Analysis of XML files
I have a problem, the analysis of this XML file. I swear it worked but now the sections DC_Source and DC_Load return null.
In XML (Subvi) .vi tag monitor, look at the results on the terminal. The wire that connects to the Terminal should use a shift register.
Tags: NI Software
Similar Questions
-
Analysis of XML file with the word & quot; Infinity & quot; in it
I'm having a problem in Flex that parses an XML file, one of the names in the text file contains the word "infinite". Unfortunately, it is a constant in Flex and the element of my table don't think it's a text string but a value. I tried the definition of the xml element type and by putting the characters exhaust around the text, but nothing does. If I change the text of tiny "infinite", it works fine.
Any help much appreciated.This looks like a bug. You can drop, with an example of the size of the code which illustrates, here:
Thank you!
Matt Horn
Flex docs -
Hello
I try to access a web service. I am currently using NetBeans 6.5. I am able to acess webservice by creating the stub.
This draft is back this xml content in a string format
so, when I try o use
SAXParserFactory saxfact = SAXParserFactory.newInstance ();
SAXParser sp = saxfact.newSAXParser ();
Sax InputSource = new InputSource (temp); Temp is the string that's been out since the heel in a string format
TPI Parse (Sax, this); on this step, the code is throwing an exception
/ * org.xml.sax.SAXParseException:
org.xml.sax.helpers.DefaultHandler.fatalError (+ 1)
com.sun.ukit.jaxp.Parser.panic (+ 18)
com.sun.ukit.jaxp.Parser.setinp (+ 203)
com.sun.ukit.jaxp.Parser.parse (+ 42)
analysis.(parsing.java:54)
to call_to_webservice.run(call_to_webservice.java:54) * /.I'm stuck here
I was trying to access xml directly, but the statement sp.parse () takes InputSource or InputStream
need help very urgent
Thanks in advance
Hi Panknaik,
Try this code,
try {}
SAXParserFactory plant = SAXParserFactory.newInstance ();
SAXParser saxParser = factory.newSAXParser ();
org.xml.sax.helpers.DefaultHandler Manager = new xmlReader (startTag, endTag); start and endtag you want to analyze. InputStream in = new ByteArrayInputStream (response.getBytes("UTF-8"));
InputSource source = new InputSource (in);
saxParser.parse (source, handler);
} catch (Exception e) {}---------------------------------------------------------------------------
Then extends DefaultHandle,
/**
* A class containing a generic logic to read an XML file.
*/
class xmlReader extends DefaultHandler {}
private String startTag; /**< start="" tag="" to="" be="" looked="" for.="">
private String endTag. /**< end="" tag="" to="" be="" looked="" for.="">
Private boolean currentTag;
Private boolean Errortag.
String tagValue;
/**
* Sets the start and end tag to be read in the XML file.
startTag @param tag beginning.
endTag @param tag end.
*/
{} public xmlReader (startTag, endTag String String)
this.startTag = startTag;
this.endTag = endTag;
}
/**
* Startup item implementation of the DefaultHandler.
*/
' public void startElement (String namespaceURI, String localName,
String qualifiedName, attributes atts) throws SAXException {}
If (localName.equals ("error"))
Errortag = true;
ElseIf (localName.equals (startTag))
currentTag = true;
}
/**
* Implementation of the DefaultHandler element ends.
*/
' public void endElement (String namespaceURI, String localName,
String QualifiedName) throws SAXException {}
If (localName.equals ("error"))
Errortag = false;
ElseIf (localName.equals (endTag))
currentTag = false;
Else if (currentTag == true) {}
attribValue.addElement (tagValue); Add it to vector
tagValue = "";
}
}
/**
* The treatment on the tag to read.
ch @param String containing the tag.
@param start starting location of the tag.
@param tag length.
