPRINGUSR bragi 98
SPRINGUSR hermod 59
SPRINGUSR YUH 49
Therefore, total logons per month per user.
for the second requirement, we use the tracking query:
select USERID "Cuenta", USERHOST, TERMINAL, to_char(NTIMESTAMP#,'YYYYMMDD HH24:MI:SS') "Fec Ing", nombres||' '||PRIMER_APELLIDO||' '||SEGUNDO_APELLIDO "WhiteList" --, count(*) "TOTAL" from aud$, ab.usuarios where (ACTION# = 100) and --to_char(NTIMESTAMP#,'dd-mm-yy')=to_char(sysdate-50,'dd-mm-yy') and (NTIMESTAMP# between (to_date(to_char('01062013 18:00:00'),'ddmmyyyy HH24:MI:SS')) and (to_date(to_char('30062013 23:59:00'),'ddmmyyyy HH24:MI:SS'))) and USERID = CODIGO_USUARIO(+) and USERID not in ('DBSNMP','SYSMAN') group by USERID, USERHOST, TERMINAL,to_char(NTIMESTAMP#,'YYYYMMDD HH24:MI:SS'), nombres||' '||PRIMER_APELLIDO||' '||SEGUNDO_APELLIDO order by USERID, USERHOST, TERMINAL;Header 1 Cuenta USERHOST Fec TERMINAL Ing white list
-------------------- ------------------------- --------------- -------------------- ----------------------------------------
UTILISATEUR12 DOMINIODDD\IOIPOP IOIPOP 20130930 12:08:33 ANGEL ROBERTO GARCIA Y GARCIA S
UTILISATEUR12 DOMINIODDD\IOIPOP IOIPOP 20130930 14:28:47 ANGEL ROBERTO GARCIA Y GARCIA S
UTILISATEUR12 DOMINIODDD\IOIPOP IOIPOP 20130930 16:24:43 ANGEL ROBERTO GARCIA Y GARCIA S
Thus, shows the opening of each session conducted per user per month.
But in the two queries, the results are different. This is not to assume that they must have the same number of logons?
I mean, if I have summarized the numbers in the TOTAL column I less that I get in the second query. Always!
could you help us?
Thank you
Hello
Why you use GROUP BY in the second query, remove it from the second query, then result will be the same
HTH
-
two rows of delete with different values
Hello
I wouldn't lines with the same id and have values of E and F 10258932.
I would like the following data:
But I have the following lines:A B C D E N -------- -- ------ ----- - - 10258927 1 103,35 0 10258929 3 284,85 89,52 E N 10258929 4 323,85 89,52 E N 10258930 5 478,80 91,53 E N 10258931 6 436,67 78,09 E N
Does anyone have an idea?SQL> with my_table as 2 ( 3 select '10258927' a, '1' b, '103,35' c, '0' d, NULL e from dual union all 4 select '10258928' a, '2' b, '0' c, '15,19' d, 'E' e from dual union all 5 select '10258929' a, '3' b, '284,85' c, '89,52' d, 'E' e from dual union all 6 select '10258929' a, '4' b, '323,85' c, '89,52' d, 'E' e from dual union all 7 select '10258930' a, '5' b, '478,80' c, '91,53' d, 'E' e from dual union all 8 select '10258931' a, '6' b, '436,67' c, '78,09' d, 'E' e from dual union all 9 select '10258932' a, '7' b, '784,88' c, '23,19' d, 'E' e from dual union all 10 select '10258932' a, '8' b, '100,88' c, '11,11' d, 'E' e from dual union all 11 select '10258932' a, '9' b, '300,88' c, '22,22' d, 'F' e from dual union all 12 select '10258932' a, '10' b, '468,25' c, '78,33' d, 'F' e from dual) 13 select a, b, c, d, e, no_ds from 14 ( 15 select a, b, c, d, e, 16 case when c > 0 and e != 'F' 17 then 'N' 18 end no_ds 19 from my_table) 20 where no_ds = 'N' or e is null 21 order by 1 22 / A B C D E N -------- -- ------ ----- - - 10258927 1 103,35 0 10258929 3 284,85 89,52 E N 10258929 4 323,85 89,52 E N 10258930 5 478,80 91,53 E N 10258931 6 436,67 78,09 E N 10258932 7 784,88 23,19 E N 10258932 8 100,88 11,11 E N 7 Zeilen ausgewählt. SQL>Oh, I read the title again once: 'remove double lines with different values.
