Better way to write this sql?
Hi guru, I was able to get what I want, but I find there must be a better way/more efficient way to write this sql?
Database: Oracle 11g
This is the create for the test database statement:
create table sample_test (prog_id number (9) DEFAULT 0 NOT NULL, chan_rights CHAR (2) DEFAULT ' ' NOT NULL)
This is the insert statement:
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A4')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A5')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A6')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (555633, 'A7')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'A3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B1')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B2')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B3')
INSERT INTO sample_test (prog_id, chan_rights) VALUES (495641, 'B4')
Here's what I did to get the data:
Select distinct a.prog_id, rt_cnt, CASE
WHEN a.rt_cnt = 7
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A1')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = "A2")
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = "A3")
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A4')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A5')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A6')
and there are (select 'Y' b sample_test where a.prog_id = b.prog_id and b.chan_rights = 'A7')
THEN "A_ONLY".
else 'SINGLE '.
end CHAN_GROUP
from (select prog_id, count (chan_rights) rt_cnt
of sample_test
Prog_id group) a, b sample_test
where a.prog_id = b.prog_id
That appears as follows:
| PROG_ID | RT_CNT | CHAN_GROUP |
|---|---|---|
| 495641 | 7 | UNIQUE |
| 555633 | 7 | A_ONLY |
As seen:
1 / I count how many rights is available, and in this case, each program gets a "7"
Set 2 / from these data, for each programme, I try to make sure it belongs to the company chan_rights right, for example, "A_ONLY". Therefore, as shown, Prog_ID 495641 does not contain "A_ONLY" channels listed in the case statement and there is unique. "A_ONLY" should only contain A1 to A7 inclusive and nothing else.
Can I create a function that returns the value "Chan_Group", but is there a better way to rewrite the statement 'BOX' like a LOOP or something? I have millions of records to go through and someone told me that using "is" slows down the database so just thought that I could ask ahead...
Please indicate if there is a better and more efficient method to get what I need?
Thank you
John
I would do something like
select prog_id,
rt_cnt,
(case when rt_cnt = 7 and num_a = 7
then 'A_ONLY'
else 'UNIQUE'
end) chan_group
from (select prog_id,
count(chan_rights) rt_cnt,
sum( case when chan_rights in ('A1','A2','A3','A4','A5','A6','A7')
then 1
else 0
end ) num_a
from sample_test
group by prog_id)
View of inline, I count the number of values chan_rights, as well as the number that are in your list of A1 - A7. In the outer query, I implement the logic that checks that the two charges are 7.
Here is an example of sqlfiddle this http://www.sqlfiddle.com/#! 4/95438/2
Justin
Tags: Database
Similar Questions
-
Looking for a better way to write this SQL
Oracle version 11R2
Version of the OS (any)
What I try to do is write a query that finds Public synonyms without a target object. I came up with this, but I think there is a better way.
object_type is null appears to be weak. It seems that the target object must be better.Select s.owner, s.synonym_name, s.table_name, s.table_owner, s.db_link, InitCap(o.object_type) object_type from sys.DBA_SYNONYMS s, sys.DBA_OBJECTS o where s.synonym_name is not null and s.table_owner = o.owner (+) and s.table_name = o.object_name (+) and s.owner = 'PUBLIC' and object_type is null;
Your comments, observations, questions welcome.I don't know exactly what 'better' means in this context (faster, easier to read, etc.), but I tend to use a NOT EXISTS
SELECT s.* FROM dba_synonyms s WHERE owner = 'PUBLIC' AND s.db_link IS NULL AND NOT EXISTS ( SELECT 1 FROM dba_objects o WHERE o.owner = s.table_owner AND o.object_name = s.table_name )I added the criteria DB_LINK to filter the public synonyms referring to objects in remote databases that obviously do not exist in the local DBA_OBJECTS.
Justin
-
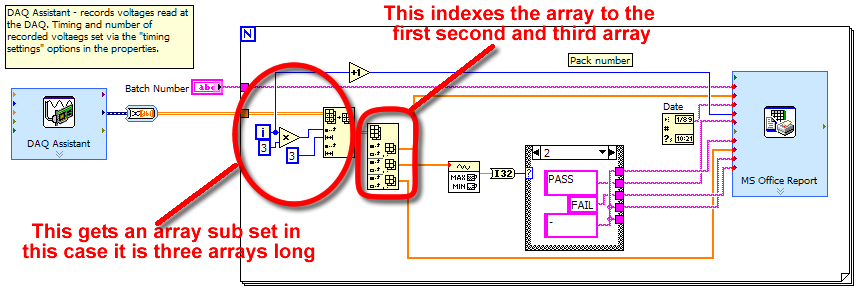
There must be a better way to do this
There must be a better way to do this!
25 separate reports - 1 voltage recorded by chanel every minute for 21 hours (end - times will have to be changed)
Anyone has ideas/directions
CC
The DAQ Assistant reads the tensions based on the timings specified, which means that if I set the number of samples finish say 20 and the frequency of samples to 1, then data acquisition will take 20 seconds to save 20 data points (one second) per channel. Then the DAQ pump data to the loop that creates reports (N number of reports).
