Definition of tables in MathScript
I noticed a problem when using tables that have been defined using the MathScript.
If I enter A = 0.1:0.1:3 and then I get A = 0.1, 0.2, 0.3... all the way up to and including 3.
However, if I get a value greater final, say that a = 0.1:0.1:10 then the table goes up to 9.9.
Is there a reason for this deliberate or is it just some kind of bug?
James
James,
I have not checked this with Mathscript, but it is likely that what you see is the common result of the representation of numbers in binary. Values such as 0.1 infinitely repeating fractions in binary. So when you are 100 of them, the error accumulated can be sufficient to cause the effect that you saw.
Lynn
Tags: NI Software
Similar Questions
-
Changing the definition of table PS_TXN use SECUREFICHIERS
Fusion Middleware Version: 11.1.1.7
WebLogic: 10.3.6.0
JDeveloper Build JDEVADF_11.1.1.7.0_GENERIC_130226.1400.6493
Project: Custom Portal Application WebCenter integrated with ADF custom workflows.
During our ADF application performance tests, we noticed that a lot of contention on the LOB segments for the table PS_TXN (supports transactions State passivation/activation).
Movement of the LOB segment to use Oracle SECUREFICHIERS, most other tweaks to the definition of the table showed significantly reduce the contention as providing a much higher throughput for read and write operations.
To implement these changes, we would like to modify the ADF internal script that creates the table in the first place rather manually, dropping the table or by using the online table reorganization.
This approach is documented, and suggests that this can be done my edit script "adfbc_create_statesnapshottables.sql" located under the directory MIDDLEWARE_HOME/oracle_common/sql $. We tried it, but after letting off the table in a test environment, ADF is re - create the table using the original definition when the application is done after the operation first move.
The same scenario can also be found under $MIDDLEWARE_HOME/oracle_common/modules/oracle.adf.model_11.1.1/bin however edit this file also makes no difference.
Does anyone know what script ADF uses to create the table, or if this is now coded in a class file or some other mechanism?
Automatic creation of table PS_TXN is hardcoded in the oracle.jbo.pcoll.OraclePersistManager class. Have a look at the statements at the end of the OraclePersistManager.createTable () method (in line 904 according to my decompiler). Other SQL statements (for example to drop the table, to the updates/insertions/deletions in the table, etc.) are defined inside the class oracle.jbo.pcoll.TransactionTableSqlStrings. You can find these classes within $MIDDLEWARE_HOME/oracle_common/modules/oracle.adf.model_11.1.1/adfm.jar.
If your database is not Oracle, but DB2 or MS SQL Server, then you should look at the classes oracle.jbo.pcoll.pmgr.DB2PersistManager and oracle.jbo.pcoll.pmgr.SQLServerPersistManager respectively.
You can override the default value PersistManager (create a new class that extends oracle.jbo.pcoll.OraclePersistManager and override/change the createTable() method), and then specify the new class in the AOS "jbo.pcoll.mgr" configuration property CreateTable() method has a package-level visibility, it would be very easy to do. This approach is delicate and the efforts needed to make does not, in my opinion. If I were you, I would be to pre-create the necessary tables in PS_TXN updated the manually.
Dimitar
PS Scripts SQL "adfbc_create_statesnapshottables.sql" aims to be used by advanced users who want to create their paintings previously manually. These scripts are not used by the infrastructure when it automatically creates the necessary tables.
-
definition of tables sweet people
Hello
where can I find the definition of the tables sweet people?
Something like that for example the oracle tables:
http://download.Oracle.com/docs/CD/B19306_01/server.102/b14237/dynviews_1131.htm#REFRN30105
Thanks a lot before.V$INSTANCEThis view displays the state of the current instance. Column Datatype Description INSTANCE_NUMBER NUMBER Instance number used for instance registration (corresponds to the INSTANCE_NUMBER initialization parameter) See Also: "INSTANCE_NUMBER" INSTANCE_NAME VARCHAR2(16) Name of the instance HOST_NAME VARCHAR2(64) Name of the host machine VERSION VARCHAR2(17) Database version ....................... ............................ .................................You asked the same question in August ' 08, please consult your own thread:
Re: The definition of column in table PSPRCSRQSTNicolas.
-
Definition of table PSPRCSRQST column
Hello
where can I find the PSPRCSRQST of the table column definition?
Thank you.Is it useful or correct answer?
;-)Mr. Nichols.
