Min/max number of conclusion in a selected range of dates - Please HELP!
Hi all
I'm not very advanced at complex formulas however using this forum in recent weeks thanks to everyone here, I was able to create the automated collection of amazing data workbook. I searched for the last missing piece, and according to two explanations I've found here so far, that they are too complex for me to understand yet what I am eager to realize I thought was pretty simple.
If anyone can help me with the formula to be used in these empty boxes, it will make my week!
FYI, I use a mac look that is all to date.
Thank you.

Until there is an update to mac OS Sierra and new formula to exceed the numbers had worked for me. What is more, so I'm looking for the same answer on the new numbers. Take a look at the formula below and maybe it will give you an idea
SUMIF (table 1: $1: $1, ">" & EOMONTH(A1,0) will GET (DATE ($A2, $ 1.1 M), 0), table 1: $VP)
Tags: iWork
Similar Questions
-
Cannot return number of orders by the hour in the request please help
Here's the query I run currently. It allows you to select the Date and time on a form and returns a total number of commands between the Date and the selected hours. What I need to break further down, at the time, the number of orders. So it should take the 05:00 06/08/2012-06/08/2012 11:00 show me the number of orders at the time. Where currently it totals orders for the chosen duration
This query currently works but does not divide it by time unless I select the 05:00 06/08/2012-06/08/2012 06:00 and then repeat for each hour. Which is very time consuming.
Any help would be amazing as I have been at it for weeks.
SELECT
ENTITIES OF ROUND (SUM (COUNTWEIGHT)), AREA OF Z.NAME
Of
PPSDBA. ARCH_RX RX,
PPSDBA. ARCH_VIAL_CONTENTS STROKE,
PPSDBA. ZONE Z,
(SELECT 1 / COUNT (RX.) TOTE_ORDER_ID COUNTWEIGHT), RX. TOTE_ORDER_ID ORDER NO.
OF PPSDBA. ARCH_RX RX,
PPSDBA. ARCH_VIAL_CONTENTS STROKE,
PPSDBA. ARCH_VIAL AV
WHERE AV RX_ID = RX. RX_ID AND
STROKE. VIAL_ID = BC VIAL_ID AND
RX. FILLED_TYPE NOT IN (19.20) and
STROKE. FILL_DATE BETWEEN TO_DATE('#DATE_FROM#', 'MM/DD/YYYY hh24:mi') AND TO_DATE (' #DATE_TO # "," MM/DD/YYYY HH24 ')
RX GROUP. SUBQUERY TOTE_ORDER_ID),
PPSDBA. ARCH_VIAL AV
WHERE
SUBQUERY. ORDERID = RX. TOTE_ORDER_ID AND
AV. RX_ID = RX. RX_ID AND
RX. FILLED_TYPE = Z.ZONE_ID AND
STROKE. VIAL_ID = BC VIAL_ID AND
RX. FILLED_TYPE NOT IN (19.20) and
STROKE. FILL_DATE BETWEEN TO_DATE('#DATE_FROM#', 'MM/DD/YYYY hh24:mi') AND TO_DATE (' #DATE_TO # "," MM/DD/YYYY HH24 ')
Z.NAME GROUPThis will probably work. I can't test it because I don't have the tables:
SELECT
TRUNC (STROKE. FILL_DATE, 'HH') FILL_DATE_HOUR,.
ENTITIES OF ROUND (SUM (COUNTWEIGHT)), AREA OF Z.NAME
Of
PPSDBA. ARCH_RX RX,
PPSDBA. ARCH_VIAL_CONTENTS STROKE,
PPSDBA. ZONE Z,
(SELECT 1 / COUNT (RX.) TOTE_ORDER_ID COUNTWEIGHT), RX. TOTE_ORDER_ID ORDER NO.
OF PPSDBA. ARCH_RX RX,
PPSDBA. ARCH_VIAL_CONTENTS STROKE,
PPSDBA. ARCH_VIAL AV
WHERE AV RX_ID = RX. RX_ID AND
STROKE. VIAL_ID = BC VIAL_ID AND
RX. FILLED_TYPE NOT IN (19.20) and
STROKE. FILL_DATE BETWEEN TO_DATE('#DATE_FROM#', 'MM/DD/YYYY hh24:mi') AND TO_DATE (' #DATE_TO # "," MM/DD/YYYY HH24 ')
RX GROUP. SUBQUERY TOTE_ORDER_ID),
PPSDBA. ARCH_VIAL AV
WHERE
SUBQUERY. ORDERID = RX. TOTE_ORDER_ID AND
AV. RX_ID = RX. RX_ID AND
RX. FILLED_TYPE = Z.ZONE_ID AND
STROKE. VIAL_ID = BC VIAL_ID AND
RX. FILLED_TYPE NOT IN (19.20) and
STROKE. FILL_DATE BETWEEN TO_DATE('#DATE_FROM#', 'MM/DD/YYYY hh24:mi') AND TO_DATE (' #DATE_TO # "," MM/DD/YYYY HH24 ')
Z.NAME GROUP, , TRUNC (STROKE. FILL_DATE, 'HH') -
Get the date range min/max for consecutive events.
Hi all...
I am fairly new to the programming of the DB and is working on some examples I picked up a few places. The database version is 10g R2.