TO answer this question: the DAQ Assistant will do exactly what you suggest here.
Two questions:
-the loop will be able to separate the different channels ie first report contains data AI1, AI2 and AI3, then the second contains data AI4, AI5 AI6 etc.. ? What is the purpose of the table screws?
TO answer this question: If you look inside the front loop, you see I have the sub table value function. I have set the index to the increment and then multiply 3 X. The first time in the loop take 0 and multiply by 3 and I get zero. second time through I multiply 1 X 3 and get 3. The second thing I have on the sub table set is giving him a length of 3. This will make return three matrices. So this will give me the next three tables each time through. So the first time through I get AI0 AI1, AI2 AI3 AI4, AI5 second time or however you have configured channels.
- and what is the function of painting that the subset of table is wired to (can not find the icon of my pallet table)?
TO answer this question: Index table. Handel, it automatically becomes a 2D array.
-
Hello
I have a problem and I realized a simplified version of it:
The id of the requirement to join these two tables based on:create table deals (id_prsn number, id_deal number, fragment number); create table deal_values (id_prsn number, id_deal number, value_ number, date_ date); insert into deals values(1,1,50); insert into deals values(2,2,40); insert into deals values(1,3,50); insert into deals values(2,4,80); insert into deals values(1,5,20); insert into deals values(2,6,80); insert into deal_values values(1,1,10 ,sysdate - 3); insert into deal_values values(2,2,208, sysdate - 3); insert into deal_values values(2,4,984, sysdate - 3); insert into deal_values values(1,null,134,sysdate - 3); insert into deal_values values(1,1,13, sysdate - 2); insert into deal_values values(2,2,118, sysdate - 2); insert into deal_values values(2,4,776, sysdate - 1); insert into deal_values values(1,null,205,sysdate - 1); insert into deal_values values(2,null,-5,sysdate - 1);
1.) ID_PRSN and ID_DEAL
2.) max DATE_ grouped per person and deal
(3.) in the case that ID_DEAL is defined in the AGREEMENTS, but not defined in the DEAL_VALUES table, I have to join this records to DEAL_VALUES based on the person where id_Deal is null.
Number 3 gives me headache. I realized the following query:
It returns the correct result of he,select *from ( select a.id_prsn, a.id_deal, a.fragment, b.value_, b.date_, max(b.date_) over (partition by b.id_prsn, b.id_deal) max_date from deals a inner join deal_values b on a.id_deal = b.id_deal or b.id_deal is null and not exists (select 1 from deal_values where id_prsn = a.id_prsn and id_deal = a.id_deal) and a.id_prsn = b.id_prsn ) where date_ = max_Date;
ID_PRSN ID_DEAL FRAGMENT VALUE_ DATE_ MAX_DATE
1 1 50 13 16.10.2012 09:59:48 16.10.2012 09:59:48
1 3 50 205 17.10.2012 09:59:48 17.10.2012 09:59:48 OK
1 5 20 205 17.10.2012 09:59:48 17.10.2012 09:59:48 OK
2 2 40 118 16.10.2012 09:59:48 16.10.2012 09:59:48
2 4 80 776 17.10.2012 09:59:48 17.10.2012 09:59:48
2 6 80-5 17.10.2012 09:59:48 17.10.2012 09:59:48 OK
but the join clause:
in fact the query much slower.on a.id_deal = b.id_deal or b.id_deal is null and not exists (select 1 from deal_values where id_prsn = a.id_prsn and id_deal = a.id_deal) and a.id_prsn = b.id_prsn
I was wondering is there a different way to write this join and manage the logic.
Thanks in advanceHere's a different approach:
select * from ( select a.id_prsn, a.id_deal, a.fragment, B.value_, b.date_, ROW_NUMBER() over( partition by a.ID_PRSN, a.ID_DEAL order by B.ID_DEAL nulls last, B.DATE_ desc ) RN from DEALS a join DEAL_VALUES B on a.ID_PRSN = B.ID_PRSN and a.ID_DEAL = NVL(B.ID_DEAL, a.ID_DEAL) ) where rn = 1 order by 1, 2;"nulls last" is the default sort order; I just put that for clarity.
Published by: stew Ashton on October 18, 2012 12:58
-
Can you help me? Is there a simpler way to write this short code?
Hi, I'm quite new to coding and EDGE and think there must be a simpler way to write this? :
sym.getSymbol("USA_animation").play ();
sym.getSymbol("World_map").play ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("UK").fadeOut ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("Piechart").fadeOut ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("people").fadeOut ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("PeopleText").fadeOut ();
sym.getComposition () .getStage ().getSymbol("UK_animation").$("UKText").fadeOut ();
sym.getComposition () .getStage ().getSymbol("AUS_animation").$("AUSTRALIA").fadeOut ();
sym.getComposition () .getStage ().getSymbol("USA_animation").$("USA").show ();
sym.getComposition () .getStage ().getSymbol("USA_animation").$("USAText").show ();
Can you help me?
