Should I use the design of producer/consumer model (Instead of Globals)?
Hello everyone.
I have a request including several loops in it. A loop reading data series and he analyses for use in the other loops, another loop acquires via DAQmx data and performs calculations on it for use in other loops, the other formats the data from two loops and poster and one last test data. I was wondering if this is a good candidate for the design of producer/consumer model.
For now, I use global variables to send data from the series and DAQmx loops to other loops. I use motors of the action for the different parts of the program that should be used everywhere, as the serial port. The test loop needs than the most recent data to run his test.
Thanks for your suggestions!
The short answer is Yes. If nothing else using queues to pass data will allow your various loops inactive if no data is present. By using globals your curls must continuously survey to see if the data has changed. You always are beter off if you can make your request, driven by events rather than to use the polling stations.
Tags: NI Software
Similar Questions
-
Buffer could replace the queue in the design of producer/consumer model
Hello
I have a question to which the task of buffer to store the data and the queue is also of the same thing so we could use the inplace queue buffer in a design of producer/consumer model.
No, these examples of buffer not almost equal to a queue, and never "replaces" queue at the producer/consumer.
The advantage the most important of the queues for the producers/consumers (which none of the other mechanics buffer sharing), it is that it works activities to warn the reader that the data is available. So if you would simply replace the queue by mechanics of tampon too developed that you have attached to your last post, you will lose a large part of the object using producer/consumer.
Thus, to compare the two mechanics:
-Tail works activities, while the example of the buffer is not.
-Tail must allocate memory during execution if several items are written in that corresponding queue. This also applies to the buffer (must be resized).
-Given that the buffer is actually simply a table with overhead, memory management becomes slow and messy with the increase in fragmentation of memory. Queues to play much better here (but have their limitations, there also).
-Overload of the buffer (the table manipulation) must be implemented manually. The queue functions encapsulate all the necessary features that you will need. So the queues have a simple API, while the buffer is not.
-Given that the buffer is simply a table, you will have a hard time sharing the content in two parallel running loops. You will need to implement an additional charge using data value references to manage the buffer or lose a lot of memory using mechanics as variables. Lose the memory, you will probably encounter racing conditions so don't think not even on this subject.
This led to four '+' for the queue and only a single point where 'buffer' is equal to the queue.
Hopefully, this clears things up a bit.
Norbert
-
Data types in the design for the producer consumer model
Is it possible for me to use any type of data in a model of design producer consumer, without specifying specific data type?
what I mean is if there is a way to connect to a data type with which I can use any other type of data, not to mention that one that I have connected, and if not, how can I specify the data type for a number or any other data type, for use in a design of producer-consumer model?
You can make a part of your cluster of data a Variant. It will take any type of data. A common architecture for the producer/consumer is a cluster which is an enum and a Variant. The enum contains all possible "orders", you might want to send. The variant contains data that could be of any type.
Ungroup you in the consumer and get the enum and Variant. Attach the enum to a case structure. In the specific case, convert the variant type in a data type of regular LabVIEW and with it as you please.
-
acquisition and recording of analog data with producer consumer model
Someone on this forum, in a separate last week discussion, suggested that I use the producer model consumer data acq. My ultimate goal is to acquire analog channels 1-4 continuous data, display graphical band style and save the data on the boot disk when the user presses the 'Start Saving' button (and will continue to display recorder cards). Economy will stop when the user presses the button "Stop Saving" but strip map will continue to operate.
My attempt to use the producer-consumer model is attached (LV 8.5 only). It does not work. I have not tried to implement for recording user controls - just trying to make simple continuous display and save (1 channel) at this stage, using this model. VI runs, but the graphic Strip is never updated with the actual data, and the data file that is saved has zero byte inside.
Thank you.
WCR,
Looked at your code, and you are right. It won't work.
Take a look at this example:
http://decibel.NI.com/content/docs/doc-2431
The VI of the acquisition must be inserted in the loop of the producer. In addition, you must tell him how many samples for (otherwise, it will get 0).
-
Original title: windows 7 Teredo: how to configure the teredo prefix
Hello
I deployed a private teredo server, I'm not using the public prefix 2001: 0 / 32, instead, I use the prefix 2001:2222 / 32But I got win7 can't connect to my server if I use the prefix 2001:2222 / 32.A test, I put the prefix 2001: 0 / 32, win7 it can connect.How can I do so that win7 customer teredo can connect to my private server that use the prefix 2001:2222 / 32?Hi,
The question you posted would be better suited in the TechNet Forums.
I would recommend posting your query in the link below.
Windows Server forums:
http://social.technet.Microsoft.com/forums/en-us/category/WindowsServer
I hope that the information above helps you.
