Duplicate values in fast graphics
I use prompt graphic for one of my graphics and when I run the Analyses with the graphic prompt from the drop it is picking up items in there. I don't know why this is happening. For ex: I a, b, c, d elements but quick drop-down chart me a, b, a, c, d, a, b, c and d, a, a some like this I wanted to is a, b, c, d. me please advice
Thank you
Srinivas.
Hi Srinivas,
If you create a calculated item several times in a table view, those who come in duplicate chart prompt.
Tags: Oracle Applications
Similar Questions
-
Want to have a faster graphics on the Satellite A100-326
Hi all
How can I make my Nvidia 7300 running faster graphics card? On Star Trek Legacy if I turn anti-aliasing on it starts to become very slow. Any chance to do an upgrade?
Thank you
Ricardo
The nVidia GeForce FX Go 7300 is a powerful graphics card with 256 MB memory clean (not shared memory)
Generally there is not a lot to do, but some settings can be changed in the nVidia GeForce tab which is located in the properties of the graphics card-> advancedThere is an area of performance tuning & quality. You can change the anti-aliasing settings manually or controlled Application.
You can also set the maximum performance PowerMizer settings. The graphics card will waste more power but runs well powerful. But this setting is not recommended if you are running the laptop on battery. -
How to find duplicates of a field value? For example - in a field, I have values like {123,345,346,123}, now I want to remove the duplicate value in the field so that my output looks like {123,345,346}
If it's an array you want to deduplicate then here is a script [for use in the Script Processor] I prepared earlier:
var result = new Array();
var added = new Object();
If (input1 [0]! = null)
{
for (var i = 0; i)< input1[0].length;="">
{
var point = input1 [0] [i];
If (! added [item])
{
added [item] = 1;
result [result. Length] = item;
}
}
}
Output 1 = result;
Kind regards
Nick
-
Duplicate values generated by an Oracle sequence
Hello
Since a few days we are facing a weird problem in our application where the sequences seem to be generating duplicate values. Previously I thought is this is not possible, but now it seems to be a problem. Here are the details:
Select * from v$ version;
Oracle Database 11 g Enterprise Edition Release 11.2.0.2.0 - 64 bit Production
PL/SQL Release 11.2.0.2.0 - Production
CORE Production 11.2.0.2.0
AMT for Linux: Version 11.2.0.2.0 - Production
NLSRTL Version 11.2.0.2.0 - Production
We use to insert it into a table column of the last sequence value that is of course the primary key of the table column. Today, we received a violation of unique constraint on the column of the primary key (which is driven by the sequence). Below is the last value of the PK column
SELECT MAX(PCCURVEDETAILID) OF T_PC_CURVE_DETAILS;
162636
and below, was the last value in the sequence that has been less than the PK column
SELECT S_PCCURVEDETAILS. NEXTVAL FROM DUAL;
162631
Then we checked the data of the user_sequences and found the next sequence value (LAST_NUMBER) to be 162645 which was greater than the current value of the sequence:
Select * de user_sequences one où a.sequence_name as "S_PCCURVEDETAILS" ;
SEQUENCE_NAME
MIN_VALUE
MAX_VALUE
INCREMENT_BY
CYCLE_FLAG
ORDER_FLAG
CACHE_SIZE
LAST_NUMBER
S_PCCURVEDETAILS
1
1E + 27
1
N
N
20
162645
I then modified the nocache sequence:
change sequence S_PCCURVEDETAILS NoCache ;
Select * de user_sequences one où a.sequence_name as "S_PCCURVEDETAILS" ;
SEQUENCE_NAME
MIN_VALUE
MAX_VALUE
INCREMENT_BY
CYCLE_FLAG
ORDER_FLAG
CACHE_SIZE
LAST_NUMBER
S_PCCURVEDETAILS
1
1E + 27
1
N
N
0
162633
SELECT S_PCCURVEDETAILS. NEXTVAL FROM DUAL;
162632
We also face the same type of problem of violation of primary key to another sequence-driven table, a few days before.
In our code, I also checked that the primary key in the table value is inserted using only the value of the sequence.
Can anyone please suggest any reason this issue for
Concerning
Deepak
I faced a similar problem about 3 years ago. Here's the story, suddenly in my UAT environment a job that inserts data in some tables began to throw exceptions of primary key violation. After investigation, I found that the sequence is x, but the primary key for the table is x + y. investigation more - DBA moved all production data without even notifying the application support team.
