myRIO ADC problem: side affacted channel of its previous channel
Hello
I use several channels ADC myRIO now and facing a question about it.
I use 3-channel ADC Port A: AI0 AI1 and AI2.
I have connected AI0 in the middle of a potentiometer for voltage accoss it. And connect anything to AI1 and AI2.
CDA works very well. I can move the potentiometer valtage perfectly AI0.
However, when I changed the value of the potentiometer, the CDA of AI1 and AI2 results changed also, 0, 1V to 0.8V about. Please note I have nothing plugged in these two ports.
Is this true? the ADC AI1 and AI2 and AI3 same (PORT A) port are affacted by AI0?
When I connected AI1 to an Anolog output senser, the result was also affacted by the potentiometer which was connected to the AI0.
When I connect AI1 in power, he was out of influence.
Did someone already had such a problem? Can someone help me to solve it?
Thank you
Fisher lah
It is the response of support OR:
Please note the small change you notice when both of your strings are attached can be due to several factors such as the wrong wire shielding, etc and EMC (electromagnetic coupling).
What is a floating channel terminal, random or variation is normal and due to internal correlated myRIO circuits and should not be a cause for concern.
Well, I'm still very confused.
Tags: NI Products
Similar Questions
-
BBM I have problem in my channel
I have a problem in the channel in BBM, I don't know what the reason
This is the channel number between: C0033A8C6
Please, help me
blackerror wrote:
Sorry arrived in Genk
Wrote which violates the terms of use, but you're wrong
Channel bother hack definition and how to protect them for the benefit of the people and not be a victim of fraud and phishingSo in my opinion, you have violated the guideline, the content of the channels of BBM. It is not clear to me what specific rule you violated because your message was unclear, perhaps you post potentially malicious links or mislead, I don't know... Unfortunately, you cannot recover the said channel BBM, you can always create a new channel, but avoid violating the guidelines again to prevent your BlackBerry ID being suspended permanently.
Also check the orientation content channels BBM here (choose the language you master): channels BBM content guidelines
-
Windows 2K 3 is removed from the network, every hour, sixth of its previous disconnection
Hi all
I have a problem here in a production environment. We use the combination W2K3 SP2 and SQL 2008. It is the server gets disconnected from the network, every hour, sixth of its previous logout. SQL resources are working well, but the server itself becomes not accessible. When I mean the server by its IP address or name DNS etc.
While closely watching the issue, we found that even the RDP connection to it expires exactly at the same time. It's just an interruption of 10-30 seconds, and after him, everything is normal. Only clue is, it happens exactly every sixth hour. We also found his happens for all servers in the VIRTUAL local area network at the same time.
Sixth hour that I mean, is the model... for example it happes to 09:15 then it will happen about 15:16 and then 21:17, then new tomorrow 03:18, 09:19, 15:20, 21:21 etc. If this isn't exactly every six hours, it every hour, sixth of its previous logout. The calendar is always in motion.
Note:
DHCP is not enabled on the server. Its configured to use a static ip address. The server is based. No DHCP server in the environment.
Client DHCP is running on the machine to register DNS for the DNS server. No windows firewall is turned on.So its more like a configuration problem which is something set up to do something every time sixth from his previous instance.
Please let me know if you think anything.
Thank you
DamienHello
We have a separate Department of Microsoft who work with servers. Thanks for posting your query in the link below:
http://social.technet.Microsoft.com/forums/en-us/winserverfiles/threads
Thank you
-
Error message: failure of the last attempt to resume the system from its previous location
I have problem, I can't do anything computer just stuck on the error message screen that reads "the ultimate attempt to resume the system from its previous location failed", the keyboard does not work I can not choose between the choice that is to say 1. continue with the curriculum vitae of system or 2. delete restore data I can't even boot from an installation CD. Help, please
Hello aliciamulrainqz,
Apart from questions of Gerry C J Cornell, I have included a link below where the user reported an error even. Please let us know status.
Microsoft Answers:
Thank you
-
How to run the VI developed in labVIEW 2011 in its previous versions
Hi all
I am currently using LabVIEW 2011 in my PC at home.
But, all my school's computers are installed with LabVIEW 2010 and 2010 SP1.
How to run the VI developed in LabVIEW 2011 in its previous versions?
Is there any conveter why?
Concerning
Prasanth T
Open the VI in LabVIEW 2011 and use the file menu option, save for the previous Version.
-
Help, please! I lost a file with all my notes said corrupt says suddenly and ruined.is it is possible to recover to its previous state intact?
Hello
Can you give us more information so that we can help you?
That is the app do you use? What is the desktop Reader on your Windows or Mac desktop or the mobile Reader on a Tablet iPad/iPhone or Android?
What is the version of the operation on your computer/device system?
-
LaserJet Pro 400 M401dne problem Duplex - duplex printing on its own from Windows computers.
401dne's all jobs from two sided printing windows different computers even if I did not turn on "Print we Both Sides" in the properties of the printer from any application. I even check it whenever I print. A MacBook Pro with OSX 10.8 also have printing on this printer and is not Duplex no print jobs. Note This duplexing on its own comes in all applications (printing from IE, Office 2013 etc.).
I upgraded to the latest firmware and update the latest drivers to print (complete solution install). A printer connected via network domestic (hard wired ethernet to the router) being accessible by two computers Windows and a Mac.
How can I fix this to the o of Windows computers, I can print on the front of each page only, when I want to.
Thank you
Problem solved. I contacted HP Support by Chat online and we opted for the PS driver. It works correctly, a face print individual pages, Duplex prints two pages on one. So yes, the PCL6 driver is deficient.
-
Problem creating new channels charger after an election when ReplicationGroupAdmin or DbPing used
This question relates to 5.0.84. I have found no messages forward precisely the same problem here.
My application uses I HA with replication on 4 nodes. We tested different failure scenarios in which us network-isolate the master node. We see survivors 3 replicas of an election, a master is determined, food chains are established and the overall replication group resumes its features. We also tested the scenarios in which the master of the now 3-node replication-reduced group is isolated from the network in the same way. The results generally worked, but were less reliable when the Group transitions from 3 to 2 knots. We thought the quorum (replacement of likely to be elected group size) setting was the proper way to address this issue and had good results by manually setting the substitution of group likely to be elected to down size.
