Creation of period moving average trend line 50
HI, im trying to set my curve in LabView and trying to create a 50 period moving average treadline as in excel.
is it possible for me to do in LabView?
I tried general polynomial Fit VI and a few other screw in unions, but failed to get anything close to the way I want
any ideas? anyone?
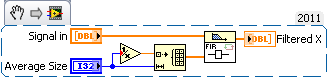
Charlie, there is a better VI called means"PtByPt". Look in the palette "Signal Processing > point-to-point > Prob and Stat > means. Add an advantage: this VI gives data valid for the first 50 points, although the average is not "development" or "stabilized" during early iterations. (Also, don't forget that primitives "delete table ' and 'Building the table' call memory, meaning Manager memory copies of great paintings and fast loop rates will result in a bottleneck of the CPU.) Using circular buffers is one way to alleviate this limitation.)
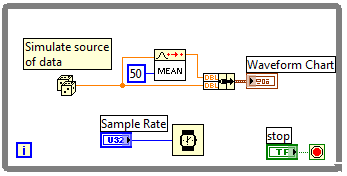
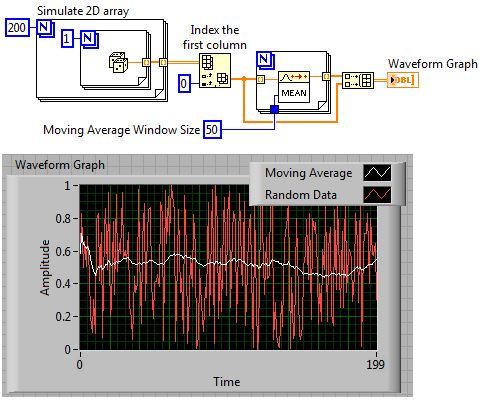
64864050, try to adapt this code to meet your needs:
Tags: NI Software
Similar Questions
-
[8i] how to calculate a moving average?
I am trying to calculate a moving average over a specific period of time, but I can't quite figure out how to do this. For this particular problem, I am also stuck on a 8i database.
Some examples of data for the problem:
It is a sample of the actual data, which includes the lines around 50K, and is the result of a query, not a table. In addition, the actual data also have a reference number attached to each order, and the end result will be be partitioned by party id number and the region. This sample represents basically something, you might see a unique part number. In addition, these records at the time spacing is not predictable. You might have a single year that has 20 ordered, and another year (or years) that does not.CREATE TABLE my_data ( order_no CHAR(10) , seq_nbr CHAR(4) , area_id CHAR(4) , start_date DATE , unit_time NUMBER(7,2) ); INSERT INTO my_data VALUES ('0000567890','0010','A001',TO_DATE('05/01/2000','mm/dd/yyyy'),0.34); INSERT INTO my_data VALUES ('0000567890','0020','A001',TO_DATE('05/02/2000','mm/dd/yyyy'),0.78); INSERT INTO my_data VALUES ('0000567890','0030','A002',TO_DATE('05/03/2000','mm/dd/yyyy'),0.91); INSERT INTO my_data VALUES ('0000567890','0040','A003',TO_DATE('05/03/2000','mm/dd/yyyy'),0.27); INSERT INTO my_data VALUES ('0000123456','0010','A001',TO_DATE('04/01/2001','mm/dd/yyyy'),0.39); INSERT INTO my_data VALUES ('0000123456','0020','A001',TO_DATE('04/02/2001','mm/dd/yyyy'),0.98); INSERT INTO my_data VALUES ('0000123456','0030','A002',TO_DATE('04/03/2001','mm/dd/yyyy'),0.77); INSERT INTO my_data VALUES ('0000123456','0040','A003',TO_DATE('04/03/2001','mm/dd/yyyy'),0.28); INSERT INTO my_data VALUES ('0000123123','0010','A001',TO_DATE('12/01/2001','mm/dd/yyyy'),0.31); INSERT INTO my_data VALUES ('0000123123','0020','A001',TO_DATE('12/02/2001','mm/dd/yyyy'),0.86); INSERT INTO my_data VALUES ('0000123123','0030','A002',TO_DATE('12/03/2001','mm/dd/yyyy'),0.82); INSERT INTO my_data VALUES ('0000123123','0040','A003',TO_DATE('12/03/2001','mm/dd/yyyy'),0.23); INSERT INTO my_data VALUES ('0000111111','0010','A001',TO_DATE('06/01/2002','mm/dd/yyyy'),0.29); INSERT INTO my_data VALUES ('0000111111','0020','A001',TO_DATE('06/02/2002','mm/dd/yyyy'),0.84); INSERT INTO my_data VALUES ('0000111111','0030','A002',TO_DATE('06/03/2002','mm/dd/yyyy'),0.78); INSERT INTO my_data VALUES ('0000111111','0040','A003',TO_DATE('06/03/2002','mm/dd/yyyy'),0.26); INSERT INTO my_data VALUES ('0000654321','0010','A001',TO_DATE('05/01/2003','mm/dd/yyyy'),0.28); INSERT INTO my_data VALUES ('0000654321','0020','A001',TO_DATE('05/02/2003','mm/dd/yyyy'),0.88); INSERT INTO my_data VALUES ('0000654321','0030','A002',TO_DATE('05/03/2003','mm/dd/yyyy'),0.75); INSERT INTO my_data VALUES ('0000654321','0040','A003',TO_DATE('05/03/2003','mm/dd/yyyy'),0.25);
Here is where I am now in the problem. For example, suppose I want to calculate a moving average over 2 years (average for the 2 years preceding the date of the current row). For my actual data, I probably want to be able to change the period of time (at different times in several queries) on which the moving average is calculated.