*/
characters public Sub (ch of char [], int start, int length)
throws SAXException {}
Dim str As String = new String (ch);
String tempTagValue = str.substring (start, start + length);
If (Errortag is true)
errorNo = Integer.parseInt (tempTagValue);
Else if (currentTag == true)
tagValue = tempTagValue;
}
}I think that it solve your problem.
Kind regards
-Jitu.
-
Two apparently identical xml files. A fine exception analysis expects a name
Hey. For a beginner to xml, these look similar v:
Analysis:
Will not scan:
Code is below. Thoughts why?
private static NodeList GetNodeListFromInputStream(InputStream is) { NodeList list = null; try { DocumentBuilderFactory docBuilderFactory = DocumentBuilderFactory. newInstance(); DocumentBuilder docBuilder = docBuilderFactory.newDocumentBuilder(); docBuilder.isValidating(); Document doc = docBuilder.parse(is); // FAILS HERE- why // Get stream from xml file // 2 ways to do it- heirarchically from root node or getElByTag* as a list. We do list list = doc.getElementsByTagName("*"); } catch ( Exception e ) { System.out.println( "\n\n*****************\n" + e.toString() ); } return list; }If you don't find anything, why not try and write it yourself? You can easily write a parser of the state machine-based in order to transform the entrance in a simple way.
-
error analysis in the file c:\program files (x 86) \hp\digital imaging\bin\hpqscloc\1033.xml
Hi all..
I had this problem for a while now, but now its got to the point where I can't scan anything now or the other.
If I try to click on the HP Solution Center, all I get is a popup saying "error analysis in the file c:\program files (x 86) \hp\digital imaging\bin\hpqscloc\1033.xml.
I had a link to the screen so that I could use my scanner, but now it will not work, and I tried uninstalling and reinstalling every driver HP & file I can find, but I'm not getting anywhere. Any ideas?
IM using a laptop Toshiba Satellite C660D-1 and can connect to my HP Officejet 6500 has more (E710 n) by usb and wireless network.
IM using 64 bit Win 7 Home Premium, Service Pack 1, with an AMD E - 450 APU Radeon HD Graphics and 6 GB of ram.
Its a cell phone works, so reformatting wouldn't the best solution, even if it's as well as I would have originally been.
Any other suggestions would be appreciated
Thanks in advance
Roy
Hi DavRao
Thanks for the answer... Sorry that I won't be back for you so far, I ended up going out on the road all week.
I had already seen the advice below on the first page I've found in research to help, but I forgot to mention that I had already tried.
I have a drive and downloaded another copy of my drivers, but at no time I found L4uninstall.exe
Also, I do not consider the L1, L2 and L3 uninstall that I've seen mentioned previously...
I found the uninslaller on the HP Web sites, and runing it me have once step 1, a second round was stage 2, stage 3, stage 4.
By now, I got desperate and tried everything I thought that could help to remove all traces of services in msconfig, uninstall everything related to HP, I even backed up and then deleted (in desperation) and the entered boot records of HP.
Nothing helps. Uninstall would start to remove the drivers, but just before it finished every time, it would start to recede and that should give up then.
I ran a system restore to before you start tweaking options, etc, just so that everything was back to normal, but still does not...
Then downloaded and installed "Iobit Advanced Uninstaller" (100% free to use)
http://www.iobit.com/advanceduninstaller.php
This allows to uninstall all references of HP and its first rotation used the regular unilstall sequence and didn't, but then he gave me the choice of force uninstall...
He gave me options of backup/backup so that if things went wrong, it could be cancelled... and it all uninstalled... Then authorized registry references and a set much more that I never would have found manually.
After that restart 99% of HP had disappeared... I then used CCleaner (100% free to use)
http://www.Piriform.com/CCleaner
It cleaned all the cookies for leftovers, abandoned the entries in registry etc...
I was on the moon...
HP full software downloaded again, just to be sure, I got later and he ran...
It was the same version that I had often tried to install above all that I had been unable to remove, but this time, the options and the stadiums were completely different, it was as if my laptop had never seen a HP printer before and has been learning new.
