Request: Make these more fast screws for large tables
Hey everybody,
Did anyone mind take a look at these two screws? They work very well for small data sets, but they are starting to take up to 200ms each for large arrays (~ 5000 rows x 2 columns). The first actually sends data to the 2nd, so the total delay when running these screws may be 400, 500 ms. Too much to use them in real time.
Reminder of how they are used:
The user can click or click-and - dragging on a graph of intensity to create a card to die to test. These VI are run to update a list of that die are selected and a list of how the machine will move. In mode click - drag, these VI create a very big delay in the response of the public Service.
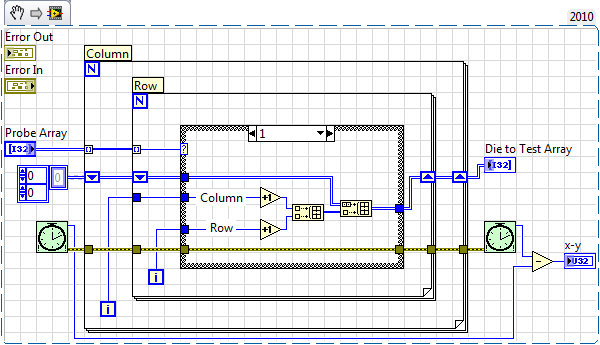
First VI:
The entrance is a 2D table 1 or 0, indicating the test or not test. The output is a 2D line (Nx2) table, column numbers should be probed.
Second VI:
The entrance is a table 2D (Nx2) R, C numbers (from the 1st VI). This VI calculates a relative movement of the current matrix with the following matrix. The output is a table 2D (Nx2) of the relative motions (Y, X). Example: ((2,4), (5.1)) back in ((0,0), (3, -3)).
I've already cut the running time up to half of what it was, but it is still not fast enough. And Yes, the limits of error are not connected, I know :-)
Screws (also attached):

So, what do you think? Is there some Subvi I don't know which completely replaces the 1st VI? Is one of the Subvi I use inherently slow?
Tags: NI Software
Similar Questions
-
Paging query needed help for large table - force a different index
I use a slight modification of the pagination to be completed request to ask Tom: [http://www.oracle.com/technology/oramag/oracle/07-jan/o17asktom.html]
Mine looks like this to extract the first 100 lines of everyone whose last name Smith, ordered by join date:
The difference between this and ask Tom is my innermost query returns just the ROWID. Then, in the outermost query we associate him returned to the members table ROWID, after that we have cut the ROWID down to only the 100 piece we want. This makes it MUCH more (verifiable) fast on our large tables, because it is able to use the index on the innermost query (well... to read more).SELECT members.* FROM members, ( SELECT RID, rownum rnum FROM ( SELECT rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate ) WHERE rownum <= 100 ) WHERE rnum >= 1 and RID = members.rowid
The problem I have is this:
It will use the index for the column predicate (last_name) rather than the unique index that I defined for the column joindate (joindate, sequence). (Verifiable with explain plan). It is much slower this way on a large table. So I can reference using one of the following methods:SELECT rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindateSELECT /*+ index(members, joindate_idx) */ rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate
Whatever it is, it now uses the index of the column ORDER BY (joindate_idx), so now it's much faster there not to sort (remember, VERY large table, millions of records). If it sounds good. But now, on my outermost query, I join the rowid with the significant data in the members table columns, as commented below:SELECT /*+ first_rows(100) */ rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate
As soon as I did this join, this goes back to the use of the index of predicate (last_name) and perform the sort once he finds all the corresponding values (which can be a lot in this table, there is a cardinality high on some columns).SELECT members.* -- Select all data from members table FROM members, -- members table added to FROM clause ( SELECT RID, rownum rnum FROM ( SELECT /*+ index(members, joindate_idx) */ rowid as RID -- Hint is ignored now that I am joining in the outer query FROM members WHERE last_name = 'Smith' ORDER BY joindate ) WHERE rownum <= 100 ) WHERE rnum >= 1 and RID = members.rowid -- Merge the members table on the rowid we pulled from the inner queries
My question therefore, in the query full above, is it possible that I can get to use the ORDER of indexing BY column to prevent having to sort? The join is what makes go back to using the predicate index, even with notes. Remove the join and just return the ROWID for these 100 records and it flies, even over 10 millions of documents.
