PerlRegEx in FC-RegEx
HelloHow can I make this RegEx workin in the CF:
$test = join "", /(\w*und\w*)/g;) "
BR
Charlie
> Sorry, I made a mistake with copy & paste. It should be:
> ReReplaceNoCase (variables.myValues, '(\w*und\w*)', ' ', 'All')
I thought as well. So, Yes, it's no COP you replace actively
the pieces that you put in correspondence with nothing. You want to replace the bits
you don't want with nothing.
> How can I get this to work?
NB: day @ work today, is only 5 minutes to think about it. He Maybe try some setting... --
Maybe not the best approach. If you look at the s2, there are a lot of
repeated commas in there, which makes me think that there is a better way of
no step over each intermediate character between matches.
Adam
Tags: ColdFusion
Similar Questions
-
Hi, I have a question about the regular expression: If you look at the attached code you will find two examples. It is an old piece of code, but now I have to fix a bug that was discovered after a few years of use. Task: If the entry is for example C1 - C4, the algorithm needs generate a table of C1, C2, C3, C4. This should work on any digit and letter. Examples: R1 - R5, K569-K799, S2 - S3. This works very well for [letter] [number], but my regex won't work for the case now, I have to solve. If the entry is C1A1-C1A4 the output should be C1A2 C1A1, C1A3, C1A4, but I don't know what should look like the new RegEx so that it still works on [letter] [number] [letter] [number].
You can not only use [0-9] + $ to return only the number of the end of the string?
Regular correspondence Expression.vi will return all the foregoing the final number in 'before the game '.
I'm sorry that I can't look at your code since I don't have a LabVIEW 2011 on my system.
Rob
-
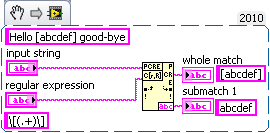
Someday I'll learn Regex. However, that day is not yet. What I have to do is choose the string in square brackets [abcde] returns abcde. I thought it would be something like------[(.+)------] but I can't run in LabVIEW. Suggestions?
You have the regular expression on the right. Here is the code that I tested. (One of the constants represent values in controls and indicators)
-
Regex find number at end of string
Hi guys,.
I try to learn regex, but it's hard and I'm stuck to a simple task:
Let's say I have this string:
"C1".
I would like to find what is the number to the end of the line. I can do with this regular expression ' [0-9] + $".
Now if this chain was formed with a small error, say a character 'space' after the number:
"C1".
My regex would not '1 '.
What should I change in my regex to find the last number in the string, even if it has an error?
P.S. The string can contain several numbers, such as "C5_IND1". My regex must return '1 '.
Use the look early. I sounds like you want the last number which is not followed by another number:
(\d+) (?!. * \d)
-
How to extract the corresponding regex string
Hello
I am trying to extract text from a long string using QRegEx. Here's my regex:
Rx QRegExp ("^. *(192|210). * key =? *");
QString url = ""https://192.168.1.10/files/30/encrypt/key=s6h779bf " "
rx.setPatternSyntax (QRegExp::Wildcard);
rx.indexIn (str, 0);
qDebug()<>
qDebug()<>
However, it is does not match anything.
If I change the regular expression of "(192|210)." * key =? ' * ' can he match but I can't get the string after the = key
You use a regular expression capture if you want that the parameter "key."
QRegExp rx("^.*(192|210).*key=(.*)?"); qDebug() << rx.cap(1); // here's the first octet of your IP qDebug() << rx.cap(2); // key parameter (optional)Your regex could do with a lot of improvement in my humble opinion. You might want to consuder the class QUrl that does what you want already:
QUrl url("https://192.168.1.10/files/30/encrypt/key=s6h779bf"); qDebug() << url.queryItemValue("key");Tip: rubular is a handy Tester on the regex web which makes this kind of thing much easier to debug
-
Widget API Find: regex case sensitive does not work
I try to use the blackberry.find and the blackberry.pim.Contact Widget API to search for a contact.
I need the contact can be found if the specified filter string is anywhere in the field, regardless of case. (I need the query to be case insensitive).
I have a contact, field firstName = 'Norman '.
I use method REGEX (the only one that might work in this case, I think), with these expressions regex to match "Norman":
«. * Norm.*' matches
«. * norm.*"does not match
So I tried the regex (? I) indicator in the expression, and the discovery does not at all.
var fe = new blackberry.find.FilterExpression("firstName", "REGEX", ".*(?i)norm.*"); // causes blackberry.pim.Contact.find() to failThe API doc says "Please refer to java.lang.String.matches () API for more information on the creation of the regular expression correct... "Well, case has been there for some time.
Case is not supported? If not, well... which sucks.
