Better way to access a class in reading/writing of several other classes?
I need run to be retained on a class that gets read and written by the other classes. They share no common ancestor. The reads/writes will be synchronous, so there is no race condition to worry. My idea is to have just the class of all classes that need to access private data and make a 'transfer' between classes, e.g. bundling and unbundling in the classes that need it. This seems very messy. Any ideas?
I use a data value reference in this situation. You do just a digital recorder that contains your shared class, and then pass this DVR in all your other items to their initialization. Given that everyone who needs to change the data has a reference to the data, anyone can modify it within their private methods through a Structure of elements in Place.
Tags: NI Software
Similar Questions
-
A better way to make a continuous read/write on a NOR-6008
Hello
I use a USB of NOR-6008 module and have a loop of the software configuration where I acquire analog signals, digital signals, then, then put a digital high or low and repeat. I use digital multiplex outside the material so that I can use 6 of the analog inputs to read 12 signals. The digital inputs that I have are connected to the buttons on a panel that are used for the entry instead of the screen of the computer of the user. My loop is also to build a buffer zone of all the signals on the analog and digital lines that I read in so I can on average and this process elsewhere in the program.
The question that I am running is because this loop is very slow and on the final product is performed on a touch screen, XP Embedded PC and just this acquisition loop begins again as much CPU as the rest of my program. I would say that drops of loops on 4 or 5 cycles per second, which means that my update of 2 multiplex signals or longer than a second time. I would really like to better performance and does not use as much of my CPU resources.
I use a way simple enough to make the loop of the acquisition, by setting the parameters I, reading, deleting the task, defining the parameters DI, read, erase the task and then by setting the parameters, write about it and delete the task, which gives a slight delay and repeat.
Any thoughts on a better way to start the read/write that what I'm doing?
I have attached the code examples in the loop of the acquisition that I use.
Thank you!
First of all, the best plan is to move the chain DAQmx before the loop to create and use a start DAQmx, then write in the loop, then clear once the loop ends. This configuration must be done once, not every time you write the channel. This should speed things up considerably.
-
Is there a better way to eliminate the "frequently used tools.
toolbar (which I've never used!) to open whenever I open Acrobat
drive. rather than uninstall Acrobat and use another PDF reader?Hi jg49392310,
You can disable the tool pane with Adobe Acrobat Reader DC was last updated, see this note cover hide the tools Panel in Acrobat and Acrobat Reader DC at all times.
Kind regards
Nicos
-
can you suggest a better way to store and read Arabic oracle database?
Hello
can you suggest a better way to store and read Arabic oracle database?
My oracle database is Oracle Database 10 g Release 10.1.0.5.0 - 64 bit Production UNIX HP - UX ia64.
NLS_NCHAR_CHARACTERSET AL16UTF16
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
WE8ISO8859P1 NLS_CHARACTERSET
I currently stored data in field nvarchar2. But I'm not able to view it properly.You're still on 10gR 1, so even when NVARCHAR2 is used, when you insert characters, these are first converted into WE8ISO8859P1, which does not support Arabic.
It is not a problem to read the characters, if they are properly stored.
If you have a fundamental problem with normal data characters. -
Easy way to access your Photos
Hello
is there an easy way to access my photos in the Photo for OS X app?
I know that I can export (for example on the desktop) and then drag and drop it into the destination folder/app
Another way is to use the menu to access media when opening files in apps but its not convenient to get the right picture.
Are there other/better ways that I can get my faster photos to other applications?
Use the menu to share Photos to share on Facebook or other applications.
And if you want to open photos in other applications, you can use the extensions of these photo editing applications. Or use the External Editor extension to open any other photo editor of pictures.
