Calendar of slow FPGA
We have a compact device of cRIO-9072 Rio FPGA.
1 analogue out, analogue 2 in 1 race of SSR. My program works well, but I can't get the cycle time for update reads to move faster than about 1 second / cycle.
I perform a host VI and the target FPGA VI. The clock frequency is 40 M.
I know this isn't much information but I can't find genericly how to control the speed of this card FPGA update. I would like to be updated about 10 to 100 times faster.
Any ideas?
Thank you
tophatjim
Most likely, the CRDD is slowing down the speed of the loop on the FPGA. I assume you are using the module 9485.
You must place the I/O nodes for your different modules in different loops so that your HAVE and AO can run faster. Updates of the CRDD will run more slowly in their own loop.
Tags: NI Hardware
Similar Questions
-
Hi, I am fairly new to real-time and FPGA programming. I read a lot about speed problems, such as some modules slows the rest unless you use their own lines, and using fifo to move data more quickly.
But for now, I'm just a simple reading and a simple LED control. If you look at my code that I have attached, you will see the readings in a loop and the LED control in its own loop. I have the LED just turn every 1/2 second. (The counties of ticks are set to mSec, 8 bit) But when the code is running on my FPGA, the LED flashes only every other 12.5 seconds. It's basically 25 times slower than expected.
I also have a counter tick sending its value to my code in real time, which also has its own meter of ticks, and both are to get connected. When I look at the counter of the two side by side tick data, it shows time to counter tick in real-time is perfect, but the fpga tick counter time is way slower. It ends up being 25 times slower.
Why the FPGA reports that it runs so slow? It's going slowly? Or is the meter tick does not properly? I understand how it works? Although there are more slow IO modules causing the fpga to run more slowly, the counters of the tick must still report the right to the exact time?
What is possibly sense as to why I get this behavior?
Thank you
JES-
Hey Jes,
In view of these figures, I think what have seen you, it is correct. Assuming a 40 MHz clock, the calculation is:
500 Mticks / 40 Mticks/s = 12.5 sec.
The 32-bit parameter does not affect the behavior of timing, he controls just what tick counter height can go without flipping.
Jim
-
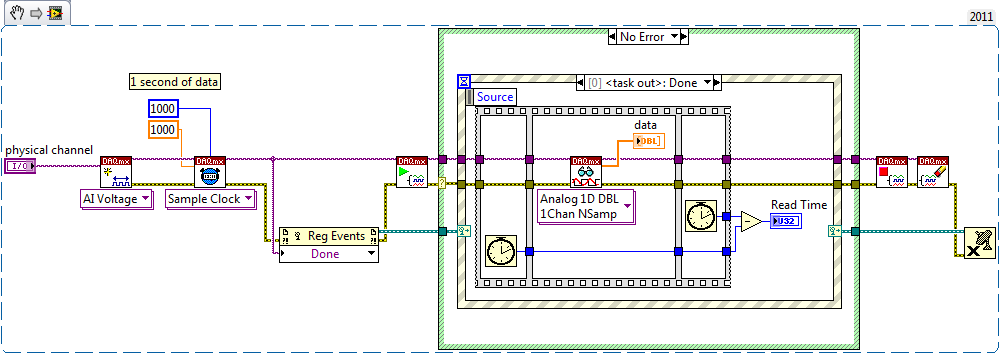
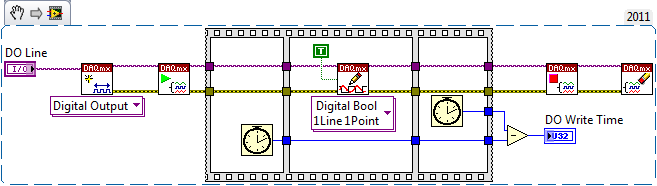
USB6363 DAQmx (reading and writing) calendar seems slower than other similar USB DAQ devices
Hey people,
I have currently a service waiting number with OR the subject, but I thought I'd post up incase anyone has ever dealt with a similar question pertaining to USB DAQ hardware.
Try to understand why there is a difference of synchronization between the 6363 USB and some of the other less expensive USB devices like the 6525 or 6501.

It's a watered the actual code that my team has noticed this difference in the simplified version. The actual code is a reading analog daqmx (it's triggered hw, so we begin the task of analog playback, trigger, wait the time we acquire to and then run reading daqmx. who takes 6 ms to read a single 50 values of the buffer).