-
Problems creating table in MathScript
ENGLISH: Hello I'm reading coordinates x and Y, they may be together or separated, such X10Y20 or X 10 or 20, I managed to separate them and read, now that I wanted to put them in a table, but can't, I did following annex, F (1, T) = X, where T is the value of each increment would keep well in different positions of the table except that each value that adds to the previous guess the value zero, sorry - for me typing errors, do not speak English, speaks only of the Portuguese and I use a translator.
Português: Ola estou lendo coordinated some em X e Y, elas shaped estar juntas, UO entraba, exemplo X10Y20 UO X 10 UO Y20, ja separa las e ler, agora EU queria could love-las em uma matriz, mas nao can, EU fiz a seguinte programacao, M (1, T) = X, T wave e o cada increase assim iria save em posicoes diferent valor da matriz , that so a cada valor than scene os anteriores assumem o valor zero, desculpe - me por haver digitacao erros, não falo ingles, so falo portugues e estou using um tradutor.
-
Definition of Table stamp using a tabular presentation
Hello
I have a form of Tabluar (update only) where 2 columns can be updated on
a table, something like:
Employee (table)
-------------------------
emp_name varchar2
Status char (1)
Modified_By varchar2
If the columns emp_name or status is changed, I want the Modified_By define
for this line.
Sounds easy, but I only know how to use the automatic treatment of the form of tables.
Thanks for any help.
CarolThe best sollution to use the trigger somethink like him:
-This generation of trigger id (PK), stamp date of creation and editing and creation of stamp as to who.
CREATE OR REPLACE TRIGGER Employee_trg
FRONT
INSERT OR UPDATE
WE employee
REFERRING AGAIN AS NINE OLD AND OLD
FOR EACH LINE
BEGIN-insertion, you can omit but it is very useful for
IF THE INSERTION
If: NEW. EM_ID is NULL then
SELECT Employee seq. NEXTVAL INTO: NEW. EMID FROM DUAL;
end if;
: NEW. CREATED_ON: = SYSDATE;
: NEW. CREATED_BY: = nvl (v ('APP_USER'), USER);
END IF;IF THE UPDATE CAN
: NEW. LAST_UPDATED_ON: = SYSDATE; -It is also useful
: NEW. Modified_By: = nvl (v ('APP_USER'), USER);
END IF;
END;
/ -
Is it possible to have definitions of columns in a table to create
I was wondering if it is possible to have calculated columns, such as those below in the statement CREATE TABLE in Oracle. And if so, how do write you?
* CREATE TABLE [Sales]. [SalesOrderHeader] (*
* [SalesOrderID] [int] IDENTITY (1,1) NOT for REPLICATION NOT NULL, *.
* [SalesOrderNumber] AS (isnull (do SO'+ CONVERT ([nvarchar] (23) [SalesOrderID], 0), no * ERROR *')), *.
* [Subtotal] [money] NOT NULL, *.
* [TaxAmt] [money] NOT NULL, *.
* [Transport] [money] NOT NULL, *.
* [TotalDue] AS (isnull (([SubTotal]+[TaxAmt]) + [Freight], (0))), *.
*)*
I would like to re - write the definition of table CREATE TABLE DTPartInv with partinv_flag AS a computed column when the value is X,
If partinv_instock < partinv_reorder and O
If partinv_instock > = partinv_reorder:
CREATE TABLE DTPartInv
(partinv_partnbr VARCHAR2 (10) NOT NULL,)
partinv_prodname VARCHAR2 (25).
partinv_desc VARCHAR2 (25).
partinv_manufact VARCHAR2 (25).
partinv_instock INTEGER NOT NULL,
partinv_category VARCHAR2 (20).
partinv_purchdate DATE,
partinv_loc VARCHAR2 (15).
partinv_price NUMBER (6.2),
partinv_vendor VARCHAR2 (20).
partinv_reorder INTEGER NOT NULL,
partinv_serial VARCHAR2 (20).
partinv_flag VARCHAR2 (1).
CONSTRAINT DTPartInv_partinv_partnbr_pk
PRIMARY KEY (partinv_partnbr)
);>
I was wondering if it is possible to have calculated columns, such as those below in the statement CREATE TABLE in Oracle. And if so, how do write you?