Check out these links:
-
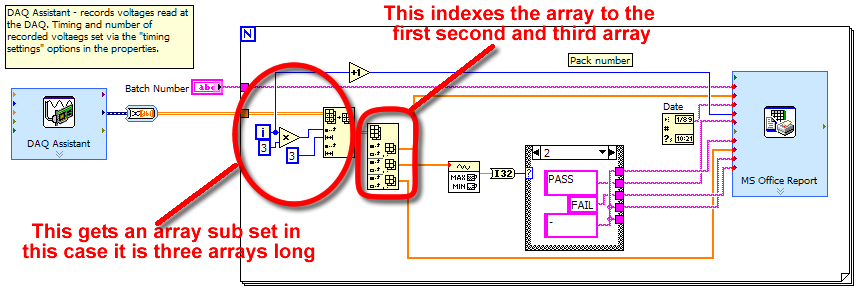
There must be a better way to do this
There must be a better way to do this!
25 separate reports - 1 voltage recorded by chanel every minute for 21 hours (end - times will have to be changed)
Anyone has ideas/directions
CC
The DAQ Assistant reads the tensions based on the timings specified, which means that if I set the number of samples finish say 20 and the frequency of samples to 1, then data acquisition will take 20 seconds to save 20 data points (one second) per channel. Then the DAQ pump data to the loop that creates reports (N number of reports).
TO answer this question: the DAQ Assistant will do exactly what you suggest here.
Two questions:
-the loop will be able to separate the different channels ie first report contains data AI1, AI2 and AI3, then the second contains data AI4, AI5 AI6 etc.. ? What is the purpose of the table screws?
TO answer this question: If you look inside the front loop, you see I have the sub table value function. I have set the index to the increment and then multiply 3 X. The first time in the loop take 0 and multiply by 3 and I get zero. second time through I multiply 1 X 3 and get 3. The second thing I have on the sub table set is giving him a length of 3. This will make return three matrices. So this will give me the next three tables each time through. So the first time through I get AI0 AI1, AI2 AI3 AI4, AI5 second time or however you have configured channels.
- and what is the function of painting that the subset of table is wired to (can not find the icon of my pallet table)?
TO answer this question: Index table. Handel, it automatically becomes a 2D array.
-
Multi-terrain graphs, is there a better way?
I'm still not good at graphics in LabView, but I think I do a few programs and I can usually get a graph to show with what I want to show him only a few hours of dinking with it autour...
In any case using graphics certainly made for messy code unless there is a better way to this thread. Basically, this chart shows the four temperature sensors and is updated every minute. A check of stabilization is carried out every 15 minutes. Apparently the only way I could get the multiple locations with time that x-axis it are use an xy graph, but I have my reading on the index individually and each put in it is the own shift register and add it to the chart separately.
There must be a better way?
I think that part of your problem is that you are not aware of the option 'Concatenate entries"to build array. You don't need several bays to build the set of clusters, we made connections in graph (pink wire). Just expand the build, wire all clusters, then right-click on the picture of construction and choose 'Concatenate entries. Then, you can use a cluster to store all your berries to graph (orange wire) which will be greatly cleans your diagram.
-
I used to go to Windows Explorer in the start button to find things and see how my computer data is based. After that I switched to Vista user accounts began to appear in the folder hierarchy. There are accounts of users 'Administrator', 'Office Adminitrator s', 'my name', 'guest' and 'default '. Under each of them except comments and by default, it seems to be duplicates of many of my files. These "duplicate" files are really the same files that are accessible only through these different users? Or is my computer overloaded with multiple copies of things. And if this is the case, how can ensure me that I am always access the right, since they have the same names and I need to check what 'user' with which it is associated to know which it is really?
Hello
1. What are the files or folders that you see in the user accounts?
2. were there any changes (hardware or software) to the computer before the show?They are different ways to access the same files.Users folder would show records of other users, subject to an authorization.But the images by default and other folders that appear are the currently connected user.
Reply with answers to help you in a better way. -
To access the classes of CPP in qml.
I have set up to access the classes of PCB in qml in two ways: -.
1. create an attached object and the id of the class of CPP special and then access via the id.
2. fix the CPP on the qml class before pushing the page using the setContextProperty.
I wanted to know exactly when to use these two methods. There a difference in terms of scope and memory. Please explain.
Great Question!
Local objects:
Attached to objects, or who inherit from classes of cascades, is the simplest way to expose c ++ objects that relate to user interface elements. This is what you use if you want this object to BELONG to this context qml. It is created by the qml context when createObject is called (your qml file is loaded) and destroyed with the user interface objects. You can create many of these objects, anywhere you need. However, if you want to expose global properties, it is probably not a good approach.