I thought that using the analytical function AVERAGE with a window clause might be the way to go, but I don't know exactly how to use the window clause. I can even be completely wrong interpret what is its use, but if all goes well, it should still show what I'm after.
As you can see from the above query, I want to calculate the sum of the unit_time for each order/area_id combo, then roll the way to this total time. (I'm the average total time that a product passes through each area_id per order).SELECT area_id , AVG(tot_area_unit_hrs) OVER ( PARTITION BY area_id ORDER BY min_start ROWS BETWEEN --2 years prior to min_start of current row AND CURRENT ROW ) , --something to indicate the time period the average is over AS time_period FROM ( SELECT order_no , area_id , MIN(start_date) AS min_start , SUM(unit_time) AS tot_area_unit_hrs FROM my_data GROUP BY order_no , area_id ) ORDER BY area_id , time_period
I want to see results like something along those lines... I really don't like how the time period is identified, as long as I can pay by him in chronological order, and he tells me what period of time it covers. The way I show with period_start and period_end in the results of the sample below is just a way that I thought to do this.
Any suggestions?area_id period_start period_end avg_unit_time ---------------------------------------------------- A001 4/30/1998 5/1/2000 1.120 A001 3/31/1999 4/1/2001 1.245 A001 11/30/1999 12/1/2001 1.220 A001 5/31/2000 6/1/2002 1.223 A001 4/30/2001 5/1/2003 1.153 A002 5/2/1998 5/3/2000 0.910 A002 4/2/1999 4/3/2001 0.840 A002 12/2/1999 12/3/2001 0.833 A002 6/2/2000 6/3/2002 0.790 A002 5/2/2001 5/3/2003 0.783 A003 5/2/1998 5/3/2000 0.270 A003 4/2/1999 4/3/2001 0.275 A003 12/2/1999 12/3/2001 0.260 A003 6/2/2000 6/3/2002 0.257 A003 5/2/2001 5/3/2003 0.247Hello
You're close enough. You want a window based on the BEACH, no LINES.
LINES BETWEEN... means that you know exactly how many lines will be in the window, and you don't care what range of values that represents.
RANGE BETWEEN... means that you know the exact scope of the ORDER BY value to include in the window, which could mean any number of lines.When you say "RANGE BETWEEN x BEFORE...". "where the words ORDER BY id of a DATE, x is considered as the number of days. (Which is consistent with the arithmetic DATE Oracle).
