How to capture multiple line String using regular expressions?
Hello
I have a simple program like this:
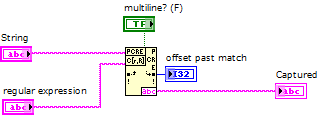
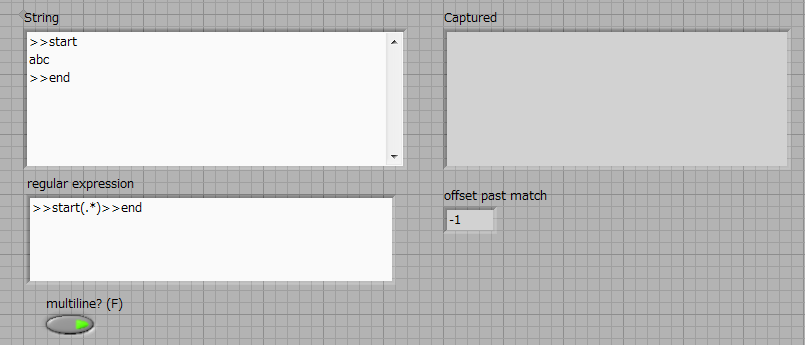
What I want to accomplish is to capture everything between > start and > to end with a single regular expression matching node. It seems that the definition of multiples? true or False does not help.
I'm using LabVIEW 2012.
If it is impossible to capture using a single node, that's fine. But I want to assure you that I can make full use of this node without combining several others.
Thank you!
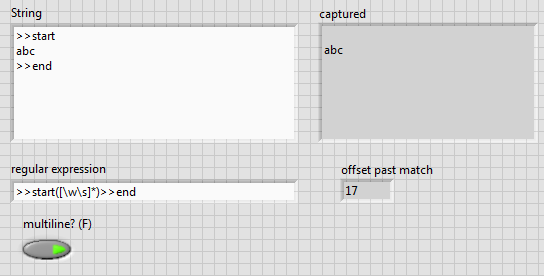
> start([\w\s]*) > end
A point matches any character except line break characters. You have two of them.
Tags: NI Software
Similar Questions
-
Changeparticular the characters of a string using regular expressions...
Hi all
I'm writing a function using the function of expression regular oracles REGEXP_REPLACE but I could not succeed until now.
My problem is as follows, I have a text in a column say "Scott Sdfdfs Sdfd" I want to replace all the s and S with X characters and make the text looks like "XdfXdf XdfdfX Xdfd".
It is possible by using regular expressions in oracle?
Can you give me some clue?
Thank youselect regexp_replace('sdfsdf Sdfdfs Sdfd', 's|S', 'X') Replaced from dual;REPLACED ------------------ XdfXdf XdfdfX Xdfd -
Operation of string using regular expressions
SQL> with raw_data as 2 ( 3 select 1 id ,'A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR A11' str from dual union all 4 select 2,'A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR' str from dual union all 5 select 3,'A11P75 P76 R01 U01 U12 U40 U42 V53 VL A11 VR' str from dual union all 6 select 4,'A11P75 P76 R01 U01 U12 U40 U42 V53 A11 VL VR' str from dual union all 7 select 5,'P75 P76 R01 A11 U01 U12 U40 A11 U42 V53 VL VR ' str from dual 8 ) 9 select id 10 ,str 11 ,case when instr(replace(substr(str,instr(str,' ',-1,3)),'A11','#'),'#')>1 12 then replace(str,' A11','') 13 else str 14 end Expected 15 from raw_data 16 / ID STR EXPECTED ---------- --------------------------------------------------- --------------------------------------------------- 1 A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR A11 A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR 2 A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR 3 A11P75 P76 R01 U01 U12 U40 U42 V53 VL A11 VR A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR 4 A11P75 P76 R01 U01 U12 U40 U42 V53 A11 VL VR A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR 5 P75 P76 R01 A11 U01 U12 U40 A11 U42 V53 VL VR P75 P76 R01 A11 U01 U12 U40 A11 U42 V53 VL VR SQL>
Logic of waiting: there will be a WORD like here "A11" who is looking within the chain
If this word found in the last three words separated by space, delete this letter as a guide / appearing in the column PROVIDED
First of all, your solution will not delete words A11 but instead of words that begin with A11:
with raw_data as)
Select the 1 id, str "A11P75 P76 R01 U01 A11MIDDLE U40 U42 V53 VL VR A11FAKE' of the double
