PDM writing time
Hey guys,.
I have a clip attached.
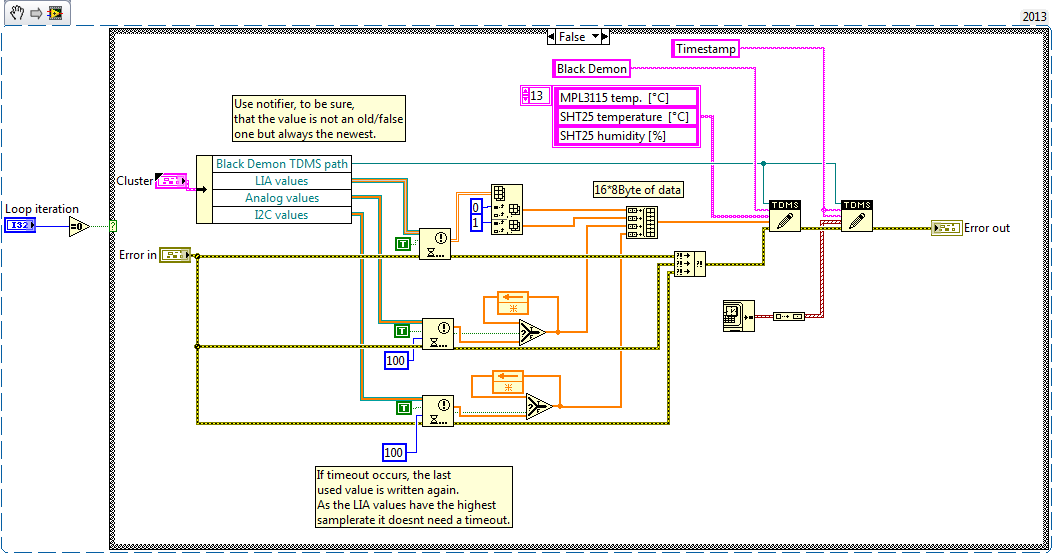
This code snippet runs in a loop timed with maximum speed 500 ms = 2Hz.Only LIA values must always be the most recent. I2C and analog values are not sampling that fast in another loop, so it's ok, if the last value is saved two or three times.
How do I set the timeout, that the loop is still able to finish in time?
Any other suggestions how to improve performance?
Kind regards
Slev1n
In these situations, I generally use a global variable or the library of the current value (CVT) table to contain the latest data instead of the notifier. You don't need to follow a reference in this way, nor do you need to close. A little easier.
Tags: NI Software
Similar Questions
-
ATTENTION: newspaper writing time
Hello
so many warnings:
This means that writing to disk is a concern for our system?mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 5010ms, size 1KB mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 18930ms, size 3KB mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 4210ms, size 1KB mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 3800ms, size 3KB mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 1520ms, size 0KB
Thank you.user522961 wrote:
Hello
so many warnings:mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 5010ms, size 1KB mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 18930ms, size 3KB mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 4210ms, size 1KB mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 3800ms, size 3KB mydb/bdump/mydb_lgwr_8716376.trc:Warning: log write time 1520ms, size 0KBThis means that writing to disk is a concern for our system?
Thank you.
These messages can be ignored.
Also check * file LGWR is followed by production with "WARNING: 540ms journal entry time, size 5444 Ko" in 10.2.0.4 Database [601316.1 ID] *. -
LV 2010.0
I am trying to figure files TDMS, including how to manage changes in configuration along the way.
For example:
I have install the config as TIME + channels A, B, C.
I save some data.
I then change the config on TIME + channels A, B, C, D
I have some more data.