Try this:
SELECT area_id , min_start - 730 AS period_start , min_start AS period_end , AVG(tot_area_unit_hrs) OVER ( PARTITION BY area_id ORDER BY min_start RANGE BETWEEN 365 * 2 PRECEDING AND CURRENT ROW ) AS avg_unit_time FROM ( SELECT order_no , area_id , MIN(start_date) AS min_start , SUM(unit_time) AS tot_area_unit_hrs FROM my_data GROUP BY order_no , area_id ) ORDER BY area_id , period_end ;Output of your sample data:
AREA PERIOD_STA PERIOD_END AVG_UNIT_TIME ---- ---------- ---------- ------------- A001 5/2/1998 5/1/2000 1.120 A001 4/2/1999 4/1/2001 1.245 A001 12/2/1999 12/1/2001 1.220 A001 6/1/2000 6/1/2002 1.223 A001 5/1/2001 5/1/2003 1.153 A002 5/4/1998 5/3/2000 .910 A002 4/4/1999 4/3/2001 .840 A002 12/4/1999 12/3/2001 .833 A002 6/3/2000 6/3/2002 .790 A002 5/3/2001 5/3/2003 .783 A003 5/4/1998 5/3/2000 .270 A003 4/4/1999 4/3/2001 .275 A003 12/4/1999 12/3/2001 .260 A003 6/3/2000 6/3/2002 .257 A003 5/3/2001 5/3/2003 .247The period_starts are not quite what you posted, but, if I understand you correctly, you don't mind that.
There should be no problem of partitioning an additional column. -
Hi all
I am trying to achieve a moving average Calc very simple. Even if my calc is valid, I get an error message after I run my script to calc:
' scalar double argument expected in function [@__SHIFT].
Here's my calc script:
"Measure_1" = (@SUMRANGE ("Measure_2", @CURRMBR ("Period")) +) ".
@SUMRANGE ("Measure_2", @NEXT (@LIST (@CURRMBR ("Period"), "Jan":"Nov"))) / 2;)))
Here is the obligation to calculate the Measure_2:
Jan Feb Mar Apr
Measure_1 10 20 40 100
Measure_2 15 30 70
Under calc worked, but then I really don't want to repeat the same logic 12 times:
Measure_2-> "Jan" = (Measure_1-> "Jan" + Measure_1-> "February") / 2;
Any ideas?
Thank you!
Mehmetyou would be better to use the currmbrrange function. Here is a generic example of the tech reference
@SUMRANGE ('Measure1', @CURRMBRRANGE(Year, LEV, 0,, 0))Note there is also an avgrange instead of the sumrange function in order to get the average over time. There is an additional setting in jump missing and zero members.
-
HFR 9.3.1
I have a month (defined as the time) dimension and a years. Basically:
Measures
-Net margin
-Revenue
-Cost
Month
-Jan
-Etc.
-Dec
Years
-EF07
-AFA 08
-EXERCISE 09
I am trying to build a State that displays the selected month and moving average 12 months, but have a problem of displacement of the year at the correct place.
BASICE installation would be
A--FY08---FY08---FY08---FY08---FY09---FY09---FY09---FY09---FY09---FY09---currentYear(or user selection) column header
B---Sep---Oct---Nov---Dec---Jan---Feb---Mar---Apr---May---Jun---CurrentMonth(or user selction) column header
Tier 1-recipes
Cost of line 2
I can get 12 months of lag, np, but how to make the second dimension (year) to change when it is Dec?
Jcreate 2 columns (col A and column B)
Col A:
Year: POV sometime this year
Time: Jan of POV for timeCol B:
Year: Member Relative [POV current year - 1]
Time: Member [current time + 1 POV] Relative to decExample:
If you select 2009 and Mar
ColA: Year: 2009 / time: January to March
ColB: Year: 2008 / duration: April to DecemberI think that's what you want.
Kind regards
Rahul -
'several trend lines' numbers 3.0
Years, I had an Excel spreadsheet that graphed the weekly course of actions as well as moving averages of 5 weeks, 15 weeks and 40 weeks.
When I moved the worksheet to a number, I can get one of them, that I indicate in the Format Inspector (series-trendlines). Interestingly, the bar under the graph shows three moving averages, but all with the same name. All three titles are changing everything I put in the Inspector to Format. But they all retain the colors I used in the Excel worksheet.
Mel Magree wrote:
Years, I had an Excel spreadsheet that graphed the weekly course of actions as well as moving averages of 5 weeks, 15 weeks and 40 weeks.
When I moved the worksheet to a number, I can get one of them, that I indicate in the Format Inspector (series-trendlines). Interestingly, the bar under the graph shows three moving averages, but all with the same name.
You can recreate the data graphic that you have transferred to the numbers. You don't mention what type of graph you have, but here's a quick 2D scatterplot I made, choosing to view the moving average.

Note When you do then a 2D scatterplot, you do NOT want to be defined as a column header in the left column.