)
SELECT id,
Str,
-case when instr (replace (substr (str, instr (str,' ', - 1, 3)), "A11", "#"), "#") > 1
then replace (str, 'A11', ")
of another str
End expected
of raw_data
/
ID STR EXPECTED
---------- ------------------------------------------------------------ -----------------------------------------------------
1 A11P75 P76 R01, U01 A11MIDDLE U40-U42 V53 A11FAKE A11P75 P76 R01 U01MIDDLE U40-U42 V53 VRFAKE VL VL RVSQL >
In any case, something like:
with raw_data as)
Select the 1 id, str "A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR A11' Union double all the
Select 2, str "A11P75 P76 R01 U01 U12 U40 U42 V53 VL VR' Union double all the
Select 3, str "A11P75 P76 R01 U01 U12 U40 U42 V53 VL A11 VR' Union double all the
Select option 4, str "A11P75 P76 R01 U01 U12 U40 U42 V53 A11 VL VR' Union double all the
Select 5, str "P75 P76 R01 A11 U01 U12 U40 A11 U42 V53 VL VR" of double
)
SELECT id,
Str,
case
Where regexp_like (str,'(^ |) (\s+))A11(\s+\w+){2}$) ')
then regexp_replace (str '(^ |) (\s+))A11((\s+\w+){2}$)','\3) ')
Where regexp_like (str,'(^ |) (\s+))\w+\s+A11\s+\w+$) ')
then regexp_replace (str,'((^ |))) (\s+))\w+\s+)A11\s+(\w+)$','\1\4) ')
Where regexp_like (str,'(^ |) (\s+))\w+\s+\w+\s+a11$) ')
then regexp_replace (str,'((^ |))) (\s+))\w+\s+\w+)\s+a11$','\1) ')
of another str
End expected
of raw_data
/
ID EXPECTED STR
---------- --------------------------------------------------- ---------------------------------------------------
1 A11P75 P76 R01, U01 U12 U40-U42 V53 VR A11 A11P75 P76 R01, U01 U12 U40-U42 V53 RV VL VL
A11P75 2 P76 R01, U01 U12 U40-U42 V53 A11P75 P76 R01, U01 U12 U40-U42 V53 RV VL VL RV
3 A11P75 P76 R01, U01 U12 U40-U42 V53 VL A11 A11P75 P76 R01, U01 U12 U40-U42 V53 VL VR VR
A11P75 4 P76 R01, U01 U12 U40-U42 V53 A11 VL A11P75 P76 R01, U01 U12 U40-U42 V53 VL VR VR
5 P75 P76 R01 A11 U01 U12 U40 A11 U42 V53 RV VL R01 A11 U01 U12 U40-U42 V53 VL VR A11 P76 P75SQL >
SY.
-
Manipulating strings using regular expressions
Hello guys,.
I stuck in a situation in which I want to extract specific data from a column of the table.
Here are the values for a particular column in which I want to ignore the values as well as support in the support and who are as .pdf, .doc.
TRIS (dibenzylideneacetone) dipalladium (0) 451CDHA.pdf
AM57001A (ASRM549CDH). DOC
Identity sulfate AM23021A (project)
PG-1183. E.2 (0.25 mg CTF)
AS149656A (DEV APPL AERO WHT PROVENTIL HFA)
Report on the stability (ISR) annex.2 semi-solid form (internal information)
TSE(batch#USLF000332)-242CDH, Lancaster synthesis.pdf
Additive TR3018520A 1 (REF 3018520)
AM10311A Particle size airjet by sieving (constant sieving) (project)
ASE00099B additive (REF E000099) mesh 90
Palladium AM37101_312-99 (Z11c) by DCP.doc
PS21001A_1H - NMR.doc (PN 332-00)
AM68311A (Q - a CP 33021.02) attachment
Attachment AM68202-1 has (BioReliance No. 02.102006)
I want below output to above the values for the column
Trisdipalladium451CDHA
AM57001A
Identity AM23021A sulfate
PG-1183. E.2
...
..
.