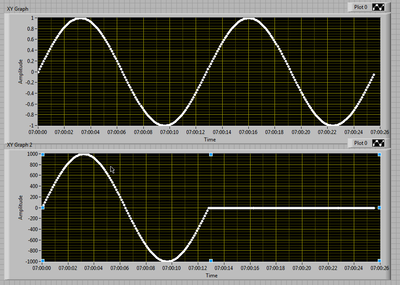
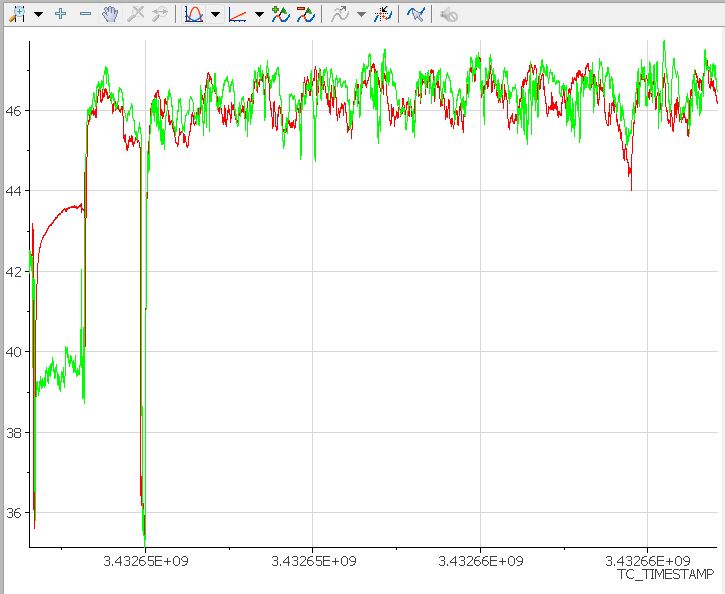
When I extracted the data from the file and the plot vs. time and D vs time, I expect to see the plot D delayed with respect to a location. After all the beginning of D took place AFTER the beginning of the.
But I can't do this job. I tried interlacing / not. It does not appear to associate the trace of both that she took.
This is the result I get:
What I expect is for this parcel from the bottom on the side RIGHT. As it is, he is lying to me.
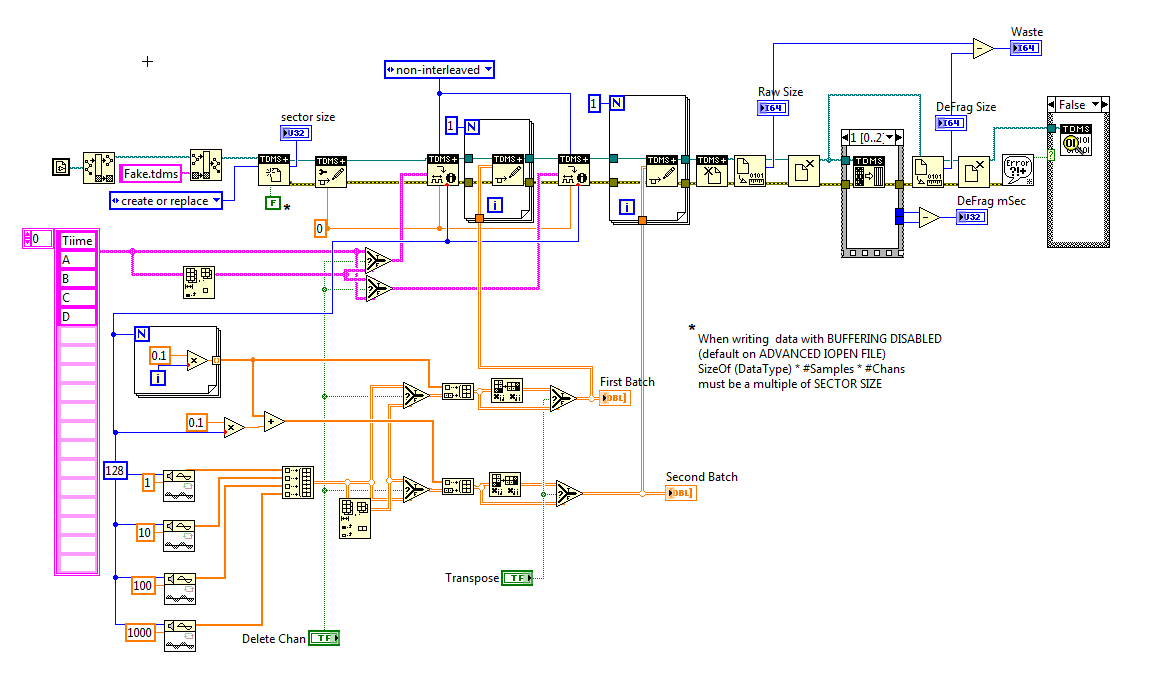
Here is the code that is WRITTEN to the file:
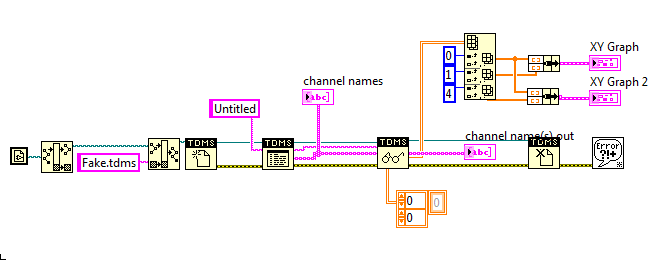
Here's the code that READS the file:
Attached are the screws themselves.