SG
-
I'm doing something similar to an average commute, but I want it on average to each 10 data instead of keep moving points. I don't know exactly what it is, part of the reason why I'm a bit confused on what to do. I've seen several functions of moving averages, but still, this isn't what is needed. I have a very large data collection and wanted to get to a whole easier to manage data. The data comes in the form of one and zeroes. No indication in this regard would be appreciated.
Hello
You can see thispost on the forum that addresses similar requirement you have.
Concerning
-
FPGA - windowed moving average, variance, standard deviation, kurtosis and asymmetry
Hello!
I'm processing in FPGA and I want to calculate the MOVING WINDOW average, variance, standard deviation, kurtosis, asymmetry online for the last N (N is the size of windows) elements. The frequency is about 100 kHz and N about 10000 (100 ms of signal).
I found something like EMA (moving average exponential)...
Have someone solved something like that? Any ideas how to fix?
That looks like a problem. What type of window you need? The moving average exponential isn't an option? There are online algorithms described in Wikipedia, but they can suffer from problems of numerical accuracy when it is implemented in a fixed point (depending on the nature of the data). They would be interesting watch in, however.
Other than that, here are some options that I can think of:
- More large FPGA
- Be part of the treatment on the RT controller - have - you looked into that?
- Return to your needs and push some of the numbers. Do you really need 100 ms in all cases, etc.?
- Depending on the nature of the data, simple compression techniques may be an option
- An precision analysis to determine the data type minimum, that you really need. For example, getting to 25 bits, would have a huge impact on your cost of multiplier.
- Consider the mathematics of floating (using Xilinx IP cores) point to online methods. Your flow is relatively low, so you could share it resources between all channels. Manage States of different channels is complicated but is doable.
