Regular expression for Dreamweaver
I haven't had time to really become a professional when it comes to regular expressions, and unfortunately, I need one a conclusion it's hard wrap the head around.
In a text file, I have hundreds of cases as follows:
{Click here to visit my website} {} fromhttp://www.adobe.com/
I need a regular expression for Dreamweaver that I can run in the window 'Search and replace' to switch the order of the above to:
{http://www.adobe.com/} {click here to visit my website}
Can someone provide some guidance? I'll be short due to my lack of experience with regular expressions.
Thank you in advance!
For Dreamweaver:
{([{([Search: {([^)}] *)} {([^)}] *)}
Replace: {$2} {$1}
Tags: ColdFusion
Similar Questions
-
Regular expression for the format: 000-000 - 000000 000000
Hi guys,.
I need to validate the columns in a regular expression for the format of 000 000 - 000000 000000.
For example - if the column contains a value such as "500 110 - 500044 000100" then it should return 'true' otherwise 'false. '
Your timely help is well appreciated.
Thanks in advance.
Hello
inDiscover wrote:
Hi guys,.
I need to validate the columns in a regular expression for the format of 000 000 - 000000 000000.
For example - if the column contains a value such as "500 110 - 500044 000100" then it should return 'true' otherwise 'false. '
Your timely help is well appreciated.
Thanks in advance.
If you want a regular expression
REGEXP_LIKE (str
{{' ^ {\d{3} \d{3}-\d{6} \d{6}$'
)
According to your needs.
You don't need regular expressions for this. It will be more efficient to use
TRANSLATE (str
'012345678'
'999999999'
) = 999 999 - 999999 999999'
-
I have a list of strings in a LOV. I tried filtering by typing in ' ^ disc "in the search bar, that I hope will return a list of strings starting with 'disc', but I failed.
Any idea on how to use regular expressions for LOVs? Thank you!HI Buffalo,
I have an element of the selection list in my named page1: P1_EMPNAME with the value of query lov
Select ename, ename from emp WHERE EGEXP_LIKE(ename,:P1_SEARCH) r like as or: P1_SEARCH IS NULL
I have a text box search in my page 1 name: P1_SEARCH
When I run the page, by default all empnames appear in the lov list item
I gave ^ bison in the element of text search and click on the button submit, it shows the buffalo employee in my lov point list.If you want all entries beginning with S, get ^ s
Ends with R, use r$Please try this link http://download.oracle.com/docs/cd/B28359_01/appdev.111/b28424/adfns_regexp.htm
Thank you
Logaa -
What would be the regular expression to extract the "LEDsOnFront" of the string "FELIX-TestModules-LEDsOnFront - VIT.vit" (price not included)?
Looking for whatever text is between FELIX-TestModules - and - VIT.vit? If so, try using the Scan of string with a 'PUME-TestModules-%[^-]-VIT.vit' format specifier
-
regular expression for alarm url
Hello
I have a problem with the regular expression. I want to filter only the name of a dsc alarm url: \\EW-MONITOR\monitor\000_t-ist_STB-M1-AS. Alarms.HI must be 000_t-ist_STB-M1-AS. Someone has a tip for me?
Best regards
--
JoachimIf as jcarmody asked, the name will always be between 'monitor\' and '. '. Alarms"use the output matching sub regular expression corresponds to
It takes the name from alam of the entire game.
-
Build a regular expression for data series of Arduino.
All,
I have a few Arduinos Council integrated into a test configuration that I can't save the data of. I now need to be able to see my data in real-time as it comes on the serial port. I found a VI that seems like it should work, my problem is that I can't get a regular expression to work.
The VI is not mine, but if I can get this working, I can easily put it in my VI.
Here's my Arduino code; This is the timestamp, followed four data points, with delimiters tab. It prints on the serial port as
190876 762314 814437 1108235 1091719
Serial.print(sTime); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead1); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead2); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead3); data = data>>4; Serial.println(data);I think it is especially a problem with regular expression. Any advice or pointers would be great.
I wish there was a place where you just have to copy and paste my thong in and get a regular expression.
Do not use bytes to the port!