We have set up a StateChangeListener and in its stateChange() method try to automate adjustment of the size of likely to be elected group override by calling DbPing getNodeState() (alternating) methods and ReplicationGroupAdmin for interview each of 4 nodes possible to see who was available and no INDIVIDUAL State. However, it seems that DbPing or ReplicationGroupAdmin employment within our application to any node causes the implementation of feeder channels after an election of a new master failed (regardless of the number of survivors is likely to be elected nodes). It seems rather ironic, or that the introduction be DbPing or ReplicationGroupAdmin in our application code introduces a principle of Heisenberg uncertainty effect in which tent to observe the number of active nodes causes the behavior of replication group, or more precisely - creating channel charger - for change. Is there a prohibition against using DbPing, ReplicationGroupAdmin or getNodeState() in an application node methods likely to be elected? Do same using these objects/methods in a cause of app monitor a change in behavior among the nodes to be elected after an election? We seem to be observing such behavior.
Thank you
Ted
Here's the log of je.info.0, of NŒUD01. Initially, the NŒUD02 is the master. 17:57:55, we network-isolate NŒUD02. We see an election is called, node01 wins and starts trying to establish the feeders but can't.
130903 17:55:56:752 INFO [NŒUD01] began to ServiceDispatcher. HostPort = ap01.domain.acme .net: 13000
current group 130903 size INFO [NŒUD01] 17:55:56:867: 4
INFO [node01] existing 17:55:56:868 130903 node01 mark for a current master node.
17:55:56:913 INFO [node01] node node01 130903 began
17:55:56:914 130903 INFO [node01] committed election; choice #1
130903 17:55:56:926 INFO [node01] Started election thread kills Sep 03 17:55:56 CDT 2013
130903 changed NŒUD02 master INFO [node01] 17:56:29:308
17:56:29:310 130903 INFO [node01] election is completed. Elapsed time: 32396ms
17:56:29:310 INFO [NŒUD01] exit election after 5 attempts 130903
130903 wire INFO [node01] election of 17:56:29:311 came out. Group master: node02 (64)
130903 17:56:29:310 INFO [node01] Replica loop started with master: node02 (64)
Departure from 130903 17:56:29:343 INFO [node01] Replica-power handshake
Handshake 130903 17:56:29:536 INFO [node01] Replica-charger NŒUD02 completed.
130903 17:56:29:553 INFO [node01] Replica-charger NŒUD02 syncup began. Replica range: first = 843, 326 last = 843, 393 sync 843, 393 = txnEnd = 843, 393
130903 17:56:29:650 INFO [node01] Rollback to matchpoint 843 393-0 x 33/0x2d38 status not = no active txns, nothing to restore
17:56:29:651 130903 NŒUD02 start INFO [node01] VLSN Replica-feeder stream: 843 394
130903 17:56:29:652 INFO [node01] Replica-charger NŒUD02 syncup completed. Elapsed time: 102ms
Replica of INFORMATION [node01] 130903 17:56:29:658 initialization is complete. Replica VLSN: VLSN validation master Heartbeat 843 393: 843 393 delta VLSN: 0
17:56:29:662 INFO [NŒUD01] 130903 joined group as a replica. Join consistencyPolicy = PointConsistencyPolicy targetVLSN = 843, 393 first = 843, 326 last = 843, 393 sync 843, 393 = txnEnd = 843, 393
130903 17:56:29:667 Replay INFO [node01] started thread. Message queue size: 1000
130903 17:56:29:666 INFO [node01] refreshed 0 monitors.
130903 17:56:30:939 WARNING [node01] likely to be elected changed size override group: 3
130903 inactive channel INFO [NŒUD01] 17:57:54:860: node02 (64) forced close. Timeout: 7000ms.
17:57:55:406 130903 INFO [NŒUD01] exit inner loop of the replica.
130903 replica of the INFO [NŒUD01] 17:57:55:407 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
17:57:56:049 130903 INFO [node01] committed election; choice #2
130903 17:57:56:050 INFO [node01] pending election. Waiting...
130903 17:57:56:057 INFO [node01] Started election thread kills Sep 03 17:57:56 CDT 2013
17:58:08:115 INFO [node01] 130903 master changed to node01
17:58:08:116 130903 INFO [node01] election is completed. Elapsed time: 12067ms
17:58:08:121 130903 INFO [NŒUD01] Unknown Service request: registered Feeder services: [Acceptor learner, LogFileFeeder, LDiff, NodeState, group, BinaryNodeState]
17:58:08:122 130903 INFO [NŒUD01] Unknown Service request: registered Feeder services: [Acceptor learner, LogFileFeeder, LDiff, NodeState, group, BinaryNodeState]
17:58:08:122 INFO [NŒUD01] exit election after 2 attempts 130903
130903 wire INFO [node01] election of 17:58:08:123 came out. Group master: node01 (61)
17:58:09:124 130903 INFO [NŒUD01] Unknown Service request: registered Feeder services: [Acceptor learner, LogFileFeeder, LDiff, NodeState, group, BinaryNodeState]
17:58:09:130 130903 INFO [NŒUD01] Unknown Service request: registered Feeder services: [Acceptor learner, LogFileFeeder, LDiff, NodeState, group, BinaryNodeState]
17:58:10:128 130903 INFO [NŒUD01] Unknown Service request: registered Feeder services: [Acceptor learner, LogFileFeeder, LDiff, NodeState, group, BinaryNodeState]
17:58:10:137 130903 INFO [NŒUD01] Unknown Service request: registered Feeder services: [Acceptor learner, LogFileFeeder, LDiff, NodeState, group, BinaryNodeState]
17:58:11:132 130903 INFO [NŒUD01] Unknown Service request: registered Feeder services: [Acceptor learner, LogFileFeeder, LDiff, NodeState, group, BinaryNodeState]
... The same message repeated ad nauseam...