So... What am I missing? How to trace D vs time and get him out exactly?
-
Hi friends,
in my project of mtech, I made an image using some calculation.but when I want to write it in image, needs a lot of time why?
concerning
Ragil
It is not only the calculations that you make in this loop, you make image also writes for each iteration.
-Instead of this, you will need to use imaq write only once. -
TDMS of MDF time stamp conversion error / storage date time change
I fought it for a while, I thought I'd throw it out there...
Let's say I have a file TDMS which has a channel of labview time stamp and thermocouple 2.
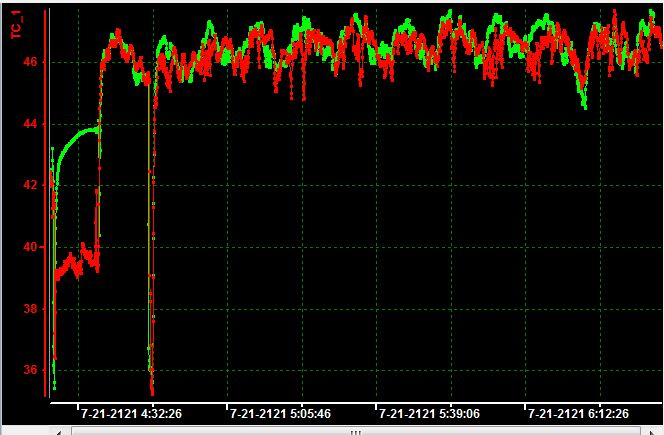
I load in DIADEM, I get this:
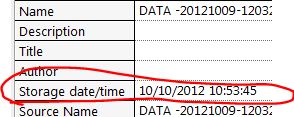
Perfect! But now let's say I want to save the PDM as a MDF file so I can see him in Vector sofa. I right click and save as MDF, perfect. I started couch and get this:
The year 2121, yes I take data on a star boat! It seems to be taking the stamp of date/time storage TDMS as starting point and adding the TC_Timestamp channel.
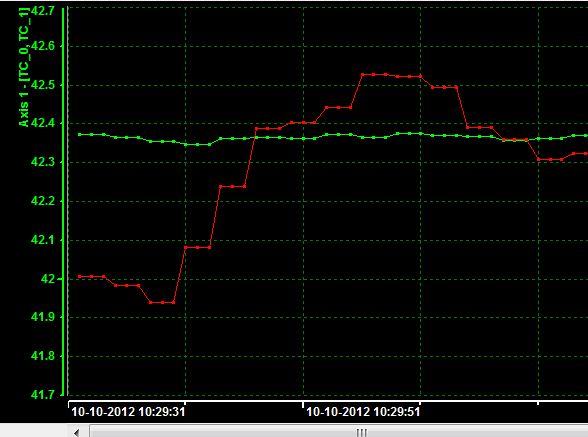
If I change the channel of TC_Timestamp to 1, 2, 3, 4, 5, 6, 7 etc... and save as MDF, I get this:
Very close, 2012! But what I really want is what to show of the time, it was recorded what would be the 10/09/2012.
The problem is whenever I do like recording, date storage time is updated right now, then the MDF plugin seems to use it as a starting point.
is it possible to stop this update in TIARA?
Thank you
Ben
Hi Ben,
You got it right that the MDF use written the time of storage to start MDF that is updated by DIAdem when writing time. We are working on this and will return to you, if there is no progress.
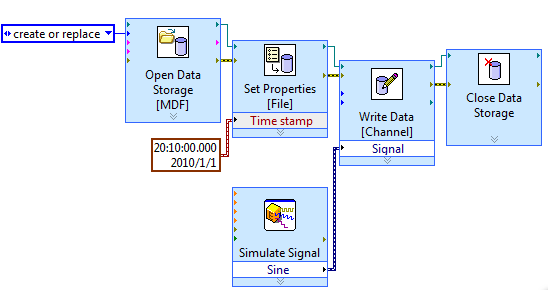
To work around the problem, you can try convert TDMS MDF in LabVIEW storage vis.
