Help conversion table...
Need help here some Labview... I'm stuck...
No need to...
Step 1 - Take a 1 d array with 4 index example: 0.153, 121, 249
Step 2 - convert the elements of the array in their 0 hexadecimal equivalent, 99, 79, F9
Step 3 - concatenate the array index 09979F9
Step 4 - convert the hexadecimal string to a decimal 10058233
Any suggestions?
Thank you
Aaron
OK, much simpler (at the bottom).  A first simplification would be to get rid of 'snacking' (Center). I don't know why you're doing it (above).
A first simplification would be to get rid of 'snacking' (Center). I don't know why you're doing it (above).
All outputs are the same.
Of course, the way the question was asked was a little difficult, describing a complicated four steps procedure when a step is really necessary.
(In the grand scheme of things, there will be complications such as the byte order.)

Yes, catalogued is powerful, but extremely stupid at the same time:
In a first approximation, it doesn't change the bits of memory resembles them differently.
Tags: NI Software
Similar Questions
-
Conversion Table helps with Note/caution
I'm almost finished my conversion table, but I'm having problems with two things: lists and notes/warnings. For simplicity and brevity, I'll discuss the lists in another post.
My < note > elements have an attribute of caution are simply formatted as a paragraph Level0. My conversion table looks like this:


I've looked at these for too long to be able to determine why the score is correctly convert paragraph tag, but the caution paragraph tag is just a paragraph.
TIA,
Marsha
Hi Marsha...
I think that the problem lies elsewhere... that seems essentially functional for me.
However, your TC: P: * maps look like they could cause problems, but not for what you describe (although this syntax isn't something I used so I could be all wet it).
Note that the default @type for
is "note", so there is no need to assign type = "note" a note regular... it's not bad, it is not necessary. See you soon,.
.. .Scott
-
Issues of conversion table: element
For example, in a table of conversion (FM12) an element must contain what might be in there? For example:
Question has)
E:head [H1], p +, (p | ul | ol |) GRAPHIC | Table | Anchor | E:section [S2]) * in the Section [S1] element.
In other words, included it 1 or more E:Section [S2] can itself contain an E:Section [S3], but the [S1] Section would not just outside the Section [S2]. So, should I include E:Section [S3] within the definition of Section [S1]?
==========
Issue B)
Also, I don't get specified TEXT anywhere in the samples, I look. TEXT must be in my conversion table?
Am I right that I should add my lists to the right, if I want lists to be valid in the Sections?
==========
Question C)
In addition, I understand that the following specifices 0 or more of the content items: E:Head [H1], p +, (p | ul | ol |) GRAPHIC | Table | Anchor | E:section [S2]) * in the Section [S1] item.
However, the reality is for E:Secton [S2] there must be two or more none (there can be only one). Then, the following text describes what I just said?
E:head [H1], p +, (p | ul | ol |) GRAPHIC | Table | Anchor | (E:Section [S2],E:Section[S2]+)) *
Thank you
Sean
Sean,
This can be complicated to address with simplicity (like language), but I'll take a shot at him.
-------------------------------------------------------------------------------
Question has)
E:head [H1], p +, (p | ul | ol |) GRAPHIC | Table | Anchor | E:section [S2]) * in the Section [S1] element.
In other words, included it 1 or more E:Section [S2] can itself contain an E:Section [S3], but the [S1] Section would not just outside the Section [S2]. So, should I include E:Section [S3] within the definition of Section [S1]?
RW: No. each rule as this specifies the child direct candidates only. You would have a separate line in your table in the Section [S2}, which indicates its respective candidates children (a which Section [S3].)] Similarly, Section [S3] would have its own line, etc.
----------------------------------------------------------------------------------
Issue B)
Also, I don't get specified TEXT anywhere in the samples, I look. TEXT must be in my conversion table?
Am I right that I should add my lists to the right, if I want lists to be valid in the Sections?