I had asked one of the guys on the team who had some difficulty getting case capacity for work. It came with a work around that is just a bit hacky, but did the trick
var hack = ""; var searchText = searchField.value;for (var i = 0; i < searchField.value.length; i++) { hack = hack + "[" + searchField.value[i].toLowerCase() + searchField.value[i].toUpperCase() + "]"; } var fe = new blackberry.find.FilterExpression("firstName", "REGEX", hack + "[a-zA-Z_0-9_\\s]*"); var contacts = blackberry.pim.Contact.find(fe, "firstName", null, null, true);They created a character set which contained both lowercase and uppercase letter.
-
Hello world
I would like to create a signature to look for SMTP "mail from the command:<>'.»» Is this the right regex statement get this traffic?
[Mm] [Aa] [Ii] [he's] [Ff] [Rr] [Oo] [Mm] [:] [<>]
I usually use the hexadecimal equivalent of the space, but that's just personal preference because it makes it easier to read for me (and I don't inadvertently add random spaces where I don't want them).
[Mm] [Aa] [Ii] \X20 [he's] [Ff] [Rr] [Oo] [Mm] [:] [<>]
Realize that [<>] is a character class and means "<" or="" "="">" as would correspond to the place, so the regex you propose:
post:
or
mail to: >
If you want to find:
mail to:<> (no value between the curly brackets) then the following:
[Mm] [Aa] [Ii] \X20 [he's] [Ff] [Rr] [Oo] [Mm] [:] [<][>]
-
find multiple instances of a string, for example the word 'src' inside another string.
using IndexOf I can find the first occurrence of 'src' and use substrings, as suggested by me simon in another thread, closely related to this.
But this forces me to find several instances of a string within a larger string and insert substrings in an efficient manner, without RegEx features.
Clues?
I can make it through if statements and that work my way towards the end of the string, but that seems a lot more code it should be necessary.
Instead of getting this RegEx program that has been proposed, I found this perfect alternative.
public static String replace(String _text, String _searchStr, String _replacementStr) { //String buffer to store str StringBuffer sb = new StringBuffer(); // Search for search int searchStringPos = _text.indexOf(_searchStr); int startPos = 0; int searchStringLength = _searchStr.length(); // Iterate to add string while (searchStringPos != -1) { sb.append(_text.substring(startPos, searchStringPos)).append(_replacementStr); startPos = searchStringPos + searchStringLength; searchStringPos = _text.indexOf(_searchStr, startPos); } // Create string sb.append(_text.substring(startPos,_text.length())); return sb.toString(); }So there go.
-
OK, so after having poking around seeking support of Regex on BlackBerry, I came across the model repository... I don't understand! It seems to me that with this repository you are adding patterns matching so that the operating system can recognize them?
How can I use in my code?
All I want to do is to perform simple regex matches and replaced so that I can format of phone numbers...
Get a phone like that number.
String PhoneNum = "17775551212"; or "91 7775551212" or "
" etc. Perform a Regex
Output: 91-777-555-1212
right now I use IndexOf(), a method for changing channels and SubString() but its ugly!
Thank you!
Try the regexp - me project
-
Hello
Anyone know the regex string to Boolean operator "AND". I got to know OR operator has string ' |. ' But impossible to find the string for the AND operator.
any help would be appreciated.
Hi Ganesh,
Say, in your example, if channels color and green separated by AAAA, you can write a regular expression like 'ColorAAAAGreen '.
If you are not sure what characters can be between color and green, you can have a regex like "color [\x00-\xff] * Green. It fires if you see followed green color in the traffic flow. But this includes a wildcard character and could be memory. multiple string engine is preferable in this case.
So depending on the traffic as you get closer, you can hardcode strings in the regex and features AND.
HTH,
Radhika
-
I need corrective help on the use of regular expressions in integrated sigs.
In particular, I am referring to the expressions used in the GIS 3115 (Sendmail header overflow). I see many false positives and I try to understand what the signature is looking for.
These are the expressions:
(\x3c >) {20}
\x26lt;>\x26lt;>\x26lt; >...
Can you help me?
Thank you
Don
Your expressions above, I guess you are using sensors 4.x and look subsignature 3 of the signature 3115. This signature is looking for the following:
(<>){20}
It is essentially"<><><>... "repeated 20 times or more. "" (\x3c >) {20} "is the same thing as above. \x3C is the same as "<". we="" had="" to="" do="" this="" because="" of="" a="" regex="" quirk.="" the="" "\x26lt;="">\x26lt;>\x26lt;" >... "" should look to "<><><>... ». He is a victim of our XML data file that can not handle some characters correctly. This is a bug of display. I'll look to this problem.
Regarding false positives, if you can capture a few iplogs and send them to [email protected] / * /, I'll look into the cause. I need to see the traffic to say what exactly happens.