>You did not mention your Oracle database version. Depending on your version, you can do. If you're on 11 GR 1 material or above, you can follow these steps:
CREATE TABLE DTPartInv ( partinv_partnbr VARCHAR2(10) NOT NULL, partinv_prodname VARCHAR2(25), partinv_desc VARCHAR2(25), partinv_manufact VARCHAR2(25), partinv_instock INTEGER NOT NULL, partinv_category VARCHAR2(20), partinv_purchdate DATE, partinv_loc VARCHAR2(15), partinv_price NUMBER(6,2), partinv_vendor VARCHAR2(20), partinv_reorder INTEGER NOT NULL, partinv_serial VARCHAR2(20), partinv_flag as (case when partinv_instock < partinv_reorder then 'X' else 'O' end), CONSTRAINT DTPartInv_partinv_partnbr_pk PRIMARY KEY (partinv_partnbr) ) ; Table created.-Test it now
-Box partinv_instock when <> _
SQL > insert into DTPartInv (partinv_partnbr, partinv_instock, partinv_reorder) values ('Test', 10, 20);1 line of creation.
-Box when partinv_instock = partinv_reorder_
SQL > insert into DTPartInv (partinv_partnbr, partinv_instock, partinv_reorder) values ('Test2', 10, 10);1 line of creation.
-Box when partinv_instock > partinv_reorder_
SQL > insert into DTPartInv (partinv_partnbr, partinv_instock, partinv_reorder) values ('Test3', 20, 10);
1 line of creation.
SQL> select partinv_partnbr, partinv_flag from DTPartInv; PARTINV_PA P ---------- - Test X Test2 O Test3 O 3 rows selected.Happy?
Therefore, always mention the version of database when you post specific requests as features differ from one version to the next.
Concerning
-
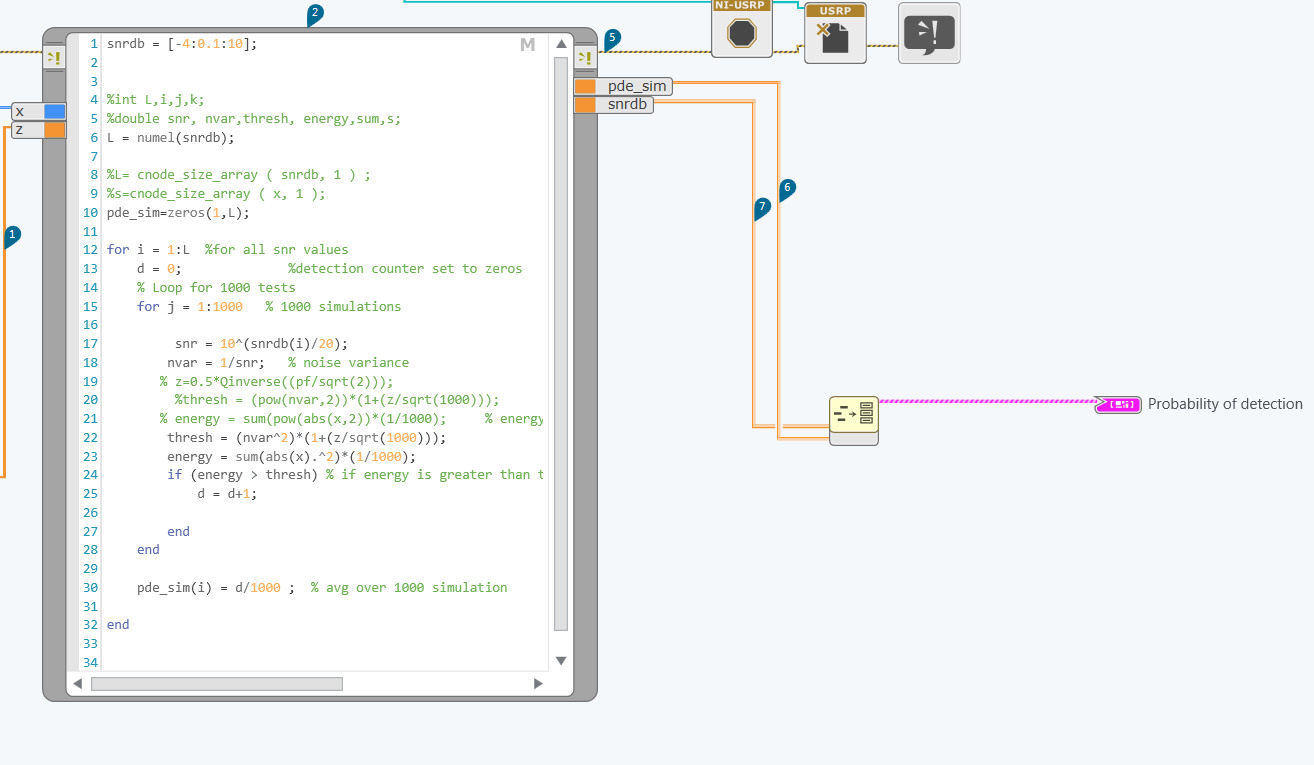
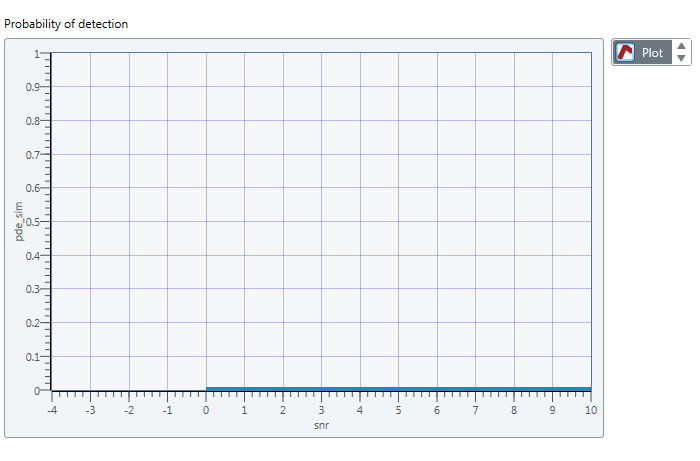
How to draw 2 tables on a graph in labview communication design
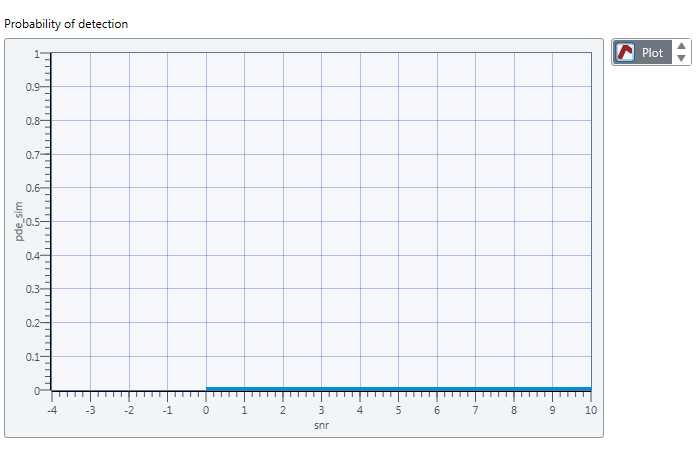
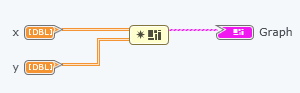