Something like the following, you can write your start time of measurement to the MDF file.
Hope this helps,
Mavis
-
Get the time seconds function in LabVIEW returns incorrect Timestamp
Hi to everyone.
In the following link:
http://digital.NI.com/public.nsf/allkb/0ED147D1507C183F862574BA0070AF06?OpenDocument
is written how to solve the problem found during the passage of time stamp wrong.
In my Im application data in files TDMS. When I read the PDM with Ms Excel data, the time is 1 hour before esactly if data is read by another computer.
Time is okay if the data is read by the computer that registered the tdms files.
So I colleague the link suggestion, but in records of Windows I have not found any key TZ.
IM using old profesasional of Ms Windows Xp, version 2002, Service pack 2.
Does anyone have suggestions for this problem?
Thank you very much
Ant
I tried to use the forum suggestions, but all results were unsuccessful.
In any case I solved the problem and I want to share with other users of Lv.
I noticed that in the computer used for the acquisition and recording of the PDM, the time file has shown is correct but the zone was wrong (I live in + 1, and pc was set to + 0)
The laptop I use for reading the PDM data is correctly set to + 1.
I lined up zones, the problem disappeared.
Good bye
-
"redo the write time" includes "log file parallel write".
IO performance Guru Christian said in his blog:
http://christianbilien.WordPress.com/2008/02/12/the-%E2%80%9Clog-file-sync%E2%80%9D-wait-event-is-not-always-spent-waiting-for-an-IO/
Waiting for synchronization of log file can be divided into:
1. the 'writing time again': this is the total elapsed time of the writing of the redo log buffer in the log during recovery (in centisecondes).
2. the 'parallel log writing' is actually the time for the e/s of journal writing complete
3. the LGWR may have some post processing to do, signals, then the foreground process on hold that Scripture is complete. The foreground process is finally awake upward by the dispatcher of system. This completes pending "journal of file synchronization.
In his mind, there is no overlap between "redo write time" and "log file parallel write.
But in the metalink 34592.1:
Waiting for synchronization of log file may be broken down into the following:
1 awakening LGWR if idle
2 LGWR gathers again to be written and issue the e/s
3. the time for the IO journal writing complete
4 LGWR I/O post processing
...
Notes on adjustment according to log file sync component breakdown above:
Steps 2 and 3 are accumulated in the statistic "redo write time". (that is found in the SEO Title Statspack and AWR)
Step 3 is the wait event "log file parallel write. (Note.34583.1: "log file parallel write" reference Note :) )
MetaLink said there is overlap as "remake the writing time" include steps 2 and and "log file parallel write" don't understand step 3, so time to "log file parallel write" is only part of the time of 'redo write time. Won't the metalink note, or I missed something?
-
one of the three internal hard drives slowing down
Everything was perfectly fine, I have three internal hard work led in may Mac pro early 2008, 10.10.5 yosemite OSX, 32 GB of ram, 128 GB SSD boot drive, a hitachi 1 TB and a 2 TB WD I bought 3 months ago. Suddenly a week ago that my 2 TB WD started working slowly, reading and writing time is too long for small amounts of data. Folder icons take the time of loading, and even if this isn't my boot drive, but its cause my very slow closing system. Other drives work perfectly well. I tried to repair the two partitions via disk utility, but nothing helped. The problem is that I can not change my project pro Prime Minister because that all files associated with the project are lying in this same WD drive files cache for After Effects and Premier Pro causing these applications run slowly. I'm working on a feature film project any help would be appreciated.
Thank you
Probably the drive is a failure. When a disc is a failure it should read data multiple times to get a free reading of the error. That really slows thinks down I will quickly copy the data to another disk
-
Dry well EMC CX4 - 120 disks before the gift
We have an installed SC8000 Compellent, and I would like to find a way to erase (wipe of multipass DOD) data from the drives before you make a donation or surplussing safely our old CX4-120.
I came across this old thread, but it's a little bit conclusive and unresolved:

Anyone else have ideas on how to do better to achieve this? Also, I can't imagine there would be any sensitive data that would be on the OS on the first five drives SAN, right?
Thank you for all the ideas, people.
The easiest way is to implement raid groups 1 or more with readers supporting a raid 0 on electromagnetic compatibility (16 my head) or a maximum number. Then create a LUN, set up 1 server with a connection to the CX4-120, put the server and the logical unit number in the same storage group and use some server software to wipe the drives.