Here's the log of je.info.0 of NŒUD02 for the same period of time. NŒUD02 begins as master, but this host becomes isolated from the network and its supply channels stops at 17:57:55:
130903 17:56:26:861 INFO [NŒUD02] file chose lowest used for cleaning. fileChosen: 0x2f totalUtilization: 50 bestFileUtilization: 0 lnSizeCorrectionFactor: isProbe 0.55577517: false
17:56:26:912 130903 INFO [NŒUD02] CleanerRun 1 ends on the probe file 0x2f = false invokedFromDaemon = true finished = true fileDeleted = false nEntriesRead = 1 nINsObsolete = 0 nINsCleaned = 0 nINsDead = 0 nINsMigrated = 0 nBINDeltasObsolete = 0 nBINDeltasCleaned = 0 nBINDeltasDead = 0 nBINDeltasMigrated = 0 nLNsObsolete = 0 nLNsCleaned = 0 nLNsDead = 0 nLNsMigrated = 0 nLNsMarked = 0 nLNQueueHits = 0 nLNsLocked = 0 logSummary = < CleanerLogSummary endFileNumAtLastAdjustment = '0 x 33' initialAdjustments = '5' recentLNSizesAndCounts = "Horn : 1274201 / 3219 - is: 1494628 / 3219 Cor: 535 / 6-is: 965 / 11 Cor: 788 / 8-East: 1190 / Cor 13: 789 / 8-is: 1289/14 Horn: 714 / 2-is: 1310 / 9 Horn: 37694 / 611 - is: 178596 / 619 Horn: 168637 / 3961 - is: 1164331 / 3961 Cor: 62 / 1-is: 2286 / 21 Cor: 22130 / 1446 - is: 417561 / 1451 Horn: 2429020 / 9915 - is: 3837944 / 9915 "> inSummary = < totalINCount INSummary = '0' totalINSize = '0' totalBINDeltaCount = '0' totalBINDeltaSize = '0' obsoleteINCount = '0' obsoleteINSize = '0' obsoleteBINDeltaCount = '0' obsoleteBINDeltaSize = '0' / >» estFileSummary = < Sommaire totalCount = « 1 » totalSize = « 31 » totalINCount = « 0 » totalINSize = « 0 » totalLNCount = « 0 » totalLNSize = « 0 » maxLNSize = « 0 » obsoleteINCount = « 0 » obsoleteLNCount = « 0 » obsoleteLNSize = « 0 » obsoleteLNSizeCounted = « 0 » getObsoleteSize = « 31 » getObsoleteINSize = « 0 » getObsoleteLNSize = « 0 » getMaxObsoleteSize = « 31 » getMaxObsoleteLNSize = « 0 » getAvgObsoleteLNSizeNotCounted = « NaN » / > recalcFileSummary = < Sommaire totalCount = « 1 » totalSize = « 31 » totalINCount = « 0 » totalINSize = « 0 » totalLNCount = « 0 » totalLNSize = « 0 » maxLNSize = « 0 » obsoleteINCount = « 0 » obsoleteLNCount = « 0 » obsoleteLNSize = « 0 » obsoleteLNSizeCounted = « 0 » getObsoleteSize = « 31 » getObsoleteINSize = « 0 » getObsoleteLNSize = « 0 » getMaxObsoleteSize = « 31 » getMaxObsoleteLNSize = « 0 » getAvgObsoleteLNSizeNotCounted = « NaN » / > lnSizeCorrection = 0.55577517 newLnSizeCorrection = 0.55577517 estimatedUtilization = 0 correctedUtilization = 0 recalcUtilization = 0
130903 17:56:26:973 INFO [NŒUD02] began to ServiceDispatcher. HostPort = ap02.domain.acme .net: 13000
[17:56:26:992 130903 INFO [NŒUD02] Unknown Service request: Acceptor registered services:]
current group 130903 size INFO [NŒUD02] 17:56:27:108: 4
INFO [NŒUD02] existing 17:56:27:108 130903 NŒUD02 mark for a current master node.
17:56:27:186 INFO [NŒUD02] node NŒUD02 130903 began
17:56:27:186 130903 INFO [NŒUD02] committed election; choice #1
130903 17:56:27:206 INFO [NŒUD02] Started election thread kills Sep 03 17:56:27 CDT 2013
130903 17:56:29:290 INFO [NŒUD02] winning proposal: Proposal(00000140e6787717:0000000000000000000000000a000253:00000001) value: value: 10.0.2.83 13000. $ $$$ $$ NŒUD02$ $$ 64
17:56:29:299 INFO [NŒUD02] master changed from NŒUD02 130903
17:56:29:301 130903 INFO [NŒUD02] completed election. Elapsed time: 2114ms
Manager of Feeder INFO [NŒUD02] 17:56:29:302 130903 accepts applications.
17:56:29:309 130903 INFO [NŒUD02] Unknown Service request: registered Feeder services: [Acceptor learner, LogFileFeeder, LDiff, NodeState, group, BinaryNodeState]
Group INFO [NŒUD02] Joining 130903 17:56:29:312 as master
130903 17:56:29:317 INFO [NŒUD02] refreshed 0 monitors.
130903 wire INFO [NŒUD02] election of 17:56:29:318 came out. Group master: node02 (64)
17:56:29:374 130903 Feeder INFO [NŒUD02] has accepted the java.nio.channels.SocketChannel connection [connected local=/10.0.2.83:13000 remote=/10.0.2.82:60052]
Departure of handshake 17:56:29:477 INFO [NŒUD02] replica Feeder 130903
Handshake 130903 17:56:29:539 INFO [NŒUD02] Feeder-replica completed node01.
Syncup 17:56:29:542 130903 INFO [NŒUD02] Feeder-replica node01 began. Range of charger: first = 843, 326 last = 843, 393 sync 843, 393 = txnEnd = 843, 393
17:56:29:654 130903 node01 start INFO [NŒUD02] replica Feeder to VLSN stream: 843 394
130903 17:56:29:656 INFO [NŒUD02] Feeder-replica node01 syncup completed. Elapsed time: 113ms
130903 17:56:29:660 Feeder INFO [NŒUD02] release thread for the replica node01 started at master VLSN 843 394 to 843 393 VLSN delta = - 1 = socket (node01 (61)) java.nio.channels.SocketChannel [remote=/10.0.2.82:60052 connected local=/10.0.2.83:13000]
17:56:30:321 130903 Feeder INFO [NŒUD02] has accepted the java.nio.channels.SocketChannel connection [connected local=/10.0.2.83:13000 remote=/10.0.2.63:47920]
Departure of handshake 17:56:30:326 INFO [NŒUD02] replica Feeder 130903
Handshake 130903 17:56:30:349 INFO [NŒUD02] Feeder-replica completed node04.