I would like to configure the data here and I can explain my requirement.
create table table_1 (product_id varchar2(25), region_id number, event_id number event_date date, event_status number(1)) /
Now the data because it is->
insert into table_1 values ('Prod-1',10, null, to_date('01-feb-2014','dd-mon-yyyy'),null) / insert into table_1 values('Prod-1',10, 1001, to_date('10-mar-2014','dd-mon-yyyy'), 1) / insert into table_1 values('Prod-1',10, 1001, to_date('20-mar-2014','dd-mon-yyyy'), 3) / insert into table_1 values('Prod-1',10,1002, to_date('01-apr-2014','dd-mon-yyyy'), 1) / insert into table_1 values('Prod-1',10, 1002, to_date('10-apr-2014','dd-mon-yyyy'), 3) / commit /If the table now contains the following data
select * from table_1;
PRODUCT_ID REGION_ID EVENT ID EVENT_DAT EVENT_STATUS
------------------------- ---------- -------- --------- ------------
Prod-1 10 1 February 14
Prod-1 10 1001 10 March 14 1
Prod-1 10 1001 20 March 14 3
Prod-1 10 1002 1 April 14 1
Prod-1 10 1002 April 10, 14 3
Now, the condition is as follows:
Above is the dates start and end for the tests on a product in a given region. The event_status column indicates the dates of beginning and end. Event_status = 1, for the date of beginning and the event_status = 3 of the end date.
A new event is now coming from March 21 and ending on March 31.
The power required is a product identifier / region; If there are events that are ending and then count the days, for example, 1001 to end on March 20, but now the new event begins on 21 March... and the new event ends on 31 March and event 1002 begins 01 - Apr... and so on.
The output required for this is as follows:
PRODUCT_ID REGION_ID EVENT_MIN_DATE EVENT_MAX_DATE
------------------------- ---------- -------------- --------------
Prod-1 10 10 14 March 10 April 14
The output should give a product identifier / region, when events are immediately after the other, out the min date of beginning and end of max for all these manifestations of "back to back".
Now I wrote the code for this, but it goes into a purely 'loop' for application in PLSQL... But my head tells me that if the results are correct. the PLSQL implementation is not the most efficient and effective way.
Can someone help me to form the query? I tried to use functions analytical min/max but it gives me the start and end dates back even if my events are not "back to back" or previous/succeed each other... so my query result is not quite correct.
Am reading on the TYPE clause but would be grateful if someone could help me with this query... or any other form better to implement this event so PLSQL can be used. The database version is 10g R2.
Thank you
K
PS - The number of such events back to back is limited to 4 and the events could be created in any order. But if someone could help me with the scenario above; am sure I could make a request addressed to any change in the order. :-)
No this isn't a recursive with clause, perhaps the UNION ALL you got confused. She will work with 10g.
Since there are 2 tables that you said, the block all_data brings together only the lines of the two tables. table_1 start_date and end_date are built from the event_status (where the max in group by).
-
I'm currently doing tests on Oracle, Postgres and MySQL.
However, Oracle returns me "ORA-00934: Group feature is not allowed here" the same query works with others.
The idea is to return first, Min, Max, last prices for one day on a particular ID.
I tried to use HAVING and pass the query to the place WHERE but no luck.SELECT quotes.id, min(quotes.received_time) as opening_time, (SELECT ask_price FROM "price_quotes" WHERE id=quotes.id AND received_time >=timestamp'2012-12-10 00:00:00' AND received_time < timestamp'2012-12-11 00:00:00' AND received_time=min(quotes.received_time) ) AS opening_price, (SELECT received_time FROM "price_quotes" WHERE received_time >=timestamp'2012-12-10 00:00:00' AND received_time < timestamp'2012-12-11 00:00:00' AND id=quotes.id and ask_price=min(quotes.ask_price) LIMIT 1) as min_price_time, min(quotes.ask_price) as min_price, max(quotes.received_time) as closing_time, (SELECT ask_price FROM "price_quotes" WHERE id=quotes.id AND received_time >=timestamp'2012-12-10 00:00:00' AND received_time < timestamp'2012-12-11 00:00:00' AND received_time=max(quotes.received_time)) as closing_price, (SELECT received_time FROM "price_quotes" WHERE received_time >=timestamp'2012-12-10 00:00:00' AND received_time < timestamp'2012-12-11 00:00:00' AND id=quotes.id and ask_price=max(quotes.ask_price) LIMIT 1) as max_price_time, max(quotes.ask_price) as max_price FROM "price_quotes" quotes WHERE quotes.received_time >= timestamp'2012-12-10 00:00:00' and quotes.received_time < timestamp'2012-12-11 00:00:00' AND quotes.id = 668792 GROUP BY quotes.id ORDER BY quotes.id ;
This is the Create Table:
Sample data:CREATE TABLE "price_quotes" ( id number(8), received_time timestamp, mid_price float, bid_price float, ask_price float, mid_yield float, bid_yield float, ask_yield float, mid_spread float, bid_spread float, ask_spread float, product_id number(8), product_yield float, PRIMARY KEY ( id , received_time ) );
Oracle: 11.2.0.1.0INSERT INTO "price_quotes" VALUES ( 668792, timestamp'2012-12-10 08:00:00', 103, 120, 110, 7, 8, 9, 2.100, 3.050, 4.28999, 29, 1.050); INSERT INTO "price_quotes" VALUES ( 668792, timestamp'2012-12-10 10:00:00', 99, 98, 100, 4, 2, 3, 0.100, 0.050, 0.28999, 24, 0.050); INSERT INTO "price_quotes" VALUES ( 668792, timestamp'2012-12-10 16:00:00', 100, 99, 101, 5, 3, 4, 0.200, 0.100, 0.29999, 25, 0.100); INSERT INTO "price_quotes" VALUES ( 668792, timestamp'2012-12-10 17:00:00', 10, 9, 11, 1, 2, 3, 0.210, 0.330, 0.99, 15, 1.100);
Published by: 986853 on February 7, 2013 12:23Hello
986853 wrote:
Thanks for the info, I have edited and corrected the post.Thank you.