Obivious to increase efficiency is
var USA_animation = sym.getSymbol ("USA_animation")
USA_animation. Play();
sym.getSymbol("World_map").play ();
USA_animation.$("UK").fadeout ();
USA_animation.$("PieChart").fadeout ();
USA_animation.$("people"). fadeOut();
USA_animation.$("PeopleText").fadeout ();
USA_animation.$("UKText").fadeout ();
USA_animation.$("AUSTRALI_A").fadeout ();
USA_animation.$("USA"). Show();
USA_animation.$("USAText"). Show();
If you perform a single operation on all the symbols of the "USA_animation" child, you can also reduce somethinng as
sym.getSymbol("World_map").play ();
var USA_animation = sym.getSymbol ("USA_animation")
USA_animation. Play();
var childSymbols = USA_animation.getChildSymbols (); f
for (var i = 0; i)
childSymbols [i] .fadeOut ();
I don't know if these are the best ways, but these are in a way that I could think of.
Let us know if offer you a lot shorted way to write this
-
Is there a better way to make this pop up?
I have a VI that has more than 900 void screw which has been developing since the Labview V5. It has a control loop and a loop of data. The vehicle currently has half a dozen or more Windows vi it appears for different reasons. Most collect all of the data passed to them but don't have to return data. I called the sub, it opens and the data is passed but he shares time with the main window, so I can not change anything in the main window as the Sub keeps seizing control.
I came up with this solution attached below, but it seems that there must be a better way? I don't know that I just lack. I need to be able to start in a field of the program running on a while loop and sends the data to the it in an another while loop which collects data while giving full control to the main VI.
Thanks for any help.
-
What is the most effective way to run this sql
I have a sql like this:
As you can see, the sql calculate a field value to another view (View1 view2 View3, view4).select ((select q_avg24 from view1 where years=2009 and qtr=1) - (select q_avg24 from view1 where years=2010 and qtr=1)) as sub_s1_avg24, ((select q_avg24 from view2 where years=2009 and qtr=1) - (select q_avg24 from view2 where years=2010 and qtr=1)) as sub_s2_avg24, ((select q_avg24 from view3 where years=2009 and qtr=1) - (select q_avg24 from view3 where years=2010 and qtr=1)) as sub_s3_avg24, ((select q_avg24 from view4 where years=2009 and qtr=1) - (select q_avg24 from view4 where years=2010 and qtr=1)) as sub_s4_avg24 from dual
It returns the difference between the 2 years.
In this sql, you can see she will solicit the views of the 2 x 4 = 8 times to get result table.
Each query sql (select statement) return a result within 5 seconds, then... for total = 8 X 5 = 40secs...
40 dry is not so big problem... but in fact, I have at least 5 games queries (select statements) with other parameters are not an entry for the calculation of this query...
There are a lot of your time in SQL that results from: (8X5secs) x 5 = 200secs...
I would like to know is there a solution better if we face such problems?
Thank you!!!You can use as... not tested...
But if you provide additional information on the data, I think we can think best solutionselect sum(decode(id,1,decode(yers,2009,av,0),0))-sum(decode(id,1,decode(yers,2010,av,0),0)) av1, sum(decode(id,2,decode(yers,2009,av,0),0))-sum(decode(id,2,decode(yers,2010,av,0),0)) av2, sum(decode(id,3,decode(yers,2009,av,0),0))-sum(decode(id,3,decode(yers,2010,av,0),0)) av3, sum(decode(id,4,decode(yers,2009,av,0),0))-sum(decode(id,4,decode(yers,2010,av,0),0)) av4 from( select 1 id,q_avg24 av,years from view1 where years in (2009,2010) and qtr = 1 union all select 2 id,q_avg24,years from view2 where years in (2009,2010) and qtr = 1 union all select 3 id,q_avg24,years from view3 where years in (2009,2010) and qtr = 1 union all select 4 id,q_avg24,years from view4 where years in (2009,2010) and qtr = 1)Published by: JAC on March 30, 2012 13:31
-
There must be a better way to do this (frustration of RAM Preview)
I loaded one 01:20 second Full HD clip in sequels. I need to edit the video based on some sounds in the video and see if I match them correctly by the image previewed with the sound.
The problem is that I'm frustrated due to After effects does not not like first. First who thought it was a good idea is not to integrate sound in sequels? Secondly, I have an i7 processor sandy bridge, and 16 GB of ram, but he always takes time to render the preview ram (with still no effect on it).
Ram preview is my only option for sound, but the problem is every time I hit the ram preview it starts the video all the way from the beginning. It's frustrating because I want to start at a specific time. Imagine having a video more long where editing must take place at the end.
Professional projects of people out there doing a lot more complicated, you guys how to work around this problem?
Why can't after that effects do some basic things like first as make fast with the sound? Is it because of the Mercury engine and 64-bit?
It is one of the best products on the market, there must be a better way of doing things?