RW: no, by nature, a text node is locked to his current position, as a child of its current parent. Everywhere where parents who will, the child text node needs to go also. So no choice in the matter. Of course, however, the general rule in your EDD must allow text as long as it is necessary to maintain the validity.
Another explanation, imagine how a text node is displayed... usually by wrapping text in a component of character Beach, where there is additional text before and/or after the inside of the paragraph. The conversion table normally does this skin based on the character formats, then text nodes are just there and fixed.
-------------------------------------------------------------------------------
Question C)
In addition, I understand that the following specifices 0 or more of the content items: E:Head [H1], p +, (p | ul | ol |) GRAPHIC | Table | Anchor | E:section [S2]) * in the Section [S1] element.
However, the reality is for E:Secton [S2] there must be two or more none (there can be only one). Then, the following text describes what I just said?
E:head [H1], p +, (p | ul | ol |) GRAPHIC | Table | Anchor | (E:Section[S2],E:Section[S2]+)) *
RW: The logic seems wrong to me. I don't know exactly what your EDD or source file looks like this, but I think more in the sense of something like:
E:head [H1], p +, (p | ul | ol |) GRAPHIC | Table | Anchor) *, article [S2], article [S2] +.
Otherwise, you might get more
- , etc. after the sections. While we are on this issue, let me throw out some thoughts...
-You must decide if you try to apply strictly the structural rules here or simply to get the optimal structure applied. As a general rule, a rule of conversion table can be more lenient, so it may capture abnormalities that can be cleared up later using the validation of ESD. You come with additional consideration of another agreement, that an article must begin with a
I would usually use a simpler rule, such as:
E:head [H1], (p | ul | ol |) GRAPHIC | Table | Anchor) *, Section [S2] *.
It is perhaps more lenient than the structure that you intend to apply in your documents. But it is much more likely to get your most feasible initial structure from the beginning. During the cleanup after conversion, it is easier to correct a little lost
elements only to the rearrange a bunch of hierarchies section, everything simply because you were looking for perfection in the first passage.
-Once again, although not knowing your EDD, this jumps at me... by putting GRAPHICS, table and anchor in a single rule, this means they must be brothers and sisters. However, from previous conversations, I'm suspicious that they are not. In other words, I suspect that the anchor can be one parent to the other two. If so, this rule should be anchor only and it should be separate rules to push the GRAPHICS elements and table under anchor, then this rule simply has to pull on the anchor and children.
-------------------------------------------------------------------------------
I hope this helps!
Russ
-
Conversion table problem (FM unstructured for DITA, cannot create valid choicetable)
Hello
I'm trying to set up a table of FM migration to DITA. I was able to map most of my paintings on the table suuported in DITA style CLIENT access licenses, but I can not choicetables right.
My problem is the element specific FM for the body of the table.
It's my conversion table:

And that's what I get:

Where is my mistake? I tried several variants for fm-chbody, but the result is always the same.
Thanks for any help
Susanne
Susanne,
Two observations:
First, I tried your table of conversion to FM 10. As it is, I failed to the package body element. However, when I changed the first cell in the line fm-chbody to + TB:E:chrow or simply TB:chrow +, the element of body wrapped as expected.
Second, the Structure display you proposed shows that items in your results the fm-chheadrow and Charles are the two children of the tbody element. So, it seems that the two types of lines in your unstructured document appear as body lines. Applying a conversion of a document informal table cannot move content from a header to a body line line. Your fm-chheadrow rule only applies to lines in a table header and your fm-chbody rule applies only when all the lines in the body of the table are mapped to the Charles. Try to move the first line of your table to a header row and see what happens.
Good luck.
-Lynne
-
FDK - apply document Conversion table
Hello
I want to be able to apply a conversion to an open document table, through an FDK.
Is it possible to call the command "Structure current document...". "the client and pass a filepath, open the document Conversion table, and that applies to the current document?