Installed perfectly, (with all updates and shopping addons unchecked)
My scanner now works on the whish network wireless its NEVER done in almost 2 years.
All the drivers are up to date, where as before, I often saw up to 10 versions of my printer all the tag errors, even if the printer would work for basic operations...
IM happy now IM 100% healed...
All this thanks to 2 bits of free software that I am now keeping the hand on lol...
Hope this helps someone else with similar issues
Roy
Fan of HP printer, HP software hater
-
Problem with large XML files over HTTP segmented analysis
I am trying to isolate a bug introduced when the JRE in Java 7u51 use 7u71 without changing the codes. The problem seems to be very similar to: Bug ID: JDK-8027359 XML parser returns incorrect results of analysis.
Further investigation showed that it was also introduced in the same versions (7u71) where this patch has been applied. Unlike this bug, my XML is marked as version 1.0. He also seems to be with only large XML, the order of 10 MB files or more.
Is the closest I've been able to reduce it down to the code uses JAXB to disrupt a flow which tells me that the debugger is an org.apache.http.com.EofSensorInputStream / org.apache.http.impl.io.ChunkedInputStream. The exception I get is not consistent, but usually appears from pieces are replaced or mixed, with result the letters appearing in the attributes that are actually numbers, or like the following, where an attribute "testAttribute" gets partially crushed by the end of a timestamp that was in another section of the XML file.
javax.xml.bind.UnmarshalException - with linked exception: [javax.xml.stream.XMLStreamException: ParseError at [row,col]:[1,98748] Message: Attribute name "testAttribu00Z" associated with an element type "testElement" must be followed by the ' = ' character.] at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.handleStreamException(UnmarshallerImpl.java:421) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal0(UnmarshallerImpl.java:357) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal(UnmarshallerImpl.java:334) Caused by: javax.xml.stream.XMLStreamException: ParseError at [row,col]:[1,98748] Message: Attribute name "testAttribu00Z" associated with an element type "testElement" must be followed by the ' = ' character. at com.sun.org.apache.xerces.internal.impl.XMLStreamReaderImpl.next(XMLStreamReaderImpl.java:598) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.StAXStreamConnector.bridge(StAXStreamConnector.java:181) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal0(UnmarshallerImpl.java:355) ... 6 more
A code here which seems to reproduce if you can connect to an XML server that returns a large segmented XML file:
SchemeRegistry registry = new SchemeRegistry(); registry.register( new Scheme("http", 80, PlainSocketFactory.getSocketFactory())); HttpClient client = new DefaultHttpClient(new BasicClientConnectionManager(registry)); String url = "http://someUrlReturningAlargeChunkedXML"; HttpGet method = new HttpGet(url); HttpResponse response = client.execute(method); InputStream inputStream = response.getEntity().getContent(); XMLStreamReader responseReader = factory.createXMLStreamReader(inputStream); JAXBElement<JaxBObjectOfResponse> wot = unmarshaller.unmarshal(responseReader, JaxBObjectOfResponse.class);There is no error if you connect using URL.openStream () to the same service. If I read bytes directly and write to a file, there is no error. The error occurs only when I try to disrupt it is great and I use Java 7u71 (or later). It can be constantly repeated with the jsp webapp I use, but did not show the error when I used the same code with a Wikipedia dump XML file.
How can I unmarshal differently to avoid this problem? Or, how can I best isolate the bug so it can be sent to the appropriate bugs system?
Seems to be related to this bug, which will be fixed in 7u80 and others (in April?).
http://bugs.Java.com/bugdatabase/view_bug.do?bug_id=8059327
Tests with the final version in early 7u80 showed it fixed my related question.
-
What is the recommended API for reading/analysis of XML in Java files?
Hello, everyone!
In my application, I have to read a XML file. I think that Java has several APIs to parse XML files and as I am new to this, I would like to know from you what is the recommended Java for this API.
Thank you.