If it means that he is not specifically E and F values, but only if there is more than one distinct value, then you can do the following:with my_table as ( select '10258927' a, '1' b, '103,35' c, '0' d, NULL e from dual union all select '10258928' a, '2' b, '0' c, '15,19' d, 'E' e from dual union all select '10258929' a, '3' b, '284,85' c, '89,52' d, 'E' e from dual union all select '10258929' a, '4' b, '323,85' c, '89,52' d, 'E' e from dual union all select '10258930' a, '5' b, '478,80' c, '91,53' d, 'E' e from dual union all select '10258931' a, '6' b, '436,67' c, '78,09' d, 'E' e from dual union all select '10258932' a, '7' b, '784,88' c, '23,19' d, 'E' e from dual union all select '10258932' a, '8' b, '100,88' c, '11,11' d, 'E' e from dual union all select '10258932' a, '9' b, '300,88' c, '22,22' d, 'F' e from dual union all select '10258932' a, '10' b, '468,25' c, '78,33' d, 'F' e from dual ) -- -- end-of-test-data -- select a, b, c, d, e, num_distinct_values from ( select a, b, c, d, e, count(distinct e) over (partition by a) num_distinct_values from my_table) where num_distinct_values <= 1 order by 1 /The county notes how the distinct non-null values in column e for each one.
Where clause then selects those with count = 0 (this is where e = null) and count = 1.
If the number is greater than 1, different values exist for this id.Choose what fits your condition ;-)
-
Interleaving of samples: two outputs analog (tables with different lengths)
CHAN AOCHANNEL1 AOCHANNEL2 AOCHANNEL1 AOCHANNEL2 .. .and so on
SAMP * * * * * * * * * * * * .............and so on
Hi guys, how could I go on the interlacing of two arrays of different lengths in a two-channel analog output?
In the illustration above, for example, I like to write 5 values in channel 1, followed a string of unique value 2 and so on...
I use DAQmx library controls to achieve this (not LabView).
I am able to write unique values each time a task is opened without any problem, I was wondering if I can interleave the berries so that values are buffered and tasks are performed with greater haste.
best regards,
Ravi
target met: I've made the following changes:
CREATION OF TASK 1
CREATION ANALOG_VO channel 1 & channel 2 in TASK 1
CONFIG. CALENDAR OF TASK 1CREATED some TENSION with SAMPLES interleaved pre
WRITING TASK 1 VALUES
TASK 1 STARTED
DAQmxCfgSampClkTiming(taskHandle1,"",SAMPLING_RATE,DAQmx_Val_Rising,DAQmx_Val_FiniteSamps,2*SAMPLE_SIZE_WX) -
How to listen to a couple of times (with different names) table in another schema?
Hello guys,.
I replicate a table schema (SCH_1) (TAB_1) on the basis of data source (named DB_1) twice on the schema (SCH_2) on the basis of data target (DB_2) with two different names (TAB_1 and TAB_1_SHORT). TAB_1_SHORT on db target must be a subset (eg. WHERE STATUS = 1) of TAB_1!
How to do? can someone help me?
I tried to realize that in this way:
(1) creation of 1 capture process with the rule 1 table on source db (without any rule of subset to capture all changes) for table TAB_1
(2) creating a process of spreading with no rules
(3) creation 1 apply the process with a rule in table for table TAB_1 without any subset_rule but with the transformation of the pattern of SCH_1 to SCH_2 (DBMS_STREAMS_ADM. RENAME_SCHEMA) = > it works correctly!