The BRAM will be used for FIFO buffers, but is also available for general use to implement the fifo and memories. Some IP use BRAM under the hood, keep an eye on the compilation summaries to monitor how much still you have.
-
I have a file (excel) which has 11,12,13,14,15,16,17,18,19, 20, 21, 22, 23, 24, 25, or no matter what random numbers in no particular order.
I have a bearing everytime calculation that reads the file. for example.
Add the first 5 digits in the file and divide by 5, then place the first number and move one to the right and get the number following 5 and then divide it by 5, etc.
(11 + 12 + 13 + 14 + 15) / 5 = 13, the first time, he reads then file the first number and move one to the right (12 + 13 + 14 + 15 + 16) / 5 = 14 then (13 + 14 + 15 + 16 + 17) / 5 = 15.
Can anyone help please?
There are many examples of functioning / moving averages on this forum. But I don't remember them ever called rolling average. So you might want to search for running or moving average.
A recent thread started by comes me to mind.
The simplest example I saw while loop with shift registers, especially if you do not need to change the size of the sample running.
-
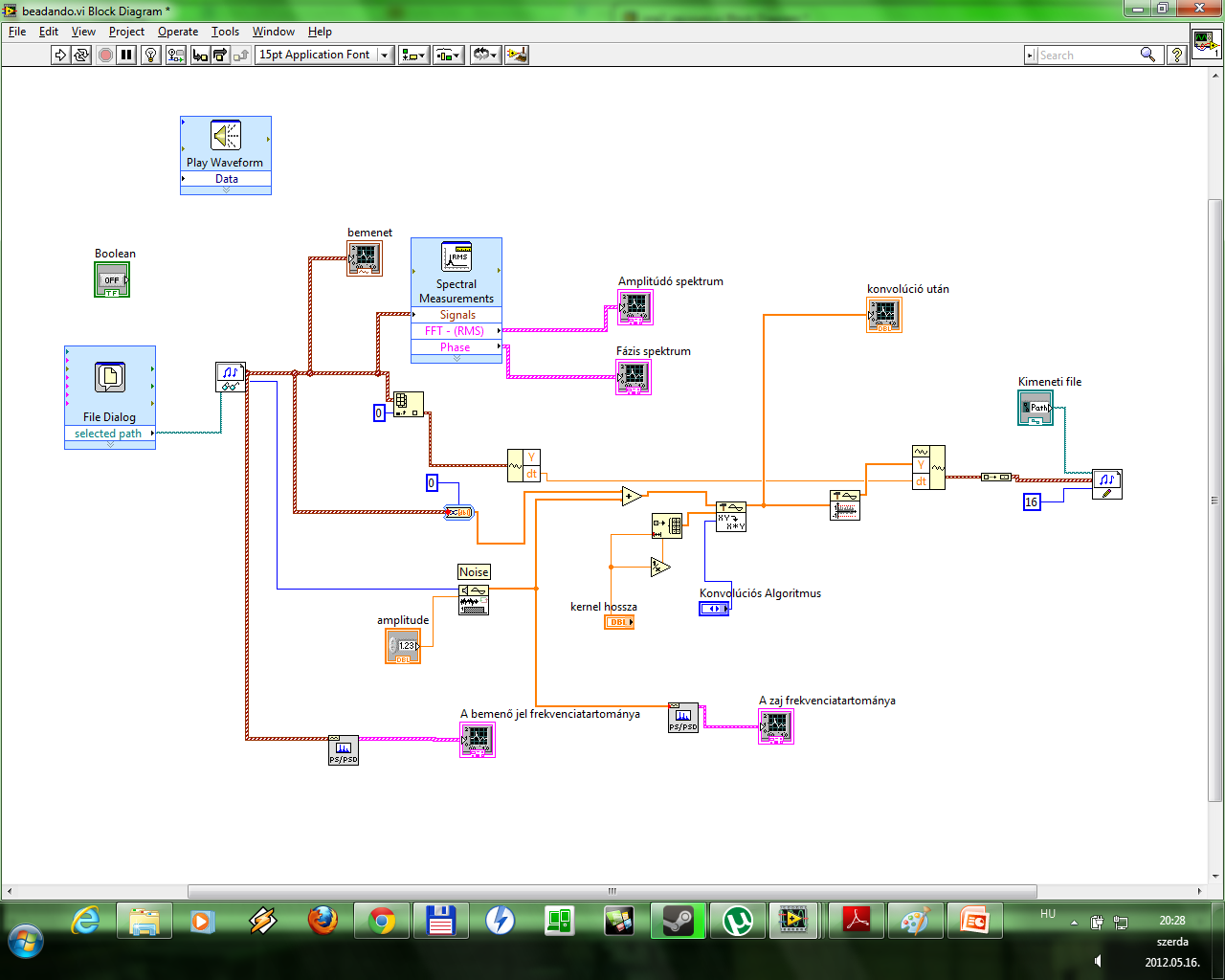
Hello. I want to do a mobile medium filter for my VI. I did a basic FIR filter... but I have not a clue how to make a filter means mobile.
+ I want a button to play the input wav file... How can I do this?This is the vi:
My tip for a moving average is to use the FIR filter with specific coefficients.
Regarding your wav file playback, discover the graphics and the sound palette. I have little experience with them, but I know that there is a screw there to read your wav file.
-
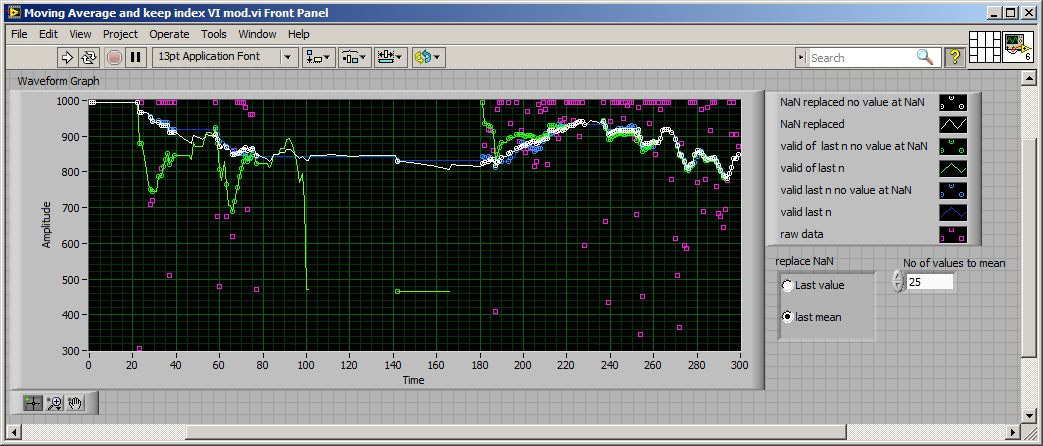
Moving average and keep indexing
Hi all
Many members share so nice VI for the execution of moving average. But if the measure deliver (NaN) it will be a problem in this case, specifically. When
the processing of the data is in real time mode. So please can help me to handle this.
Here I try to do, its works well, but when I insert it to the acquisition in time real and treatment he puts a lot of problems.
Thank you.
some methods more...