Take advantage of the termination character you have. Activate it on the series set up and set it to the newline character.
Now the VISA Read will wait until she has the entire line (or timeout if it does not). Then you can analyze your data out there.
I think the problem with your code, it's that you're looking for a backslash n. Not a line break. Turn it on the style of display of this constant and you will see it is fixed for normal display and backslash is no bar display.
-
Regular expression for middle of string
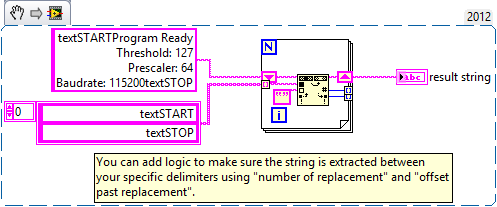
Little background. I get the data (only the numbers) and text (can contain numbers) series. Since I don't know which I get and when it starts / ends, I do the sender send 'textSTART ###textSTOP' where ' # ' is what I want to extract. # can contain text, numbers, new line, carriage return or whatever.
The same for the data : "dataSTART ###dataSTOP", where # contains only numbers.
I think I should use the match pattern, but I don't know how to make my regular expression.
Any help is appreciated.
There are many solutions if you want to only extract the string between your specific delimiters. Here's a solution:
-
regular expression for the xml tags
Dear smart people of the labview world.
I have a question about how to match the names of xml text elements.
The image that I have some xml, for example:
Peter 13 and I want to match all of the names of elements, that is to say: no, son, grandson, age, regardless of any attribute have these items. There is a regular expression, I can loop, that can do this? (Something like "\<.+\> ". "") It is no good because it matches the entire xml string.) I'd really only two different expressions, one for the match start elements, e.g.
and one for the correspondence of the elements, for example. Thanks for your help in advance!
Paul.
The site Of regular Expressions will be very convenient.
They have some good tutorials on regexp with a demo of the XML tags:
Here is a small excerpt:
The regular expression <\i\c*\s*>matches an opening of the XML without the attributes tag corresponds to a closing tag. <\i\c*(\s+\i\c*\s*=\s*("[^"]*"|'[^']*'))*\s*>corresponds to an opening with a number any attributes. Put all together, <(\i\c*(\s+\i\c*\s*=\s*("[^"]*"|'[^']*'))*| i\c*)\s*="">corresponds to an opening with attributes or a closing tag. (source)
If you want advanced XML analysis I suggest JKI XML toolkit.
Tone
-
regexp_substr: a regular expression for the separate comma operator of witn of string literals IN
The following regular expression separates simple values separated by commas (SELECT regexp_substr (: pCsv,'[^,] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,] +', 1, level) IS NOT NULL); Exampple: 300100033146068, 300100033146071, 300100033146079 returns 300100033146068 300100033146071 300100033146079
This works very well if we use the regex with SQL IN operator select * from mytable where t.mycolumn IN (SELECT regexp_substr (: pCsv,'[^,] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,] +', 1, level) IS NOT NULL);
But this query does not work if the comma-separated value is a single literal string 'one', 'two', 'three '.
Thanks for your reply. my request was mainly on regexp_substr. Need to request was simple: any table with a column of varchar type can be used. Next time I'll give you an example.
All ways working answer for my question is is SELECT regexp_substr (: pCsv,'[^, "] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,"] +', 1, level) IS NOT NULL
-
Help in regular Expression for the beaches of limitation
Hi, I'm working on the provision of a text field is limited to dates, it's just a part of the code. I already have the validation of the dates, but I am now limiting what the user enters using a regular expression. This code works a little however, it does not limit me for example I can enter more than 2 digits, but then he limits based on the total amount allowable so for example 8 digits are allowed if I just type. I need to stop after 2 digits then have a - then 2 other numbers then one - and then followed by 4 digits. I tried to limit each section and grouping as well. Any help would be greatly appreciated. Thank you.