Thanks in advance
Like this?
SQL> with t 2 as 3 ( 4 select 'Tris(dibenzylideneacetone)dipalladium (0) 451CDHA.pdf' str from dual 5 union all 6 select 'AM57001A(ASRM549CDH).DOC' str from dual 7 union all 8 select 'AM23021A Identity of sulfate (draft)' str from dual 9 union all 10 select 'PG-1183.E.2 (0.25 mg FCT)' str from dual 11 union all 12 select 'AS149656A (DEV AERO APPL HFA WHT PROVENTIL)' str from dual 13 union all 14 select 'Stability report (RSR) Annex2 semi-solid form (internal information)' str from dual 15 union all 16 select 'TSE(Batch#USLF000332)-242CDH, Lancaster synthesis.pdf' str from dual 17 union all 18 select 'TR3018520A Addendum 1 (PN 3018520)' str from dual 19 union all 20 select 'AM10311A Particle size air-jet sieving (constant sieving) (draft)' str from dual 21 union all 22 select 'ASE00099B Addendum (PN E000099) 90 mesh' str from dual 23 union all 24 select 'AM37101_312-99 (Z11c) Palladium by DCP.doc' str from dual 25 union all 26 select 'PS21001A_1H-NMR.doc (PN 332-00)' str from dual 27 union all 28 select 'AM68311A (Q-One CP 33021.02) Attachment' str from dual 29 union all 30 select 'AM68202-1A (BioReliance no. 02.102006) Attachment' str from dual 31 ) 32 select str 33 , regexp_replace(str, '(\([^)]+\))|(\..{3})') str_new 34 from t; STR STR_NEW---------------------------------------------------------------------- --------------------------------------Tris(dibenzylideneacetone)dipalladium (0) 451CDHA.pdf Trisdipalladium 451CDHAAM57001A(ASRM549CDH).DOC AM57001AAM23021A Identity of sulfate (draft) AM23021A Identity of sulfatePG-1183.E.2 (0.25 mg FCT) PG-1183AS149656A (DEV AERO APPL HFA WHT PROVENTIL) AS149656AStability report (RSR) Annex2 semi-solid form (internal information) Stability report Annex2 semi-solid formTSE(Batch#USLF000332)-242CDH, Lancaster synthesis.pdf TSE-242CDH, Lancaster synthesisTR3018520A Addendum 1 (PN 3018520) TR3018520A Addendum 1AM10311A Particle size air-jet sieving (constant sieving) (draft) AM10311A Particle size air-jet sievingASE00099B Addendum (PN E000099) 90 mesh ASE00099B Addendum 90 meshAM37101_312-99 (Z11c) Palladium by DCP.doc AM37101_312-99 Palladium by DCPPS21001A_1H-NMR.doc (PN 332-00) PS21001A_1H-NMRAM68311A (Q-One CP 33021.02) Attachment AM68311A AttachmentAM68202-1A (BioReliance no. 02.102006) Attachment AM68202-1A Attachment 14 rows selected. -
Chips with 3 delimiter characters using regular expressions
Hello world
I have a function that is able to mark the input in a collection string using regular expressions.
In case the input string is a character such as the comma or semicolon delimiter,
We can just get the result we want like the example below.
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production PL/SQL Release 11.2.0.1.0 - Production CORE 11.2.0.1.0 Production TNS for 64-bit Windows: Version 11.2.0.1.0 - Production NLSRTL Version 11.2.0.1.0 - Production
SQL> with tab1 as ( 2 select 'abc,dfg,h,,1234' as col1 from dual 3 ) 4 select regexp_substr(col1, '([^,]*)(,|$)', 1, level, 'i', 1) as result 5 from tab1 6 connect by level <= regexp_count(col1, ',')+1; RESULT --------------- abc dfg h 1234
But in the case where the channel of entry has 2 types of delimiter and each delimiter consists of 3 characters as below
I wonder if it is possible to get the result as below.
The input string: 01| ^ | ABCD| ^ | 111| * | 02| ^ | efgh| ^ | 222
Separators: | * | is divided into lines, | ^ | is divided into columns
Expected result:
col1 col2 col3
Row1 - > 01 abcd 111
row2-> efgh 02 222
Simply put, take a next
The input string: 01| ^ | ABCD |^| 111 |*| 02 |^| efgh |^| 222
Separator: | * |
Result:
01. ^ | ABCD | ^ | 111
02. ^ | efgh | ^ | 222
How can I achieve this using regular expressions?