It would be great if there was some generic hint that could accomplish this, such as if we change the table/column/index, do not change the indicator (indicator FIRST_ROWS is a good example of this, while the INDEX indicator is the opposite), but any help would be appreciated. I can provide explain plans for the foregoing, if necessary.
Thank you!
-
Bitmap Vs domain of index for large tables
I have a DB warehouse which consists of very large tables.
I have two questions:
1 can I use Bitmap or field type index?
2. use a different tablespace for storing the indices? This would improve performance?
Please give me advice to improve the performance of queries for these large tables (more than 300 M record).
Concerning
When to use bitmap indexes
------------------------------
-The column has a low cardinality: little separate value
-Bitmap indexes are particularly useful for complex with ad-hoc queries
long WHERE clauses or applications of aggregation (containing SUM, COUNT, or other
aggregate functions)
-The table contains the number of lines (1,000,000 lines with 10,000 distinct values)
may be acceptable)
-There are frequent, possibly ad hoc queries on the table
-L' environment is focused on the data warehouse (System DSS). Bitmap indexes are
not ideal for due processing (OLTP) environments transactional online
their locking behavior. It is not possible to lock a single bitmap.
The smallest amount of a bitmap that can be locked is a bitmap segment, which
can be a block of data up to half size. Changing the value of a row results in
a bitmap segment becomes locked, blocking to force change on a number of lines.
This is a serious drawback when there are several UPDATE, INSERT or DELETE
statements made by users. It is not a problem when loading data or
updated to the stock in bulk, as in data warehouse systems.
-Bitmap join indexes are a new method of 9.0 by which joins can be avoided in
pre-creation index bitmap on the join criteria.
The BJI is an effective way of space reduction in the volume of selected data.
The data resulting from the join operation and restrictions are
kept permanently in a BJI. The join condition is a join, equi-internal between the
column/columns in primary key of the dimension and the foreign key tables
column or columns in the fact table.
When to use domain indexes
---------------------------------------
https://docs.Oracle.com/CD/E11882_01/AppDev.112/e41502/adfns_indexes.htm#ADFNS00504
-
Collect table statistics take longer for large tables
Version: 11.2
I noticed brings his stats (via dbms_stats.gather_table_stats) takes more time for the large tables.
As number of rows must be calculated, collection of statistics on the table a big would naturally be a little longer (running COUNT (*) SELECT internal).
But for a table not partitioned with 3 million lines, it took 12 minutes to retrieve the stats? Outside the County info and the row index what other information is collected for the table stats gather?
Size of the Table is actually important for the collection of statistics?USER_TABLES DESC
and also
USER_IND_STATISTICS
USER_PART_COL_STATISTICS
USER_SUBPART_COL_STATISTICS
USER_TAB_COL_STATISTICS
USER_TAB_STATISTICS
USER_TAB_STATS_HISTORY
USER_USTATS
USER_TAB_HISTOGRAMS
USER_PART_HISTOGRAMS
USER_SUBPART_HISTOGRAMS -
How to use partitioning for large table
Hello
******************
Oracle 10 g 2/Redhat4
RAC database
ASM
*******************
I have a TRACE table that will also grow very fast, in fact, I 15,000,000 lines.
TRACES (IDENTIFICATION NUMBER,
NUMBER OF COUNTRY_NUM
Timestampe NUMBER,
MESSAGE VARCHAR2 (300),
type_of_action varchar (20),
CREATED_TIME DATE,
DATE OF UPDATE_DATE)
Querys who asked for this table are and make a lot of discs!
--------------------------------------------------------
Select count (*) as y0_
TRACES this_
where this_. COUNTRY_NUM =: 1
and this_. TIMESTAMP between: 2 and: 3
and lower (this_. This MESSAGE) as: 4;
---------------------------------------------------------
SELECT *.
FROM (SELECT this_.id,
this_. TIMESTAMP
Traces this_
WHERE this_. COUNTRY_NUM =: 1
AND this_. TIMESTAMP BETWEEN: 2 AND: 3
AND this_.type_of_action =: 4
AND LOWER (this_. MESSAGE) AS: 5
ORDER BY this_. TIMESTAMP DESC)
WHERE ROWNUM < =: 6;
-----------------------------------------------------------
I have 16 distinct COUNTRY_NUM in the table and the TIMESTAMPE is a number that the application is inserted into the table.