Morale - pretty obvious
-
Check all the duplicate values in the column COUNT()
Hello
I'll do some tests, and for this I need to retrieve data based on a single column for example test_data_col, which-
1 to 3 or more count (test_data_col) for a given set of columns for example grp_col1, grp_col2, grp_col3 group
2. overall recovered lines, this particular column has some duplicate values. I don't need displayed duplicates, just whether or not duplicates exist.
Which could explain what I'm trying to do -
grp_col1, grp_col2, grp_col3, test_data_col
1, A, xyz, HELLO
1, A, xyz, HELLO
1, a, xyz, BYE
1, A, xyz, goodbye
2, C, pqr, WELCOME
2, C, pqr, GOOD MORNING
2, C, pqr, BAD MORNING
So for condition 1, I do something like that.
In this request, I want to do something that will tell me if the aggregate COUNT (test_data_col) has all the duplicate values it contains. Yet once, display the duplicates is not important here.SELECT COUNT(test_data_col) cnt, grp_col_1, grp_col2, grp_col3 FROM test_tab GROUP BY grp_col_1, grp_col2, grp_col3 HAVING COUNT(test_data_col) >= 3;
With the correct to replace coding / * some * logic /, I have following values.SELECT COUNT(test_data_col) cnt, grp_col_1, grp_col2, grp_col3, /*some logic*/ dup_val FROM test_tab GROUP BY grp_col_1, grp_col2, grp_col3 HAVING COUNT(test_data_col) >= 3;
CNT, grp_col_1, grp_col2, grp_col3, dup_val
4, 1, a, xyz, Y
3, 2, C, pqr, N
I have dup_val column to explain what I'm trying to achieve... Another way to know the existence of duplicates in the aggregate count will be fine.
My version of Oracle's Oracle Database 11 g Enterprise Edition Release 11.1.0.7.0
Do you like the answer!Your somewhere logical can be like that
case when COUNT(test_data_col) != COUNT(distinct test_data_col) the 'Y' else 'N' end dup_val -
Hi all
I have a table with collums as follows:
and the following data:create table uni_ids (ID varchar2(10), field number, activity number, frequence number, field_1 number, field_2 varchar(100));
What I would get with my querry is duplicated files, so resoul of it should be like:insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1999',1,2,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1999',1,2,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1990',1,3,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1990',1,4,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1990',1,2,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1991',1,2,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1991',1,3,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1991',1,3,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1992',1,2,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1997',1,2,600,15,'SOME TEXT'); insert into uni_ids (ID,field,activity,frequence,field_1,field_2) values('N1995',1,8,600,15,'SOME TEXT');
Insofar as that I came up with this SQL that does not work as it should. It returns the other (do not duplicate) values as well...ID field activity frequence field_1 field_2 N1999 1 2 600 15 SOME TEXT N1999 1 2 600 15 SOME TEXT N1991 1 3 600 15 SOME TEXT N1991 1 3 600 15 SOME TEXT
If anyone can help please post solutionselect a.id, a.field, a.activity, a.frequence, a.field_1, a.field_2 from uni_ids a where a.rowid <> ( select max(b.rowid) from uni_ids b where a.id= b.id and a.field = b.field and a.activity = b.activity) ORDER BY a.id;
Thank you!Select
a.ID,
a.Field,
a.Activity,
a.FREQUENCE,
a.Field_1,
a.Field_2
of uni_ids one
where
(id, domain, activity, frequency, Champ_1, Champ_2) in
(select id
field
activity
frequency
Champ_1
Champ_2
of uni_ids
Group by domain, activity, frequency, Champ_1, id, Champ_2
having count (*) > 1); -
Returns all the duplicate values in object lookup (PHP, drop-down list)
Hi, I have a PHP page I designed as a search page. I have a number of drop-down lists that get their dynamic values from the fields in a MySQL database.
At present, if there are any entries that have duplicate values in a certain area, they are all listed, in the order of the index database. For example:
City:
Derby
Stoke
Stafford
Stoke
Derby
Derby
Stoke
etc...
Now, I want to do is be able to show all results for a given city. In the find what drop-down list box, I would than each of the cities to appear only once rather than every time it is registered. included in this, I would like the page of results to then display ALL results that match this search criteria.