I want to be able to pass the path to the command automatically without displaying the dialog box.
I appreciate any help!
Thanks in advance,
KFN
Hi David,
Yes. It is in the chapter of the FDK ref called "Call Clients shipped with FrameMaker." The table of conversion process is done by another client API called generator of Structure, and you will need to make calls to it. However, in the last ref FDK I, I think that the syntax in the documentation is wrong. I'll copy and paste parts of the device below, replacing it with the syntax that I know works. Note that you must have all documents open with their identity papers seized... you can't just send a path.
To perform most operations with customers of FrameMaker, you perform a sequence of several
Calls F_ApiCallClient().To structure a document, use the following sequence of calls from F_ApiCallClient():
F_ApiCallClient ("Structure Generator", "INPUTDOCID objectID");
.. .or objectID is the ID of the input document.F_ApiCallClient ("Structure Generator", "RULEDOCID objectID");
.. .or objectID is the ID of the document table rule (conversion).F_ApiCallClient ("Structure Generator", "OUTPUTDOCNAME path");
.. where path is the full path of the output document. This command is optional. If you do
not specify a path, the leaves of the unsaved document structure generator and open.F_ApiCallClient ("Structure Generator", "StructureDoc");
... This call tells the structure generator to generate the structure using the parameters provided by the
calls listed above.KFN, is again Russ. Thus, for example, to make the call where send you the number of the document that you want to the structure, you would do something like:
UCharT msg [1024];
F_ObjHandleT docId.
... code for docId, etc...
F_Sprintf (msg, "%d INPUTDOCID", docId);
F_ApiCallClient ("Structure Generator", msg (StringT));
... rest of calls, etc...
I hope this helps.
Russ
-
How to apply the Conversion Table of file FM.
I have a conversion table generated for a group of files that I am trying to structure. I want to be able to apply the conversion with Extendscript table. The script that I have does not save any file converted. I don't know why is it not save the file. I was under the impression that the "Structure Generator" should create the new file. If this incorrect.
Here is the code I am using.
var myFile = File.openDialog ("Select File to Convert"); var myCT = File.openDialog ("Select ConversionTable"); var CT = openFile (myCT.fsName, 0); applyConversionTable (myFile.fsName, CT) closeFile (CT); function applyConversionTable(fileName, CT){ var doc= openFile (fileName, 0); var name = fileName.replace(/[\w\.]+$/,"test.fm") CallClient("Structure Generator", "InputDocId " + doc.id); CallClient("Structure Generator", "RuleDocId " + CT.id); CallClient("Structure Generator", "OutputDocName " + name); CallClient("Structure Generator", "GenerateDoc"); closeFile (doc); } function openFile( fileName, visible){ var i = 0; var doc = 0; var openParams = GetOpenDefaultParams(); var retParams = new PropVals(); i = GetPropIndex(openParams, Constants.FS_AlertUserAboutFailure); openParams[i].propVal.ival = false; i = GetPropIndex(openParams, Constants.FS_MakeVisible); openParams[i].propVal.ival = visible; i = GetPropIndex(openParams, Constants.FS_FileIsOldVersion); openParams[i].propVal.ival = Constants.FV_DoOK; i = GetPropIndex(openParams, Constants.FS_FileIsInUse); openParams[i].propVal.ival = Constants.FV_ResetLockAndContinue; i = GetPropIndex(openParams, Constants.FS_FontChangedMetric); openParams[i].propVal.ival = Constants.FV_DoOK; i = GetPropIndex(openParams, Constants.FS_FontNotFoundInCatalog); openParams[i].propVal.ival = Constants.FV_DoOK; i = GetPropIndex(openParams, Constants.FS_FontNotFoundInDoc); openParams[i].propVal.ival = Constants.FV_DoOK; i = GetPropIndex(openParams, Constants.FS_RefFileNotFound); openParams[i].propVal.ival = Constants.FV_AllowAllRefFilesUnFindable; doc = Open(fileName, openParams, retParams); if (doc.ObjectValid() ===1){ doc.openedByScript = true; } else{ PrintOpenStatus(retParams); } return doc } function closeFile(doc){ Constants.FF_CLOSE_MODIFIED = 1; var res = doc.Close(Constants.FF_CLOSE_MODIFIED); }Ah, found the problem. I noticed this earlier, but do not think that it was important, it apparently. The other arguments must be all uppercase. Like this:
CallClient ("Generator of Structure", "INPUTDOCID" + doc.id); CallClient ("Structure Generator", "RULEDOCID" + CT.id); CallClient ("Generator of Structure", "OUTPUTDOCNAME" + name); CallClient ("Structure Generator", "StructureDoc"); I tested it and it works for me. FWIW, I think that it is a poor quality of a client API feature otherwise very slippery.