The reason for raid 0 is 2 times; I guess that you are not using raid 0 in production, so readers will be cleaned by the RAID 0 array, but it also gives you the fastest writing time while you let the software do the washing.
-
use of multiple distributed same caches scheme, what about config dumps?
Hello
If a distributed system is configured with the reading-writing-support-map, all caches will be required to set the configuration of dumps if the caches use the same distributed schema? For example, we have two caches 'ExpireSessions' and 'Client' who are using distributed system. But only "ExpiredSession" cache must have the reading-writing-support-map (for transaction lite) AND the "ExpiredSession" must be persistent at DB. For cache 'Customer', there NO need to have the reading-writing-support-map AND there is NO need to be persistent in DB. We currently have the following configuration, which also has the "write-delay" and "cache-store' configurations for the cache of 'customer '.
Is it possible has no cache to store configuration configuration (writing / time, cache-store) for the cache of the client even if it uses the same schema distributed as "ExpiredSession" (who needs the configuration of the cache store?) We think that he can probably remove some of the load and improve efficiency) for the 'client' cache operations.
Or is it necessary to have a separate distributed system for cache 'Customer' without right cache store configuration? But then pools of separate/additional threads to use for the service?
Any suggestions?
Thanks in advance for your help.
< name-cache > ExpiredSessions < / cache-name >
< scheme name > distributed by default < / system-name >
< init-params >
< init-param >
timeout < param-name > < / param-name >
< param-value > 2 s < / param-value >
< / init-param >
< init-param >
< param-name > writing-delay < / param-name >
< param-value > 1 s < / param-value >
< / init-param >
< init-param >
cache-store < param name > < / param-name >
xxx.xxx.DBCacheStore < param-value > < / param-value >
< / param-value >
< / init-param >
< / init-params >
<>cache-mapping
< name of cache - > customer < / cache-name >
< scheme name > distributed by default < / system-name >
< init-params >
< init-param >
cache-store < param name > < / param-name >
xxx.xxx.EmptyCacheStore < param-value > < / param-value >
< / init-param >
< init-param >
< param-name > writing-delay < / param-name >
< param-value > 24 h < / param-value >
< / init-param >
< / init-params >
< / cache-mapping >
<!--
The scheme of pricing-distributedcaching distributed by default.
->
< distributed plan >
< scheme name > distributed by default < / system-name >
< service name > XXXDistributedCache < / service-name >
< number > 16 threads < / thread count >
< support-map-plan >
< reading-writing-support-map-plan >
<>plan-Ref rw - bm < / plan-ref >
< / reading-writing-support-map-plan >
< / support-map-plan >
< autostart > true < / autostart >
< / distributed plan >user621063 wrote:
Thank you, Robert/NJIt's when people usually press the [OK] button to assign some points...
Best regards
Robert
-
Filter based on lov using textfield Selectlist?
Hello guys!
I have a list of selection containing up to 500 values. As a fact, that it can become quite difficult to find the entry you're looking for, even if the values are sorted.
My idea was to add a text field where a user can enter a string or narrow down to the selectlist and part of it at present or even better without submitting it using ajax.
Apart from the status of request (REGEXP_LIKE (lower (c.searchstring), lower(:P1_FILTER))) and I do not know now how to do this task. It is even possible to refine the selection list LOV?
Any ideas are greatly appreciated!
Thank you
SEBHello
Ok
I have no instructions better you can find this post
Re: JQuery autocomplete plugin - solutionI can try to find more writing time if you need
Kind regards
Jari -
Read/write mysteriously high flow in a pipeline, why?
Hello people,
I'm quite new to java programming. I'm trying to implement a pipeline procedure:
client connects to server socket and starts to send a file to the server on the basic package. In my case, I use the package of 64KB for sending file of 1 GB. After each packet to the client, the server stores the package to disk. Move Server to receive the next packet.
Server:
ServerSocket ss = (socketWriteTimeout > 0)?