Thank you
-Pat
Hi Pat,
Try benchmarking of HAVE it read that way (with the wait timed by the software, it seems to me that the task is probably not yet made to the time you want to read - I guess that the question is relative between the event of the task performed and all the data is available in the DAQmx buffer, I don't have a series of X USB to see) :
Try benchmarking your writing clocked by the software in this way (there no reason to include the check/reserve/validation/start sequence in your writing of reference when the task can easily be launched during initialization of your program):
On my PCIe X Series as the two cases take< 1="">
Best regards
-
BlackBerry smartphones! SLOW CALENDAR ON 8530 AFTER UPDATE TO 5.0.0.734!
Hi all
I was looking through this forum, and I have not met anyone mention anything to this topic, so I hope I do just something wrong...
I've recently updated OS from my Berry to 5.0.0.734, and since I did it, my calendar is simply unusable. When I click on the icon to enter the calendar, it crashes just for about 10 to 20 seconds (depending on which is open) and won't let me do anything, even go out... Total crash... and then once he enter the calendar, it crashes again before it allows me to scroll to enter an appointment. In total, he is probably going to take me 20 to 30 seconds to get to the point where I can start typing the actual appointment details.

What have I done? Is there a cure? What I do back? I never had to push back a Berry before, it's that something simple? Really sucks!
PIN please me or just add me to BB Messenger - PIN: XXXXXXXX
Help, please!
Thanks for your time...
EDIT: Personal information removed - information such as personnel of pines, IMEIs, e-mails & phone numbers are prohibited for safety reasons.
~ Tom
Curve 8530
Problem solved...
I was in the previous version of the BlackBerry operating system (OS: 5.0.0.508) and all my pains have disappeared. I just couldn' is to live without a responsive phone...
For some reason, the recent software update failed miserably, or is miserable to start. I recommend to keep 5.0.0.508 and won't 5.0.0.734.
In any case, I was able to restore my recurrances endless in my calendar and it's as soon as I click on the calendar on the homescreen application icon.
Bifocals, I really appreciate the time you took, but two days was long enough for me without a decent phone... now I am a proud and happy owner of BlackBerry Curve again.
I hope that we can discuss again on the road... just not on the calendars being slow...
 hehehe.
hehehe.Sincerely,
~ Tom
-
FPGA square wave generator diverts loop calendar
Description of the problem:
I have a simple while loop with a structure of matter inside. In one case, I have the
Generator FPGA Sinewave sending the data of output to AO0, otherwise, I have
the square wave FPGA sending output to AO0 generator. The sine and square
waves are set to run at 10 kHzI also have a shift register that changes the State of DIO0 each loop through.
In this way, I can look DIO0 on my scope and say how fast the loop runs.When I choose the sine wave generator, the output on AO0 is what I expect. That
is I have a sinusoidal signal at 10 kHz and the loop speed is approximately 1 US. Everything is good.Then I move to the square wave. I get a signal square 10 kHz, which is good. But
My loop speed was slowed down to 50 US (it follows the square wave
exactly) is: once the loop defines the FS square wave and the
the next time through the loop, it defines the square wave to-FS.My problem is that when I generate a square wave, I expect the speed of loop
to stay fast he does it for the sine wave. You can see what my loop speed
slows to 50 (a square wave of 10 kHz) and then all my calculations that must
go in parallel with the square wave will also be slowed.Please help me with my understanding of the use of the square wave FPGA sub - VI
Thank you
RichSoftware of NEITHER: LabVIEW FPGA Module version 2013 SP1
OR hardware: USB-7855R R Series deviceIf you dig into the express VI, it will loop an SSTL until there is a change in value. The sine wave has no need to do so because the value changes constantly.
If you can, I recommend doing your loop a SSTL and configure the express screw accordingly. This will work as long as the rest of your code in the loop can be run in a single clock cycle.
-
I have the following code in the FPGA (didn't integrate the png because it is too big. You will have to click on the attachment below) and I noticed a bottleneck in the FIFO, when both running on the FPGA and jusing simulating values in the Dev Enviroment. Here are the values of control
Sampling frequency - 1 ms
Btwn samples - 1000 ms delay
NB of static samples - 10
I know that my conversion fxp is lousy right now and I will correct this, but I know that's not the issue. The question is in my FIFO because when I disable it everything works correctly. See the following questions which I will describe here is what I notice when I do not disable the part of the diagram:
Running in the Dev Environment:
Code works very well... for a while. If I look at the indicator loop counter it goes fast (about 1ms as programmed to do) of 0 to 9, then breaks for 1000 ms wait and then goes again. After about 20 all iterations of the loop, the for loop suddenly slows down way. I can see this because if I look at the counter of the loop, it starts to increment once every 5 seconds. I thought, well maybe the FIFO DMA reaches its limit, but is it not fixed? Old data should not only be overwritten? Is not delay because the delay indicator will never true so I have no idea whats going on.