Russ
-
Conversion table, EDD, manage multiple formats table
Hello! I'm quite new to structured framemaker and I plan to migrate legacy documentation not structured in XML format. In documentation existing as well as ordinary tables I Note and warning messages in a table:

The icon is a paragraph with a frame higher TFP. format and table shading
When I generate a conversion table, framemaker creates that one set of items for the table cells, rows, etc. I'm a little confused about how to deal with these tables in the table of conversion and ESD file so that I can save the converted to XML file, then load it and get the same table format? I would appreciate any advice. Thank you!
Elektroneg,
It is always tempting to start a new project structured FM by converting existing documents. I recommend, however, that, until you are familiar with the structure, you start by building a structured model and ESD and take a good start on them debugging with the test data. Once you have created a catalog of the element, it will give you a target for a table of conversion and implementation of an XML application.
A table structured FM must have the elements on each side of the table: the entire table, any title of table, any position table, the body of the table, a table leg, all ranks, and each cell. Each of these item types can be used for one purpose. You cannot, for example, have a general element called TableSection which is used for the header, body and foot or an element called title, which is used for the section headings, but also the titles table. However, you can have several elements of each of these types.
A DSP defines all the elements for the tables and the various components of the table, including the command of no subitem. It can also define an initial table format the format applied when the table is created and the initial models that specify the names of the line items in a topic of table, foot or body, and those of the cells of each type of line. Note that these are the original formats and models of structure only.
In your case, for example, you can set a table format called Message with the shaded background desired. If the note and Attention messages have different icons, you can define two elements of the array, called Note, and called Attention. The body of a Note might be called NoteBody, and the only line of a NoteBody might be NoteRow. The two cells in a NoteRow could be called NoteIcon and MessageText and may contain paragraphs which forms have the same name as these elements. Tables of attention would be defined by analogy.
To generate a table of conversion that structure this content, remember that any table generated by FM conversion is only a starting point. The project creates the FM does not define several the table header, body, foot, line or cell elements. You can change the conversion table to do this. For example, the part of your grade conversion table will be something like:
Wrap this object or objects This element of
With this qualifier TC: P:NoteIcon
NoteIcon TC: P:MessageText MessageText TR:NoteIcon, MessageText NoteRow TB:NoteRow NoteBody T:NoteBody NoteTable This conversion table fragment defines a table cell that contains a NoteIcon paragraph labeled as a part of NoteIcon, a cell with a paragraph containing the MessageText tag to be a MessageText, a line containing an element tag NoteIcon followed a MessageText marked to be a NoteRow, a table containing a single element tag NoteRow to be a NoteBody , and a table composed only a NoteBody be labeled NoteTable.
-Lynne
-
ORA-02374: error loading conversion table / ORA-12899: value too large for column
Hi all.
Yesterday I got a dump of a database that I don't have access and Production is not under my administration. This release was delivered to me because it was necessary to update a database of development with some new records of the Production tables.