Be sure to post the results desired from these sample data.This is the Create Table:
CREATE TABLE "price_quotes" ( id number(8), received_time timestamp, ...In Oracle, the names of table in double - quotes are a huge pain.
In addition, if you do not need to register the fractions of a second, use DATEs instead of TIMESTAMPs. They are more effective, and there are a lot more built-in features for dealing with DATEs.
Of course, if you're trying to minimize the differences between the databases, which may influence your decision.Here are the results you want from the given sample data?
` OPENING OPENING MIN_ CLOSING CLOSING MAX_PRICE MAX_ ID _TIME _PRICE PRICE _TIME _PRICE _TIME PRICE ------- ---------- ------- ----- ---------- ------- ---------- ----- 668792 10-DEC-12 110 11 10-DEC-12 11 10-DEC-12 110 08.00.00.0 05.00.00.0 08.00.00.0 00000 AM 00000 PM 00000 AMHere's a way to recover them with the FIRST and LAST fucntions aggregate:
SELECT id , MIN (received_time) AS opening_time , MIN (ask_price) KEEP (DENSE_RANK FIRST ORDER BY received_time) AS opening_price , MIN (ask_price) AS min_price , MAX (received_time) AS closing_time , MIN (ask_price) KEEP (DENSE_RANK LAST ORDER BY received_time) AS closing_price , MIN (received_time) KEEP (DENSE_RANK LAST ORDER BY ask_price) AS max_price_time , MAX (ask_price) AS max_price FROM price_quotes WHERE received_time >= TIMESTAMP '2012-12-10 00:00:00' AND received_time < TIMESTAMP '2012-12-11 00:00:00' -- AND id = 668792 GROUP BY id ORDER BY id ; -
Min - Max planning of simple questions
Hello
I try to use Min - Max planning. The user guide of the inventory indicating that Min - Max Plannig uses a request to assess the order quantity, but do not say if such request per month, year or whatever. Looking for the numbers seems to be the annual demand (but does not match my annual turnover). What kind of request is used?
If demand is calculated on an annual basis, order quantity resulting should be to meet the sales of an entire year (I guess).
Is it possible to change this? Does really matter?
Please a few words of counsel
OscarOPR wrote:
Hello
I try to use Min - Max planning. The user guide of the inventory indicating that Min - Max Plannig uses a request to assess the order quantity, but do not say if such request per month, year or whatever. Looking for the numbers seems to be the annual demand (but does not match my annual turnover). What kind of request is used?Hi Oscar,.
According to what level (organization or subinventory) you run mini-maxi planning and the options selected for the net demand will determine which will appear under the open request. Open total demand, or before the application deadline, a selection net demand for reserved and unreserved orders and ONGOING work. It is NOT a month, year or no matter what time.Min - Max at the organization level:
If you choose Yes for net without reservation orders, booked net orders and request for net WIP then open application is the sum of full orders, inventory (including orders reserved) reservations, account question move commands and application component WIP scheduled for issue on or before the application deadline.Min - Max in the Subinventory level:
If you choose Yes for orders without reserve Net and Net booked (without WIP request option here), then open the request matches the sum of reserves inventory (including reserved orders), account number move orders and transfer subinventory move orders to demand because of this subinventory or before the power demand
Date. Reservations subinventory level inventory referencing a different subinventory, or with no specified subinventory, are not included.for example if the application deadline is June 30, 2009 and net options have been included as Yes and then he's going to pick up the order until June 30, 2009 (Note: some applications reports have part time question while comparing dates, so in these cases, 30 June 2009 is taken as 30 June 2009 00:00:00 i.e June 29, 2009 midnight!).
Also if you specify a past date for the cut in demand date, that it would consider open requires available, if necessary, until this last date (but you plan for the future, not past).
-
Strange behavior with MIN MAX at the same time.
Hi all
I had a large table of 5100 K records. I created a Unique Index on a column:
CREATE UNIQUE INDEX TRANS_ID_IDX on TRANS (TRANS_ID);
When I asked the Table with this these two applications:
Select min (trans_id) in trans;
Select max (trans_id) in trans;
The execution Plan shows INDEX FULL SCAN (MIN/MAX) and the performance is really quickly (0.01 sec) because the optimizer chooses get the value of the index, of course.
But now, if I ask the table with two operators:
Select max (trans_id), min (trans_id) in trans;
I got:
TABLE ACCESS FULL and indeed it's really slow to get my answer (9 seconds).
Even if they are shown a suspicion in my request, it does not:
Select / * + INDEX (TRANS TRANS_ID_IDX) * / max (trans_id), minutes (trans_id) from trans; == > always TABLE FULL ACCESS!
So why the optimizer does not use INDEX FULL SCAN (MIN/MAX) to the query when the min and max are both both in the query?