It is in the format code and I am the appellant in the key sequence.
function DateKS () {}
var value = AFMergeChange (event);
If (! event.willCommit) {}
Allow only characters that match the regular expression
Event.RC = /^([0]{0,1}[1-9]{0,1}|[_1]{0,1}[012]{0,1}) ([-] {0,1}) ([0] {0,1} [1-9] {0,1} |) [12] {0,1} [0-9] {0,1} | ([3] {0,1} [01] {0,1}) ([-] {0,1}) ([0-9] {0,4}) $/ .test (value);
}
}
I decided that control for 100 and 400 was not necessary because this event does occur that all 400 years. But I'm working on it further and changed even more. Here is my code to work.
function isLeapYear (year) {}
year return % 4 = 0;
}function checkDaysInMonth (day, month, year) {}
daysInMonth var = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31];If (month = 2) {}
If (isLeapYear (year)) {}
daysInMonth [1] += 1;
}
}return daysInMonth [month - 1] > = day;
}function checkDateFormat (dateStr) {}
var errorMsg = ",
maxYear = (new Date()) .getFullYear (),
minYear = maxYear - 1,.
match = dateStr.match(/^(\d{2})-(\d{2})-(\d{4})$/),
months,
day,
year;If {(matches)
month = parseInt (matches [1], 10);
day = parseInt (matches [2], 10);
year = parseInt (matches [3], 10);If (month < 1="" ||="" month=""> 12) {}
errorMsg = "invalid value for the month: ' + matches [1];"
} ElseIf (day = 0) {}
errorMsg = "invalid value for the day:" + match [2];
} else if (! checkDaysInMonth (day, month, year)) {}
errorMsg = "number of days for invalid month: ' + match [2];"
} ElseIf (year < minyear="" ||="" year=""> maxYear) {}
errorMsg = "invalid value for the year:" + match [3] + "-must be between" + minYear + "and" + maxYear;
}
} else {}
errorMsg = "invalid date format: ' + dateStr + ' \r\nPlease use format: dd-mm-yyyy ';"
}return errorMsg;
}function checkReceivedDate() {}
var value = AFMergeChange (event),
errorMsg = ";
ignore control if the value is blank, because this field is not mandatory
If (! value) {}
return;
}If {(event.willCommit)
errorMsg = checkDateFormat (value);If (errorMsg) {}
App.Alert (errorMsg, 0, 0, "error");
Event.value = ";Returns false;
}
} else {}
Allow only characters that match the regular expression
Event.RC = /^(?:0) [1-9]? 1 [012]?) ? -? ( ? : 0 [1-9] ? | [12] [0-9]? 3 [01]?) ? - ? 2? 0? [0-9] {0,2} $/ .test (value);
Event.RC = / ^ \d{0,2}-?\d{0,2}-?\d{0,4}$/.test(value);
}Returns true;
} -
regular expressions for numbers demical in a comma-delimited list
I have a table that lists the details of the occupation of the sites of a comma-delimited list:create table tenure_test)
number of site_number
tenure_detail varchar2 (255));insert into tenure_test values (1, ' Crown (Other) (0.15 ha), private (555.25 ha)');
insert into tenure_test values (2, ' private (5.76 ha)');
insert into tenure_test values (3, ' private (0.18 ha, Crown (3.25 hectares), Indeterminate (Leased) (5.85 ha)');)What I want to do is to use a regular expression to calculate the sum only numbers in the tenure_detail column.
For example, for site_number 1, it would be 0.15 + 555.25 = 555,4
I also have another regular expression that has just the numbers in a comma-delimited list.
For site_number 1: 0.15, 555.25
I tried this:
Select site_number, tenure_detail, regexp_substr (tenure_detail, "[0-9] + \.") ([0-9] {2}') under the name test1
of tenure_test;
but it lists only the first number.
Hello
996454 wrote:
I have a table that lists the details of the occupation of the sites of a comma-delimited list:
create table tenure_test)
number of site_number
tenure_detail varchar2 (255));insert into tenure_test values (1, ' Crown (Other) (0.15 ha), private (555.25 ha)');
insert into tenure_test values (2, ' private (5.76 ha)');
insert into tenure_test values (3, ' private (0.18 ha, Crown (3.25 hectares), Indeterminate (Leased) (5.85 ha)');)What I want to do is to use a regular expression to calculate the sum only numbers in the tenure_detail column.