The Production database has NLS_CHARACTERSET = WE8ISO8859P1 and development database a NLS_CHARACTERSET = AL32UTF8 and it must be in that CHARACTER set because of the Application requirements.
During the import of this discharge, two tables you have a problem with ORA-02374 and ORA-12899. The results were that six records failed because of this conversion problem. I list the errors below in this thread.
Read the note ID 1922020.1 (import and insert with ORA-12899 questions: value too large for column) I could see that Oracle gives an alternative and a workaround that is to create a file .sql with content metadata and then modifying the columns that you have the problem with the TANK, instead of BYTE value. So, as a result of the document, I done the workaround and generated a discharge .sql file. Read the contents of the file after completing the import that I saw that the columns were already in the CHAR value.
Does anyone have an alternative workaround for these cases? Because I can't change the CHARACTER set of the database the database of development and Production, and is not a good idea to keep these missing documents.
Errors received import the dump: (the two columns listed below are VARCHAR2 (4000))
ORA-02374: error loading «PPM» conversion table "" KNTA_SAVED_SEARCH_FILTERS ".
ORA-12899: value too large for column FILTER_HIDDEN_VALUE (real: 3929, maximum: 4000)
"ORA-02372: row data: FILTER_HIDDEN_VALUE: 5.93.44667. (NET. (UNO) - NET BI. UNO - Ambiente tests '
. . imported "PPM". "' KNTA_SAVED_SEARCH_FILTERS ' 5,492 MB 42221 42225-offline
ORA-02374: error loading «PPM» conversion table "" KDSH_DATA_SOURCES_NLS ".
ORA-12899: value too large for column BASE_FROM_CLAUSE (real: 3988, maximum: 4000)
ORA-02372: row data: BASE_FROM_CLAUSE: 0 X '46524F4D20706D5F70726F6A6563747320700A494E4E455220 '.
. . imported "PPM". "' KDSH_DATA_SOURCES_NLS ' lines 229 of the 230 308.4 KB
Thank you very much
Bruno Palma
Even with the semantics of TANK, the bytes for a column VARCHAR2 max length is 4000 (pre 12 c)
OLA Yehia makes reference to the support doc that explains your options - but essentially, in this case with a VARCHAR2 (4000), you need either to lose data or change your data type of VARCHAR2 (4000) to CLOB.
Suggest you read the note.
-
Conversion tables and the entries in the table
I'm working on a conversion table for our former products of FM unstructured to DITA. I understand the basic concepts, but I'm having a problem with the table cells.
I have P:CellBody in my conversion table, in the first row, mapped at the entrance with a cellbody qualifier.
I also TC mapped at the entrance.
The same applies to P:CellHeading, and Th.
Therefore, my text is wrapped in two input elements. The context tab to show the item says:
entry
entry
line
TBODY
tgroup
Table
body
NoName
NoName
I'm sure it should be the same as above with the input only one element (and of course with the fixed NoNames which I think I know how to do; I just have not had here yet).
How to avoid get my cells wrapped in two input elements?
Thanks in advance,
Marsha
Marsha,
I don't understand what you're trying to do, or what is exactly in your conversion table. Be aware, however, that FrameMaker will always create elements for the basic elements that occur in your tables. The table of conversion that you give little control of how these items will be marked, but not question whether elements will exist.
If your conversion table contains lines such as:
P:CellBody entry cellbody TC: entry You will get the nested input elements. External is the cell of the table itself and inside is the paragraph. FrameMaker does not have a valid document to use the tag of the element itself to a cell and a container, so aside from the results is not what you wanted, they are not correct in FrameMaker.
If your table cells contain simple paragraphs and you don't want the elements for cells and paragraphs, your conversion table didn't even need to mention paragraph CellBody and CellHeading tags. Indeed, if your table formats using CellBody as paragraph format for cells in the body of a table and CellHeading as the paragraph format for the cells in the table, your ESD header didn't even apply the paragraph formats.