What are you going to measure? Just curious

-
exponential response moving average stage fpga
Hey guys,.
I have a problem with my filter, the exponential weighted moving average filter (IIR 1 st order.). Excerpt from the book: understand the digital signal processing (Richard Lyons) I have the following formula, calculate the frequency of 3dB (CF) of alpha. Alpha is the parameter to control the filter.
Differential equation of the filter: y [n] = x [n] * alpha + (1 - alpha) * y [n-1]
Relationship between CF and alpha: alpha = cos(2fc/fs) - 1 + sqrt [cos²(2fc/fs) - 4 * cos(2fc/fs) + 3]
If I now choose a frequency of 3 dB from 0, 0794Hz (time constant (TC) = 2 s) alpha = 0,00169621. (fs = 94)
For a filter command 1st IIR, the rise time (your) of the stepresponse (from 10% to 90%) is: ta = 2, 2 * TC which translates your = 4, 4S.
But if I simulate the step response, my rise time is about 3 times this value at 14.
I can't explain why the response of my filter is so much different. For my Moving Average filter, the calculated and simulated rise time are equal.
I have the vi that is performed on the attached FPGA. Maybe someone can find a mistake...
Greetz
Slev1n
Hey ZX81.
Thank you very much for your detailed answer.
Regarding the issue with the rise time, I think I've found the error. You might be right, that the formula is not correct, or which is most probably misunderstood by me and put in the wrong context.
When I was cycling home from work I remembered a practical function of labview: 'coefficients.vi filter smoothing' here you only need to define tau/TC and fs and it calculates the numerator and the denominator for the moving average exponential and the moving average. Offering it is alpha I could compare the result of the formula I've used and there was a big difference. LabVIEW uses the following formula: alpha = 1 - exp (-1 /(fs*TC)). With this formula, TC = 2 s is equal to alpha = 0, 0053.
And with this alpha my simulation works! Risetime 4.4 s

Quote you: "in general, at this stage, I have maturities adjust alpha until my results matching what I wanted and move." I would like to do the same thing, but as it's my thesis I have to solve such things
Now, back to the rounded questions. I understand that the small values are a more serious problem. This filter is used in a Lock In, the values are going to be REALLY small. But I've already tested on our measuring device and it works, to that effect, I'll test your version as well, but if I get no problems, I guess I keep to the 40bits. Simulating the following configuration, caused an error of 2.3%. 57 bits using reduced the error less than 1%. I think that 40bits should be sufficient.
Alpha = 0, 000335693 entry = 1, 19209E-7 And regarding resources, I have no worries. Although using a myrio ultimately I still have a lot of DSP Slices for the multiplication and 10% in flip flops.
So I guess that this matter is resolved. Thanks for your great help and interesting reflections.
Kind regards
Slev1n
-
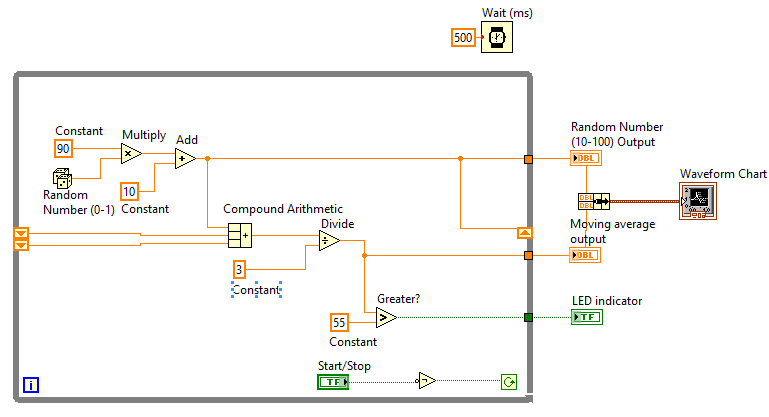
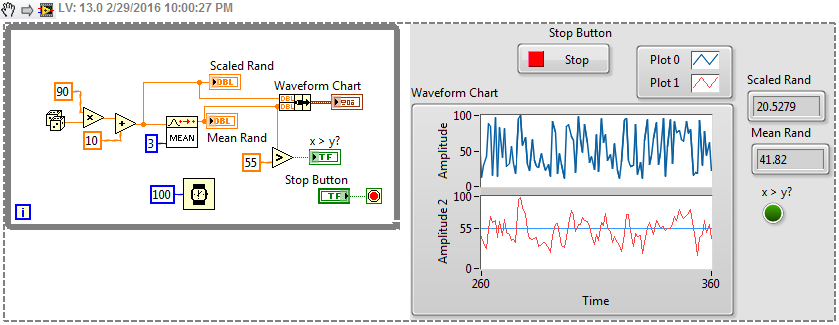
the moving average of 3 random numbers
This is my first time using LabVIEW and I need help.