Thus, in the example above, "Derby" appears only once, but when the user has selected 'Derby', it would return all three results in the results page.
My results page is built on a dynamic form, so I am confident that the results page would make it according to the needs. However, how can I get the drop-down list box to ask him?
> 'SELECT DISTINCT table1.champ1, table1.champ2, table1.champ3 FROM Table1 ";
Duplicate rows to remove the DISTINCT keyword strength SQL. In other words, that it will only return the unique combinations of fields in your selection list. If you examine your results set, you will see that each line is separate, although there may be duplicates in a particular area. Because you want to populate a drop-down list, you must include a field in your select list only, otherwise you get of the dupes.
-
Customize alert messages to check the duplicate value and alert success
Hi all
I want to show two alert against the button 'Submit' even at -.
1 the attention of messages to check the duplicate value and show the duplicate value found alert and
2 alert if successful the form's success to commit no duplicate values found.
I did all the thing but what alert-1 show and I pressed the ok button of the alert, then the second alert also shows that I don't want to show.
Who can I do about it? Have someone to help me!
ArifUse the folliwng in PRE-INSERT-TRIGGER.
There is not a lot of changes with the exception
where CANCELLATION_USERID =: CANCELLATION_USERID;
and
If valExists > 0 then
declare valExists number; begin select count(*) into valExists from USERDELETION where CANCELLATION_USERID = to_char(:CANCELLATION_USERID); if valExists > 0 then message('Duplicate value found !'); -- show_alert('ERROR_ALERT'); else message('All is well'); -- show_alert('All is well '); end if; end; -
Query generates duplicate values in successive lines. I can null out them?
I have had very good success (thanks to Andy) to obtain detailed responses to my questions posted, and I wonder if there is a way in a region report join query that produces lines with duplicate values, I cannot suppress (replace) printing of duplicate values in successive lines. In the event that I managed to turn the question into a mess unintelligible (one of my specialities), let me give an example:
We try institutions undergraduate that an applicant has participated in the list and display information on release dates, gpa and major (s) / according to decision-making. The problem is that there may be several major (s) / minor (s) for a given undergraduate institution, so the following is produced by the query:
Knox College hard 01/02 01/06 4,00 knitting
Knox College hard 01/02 01/06 4,00 cloth repair
Advanced University 02/06 01/08 3.75 Clothing Design
Really advanced U 02/08 01/09 4,00 sportswear
Really advanced U 02/08 01/09 4,00 basketball burlap
I want it to look like this:
Knox College hard 01/02 01/06 4,00 knitting
Tissue repair
Advanced University 02/06 01/08 3.75 Clothing Design
Really advanced U 02/08 01/09 4,00 sportswear
Burlap tennis shoe
* (Edit) Please note that the repair of fabric and lines tennis shoe repair should be positioned properly in a table, but unfortunately had space here for a reason suppresed any. *
Under the tuteage of Andy, I would say the answer is probably javascript one loop in the DOM, you are looking for the innerHTML of specific TDs in the table, but I want to confirm that, or Apex provides it a box I can check which will produce the same results? Thanks to the guy to advance and sorry for all the questions. We were charged to use Apex for our next project and learn it using it, as the training budget is non-existent this year. I love ;) unfunded mandates
Phil
Published by: Phil McDermott on August 13, 2009 09:34Hi Phil,
JavaScript is useful, because the feature break column in the report attributes (which would be my first choice if poss).
If you need to go beyond 3 columns, I would say something in the SQL statement itself. This means that the sort would probably have to be controlled, but it is doable.
This is a pretty old thread on the subject: Re: grouping reports (non-interactive) -with an example here: [http://htmldb.oracle.com/pls/otn/f?p=33642:112] (I used a custom template for the report, but you don't need to go that far!)
This uses the features of LAG in SQL to compare the values on line for values on the line before - ability to compare these values allows you to determine which ones to show or hide.
Andy
-
Hi guys of
How can I select only the duplicate values in a column? upward on the selection I'll be removing duplicates
Thank you
REDAHi reda,.
delete from table_name where rowid not in ( select min(rowid) from table_name group by column_name);Concerning
Peter -
How to set the minimum value of a graphic waveform window?
I have a graphics property of waveform "minimum value", but the graph is not take the value that I gave him. He tends to zero, as well as the first two sliders that I put on the graph. The maximum value "will be" no problem, just like the second slider value. Everyone knows about this problem? Here's a screenshot...