My question is the best solution to resolve this table is to use partitioninig for a smal parts?
I have need of a partitioning using a list by date (YEAR/month) and COUNTRY_NUM, is there a better way for her?
NB: for an example of TRACES in my test database
1 Select COUNTR_NUM, count (*) traces
Group 2 by COUNTR_NUM
3 * order by COUNTR_NUM
SQL > /.
COUNTR_NUM COUNT (*)
194716 1
3 1796581
4 1429393
5 1536092
6 151820
7 148431
8 76452
9 91456
10 91044
11 186370
13 76
15 29317
16 33470Hello
Yes and part is that you can remove the whole score once you don't need "of them. I think you should be good to go. Let me know if you have any other questions.
Concerning
-
Pavilion TS 15n-070sa: more fast motherboard for HP Pavilion TS 15n-070sa
Product name: HP Pavilion TS 15n-070sa
Product number: E7G63EA
OS: Windows 10 (primary), Kali Linux Sana (2.0)
Recent hardware changes: None
Problem:
Recently, I decided to upgrade my Pavilion TS 15n-070sa processor. However, I took soon a problem after having disassembled my hard drive, due to the fact the processor is soldered to the Board rather than just locked to it. Then, I got a glance in the maintenance and service guide, which made me think that the other portable Pavilion TS 15 could have the same shape of the investment just (perhaps) with a better processor and motherboard. However, I am still not sure of the fact that last and that's why I came here to ask where I could get a replacement and a better motherboard for my laptop.
It would be the best motherboard:
AMD A10 - 5745 M 8670 M 2.9 GHz/2.1 GHz (2 GB L2, 1333 MHz DDR3L Quad 25 W) for use with Standard Windows. 734824 501
Here is the Service Manual:
HP is out of stock.
http://www.discounteddealz.com/product.asp?Itemid=327740&gclid=CIC4jIq6k8oCFQEcaQodVJ4BZA
If it's 'the Answer' please click on 'Accept as Solution' to help others find it.
-
Oracle ADF - request fast refresh for a table in the pop-up.
Hello
I use Oracle jDev 11.1.1.4.0
In my application, I have a Search button in jspx.
OnClick of the button Search , a popup opens.
When I search a name in QuickQuery registration, assume - I got the name as jon.
It gives me a correct result.
Now when I close the pop up and still once, click on the Search button, the previous search remains as it is in the pop up
and as the criteria in a query quick search area as "jon".
I changed the refresh of iterator (from table in popup) property in pageDef
But still does not...
How do I update this area of research for all the find , click.
Appreciate your help.
Thank you
MadhavMalenfant,
Check [url: http://jobinesh.blogspot.com/2011/04/programmatically-resetting-and-search.html] this blog
Jean Lou
-
The fastest way to import data for large tables
Hi friends,
I recently joined a billing product put up a team for TELECOM giant. Under the procedure of installation/initial tests, we have huge data (size of almost 1.5 billion records / ~ 200 GB of data) in some tables. Currently I use impdp to import. It takes a long time (almost > 9 hours to load these data).
I tried the ways below to import the data (all of these tables is partitioned):
1. normal impdp (single thread that is, parallel = 1): it takes a long time (> 24 hours).
2. normal impdp but partition-wise. It was completed in relatively less amout of time compared to the 1st method.
3 fall drop the index, framed adding another scheme in the same forum that includes data, and then recreate the index (whole process takes about 9 hours)
My questions at all:
1. is there any other way/trick in the book that I can try to put the data in less time
2. what I pointed out that even if I give parallel = 8 or more, sometimes parallel workers are laid and sometimes not. Can someone tell me why?
3. How can I come to know (before running the impdp) that my parallel article will spawn parallel workers or not. As to how I will come to find out, I searched this topic but without success.
I don't know what strategy to follow, because it is an involved and repetitive task for me. Because of the task above, I am not able to focus on other DBA tasks because of what comes to me.
See you soon,.