-
VCS Regex ([email protected] / * /)
Hello, I noticed that when I try to call an IP address of a client Jabber video on the iPad, than if I just dial one IP address, it adds the SIP client Jabber domain name to the IP address and the call fails because it does not recognize this address format. I know that I can call by putting an alias in front of the intellectual property and it work, but what a transformation regex would I need to integrate into our VCS for the call to work if users want to just put the single IP address?
I want to take
@ and make it just . How can I make this possible using the regex? Thanks, Patrick
(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3)} (@domain.com)
Then replace with \1, which is the first capturing group that must be the IPv4 address.
You might want to put a? After the domain.com) bit so that becomes optional when it stops to send in the future.
Sent by Cisco Support technique iPhone App
-
I am trying to reverse the effect of the following regex following;
. {[Office@{User.EmailAddress['^.+?@'= "]}
This particular regex comes from the RFSO for provisioning of Jabber. What I want to do is to remove the domain of the email address or leave all the characters before the @.
Thank you.
Sent by Cisco Support technique iPhone App
The Regex paper available at https://supportforums.cisco.com/docs/DOC-25084 could be useful for you.
BTW, Note If you use the commissioning, please be sure to remove domain for all search rule as supply/presence etc. use full URL format for the management of signal.
-
Hello, looking for basic using regex.
I can do the sharing by using the CASE statements, but how can I use it with regex.
How can I separate the below address in separate columns and regex substr, replace S by SOUTH, with NORTH etc and orientation N (N, S, E, W) may appear anywhere.
1850 S LAKEWOOD RD NW
PATTON 300 CL SO
Results as
SUFDIR, SUFTYPE, STRID, VECTOR, STREET
1850, LAKEWOOD, RD, TO THE SOUTH, NW
300, PATTON, CL, WEST, SOUTHWEST
Any help would be appreciated. Apologies if this isn't the right forum.
Thank you.
Any help would be appreciated. Apologies if this isn't the right forum.
OK - you have the wrong forum.
This forum is ONLY for Sql Developer questions.
Please mark the thread ANSWERED and repost it in Sql and Pl/Sql forum
-
ARE regex does not recognize umlauts, etc...
Friends of regular expressions!
I want to check (Special) valid variable names and
\w
for alphabetic characters. This is no characters such as ä - or any character of no ASCI.
My test script is:
var toTest = [], j, n; toTest.push("#Apple"); // true toTest.push("#Apfel, #apple, #Gurkensalateska"); // true toTest.push("#t_27Apples"); // true toTest.push("#côté"); // false toTest.push("#Grüne_5Äpfel"); // false toTest.push("#Äpfel"); // false n = toTest.length; for (j=0; j < n; j++) { $.writeln(ContainsVariable (toTest[j]), " ", toTest[j]); } function ContainsVariable (text) { var re_variable= /(^#[\w][\d_\w]*)(, +)?/, indexOfChar, character, lSkip, kText; for(indexOfChar = 0; character = text[indexOfChar]; indexOfChar++) { kText = text.substring(indexOfChar); // rest of the statement sFound = kText.match(re_variable); if (sFound != null) { lSkip = sFound[0].length; indexOfChar = indexOfChar + lSkip -1; continue; } return false; } return true; }Any ideas how to get valid results for non-English variable names?
There is also other gaps: indesign-scripts-forum-roundup-7 #hd4sb3.
I have not found any documation the regex flavor to YOU. Is there anything?
Klaus
Well, friends, this page gave me a clue:
var re_variable= /(^#[A-Za-z\u00C0-\u017E][\d_A-Za-z\u00C0-\u017E]*)(, +)?/,
works as expected.
Thanks for listening
Klaus
Maybe you are looking for
-
No Satellite A660-1DW no available connection & the State of the map down
Hello Earlier this evening, I closed my laptop, its implementation mode 'sleep', while the battery is dead in mode 'sleep'. When I opened my machine up once again to go online (via radio) icon wireless (bottom left of the screen), showed a red x over
-
Satellite L500 - cannot flash BIOS
Hi all Looking for help here - I have a series of Satellite L500 and the battery has recently stopped charging - from 3 hours to 0% - not charging not from one day to the next. Have you tried altering the eco of the settings button, by pressing power
-
After update for HP UPD PCL 5 on the network drivers, local printers now very slow printing
I've recently updated the HP Universal Print Driver PCL 5 on my Windows 2008 R2 file and print server. All printers on network HP 5 now show the new driver of the UPD PCL 5, and 5 all seems to work fine from all clients on the attached network. Howe
-
Referring to this page http://windows.microsoft.com/en-US/windows/downloads/xp-muiMUI packs are available for download, if you are a volume license customer. I m and already looked at downloads of Volume Licensing Service Center, but he can find. Any
-
How to set Yahoo as my default e-mail on my Windows 7 computer?
Please guide me through the definition of my Yahoo mail like e-mail by default for my new Windows 7 computer. I already have a Yahoo account set and I'm able to do this easily by using the Windows XP operating system. Thank you