MarcosUnless you plan to edit nodes and I would recommend that you use a Sax parser, which is a lot less hunger of memory as a DOM parser. The DOM parser to read the entire document in memory for the manipulation of the user.
If you are looking only to read the document and extract specific values then a DOM parser would be an exaggeration. If you are planning leave the document unchanged then a SAX parser is the way to go - a little more complex to write but worth the extra as it will be faster and more scalable. -
Hello
I work with an XML file that is generated through the API of Google Books. I'll apologize in advance if I don't get quite accurate XML terminology - it's my first foray into some of the tags XML see I'm reading a XML file in and attempt to send data:
"< cfhttp url = 'http://www.google.com/books/feeds/volumes?q=john+grisham+the+firm & min-viewability biased =" method = "GET" > "
< CFSET xmlfile = xmlparse (cfhttp.filecontent) >
< cfset xmlsize = arraylen (xmlfile.feed.entry) >
< cfloop from = "1" = "" #xmlsize # "index ="a">"< b > title: #xmlfile.feed.entry [a].title.xmlText # < /b > < br >
< b > Format: #xmlfile.feed.entry [a].format.xmlText # < /b > < br >
< b > author: #xmlfile.feed.entry [a].creator.xmlText # < /b > < br >
< b > identifier1: #xmlfile.feed.entry [a].identifier.xmlText # < /b > < br >
< b > identifier2: #xmlfile.feed.entry [a] .identify [2] .xmlText # < /b > < br >< / cfoutput >
< / cfloop >It works pretty well. Here's the problem: there is often a third identifier field (xmlfile.feed.entry [a] .identify [3] .xmlText)- but not always.
I'm testing the existence of this field before you post. I tried the following:
< CFIF isdefined("xmlfile.feed.entry[a].identifier[3].xmlText") >
is defined< CFELSE >
is not defined
< / cfif >Gives the typical error:
Parameter 1 of function IsDefined, which is now xmlfile.feed.entry [a] .identify [3] .xmlText, must be a valid variable name syntactically.
I would use structkeyExists, but I can't understand how the third node (?) using the reference code:
< cfif structKeyExists(xmlfile.feed.entry[a],"identifier") > only works for xmlfile.feed.entry [a] .identify [1] .xmlText
< cfif structKeyExists(xmlfile.feed.entry[a],"identifier[3]") > is not valid.
So with strucktkeyexists, I can not understand how to properly reference the name of the variable...
Any help? Or the best ideas to verify the existence of this variable?
The node you are looking at is an array, so:
you need to do. At the present time, you test for the attribute 'xmltext' rather than to check its node parent exists.
HTH.
-
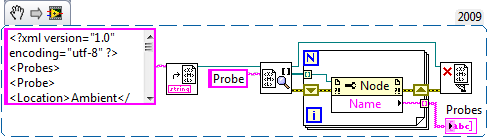
Just starting to learn more about XML.
I have a simple XML I created which is
Ambient panel1 panel2 panel3 Using the XML property - child results node table of nodes in a table of 9 elements:
#text Probe #text Probe #text Probe #text Probe #text
My question is what are all the #text that are there? Should the child nodes be not just the probes?
It seems to me you may be heading down a dark path. Instead of using the "table of nodes child" and fighting through the unnecessary complications and text nodes, let me suggest you look at XPath and using "get all matched Nodes.vi ' or 'Get first match Node.vi' to get the items. XPath allows parsing XML child's play.
For example:
Of course, I hope that you use XP does not mean you use LV8.6 or earlier since the XPath screws are new to LV9.
If you use LV8.6 or earlier, I suggest looking in the .NET functions to implement XPath. Once you get the hang of it, it still beats the attempt to parse XML the old-fashioned way.
As for the editor, I generate very few XML files by hand, for the most part I bring other programs and analyse them in LV again, XPath adjusts the rough edges.
-
Hi guys,.
I need to parse a XML file. These XML files have sizes range from 4 k to 1500 k.