For example, for site_number 1, it would be 0.15 + 555.25 = 555,4
I also have another regular expression that has just the numbers in a comma-delimited list.
For site_number 1: 0.15, 555.25
I tried this:
Select site_number, tenure_detail, regexp_substr (tenure_detail, "[0-9] + \.") ([0-9] {2}') under the name test1
of tenure_test;
but it lists only the first number.
Here's one way:
SELECT site_number
SUM (TO_NUMBER (REGEXP_SUBSTR (tenure_detail
, "\d+\.\d*" - see Note 1
) T
LEVEL
)
)
), Total
OF tenure_test
CONNECT BY LEVEL<= regexp_count="" (="">
, '\d+\.\d*'
)
AND PRIOR site_number = site_number
AND PRIOR SYS_GUID () IS NOT NULL
GROUP BY site_number
;
Output:
TOTAL OF SITE_NUMBER
----------- ----------
1 555,4
2 5.76
3 9.28
Note 1: what exactly makes a 'number '? I'm assuming it's 1 or more digits, followed by a comma, followed by 0 or more numbers. You can have a slightly different definition; in this case, change the arguments 2nd REGEXP_SUBSTR and REGEXP_COUNT.
I guess also that site_number is unique. If not, you will have to change the CONNECT BY and GROUP BY clauses, to refer to something (or a combination of things) which is unique.
Relational databases are designed for each column of each row contain 1 single piece of information, not a list delimited with a variable number of elements. It is so basic to the design of database he called the first normal form. If your first followed table form normal, this query (and many other queries that involve that table) would be much simpler to write, more efficient to run and less likely to have bugs. See if you can normalize this table. Any effort that you have to spend now to normalize the table will pay very quickly.
Thanks for posting the CREATE TABLE and INSERT statements; It is very useful.
Don't forget to tell what version of Oracle you are using. I tried the query in Oracle 11.2 above. You may need to CONNECT BY a little differently in earlier versions, and REGEXP_COUNT will not work in Oracle 10.
-
Regular expression for invalid number
Hello world
I use version oracle as follows:
SQL > select * from v version $;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - production
PL/SQL Release 10.2.0.4.0 - Production
CORE 10.2.0.4.0 Production
AMT for 32-bit Windows: release 10.2.0.4.0 - Production
NLSRTL Version 10.2.0.4.0 - Production------------------------------------------------------------------------
I use a regular expression to replace invalid values in a table.
I got oracle error 'ORA-01722 invalid number '.
My query looks like this:
SELECT DISTINCT
MRC_KEY,
PURPOSE_CD,
RESIDENCE_DESC,
TO_NUMBER (regexp_replace (ICAP_GEN_MADAPTIVE, "..?")) 0? 0? (\d+) [-.] ((?', '\1')) as ICAP_GEN_MADAPTIVE,
Of
MRRC_INT
I don't know what are invalid values in the table, so I can write regexp accordingly.
Any guidance is appreciated!
Thanks in advance
J
Hello
Whenever you have a problem, please post a small example of data (CREATE TABLE and only relevant columns, INSERT statements) for all of the tables involved and also publish outcomes from these data.
Explain, using specific examples, how you get these results from these data. View of the code which is not what you want can be useful, but there niot enough by itself.
See the FAQ forum: https://forums.oracle.com/message/9362002Let's look at what you do:
REGEXP_REPLACE (icap_gen_madaptive
, '[+. ]' || -exactly 1 of these characters
'?0?0?' || -up to 2 ' 0 '
'(\d+)' || -some numbers (it comes to \1)
'[-.]?' -0 or 1 of these characters
, '\1'
)
Is it really what you want? A group of figures don't match, as the patten must start with a sign more, a point or a space. You want to allow a decimal point at the beginning and at the end, as in "." 9. '? If there are numbers before and after the decimal point, as in "1.2", you want only the digints before the comma? You never said what you want, but I'm guessing that these are things that you don't want.
If the pattern is found, this changes only the schema, so a string like "FU + 123 BAR" more than the model + 9 "" changed to "9" and the resulting string. "" "" FU9BAR"would be passed TO_NUMBER.
If the pattern is not found, as in "FOO", nothing is changed, and the entire string is passed to TO_NUMBER.