130903 17:56:30:350 INFO [NŒUD02] Feeder-replica node04 syncup began. Range of charger: first = 843, 326 last = 843, 395 sync = 843, txnEnd 395 = 843, 395
17:56:30:363 130903 node04 start INFO [NŒUD02] replica Feeder to VLSN stream: 843 394
130903 17:56:30:364 INFO [NŒUD02] Feeder-replica node04 syncup completed. Elapsed time: 14ms
17:56:30:383 130903 Feeder INFO [NŒUD02] out of thread for the replica node04 started to master VLSN 843 394 to 843 395 delta VLSN = 1 socket = (node04 (62)) java.nio.channels.SocketChannel [remote=/10.0.2.63:47920 connected local=/10.0.2.83:13000]
130903 17:56:31:678 likely to be elected [NŒUD02] WARNING group size changed override: 3
17:57:21:200 130903 Feeder INFO [NŒUD02] has accepted the java.nio.channels.SocketChannel connection [connected local=/10.0.2.83:13000 remote=/10.0.2.84:38224]
Departure of handshake 17:57:21:206 INFO [NŒUD02] replica Feeder 130903
Handshake 130903 17:57:21:272 INFO [NŒUD02] Feeder-replica completed node03.
130903 17:57:21:273 INFO [NŒUD02] Feeder-replica node03 syncup began. Range of charger: first = 843, 326 last = 843, 399 sync = 843, 399 = 843, 399 txnEnd
17:57:21:389 130903 node03 start INFO [NŒUD02] replica Feeder to VLSN stream: 843 394
130903 17:57:21:390 INFO [NŒUD02] Feeder-replica node03 syncup completed. Elapsed time: 117ms
17:57:21:392 130903 Feeder INFO [NŒUD02] out of thread for the replica node03 started to master VLSN 843 394 to 843 399 delta VLSN = 5 socket = (node03 (63)) java.nio.channels.SocketChannel [remote=/10.0.2.84:38224 connected local=/10.0.2.83:13000]
130903 inactive channel INFO [NŒUD02] 17:57:55:115: node01 (61) forced close. Timeout: 7000ms.
130903 inactive channel INFO [NŒUD02] 17:57:55:115: node04 (62) forced close. Timeout: 7000ms.
130903 17:57:55:116 INFO [NŒUD02] closing feeder for replica node01 reason: null write time: 2ms Avg write time: 98us
130903 inactive channel INFO [NŒUD02] 17:57:55:125: node03 (63) forced close. Timeout: 7000ms.
130903 17:57:55:126 INFO [NŒUD02] closing feeder for replica node04 reason: null write time: 3ms Avg write time: 147us
130903 17:57:55:127 INFO [NŒUD02] closing feeder for replica node03 reason: null write time: 1ms Avg write time: 90us
17:57:55:409 130903 Feeder INFO [NŒUD02] out to stop node01 replica. VLSN charger: 843 402 currentTxnEndVLSN: 843 401
Out of the 17:57:55:410 130903 Feeder INFO [NŒUD02] judgment of the node03 replica. VLSN charger: 843 402 currentTxnEndVLSN: 843 401
Out of the 17:57:55:411 130903 Feeder INFO [NŒUD02] judgment of the node04 replica. VLSN charger: 843 402 currentTxnEndVLSN: 843 401
17:58:49:456 INFO [NŒUD02] master changed to node01 130903
17:58:50:227 130903 Master INFO [NŒUD02] change: managing change. The ID of the master node: master group to node02 id (64): node01 (61)
Block latch commit 17:58:50:228 130903 Releasing INFO [NŒUD02]
130903 Feeder INFO [NŒUD02] 17:58:50:229 Manager is out. VLSN CurrentTxnEnd: 843 401
17:58:50:230 INFO [NŒUD02] RepNode thread 130903 main stop.
Shutdown 17:58:50:233 130903 INFO [NŒUD02] RepNode exception:
(I 5.0.84) NŒUD02 (64): / data / NŒUD02 com.sleepycat.je.rep.stream.MasterStatus$ MasterSyncException: master the change. The ID of the master node: master group to node02 id (64): node01 (61) MASTER_TO_REPLICA_TRANSITION: this node was a master and must reset the internal State to become a replica. The application must close and reopen all the environment handles. The environment is not valid and must be closed.node02 (64) [MASTER]
No feeders.
GlobalCBVLSN = 843, 393
Group info [RepGroup] 8e8b97b5-f9bc-4b9e-bb6e-56edfbe79674
Version of the representation: 2
Change version: 4
Node for the max rep ID: 64
Node: NŒUD02 ap02.domain.acme .net: 13000 (belongs) changeVersion:4 LocalCBVLSN:843, 393 to: kills Sep 03 17:56:31 CDT 2013
Node: node03 ap03.domain.acme .net: 13000 (belongs) changeVersion:3 LocalCBVLSN:843, 393 to: kills Sep 03 17:57:21 CDT 2013
Node: node01 ap01.domain.acme .net: 13000 (belongs) changeVersion:1 LocalCBVLSN:843, 393 to: kills Sep 03 17:56:29 CDT 2013
Node: node04 ap04.domain.acme .net: 13000 (belongs) changeVersion:2 LocalCBVLSN:843, 393 to: kills Sep 03 17:56:30 CDT 2013
vlsnRange = first = 843, 326 last = 843, 401 sync = 843, txnEnd 401 = 843, 401
lastReplayedTxn = null lastReplayedVLSN = 843, 393 numActiveReplayTxns = 0
130903 17:58:50:234 INFO [NŒUD02] stop the node node02 (64)
INFO [NŒUD02] elections stop 130903 17:58:50:235 triggered
INFO [NŒUD02] elections stop 130903 17:58:50:238 finished
130903 17:58:50:239 RepNode INFO [NŒUD02] main thread: MASTER node02 (64) was released.
17:58:50:240 130903 INFO [NŒUD02] ServiceDispatcher stop starting. [HostPort = ap02.domain.acme .net: 13000 registered services:]
Stop INFO [NŒUD02] ServiceDispatcher 17:58:50:243 130903 done. HostPort = ap02.domain.acme .net: 13000
Stop 17:58:50:243 INFO [NŒUD02] node02 130903 (64) finished.