In fact, I'm trying to draw 2 tables the mathscript node .one depends on the other. I did a cluster for the 2 bays and led to plot in the chart, but the chart doesn't really show the exact values.
I want to draw pde_sim which depends on the snrdb.
the figure resulted that I get is:
Is something wrong with my code?
Hello
You must use the Cluster to build instead of building Cluster Bay.
-
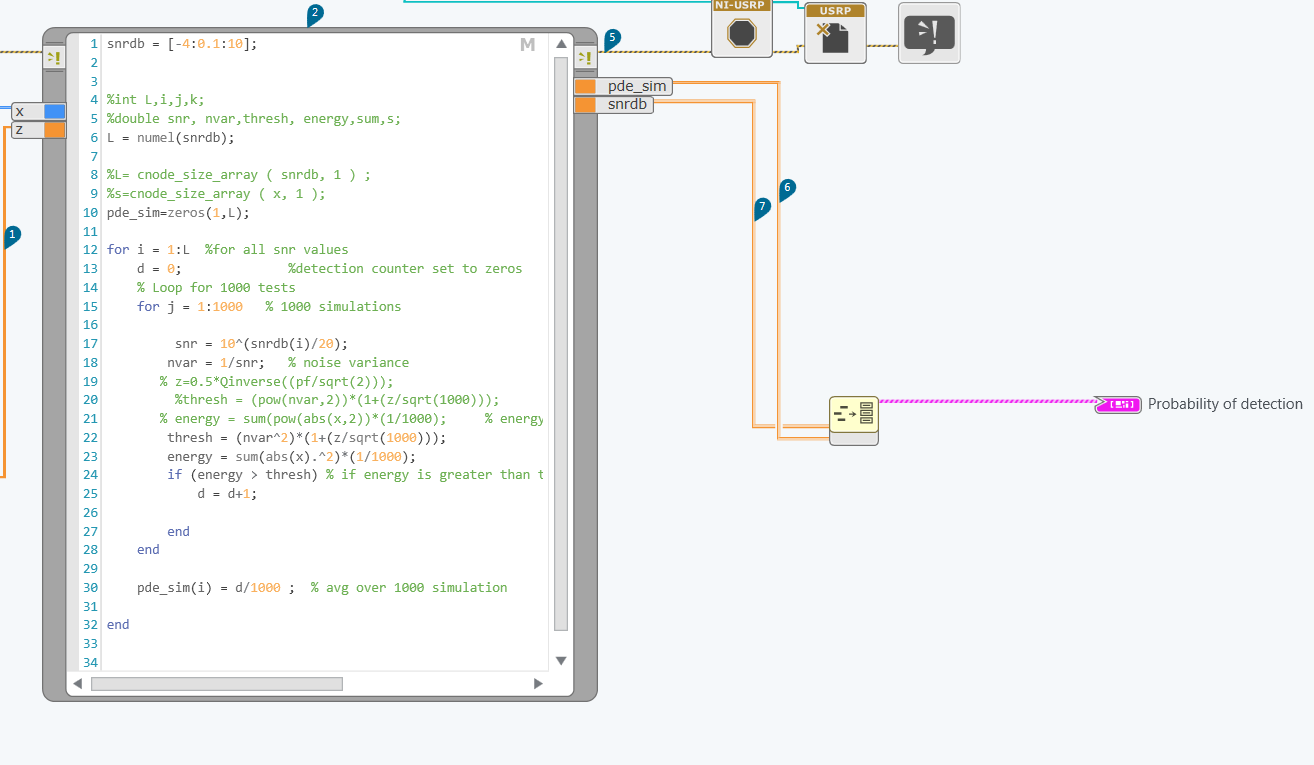
How to draw 2 tables on a graph?
In fact, I'm trying to draw 2 tables the mathscript node .one depends on the other. I did a cluster for the 2 bays and led to plot in the chart, but the chart doesn't really show the exact values.
I want to draw pde_sim which depends on the snrdb.
the figure resulted that I get is:
Is something wrong with my code?
See duplicate:
-
Hello
I wrote the MATLAB code to produce a square at a certain frequency to 0.01 seconds. The code performs a loop then back to produce a similar squares but at a different frequency and it then concatenates up to the end of the first square. There are 100 these iterations as she founded a square of frequency change that runs for 1 second (or 0.01 * 100). I want this squares with the computer output speakers.
The code works in MATLAB, but when I copy in the window of Matchscript it does not work. The commands I use seem to be compatible with Mathscript and it seems that the problem happens at the stage of the loop. My MATLAB code is pasted below and I join the LabVIEW VI with my Mathscript window. Could someone please take a look at my code and see if I am missing any common questions? I am a new user of LabVIEW and am not completely familiar with its intricacies.
______________________________________________________________________________
CLC
sample rate = 40000;