No need to preview RAM just to hear the sound, use the comma on the numeric keypad key to play an audio preview only.
If you want to mark certain audio events, twirl down the properties for the audio until you see the waveform and then use it to synchronize audio and animations.
And if you want RAM Preview from your current position, simply press the 'B' button to set your start of work area to the playhead, and then the RAM previews will begin from that point.
Use ctrl - drag to scrub audio & video. Use ctrl-alt-drag to scrub just audio.
AE has all the audio features of first (and), he just behaves in a different way.
-
Most clean way to write this expression GREP
Hello
I have a GREP expression which is now:
InDesign
InDesign CS
InDesign CS2 (or 3,4,5)
InDesign CS2 (or 3,4,5)
.. .and this is what it looks like... I don't know there is a way to write, but I can't ahven managed to run... any thoughts there ;-)

Thank you!
Babs
Hi Babs! Chips a glance, shall we.
First of all, I fill a frame with placeholder text; then I add "InDesign" and all its variants up randomly in the text, with spaces around and there followed by punctuation.
Then I create a character style "Hi-lite" adapted; a light blue background, so I can see exactly what is being matched. Then, I go to my definition of standard paragraph and create a GREP style with Preview on. Then it's just a case of the entry of codes and look at the preview.
Hang on while I do it. (You can use a ready earlier.)
Here you are:
\bInDesign (CS [2345]?)? (~]s)?\b
fits all blue below. Note it does not match "InDesign CS6" (and more recent); If you do not want to be prepared for the future, you would use
\bInDesign (CS\d?)? (~]s)?\b
Look at how the combination of parentheses and question mark together define strings: it's all or nothing with those. The \b's are just to force - define whole words, no funny stuff admitted directly before or after the speech - punctuation is fine.

-
All currents are RED. All others are Sparse. 'Has' members accounts. This works very well and runs quickly, but just wants to make sure that it is recommended, etc. I tried to make ElseIf instead of opening of blocks every time, but it stopped working after all that 20th. I am also uncertain on what block missing is correct.
SET AGGMISSG
UPDATECALC OFF SET;
SET CREATENONMISSINGBLK
SET CREATEBLOCKONEQ
Difficulty ({RTP_Scenario}, {RTP_Year}, 'Work', 'No_Location')Difficulty ("TPD-90000", "PRJ-90001-LTVDS', 'No_Category')
("A-65000"
If (@ISMBR ("EC-OFFICESUPP") AND @ISMBR('Jan': 'Feb') AND @ISMBR ("TwoPlusTen") AND @ISMBR (& CurrFcstYr))
"A-65000"="A-65000"->"Pre real Alloc"->"Final"->"Total departments '->' locations '->' Total Categories '->' Total Total of charges Code."
Endif)("A-65100"
If (@ISMBR ("EC-SHIPPING') AND @ISMBR ('"Jan ":" Feb"') AND @ISMBR ("TwoPlusTen") AND @ISMBR (& CurrFcstYr))
"A-65100'='A-65100"->"Pre real Alloc"->"Final"->"Total departments '->' locations '->' Total Categories '->' Total Total of loads Code";
Endif)etc...
etc...
Two things you could try
1. put all Calc in a block unique member instead of each of them having its own
("A-65000"
If (@ISMBR ("EC-OFFICESUPP") AND @ISMBR('Jan': 'Feb') AND @ISMBR ("TwoPlusTen") AND @ISMBR (& CurrFcstYr))
'A-65000'='A-65000"->" Pre Alloc real '-> 'Final'-> 'Total departments'-> 'Total locations'-> 'Total categories'-> 'the Total expenses Code ";
Endif
If (@ISMBR ("EC-SHIPPING') AND @ISMBR ('"Jan ":" Feb"') AND @ISMBR ("TwoPlusTen") AND @ISMBR (& CurrFcstYr))
'A-65100'='A-65100"->" Pre Alloc real '-> 'Final'-> 'Total departments'-> 'Total locations'-> 'Total categories'-> 'the Total expenses Code ";
Endifetc...
)
the way in which each block is visited once
2. If you want to be more weird to get rid of the if statements (if the statements are slow)
'A-65000'-> ='A-65000"->" Pre Alloc' real' Final '-> 'Total departments '->' locations '->' categories Total Total'-> "The Total expenses Code" / @ISMBR("EC-OFFICESUPP") / @ISMBR("Jan":"Feb") / @ISMBR (& CurrFcstYr);
@ismbr returns a 1 if the Member and 0 if it is not. whatever this is divided by 0 is #missing
-
Better way to write the simple query?
I'm trying to get the date of 'busy' max 'mansion '.
It is an example, I imagined, since I can't post our actual data. The following query works, but is their path easier.