I suspect you want to use instead of REGEXP_REPLACE REGEXP_SUBSTR, or, if there is stuff to ignore before and/or after the number you want to include in the model, so that REGEXP_REPLACE will be replaced by nothing.
This looks like a good argument to use the NUMBER of columns to store numbers.
-
Indexing on search for regular expression for dynamic model
Hi all
Is it not possible to create an index for the regular expression search (REGEXP_LIKE) for the model 'dynamic '?
If the model is static, we can create FBI, but is it possible for dynamic diagrams? Please notify.
Kind regards
HariN °
The best option is an Oracle text index.
http://download.Oracle.com/docs/CD/E11882_01/text.112/e16594/TOC.htm -
Help... Regular expression for characters [special] /: ^ & * () @# $
Regular expression to parse the string in square brackets:
I am trying to parse a string in square brackets, but as [] are special characters used in regular expressions to start a character class, I want to remove its special meaning. This regular expression **_user=[a-zA-Z]*@[a-zA-Z]{2}+.abc.com_** works for the analysis of [email protected]* but I want to analyze _user = [[email protected]] _ *, I use the term regular *user=\[[a-zA-Z]*@[a-zA-Z]{2}+.abc.com\]*_* but is in error because it makes special sense of character class. I tried to use \ backslash before *------[]] * but it not working giving error * "INVALID ESCAPE SEQUENCE."
[JAVA CODE: user = "user=\[[a-zA-Z]*@[a-zA-Z]{2}+.abc.com\"];
Pat pattern is Pattern.compile (user);.
Carpet to match = pat.matcher ("2011-03-11 02:08:44, 653: User = [[email protected]], Doing report: account.server.regprocmemunix.daily");
If (mat.find ()) {}
User1 = mat.group ();
}
This room code gives error _ _ "SEQUENCE EXHAUST" INVALID and throw a PatternSyntaxException*.
Please help me parse the string within large brackets [].You realize that, although ' [' is a special character in a regular expression, ' \' is a special character in Java, right?] You also need to escape to the ' \'.
So, if you want to use ' [' in your regular expression, you must use something in the sense of]
\\[Published by: almightywiz on April 25, 2011 14:05
DOH... too slow...
-
regular expression for something that does not have a fixed sequence
Hello
Just having a little trouble with a regular expression. I have an input string and I want to find something that is not this string, so
Input = Hello
Match = Hello
Football game? = False
Entry = Hello1
Match = Hello
Football game? = False
Input = Hello
Match = goodbye
Football game? = True
As I thought that I understood it, to enter as a regular expression in the regular Expression.vi of Match would be ~ (Hello).
If I understand as well, I can't do this by using the match pattern.
Maybe you good people can correct me. Thank you!

Maybe you are looking for
-
Videos YouTube are black when you use the HTML5 player.
Today when I booted up my laptop, Firefox would not play any YouTube video - audio still works and the preview of the image when the research is there, but instead of the video there is just a black screen. I have NO intention to install Flash Player
-
TOSHIBA HDD/SSD Alert - do I need if I have my laptop on a desk?
Hello all, I guess my question is not on the HARD drive or the hardware itself, its subject the load or the process CPU usage alert hdd in my laptop. Fact it gives a heavy load for my memory?Someone at - he noticed your laptop to be a bit slower when
-
need driver for SD - windows 7 - HP Pavilion Notebook 15-n244sa card reader
Hello I need a driver for me SD card reader. Hardware ID are ACPI\HPQ6007* HPQ6007 Thank you
-
Failure of perpetual update KB948465 (error 800b0100)
original title: failure of perpetual update KB948465 Hi all I have a Dell Inspiron I1720: 32-bit, Windows Vista. Windows Update KB948465 (Windows Vista Service Pack 2) has been lacking since 07/08/09. 800b0100 error code, try manually downloading/ru
-
New place doesn't wake up after going to sleep
I'm frustrated with my new coming 11 Pro, because 9 times out of 10, each time that I put it to go to the mode 'sleep', or he falls asleep, he wakes up not again. It seems to go to sleep very well and I push the button once to wake him up and vibrate