Here's the log of node03. We see node01 wins the election, but
17:57:20:961 130903 INFO [node03] CleanerRun 1 ends on the probe file 0x2f = false invokedFromDaemon = true finished = true fileDeleted = false nEntriesRead = 1 nINsObsolete = 0 nINsCleaned = 0 nINsDead = 0 nINsMigrated = 0 nBINDeltasObsolete = 0 nBINDeltasCleaned = 0 nBINDeltasDead = 0 nBINDeltasMigrated = 0 nLNsObsolete = 0 nLNsCleaned = 0 nLNsDead = 0 nLNsMigrated = 0 nLNsMarked = 0 nLNQueueHits = 0 nLNsLocked = 0 logSummary = < CleanerLogSummary endFileNumAtLastAdjustment = '0 x 32' initialAdjustments = '5' recentLNSizesAndCounts = "Horn : 1274201 / 3219 - is: 1494628 / 3219 Cor: 535 / 6-is: 965 / 11 Cor: 788 / 8-East: 1190 / Cor 13: 789 / 8-is: 1289/14 Horn: 714 / 2-is: 1310 / 9 Horn: 37694 / 611 - is: 178596 / 619 Horn: 168637 / 3961 - is: 1164331 / 3961 Cor: 62 / 1-is: 2286 / 21 Cor: 22130 / 1446 - is: 417561 / 1451 Horn: 2429020 / 9915 - is: 3837944 / 9915 "> inSummary = < totalINCount INSummary = '0' totalINSize = '0' totalBINDeltaCount = '0' totalBINDeltaSize = '0' obsoleteINCount = '0' obsoleteINSize = '0' obsoleteBINDeltaCount = '0' obsoleteBINDeltaSize = '0' / >» estFileSummary = < Sommaire totalCount = « 1 » totalSize = « 31 » totalINCount = « 0 » totalINSize = « 0 » totalLNCount = « 0 » totalLNSize = « 0 » maxLNSize = « 0 » obsoleteINCount = « 0 » obsoleteLNCount = « 0 » obsoleteLNSize = « 0 » obsoleteLNSizeCounted = « 0 » getObsoleteSize = « 31 » getObsoleteINSize = « 0 » getObsoleteLNSize = « 0 » getMaxObsoleteSize = « 31 » getMaxObsoleteLNSize = « 0 » getAvgObsoleteLNSizeNotCounted = « NaN » / > recalcFileSummary = < Sommaire totalCount = « 1 » totalSize = « 31 » totalINCount = « 0 » totalINSize = « 0 » totalLNCount = « 0 » totalLNSize = « 0 » maxLNSize = « 0 » obsoleteINCount = « 0 » obsoleteLNCount = « 0 » obsoleteLNSize = « 0 » obsoleteLNSizeCounted = « 0 » getObsoleteSize = « 31 » getObsoleteINSize = « 0 » getObsoleteLNSize = « 0 » getMaxObsoleteSize = « 31 » getMaxObsoleteLNSize = « 0 » getAvgObsoleteLNSizeNotCounted = « NaN » / > lnSizeCorrection = 0.55577517 newLnSizeCorrection = 0.55577517 estimatedUtilization = 0 correctedUtilization = 0 recalcUtilization = 0
130903 17:57:20:991 INFO [node03] began to ServiceDispatcher. HostPort = ap03.domain.acme .net: 13000
current group 130903 size INFO [node03] 17:57:21:111: 4
INFO [node03] existing 17:57:21:112 130903 node03 mark for a current master node.
17:57:21:155 130903 INFO [node03] master changed from NŒUD02
17:57:21:182 INFO [node03] node node03 130903 began
130903 17:57:21:183 INFO [node03] Replica loop started with master: node02 (64)
Departure from 17:57:21:205 130903 INFO [node03] Replica-power handshake
Handshake 130903 17:57:21:269 INFO [node03] Replica-charger NŒUD02 completed.
Syncup of NŒUD02 17:57:21:282 130903 INFO [node03] Replica-power began. Replica range: first = 843, 326 last = 843, 393 sync 843, 393 = txnEnd = 843, 393
130903 17:57:21:385 INFO [node03] Rollback to matchpoint 843 393-0 x 32/0x55da status not = no active txns, nothing to restore
17:57:21:386 130903 NŒUD02 start INFO [node03] Replica-feeder VLSN stream: 843 394
130903 17:57:21:387 INFO [node03] Replica-charger NŒUD02 syncup completed. Elapsed time: 105ms
Replica of the INFO [node03] 130903 17:57:21:391 initialization is complete. Replica VLSN: VLSN validation master Heartbeat 843 393: 843 399 delta VLSN: 6
130903 17:57:21:396 Replay INFO [node03] thread started. Message queue size: 1000
17:57:21:417 INFO [node03] 130903 joined group as a replica. Join consistencyPolicy = PointConsistencyPolicy targetVLSN = 843, 399 first = 843, 326 last = 843, 399 sync = 843, 399 = 843, 399 txnEnd
130903 17:57:21:421 INFO [node03] refreshed 0 monitors.
130903 inactive channel INFO [node03] 17:57:55:069: node02 (64) forced close. Timeout: 7000ms.
17:57:55:406 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:57:55:407 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
17:57:56:059 130903 INFO [node03] committed election; choice #1
130903 17:57:56:068 INFO [node03] Started election thread kills Sep 03 17:57:56 CDT 2013
130903 17:58:08:101 INFO [node03] winning proposal: Proposal(00000140e679d235:0000000000000000000000000a000254:00000001) value: value: 10.0.2.82 13000. $ $$$ $$ NŒUD01$ $$ 61
17:58:08:108 130903 INFO [node03] master changed to node01
17:58:08:112 130903 INFO [node03] completed election. Elapsed time: 12053ms
130903 17:58:08:113 INFO [node03] Replica loop started with master: node01 (61)
17:58:08:124 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:08:125 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:08:126 INFO [node03] try again #: 0/10 retries loop replica after 1000ms.
130903 17:58:09:127 INFO [node03] Replica loop started with master: node01 (61)
17:58:09:131 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:09:131 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:09:132 INFO [node03] try again #: 1/10 retries loop replica after 1000ms.
130903 17:58:10:133 INFO [node03] Replica loop started with master: node01 (61)
17:58:10:138 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:10:138 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:10:139 INFO [node03] try again #: 2/10 retries loop replica after 1000ms.
130903 17:58:11:139 INFO [node03] Replica loop started with master: node01 (61)
17:58:11:142 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:11:142 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:11:143 INFO [node03] try again #: 3/10 retries loop replica after 1000ms.
130903 17:58:12:144 INFO [node03] Replica loop started with master: node01 (61)
17:58:12:146 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:12:147 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:12:147 INFO [node03] try again #: 4/10 retries loop replica after 1000ms.
130903 17:58:13:148 INFO [node03] Replica loop started with master: node01 (61)
17:58:13:162 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:13:222 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:13:222 INFO [node03] try again #: 5/10 retries loop replica after 1000ms.