Reason, I take the ID's for the second join because I know that the ID max = max.CREATE TABLE TEST_TABLE ( LOAN_NUMBER VARCHAR2(15 Byte), UN_ID NUMBER, CHANGE_DATE DATE, PROP_TYPE VARCHAR2(25 Byte), OCCSTAT VARCHAR2(25 Byte) ); COMMIT; INSERT INTO TEST_TABLE VALUES (123456, 1,'01-JAN-09','Tent','Occupied'); INSERT INTO TEST_TABLE VALUES (123456, 2,'01-FEB-09','Shack','Occupied'); INSERT INTO TEST_TABLE VALUES (123456, 3,'01-JUN-08','Single Family','Occupied'); INSERT INTO TEST_TABLE VALUES (123456, 4,'01-OCT-08','Single Family Plus','Occupied'); INSERT INTO TEST_TABLE VALUES (123456, 5,'01-DEC-08','Mansion','Occupied'); INSERT INTO TEST_TABLE VALUES (123456, 6,'05-JAN-09','Mansion','Unoccupied'); COMMIT;
easier way without the second join?select i2.UN_ID, i2.CHANGE_DATE, i2.PROP_TYPE, i2.OCCSTAT from ( select distinct(LOAN_NUMBER) AS "LOAN_ID", max(UN_ID) AS "ID_MAX" from( select LOAN_NUMBER, UN_ID from TEST_TABLE where OCCSTAT = 'Occupied' group by LOAN_NUMBER, UN_ID ) group by LOAN_NUMBER )i left join TEST_TABLE i2 on i.ID_MAX = i2.UN_ID
Thanks in advance.
RTry this query, it should be equivalent to your:
select UN_ID, CHANGE_DATE, PROP_TYPE, OCCSTAT from ( select LOAN_NUMBER, UN_ID, CHANGE_DATE, PROP_TYPE, OCCSTAT, rank() over(partition by LOAN_NUMBER order by un_id desc) rn from test_table where OCCSTAT = 'Occupied' ) where rn=1Max
-
Please help me write this SQL query...
Thanks in advanceHi everyone, Please help me in this query. A patient can multiple types of Adresses (types P,M,D).If they have all the 3 types i need to select type: p and if they have (M and D) i need to select type M,and if they have only type D i have to select that. For each address i need to validate whether that particular address is valid or not (by start date and end date and valid flag) Patient table ============= Patient_id First_name last_name 1 sanjay kumar 2 ajay singh 3 Mike John Adress table ============ address_id patient_id adresss city type startdate enddate valid_flg 1 1 6222 dsadsa P 01/01/2007 01/01/2010 2 1 63333 dsad M 01/02/2006 01/01/2007 N 3 1 64564 fdf M 01/01/2008 07/01/2009 4 1 654757 fsdfsa D 01/02/2008 09/10/2009 5 2 fsdfsd fsdfsd M 01/03/2007 09/10/2009 6 2 jhkjk dsad D 01/01/2007 10/10/2010 7 3 asfd sfds D 01/02/2008 10/10/2009 output ===== 1 sanjay kumar 6222 dsadsa P 01/01/2007 01/01/2010 2 ajay singh fsdfsd fsdfsd M 01/03/2007 09/10/2009 3 mike john asfd sfds D 01/02/2008 10/10/2009
PhaniHello, Fabienne,.
This race for you (twisted code of Sarma):
SELECT patient_id, first_name, last_name, address, city, type, startdate, enddate FROM ( SELECT a.patient_id patient_id, first_name, last_name, address, city, type, startdate, enddate, ROW_NUMBER() OVER (PARTITION BY p.patient_id ORDER BY CASE type WHEN 'P' THEN 1 WHEN 'M' THEN 2 WHEN 'D' THEN 3 END) rn FROM patient p JOIN address a ON (p.patient_id = a.patient_id ) WHERE NVL(valid_flg, 'X') != 'N' AND SYSDATE BETWEEN startdate AND NVL(enddate, SYSDATE) ) WHERE rn = 1;Edit, currently in the trial:
With Patient AS ( SELECT 1 Patient_id , 'sanjay' First_name, 'kumar' last_name FROM DUAL UNION ALL SELECT 2, 'ajay', 'singh' FROM DUAL UNION ALL SELECT 3, 'Mike', 'John' FROM DUAL), Address AS ( SELECT 1 address_id, 1 patient_id, '6222' address, 'dsadsa' city, 'P' type, to_date('01/01/2007', 'DD/MM/YYYY') startdate, to_date('01/01/2010', 'DD/MM/YYYY') enddate, NULL valid_flg FROM DUAL UNION ALL SELECT 2,1,'63333','dsad','M', to_date('01/02/2006', 'DD/MM/YYYY'), to_date('01/01/2007', 'DD/MM/YYYY'), ' N' FROM DUAL UNION ALL SELECT 3,1,'64564','fdf','M', to_date('01/01/2008', 'DD/MM/YYYY'), to_date('07/01/2009', 'DD/MM/YYYY'), NULL FROM DUAL UNION ALL SELECT 4,1,'654757','fsdfsa','D', to_date('01/02/2008', 'DD/MM/YYYY'), to_date('09/10/2009', 'DD/MM/YYYY'), NULL FROM DUAL UNION ALL SELECT 5,2,'fsdfsd ','fsdfsd','M', to_date('01/03/2007', 'DD/MM/YYYY'), to_date('09/10/2009', 'DD/MM/YYYY'), NULL FROM DUAL UNION ALL SELECT 6,2,' jhkjk','dsad','D', to_date('01/01/2007', 'DD/MM/YYYY'), to_date('10/10/2010', 'DD/MM/YYYY'), NULL FROM DUAL UNION ALL SELECT 7,3,'asfd',' sfds',' D', to_date('01/02/2008', 'DD/MM/YYYY'), to_date('10/10/2009', 'DD/MM/YYYY'), NULL FROM DUAL) -- end test data SELECT patient_id, first_name, last_name, address, city, type, startdate, enddate FROM ( SELECT a.patient_id patient_id, first_name, last_name, address, city, type, startdate, enddate, ROW_NUMBER() OVER (PARTITION BY p.patient_id ORDER BY CASE type WHEN 'P' THEN 1 WHEN 'M' THEN 2 WHEN 'D' THEN 3 END) rn FROM patient p JOIN address a ON (p.patient_id = a.patient_id ) WHERE NVL(valid_flg, 'X') != 'N' AND SYSDATE BETWEEN startdate AND NVL(enddate, SYSDATE) ) WHERE rn = 1; PATIENT_ID FIRST_ LAST_ ADDRESS CITY TY STARTDATE ENDDATE ---------- ------ ----- ------- ------ -- --------- --------- 1 sanjay kumar 6222 dsadsa P 01-JAN-07 01-JAN-10 2 ajay singh fsdfsd fsdfsd M 01-MAR-07 09-OCT-09 3 Mike John asfd sfds D 01-FEB-08 10-OCT-09 -
UNION ALL GROUP THEN SQL - is a better way
Hi gurus of SQL,.
Just try my luck to see if there is a better way to write the following SQL code. I don't know if the UNION ALL + GROUP BY is the best way. Is it better to use a FULL OUTER JOIN instead?
Thanks for your time.
See you soon
Ligon
... and here's the planSELECT x.task_id, x.task_name, max(x.actual_effort) actual_effort, max(x.date_completed) date_completed, max(x.status) status FROM ( SELECT t.task_id, t.task_name, NULL actual_effort, NULL date_completed, NULL status FROM tt_tbl_tasks t, tt_tbl_emps e, tt_tbl_references r WHERE /*t.task_status = 'Y' AND*/ t.task_start_dt <= menu_util.get_date('15/02/2010',menu_util.df) AND NVL(t.task_end_dt,SYSDATE+9999) >= menu_util.get_date('15/02/2010',menu_util.df) AND e.emp_id = 'MEARS_MP' AND t.task_id = e.task_id AND r.ref_type = 'FREQUENCY' AND t.task_frequency = r.ref_id AND is_event_ready (p_start_dt => t.task_start_dt, p_end_dt => t.task_end_dt, p_check_dt => menu_util.get_date('15/02/2010',menu_util.df), p_freq => to_number(r.ref_name)) = 'Y' UNION ALL SELECT t.task_id, t.task_name, ev.actual_effort, ev.date_completed, ev.status FROM tt_tbl_tasks t, tt_tbl_emps e, tt_tbl_events ev WHERE ev.date_completed = menu_util.get_date('15/02/2010',menu_util.df) AND t.task_id = ev.task_id AND e.emp_id = 'MEARS_MP' AND t.task_id = e.task_id )x GROUP BY x.task_id,x.task_name
Plan SELECT STATEMENT ALL_ROWSCost: 11 Bytes: 178 Cardinality: 2 18 HASH GROUP BY Cost: 11 Bytes: 178 Cardinality: 2 17 VIEW TTDB. Cost: 10 Bytes: 178 Cardinality: 2 16 UNION-ALL 8 NESTED LOOPS 6 NESTED LOOPS Cost: 5 Bytes: 88 Cardinality: 1 4 NESTED LOOPS Cost: 4 Bytes: 65 Cardinality: 1 2 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_TASKS Cost: 4 Bytes: 52 Cardinality: 1 1 INDEX RANGE SCAN INDEX TTDB.TT_TBL_TASKS_IDX_START_DT Cost: 2 Cardinality: 5 3 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_EMPS_PK Cost: 0 Bytes: 13 Cardinality: 1 5 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_REFERENCES_PK Cost: 0 Cardinality: 1 7 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_REFERENCES Cost: 1 Bytes: 23 Cardinality: 1 15 NESTED LOOPS Cost: 5 Bytes: 64 Cardinality: 1 13 NESTED LOOPS Cost: 5 Bytes: 102 Cardinality: 2 10 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_EVENTS Cost: 3 Bytes: 36 Cardinality: 2 9 INDEX RANGE SCAN INDEX TTDB.TT_TBL_EVENTS_IDX_DT_COMPLETED Cost: 1 Cardinality: 2 12 TABLE ACCESS BY INDEX ROWID TABLE TTDB.TT_TBL_TASKS Cost: 1 Bytes: 33 Cardinality: 1 11 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_TASKS_PK Cost: 0 Cardinality: 1 14 INDEX UNIQUE SCAN INDEX (UNIQUE) TTDB.TT_TBL_EMPS_PK Cost: 0 Bytes: 13 Cardinality: 1Something like that I guess.