My code currently supported files XML as an InputStream as shown below.DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); factory.setIgnoringElementContentWhitespace(true); DocumentBuilder builder = factory.newDocumentBuilder(); ByteArrayInputStream stream = new ByteArrayInputStream(xmlData.getBytes()); Document doc = builder.parse( stream ); // <-- this string works very slow !!!!!!!!
It works fine, but when the size of the file (for example) is about 1200 KB, it took 12 minutes to parse this file. It is extremely slow and unusable... It freezes device and I need to wait until the end of the analysis...
Is there another way to analyze large files? Why it works slowly? Does anyone have the same problems? Help, please!
Thanks, Vlad.
Thanks Simon! I'll try it

-
HTTP Communication tutorial - parsing of the XML file error
Hello again,
I went through the tutorial of HTTP Communication today is here. Built just fine and it loaded into the Simulator, however when I hit refresh to load the XML from an HTTP network call I get the error:
XmlDataModel: Analysis of the file error... /... /.. /Data/model.XML on line 14, column 8: "unexpected character.
After the end of the XML file, given the location of the character of line 14, column 8 is that it really confused me.
Any thoughts on how to bypass this?
The XML file can be found at https://developer.blackberry.com/cascades/files/documentation/device_platform/networking/model.xml
try changing the url https://developer.blackberry.com/cascades/files/documentation/device_platform/networking/model.xml
-
RSS feeds save in the xml file in the device memory
Hello
I'm in the analysis of an RSS feed with SAX parser. Now, I want to record the first RSS an xml file in the memory of the device or on the SD card. Can someone guide me through this process
To write in an XML rss content, start by creating the file with the extension ".xml" with the help of the FileConnection API, then write content (rss data) in the XML file.
You can use code below to write the content in the file. We must give the path as a string & content in byte format.
public boolean writeFile(String path, byte[] data) { javax.microedition.io.Connection c = null; java.io.OutputStream os = null; try { c = javax.microedition.io.Connector.open("file:///" + path, javax.microedition.io.Connector.READ_WRITE); javax.microedition.io.file.FileConnection fc = (javax.microedition.io.file.FileConnection) c; if (!fc.exists()) fc.create(); else fc.truncate(0); os = fc.openOutputStream(); os.write(data); os.flush(); return true; } catch (Exception e) { return false; } finally { try { if (os != null) os.close(); if (c != null) c.close(); } catch (Exception ex) { ex.printStackTrace(); } } } -
Hello...
I would like to publish this example to help pasring xml or live feed from a URL.
SAXParserFactory plant = SAXParserFactory.newInstance ();
SAXParser saxParser = factory.newSAXParser ();DefaultHandler Manager = new DefaultHandler() {}
' public void startElement (String uri, String localName, String qName,
Attributes attributes) throws SAXException {}
If (qName.equalsIgnoreCase ("an element of xml"))
{vector.addElement (attributes.getValue ("attribute of an element"));
}
ElseIf (qName.equalsIgnoreCase ("second item FRO xml"))
{attributteValue = attributes.getValue ("title");
}
' public void endElement (String uri, String localName, String qName)
throws SAXException {}currentElement = false;
If (qName.equalsIgnoreCase ("end of the element"))
{
do something
}}
};
S StreamConnection = null;s = (StreamConnection) Connector.open ("enter the url that provides the xml file");
HttpConnection httpConn s = (HttpConnection);If (httpConn.getResponseCode () is 400)
{
Dialog.Alert ("internett noaccess");}
InputStream input = null;
entry = s.openInputStream ();Reader reader = new InputStreamReader(input,"UTF-8");
InputSource is = new InputSource (reader);
is.setEncoding("UTF-8");saxParser.parse (, Manager);
}Add the required elements of the XML in the analysis to the vectors and do something.