Step = 1/sampling rate;freqArray = [5247.819345 2691.190023 2379.575143 2242.862777 2162.605492 2105.101801 2056.973700 2011.841157 1966.260707 1918.191205 1866.327910 1809.784986 1747.934921 1680.325561 1606.638751 1526.672983 1440.340700 1347.674817 1248.840788 1144.151306 1034.080952 919.278207 800.572260 678.972385 629.941608 670.923135 706.090004 733.248856 750.729600 757.468401 753.055128 737.746864 712.449234 678.666661 638.422079 594.147026 548.544635 504.430794 464.562051 431.461673 407.256955 393.540721 391.268089 400.696344 421.371792 452.163428 479.456733 499.635983 519.683091 539.345489 558.379030 576.550816 593.641724 609.448655 623.786494 636.489853 647.414604 656.439263 663.466274 668.423222 671.264030 671.970137 670.551695 667.048751 661.532385 654.105760 660.331784 659.175196 658.042926 656.973398 656.008980 655.196461 654.587596 654.239768 654.216768 654.589753] [655.438402 656.852357 658.933014 661.795790 665.573014 670.417674 676.508334 684.055673 693.311331 704.580088 718.236954 734.751698 754.724945 778.942900 808.463177 844.755078 889.940437 947.233277 1021.807261 1122.692006 1267.554308 1497.662150 1946.857495 4694.713066];
z = [ ];
T2 = [];
for n = 0:99
t = (0 + (0.01 * n)): step: (0.01*(n+1)) - stage;
y = (square (2 * pi * freqArray (n + 1) * t) + 1) / 2; % VL creation at different frequencies
z = [z, y]; % is concatenate matrices
T2 = [t2, t]; tables of time CONCATENATE %
endPlot (T2, z)
Sound (z, 40000, 16)_______________________________________________________________________________
DCT,
Remember that table in MathScript indices are 1-based, so change the for loop statement "for n = 1/100' should do the job. It can be a little confusing because array indices are based on 0 in native LabVIEW, so you must make sure to add or subtract 1 during the back and forth between LabVIEW code and MathScript code.