select t.Task_ID ,t.Task_Name ,p.Actual_Effort ,p.Date_Completed ,p.Status from ( select t.Task_ID as Task_ID ,t.Task_Name as Task_Name from tt_tbl_Tasks t ,tt_tbl_Emps e ,tt_tbl_References r where t.Task_Start_Dt <= Menu_Util.Get_Date('15/02/2010',Menu_Util.Df) and nvl(t.Task_End_Dt,sysdate + 9999) >= Menu_Util.Get_Date('15/02/2010',Menu_Util.Df) and e.Emp_ID = 'MEARS_MP' and t.Task_ID = e.Task_ID and r.Ref_Type = 'FREQUENCY' and t.Task_Frequency = r.Ref_ID and is_Event_Ready (p_Start_Dt => t.Task_Start_Dt, p_End_Dt => t.Task_End_Dt, p_Check_Dt => Menu_Util.Get_Date('15/02/2010',Menu_Util.Df), p_Freq => to_number(r.Ref_Name)) = 'Y' ) t left join ( select Task_ID ,Task_Name ,Actual_Effort ,Date_Completed ,Status from ( select t.Task_ID as Task_ID ,t.Task_Name as Task_Name ,ev.Actual_Effort as Actual_Effort ,ev.Date_Completed as Date_Completed ,ev.Status as Status ,row_number() over (partition by t.Task_ID, t.Task_Name order by ev.Actual_Effort desc ,ev.Date_Completed desc ,ev.Status desc) rn from tt_tbl_Tasks t ,tt_tbl_Emps e ,tt_tbl_Events ev where ev.Date_Completed = Menu_Util.Get_Date('15/02/2010', Menu_Util.Df) and t.Task_ID = ev.Task_ID and e.Emp_ID = 'MEARS_MP' and t.Task_ID = e.Task_ID ) where rn = 1 ) p on t.Task_ID = p.Task_ID and t.Task_Name = p.Task_NameThe join type and if you filter by null will determine what your require, then its up to you to experiment.
-
Is there a better way to make the selection on this slider?
Is there a better way to make the selection on this slider?
I need to retrieve the test scores max (tesc_code SO1, S02, S03 etc... etc...)
I get the results presented here, but I wonder if it's a better way to do this.
The results should be back in the same cursor... e
CURSOR c_sortest_SAT_scores(p_pidm IN saturn.sortest.sortest_pidm%TYPE, p_term in saradap.saradap_term_code_entry%TYPE) IS SELECT s01.sortest_pidm pidm_s01, s01.sortest_tesc_code tesc_code_s01, s01.sortest_test_score score_s01, s02.sortest_pidm pidm_s02, s02.sortest_tesc_code tesc_code_s02, s02.sortest_test_score score_s02, s07.sortest_pidm pidm_s07, s07.sortest_tesc_code tesc_code_s07, s07.sortest_test_score score_s07, s08.sortest_pidm pidm_s08, s08.sortest_tesc_code tesc_code_s08, s08.sortest_test_score score_s08, s09.sortest_pidm pidm_s09, s09.sortest_tesc_code tesc_code_s09, s09.sortest_test_score score_s09 FROM saturn.sortest s01, saturn.sortest s02, saturn.sortest s07, saturn.sortest s08, saturn.sortest s09 WHERE s01.sortest_tesc_code IN ('S01') AND s01.sortest_pidm = p_pidm AND s01.sortest_term_code_entry = p_term AND s01.sortest_test_score = (SELECT MAX (s01a.sortest_test_score) FROM saturn.sortest s01a WHERE S01.sortest_pidm = s01a.sortest_pidm AND S01A.sortest_tesc_code IN ('S01')) AND s02.sortest_tesc_code IN ('S02') AND s02.sortest_pidm = p_pidm AND s02.sortest_term_code_entry = p_term AND s02.sortest_test_score = (SELECT MAX (S02A.sortest_test_score) FROM saturn.sortest s02a WHERE S02.sortest_pidm = s02a.sortest_pidm AND S02A.sortest_tesc_code IN ('S02')) AND s07.sortest_tesc_code IN ('S07') AND s07.sortest_pidm = p_pidm AND s07.sortest_term_code_entry = p_term AND s07.sortest_test_score = (SELECT MAX (S07A.sortest_test_score) FROM saturn.sortest S07A WHERE S07.sortest_pidm = S07A.sortest_pidm AND S07A.sortest_tesc_code IN ('S07')) AND S08.sortest_tesc_code IN ('S08') AND S08.sortest_pidm = p_pidm AND S08.sortest_term_code_entry = p_term AND S08.sortest_test_score = (SELECT MAX (S08A.sortest_test_score) FROM saturn.sortest S08A WHERE S08.sortest_pidm = S08A.sortest_pidm AND S08A.sortest_tesc_code IN ('S08')) AND S09.sortest_tesc_code IN ('S09') AND S09.sortest_pidm = p_pidm AND S09.sortest_term_code_entry = p_term AND S09.sortest_test_score = (SELECT MAX (S09A.sortest_test_score) FROM saturn.sortest S09A WHERE S09.sortest_pidm = S09A.sortest_pidm AND S09A.sortest_tesc_code IN ('S09'));Hello
The problem is that you to act as a Cartesian product with all the tables (you will get: S01 * S02 * S08 * S09 lines!) Is it really what you want?