(4) creating a subset_rule (WHERE STATUS = 1), a transformation of the pattern of SCH_1 to SCH_2 (DBMS_STREAMS_ADM. RENAME_SCHEMA) and a transformation of tablename from TAB_1 to TAB_1_SHORT (DBMS_STREAMS_ADM. RENAME_SCHEMA) for table TAB_1_SHORT = > does not work, no errors posted in dba_apply_error!
in another chance, I tried to turn the table and the schemaname in the process of capture, with the effect that my first table TAB_1 would not be listened to again.
I don't know what the problem is. I think it must be possible to publish a table for two different targettables in the same pattern on an another db, is not it?
I hope that the greetings
FloHello
Adding a normal table rule and also a subset rule would not work because the rule would be evaluated only once in the set of positive rules. If the normal rule is evaluated first, then the subset rule and the rest of the rules would not be assessed at all that's why it would not work.
This can be done using one of the following methods:
Method 1:
1 use the declarative transformation on the capture/apply and rename SCH_1 to SCH_2 scheme.
2. now, on the site apply, define a DML for SCH_2.TAB_1 Manager
3 al ' DML Handler, do the following:
a. get the value of the STATUS column
b. check if the value of STATUS = 1, if yes, then change the name of the object to TAB_1_SHORT and run the LCR.
(c) another thing not to change the name of the object (leave it as it is, TAB_1) and run the LCR.
Method 2:1. Add a DML for SCH_1.TAB_1 Manager
2. in the DML handler perform:
method of set_object_owner use of LCR$ _ROW_RECORD to rename the owner at the SCH_2
b. get the value of the STATUS column
c. check if the value of STATUS = 1, if yes, then change the name of the object to TAB_1_SHORT and run the LCR.
(d) another thing not to change the name of the object (leave it as it is, TAB_1) and run the LCR.Please let me know if you need examples of code.
Thank you
Florent -
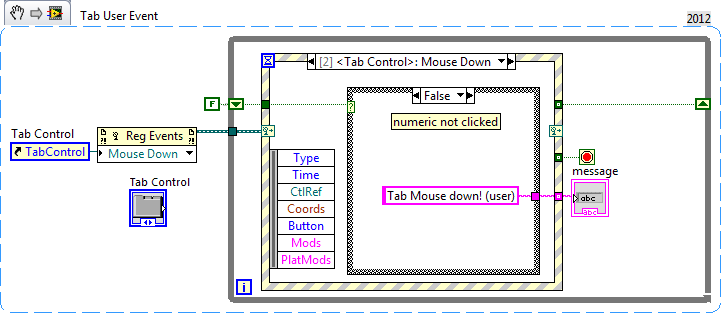
Hi all
I have a digital control in a tab control. Both of them have their own events 'mouse-down' in a while loop. But when I click on the digital command, instead of raising the event of digital control only, both of these two events fired.
Maybe I can check if the mouse is in the range of digital technology to filter events, but if the window is resized, I have to recalculate the range once again.
Is there another way to do it?
I pasted the test code too.
Thank you!
Excerpts of work
Side note: I really don't like the controls on the tab and use them very rarely. And the few times I use them, it is for tabs to which I often use to select among the screws to put in a secondary school.
-
Export to JPG format several times with different resolution
Hello world
I want to export my document of jpg files in different resolutions - an overview and a thumbnail image. I use this code, I found here in the forum for export:
function exportPages (_dpi, _destFilename) {}
try {}
app.jpegExportPreferences.exportResolution = _dpi;
app.jpegExportPreferences.jpegQuality = JPEGOptionsQuality.LOW;
app.jpegExportPreferences.jpegExportRange = ExportRangeOrAllPages.EXPORT_ALL;
app.scriptPreferences.version = "7.0".
app.jpegExportPreferences.jpegColorSpace = JpegColorSpaceEnum.RGB;
app.scriptPreferences.version = "6.0".
app.activeDocument.sections.everyItem () .includeSectionPrefix = false;
var f = file (_destFilename);
app.activeDocument.exportFile (ExportFormat.jpg, f);
} catch (err) {}
Alert (err.message);
}
}
and I call you
exportPages (96, "~ / jdExport.jpg");
exportPages (30, "~ / jdExportThumbnail.jpg");
This should create images with 96 DPI and dpi 30. But after the first call the app.jpegExportPreferences.exportResolution is not defined. I can swap function calls - first works, second fails.