130903 17:58:14:223 INFO [node03] Replica loop started with master: node01 (61)
17:58:14:225 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:14:226 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:14:226 INFO [node03] try again #: 6/10 retries loop replica after 1000ms.
130903 17:58:15:227 INFO [node03] Replica loop started with master: node01 (61)
17:58:15:229 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:15:230 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:15:230 INFO [node03] try again #: 7/10 retries loop replica after 1000ms.
130903 17:58:16:231 INFO [node03] Replica loop started with master: node01 (61)
17:58:16:233 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:16:234 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:16:234 INFO [node03] try again #: 8/10 retries loop replica after 1000ms.
130903 17:58:17:235 INFO [node03] Replica loop started with master: node01 (61)
17:58:17:237 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:17:238 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:17:238 INFO [node03] try again #: 9/10 retries loop replica after 1000ms.
130903 wire INFO [node03] election of 17:58:18:112 came out. Group master: node01 (61)
130903 17:58:18:239 INFO [node03] Replica loop started with master: node01 (61)
17:58:18:280 INFO [node03] 130903 exit inner loop of the replica.
130903 replica of the INFO [node03] 17:58:18:280 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
17:58:18:281 130903 INFO [node03] could not recover from exception: failed after attempts: 10 with retry interval: 1000ms., despite 10 attempts.
com.sleepycat.je.rep.impl.node.Replica$ ConnectRetryException: failed after attempts: 10 with retry interval: 1000ms.
at com.sleepycat.je.rep.impl.node.Replica.createReplicaFeederChannel(Replica.java:777)
at com.sleepycat.je.rep.impl.node.Replica.initReplicaLoop(Replica.java:578)
at com.sleepycat.je.rep.impl.node.Replica.runReplicaLoopInternal(Replica.java:392)
at com.sleepycat.je.rep.impl.node.Replica.runReplicaLoop(Replica.java:328)
at com.sleepycat.je.rep.impl.node.RepNode.run(RepNode.java:1402)
17:58:18:282 130903 INFO [node03] committed election; choice #2
130903 17:58:18:282 INFO [node03] in the current election. Waiting...
.... Attempts and the ConnectRetryException repeat ad nauseam...
We see a similar trend in the node04 newspaper. We observe on 17:58:08:101 node01 became master, but we are unable to establish a connection to power supply to:
130903 17:55:48:149 INFO [node04] began to ServiceDispatcher. HostPort = ap04.domain.acme .net: 13000
current group 130903 size INFO [node04] 17:55:48:230: 4
130903 17:55:48:231 INFO [node04 Existing node04 mark for a current master node.
17:55:48:258 INFO [node04] node node04 130903 began
17:55:48:259 130903 INFO [node04] committed election; choice #1
130903 17:55:48:266 INFO [node04] Started election thread kills Sep 03 17:55:48 PDT 17:56:29:300 2013130903 Master INFO [node04] changed to NŒUD02
17:56:29:301 130903 INFO [node04] completed election. Elapsed time: 41043ms
130903 17:56:29:301 INFO [node04] Replica loop started with master: NŒUD02 (64) 130903 17:56:29:303 INFO [node04] out election after 5 retries130903 17:56:29:304 wire INFO [node04] election came out. Group master: NŒUD02 (6
4)
17:56:29:309 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:56:29:310 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:56:29:310 INFO [node04] try again #: 0/10 retries loop replica after 10
00ms.130903 17:56:30:310 INFO [node04] Replica loop started with master: node02 (64)
Departure from 17:56:30:324 130903 INFO [node04] Replica-power handshake
Handshake 130903 17:56:30:348 INFO [node04] Replica-charger NŒUD02 completed.
Syncup of NŒUD02 17:56:30:352 130903 INFO [node04] Replica-power began. Replica range: first = 843, 326 last = 843, 393 sync 843, 393 = txnEnd = 843, 393
130903 17:56:30:361 INFO [node04] Rollback to matchpoint 843 393-0 x 34 / 0 x 1628
status = no active txns, nothing to restore
17:56:30:362 130903 NŒUD02 start INFO [node04] Replica-feeder VLSN stream: 843 394
130903 17:56:30:362 INFO [node04] Replica-charger NŒUD02 syncup completed. Elapsed time: 10 ms
Replica of the INFO [node04] 130903 17:56:30:382 initialization is complete. Replica VLSN: VLSN validation master 843 393: 843 395 delta VLSN: 2 Heartbeat
130903 17:56:30:386 Replay INFO [node04] thread started. Message queue size: 1000
17:56:30:397 INFO [node04] 130903 joined group as a replica. Join consistencyPolicy = PointConsistencyPolicy targetVLSN = 843 395 first = 843, 326 last = 843, 395 sync = 843, txnEnd 395 = 843, 395
130903 17:56:30:401 INFO [node04] refreshed 0 monitors.
130903 17:56:30:922 WARNING [node04] likely to be elected changed size override group: 3
130903 inactive channel INFO [node04] 17:57:55:223: node02 (64) forced close. Timeout: 7000ms.
17:57:55:398 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:57:55:399 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
17:57:55:401 130903 INFO [node04] committed election; choice #2
130903 17:57:55:401 INFO [node04] in the current election. Waiting...
130903 17:57:55:406 INFO [node04] Started election thread kills Sep 03 17:57:55 CDT 2013
17:58:08:101 130903 INFO [node04] master changed to node01
17:58:08:102 130903 INFO [node04] completed election. Elapsed time: 12701ms
17:58:08:102 INFO [node04] 130903 exit election after 2 attempts
130903 17:58:08:102 INFO [node04] Replica loop started with master: node01 (61)
130903 wire INFO [node04] election of 17:58:08:103 came out. Group master: node01 (61)
17:58:08:110 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:08:110 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:08:111 INFO [node04] try again #: 0/10 retries loop replica after 1000ms.
130903 17:58:09:111 INFO [node04] Replica loop started with master: node01 (61)
17:58:09:114 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:09:114 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:09:114 INFO [node04] try again #: 1/10 retries loop replica after 1000ms.
130903 17:58:10:115 INFO [node04] Replica loop started with master: node01 (61)
17:58:10:117 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:10:118 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:10:118 INFO [node04] try again #: 2/10 retries loop replica after 1000ms.
130903 17:58:11:118 INFO [node04] Replica loop started with master: node01 (61)
17:58:11:121 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:11:121 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:11:122 INFO [node04] try again #: 3/10 retries loop replica after 1000ms.