Another alternative is to include a paragraph tag in a table row of conversion for a table cell by combining TC: and P: to match table cells containing such paragraphs. For example:
TC: P:CellBody entry creates items named cell entry of table cells containing paragraphs tag CellBody. The paragraph in such a cell is not encapsulated in an extra element.
One final note is that TH: in a conversion table refers to the position of the entire table. his children are header lines. The analogue of table of TH body: to:, not TC.:
-Lynne
-
Add multiple attributes to the element via the conversion table?
Hello...
I'm sure I know the answer to this question, but am looking for validation.
Is it possible to add multiple values of the attribute to an element using a conversion table? Table following conversion creates the < some-elem > element with the attribute @attrname to "attrval"... but what happens if I wanted to put two attributes? I tried this... Some-elem [attrname = "attrval"] [otherattrname = "attrval2"]... but the second definition is ignored. Is it possible to do (with conversion tables)?
Wrap this object This element of With this qualifier P: some-para-tag Some-elem [attrname = "attrval"] Thank you!
.. .Scott
Scott,
The structured reference apps said to separate assignments of two attribute with an ampersand, as in
Some-elem [atttrname = "attrval" & otherattrname = "attrval2"]
I've never done, so it is not tested.
Van
-
Conversion table of Partition Non-Partition and vice versa
Hello
I followed the method of Partition to Partition and vice versa conversion table below. Please suggest is here
any other altrnative methods available to accomplish the same thing.
Conversion table of partition table partitions. Export data, drop the table, create the table with partitions and
import data into the same table, now, the data is organized with Partitions.
Conversion table of partition table non-partition. Export data, drop the table, create the table without partitions and
import data into the same table, now, the data are organized without Partitions.
Thank you.Google "oracle Exchange partition".
-
Conversion table of varying Dynamics
I tried to convert a number of 2D, dynamically assigned tables to VARIANTS in order to generate a plot of parametric Surface 3D ActiveX. Unfortunately, the CA_VariantSet2DArray function has problems with this. If I understand the question, a translation to the VARIANT cannot be completed if non-contiguous memory is passed into the function. I AM able to pass arrays statically defined in the CA_VariantSet2DArray function and generate my very well 3D parametric Surface plot. In the end, however, table sizes that will be Wescott may vary each time the user the parcel data. Given that the size info is not known at compile time, I can't define static arrays.
I saw a few people who have asked similar questions in these forums in the past, but there seems to be no solution. Is there an a way in which the varrient conversion functions can be used with dynamically created tables? Is there some sort or work-arround? I tried defining a very large static arrays and then using only a part of them because the CA_VariantSet2DArray requires the dimensions of the matrix as input. Let us, the unused portions of static arrays are always copied in the VARIANT and bad data are thus drawn to the plot of 3D parametric Surface.
Any help would be GREATLY appreciated! Thank you!!
Here is a snippet of my code simplfied:
-----------------------------------------------------------------
IT DOES NOT WORK...
-----------------------------------------------------------------
XVt VARIANT, yVt, zVt;
nRows = 40;
Matches = 39;
float * xVals.
float * yVals;float * zval;
int row, col;
xVals = (Char *) malloc (nRows * sizeof(float *));
yVals = (Char *) malloc (nRows * sizeof(float *));
ZVAL = (Char *) malloc (nRows * sizeof(float *));
for (row = 0; row)< nrows;="">{
xVals [Online] = (Char *) malloc (matches * sizeof (float));
yVals [Online] = (Char *) malloc (matches * sizeof (float));
ZVAL [line] = (Char *) malloc (matches * sizeof (float));
}for (row = 0; row)< nrows;="">
{
for (col = 0; col< ncols;="">
{xVals [Online] [column] = 0;
yVals [Online] [column] = 0;
ZVAL [row] [column] = 0;}
}
Valid values plot copied in yVals, xVals, zVals here.