The only time you would use objects attached to global stuff is if you expose a singleton class to allow qml set locations to manage signals (OrientationHandler is an example of that, without an OrientationHandler object, that you have nothing to connect).
Global objects:
Context properties can be considered global variables for a particular context, but with inheritance: context properties are passed to the contexts of the child. These objects are the PROPERTY of c ++, must be created before the creation of the object (createObject is called) and must remain valid for the lifetime of any context, they are placed in, but then destroyed is no longer necessary.
The disadvantage of context properties changing them can be expensive. If you set a context property after the createObject call (that is to say an object exists that was created from this context), then all links in javascript in this context will be re-evaluated. However, you can mitigate this issue by exposing an object that contains the value as a property, so that links to branch on change of signals well if necessary.
Inheritance is where shine context properties. There is a context root, which is in this context of default parent for new contexts. If you set a context property of the root context, it is available everywhere in any document qml. Here is an example of how do:
QmlDocument::defaultDeclarativeEngine()->rootContext()->setContextProperty("app", myApp);Note: when I speak of createObject, I'm talking about QDeclarativeContext::createObject. It is called internally by QmlDocument::createRootObject.
For more information on the Qml contexts, see http://qt-project.org/doc/qt-4.8/qdeclarativecontext.html
For more information about the inner workings of qtdeclarative, see http://qt-project.org/doc/qt-4.8/qdeclarativeengine.html and http://qt-project.org/doc/qt-4.8/qdeclarativecomponent.html
http://Qt-project.org/doc/Qt-4.8/qtbinding.html is still relevant as well
-
Is there a way to access a PC for a Windows 8 is locked by a local or a Microsoft account.
OT:bereavement access to the PC.
Good afternoon
Is there a way to access a PC for a widow locked by a local or a Microsoft account of her late husband other than pulling the hard drive?
If you are looking to access information stored online in the Microsoft account, read here on the access to the next of kin.
If you just want to access the files on the user account, have another administrator account on the PC take ownership of the folder of the user of the deceased person, change the permissions so that the administrator has access and enter the files this way.
-
My source data in the remote database schema (say C3.case). And I am trying to insert data of this CASE table in my database table (for example SIMS.case) I use the stored procedure to load the data.
I was going through the documentation and I thought that the creation of MV is not possible in this case is the source table in the remote database schema. Is this correct?
or create a link DB is the only option available to access the remote database schema table.
Thank you.
Hello
2929538 wrote:
My apologies for the bad conventions help. I meant remote schema.
the required data and the destination table, the two are in oracle, but in totally different schemas.
Yes, you said a table is in a scheme called C3, and the other is in a schema called SIMS. Are these schemas in the same database or in different databases?
If they are in the same database, then you do not have a database link. Or the other schema can reference tables in the other qualifying names correctly, for example
SELECT *.
OF C3. case_studies
...
assuming that the right privileges have been granted.
If the schemas are in different databases, a database link is the best way to access data in a database in a different database.
Without a database link, you will probably use some kind of use outside the database to write the data to a database, the file if necessary, transport and read in other databases. DataPump files of images or CSV files, as Paulzip said in answer to #1, could be used for this.
-
UNION ALL GROUP THEN SQL - is a better way
Hi gurus of SQL,.
Just try my luck to see if there is a better way to write the following SQL code. I don't know if the UNION ALL + GROUP BY is the best way. Is it better to use a FULL OUTER JOIN instead?
Thanks for your time.