My database is 11.1.0.7 (with the last batch of patches) on Win XP
ConcerningSomeoneElse says:
... My order_line_detail table has about 42 M lines. order_line_detail_id is the primary key.
..Primary key does the trick here, or even NOT NULL column definition.
SQL> drop table dingostar; Table dropped. SQL> create table dingostar (id number); Table created. SQL> insert into dingostar select rownum as id from dual connect by level <= 5000; 5000 rows created. SQL> create index dingostar_idx on dingostar(id); Index created. SQL> explain plan for 2 select max(id),min(id) from dingostar; Explained. SQL> select * from table(dbms_xplan.display); PLAN_TABLE_OUTPUT --------------------------------------------------------------------------------------- Plan hash value: 1182922403 -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 13 | 5 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 13 | | | | 2 | TABLE ACCESS FULL| DINGOSTAR | 5000 | 65000 | 5 (0)| 00:00:01 | -------------------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement 13 rows selected. SQL> SQL> drop table dingostar; Table dropped. SQL> create table dingostar (id number primary key); Table created. SQL> create index dingostar_idx on dingostar(id); create index dingostar_idx on dingostar(id) * ERROR at line 1: ORA-01408: such column list already indexed SQL> insert into dingostar select rownum as id from dual connect by level <= 5000; 5000 rows created. SQL> explain plan for 2 select max(id),min(id) from dingostar; Explained. SQL> select * from table(dbms_xplan.display); PLAN_TABLE_OUTPUT --------------------------------------------------------------------------------------- Plan hash value: 528434344 ------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 13 | 5 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 13 | | | | 2 | INDEX FAST FULL SCAN| SYS_C007051 | 5000 | 65000 | 5 (0)| 00:00:01 | ------------------------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement 13 rows selected. SQL> SQL> drop table dingostar; Table dropped. SQL> create table dingostar (id number not null); Table created. SQL> create index dingostar_idx on dingostar(id); Index created. SQL> insert into dingostar select rownum as id from dual connect by level <= 5000; 5000 rows created. SQL> explain plan for 2 select max(id),min(id) from dingostar; Explained. SQL> select * from table(dbms_xplan.display); PLAN_TABLE_OUTPUT --------------------------------------------------------------------------------------- Plan hash value: 2124830711 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 13 | 5 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 13 | | | | 2 | INDEX FAST FULL SCAN| DINGOSTAR_IDX | 5000 | 65000 | 5 (0)| 00:00:01 | --------------------------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement 13 rows selected. SQL>Nicolas.
-
min/max with outputs ttl statistics
This is a weird problem. I have attached the worksheet because it is difficult to explain the problem. First of all, let me explain what this thing is supposed to do. A generator of signals outputs sine 5Vp - p, in addition to four. After being added, I use a module of statistics to determine the Min/Max. All I need is the maximum, the minimum is ignored (I'm only looking to the + pics). The + peaks are evaluated to identify uniquely to the final output, which sinewave (s) have been entered in the worksheet. Since I finally need 16 - bit I had to add a scalar unit (scale module) to create the entry 16 (max 15 son allowed an output) by expanding the 15th input to two outputs. I see the expected level of TTL is issued by the module of statistics on three modules Y/t diagram. This tells me that things seem a little work at the exit of the module of SEO (the values of hysteresis in the stat module need to be tweaked to produce all the unique values (16), but it works at least. The problem is that the module of bitmask (set to combine tips - 16-bit conversion for a wide release) generates no output regardless of sinewave different combinations of entry. I thought that I have had set a good example of C.J. provided. I hooked of DMM to also monitor the inputs to the module of bitmask (called 16-bit encoder) - I can't get the digital multimeter to display the output of the module of the stat, but the modules Y/t show the output TTL values there. Both show the modules expected to show which is output, but don't--that intrigues me. The frequency of the sine wave is set to 1,2,4 & 8 Hz for debugging, so I know it is not too fast for the DMM display - I proved this by connecting the sum as an input for the senior DMM sinewave and it displays the voltage changes without problem.
Thus, the two questions are: 1) why the DMM is not working at the release of the Y/t modules or Module Min/Max of Stat? (2) why the bitmask Module cannot evaluate its entries? The added sine wave is continuous and constant phase.
Any help would be appreciated. This has really baffled me, trying to debug.
It dawned on me that the DMM is placed where they will not work because they are supposed to show a too short period of tension. They would appear between 5V and 25V depending on the number of 5V wfm summary, but each TTL output, they try to show are nothing more than the duration milliseconds--not a good application for a DMM. Now, it's just a question of what is the problem with the 16-bit conversion package around!
Any suggestions on the problem?
-
Min/max to accumulate dasylab peaks? Is this possible?
In collaboration with Dasylab 10. I'm looking to collect peaks min/max on a form of sinwave we will run. Is this possible? If so, how? Or I have to just to oversample and sift through data?
Thank you!
Select this option.
Use the statistics module called Minimum / Maximum.
This will display the value (you choose minimum, maximum or both), or will display a TTL signal, with a peak TTL (5V) to record highs.
Adjust the hysteresis value to avoid detection from noise and spikes, or use a moving average to smooth out the signal.