Kind regards
Euntaek
You need to know the number of the column from the outset:
with tab1 as)
Select ' 01 | ^ | ABCD | ^ | 111. * | 02. ^ | efgh | ^ | 222' as double col1
)
Select rownum,
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 1, null, 1) col1,.
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 2, null, 1) col2.
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 3, null, 1) col3
of tab1
connect by level<= regexp_count(col1,'\|\*\|')="" +="">
/
ROWNUM COL1 COL2 COL3
---------- ----- ----- -----
1 01 abcd 111
2 efgh 02 222
SQL >
SY.
-
How to insert multiple lines using a single query
Hi all
How to insert multiple lines using a single query to the emp table?
I have the number of rows to insert into table x. consumes a lot of time. I tried to insert several lines using a single query, but get errors. I know exactly the query to do this.
Thank you
SunilLike this?
SQL> create table test(id number , dt date); Table created. SQL> insert into test values(&a,&b); Enter value for a: 1 --- It asked me and I entered 1 Enter value for b: sysdate --- It asked me and I entered sysdate old 1: insert into test values(&a,&b) new 1: insert into test values(1,sysdate) 1 row created. SQL>g.
-
How to add multiple lines when the button is clicked
How to add multiple lines when the click on button now is just add a row .plz give me idea how... waiting for answer
/ public final class screen extends MyScreen
{
/**
* Creates a new object of MyScreen
*/
ObjectChoiceField obj1 obj2, obj3, obj4.
Table of String() = {'101 ', ' 102'};
String of shadow [] = {"Shade1", "Shade2"};
Rolls of string [] = {'101 ', ' 102'};
String cutting [] = {"100-150", "150-200"};
Chain of selectedindex1, selectedindex2, selectedindex3, selectedindex4;
LabelField lbl1 lbl2, lbl3, lbl4;
GFM LinedGridFieldManager;
HFM HorizontalFieldManager, hfm1, hfm2 hfm3;
VerticalFieldManager vfmMain;
public MyScreen()
{
Set the displayed title of the screen
hfm1 = new HorizontalFieldManager (HorizontalFieldManager.NO_VERTICAL_SCROLL |) HorizontalFieldManager.NO_VERTICAL_SCROLLBAR);
hfm2 = new HorizontalFieldManager (HorizontalFieldManager.NO_VERTICAL_SCROLL |) HorizontalFieldManager.NO_VERTICAL_SCROLLBAR);
hfm3 = new HorizontalFieldManager (HorizontalFieldManager.NO_VERTICAL_SCROLL |) HorizontalFieldManager.NO_VERTICAL_SCROLLBAR);
HFM = new HorizontalFieldManager (HorizontalFieldManager.FIELD_RIGHT);
vfmMain = new VerticalFieldManager (Manager.NO_VERTICAL_SCROLL |) Manager.NO_HORIZONTAL_SCROLLBAR);
obj1 = new ObjectChoiceField ("", graph, 0, FIELD_LEFT);
obj2 = new ObjectChoiceField ("", blind, 0, FIELD_LEFT);
Obj3 = new ObjectChoiceField ("", rolls, 0, FIELD_LEFT);
Obj4 = new ObjectChoiceField ("", cuts, 0, FIELD_LEFT);
LBL1 = new LabelField("");
LBL2 = new LabelField("");
lbl3 = new LabelField("");
lbl4 = new LabelField("");
ButtonField btnAdd = new ButtonField ("ADD", FIELD_RIGHT);
GFM = new LinedGridFieldManager (4, LinedGridFieldManager.VERTICAL_SCROLL);
hfm1.setMargin (20, 0, 10, 0);
hfm1. Add (new LabelField ("Chart"));
hfm1. Add (obj1);
hfm1. Add (new LabelField ("Shade"));
hfm1. Add (obj2);
hfm2. Add (new LabelField ("Rolls"));
hfm2. Add (Obj3);
hfm2. Add (new LabelField ("Cuts"));
hfm2. Add (Obj4);
HFM. Add (btnAdd);
GFM. Add (new LabelField ("Chart"));
GFM. Add (new LabelField ("Shade"));
GFM. Add (new LabelField ("Rolls"));
GFM. Add (new LabelField ("Cuts"));
vfmMain.add (hfm1);
vfmMain.add (hfm2);
vfmMain.add (hfm3);
vfmMain.add (hfm);
vfmMain.add (new SeparatorField());
vfmMain.add (gfm);
Add (vfmMain);