Is there a reason why my chart does not have what I have to say?
Thank you
Sometimes you may have problems if the new minimum is higher than the maximum of old. Try to write at least again in another node in property after you set the maximum value
Without seeing your VI and some parameters of the example, (old max and min) new max and min, it is otherwise difficult to say.
-
the variant attribute value - how fast it is?
Hello
There were days OR presentation on attributes of type variant. There are example saying that variant can be used to remove duplicates from table 1 d and this supposed to be a very quick solution. I did some tests and it seems that is not:

On the other hand the variant is very fast research once all atrubutes are implemented.

My question is how fast is being variant attributes and how this structure variant is allocated and stored in memory.
Excerpts from VI attached.
LabVIEW manages memory for you.
However, if you make too much reallocation of arrays of surfaces, you might run out of contiguous memory and thus running out of memory, memory fragmentation can cause problems.
-
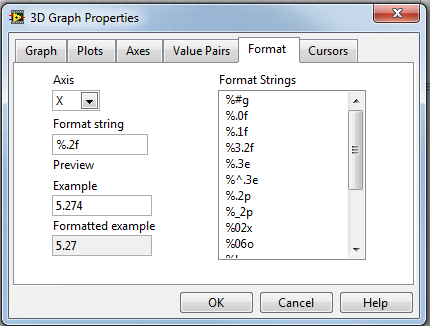
Hello
I was wondering what I can do for the z axis have visible values. The video is running OK but there is no value appear
on the z axis, only these zeros. Also the same thing happens on a graph of intensity connected to it. I would appreciate your help. Thank you!
Hi LambdaDigamma,
Are you sure that the z values are not being rounded up because of the display as a lower accuracy - IE 0.02 being rounded to 0.
If you right-click on the graphic bar and click on 'Properties of 3D-graphics', you can then Descent to the below tab and set the formatting options:
I hope this helps.
-
Masking of series that is null or 0 return values in the graphics in flash
Hello
I'm creating a bar chart stacked with several (about 15-20 series) series and some of the series return null/0 values, but they are always displayed on the table... It is not visually appealing because several series of null in a stacked chart values overlap between them... is there a way I can add a condition somewhere to hide these series that return null/0 values and not display them on the graph?
Any ideas?
Thanks for your help!Would check you closely because I thought showed no null values? Values null are not displayed. I found this useful once.
But in general it is visually unexpected when you, for example, a histogram 3D height zero bar. If you were made by hand, you leave a free space but omit the bar all together. I doubt that this can be done in a chart.They had to choose an interpretation. Zero average disappear or does it mean a zero graphic? I think that trace of zeros and nulls don't--what value would they draw?
If actually nulls are not displayed, you can preprocess the data changing zeros to nulls before plotting. But be aware that the entire column will probably disappear if all data for a label entries are zero. I'm sure that's what I lived. Fine if you want to.
In fact, I had several sets of data to draw: OC, given OO dat, data WR (3 sites, 4 points given per day) who well sort and I added a (0, null, null, null,) as a spacer between the columns of data.
Maybe someone knows something that can help.
Kind regards
Howard -
Hello
I am change the below query, the results that are returned contain duplicates.
For example the 'Customer' column contains the value "GBI-FELIX" 5 times.
I had a glance through the SQL and can not see any because of that. Can you see the problem?