- I have to design VI which generates the random number from 10 to 100
- VI shows the last generated number and the moving average of the last 3 generated number on a waveform graph
- If the average of the last 3 numbers obtained is greater than 55, to turn on the LED.
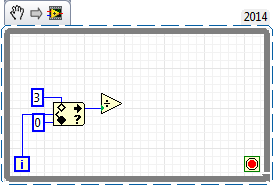
I did the whole VI but I have the problem with the first two loops. In the first loop, the moving average should show the random number itself (((random number) 1 + 0 + 0) / 1). In the second loop (((random number 1) + (random number) 2 + 0) / 2) and after that my VI works correctly. The moving average shows the other values in the first two loops (random number e.g. 17.54, average 29.28). Probably I have to change something in the shift registers, but I'm not sure how to do it. I need help to fix my VI for the first two loops. Thank you in advance.
easy
No explin he for grade
Of course there are other ways
-
What is meant by moving average? and hoe do we calculate in essbase.
Read the technical link referance and get back if you had doubts below.
http://download.Oracle.com/docs/CD/E10530_01/doc/EPM.931/html_esb_techref/funcs/movavg.htm
-
The CF is there a predefined function, method, function or an available UDF, which creates a trend line based on an analysis of regression on a cfquery result?
Thanks in advance!elbojpb wrote:
> The CF is there a predefined function, the function method or UDF available
> which will create a trend line based on an analysis of regression on a cfquery
> result?Take a look at the regression CFC here: http://www.cfczone.org/cfcs/index.cfm
-
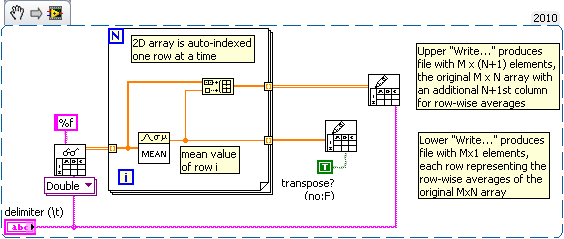
With an average of lines in a multidimensional array
I have a file (file1.dat) that is created using the 'write on the worksheet file vi', that writes the output of a photo detector. Experience a try N. Each test gives a table 1 d M number of data as a column. Once the experience complete, the file will contain N columns and rows of Mr. I'd like to find the average of each line in labview. The output (file 2.dat) should be a column of M elements, each element being the average of the N data contained in one line. Treatment in excel or origin is not possible. Generally, > 10000 and N > 100 M. Can help? For example:
file 1.dat:
A1 B1 C1
A2 B2 C2
A3 B3 C3
A4 B4 C4
File 2. dat must be:
(A1 + B1 + C1) / 3
(A2 + B2 + C2) / 3
(A3 + B3 + C3) / 3
(A4 + B4 + C4) / 3
Thank you!
If everything you have in the database without headers or footers, it should be fairly simple. Look at this:
-Kevin P

Maybe you are looking for
-
Why do the alert time calendar (first of all to draw the attention and the attention of second) always put when I put them? I used to have this problem sometimes with my old iPhone 4 but on my 6, I always have this problem. I would like to set an ala
-
3.6.2 numbers Mac OS X 10.11.6 I need either displays a decimal number, created by the timevalue function in the format 'hh' or using a formula to create the text equivalent of the value of time. Automatic data format it just displays as a decimal nu
-
How can I resolve the error "the volume has the bad upper/lower case distinction for a backup."?
It seems that Time Machine requires a case-sensitive file system.
-
How do the "full screen"? ". Cannot display the parameters to make the change.
The screen on my laptop was changed to mode full screen. Now the Firefox icon in the upper left is hidden by the full screen, so I can't turn it off. How can I do this?
-
Re: Sat Pro P300 - setting for the user account problems
Hi guys, the fact that someone knows what this means when the main user (who is the administrator of the computer) will not connect?It comes up with an error: the user profile service is unable to open. Profile of user cannot open.I can connect with