ServerSocketChannel.open () t:System.NET.Sockets.Socket (): new ServerSocket();
Server.bind (ss, socAddr, 0);
ss.setReceiveBufferSize(128*1024);
Taking s = ss.accept ();
s.setTcpNoDelay (true);
In DataInputStream = new DataInputStream (new buffer (NetUtils.getInputStream (s), 512));
Then, for each packet of 64 k, I get and write to disk (specifically buffer for the core, unsynchronized)
long (EDT) 1 = System.currentTimeMillis ();
While (toRead > 0) {}
toRead-= in.read (buf.array (), buf.limit (), toRead);
}
long time2 = System.currentTimeMillis ();
File f = new File (fileName);
FileOutputStream out = new FileOutputStream (new RandomAccessFile(f,_"rw").getFD ())
long Time3 = System.currentTimeMillis ();
out. Write (buf, 0, BUFFER_SIZE);
out. Flush();
long years4 = System.currentTimeMillis ();
....
Client:
Socket s = new Socket (srv, port);
s.setSendBufferSize(128*1024);
DataOutputStream sockOut = new DataOutputStream)
new BufferedOutputStream (NetUtils.getOutputStream (s, writeTimeout),
512));
long worm = 0;
While (ver < 1024 * 1024 * 1024)
{
Then get a 64 k buf
sockOut.write (buf.array (), buf.position (), buf.remaining ());
Worm = buf.remaining ();
}
...
I have record receive time and disc for each packet writing time and accumulate on them at the end.
My machine is using 1 Gbps ethernet card, which gives me 102 MB/s speed n/w testable. My written disc rate is about 70 MB/s. I use Linux 2.6.31.
The interesting thing is that, for a 1 GB file that accumulation of setting time is only 4.6 seconds.
My guess is because I put the SO_RCVBUF, SO_SNDBUF, sockOut.write () of the client immediately returns when he wrote the package of 64 KB in the send buffer, then that server side, in.read () back at once when he read 64 KB of the receive buffer. So the actual transfer is made by someone else, not the write() or read() function. This guy sends data from client to server whenever the beef on each side is available.
My guess is just? Please advice.
EltonBut that triggers the transfer of actual data?
The kernel does when the data arrives in the receive buffer.
The socket transfer is initiated by the post () write(), each recorder gave in their SO_SNDBUF or SO_RCVBUF and the other have free space.
The transfer of socket is triggered on write whenever there is sending data in buffer management and the other end has to free space in its socket receive buffer. It is triggered receive every time he's given in the socket receive buffer.
And do you have any idea where can I find the details of the implementation like this?
Stevens, TCP/IP Illustrated volumes I, II and III.
I joined just extracted from code, not full version
More reason to shoot him.
I don't have your advice to not use BufferedOutputStream on socket. Why not?
Because you don't want no latency, as I said. But I would use on the file, so that you write-aligned block drive pieces of say 8192 bytes.
-
error "memory is full" with writing a file permanently PDM
Hello world
I know that the problem of "memory we complete" has been often discussed in this forum, and I have read these messages, but still could not solve the problem.
We have implemented a test function based on PXI5412 and 5122 modules. The program generates arbitrary waveforms to excite a DUT and acquires its response with digitizer and writing of the data acquired in a TDMS file (~ 40 MB for each measuring point). The program works fine in single point mode, i.e. in quiet passages. However, when I try to run it continuously in a loop TO measure several (up to 1,000) points, the program is always interrupted at halfway when ~ 10 GB of data is recorded with an error "memory is full".
My computer has 4 GB of RAM and the operating system is Windows XP Professional 32-bit. I checked the RAM usage when the error "memory is full" happened. in fact we at least 2.5 GB unused. I learned that maybe it's because he is not a continuous free space in RAM for data. It is also suggested to increase virtual memory to 3 GB for Labview by modifying the boot.ini file. But after I did the program meets still another error "Invalid TDMS" the file reference, and so I could not write all data to a file of PDM.
I joined the part of logging of data of my code here. Is there a another way around the problem of memory, as using the same block of memory for buffering of data between the memory of the digitizer and the hard drive?
cheney_anu,
I need to know your details of tdms files before I could provide a buffer appropriate setting.
for example,.
The current design: you write a tdms 40 GB file that contains 1000 groups (a point a group), each group contains 1,000 channels and each channel contains 1 d I16 table with 20 M of length. (Note: this 40 GB tdms file contains 1000 x 1000 = 1 M channels)
Change:, you could write 1 d I16 table instead of table I16 2D, which could reduce the number of channel 1 M 1 k, and then reduce the memory usage.
New design: you write a tdms 40 GB file that contains 1000 groups (a point a group), each group contains 1 channel and each channel contains 1 d I16 array with length 20G (for each point, call 'TDMS write' 1000 times in a "loop For ' and every time write 1 d I16 array with length 20 M). (Note: this 40 GB tdms file contains 1000 x 1 = 1 K channels)
-
Why Firefox from writing so given all the time?