See you soon
Ligon
... and here's the planSELECT x.task_id, x.task_name, max(x.actual_effort) actual_effort, max(x.date_completed) date_completed, max(x.status) status FROM ( SELECT t.task_id, t.task_name, NULL actual_effort, NULL date_completed, NULL status FROM tt_tbl_tasks t, tt_tbl_emps e, tt_tbl_references r WHERE /*t.task_status = 'Y' AND*/ t.task_start_dt <= menu_util.get_date('15/02/2010',menu_util.df) AND NVL(t.task_end_dt,SYSDATE+9999) >= menu_util.get_date('15/02/2010',menu_util.df) AND e.emp_id = 'MEARS_MP' AND t.task_id = e.task_id AND r.ref_type = 'FREQUENCY' AND t.task_frequency = r.ref_id AND is_event_ready (p_start_dt => t.task_start_dt, p_end_dt => t.task_end_dt, p_check_dt => menu_util.get_date('15/02/2010',menu_util.df), p_freq => to_number(r.ref_name)) = 'Y' UNION ALL SELECT t.task_id, t.task_name, ev.actual_effort, ev.date_completed, ev.status FROM tt_tbl_tasks t, tt_tbl_emps e, tt_tbl_events ev WHERE ev.date_completed = menu_util.get_date('15/02/2010',menu_util.df) AND t.task_id = ev.task_id AND e.emp_id = 'MEARS_MP' AND t.task_id = e.task_id )x GROUP BY x.task_id,x.task_name
Plan SELECT STATEMENT ALL_ROWSCost: 11 Bytes: 178 Cardinality: 2 18 HASH GROUP BY Cost: 11 Bytes: 178 Cardinality: 2 17 VIEW TTDB. Cost: 10 Bytes: 178 Cardinality: 2 16 UNION-ALL 8 NESTED LOOPS 6 NESTED LOOPS Cost: 5 Bytes: 88 Cardinality: 1 4 NESTED LOOPS Cost: 4 Bytes: 65 Cardinality: 1 2 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_TASKS Cost: 4 Bytes: 52 Cardinality: 1 1 INDEX RANGE SCAN INDEX TTDB.TT_TBL_TASKS_IDX_START_DT Cost: 2 Cardinality: 5 3 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_EMPS_PK Cost: 0 Bytes: 13 Cardinality: 1 5 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_REFERENCES_PK Cost: 0 Cardinality: 1 7 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_REFERENCES Cost: 1 Bytes: 23 Cardinality: 1 15 NESTED LOOPS Cost: 5 Bytes: 64 Cardinality: 1 13 NESTED LOOPS Cost: 5 Bytes: 102 Cardinality: 2 10 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_EVENTS Cost: 3 Bytes: 36 Cardinality: 2 9 INDEX RANGE SCAN INDEX TTDB.TT_TBL_EVENTS_IDX_DT_COMPLETED Cost: 1 Cardinality: 2 12 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_TASKS Cost: 1 Bytes: 33 Cardinality: 1 11 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_TASKS_PK Cost: 0 Cardinality: 1 14 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_EMPS_PK Cost: 0 Bytes: 13 Cardinality: 1Something like that I guess.
select t.Task_ID ,t.Task_Name ,p.Actual_Effort ,p.Date_Completed ,p.Status from ( select t.Task_ID as Task_ID ,t.Task_Name as Task_Name from tt_tbl_Tasks t ,tt_tbl_Emps e ,tt_tbl_References r where t.Task_Start_Dt <= Menu_Util.Get_Date('15/02/2010',Menu_Util.Df) and nvl(t.Task_End_Dt,sysdate + 9999) >= Menu_Util.Get_Date('15/02/2010',Menu_Util.Df) and e.Emp_ID = 'MEARS_MP' and t.Task_ID = e.Task_ID and r.Ref_Type = 'FREQUENCY' and t.Task_Frequency = r.Ref_ID and is_Event_Ready (p_Start_Dt => t.Task_Start_Dt, p_End_Dt => t.Task_End_Dt, p_Check_Dt => Menu_Util.Get_Date('15/02/2010',Menu_Util.Df), p_Freq => to_number(r.Ref_Name)) = 'Y' ) t left join ( select Task_ID ,Task_Name ,Actual_Effort ,Date_Completed ,Status from ( select t.Task_ID as Task_ID ,t.Task_Name as Task_Name ,ev.Actual_Effort as Actual_Effort ,ev.Date_Completed as Date_Completed ,ev.Status as Status ,row_number() over (partition by t.Task_ID, t.Task_Name order by ev.Actual_Effort desc ,ev.Date_Completed desc ,ev.Status desc) rn from tt_tbl_Tasks t ,tt_tbl_Emps e ,tt_tbl_Events ev where ev.Date_Completed = Menu_Util.Get_Date('15/02/2010', Menu_Util.Df) and t.Task_ID = ev.Task_ID and e.Emp_ID = 'MEARS_MP' and t.Task_ID = e.Task_ID ) where rn = 1 ) p on t.Task_ID = p.Task_ID and t.Task_Name = p.Task_NameThe join type and if you filter by null will determine what your require, then its up to you to experiment.