Running on FPGA:
Never the time to fast as iteration above. From the outset, will slow down. I noticed this, because my side of RT, I have a dedicated loop to only read items in FIFO (see below). I put it to the top to read 340 items both (34 samples of table x 10 element). It takes forever for the FIFO reach 340 items (it should take only 10 ms). Because I have 1000 ms pause between entering the data there is no reason that my buffer should be overflowing.
Suggestions? Sorry, I cannot post my RT code, but may be able to view the FPGA code if it is really necessary.

Found the problem. The RTD I use by default in mode 'accuracy '. These RTD also do not have simultaneous sampling (NI 9217). In fine mode, the conversion time is set to 200 Ms. which explains why when I bench marked it took 800 ms to run one to the loop iteration (200 ms/Channel * 4 channels).
To fix this, go to your project, click with the right button on any given RTD, choose Properties, change the conversion time of 2.5 ms.
-
Does anyone know how to get rid of the calendar in the window Live on XP? I do not use it, and whenever I check my e-mail, it checks the calendar, slows things down to the top.
Thank you!Debnfurkidsoriginal title: get rid of the calendar in live mailHi Debnfurkids,
I recommend you post your query in Live Mail Forums for assistance on this issue.
-
Thunderbird guard sync Google calendar all day and each time it slows down.
Every hour so Thunderbird sync Google Calendar, there are nearly 1000 events, so it takes a while. Meanwhile, Thunderbird get stuck. I have to wait for it to be ready before I can continue.
Why this happens suddenly (since yesterday)? If it can't be fixed, I have to delete the sync with my Google Calendar.
Great now you please mark this resolved.
-
When you use iCloud on my iMac I get the message "network unavailable or slow. The application takes more time to load than expected. "This has been the case for several hours, but other applications I use (Mail, Contacts, Notes, reminders), all seem to work well. The
I have the same message when I try to load the reminders in iCloud. All other applications work correctly. This issue has been ongoing for about a month now.
Have this problem on my work computer running Windows 7 SP1 Pro and Macbook Air late 2009 w / OS X 10.11
-
Why is the FPGA Compiler server so slow?
FPGA Cloud compiler is faster because NO servers are performing, right?
Well, my Windows 7 PC is powerful, but no luck there!Total CPU utilization is never more than 25% and the total memory (including other applications) usage is less than 16%.
Why, the compile Server uses all available resources? has been restricted?
How can I leverage more power from my PC?If servers OR compile faster code, there must be a plausible explanation / reason?
Please indicate, how to make the compile server running faster in place?I don't know what machines compilation cloud service works, but I do not.
It seems that the compilation is much faster on a Linux machine on a Windows machine (I think I've heard up to 30% faster). The Linux FPGA compile server is available for LV2012. Set up a Linux machine with a clock high enough CPU and RAM speed and you will get on the fastest possible compilation with current tools.
-
Calendar of FPGA away from promises
My enforcement focus on the measurement of time that separates digital TTL. The material used is to cRIO9068 and module 9402 at high speed. Given that the chain of hardware can run up to 16 MHz and loop simple FPGA can reach 80 MHz clock, I aspected to have for this application precision autour 5 tick (ticks 1 = 12.5ns = 1/80 MHz, 5 ticks is 62.5ns is 1/16 MHz).
Well I can test power squares request to 9402 via a function (high quality) generator. Then the accuracy on the events of time on only mounted (or only fall) TTL is pretty good (10 ticks at 1 kHz) when I use to deal with the two rise and fall events the accuracy became about 60 ticks.
Who is guilty here?
However from what I see these little paper specifications are not answer
rozzilla wrote:
TWL?
I think GerdW meant "Timed While loop", although I have not seen this abbreviation before (and I use LabVIEW FPGA for a long time).
He really need to see your code, and the project file to see how you have configured your top-level clock and derived clocks, in order to provide assistance.
I would discourage you to use the features of comparison (for example, over/under of) to compare Boolean values. Use standard Boolean logic (AND, OR, etc.) instead.