Chris M
-
Hello
I'm looking in a logging table (T1)
(a) the early line for each 'name '.
(b) these names without any entry in the table of logging. Possible names are defined in table T2.
I have a solution (see below), but I think that there must be a more adequate.
Any help is appreciated.
Thanks, Hans
Here are the definitions of table;
CREATE TABLE 'T1' ('NAME' VARCHAR2 (20 BYTE) 'INFO', DATE 'LOG_DATE', 'STATUS' VARCHAR2(20 BYTE), VARCHAR2 (20 BYTE));
CREATE TABLE 'T2' (VARCHAR2 (20 BYTE) 'NAME');
And some test values
Insert into T1 (NAME, STATE, LOG_DATE, INFO) values ('A', '0', to_date ('14.12.2015 12:09:51 ',' DD.)) MM YYYY HH24:MI:SS'), ' (INFO A 0');
Insert into T1 (NAME, STATE, LOG_DATE, INFO) values ('A', '1', to_date ('14.12.2015 12:10:16 ',' DD.)) MM YYYY HH24:MI:SS'), ' (INFO A 1');
Insert into T1 (NAME, STATE, LOG_DATE, INFO) values (' B ', 1', to_date ('14.12.2015 12:10:38 ',' DD.) ") MM YYYY HH24:MI:SS'),'INFO B 1');
Insert into T1 (NAME, STATE, LOG_DATE, INFO) values (' B ', ' 0', to_date ('14.12.2015 12:11 ',' DD.) ") MM YYYY HH24:MI:SS'),'INFO B 0');
Insert into T2 (NAME) values ('A');
Insert into T2 (NAME) values ('B');
Insert into T2 (NAME) values ('C');
My solution:
with a (too)
Select t1.name, max (log_date) MaxLogDate from T1 group by name
),
b like)
Select t1.name, t1.status, t1.log_date, t1.info
Of
a, t1
where
T1. Name = B.SID and
T1.log_date = a.MaxLogDate)
Select t2.name, b.log_date, b.status
b outer join t2 on t2.NAME = b.name right
b.name order;
What gives these results:
'NAME '. "LOG_DATE. 'STATUS '. « A » "14.12.2015 12:10:16. « 1 » « B » "14.12.2015 12:11. « 0 » « C » "" ""
using the rank function
Select t2.name, t.log_date, t.status
de)
SELECT t1.name, t1.log_date, t1.status, row_number () over (partition by t1.name t1.log_date desc order) rn
from t1
) t
join right t2 on t2.name = t.nom and t.rn = 1
order of t2.name
-
Followed by using OBIEE 11 g seems to try to insert in a table not specified in NQSconfig
Hi all
A former member of the staff to the United Nations, for it to work I had implemented monitoring using the tables S_NQ_DB_ACCT and S_NQ_ACCT of the use.
Another Member of staff then decided he wanted to customize our monitoring of its use and creates a table called USG_Tracking_F replacing S_NQ_DB_ACCT and S_NQ_ACCT.
From what I see, the layer of the RPD was updatees with the pool connection pointing to the new table. The NQSconfig file has also been updated with the new definition of table etc. and I checked the config of the mbean server and it refers to USG_Tracking_F.
I also confirmed that the data exists in the new table and not in old pictures.
The question is that something always seeks to INSERT IN S_NQ_DB_ACCT about 200 times per hour.
Following error message:
[nQSError: 17001] Oracle error code: 2291, message: ORA-02291: integrity constraint (OBI_BIPLATFORM. FK_S_NQ_DB_ACCT) violated - key parent not found
beak call OCIStmtExecute: INSERT IN S_NQ_DB_ACCT (ID, LOGICAL_QUERY_ID, QUERY_TEXT, QUERY_BLOB, TIME_SEC, ROW_COUNT, START_TS, START_DT, START_HOUR_MIN, END_TS, END_DT, END_HOUR_MIN) VALUES (: 1,: 2,: 3,: 4,: 5,: 6,: 7: 8: 9,: 10:11:12).
The server has been restarted several times, as this change was made so I can exclude.
I also removed the old tables of the RPD layer in the case which was linked.
Anyone has an idea why OBIEE is still trying to insert into the old paintings?
See you soon,.
Adam
S_NQ_DB_ACCT (physical request details) were introduced more recently in OBIEE and does not have an MBean that it directly controls. I think that OBIEE assumes that it is in the same schema/catalog like the monitoring logic (S_NQ_ACCT) use that is customizable by the MBean.