btnAdd.setChangeListener (new FieldChangeListener()
{
' Public Sub fieldChanged (field field, int context) {}
TODO self-generating method stub
selectedindex1 = chart [obj1.getSelectedIndex ()];
selectedindex2 = shade [obj2.getSelectedIndex ()];
selectedindex3 = rolls [obj3.getSelectedIndex ()];
selectedindex4 = cuts [obj4.getSelectedIndex ()];
While (LBL1. GetText(). Equals("") | LBL2. GetText(). Equals("") | lbl3. GetText(). Equals("") | lbl4. GetText(). Equals(""))
{
LBL1. SetText (selectedindex1);
LBL2. SetText (selectedindex2);
lbl3. SetText (selectedindex3);
lbl4. SetText (selectedindex4);
GFM. Add (LBL1);
GFM. Add (LBL2);
GFM. Add (lbl3);
GFM. Add (lbl4);
}
}
});
}
}Hi Piya,
I run your code, and according to your logic that it works correctly.
It's adding that line only once because according to your logic that one line can be added to MDT, if you do not want to add line on each click on the button, follow these steps:
selectedindex1 = chart [obj1.getSelectedIndex ()];
selectedindex2 = shade [obj2.getSelectedIndex ()];
selectedindex3 = rolls [obj3.getSelectedIndex ()];
selectedindex4 = cuts [obj4.getSelectedIndex ()];Lbl1 LabelField = new LabelField("");
Lbl2 LabelField = new LabelField("");
LabelField lbl3 = new LabelField("");
LabelField lbl4 = new LabelField("");
If (LBL1. GetText(). Equals("") | LBL2. GetText(). Equals("") | lbl3. GetText(). Equals("") | lbl4. GetText(). Equals(""))
{
LBL1. SetText (selectedindex1);
LBL2. SetText (selectedindex2);
lbl3. SetText (selectedindex3);
lbl4. SetText (selectedindex4);
GFM. Add (LBL1);
GFM. Add (LBL2);
GFM. Add (lbl3);
GFM. Add (lbl4);
} -
String format using regular expressions
Input string output format... SELECT q'<select ab_c "ABC", efg "EFG" from dual>' str FROM DUAL Output: STR ------------------------------------- select ab_c "ABC", efg "EFG" from dual Required output format using regular expression... STR ------------------------------------- select 'ab_c' "ABC", 'efg' "EFG" from dualRegular expressions have many limitations as tools of analysis, and you specify the rules you want. This expression puts quotation marks around a non-empty string before a quoted string:
SELECT regexp_replace(q' -
One for the era: how to get this output using REGULAR EXPRESSIONS?
How to get the bottom of output using REGULAR EXPRESSIONS?
Published by: user12240205 on June 18, 2012 03:19SQL> ed Wrote file afiedt.buf 1* CREATE TABLE cus___addresses (full_address VARCHAR2(200 BYTE)) SQL> / Table created. SQL> PROMPT Address Format is: House #/Housename, street, City, Zip Code, COUNTRY House #/Housename, street, City, Zip Code, COUNTRY SQL> INSERT INTO cus___addresses VALUES('1, 3rd street, Lansing, MI 49001, USA'); 1 row created. SQL> INSERT INTO cus___addresses VALUES('3B, fifth street, Clinton, OK 74103, USA'); 1 row created. SQL> INSERT INTO cus___addresses VALUES('Rose Villa, Stanton Grove, Murray, TN 37183, USA'); 1 row created. SQL> SELECT * FROM cus___addresses; FULL_ADDRESS ---------------------------------------------------------------------------------------------------- 1, 3rd street, Lansing, MI 49001, USA 3B, fifth street, Clinton, OK 74103, USA Rose Villa, Stanton Grove, Murray, TN 37183, USA SQL> The REG EXP query shouLd output the ZIP codes: i.e. 49001, 74103, 37183 in 3 rows./* Formatted on 2012/06/18 17:25 (Formatter Plus v4.8.8) */ SELECT REGEXP_SUBSTR ((REGEXP_SUBSTR (full_address, '[^,]+', 1, 4)), '[[:digit:]]+') RESULT FROM cus___addresses -
How to extract the value of a tag XML using regular Expressions
We get a response XML from a WEB SERVICE.