CA_VariantSet2DArray (& xVt, CAVT_FLOAT, nRows, matches, xVals);
CA_VariantSet2DArray (& yVt, CAVT_FLOAT, nRows, matches, yVals);
CA_VariantSet2DArray (& zVt, CAVT_FLOAT, nRows, matches, zval);CW3DGraphLib__DCWGraph3DPlot3DParametricSurface (surfGraphHndl, NULL, xVt, yVt, zVt, CA_DEFAULT_VAL);
-----------------------------------------------------------------
IT DOES NOT WORK...
-----------------------------------------------------------------
XVt VARIANT, yVt, zVt;
nRows = 40;
Matches = 39;
float * xVals.
float * yVals;float * zval;
float xtemp [40] [39];
float ytemp [40] [39];
float ztemp [40] [39];int row, col;
xVals = (Char *) malloc (nRows * sizeof(float *));
yVals = (Char *) malloc (nRows * sizeof(float *));
ZVAL = (Char *) malloc (nRows * sizeof(float *));
for (row = 0; row)< nrows;="">{
xVals [Online] = (Char *) malloc (matches * sizeof (float));
yVals [Online] = (Char *) malloc (matches * sizeof (float));
ZVAL [line] = (Char *) malloc (matches * sizeof (float));
}for (row = 0; row)< nrows;="">
{
for (col = 0; col< ncols;="">
{xVals [Online] [column] = 0;
yVals [Online] [column] = 0;
ZVAL [row] [column] = 0;}
}
Valid values plot copied in yVals, xVals, zVals here.
for (row = 0; row)< nrows;="">
{
for (col = 0; col< ncols;="">
{
XTemp [row] [column] is xVals [row] [column];.
[Online] ytemp [column] = yVals [row] [column];
[Online] ztemp [column] = zval [row] [column];
}
}
CA_VariantSet2DArray (& xVt, CAVT_FLOAT, nRows, matches, xtemp);
CA_VariantSet2DArray (& yVt, CAVT_FLOAT, nRows, matches, ytemp);
CA_VariantSet2DArray (& zVt, CAVT_FLOAT, nRows, matches, ztemp);CW3DGraphLib__DCWGraph3DPlot3DParametricSurface (surfGraphHndl, NULL, xVt, yVt, zVt, CA_DEFAULT_VAL);
You must allocate a block of memory for each table, something like:
VARIANT xVt, yVt, zVt; nRows = 40; nCols = 39; float *xVals; float *yVals; float *zVals; int row, col; xVals = (float *) malloc(nCols * nRows * sizeof(float)); yVals = (float *) malloc(nCols * nRows * sizeof(float)); zVals = (float *) malloc(nCols * nRows * sizeof(float)); for(row = 0; row < nRows; row++) { for(col = 0; col < nCols; col++) { xVals[nCols*row + col] = 0; yVals[nCols*row + col] = 0; zVals[nCols*row + col] = 0; } } // Valid plot values copied into xVals, yVals, and zVals here. CA_VariantSet2DArray(&xVt, CAVT_FLOAT, nRows, nCols, xVals); CA_VariantSet2DArray(&yVt, CAVT_FLOAT, nRows, nCols, yVals); CA_VariantSet2DArray(&zVt, CAVT_FLOAT, nRows, nCols, zVals); CW3DGraphLib__DCWGraph3DPlot3DParametricSurface (surfGraphHndl, NULL, xVt, yVt, zVt, CA_DEFAULT_VAL); -
Problem Word document with table conversion table of contents
Hello
I use MS Word 2003 and Acrobat 9 in Windows 7 Ultimate 64 bit.
I created the manual using Word, I put position (s) with 3 levels deep and created the table of contents in Word.
It seems as expected. There are titles, subtitles and subtle (3rd level).Table of contents in Word works very well. No problem.
In the PDFMaker options on the Bookmarks tab, I put 1 TOC with 3 levels.