No idea why I can't export twice?
Thank you
Klaus
He finds myself - there the
app.scriptPreferences.version = "6.0".
I shouldn't use copy & paste the code from the forum without understanding
-
can I take my time with me capsule to use as an external drive?
I will be away for several months, taking only my laptop. All my work files are on the Big Mac, who will not be with me. If I take the capsule of time with me, I can access all the backup files as if I had to access the Big Mac?
IMHO that's a great way to do things.
Transport CANADA is much more fragile than a cheap USB portable 2 TB drive.
In addition, your files can be difficult to obtain at a TM backup.
Copy all the files you need on the portable player of 2 TB. I would recommend that you partition so that you can also use it for backups that you travel. They are self-powered of almost any Mac laptop... neat, quick and good light cheap for transporting.
If you buy one of the best... robust... but I like the Toshiba brand... or buy LaCie Robust.
-
Time Capsule does not remove older backups.
Our 2 TB time capsule is full and no more deletes older backups so new back ups fail. We have two Macs with El Capitan. What can we do for the capsule of time delete old backups?
Unfortunately, when the proposed backup is too large, Time Machine can not delete older files to make room for new backups.
Your options... in terms of more expensive down... are:
(1) add an another Time Capsule and begin to go to backups
(2) add a USB hard drive to your existing Time Capsule and start to go back up
(3) erase the hard drive on the existing time Capsule and start backups
-
reuse of filters with different values
We have a usage scenario where the same filters will have to be applied several times with different values. Looking the javadocs, it seems like there is no way to change the values of pre-packaged filters (EqualsFilter, GreaterFilter etc.). Is that correct or is there a way to do it? I see that if we use CohQL, we can use bind variables to do this. However, the use cases we should rather just more complex extractors ReflectionFilters.
In addition, there no performance impact by using CohQL against java constructs directly?
Thank you
Manju.Hi Manju,
While it is true that you cannot change values in the built in filters, even if you could it wouldn't make you save a lot on the construction of a new filter every time. I guess that if you build a very large number of filters, then you're going to create more garbage, but that shouldn't be a problem either. Some of the more specialized filters also contain State so that you do not want to resuse them.
The main performance issue I know with CohQL which is only creates extractors of reflection so won't enjoy all serialized POF values you have. If you have indexed each value you want to query on using the same extractors relflection then it would help, but again, this means that everything you deserialization of the values for the query or insert to update the index.
Kind regards
JK


Maybe you are looking for
-
Pavilion 15 n011tu: indicators of Volume and brightness is not displayed
Hello I lowered the score of 8 Win Win 7 (64) and since then the volume and screen brightness indicators did not show. The keys work properly. HP Support Assistant displays all the missing drivers. Any help?
-
Where can I find the instructions to divide my drive so that I can load 10 Windows and Windows 7?
* Original title: Windows 7 and 10 Where can I find the instructions to divide my drive so that I can load 10 Windows and Windows 7, so that I can chose the one that I want to run. I need Windows 7 to run stand alone so that I can continue to use the
-
Wireless adapter does not work.
Original title: wireless I install win7 in my fujitsu siemens AMILO Li 1718 model system, all the drivers are installed but I have problem with my wireless, wireless is not see the amything all available wireless driver is installed courrently can so
-
The software opens with a lock to the computer, it opens on to and then can be copied from there to another computer. The program has been downloaded on all versions up to XL. The 64-bit to 32-bit conversion programs do not allow a download on my W
-
With the help of directpath with a sound card
HeyI run a test to get a sound card to work within an esxi installation.It's the hardware running im:VMware esxi 5.0 U1Server 2008 R2 X 64card board - reaktek ALC269 HD Audio (VEN_10EC & DEV_0269)I redirected the sound card in the machine and I insta