I convert it to VARCHAR2.
Now, I want to get the real answer that is inside the tag of the response.
I tried this:
DECLARE
V_1 VARCHAR2 (30000): = ' < soap: Body > < ns:ProcessArgusFeedsResponse xmlns:ns = "urn: PegaRULES:SOAP:ArgusToPegaFeeds:Services" > ' |
'< response > good < / answer >< / ns:ProcessArgusFeedsResponse > < / soap: Body > ';
v_response VARCHAR2 (100);
BEGIN
DBMS_OUTPUT. PUT_LINE (V_1);
v_response: = REGEXP_SUBSTR (v_1, ' / < >(.+?) < \/Response > answer /');
dbms_output.put_line (v_response);
END;
It does not work.
Any help would be greatly appreicated.
Hello
user12240205 wrote:
We get a response XML from a WEB SERVICE.
I convert it to VARCHAR2.
Why? XML has its own native ways of analysis; Why not use them?
If you use regular expressions, then REGEXP_REPLACE, as shown above, is a good option in Oracle 10, but starting in Oracle 11.1, you can use REGEXP_SUBSTR like this:
REGEXP_SUBSTR (v_1
, '
(.+?) '1
1
NULL
1
)
The 6th argument is like a backreference; "He tells REGEXP_SUBSTR did not return to the entire organization, but only the part inside the 1st left '(' et correspondant à sa droite).
The '?' to make it non-greedy is necessary only if v_1 can contain more than one response.
Now, I want to get the real answer that is inside the tag of the response.
I tried this:
DECLARE
V_1 VARCHAR2 (30000): = "
'
Good v_response VARCHAR2 (100);
BEGIN
DBMS_OUTPUT. PUT_LINE (V_1);
v_response: = REGEXP_SUBSTR (v_1, ' /
(. +?)) <\ esponse="">/'); dbms_output.put_line (v_response);
END;
It does not work.
That's because it's looking for a slash ("/") before the '
' tag and another after the ' tag.The backslash ("\") is not necessary here, but it is not nothing wrong.
-
Find the words (wild cards) using regular expressions
I'm testing to see if the words are present for revision 1 of a drawing of the cartridge.
The script search the digit 1 followed by a date, a title, and 4 sets of initials.
The number 1 is static, (date, title and original are the cards that they are different for each design).
I use regular expressions to match the words.
The regular expression highlighted in blue is the number 1 and the date.
Him remains highlighted in orange does not match the title and initials.
If anyone can help with the regular expression that is most appreciated.
Once I got that work will add the form fields for the initials, noting only the console at this point for the tests.
numWords = this.getPageNumWords (0);
number of words on the page
loop through the words on the page
for (var j = 0; j < numWords-1; j ++)
{/ / get the pair of words to test}
ckWords = this.getPageNthWord (0, j) + ' ' + this.getPageNthWord (0, j + 1); test words
Check if 1 26.05.16 THE STRENGTHENING REVISED MM SB AE GM word string is present
If (ckWords.match(/ ^ 1\s [0-9] {1,2}.)) [0-9] {1,2}. [0-9] {2} \s\w+(\s+\w+){1,7}/))
{
Console.println (ckWords);
}
}
You can use something like this:
ckWords = this.getPageNthWord (0, j) + ' ' + this.getPageNthWord (j, 0, + 1) + ' ' + this.getPageNthWord (0, + 2 j) + ' ' + this.getPageNthWord (0, j + 3) + ' ' + this.getPageNthWord (0, j + 4) + ' ' + this.getPageNthWord (0, j + 5) + ' ' + this.getPageNthWord (0, j + 6);
If (! ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} \.\d {2} \s\w+ (?:-s + \w +) {1.8} \s([A-Z]{2})\s([A-Z]{2})-s ([A - Z] {2}) \s([A-Z]{2})$ /)) ckWords + ckWords + "" + this.getPageNthWord (0, j + 7);
If (! ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} \.\d {2} \s\w+ (?:-s + \w +) {1.8} \s([A-Z]{2})\s([A-Z]{2})-s ([A - Z] {2}) \s([A-Z]{2})$ /)) ckWords + ckWords + "" + this.getPageNthWord (0, j + 8);
If (ckWords.match (/ ^ 1\s\d {1,2} \.\d {1,2} {2} \s\w+ \.\d (?:-s + \w +) 1.8 ([A - Z] {2}) \s([A-Z]{2})\s([A-Z]{2})\s {} \s([A-Z]{2})$ /))
{
...