I'm running Windows 7 x 64 and Firefox 8. In my task manager, I display the bytes of i/o to write to all processes. I found that Firefox is ALWAYS the process with the largest amount of bytes in writing, after that it worked an hour or two even though there are dozens of other processes. The only Web page is Google and all my plugins are disabled.
Why Firefox from writing so given all the time?
Firefox can be updated from the database of phishing protection or maintenance with other files as places.sqlite. It should be limited to a point if this was done.
Start Firefox in Firefox to solve the issues in Safe Mode to check if one of the extensions of the origin of the problem.
- Makes no changes on the start safe mode window.
- https://support.Mozilla.com/kb/safe+mode
-
After failing to recover my system from hard on the D-disk partition recovery software, I bought HP Recovery disks from HP support turned on the PC and installed the first disk according to the instructions. I also pressed ESC on powerup and then selected F9 to boot from the DVD. After 5 minutes of access to records of HP recovery in the DVD player, an error message led indicating that "HP restore incomplete". I looked at the details of the error and showed an other error message stating "[205] UIA writing failed 3 times! In any case I try to do the PC recover either by the recovery using the HP Recovery Manager Software Manager & recovery on the drive partition hard D or using the HP Recovery DVD s I get two ways the same 'error CTO flg' + ' [205] UIA writing failed 3 times. Anything else that can be done, please?
Thanks for the reply. Since I posted my problem on this Forum description, I worked directly with the HP Support and finally concluded that I have needed to push the F9 key button immediately that the PC has been poweringup. Do this correctly then leave the HP recovery disks provided (I bought them from HP) be read by the system and recovery properly executed.
But it shows there is some question buggy with the test drive HP I ran several times and each time has shown an error message of hard drive with result [305] and also [303] - that led me to that almost an expensive for a 320 GB hard drive HP replacement purchase.
Fortunately HP support people were so full with me and kep remember to follow-up with me to see how I was doing and then I got my laptop HP back from work. otherwise I would have made a mistake and installed the third disk, driver HP disk - and his great work now faster than ever.
Thanks Hewlett Packard.
Actually, I was aware of this type of support for HP since the 1970s, when I buy and install servers HP A2100, then servers HP 1000 HP 9000 server, and I have met and had presentations from the team of engineering and management in California from HP this for me and my boss the next type of systems that HP grew for the future and then the HP - DEC ALpha - all this for machinea the best range of computers with the best support for ground control systems (GE Americom in time) operating a critical General Electric fly over most of the commercial SATCOM satellites in the United States. Even if I quit this job just now, HIS AMericom always uses HP to fly to the top of 20 + satellites over the United States and around the world.
Shows just why HP is the longer computer company and will continue to be!
My support case number was 3013351909 so that whoever the Lady of HP support could get credit for its excellence and how she persisted on its initiative of checkin continuously with me and guide me and helped to stop me from buying a disk hard when I didn't need to.
Thanks HP and what concerns the life long realtionship with me!
Maybe you are looking for
-
Today, I decided to add a new device - my mobile with Android. Everything was ok - until I saw what happened on my PC... everthing, excuse me, fu * d upwards. Bookmarks and folders change the order. Also in one of the favorite folders are in a differ
-
This is nuts. My brand new 2 8 black not turn on so I turned to the "contact us" and selected "Tablets" and asked a 'series' of a small list. A K S ThinkPad Yoga I checked the back of the tablet with a magnifying glass and nothing like one of these.
-
my computer laptop allof a sudden will play not DVDS or games from the drive.
My hard drive makes a noise like it will work, but then nothing happens. I tried to install a game, and the computer does not recognize the drive. I followed the instructions for loading the game, but it won't work. Help, please
-
For xp Home: is there a way around tax for RegCure Pro do its ' job?
I was sucked to download a "free" solution to the registry and various problems of congestion. Diagnostic capabilities were fast and versatile, then after hitting the button 'Fix all your problems at once', He would not go forward without a 40 dollar
-
After chkdsk volume is clean, cannot leave disk check program
Today, I decided to run chkdsk on my Windows XP laptop. He told me that I have to restart the computer in the first place, I did. He ran through the cheque, and the end result, said the volume was clean, no errors. However, there was no way for me to