-
Looking for a better way to write this SQL
Oracle version 11R2
Version of the OS (any)
What I try to do is write a query that finds Public synonyms without a target object. I came up with this, but I think there is a better way.
object_type is null appears to be weak. It seems that the target object must be better.Select s.owner, s.synonym_name, s.table_name, s.table_owner, s.db_link, InitCap(o.object_type) object_type from sys.DBA_SYNONYMS s, sys.DBA_OBJECTS o where s.synonym_name is not null and s.table_owner = o.owner (+) and s.table_name = o.object_name (+) and s.owner = 'PUBLIC' and object_type is null;
Your comments, observations, questions welcome.I don't know exactly what 'better' means in this context (faster, easier to read, etc.), but I tend to use a NOT EXISTS
SELECT s.* FROM dba_synonyms s WHERE owner = 'PUBLIC' AND s.db_link IS NULL AND NOT EXISTS ( SELECT 1 FROM dba_objects o WHERE o.owner = s.table_owner AND o.object_name = s.table_name )I added the criteria DB_LINK to filter the public synonyms referring to objects in remote databases that obviously do not exist in the local DBA_OBJECTS.
Justin
-
Is there a better way to stop a Thread.stop () method?
First my basic problem. In one of my programs I use Solver constraints. I call the Solver constraints with a set of constraints and it turns over a card with a satisfying assignment. In most cases, this works in acceptable time (less than 1 second). But in some cases, it can take hours. I am currently in a running of the service and using Thread.stop () Thread. That look like this:
where t.getSolution (); Returns null if the Thread has been interrupted.public Map<String, Object> getConcreteModel( Collection<Constraint> constraints) { WorkingThread t=new WorkingThread(constraints); t.setName("WorkingThread"); t.start(); try { t.join(Configuration.MAX_TIME); } catch (InterruptedException e) { } if(t.isAlive()){ t.stop(); } return t.getSolution(); }
Unfortunately, it sometimes blocks the JVM with:
Anyone know a better way to do it?# # A fatal error has been detected by the Java Runtime Environment: # # EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x000000006dbeb527, pid=5788, tid=4188 # # JRE version: 6.0_18-b07 # Java VM: Java HotSpot(TM) 64-Bit Server VM (16.0-b13 mixed mode windows-amd64 ) # Problematic frame: # V [jvm.dll+0x3fb527] # # An error report file with more information is saved as: # F:\Eigene Dateien\Masterarbeit\workspace\JPF-Listener-Test\hs_err_pid5788.log # # If you would like to submit a bug report, please visit: # http://java.sun.com/webapps/bugreport/crash.jsp #
Thank you in advance.
Note 1: the Solver constraints is a third-party tool and change it is infeasible. (I tried already)
Note 2: Using Thread.stop (Throwable t) no chances as the error message.user7641489 wrote:
Other tools are worse. And stop in the library, that those who do not work.I've read that it would be possible to put the calculation in another process using the java.lang.Runtime.exec (). does anyone know how this could look like.
Note the two parameters and return values are serializeable then maybe with the object (in/out) putstream and getInputStream/getOutputStream.
And if using another process how to get the result as soon as it is ready, but still be able to kill the process when his shot the time-out.
Exec a java program that simply that the calculation doesn't work, prints the result, and then ends.
http://www.JavaWorld.com/JavaWorld/JW-12-2000/JW-1229-traps.html
Runtime.exec, or his preferred version, ProcessBuilder, you can get a java.lang.Process, who owns a destroy() method.