Malikaassuming that you have a table with 3 clues, then create a script for each index (reblace index_name_n with your index name) and start them at the same time, after the importation of the table is complete
DUMPFILE=or NETWORK_LINK= DIRECTORY=DATA_PUMP_DIR LOGFILE= CONTENT=ALL PARALLEL=1 JOB_NAME=IMP_ INCLUDE=TABLE_EXPORT/TABLE/INDEX:"IN(' ')" TABLES= . Change the following settings when importing:
increase pga_aggregate_target
increase db_writer_processes
db_block_checking = false
db_block_checksum = falsethe value undo and temporary ts autoextend
Set noarchivelogmode
create logs of restoration of 4 GBHTH
How to cut the large table into pieces
I'm trying to derive some of generic logic that would be cut into pieces of defined size a large table. The goal is to perform the update into pieces and avoid questions too small restoration. The full table on the update scan is inevitable, given that the update target each row of the table.
The BIGTABLE has 63 million lines. The purpose of the bellow SQL to give ID all 2 million rows. So I use the rownum 'auto line numering field' and run a test to see I could. I expected the piece of fist to have 2 million rows, but in fact, it is not the case:
Here is the +(NOTE I had many problems with quotes, so some ROWID appears without their enclosing quotes or they disappear from current output here) code +:
Amzingly, this code works perfectly for small tables, but fails for large tables. Does anyone has an explanation and possibly a solution to this?select rn, mod, frow, rownum from ( select rowid rn , rownum frow, mod(rownum, 2000000) mod from bigtable order by rn) where mod = 0 / SQL> / RN MOD FROW ROWNUM ------------------ ---------- ---------- ---------- AAATCjAA0AAAKAVAAd 0 4000000 1 AAATCjAA0AAAPUEAAv 0 10000000 2 AAATCjAA0AAAbULAAx 0 6000000 3 AAATCjAA0AAAsIeAAC 0 14000000 4 AAATCjAA0AAAzhSAAp 0 8000000 5 AAATCjAA0AABOtGAAa 0 26000000 6 AAATCjAA0AABe24AAE 0 16000000 7 AAATCjAA0AABjVgAAQ 0 30000000 8 AAATCjAA0AABn4LAA3 0 32000000 9 AAATCjAA0AAB3pdAAh 0 20000000 10 AAATCjAA0AAB5dmAAT 0 22000000 11 AAATCjAA0AACrFuAAW 0 36000000 12 AAATCjAA6AAAXpOAAq 0 2000000 13 AAATCjAA6AAA8CZAAO 0 18000000 14 AAATCjAA6AABLAYAAj 0 12000000 15 AAATCjAA6AABlwbAAg 0 52000000 16 AAATCjAA6AACBEoAAM 0 38000000 17 AAATCjAA6AACCYGAA1 0 24000000 18 AAATCjAA6AACKfBABI 0 28000000 19 AAATCjAA6AACe0cAAS 0 34000000 20 AAATCjAA6AAFmytAAf 0 62000000 21 AAATCjAA6AAFp+bAA6 0 60000000 22 AAATCjAA6AAF6RAAAQ 0 44000000 23 AAATCjAA6AAHJjDAAV 0 40000000 24 AAATCjAA6AAIR+jAAL 0 42000000 25 AAATCjAA6AAKomNAAE 0 48000000 26 AAATCjAA6AALdcMAA3 0 46000000 27 AAATCjAA9AAACuuAAl 0 50000000 28 AAATCjAA9AABgD6AAD 0 54000000 29 AAATCjAA9AADiA2AAC 0 56000000 30 AAATCjAA9AAEQMPAAT 0 58000000 31 31 rows selected. SQL> select count(*) from BIGTABLE where rowid < AAATCjAA0AAAKAVAAd ; COUNT(*) ---------- 518712 <-- expected around 2 000 000 SQL> select count(*) from BIGTABLE where rowid < AAATCjAA0AAAPUEAAv ; COUNT(*) ---------- 1218270 <-- expected around 4 000 000 SQL> select count(*) from BIGTABLE where rowid < AAATCjAA0AAAbULAAx ; COUNT(*) ---------- 2685289 <-- expected around 6 000 000
Here's the complete SQL code that is suppposed to generate all the predicates, I need to add update statements in order to cut into pieces:
Nice but not accurate...select line from ( with v as (select rn, mod, rownum frank from ( select rowid rn , mod(rownum, 2000000) mod from BIGTABLE order by rn ) where mod = 0), v1 as ( select rn , frank, lag(rn) over (order by frank) lag_rn from v ), v0 as ( select count(*) cpt from v) select 1, case when frank = 1 then ' and rowid < ''' || rn || '''' when frank = cpt then ' and rowid >= ''' || lag_rn ||''' and rowid < ''' ||rn || '''' else ' and rowid >= ''' || lag_rn ||''' and rowid <'''||rn||'''' end line from v1, v0 union select 2, case when frank = cpt then ' and rowid >= ''' || rn || '''' end line from v1, v0 order by 1) / and rowid < AAATCjAA0AAAKAVAAd and rowid >= 'AAATCjAA0AAAKAVAAd' and rowid < 'AAATCjAA0AAAPUEAAv'' and rowid >= 'AAATCjAA0AAAPUEAAv' and rowid < 'AAATCjAA0AAAbULAAx'' and rowid >= 'AAATCjAA0AAAbULAAx' and rowid < 'AAATCjAA0AAAsIeAAC'' and rowid >= 'AAATCjAA0AAAsIeAAC' and rowid < 'AAATCjAA0AAAzhSAAp'' and rowid >= 'AAATCjAA0AAAzhSAAp' and rowid < 'AAATCjAA0AABOtGAAa'' and rowid >= 'AAATCjAA0AAB3pdAAh' and rowid < 'AAATCjAA0AAB5dmAAT'' and rowid >= 'AAATCjAA0AAB5dmAAT' and rowid < 'AAATCjAA0AACrFuAAW'' and rowid >= 'AAATCjAA0AABOtGAAa' and rowid < 'AAATCjAA0AABe24AAE'' and rowid >= 'AAATCjAA0AABe24AAE' and rowid < 'AAATCjAA0AABjVgAAQ'' and rowid >= 'AAATCjAA0AABjVgAAQ' and rowid < 'AAATCjAA0AABn4LAA3'' and rowid >= 'AAATCjAA0AABn4LAA3' and rowid < 'AAATCjAA0AAB3pdAAh'' and rowid >= 'AAATCjAA0AACrFuAAW' and rowid < 'AAATCjAA6AAAXpOAAq'' and rowid >= 'AAATCjAA6AAA8CZAAO' and rowid < 'AAATCjAA6AABLAYAAj'' and rowid >= 'AAATCjAA6AAAXpOAAq' and rowid < 'AAATCjAA6AAA8CZAAO'' and rowid >= 'AAATCjAA6AABLAYAAj' and rowid < 'AAATCjAA6AABlwbAAg'' and rowid >= 'AAATCjAA6AABlwbAAg' and rowid < 'AAATCjAA6AACBEoAAM'' and rowid >= 'AAATCjAA6AACBEoAAM' and rowid < 'AAATCjAA6AACCYGAA1'' and rowid >= 'AAATCjAA6AACCYGAA1' and rowid < 'AAATCjAA6AACKfBABI'' and rowid >= 'AAATCjAA6AACKfBABI' and rowid < 'AAATCjAA6AACe0cAAS'' and rowid >= 'AAATCjAA6AACe0cAAS' and rowid < 'AAATCjAA6AAFmytAAf'' and rowid >= 'AAATCjAA6AAF6RAAAQ' and rowid < 'AAATCjAA6AAHJjDAAV'' and rowid >= 'AAATCjAA6AAFmytAAf' and rowid < 'AAATCjAA6AAFp+bAA6'' and rowid >= 'AAATCjAA6AAFp+bAA6' and rowid < 'AAATCjAA6AAF6RAAAQ'' and rowid >= 'AAATCjAA6AAHJjDAAV' and rowid < 'AAATCjAA6AAIR+jAAL'' and rowid >= 'AAATCjAA6AAIR+jAAL' and rowid < 'AAATCjAA6AAKomNAAE'' and rowid >= 'AAATCjAA6AAKomNAAE' and rowid < 'AAATCjAA6AALdcMAA3'' and rowid >= 'AAATCjAA6AALdcMAA3' and rowid < 'AAATCjAA9AAACuuAAl'' and rowid >= 'AAATCjAA9AAACuuAAl' and rowid < 'AAATCjAA9AABgD6AAD'' and rowid >= 'AAATCjAA9AABgD6AAD' and rowid < 'AAATCjAA9AADiA2AAC'' and rowid >= 'AAATCjAA9AADiA2AAC' and rowid < 'AAATCjAA9AAEQMPAAT'' and rowid >= 'AAATCjAA9AAEQMPAAT'' 33 rows selected. SQL> select count(*) from BIGTABLE where 1=1 and rowid < AAATCjAA0AAAKAVAAd ; COUNT(*) ---------- 518712 SQL> select count(*) from BIGTABLE where 1=1 and rowid >= 'AAATCjAA9AAEQMPAAT'' ; COUNT(*) ---------- 1846369The problem is that your query implies that ROWID, and ROWNUM are classified in the same way. For small tables it is very often the case, but not for the larger tables. Oracle does not guarantee return records in the order the rowid. However usually it works this way.