SAX (Simple API for XML) is a parser based on the events in sequential access API developed by the XML - DEV list for XML documents. SAX provides a mechanism for reading data from an XML document that is an alternative to that provided by the DOM (Document Object). When the DOM works on the document as a whole, SAX parsers function on each element of the XML document in order.
SAX parsers have certain advantages over DOM-style parsers. A SAX parser doesn't need to declare every event analysis what happens and almost all of these once-reported information normally rejects (he does, however, keep some things, for example a list of all the elements that have not been closed yet, in order to intercept errors later as the end tags in the wrong order). Thus, the minimum memory required for a SAX parser is proportional to the maximum depth of the XML (i.e. the XML tree) and the maximum data involved in a single XML event (for example, the name and the attributes of a single tag start, or the content of a processing instruction, etc.).
This amount of memory is generally regarded as negligible. A DOM parser, however, usually built a representation of the tree of the entire document in memory at first, using memory that increases with the length of the entire document. It takes a lot of time and space for large documents (memory allocation and the construction of data structures take time). The advantage of compensation, of course, is that once loaded no matter what part of the document are accessible in any order.
I hope this post was helpful.
Welcome on the support forums.
Thank you for contributing. There is however a minor problem: all blocking operations must be made on a separate thread. You cannot use Dialog.alert on a thread without use invokelater or synchronization on the eventlock, you should fix that.
In addition, there are a lot of response codes, and you should check for 200 continue, otherwise trigger an error.
There is also a xmldemo in the samples provided with the eclipse plugin or JDE, but it uses DocumentBuilder, no Sax.
-
Analysis of XML with SAX parser
It comes to my XML. I am able to analyze using the DOM parser, bt I m new analysis SAX. Can someone help me to analyze it using SAX parser
There is a snippet of Code to call the HTTP Xml & only to the analyzed using Sax parser.
SAXParserImpl saxparser = new SAXParserImpl(); ListParser receivedListHandler=new ListParser(); static DataInputStream din = null; public static String response; HttpConnection hc = null; OutputStream os; try { final String url =""+ InitClass.getConnectionString()+";ConnectionTimeout=25000"; hc = (HttpConnection)Connector.open(url); os = hc.openOutputStream(); os.write(postDataBytes); if (hc.getResponseCode() == 200) din = hc.openDataInputStream(); else response = "" + hc.getResponseCode(); saxparser.parse(din, receivedListHandler); } catch (Exception e) { } finally { try { if(din!=null) din.close(); din = null; if(hc!=null) hc.close(); hc = null; } catch (Exception e) { } } class Analyzer
public class ListParser extends DefaultHandler { private String Key=""; private Hashtable ht=new Hashtable(); vector vec = new Vector(); public ListParser() { } /** * Gets called, whenever a Xml is start . */ public void startDocument() throws SAXException { } /** * Gets called, whenever a Xml is End . */ public void endDocument() throws SAXException { } /** * Gets called, whenever a new tag is found. */ public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException { if(name.equals("")) { ht = null; ht = new Hashtable(); } else if(name.equals(" ")) { } Key=name; } /** * Gets called, whenever a closed tag is found. */ public void endElement(String uri, String localName, String name) throws SAXException { if(name.equals(" ")) { vec.addElement(ht); } } public void characters(char[] ch, int start, int length) throws SAXException { String element=new String(ch, start, length); ht.put(Key, element); } } It will analyze your XML file and you will get data of vector vec in hash tables by XML tag.
-
Analysis of XML base using E4X syntax
Hello
I'm going crazy with E4X parsing. I'm trying to parse an XML document that is rather simple, but I can't seem to find a way to analyze what I need.