As for "having the result as soon as it's ready," If you mean intermediate results on the fly, you can't if the library already provides a way to do. Otherwise, if you mean just get it as soon as the external process is finished, you will have it as soon as this process writes.
Edited by: jverd April 27, 2011 11:19
-
Legends and anchored objects - there must be a better way to do
I spent a lot of time in the last six months, reconstruct PDF files in InDesign. It is part of my regular responsibilities, but I do a lot more of him for some reason any. Because I send you the text of these rebuild on documents for translation, I like that all of the text in a single story. It really helps to have the text in 'logical order', I think; When I prepare a trifold brochure, I try pretty hard to make sure that the order in which readers will read the text is reproduced in the stream of history throughout the identity document.
So I'm rebuilding a manual as a form of 3 columns on letter paper and it is full of legends. Full of em. They are not pull quotes, either; each of these has unique text. Keeping in mind that I would like the text of those legends to stay in the same position in the text once I connected all the stories and exported a RTF for translation, which is the best way to handle them? What I do is insert a frame drawn emptly as an anchored object, size and position to sit above the text which is supposed to be shouted. When my translations come back, so they are always longer than the source document, as I crawl through the text, I resize the anchored images to match the size and position of the new extension translated the text and then move them in place with the keyboard.
There must be a better way.
It is better, right? I don't actually know too. If I really want to fill these frames anchored with text, I can't screw the them in the history. I suppose I could just put on the frames of the legend and assign two RTFs for translation instead of one, but then the 'logic' of my text order is thrown out the window. So, I am asking myself "what's more important? reduction of formatting time or maintenance of the flow of the story? "If there's something that miss me let me to dodge this decision, I would love to hear about it. The only thing I can think would work like this:
(1) reproduce the text of the legend in the history with a custom sample "Invisible."
(2) create "CalloutText" parastyle with "Invisible" swatch and apply it to the caption text
(3) Insert the anchor for framework anchored immediately before the content of CalloutText
(4) send it out for translation
(5) while I'm waiting to get him back, write a script that would be (don't know if this is possible):
(a) to scroll through the main story looking for any instance of CalloutText
(b) copies an instance of contiguous to this style to the Clipboard
(c) look back in history for the first preceding the instance of CalloutText anchor
(d) fill the object anchored with the text on the Clipboard (that's where I'm really naïve)
(e) implement a new parastyle the text of the legend
(f) continue step by step through the story, looking for other instances of CalloutText
If this is really the only decent solution, I'll simply go to the Scripting forum for more help with d). Any of you can make other suggestions?
N ° there is no plugin dependencies (as long as you do not use
APID version 1.0.46 - who had a bug that caused the warnings warning). Round-
trigger by INX dirty not the text. If you return
using the most recent version of the APID (version 1.0.47 pre5 and later - not)
really yet published), plugin data should be preserved as well.
Substances
Maybe you are looking for
-
Search function does not offer addon
-
How to connect headphones to Toshiba 40L2400Ve TV
I bought TV Toshiba 40L2400Ve, which has no Audio out. It has an Audio/video connector, USB, HDMI, and ANT.I can plug in my headphones to the Audio OUT of the digital satellite receiver, but that the TV is on mute. The receiver has a SCART (TV), a co
-
Portege R200 - Display driver for Windows 7
I upgrades the operating system on my Toshiba Portege R200 to Windows 7 TThe BONE determined my monitor as generic, it does not allow more than display settings. I think I need to replace the driver. Toshiba has no update driver for this model Is the
-
Can my iMac 21.5-inch, late 2009 with Core 2 Duo deal with 16 GB of RAM?
I think to upgrade the RAM on my Mac to 16 GB or more. My Mac will handle it well? In accordance with article Apple here: install memory in an iMac - Apple's Support, For models of iMac (late 2009), you can use 2 GB or 4 GB RAM SO-DIMM memory DDR3 SD
-
HP Officejet Pro 8600 Plus the Scanner Software
Hello I'm a big fan of HP products. My last several printers, scanners and computers were all HP. I recently bought the HP Officejet Pro 8600 Plus to replace an older machine with similar features (ADF, duplex, etc.). The previous machine was also