You could test ensuring that get you the rownum after you ordered. And see if it works then.
select rn, mod, frow, rownum from (select rn, rownum frow, mod(rownum, 2000000) mod from (select rowid rn from bigtable order by rn) order by rn ) where mod = 0 /I'm lookng for a product where I can produce a PDF secure for several clients. When the document is finished, I want to fix it with a password, to make it more difficult to copy, but then I want to record in a secure location, send the link and the password to the clients. When customers go to download the PDF, they will have to if they accept the terms and conditions. If it is accepted, they can download the document. Working in DocumentCloud PDF services? Thank you.
Hi davidc21010281,
You can try the DC Acrobat Adobe Acrobat download free trial | Acrobat Pro DC. Where you can create a secure PDF file (using Acrobat|) Securing PDF files with passwords) & send them to your customers (send and track online documents |) Tutorials Adobe Acrobat DC), on the other end, customers can download the PDF but they would need the password/certificate in order to open the PDF file.
See also the FAQ of Adobe Document Cloud.
Kind regards
Nicos
OfficeJet 6500 has more all - all-in-one makes weird noises like strings for guitar was extirpated
Operating system is Windows 7. Bought 2 years ago. Worked fine until about 2 months ago, when he started to make loud noises. Will print still, she began to stop in the middle of print intermittently job. DIY online resources say that it needs to be cleaned. I hesitate to try to do this without instructions or other suggestions from HP or a member of the community who has solved this same problem. Cannot find any printer repair shop that will serve an inkjet. Any ideas?
Hello my shadow,
Welcome to the HP Forums! I understand your Officejet 6500 a fact of loud noises. Please follow these steps to try to solve your problem:
Now, determine the noise is coming from can be difficult, and it could also be a number of reasons why.
Make sure that the printer is connected to a live wall, not a surge protector. This step is required because it will check if you have the same problem.
Sometimes paper stuck in the printer can make these noises or to transport back and forth.
This document here, HP is the right section to double check there is no paper in the printer.
Try to clean the rollers of paper of this HP document on The Noise is produced when you print.
I would like to know how your progress.
Ms more recent update for my VISTA plus old (2008 Acer laptop) was the last event, now cannot start PC... try to recovery without success, a loop back and asking to recover or normal boot... Attached to jumps, safe to ask if I want to recover... I never received an OEM of VISTA version, but the first time having problem after all these years... Help, please... Would contribute to a boot disk, if so, how can I get a copy?... Thanks, Dave * address email is removed from the privacy *
Hello
See if that helps you.
Do a Safe Mode system restore to before the problem started.
http://bertk.MVPs.org/html/restoresysv.html
How to access Safe Mode
http://www.bleepingcomputer.com/tutorials/how-to-start-Windows-in-safe-mode/#Vista
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
If it doesn't, try a startup repair and / or a system restore using a DVD of Vista from Microsoft
Manufacturers recovery disks normally do not have Service Options; they are normally a relocation to the factory only settings option.
Here is the guide to repair Options using a Vista DVD from Microsoft.