However, after you convert the entire document in PDF, bookmarks seem very strange.They contain only the titles (no subtitles at all), each bookmarked line ends with some number 3, 4 or 5 that I have not idea what it is and these bollmarks point to page table of contents no to the page, they should have.

What is the problem and how can I fix it?Thank you
JAS
Added:
I have read a lot of posts with similar problems and tried all of the suggestions posted.
I tried:1.
Reinstalling Adobe (by removing all of the related files), well I don't have any older versions (and facilities) of Acrobat in this computer.
2.In Adobe PDFMaker uncheck the option "enable accessibility and...» »
3.
Set up printer to Adobe PDF
4.
In Word > parameters-OCD I ticked the option "use hyperlinks instead of page numbers.
I also tried in Adobe PDFMaker use not FAKE, but to use 'convert Word headings to bookmarks.
The result was horrible. Double bookmarks, reverse a lot of bookmarks empty and level 1 level 2 positions (I think that created by blank lines in the charts on the pages).
Please note that by using the same word headings create TOC without any problem!
The only plus side was that some of these bookmarks came with correct links.
These bokkmarks were created using "New bookmarks from structure" option in Acrobat (after conversion of the document)
/JAS
I recommend that you look at this blog. It guides you through the steps.
http://blogs.Adobe.com/acrolaw/2011/03/ensuring-that-Word-TOCs-create-hyperlinks-in-Acroba t.
I hope this helps!
-
Hey guys,.
IM extracting data from a database and store it as a cluster of tables 1 d and now I want to find an element in a table using the table. After completing the two individual tables I try and seek help search 1 d table comparing to a fourth value has already generated. I was hoping to use the index of table 1 d search to enter something at this level since the other table.
Table im trying to look for a currently a single element, the element im trying to find, but I get a - 1 return.
can you see what I'm doing wrong here? is there something I don't understand not all table 1 d search?
Thank you guys
A common problem here is white space (spaces, tabs, and newline characters, etc.). Try to use Whitespace Trim on the search string and the elements of the array before the search.
-
Please help, insert table 1 d 2d array
Hello
I'm trying to insert a line of table 1 d in table 2d, but it must be placed in the index as the starting point.
For example, line 1, column 2. = starting point.
I already wrote the program, but the result is not that I want to.
As shown in the picture, a number of 6 in. (0.2), it must be placed in a yellow highlight.Please help and guide me.
Hey fatty,
using shift registers:

It is perhaps a good idea to include some range checks, because it is not possible to replace the non-existing items...







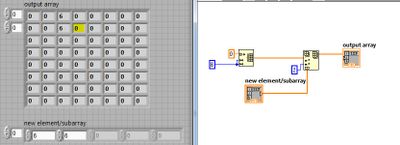
Maybe you are looking for
-
emails have disappeared, the folders and messages count rest
I have a server osx 10.7.5. Oddly enough, one of my customer emails has disappeared... The e-mail address still exists, well, the folder structure still exists. If I connect to email via [Server] / webmail email folder structure is complete and that
-
I try to use DAQ5133 to collect the waveforms. Then fft (soft) with the waveform and a more in-depth analysis. I view the waveforms and the results of the whole analysis and found that the results of the analysis behind much. Then I found 5133 seems
-
HP mini 110: how to reset the BIOS password HP 110 mini
Hello! I forgot what was the password on my BIOS, now, whenever I turned on my laptop it goes to the mode "Enter password" before loading its OS. Pls help product: HP mini 110 S/N: [personal information] P/N: VA715UA #ABA Thank you
-
How can I activate the output sound
The speakers I plugged in the job just fine so I know it's not that. It is a parameter which must be applied and I'm not sure exactly what steps to follow to activate the audio output
-
BlackBerry Smartphones support videos from YouTube
loading YouTube videos is not my Bold 9900: error "content not available. Server is blocked or unresponsive. What should do?