-
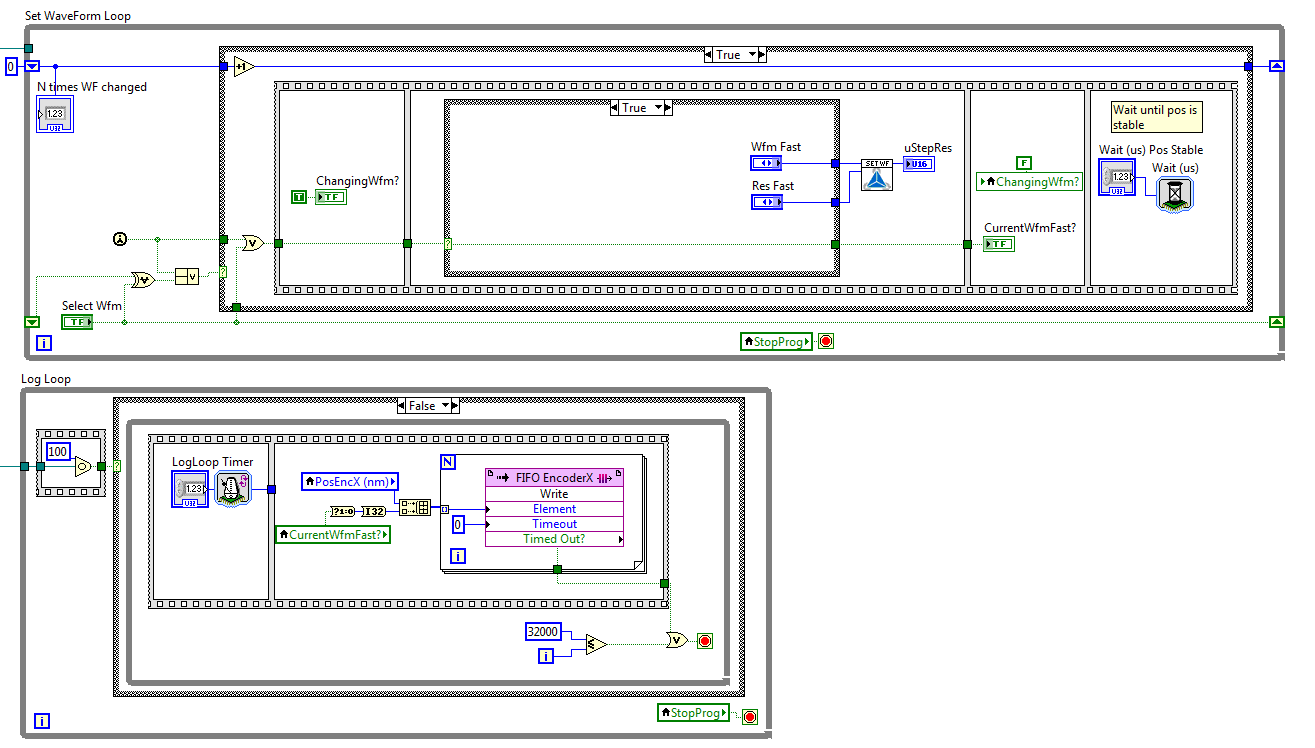
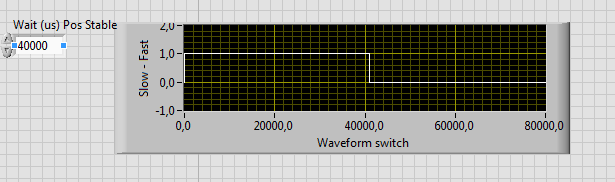
LV fpga - wait express vi slows down the other loops?
Hi all
I have a question about the use of the vi wait Express in Labview FPGA. I use 2 loops, one that changes data, the other records it these data by sending it to a FIFO. In the first loop, I change the value of a variable named "CurrentWfmFast?" from true to false. After that, I use the vi wait Express to wait a few microseconds, so the program does not change this value to true immediately. In the second loop, I connect the data a FIFO to send to the host.
If I now draw the variable in the host.vi, it seems that the value of the "CurrentWfmFast"? has changed AFTER the vi wait Express instead of before (see attachment). If I change the wait ' (we) Pos Stable ' to 60000, for example, the value of "CurrentWfmFast?" changes after 60000 US... How is that possible? What is the vi wait another Express while loops influence?
Thank you in advance,
Best regards
DriesI finally thought to it myself. Before that the value of "CurrentWfmFast?" went from true to false, the waiting already executed only once. That's why the value has not changed immediately. Instead of 1 wait, there are 2, that was my mistake.