130903 17:58:12:122 INFO [node04] Replica loop started with master: node01 (61)
17:58:12:125 INFO [node04] 130903 exit inner loop of the replica.
130903 17:58:12:125 INFO [node04] try again #: 4/10 retries loop replica after 1000ms.
130903 17:58:13:126 INFO [node04] Replica loop started with master: node01 (61)
17:58:13:129 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:13:129 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:13:129 INFO [node04] try again #: 5/10 retries loop replica after 1000ms.
130903 17:58:14:130 INFO [node04] Replica loop started with master: node01 (61)
17:58:14:132 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:14:133 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:14:133 INFO [node04] try again #: 6/10 retries loop replica after 1000ms.
130903 17:58:15:133 INFO [node04] Replica loop started with master: node01 (61)
17:58:15:136 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:15:136 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:15:137 INFO [node04] try again #: 7/10 retries loop replica after 1000ms.
130903 17:58:16:137 INFO [node04] Replica loop started with master: node01 (61)
17:58:16:140 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:16:140 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:16:140 INFO [node04] try again #: 8/10 retries loop replica after 1000ms.
130903 17:58:17:141 INFO [node04] Replica loop started with master: node01 (61)
17:58:17:143 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:17:144 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
130903 17:58:17:144 INFO [node04] try again #: 9/10 retries loop replica after 1000ms.
130903 17:58:18:145 INFO [node04] Replica loop started with master: node01 (61)
17:58:18:147 INFO [node04] 130903 exit inner loop of the replica.
130903 replica of the INFO [node04] 17:58:18:148 stats - Lag waiting: 0 Lag delay: 0ms. VLSN waiting: 0 Lag delay: 0ms.
17:58:18:148 130903 INFO [node04] could not recover from exception: failed after attempts: 10 with retry interval: 1000ms., despite 10 attempts.
com.sleepycat.je.rep.impl.node.Replica$ ConnectRetryException: failed after attempts: 10 with retry interval: 1000ms.
at com.sleepycat.je.rep.impl.node.Replica.createReplicaFeederChannel(Replica.java:777)
at com.sleepycat.je.rep.impl.node.Replica.initReplicaLoop(Replica.java:578)
at com.sleepycat.je.rep.impl.node.Replica.runReplicaLoopInternal(Replica.java:392)
at com.sleepycat.je.rep.impl.node.Replica.runReplicaLoop(Replica.java:328)
at com.sleepycat.je.rep.impl.node.RepNode.run(RepNode.java:1402)
17:58:18:149 130903 INFO [node04] committed election; choice #3
130903 17:58:18:149 INFO [node04] in the current election. Waiting...
130903 17:58:18:150 INFO [node04] Started election thread kills Sep 03 17:58:18 CDT 2013
.... Attempts and the ConnectRetryException repeat ad nauseam...
The problem is that you touch a model not supported by violating the contract of the StateChangeListener by launching an expensive operation in the middle of the stateChange method. Of http://docs.oracle.com/cd/E17277_02/html/java/com/sleepycat/je/rep/StateChangeListener.html#stateChange (com.sleepycat.je.rep.StateChangeEvent), we caution:
void stateChange(StateChangeEvent stateChangeEvent) throws RuntimeException
....
This method should do the minimum amount of work, queuing any intensive operations of resource for processing by another thread before returning to appellant, so that it does not unduly delay the other cleaning operations performed by the internal thread that calls this method.
In other words, we really mean the work done by stateChange shouldn't make any IO or network communication, and if he does, he should leave this thread back, and do the expensive work in another thread.
It seems rather ironic, or that the introduction be DbPing or ReplicationGroupAdmin in our application code introduces a principle of Heisenberg uncertainty effect in which tent to observe the number of active nodes causes the behavior of replication group, or more precisely - creating channel charger - for change. Is there a prohibition against using DbPing, ReplicationGroupAdmin or getNodeState() in an application node methods likely to be elected? Do same using these objects/methods in a cause of app monitor a change in behavior among the nodes to be elected after an election? We seem to be observing such behavior.
While an application can certainly use DbPing or ReplicationGroupAdmin, the problem is that the state change listener runs in the critical path the replication group state changes. You talked about monitors and another model of watch and manage the replication group membership is to use http://docs.oracle.com/cd/E17277_02/html/java/com/sleepycat/je/rep/monitor/Monitor.html. This class and the MonitorStateChangeListener partner, run outside the ReplicatedEnvironment and could be another means of implementation of the application logic.
So in summary, you should use com.sleepycat.je.rep.monitor.monitor * to implement your logic, or have the implementation of StateChangeListener cause another thread to perform work asynchronously, so that stateChange() can quickly return.
Please let me know if it helps.
Thank you
Bogdan
-
Hi I have just started using the myRIO. I use the I2C to connect a remote device (motor controller). I figured out how to send data (speed), but Im having problems reading certain values with the I2C of myRIO function. I want to read the register to 0 x 11 to my device. How can I specify what registry I want to read? Thank you.
RokCapuder wrote:
Thanks for the quick reply HappyAsthma!
This is the VI I'm singing and his does not work in the current state. Should I wait for a period of time between writing and reading?
N ° you shouldn't need to wait (the exception being if you were manually manipulate the clock). By specifying, you send a little of each clock cycle.
And I can't open the screw specifically because I don't have the library/drivers installed, but try to use the VI read write to make your bed instead of do it manually then 1 reading and writing 1:
http://zone.NI.com/reference/en-XX/help/373925A-01/myrioreference/myrioref_i2cwriteread/
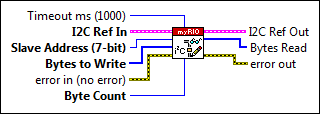
You can send the address of the slave, bytes to write is 0x11, bytes = number of bytes you want to read (your device needed to be put in a registry to make incremental "burst reads" a special value)
EDIT:
I guess (without seeing the code VI) is that the VI and VI read write send the STOP bit automatically once they are do all the bytes read/write. VI read write is probably configured for write Byte (s), and then immediately read some byte (s) before sending the STOP bit.
-
Problem with Alpha channel on AfterEffects composition
Hello
I'm editing a short film called 'Lost In Time' and one of the sequences is supposed to reflect a 1920s silent film, but Adobe AfterEffect records the images as color, even if on Premiere Pro, it was published in black and white.