If a friend or a work acquantance of yours has one, you can borrow and use it for repairs.
http://www.bleepingcomputer.com/tutorials/repair-Windows-with-Windows-Startup-Repair/
Table of contents
- Overview of Windows Vista repair options
- How to perform an automatic repair of Windows Vista using Startup Repair
- Advanced Tools Overview
- Conclusion
If you do not or can not borrow a Microsoft DVD there is a download of a file ISO of Vista Startup Repair available that you can put on a Bootable floppy to make the above startup repair and that the method is recommended by a large number of posters in these Forums.
Unfortunately, you have to buy it.
Here is a link to it:
http://NeoSmart.net/blog/2011/Windows-Recovery-discs-updated-reinstated/
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
And here's how to use Recovery of Acer.
http://Acer.custhelp.com/app/answers/detail/A_ID/2631
To start the system recovery:
- Restart the computer.
- When the Acer logo appears on the screen, press the left Alt and F10 keys.
- If you are prompted with a Microsoft Windows splash screen, press the Enter key.
- After that the Acer eRecovery Management application is loaded, select your type of restore.
- Read the review and then click Next when you are ready.
- Click Next to start the restore process. It may take 10 minutes up to an hour fom anywhere to restore.
- Once the restore is complete, your computer will restart. After the reboot it will load Windows and start the installation of your software and drivers. Your computer will restart several times during this process. Once they are all completed, your computer will be like it was when you bought it first.
See you soon.
need screws for hard drive for HP Envy Phoenix 800-060
Where can I order some of these guide of cylinder head screws that you screw on the sides of a new drive, so it will slide along the rails and lock in place in the internal slots 3.5 "? No extra charges not supplied with my computer. I need to install 2 drives more then need 8 screws (4 screws by the reader).
I called the computer of our local Mom & Pop shop and they offered to sell me a dozen screws for $1. I guess that's the only way. HP does not have.
a faster way for PDM-to-Excel conversion?
I connect my packets received using blocks PDM, since it is suggested that IO low is the fastest. Since I need data in formal Excel, after my experience, I run a small code that uses 'Reading file of measure' and 'Write in the file of the measure' blocks to convert TDMS to Excel.
This conversion takes too long, for example 15 minutes from port of 1 million bits of PDM for Excel (I connect packets in their binary form, of 1 and 0). I have attached the VI conversion.
I have 2 questions:
1. does anyone know any faster way for the conversion of PDM in Excel?
2. I need the block 'Reading files measure' in my conversion code since the packets received are saved in TDMS in the form of a single vector, and I need to convert this very long vector in a matrix where each line corresponds to a received packet. Is it possible to make connecting TDMS in the form of a matrix, instead of one vector? This can be slow down my code much.
Thank you!
Hi filipfilip,
Have you considered using the TDM Excel add-in? You can then save the resulting Excel workbook and get the desired file format.
More information can be found here:
http://www.NI.com/white-paper/4906/en/
There is a solution on this post on the forum too which can allow you to do this automatically. I don't know how much faster it would be than your current method but I think it would be interesting to give it a go.
http://forums.NI.com/T5/LabVIEW/convert-import-TDMS-to-Excel/m-p/1088746
I hope this helps, please let me know if you have any questions.
Thank you
Charlotte N.
I want to allocate more disk space for my c drive and remove the drive d
I want to allocate more disk space for my c drive and remove the drive d. I 26 gig on the d drive and only using less than 1% of it, and I have the same amount on c, but only 39% c left. How to do this.
LEM explained the problems that you tried to resize partitions on the same drive.
You can create more free space in C in carrying one of the measures suggested below.
The default allocation for the restoration of the system is 12% on your C partition is more generous. I have them would be reduced by 700 MB. Make my computer right click on your icon, and select System Restore. Place the cursor on your C drive select settings but this time find the slider and drag it to the left until it shows 700 MB and output. When you get to the settings screen, click on apply and OK and leave.
A flaw that might be useless which is for temporary internet files, especially if you keep no copies on the disk offline. Setting the default value is 3% of the walk. Depending on your attitude to copies offline, you could bring it to 1% or 2%. In Internet Explorer, select Tools, Internet Options, general, temporary Internet files, settings to make the change. At the same time, look at the number of days, the story stands.