I know it has been difficult (if not impossible) for you to understand that without the whole project, but thanks for watching it. If I need more help, I'll post the VI or the entire project.
Best regards
Dries
-
Sub - VI implicit calendar within a LabVIEW FPGA SCTL
I have a question about the time of a Subvi in one SCTL when LabVIEW is translated into VHDL. Did the translate Flatten all code within the SCTL effectively remove the Subvi borders, or a Subvi act like a framework unique sequence around this code.
For example, if I have a block of code inside a Subvi, which is not connected to any entrance or exit of the Subvi, is it still wait for all entries of Subvi settle for run? I know that the answer is Yes normally, but I was wondering if it was different inside a SCTL. If the answer is always Yes, remove implicit synchronization in the construction specifications FPGA effectively remove this application for each block of code that is not directly connected?
I ask because sometimes I wonder if the code inside a Subvi, which is part of the critical path of a loop may be simplifying the BD, but can be the critical path timing wrong because some functions/gates do not run as soon as they can if it is inside a Subvi.
The SCTL flattens all code inside, by removing all intermediate registers.
So Yes use Subvi to cleanup code / duplicate inside SCTLs.
-
Using the C-series SCTL DIO module with slower than the top level [FPGA] clock
Hey all,.
I'm running online research on a problem that I have a lot of success.
I have a chassis with integrated FPGA, top-level 9030 clock 40 MHz. I have a NOR-9401 DIO C Series module plugged and the value that will be managed by the FPGA target. I need to count some linear encoders to exactly 10 MHz, no more, no less. They are periods and gives a result of such kind that if I oversample or underestimate, I get garbage.
If I create a SCTL and assign a source of synchronization derived from 10 MHz, I get an error code generation who:
"Node read e/s for DIO3 FPGA is used in a clock domain that it does not support. Areas of clock supported include: the clock of higher and clocks that have a rate that is a multiple of 40 MHz, for example 40 MHz, 80 MHz, 120 MHz and so on. »
I tried several ways to work around this problem; First I tried just using a while loop with a loop set to 4 is ticking timer, but it then takes 9 clock cycles to perform the count for a reason any (although this code may compile in the SCTL without any problem). I then tried to use the SCTL with a constant of 'true' AS a hack for a 'timed sequence' framework-related, and that certainly has not worked.
Are there any strategies or techniques, or settings somewhere to work around this limitation on the AID I need to taste exactly 10 MHz? I'd like to do this quickly in the software and get this rolling as soon as POSSIBLE.
An image of the relevant section of the code is attached, I'm happy to provide you more things on request.
Thank you very much!
Maia Bageant
Thanks for the reply! The problem ended up being a hardware problem based on how coders were connected. Now that I've fixed it, they're perfectly happy are oversampled.
I guess my question is always legitimate to other applications, but not necessary for encoders a.
-
Video is not slow when it is added to the calendar of different cadence
I have trouble understanding what is happening here. I have a video shot in 59,94 images per second, and add it to a sequence, which is set to 29.97 FPS. He rereads normally makes sense, if the first is down to 1/2 frames, but indicator target image says that is not drop frames. The clip also runs the same length. The cadence to interpret for the clip in the project window says 59,94 frames per second, so if it is added to a sequence, which is set to 29.97 FPS and there is NOT a drop frames, shouldn't it be slowed down?
PP works as expected. Yes, it's to show you all the other images, but the indicator dropped frame one shows that if he does not play back to the proper sequence of cadence.
If you want to slow down, actually change the settings Interpret something less that's the native frame rate.
Maybe you are looking for
-
Whenever I open a Web page, it seems to be oversized. What should I do?
I have to scroll both up and down AND left and right for all to see. I can zoom out, which helps, but I would like to address, so I need to do each time.
-
How to remove "plastic umbrella" for good?
I downloaded the umbrella plastic by accident and thought that I removed it twice He's back! How can I remove this for always?
-
Problems with the retina display resolution
Hello I have a macbook pro (2015) with a retina display 15 "that I can't seem to adjust to the correct resolution. The native resolution, as I understand it, is supposed to be 2880 x 1800. I can't see my resolution when I put its "default value to di
-
Complex regular expressions without multiple passes
Does anyone know of a tool that can handle more complex regular expressions without chaining of multiple copies of the VI regular expressions? For example, if I have a XML string as Power supply error has occurred. Sorensen SGA166/188 and I am intere
-
I've got Labview 8.6 and Vision installed, but I seem to lack grab and snap IMAQ. they hide? -confused