I tried to turn off the alpha channel, but it won't let me click on 'interpret the film' in the file menu of the sequence on the composition and I can't edit each clip manually in black and white because everything is in a sequence. Assembly of the entire sequence in black and white is not an option either because the 70s Film Noir scenes are also in the same room and are supposed to be full color. So how do AfterEffects to recognize the 20 silent film as in black and white?
You have two choices. Shoot the film in black and white in After Effects and add film damage or restores the section black and white Prime Minister then apply film and AE damage. Almost all the effects, you first add will not come in AE using dynamic links, because they are not compatible. The only thing that you can do about it, it is to make your footage or all the effects work in AE.
It is a workflow problem not a bug.
-
I have a little problem in css and I don't know how to fix...

HTML
< section class = "content" >
header text < h1 > < / h1 >
< side >
text < p > < /p >
ALALA < p > < /p >
Lalala < p > < /p >
ALALA < p > < /p >
ALALA < p > < /p >
Lafon < p > < /p >
Laetitia < p > < /p >
Laetitia < p > < /p >
< / side >
< section >
text of paragraph < p > < /p >
< p > other text < /p > p
< / section >
< / item >
yellow background is cancelled inside the container and next to the section
side {}
float: left;
Width: 180px;
background: #EADCAE;
height: auto;
padding-top: 10px;
padding-right: 0;
padding-bottom: 10px;
padding-left: 0;
}
{section}
margin-top: 15px;
margin-bottom: 15px;
Width: auto;
Display: block;
}
. Container {}
Width: auto;
Max-width: 960px;
padding: 10px;
Top: 0px;
margin-right: auto;
left margin: auto;
top of the margin: 20px;
}
Obviously, I want the side next to the section be in the container.
I do not use width in pixels bacuse other pages have not cancelled and that's a liquid container
so... I Don t know where im wrong
the content must have an overflow hidden in order to work
-
Is there a problem of Windows malware and its license?
This morning I got a phone call saying that there have been complaints about Microsoft Windows used to inflict viruses through e-mail, and that the problem of malicious program involves the Windows license. This company uses software join.me and say that they have been contracted by Microsoft to resolve this issue. They offer a package of anti-logiciel upgrade and also improve my Windows license for the cost of living of $210. I had a hard time to understand their level of English very strongly accentuated. They did run an analysis that says I have 1537 viruses and my computer is high risk.
This company is legitimate? They'll call back me on Monday, June 25.
I had no problems with my computer. I have Norton 360 Antivirus software both System Mechanic, who seem to do a good job of protecting my computer.
Bob Meisterling
E-mail address is removed from the privacy *.
Saturday, June 23, 2012 21:45:03 + 0000, PINES (2) wrote:
This morning I received a phone call saying that there have been complaints about Microsoft Windows used to inflict viruses
through e-mails and malware problem involves the Windows license. This company uses software join.me and say that they have been contracted by Microsoft to resolve this issue. They offer a package of anti-logiciel upgrade and also improve my Windows license for the cost of living of $210. I had a hard time to understand their level of English very strongly accentuated. They did run an analysis that says I have 1537 viruses and my computer is high risk.This company is legitimate? They'll call back me on Monday, June 25.
They are not legitimate. It's a scam and with different names and
phone numbers, which is becoming more and more common lately. In addition to their money get on your part to do anything of any value,
If you leave them in your computer, which knows what losses they did are
where confidential information they stole.So if you have done so, I highly recommend that you do both of the following
immediately:1 do a clean reinstall of Windows.
2. change all of your passwords, especially banks or other
financial sites.I had no problems with my computer. I have both
Norton Antivirus 360 and software System Mechanic who seem to do a good job of protecting my computer.Sorry to say this, but they are all two very bad choices. Norton is
Among the worst available security programs (in my opinion and that of)
many others of us here) and should be replaced by a better
program. System Mechanic is nothing more than a useless, dangerous.
piece of junk; It should be got rid of and do not need
replacement.Ken Blake, Microsoft MVP
-
BBM problem: Send session, channel
Hi all
I tried to send session and channel to my friends in the BBM list using the code of the tutorial (this site: http://docs.blackberry.com/en/developers/deliverables/25800/BlackBerry_Messenger_SDK-Development_Gui...), but the right dialog box show me only the empty list both.
Do my friends need to install this app before I send them session or channel?
Thank you
Concerning
I don't think you send a session or the channel. I think that the process is that you open a Session or channel and invite your friends to participate in this Session or the channel. And yes I think that participate through this Session or channel, your friends will have to use your application.
You have this process work using simulators provided with the SDK?
Take a look at the code in the SDK of BBM demo application. He seems to try to demonstrate everything. At the expense of some specify in my opinion, but it's a good start.
-
having problems with flash player saying its been downloaded, but then the games does not work
Downloaded flash player but still says I need to download
Flash Player Help. Installation problems | Windows
Flash Player Help. Installation problems | Mac OS
Mylenium
-
Problem with backup external drive - its 600 GB and partition is 4 GB-needs conversion to NTFS
I have window xp3 and 600 Giga.when external hard drive I use windows backup files, the back up is stopped and get the message that my external hard drive is Fat 32 and maxim backup is 4 Gig.need help?
Run the format on it to convert it to NTFS. Look at the documentation of the product.

Maybe you are looking for
-
open new tabs in firefox on Ubuntu 12.04 12.0
Open new tabs randomly during firefox sessions. By example, if I leave firefox running all night, the morning there will be 4-6, open new tabs, even if the computer was intact all the time. Don't open new tabs to the Web sites; they just empty.
-
I find no drivers for a printer LaserJet 4 be used on a Windows 7 64 bit family OS. When I try to load from the "Wizard" the printer does not appear on the list, and when I click on Windows Update, it gives me a message saying that it cannot get a W
-
Connects to the network wireless satellite L750 - 16L
Hello I got a new Satellite L750 - 16L and it won t connect to wireless internet. It has limited access with the yellow warning icon symbol wireless bottom right of the screen. It will connect with an Ethernet cable and there are 3 other laptops, the
-
I'm unable to download windows updates, download the 800072ETD error code
Tried all anvenue but having no success
-
I can complete backup after stopping it by chance after burning 2 discs?
I got the first disk, a second full drive with my backup. He said to put another blank disc, but he was running only about 1/2 hour and disks 1 & 2 took hours to fill, so asked for another disk and it come back in & somehow, I stopped and do not wan