I don't think...Wharton, you can do (with no Cartesian product) is:
CURSOR c_sortest_SAT_scores(p_pidm IN saturn.sortest.sortest_pidm%TYPE, p_term in saradap.saradap_term_code_entry%TYPE) IS SELECT sortest_pidm pidm, sortest_tesc_code tesc_code, sortest_test_score score FROM sortest WHERE (sortest_tesc_code, sortest_test_score) IN ( SELECT sortest_tesc_code, MAX (sortest_test_score) FROM sortest WHERE sortest_tesc_code IN ('S01', 'S02', 'S07', 'S08', 'S09') AND sortest_pidm = :p_pidm AND sortest_term_code_entry = :p_term GROUP BY sortest_tesc_code) AND sortest_pidm = :p_pidm AND sortest_term_code_entry = :p_termHowever you absolutely need a Cartesian product, you can do:
WITH allrows AS (SELECT sortest_pidm pidm, sortest_tesc_code tesc_code, sortest_test_score score FROM sortest WHERE (sortest_tesc_code, sortest_test_score) IN ( SELECT sortest_tesc_code, MAX (sortest_test_score) FROM sortest WHERE sortest_tesc_code IN ('S01', 'S02', 'S07', 'S08', 'S09') AND sortest_pidm = :p_pidm AND sortest_term_code_entry = :p_term GROUP BY sortest_tesc_code) AND sortest_pidm = :p_pidm AND sortest_term_code_entry = :p_term) SELECT s01.pidm pidm_s01, s01.tesc_code tesc_code_s01, s01.score score_s01, s02.pidm pidm_s02, s02.tesc_code tesc_code_s02, s02.score score_s02, s07.pidm pidm_s07, s07.tesc_code tesc_code_s07, s07.score score_s07, s08.pidm pidm_s08, s08.tesc_code tesc_code_s08, s08.score score_s08, s09.pidm pidm_s09, s09.tesc_code tesc_code_s09, s09.score score_s09 FROM allrows s01, allrows s02, allrows s07, allrows s08, allrows s09 WHERE s01.tesc_code = 'S01' AND s02.tesc_code = 'S02' AND s07.tesc_code = 'S07' AND s08.tesc_code = 'S08' AND s09.tesc_code = 'S09'The lines will be stored in memory to a temporary table before that product happen (should be faster)...
-
What is the best way to get this layout of the chapter?
I have a document which is now a large flow of pages.
However, there are "chapters, in this 'book'. A 'chapter' actually starts on the right page. But I want the left page to participate in the design of the spread of the beginning 'chapter '. This means that left before the start page real "chapter" is reserved in control of layout and all "chapter" before that would end on a left page, needs a right-hand page empty inserted, after which the left page of the early-'chapter' spread follows.
Now, I can do the pages on the left of the start "chapter" start a section and to correct even a page number. That it is positioned on the left side. But when I add pages from the previous section, this means I have to change the page numbers of the beginning of all the sections that follow hand.
Are there not a better way to do this? Somehow I don't have to worry about the numbering of the pages myself while still getting the page before the "chapter" included in the section of this "chapter"?
(I write "chapter" because these aren't chpaters Id in an Id book, but a few sections in a single document Id).
If the previous "chapter ends with a page of pairs (left hand), you add two pages, if it ends on the right add you a..
Another way to do this automatically is to set an Option to keep on the paragraph style that you use for the first paragraph on the page at beginning of chapter, then it will start the section on the next odd-numbered page.


Maybe you are looking for
-
How stop a download if I don't like it?
It began after the last update.Desktop PC, win xp, firefox 32.0
-
Impossible to make calls to landlines at all
I have not used the feature of Skype to call landlines for a while, but recently received a reminder that some credit, I've got will expire shortly, and so I thought to make a call to someone. Either way, I was abroad at the time, and that makes it u
-
First infinite sum of HP error
(Published no calculator specific Forum)
-
RE: Problems with Windows Mail
RE: Windows Mail. 1. I have three messages of the Inbox which cannot be deleted; 2 all incoming messages since these three were received (May 27) are automatically deleted or missing the next day! Anyone know what is the cause and how to fix it?
-
photo by e-mail cancelled by printer accessory
I was testing my new B210a. I sent a few attachments to the printer, and it was no problem to print. But when I tried to send an attachment image the print job was canceled because the image was not enough high quality. Because I was not wanting to u