-
A special character validation using regular expressions in ADF
Hi guys,.
I want to put the validation of a special as character (,.') ((en) &, -) using regular expressions.
I asked the posting as [a-zA-Z0-9'(.),--/ &] but it does not work properly.
Special characters should be like:
Comma,
Hyfan-
Dot.
Open and close braces (and).
Ampercent &
Apastrophy '
Space ""
Please help if anyone has idea.
And I also tried to put under expression as...
[a-zA-Z] + (\\s* [0-9] * [a-zA-Z] *-* & * \\(*\\) *, *'*. *) * [a-zA-Z0-9] + but we need the validation if we put special characters between the charater as "ab," chain "& (bc).
his does not work if I put a special character at the beginning and the end of the string in the ADF
Thanks Timo...
its working fine...
-
How to format a value by using reg expression
Please, I need to format a value using regular expressions.
Result9911223344, 9911223344 9911223344 11223344
Some tips on how I can do this?(99) 1122-3344, (99) 1122-3344 (99) 1122-3344 1122-3344
Kind regardsHello
You were close.
The first 2 digits are optional, so add a '?' in the model.
This means that you will get results like ' ((1122-3344'), so use REPLACE to get rid of unwanted brackets.SELECT REPLACE ( REGEXP_REPLACE ( val , '(\d{2})?' -- ? added here || '(\d{4})(\d{4})' , '(\1) \2-\3' ) , '() ' ) AS formatted_val FROM t ;This assumes that "()" does not happen in the raw val. If so, use the REGEXP_REPLACE calls; a search of numbers with eactly 8 digits and the other looking for numbers with exactly 10 digits.
-
Using Regular Expressions in the Code of edge
Hello.
I am quite new to the Edge Code but find it quite interesting to use.
The find/replace feature is pretty but I got a little confused on how to use regular expression matching.
I tried to clean up the coordinates of a file Adobe Edge animate full of 120.17px (heavy and less accurate)
So basically you're looking \d+\.\d+px
First of all, she says "use /re/ for regex" even though I know the Code is made for developers who * courses * know that it took me a little time to understand I should just put my regex between slashes.
/\d+\.\d+PX/
then the time comes to replace them. ALT-cmd-F and it says "replace".
Puzzled again.
Will I type my full sentence there? Maybe a «...» "written up somewhere around would avoid this question because, there, of course, a second field to come.
And there, I got stuck.
I can not find how to get the replacement of the model.
tried to \1 $1 \1/ $1 / nothing seems to work... any hint of welcome.