-
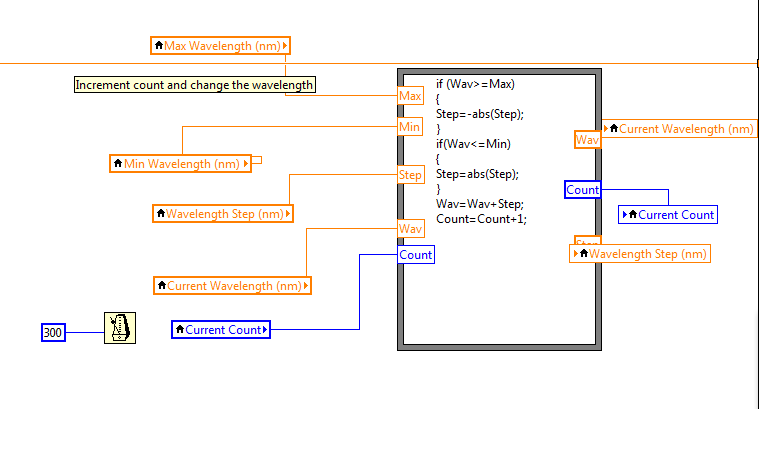
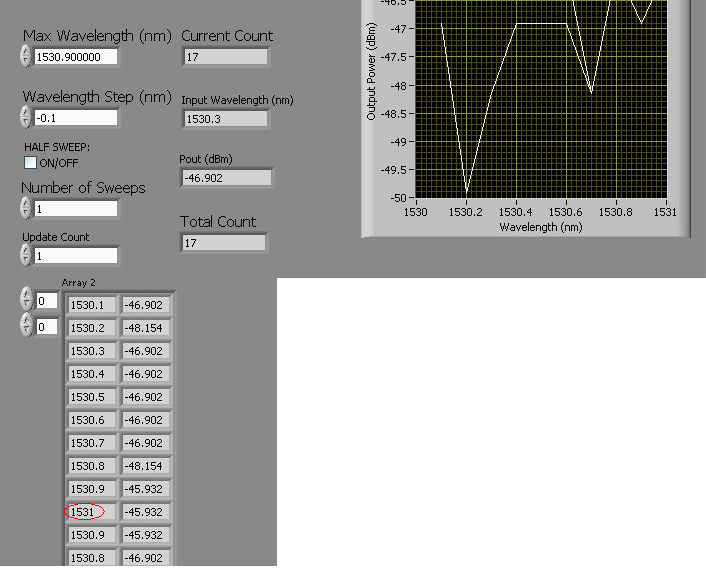
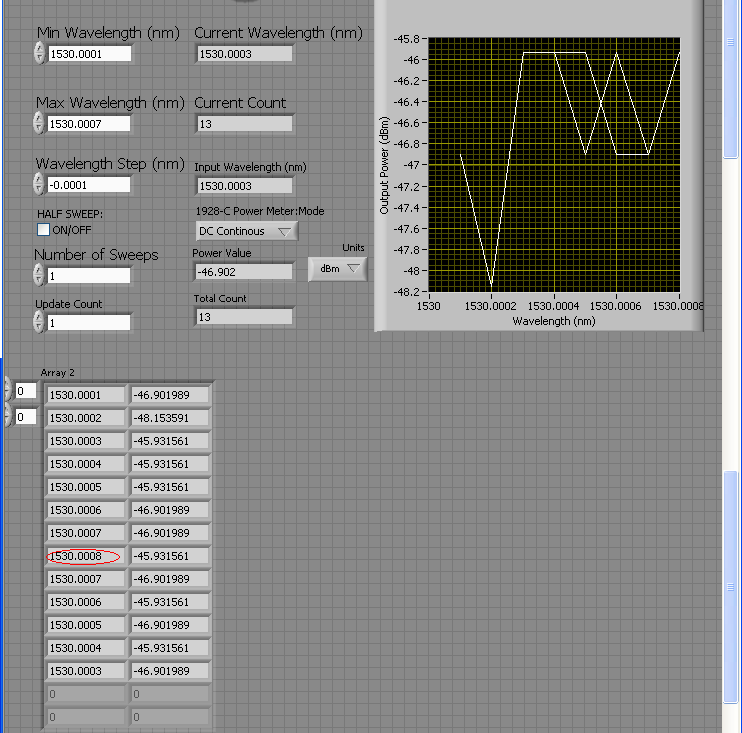
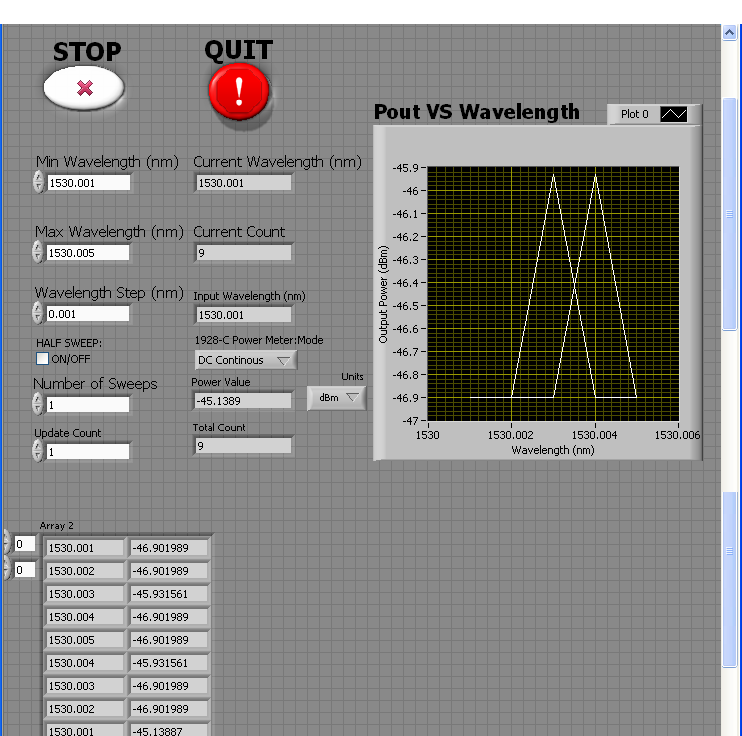
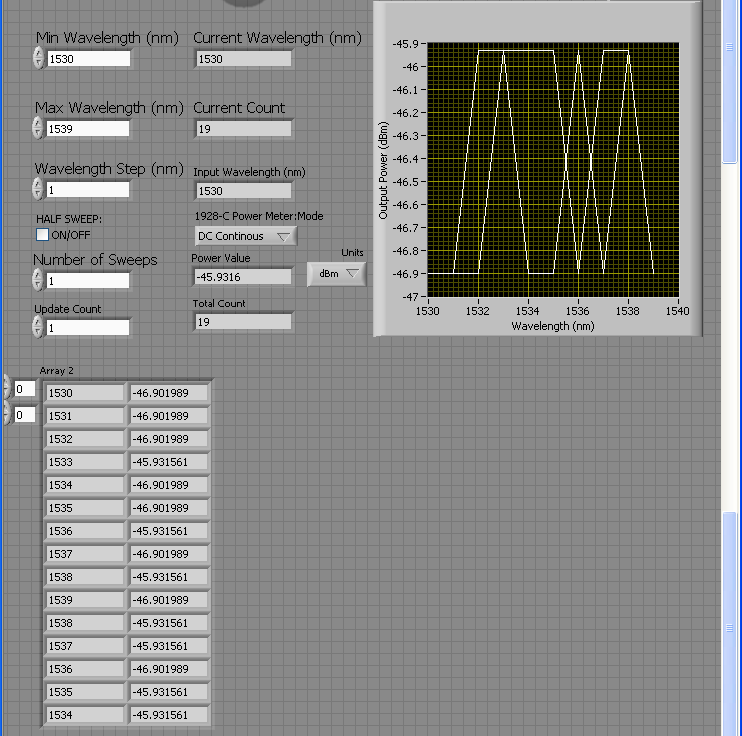
scanning question (Min, Max and Min return)
I have a tunable laser that is supposed to make a sweep of the Min to Max and then back to min.
For some reason, it seems to be an additional step after the peak wavelength as shown below.
Strange is that it seems to happen only when I put a wavelength that has 1 decimal place or 4 decimals.
I'm relatively new to labVIEW, Please HELP? any advice would be helpful.
This looks like a problem of accuracy point. Each language beats in it.
What you need to do is to calculate how many steps to the top must be made and then make comparisons on the step number (an integer).
Also, why use the node formula? A structure matter would take care of the logic.
-
Date field min, max attribute does not
Hi team,
I use in my application webworks, html date field. I want to control the date range of selection user with min and Max device attribute shows the native date picker after giving the input focus, but its does not not the given range.
Please suggest me how to do?
Kind regards
Ilhem
Thank you, it seems that the spec meets the min/max of what I could find.
I reported it to the WebWorks team.
-
Hello again I have 3 dynamic textfields: place1, there2, place3. And 3 variables:
var a:Number = Number (score1.text);
var b:Number = Number (score2.text);
var c:Number = Number (score3.text);
Place1.text = number of 'max' + maximum; for example, 175
Place2.text = number of 'med' + average; for example, 120
Place3.text = 'min' + minimum number; for example 45
How I can compare these variables and get the answer in dynamic text fields? Maby comand to compare as3 and aligin more at the lowest?
Thanks :)
Put a and b and c in table and sort the table.
var a:Number = Number (score1.text);
var b:Number = Number (score2.text);
var c:Number = Number (score3.text);
Table-list var = new Array(a,b,c);
List.sort ();
Place1.text = 'max' + list [0]; for example, 175
Place2.text = 'med' + list [1]; for example, 120
Place3.text = 'min' + list [2]; for example 45
-
Impossible to get Min, Max and median of the values in the date range values
Hello
I had a requirement as to show the data of each charge group of wise men as '< 100' ' 100-199 "" 200-299 "" 300-399 "400-499, 500-599 600-699 700-799 800-899 900-999 > = 1000 '"»
With the query be able to get the count between the beach and the total below. But impossible to get the Min and Max values for this range. For example if the County < 100 is 3 then in these 3, the lowest value is need to display in the min. Idem for Max column also.
In the light of the median value on these values.
Thanks in advance.