That is why the mucking with the tables provided by OBIEE is generally a bad idea - better to build above them (view/mview/whatever) than trying to replace. The spirit of simple problems like this one you ever - every time as schema changes (in 11.1.1.9 there are some new added columns), you need to update your custom solution.
In order to resolve your problem, you can either try and difficulty that you have, perhaps by removing the constraint (he's going to make mistakes, but the knacker of your data integrity) - or just replace the config vanilla & tables and instead build on measure on top of, rather than instead of.
Hope that helps.
-
How to perform account on a Table hierarchical Oracle based on the Parent link
Hello
I have the following to Oracle 11 g R2 hierarchical table definition:
Table Name: TECH_VALUES: ID, GROUP_ID, LINK_ID PARENT_GROUP_ID, TECH_TYPE
Above the hierarchical table definition, some examples of data might look like this:
ID GROUP_ID LINK_ID PARENT_GROUP_ID TECH_TYPE
------- ------------- ------------ -------------------- --------------
1 100 LETTER_A 0
2 200 LETTER_B 0
3 300 LETTER_C 0
4 400 LETTER_A1 100 A
5 500 LETTER_A2 100 A
6 600 LETTER_A3 100 A
7 700 LETTER_AA1 400 B
8 800 LETTER_AAA1 700 C
9 900 LETTER_B2 200 B
10 1000 LETTER_BB5 900 B
12 1200 LETTER_CC1 300 C
13 1300 LETTER_CC2 300 C
14 1400 LETTER_CC3 300 A
15 1500 LETTER_CCC5 1400 A
16 1600 LETTER_CCC6 1500 C
17 1700 LETTER_BBB8 900 B
18 1800 LETTER_B 0
19 1900 LETTER_B2 1800 B
20 2000 LETTER_BB5 1900 B
21 2100 LETTER_BBB8 1900 BKeeping in mind that there are only three Types of technology, i.e. A, B and C, but could not span on different
LINK_IDs, how can I do a count on these three differentTECH_TYPEsbased solely on the ID of parent link where the parent group id is 0 and there are children below them?NOTE: It is also possible to have parents in dual link ID such as LETTER_B and all values of children but different group ID.
I'm basically after a table/report query that looks like this:
Link ID Tech Type A Tech Type B Tech Type C
-------------- ------------------- -------------------- -------------------
LETTER_A 3 1 1
LETTER_B 0 3 0
LETTER_C 2 0 3
LETTER_B 0 3 0Be hierarchical and my table can consist more of 30 000 files, I must also ensure that performance to produce the report above shown here query is fast.
Obviously, in order to produce the report above, I need to gather all necessary County outages based on
TECH_TYPEfor all parents of the link id where thePARENT_GROUP_ID = 0and store it in a table according to the guidelines of this report layout.Hope someone can help with maybe a combined query that performs the counties as well as stores the information in a new table called LINK_COUNTS, which will be based on this report. Columns of this table will be:
ID,LINK_ID,TECH_TYPE_A,TECH_TYPE_B,TECH_TYPE_CAt the end of this entire requirement, I want to be able to update the LINK_COUNTS table based on the results returned by the sample data above in a SQL UPDATE transaction as the link ID parent top-level already exists within my table LINK_COUNTS, just need to provide values for breaking County for each parent node link , i.e.
LETTER_ALETTER_BLETTER_CLETTER_Busing something like:
UPDATE link_countsSET (TECH_TYPE_A,TECH_TYPE_B,TECH_TYPE_C) =(with xyz where link_id = LINK_COUNTS.link_id .... etcWhich must match exactly the above table/report
Thank you.
Tony.
Hi, John,.
Thanks for posting the sample data.
John Spencer wrote:
... If you need to hide the ID column, then you could simply encapsulate another external query around me. ...
Or simply not display the id column:
Select link_id, -id,
Count (case when tech_type = 'A' end then 1) tech_a.
Count (case when tech_type = 'B' then 1 end) tech_b,.
Count (case when tech_type = "C" then 1 end) tech_c
of (connect_by_root select link_id link_id,)
the connect_by_root ID, tech_type
of sample_data
Start with parent_group_id = 0
connect prior group_id = parent_group_id)
Link_id group, id
order by link_id, id;
Same results, using SELECT... PIVOT
WITH got_roots AS
(
SELECT CONNECT_BY_ROOT link_id AS link_id
Id CONNECT_BY_ROOT ID
tech_type
OF sample_data
START WITH parent_group_id = 0
CONNECT BY PRIOR group_id = parent_group_id
)
SELECT link_id, tech_a, tech_b, tech_c
OF got_roots
PIVOT (COUNT (*)
FOR tech_type IN ('A' AS tech_a
'B' AS tech_b
'C' AS tech_c
)
)
Id ORDER BY link_id
;
-
ORA-14299 & many partitions limits per table
Hello
I have linked the question, see below for the definition of table and error during the insert.