Franck,
You are right that it does not work. I open a topic. Here is the link if you want to follow: https://github.com/adobe/brackets/issues/1861
FYI, I know exactly how you want to replace the search results, but here are a few tips:
You must set the text that you want to retrieve by using parentheses. Thus, for example, if you want the integer part of the number of the result, then your regexp would be: / (\d+)\.\d+px/
Then you must specify the first result using $1, so (when it's fixed), you can use something like: $1px
Thank you
Randy
-
Using regular expressions to solve sys_refcursor of a record
Regarding my Question about sys_refcursor with record type of thread, I thought it can be solved differently. It is:
I have a string like ' 8:1706, 1194, 1817 ~ 1:1217, 1613, 1215, 1250'
I need to do a few things using regular expressions and get something like
Is it possible by using regular expressions in a single select statement?select * from <table> where c1 in (8,1) and c2 in (1706,1194,1817,1217,1613,1215,1250);Hello
Game 6' - 8 "wrote:
Your understanding is quite correct. But unfortunately it doesn't Frank.SQL> SELECT COUNT (*) 2 FROM (SELECT sp.* 3 FROM spml sp, spml_assignment spag 4 WHERE sp.spml_id = spag.spml_id 5 AND spag.class_of_svc_id = 8 6 AND spag.service_type_id IN (1706, 1194, 1817) 7 AND spag.carrier_id = 4445 8 AND NVL (spag.haulage_type_id, -1) = NVL (NULL, -1) 9 AND spag.effdate = TO_DATE ('01/01/2000', 'mm/dd/yyyy') 10 AND spag.unit_id = 5 11 AND sales_org_id = 1 12 UNION ALL 13 SELECT sp.* 14 FROM spml sp, spml_assignment spag 15 WHERE sp.spml_id = spag.spml_id 16 AND spag.class_of_svc_id = 1 17 AND spag.service_type_id IN (1217, 1613, 1215, 1250) 18 AND spag.carrier_id = 4445 19 AND NVL (spag.haulage_type_id, -1) = NVL (NULL, -1) 20 AND spag.effdate = TO_DATE ('01/01/2000', 'mm/dd/yyyy') 21 AND spag.unit_id = 5 22 AND sales_org_id = 1); COUNT(*) ---------- 88 SQL> SELECT COUNT (*) 2 FROM spml sp, spml_assignment spag 3 WHERE sp.spml_id = spag.spml_id 4 AND spag.carrier_id = 4445 5 AND NVL (spag.haulage_type_id, -1) = NVL (NULL, -1) 6 AND spag.effdate = TO_DATE ('01/01/2000', 'mm/dd/yyyy') 7 AND spag.unit_id = 5 8 AND sales_org_id = 1 9 AND REGEXP_LIKE ('8:1706,1194,1817~1:1217,1613,1215,1250', 10 '(^|~)' || spag.class_of_svc_id || ':' 11 ) 12 AND REGEXP_LIKE ('8:1706,1194,1817~1:1217,1613,1215,1250', 13 '(:|,)' || spag.service_type_id || '(,|$)' 14 ); COUNT(*) ---------- 140 SQL>Published by: release 6' - 8 "August 11, 2009 20:04
Serving what you ordered!
Originally, you said that you are looking for something that produces the same result as
where c1 in (8, 1) and c2 in (1706, 1194, 1817, 1217, 1613, 1215, 1250)in other words, the c1s could be coupled with any of the c2s.
Now, it seems that what you want iswhere ( c1 = 8 and c2 IN (1706, 1194, 1817) ) or ( c1 = 1 and c2 IN (1217, 1613, 1215, 1250) )in other words, c1 = 8 and c2 = 1250 is not good; is not c1 = 1 and c2 = 1706.
In this case, try
WHERE REGEXP_LIKE ( s , '(^|~)' || c1 || ':([0-9]+,)*' || c2 || '(,|~|$)' )
Maybe you are looking for
-
Firefox started crashing on startup this morning (23 oct), reset does not help
Since this morning (October 23), Firefox crashes at startup. Also, it crashes in safe mode. After the reset, Firefox has started once. At the next startup, Firefox crashed again and the same problem reapppeared. I have several submitted incident repo
-
Z40 cursor disappeared and the touchpad no longer works
Laptop was left on when I went to continue working. Connected again with no problems. The cursor appears but not move not initially and finally slowly disappeared. Tried the touchpad, but it does not work. Managed to get the touchpad settings with th
-
change email on vista by default
IM used to use win xp and for the life of me cannot figure out how to make my default mail my yahoo as on xp if anyone can help with this, I would be very gratefull (im not the most computer-oriented person)
-
How to disconnect from the Mail application built into Windows 8 Pro
I think that this old question / thread has been neglected (closed) and went without a good answer. Citing the answer of the moderator of this thread." Hey jayRads, There is no concept sign in email and applications on the Preview version of consumer
-
Photosmart HPC4680 cannot print... abandoned leow
I bought via recovery HP photosmart C4680. It can make copies, but cannot receive command to print from my laptop. My laptop is using Vista Home Premium. I also tried with my more old laptop that runs on XP... same miserable result. I have a new HP m