I try to extract the name of vApps (VAPP only 1 in this example):
var xmldoc = new XML(test); if (!xmldoc) { System.debug("XML PAS BON"); var errorCode = "Invalid XML Document"; throw "Invalid XML document"; } System.debug("test 1 : "+xmldoc..AdminVAppRecord.@name);It's (a response to vCloud Director REST API 5.1) XML content:
<?xml version="1.0" encoding="UTF-8"?> <QueryResultRecords xmlns="http://www.vmware.com/vcloud/v1.5" total="1" pageSize="25" page="1" name="adminVApp" type="application/vnd.vmware.vcloud.query.idrecords+xml" href="https://myvcloudhost.com/api/admin/extension/vapps/query?page=1&pageSize=25&format=idrecords&filter=isExpired==true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.vmware.com/vcloud/v1.5 http://myvcloudhost.com/api/v1.5/schema/master.xsd"> <Link rel="alternate" type="application/vnd.vmware.vcloud.query.references+xml" href="https://myvcloudhost.com/api/admin/extension/vapps/query?page=1&pageSize=25&format=references&filter=isExpired==true"/> <Link rel="alternate" type="application/vnd.vmware.vcloud.query.records+xml" href="https://myvcloudhost.com/api/admin/extension/vapps/query?page=1&pageSize=25&format=records&filter=isExpired==true"/> <AdminVAppRecord vdcName="john-vdc" vdc="urn:vcloud:vdc:4cc245-23f0-439a-9b98-e85319106af1" storageKB="8388608" status="SUSPENDED" ownerName="system" org="urn:vcloud:org:19893ffe-b5de-40a6-9a08-307e41ac0f49" numberOfVMs="1" name="qsdqs" memoryAllocationMB="3072" isVdcEnabled="true" isInMaintenanceMode="false" isExpired="true" isEnabled="true" isDeployed="false" isBusy="false" creationDate="2013-08-02T15:01:39.260+02:00" cpuAllocationMhz="2" id="urn:vcloud:vapp:fe07c653-4848-4f03-a1f8-ddba8da13a50" honorBootOrder="false" pvdcHighestSupportedHardwareVersion="9" cpuAllocationInMhz="4000" taskStatus="success" lowestHardwareVersionInVApp="9" task="urn:vcloud:task:090db9f8-4b04-4550-a1a3-5396c4f25043" autoDeleteDate="2013-08-10T17:47:56.683+02:00" numberOfCpus="2" taskStatusName="vdcUpdateVapp"/> </QueryResultRecords>
Could someone give me a hand on this one? I believe that an example of work would be enough for me to start the analysis correctly.
Thank you for your help.
A few errors here:
1. your XML file is not correct because it contains no sequence of escape '&' characters; they should be replaced by '& '.
2. your XML elements are in a namespace (see "xmlns" attribute), but your E4X query is not. You must define the namespace, for example
var vcloud = new Namespace("http://www.vmware.com/vcloud/v1.5");and then the query will become
System.log("test 1 : " + xmldoc.vcloud::AdminVAppRecord.@name);Hope this helps,
-Ilian
Maybe you are looking for
-
Firefox asks me if I run as administrator, but then won't let me install.
I have download firefox, when I try to install it tells me that I may not have permission to perform all tasks as an administrator and then gave me a password, I do not know, and if I click on as an administrator of the computer, it stops.
-
364XL cartridges do not match my Photosmart printer 7520
I recently bought replacement ink cartridges for my printer Phtotsmart 7520 (all 364 XL). I used the HP tool to make sure that I found the correct cartridges, and according to what I read (also on the cartridge packaging) they should adapt my printe
-
Hi there I have an acer aspire one and I have a problem with my wireless connection.
Hi there I have an acer aspire one and I have problems with my wireless connection.it is connected, but I can't use internet.any thoughts? Thank you
-
Reformatting of the x 3 disk password
Product HP2140 Windows xp S / N: {private information deleted} p/n NN357EA #AK8 I can not English, I write by the translator. Formatted disk and I can't run my laptop. He wrote the x 3 password, but I had not asked at all, so I can't install. Thank y
-
Where can I find the history for the cat? I had a Bold9900 and it has been automatically saved under each contact we've talked about, but the new classic doesn't seem to have it? Maybe I don't know where to look?