Requirement is as below:
State < 100 100-199, 200-299 300-399 400-499, 500-599 600-699 700-799 800-899 900-999 > = 1000 Min Total median Max
AK 1 2 0 4 1 4 4 35 35 4 1 $25 $85 850 $1,200
AL 0 0 2 27 10 17 35 2 2 35 0 $103 100-$1 500 750
* "QUERY ' * '"
WITH t AS
(SELECT 'AL' State, 12 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 67 FROM DUAL VALUE
UNION ALL
SELECT 'AL' State, 23 FROM DUAL VALUE
UNION ALL
SELECT 'AL' State, 12 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 12 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 78 FROM DUAL VALUE
UNION ALL
SELECT 'AL' State, 34 FROM DUAL VALUE
UNION ALL
SELECT 'AL' State, 4 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 12 DUAL FROM VALUE
UNION ALL
SELECT 'AL' State, 15 VALUE FROM DUAL
UNION ALL
SELECT "AZ" State, FROM DUAL VALUE 6
UNION ALL
SELECT "AZ" State, 123 FROM DUAL VALUE
UNION ALL
SELECT "AZ" State, 123 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 23 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 120 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 456 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 11 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 24 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 34 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 87 DUAL FROM VALUE
UNION ALL
SELECT 'MY' State, 23 FROM DUAL VALUE
UNION ALL
SELECT 'MY' State, 234 DUAL FROM VALUE
UNION ALL
SELECT 'MY' State, 789 FROM DUAL VALUE
UNION ALL
SELECT "HD" State, VALUE FROM DUAL 54321).
-End of test data
AS T1
(SELECT State,
NVL (COUNT (DECODE (VALUE, 0, 0)), 0) '< 100 ',.
NVL (COUNT (DECODE (VALUE, 1, 1)), 0) '100-199.
NVL (COUNT (DECODE (VALUE, 2, 2)), 0) '200-299.
NVL (COUNT (DECODE (VALUE, 3, 3)), 0) '300-399.
NVL (COUNT (DECODE (VALUE, 4, 4)), 0) '400-499.
NVL (COUNT (DECODE (VALUE, 5, 5)), 0) '500-599,'
NVL (COUNT (DECODE (VALUE, 6, 6)), 0) '600-699.
NVL (COUNT (DECODE (VALUE, 7, 7)), 0) '700-799.
NVL (COUNT (DECODE (VALUE, 8, 8)), 0) '800-899.
NVL (COUNT (DECODE (VALUE, 9, 9)), 0) '900-999. "
NVL (COUNT (DECODE (VALUE, 10, 10)), 0) ' > = 1000.
(SELECT STATE,
CASE
WHAT VALUE < 100 THEN 0
WHAT A VALUE BETWEEN 100 AND 199 THEN 1
WHAT VALUE BETWEEN 200 AND 299, THEN 2
WHAT VALUE BETWEEN 300 AND 399 THEN 3
WHAT VALUE BETWEEN 400 AND 499 THEN 4
WHAT VALUE BETWEEN 500 AND 599 5 THEN
WHAT VALUE BETWEEN 600 AND 699 6 THEN
WHAT VALUE BETWEEN 700 AND 799 THEN 7
WHAT VALUE BETWEEN 800 AND 899 8 THEN
WHAT VALUE FROM 900 TO 999 9 THEN
WHAT VALUE > = 10 THEN 1000
END
VALUE
T)
GROUP BY State)
SELECTION STATE,
"< 100."
"100-199.
"200 299",
"300-399.
"400-499.
'500-599,'
"600-699.
"700-799.
"800-899.
"900-999."
"> = 1000."
'< 100 '.
+ "100-199.
+ "200-299.
+ '300-399.
+ '400-499.
+ "500-599.
+ '600-699.
+ "700-799.
+ "800-899.
+ '900-999 ".
+ ' > = 1000.
in total,.
less ("< 100",)
"100-199.
"200 299",
"300-399.
"400-499.
'500-599,'
"600-699.
"700-799.
"800-899.
"900-999."
("> = 1000 ') min_val,.
largest ("< 100",)
"100-199.
"200 299",
"300-399.
"400-499.
'500-599,'
"600-699.
"700-799.
"800-899.
"900-999."
("> = 1000 ') max_val
FROM t1
/Why not keep it simple?
WITH t AS (SELECT 'AL' state, 12 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 67 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 23 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 12 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 12 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 78 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 34 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 4 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 12 VALUE FROM DUAL UNION ALL SELECT 'AL' state, 15 VALUE FROM DUAL UNION ALL SELECT 'AZ' state, 6 VALUE FROM DUAL UNION ALL SELECT 'AZ' state, 123 VALUE FROM DUAL UNION ALL SELECT 'AZ' state, 123 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 23 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 120 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 456 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 11 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 24 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 34 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 87 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 23 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 234 VALUE FROM DUAL UNION ALL SELECT 'MA' state, 789 VALUE FROM DUAL UNION ALL SELECT 'MH' state, 54321 VALUE FROM DUAL) SELECT state , NVL( COUNT( case when VALUE < 100 then 0 end ), 0 ) "<100" , NVL( COUNT( case when VALUE between 100 and 199 then 0 end ), 0 ) "100-199" , NVL( COUNT( case when VALUE between 200 and 299 then 0 end ), 0 ) "200-299" , NVL( COUNT( case when VALUE between 300 and 399 then 0 end ), 0 ) "300-399" , NVL( COUNT( case when VALUE between 400 and 499 then 0 end ), 0 ) "400-499" , NVL( COUNT( case when VALUE between 500 and 599 then 0 end ), 0 ) "500-599" , NVL( COUNT( case when VALUE between 600 and 699 then 0 end ), 0 ) "600-699" , NVL( COUNT( case when VALUE between 700 and 799 then 0 end ), 0 ) "700-799" , NVL( COUNT( case when VALUE between 800 and 899 then 0 end ), 0 ) "800-899" , NVL( COUNT( case when VALUE between 900 and 999 then 0 end ), 0 ) "900-999" , NVL( COUNT( case when VALUE >= 1000 then 0 end ), 0 ) ">=100" , count( value ) "total" , min( VALUE ) "min" , max( VALUE ) "max" , avg( VALUE ) "avg" , median( value ) "median" from t group by state -
Purpose of the ORDER BY clause in the analytic function Min Max
I was always using analytical functions like Min Max without ORDER BY clause. But today I used with the ORDER BY clause. The results are very different. I would like to know the purpose of the ORDER BY clause in Min, Max and analogues of analytical functions.user10566312 wrote:
I was always using analytical functions like Min Max without ORDER BY clause. But today I used with the ORDER BY clause. The results are very different. I would like to know the purpose of the ORDER BY clause in Min, Max and analogues of analytical functions.It is a good point that many developers are not so aware. As far as I understand it the way it works.