Kind regardsselect to_char(sysdate, 'DD-Mon-YYYY HH24:MI:SS'), ol.client_id client, trunc(oh.ship_by_date) shipdate, nvl(sum(ol.qty_ordered),0) as orig_ord, nvl(sum(ol.qty_shipped),0) as shipped, nvl(sum(sm.smpicked),0) as unshipped, nvl(sum(held.qty_to_move),0) as held, nvl(sum(rel.qty_to_move),0) as reld, nvl(sum(mar.qty_to_move),0) as marsh, sum(ol.qty_ordered - (nvl(ol.qty_tasked,0) + nvl(ol.qty_shipped,0))) - nvl(sum(sm.smpicked),0) as unalloc, sum(ol.qty_ordered -(nvl(sm.smpicked,0) + nvl(ol.qty_shipped,0))) - nvl(sum(mar.qty_to_move),0) as topick from order_line ol, order_header oh, (select sum(qty_picked) as smpicked, client_id, order_id, line_id from shipping_manifest where shipped != 'Y' group by client_id, order_id, line_id) sm, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status != 'Consol' and status!= 'Released' and status!= 'In Progress' group by task_id, client_id, line_id) held, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status != 'Consol' and status != 'Hold' group by task_id, client_id, line_id) rel, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status = 'Consol' group by task_id, client_id, line_id) mar where ol.client_id = oh.client_id and ol.order_id = oh.order_id and ol.order_id = sm.order_id (+) and ol.client_id = sm.client_id (+) and ol.line_id = sm.line_id (+) and trunc(oh.ship_by_date) = $P{ship_by_date} and ol.order_id = held.task_id (+) and ol.client_id = held.client_id (+) and ol.line_id = held.line_id (+) and ol.order_id = rel.task_id (+) and ol.client_id = rel.client_id (+) and ol.line_id = rel.line_id (+) and ol.order_id = mar.task_id (+) and ol.client_id = mar.client_id (+) and ol.line_id = mar.line_id (+) and ol.sku_id not in (select sku_id from sku where product_group = 'WIP') and oh.consignment not like 'DAIRN%' and oh.client_id != 'DAIRNUNEAT' group by ol.client_id, ship_by_date UNION select to_char(sysdate, 'DD-Mon-YYYY HH24:MI:SS'), (select 'Total' from dual) client, trunc(oh.ship_by_date) shipdate, nvl(sum(ol.qty_ordered),0) as orig_ord, nvl(sum(ol.qty_shipped),0) as shipped, nvl(sum(sm.smpicked),0) as unshipped, nvl(sum(held.qty_to_move),0) as held, nvl(sum(rel.qty_to_move),0) as reld, nvl(sum(mar.qty_to_move),0) as marsh, sum(ol.qty_ordered - (nvl(ol.qty_tasked,0) + nvl(ol.qty_shipped,0))) - nvl(sum(sm.smpicked),0) as unalloc, sum(ol.qty_ordered - (nvl(sm.smpicked,0) + nvl(ol.qty_shipped,0))) - nvl(sum(mar.qty_to_move),0) as topick from order_line ol, order_header oh, (select sum(qty_picked) as smpicked, client_id, order_id, line_id from shipping_manifest where shipped != 'Y' group by client_id, order_id, line_id) sm, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status != 'Consol' and status != 'Released' and status != 'In Progress' group by task_id, client_id, line_id) held, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status != 'Consol' and status != 'Hold' group by task_id, client_id, line_id) rel, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status = 'Consol' group by task_id, client_id, line_id) mar where ol.client_id = oh.client_id and ol.order_id = oh.order_id and ol.order_id = sm.order_id (+) and ol.client_id = sm.client_id (+) and ol.line_id = sm.line_id (+) and ol.order_id = held.task_id (+) and ol.client_id = held.client_id (+) and ol.line_id = held.line_id (+) and ol.order_id = rel.task_id (+) and ol.client_id = rel.client_id (+) and ol.line_id = mar.line_id (+) and ol.order_id = mar.task_id (+) and ol.client_id = mar.client_id (+) and ol.line_id = rel.line_id (+) and ol.sku_id not in (select sku_id from sku where product_group = 'WIP') and oh.consignment not like 'DAIRN%' and trunc(oh.ship_by_date) = $P{ship_by_date} group by ship_by_date UNION select to_char(sysdate, 'DD-Mon-YYYY HH24:MI:SS'), (select '1FORZA WIP ' from dual) client, trunc(oh.ship_by_date) shipdate, nvl(sum(ol.qty_ordered),0) as orig_ord, nvl(sum(ol.qty_shipped),0) as shipped, nvl(sum(sm.smpicked),0) as unshipped, nvl(sum(held.qty_to_move),0) as held, nvl(sum(rel.qty_to_move),0) as reld, nvl(sum(mar.qty_to_move),0) as marsh, sum(ol.qty_ordered - (nvl(ol.qty_tasked,0) + nvl(ol.qty_shipped,0))) - nvl(sum(sm.smpicked),0) as unalloc, sum(ol.qty_ordered - (nvl(sm.smpicked,0) + nvl(ol.qty_shipped,0))) - nvl(sum(mar.qty_to_move),0) as topick from order_line ol, order_header oh, (select sum(qty_picked) as smpicked, client_id, order_id, line_id from shipping_manifest where shipped != 'Y' group by client_id, order_id, line_id) sm, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status != 'Consol' and status != 'Released' and status != 'In Progress' group by task_id, client_id, line_id) held, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status != 'Consol' and status != 'Hold' group by task_id, client_id, line_id) rel, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status = 'Consol' group by task_id, client_id, line_id) mar where ol.client_id = oh.client_id and ol.order_id = oh.order_id and ol.order_id = sm.order_id (+) and ol.client_id = sm.client_id (+) and ol.line_id = sm.line_id (+) and ol.order_id = held.task_id (+) and ol.client_id = held.client_id (+) and ol.line_id = held.line_id (+) and ol.order_id = rel.task_id (+) and ol.client_id = rel.client_id (+) and ol.line_id = mar.line_id (+) and ol.order_id = mar.task_id (+) and ol.client_id = mar.client_id (+) and ol.line_id = rel.line_id (+) and trunc(oh.ship_by_date) = $P{ship_by_date} and ol.sku_id in (select sku_id from sku where product_group = 'WIP') group by ship_by_date UNION select to_char(sysdate, 'DD-Mon-YYYY HH24:MI:SS'), (select 'DAIRNUNEAT' from dual) client, trunc(oh.ship_by_date) shipdate, nvl(sum(ol.qty_ordered),0) as orig_ord, nvl(sum(ol.qty_shipped),0) as shipped, nvl(sum(sm.smpicked),0) as unshipped, nvl(sum(held.qty_to_move),0) as held, nvl(sum(rel.qty_to_move),0) as reld, nvl(sum(mar.qty_to_move),0) as marsh, sum(ol.qty_ordered - (nvl(ol.qty_tasked,0) + nvl(ol.qty_shipped,0))) - nvl(sum(sm.smpicked),0) as unalloc, sum(ol.qty_ordered - (nvl(sm.smpicked,0) + nvl(ol.qty_shipped,0))) - nvl(sum(mar.qty_to_move),0) as topick from order_line ol, order_header oh, (select sum(qty_picked) as smpicked, client_id, order_id, line_id from shipping_manifest where shipped != 'Y' group by client_id, order_id, line_id) sm, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status != 'Consol' and status != 'Released' and status != 'In Progress' group by task_id, client_id, line_id) held, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status != 'Consol' and status != 'Hold' group by task_id, client_id, line_id) rel, (select sum(qty_to_move) qty_to_move, task_id, client_id, line_id from move_task where task_type = 'O' and status = 'Consol' group by task_id, client_id, line_id) mar where ol.client_id = oh.client_id and ol.order_id = oh.order_id and ol.order_id = sm.order_id (+) and ol.client_id = sm.client_id (+) and ol.line_id = sm.line_id (+) and ol.order_id = held.task_id (+) and ol.client_id = held.client_id (+) and ol.line_id = held.line_id (+) and ol.order_id = rel.task_id (+) and ol.client_id = rel.client_id (+) and ol.line_id = mar.line_id (+) and ol.order_id = mar.task_id (+) and ol.client_id = mar.client_id (+) and ol.line_id = rel.line_id (+) and trunc(oh.ship_by_date) = $P{ship_by_date} and oh.consignment like 'DAIRN%' group by ship_by_date
Sam.What block of union query results in duplicate is the first, 2nd, third or fourth? If you do not try running each query and see if you can find them.
Maybe you are looking for
-
Satellite A10 stops after 40 minutes
A-10 Pro keeps closing after 40 minutes, power source is always the head of HQ, can anyone help? Has been verified the following: -.VirusManagement - never switch on stopCooling fan seems to agree
-
I saved inadvertently a unfinished solitaire game and am now asked whenever I start solitaire to finish the game or start a new one. No matter what I do I can't get the quick deletion. How, once for all, delete the saved game.
-
Blurry pictures of Canon 70-300 mm IS USM
Recently, I bought a new 70-300 IS of Canon (not the white L). I was clicking famingoes and other waders. Used servo focus and another shot in with a wide aperture aperture priority mode. I was not too impressed by its 300 especially sharpness. Sharp
-
I'm trying to install the OS from USB but my bios not showing is not USB boot acer travelmate 4050.
-
I have a new computor with windows 7 is installed