The default allocation for the basket is 10% of the disk. Change to 5%, which should be enough. In Windows Explorer hover over your Recycle Bin, right click and select Properties, Global and move the slider from 10% to 5%. However, try to let you become so complete that if it is complete and you delete a file by mistake it will bypass the Recycle Bin and have gone forever.
You can generate more space in the system (usually C) the folder move partition.
For temporary Internet files, select Start, Control Panel, Internet Options, temporary Internet files. Settings and move back.
To move the storage folder Outlook Express select from Outlook Express Tools, Options, maintenance, store folder and change. http://www.tomsterdam.com/insideoe/files/store.htm.
How to change the default location of the My Documents folder: http://support.microsoft.com/?id=310147
You may also change the default locations of the files in Microsoft Office programs when you choose to move the My Documents folder. For Word, go to tools, Options, file locations, highlight the Documents, click on edit and change the path. For Excel, go to tools, Options, general, and change the default path.
My Documents is one of the many the created system of special folders, which include my pictures, and my music. It can be more easily modified using TweakUi. Download TweakUI, one of MS powertoys, here: http://www.microsoft.com/windowsxp/pro/downloads/powertoys.asp.
In TweakUi, select workstation, special folders. You can scroll down to see the full list of special folders to the left of the button to change the location.
You can move programs, but to do this, you must uninstall and reinstall the program. With Word and Excel, the existing data files are not affected by reinstalling. Most of the work in question is going to be reinstall all updates issued after those that are included with the original Microsoft CD / DVD.
If your drive is formatted as NTFS another potential gain arises with your operating system on your C drive. In the Windows directory of your C partition you will some uninstall files in your Windows folder in general: $NtServicePackUninstall$ and $NtUninstallKB282010$ etc. These files can be compressed or not compressed. If compressed text the name of the folder appears in blue. If these files are not compressed you can compress. Right-click on each folder and select Properties, general, advanced, and check the box before you compress contents to save disk space. On the general tab, you can see the winning amount by deducting the size on disk size. File compression is only an option on an NTFS formatted disk partition / partition.
I'd be interested to see a report of Disk Defragmenter. Open Disk Defragmenter and click analysis. Select view report, and then click Save as and save. Now find VolumeC.txt in your My Documents folder. Open the file, place the cursor anywhere in the file, select Edition, select all to select all the text and copy and paste into the body of your message. To do this, before you run Disk Defragmenter because it is more informative.
Select Start, all programs, accessories, System Tools, cleaning disk to emptying your trash, delete temporary Internet files and other selected options. I recommend also you click Other Options, System Restore and delete all but the last system restore point. Run Disk Defragmenter
Using the system restore option is most appropriate when your system is slow and you need to increase the free disk space on your C partition. If you have errors that could be solved by using the system restore to your system settings back to before that the error occurred initially, do not use this option.
Select Start, Control Panel, Folder Options, view, advanced settings and check the box in front of "show files and folders" and 'Hide protected operating system files' are unchecked. You may need to scroll down to see the second element. You should also make sure that the box before "Hide extensions of known file types" is not checked. Notwithstanding, there are some files that are hidden. Again, you will not see the System Volume Information folder.
Maybe you are looking for
-
I lost my Google search. How can I get that back?
Google says click on arrow, I don't have a box to click the arrow on. Now what?
-
OfficeJet 6500 has more printing problems
My Officejet 6500 has more (model CN557A) is connected through the USB port. My operating system is XP. I can scan my computer, I can copy and print from the printer control panel, but I can't send anything to print from my computer. This proble
-
My Guest Windows XP account does not recognize the extensions of PDF Adobe Reader 10.
Regarding the files Adobe Reader 10 and pdf. My account invited Windows XP does not recognize the extensions of files Adobe Reader 10. The program is installed and works very well in my admin account. When I try to open a pdf file in my guest account
-
Hallo How can I save my settings to location of memory 1 or 2? I put memory button c1 and guide button c2 in the dialogue of customization of the help button. I change fine in raw, auto hdr to autobracketing with 3 stops and I choose my preference of
-
Extremely slow performance on Acer AO722 netbook
I use a netbook Acer model AO722 with 2.0 GB of RAM 9 (1.73 GB usable) and Windows 7 Home Premium (64 bit) OS. The system is updated with all Windows updates. 2-3 weeks during the performance of the system has declined considerably. Here are the sy