Some analytical functions do not need an order by or windowing clause (SUM, COUNT, MIN, etc.). If there is no specified window, then the full score is the window.
As soon as you add a command also add you a windowing clause. This window has the default value of 'rank ofrowsbetween unbounded preceding and current_row. So as soon as you add an order by clause, you get a sliding window.Documentation: http://docs.oracle.com/cd/B19306_01/server.102/b14200/functions001.htm
windowing_clause
...
You cannot specify this clause unless you specified the order_by_clause. Window limits defined by the clause RANGE you can not specify only a single expression to the > order_by_clause. Please refer to 'Restrictions on the ORDER BY Clause'.example of
with testdata as (select 10 numval, level lv from dual connect by level < 10) select lv, numval, sum(numval) over () sum1, sum(numval) over (order by lv) sum2 from testdata; LV NUMVAL SUM1 SUM2 -- ------ ---- ---- 1 10 90 10 2 10 90 20 3 10 90 30 4 10 90 40 5 10 90 50 6 10 90 60 7 10 90 70 8 10 90 80 9 10 90 90Published by: Sven w. on 25 Sep 2012 16:57 - default behavior has been corrected. Thanks to Chris
-
Connection pool with the OAS and the optimal value of min/max
Hello world
I have ", works with admin app to implement under oracle application server connection pool. The current value is min = 0, max = unlimited which I think means not implemented connection pool.
Anyway I don't have a lot of information on connection pooling, I searched the forums, but I'm not able to find any useful information.
My Manager would like to know what is the optimal value for min/max for the database, is there a specific formula or a tool that can help me on this issue?
Thanks in advance.Hello
It's a specific formula or a tool that can help me on this issue?
The value that you specify for the number of connections and connections Min depends on a combination of factors, including the size and configuration of your database server and the type of the SQL operations that
your application runs.For connection pooling,.
First, check what is the value of 'process' located on the end of DB (for your current value, check v$ resource_limit at the end of db)...
for example if the process is set to "1000", you cannot set the maximum value of the connection pool to the end server application above 1000 it will crash your database.now on the server side Application.
As a best practice, set the maximum number of open connections and Minimum of connections open to the same value.For more details on connection pool and its settings.
Check "Setting Up Data Sources - Performance Issues" of the link pdf belowdocs.oracle.com/cd/B14099_19/core.1012/b14001.pdf
Hope that it would be useful
Concerning
Fabian -
Since the installation of version 29, I had this problem where the three boxes are missing. It happens sometimes that I start FireFox. I can right-click in the min, max or closing of FireFox and area. I never had the problem before. I have an i7 processor and on Windows 7.
The boxes are not visible (i.e., they show a ToolTip if you hover and work if the click in this area) or whatever should not happen at all?
You can check the problems caused by a corrupt localstore.rdf file.
You can check for problems with preferences.
Delete a possible user.js file and files numbered prefs-# .js and rename (or delete) the file prefs.js to reset all the prefs by default, including the prefs set via user.js and pref which is no longer supported in the current version of Firefox.
Maybe you are looking for
-
Thunderbird freezes fo 10 seconds at the start of new email message - windows 8.1
Hello I have been using thunderbird on a PC Windows 7 years without problem. I just installed Thunderbird on a PC of Windows 8.1. Whenever I start a new email message, thunderbird will freeze for about 10 to 15 seconds. I have exactly the same config
-
Impossible to send the file from the PC to the mobile phone Nokia 5230 but able to phone
HI - how will I can send a file from my Nokia mobile to my PC but not the from my PC to my phone? It seems that the PC can find my phone as I can say "Yes or no" on the mobile phone to receive and I choose Yes After saying yes to the laptop screen: '
-
Problem with 1424 and dalsa ca d1 256bis
Hello friends. IM using a PCI card 1424 with a camera 256bis dalsa CA D1 and Im facing a problem. When I try to do a snap with MAX the picture I get is a white square. But if I click several times in the snap of MAX the image slowly appears and in th
-
repartitioned xp sp2, but now I can't find the updates
Had several viruses on my Dell Dimension 2400. I had to repartition my hard drive. The operatinng system is XP Home Edition. I could get 2 SP installed but nothing else will update. Site Web de Microsoft I cannot make updates. I have my computer
-
Problems of mismatch paper HP Officejet 4500 Wireless
Hey! I really hope you can help! I have a HP Officejet 4500 Wireless printer connected via my router wireless running on Windows Vista and it will not copy correctly. When I put something on the glass to copy, it says "Error" wrong paper size. Load d