CREATE TABLE MyTable
(
RANGEPARTKEY NUMBER (20) NOT NULL,
HASHPARTKEY NUMBER (20) NOT NULL,
SOMEID1 NUMBER (20) NOT NULL,
SOMEID2 NUMBER (20) NOT NULL,
SOMEVAL NUMBER (32,10) NOT NULL
)
PARTITION BY RANGE (RANGEPARTKEY) INTERVAL (1)
SUBPARTITION BY HASH (HASHPARTKEY) 16 SUBPARTITIONS
(PARTITION myINITPart NOCOMPRESS VALUES LESS THAN (1));
Insert Into myTable
Values
(65535,1,1,1,123.123)
ORA-14299: total number of partitions/subpartitions exceeds the maximum limit
I am aware of the restriction that Oracle has on a table. (Max 1024K-1 including the partitions
subpartitions) that prevents me to create a document with the key value of 65535.
Now I am stuck as I have more than this number (65535) ID, the question becomes how to manage
by storing data of the older identifications this 65534?
One of the alternatives that I thought is retirement/drop old partitions and modify the first partition
myINITPart to store data for more partitions (which are actually retired in any way) - that I could
having more available for store IDS.
Therefore the PARTITION myINITPart VALUES LESS THAN (1) would be replaced by VALUES myINITPart PARTITION
LESS THAN (1000) and Oracle will allow me to store additional data 1000 ids. My concern is Oracle
I do not change the attributes of the original score.
Don't we see no alternatives here? Bottomline, I want to store data for IDS higher than 65535 without restriction.
Thank you very much
Dhaval
Gents,
I want to share that I found alternative.
Here's what I did.
(1) merge first partition in following adjacent partition, in this way, I will eventually have an extra-tested partition, the number of limit of n + 1 partition (this is what I wanted) - so where before I do not - charge I will eventually merge the first partition (in this case, my first couple of partition will be empty anyway in order to not lose anything by merging)-faster in my case.
(2) any index, we have will be invalidated needs to rebuild itself, I'm good that I have none.
(3) local index is not invalidated.
So, I was able to increase the limit of fusion just first partition in following a good - work around.
Thank you all on this thread.
-
Reconstruction of the table should be performed after removal of most of its data?
Hi all
We are on Oracle 10.2.0.4 on Solaris 10. There is a table in my DB of production that has 872944 number of lines. Most of his data is now useless, that it must keep, based on a date column in the table just last a month of rest data and delete data. Thus, after the array will be just 3000 lines.
However, as the table was huge earlier (872 k lines before you remove), the deletion of data releases his oracle blocks and reduced the size of the table? Otherwise, this will help in the reconstruction of the line (redefined online) table so that the query that performs a full scan on this table goes faster?
I checked using an example of a table that simply deleting data does not remove the oracle blocks - they remain in the user_tables for this table and complete the table scan cost remains the same. I think that after this deletion, I have to do a re-definition of table online, which is the right decision so we have a query that makes the full table scan?
Thank youIf read you about the orders, you will find that they require a DDL lock. Your users should not notice this.
Maybe you are looking for
-
Download link for iTunes for Windows 10 broken
I need to download the latest version of iTunes for Windows 64-bit 10. When I go to download, the "Download" button does not work. If I go over it, there is no hyperlink to the download site. Is there another mirror where I can download it directly?
-
Toshiba control buttons stopped working on Satellite
"turn off the lights" and "windows media player" media buttons no longer work...They did a couple of days. Not sure why they stopped working. When I open media player manually, the * play/pause, stop, previous / next buttons * work, just the * LEDs p
-
Blood trace on Distance reading
Hello I am trying to trace the readings of a cell voltage of charge (for blood pressure) on the movement of the origin of a linear actuator on the same axis. I just want that the readings of the two while loops to enter a chart and draw the correlat
-
Cannot retrieve the CD in Media Player
Media Player does not recognize that a CD is in place. Tells me to insert my CD to rip. The latest version of Media Player and to use Windows XP. Thanks for the suggestions or answers!
-
my computer is stuck on searching for updates
IM using windows vista tries to install SP2 that failed. This led me to download and run the system update tool, but my computer got stuck on the search for updates. . I get not implemented automatic updated provoke more support for SP1 ceased. an