-
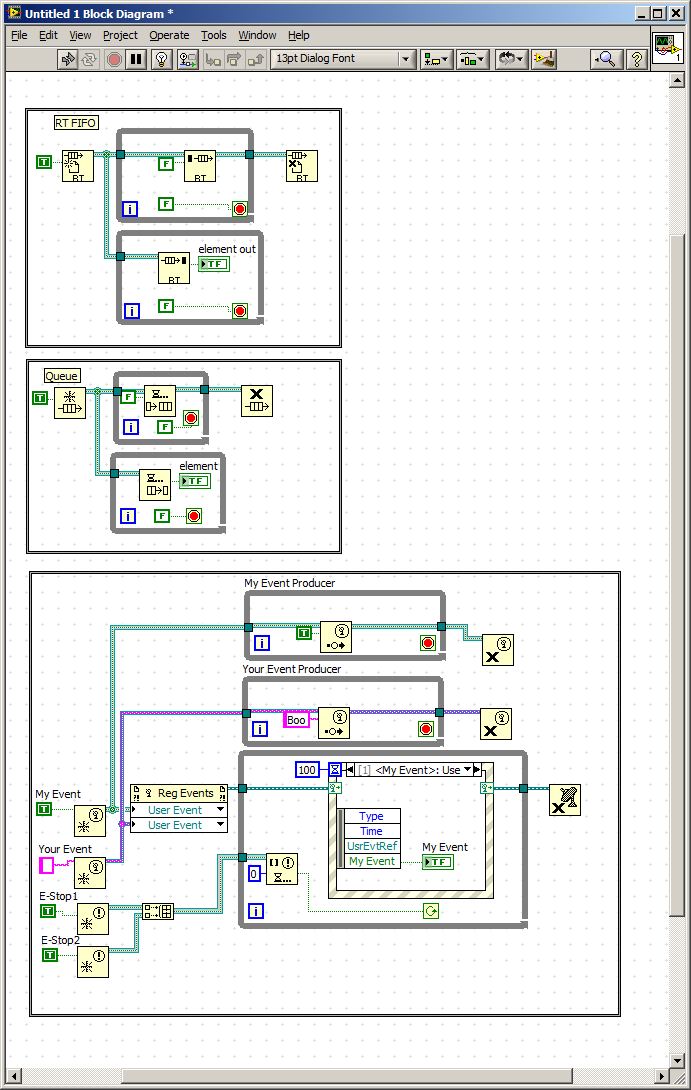
What is the fastest method producer consumer. Queue, RT-FIFO, event
Hi all
Another question completed for the pro:
I recently inherited the labview code that uses RT-FIFO for the transfer mechanism in the architecture of the producer consumer.
The code was first written in 3-4 years and is currently in LV8.6. It is possible that the reasons for the architectural decision no longer exists.
I am qualified using a producer consumer queued architecture,
I understand the RT-FIFO Architecture.
I started using an architecture based on events from the user.
(I have attached samples of each)
I also see the existence of a priority queue
Each method has its own capabilities and gaps, that hand, nobody knows the relative performance of each method.
(Assuming that the only process)
I would expect RT-FIFO to be faster, there seems to be a version of low characteristic of a standard queue.
What is the perfornace hit to use a coding user-friendly queue more
RT-FIFO description talks about commications between the time-critical and lower priority threads.
Until today, I thought that the queues had the same capacity.
I've included an event method that I commonly use for review by peers and help from other users...
It allows to:
1. several producers with different types of data
2. process 37 production order.
3 allows asynchronous verification of functional notifiers such as stop, start and abort.
4. in a system not real-time, it can include interactions of façade.
What I do not understand on this subject, that's what are overhead or thread priority changes that may occur using this architecture (it solves a lot of problems for me).
Thanks in advance,
Hi Timmar,
Here's a KB article on some frequently asked questions about the RT FIFO: http://digital.ni.com/public.nsf/allkb/7AE7075AF1B2C58486256AED006A029F?OpenDocument
The more relevant question is #4, I posted below.
What is the difference between RT FIFO and queues?
Functionally, RT FIFO and LabVIEW queues are two pads of first in, first out. However, here are the main differences between them:- RT FIFOs run deterministically in LabVIEW and evanescent code queues are not. This comes from the fact that queues use block calls during read/write to the resource shared, while RT FIFOs use non-blocking calls.
- RT FIFO are fixed size while queues develop when items are added to them.
- RT FIFOs will execute the code, even if there are input errors. They can (and will) produce new errors and spread the existing errors.
- Queues work with any type of data, while the data types that can be used with RT FIFOs are limited. Generally any type of data involving allocations of extra memory can be used with RT FIFOs to preserve determinism.
Let us know if you have persistent questions!
Ryan
-
Update the controls on the front panel producer consumer
Hello
I wanted to ask you a few tips.
Usually, when I implemented a consumer producer I use producer to create items from queue whose state of the enum and pack all the necessary data in the process of the event in a Variant.
Then the consumer does all the work.
There are two areas where I feel that I could not be using the best approaches...
(1) when I need to update a control on front panel I Pack a reference to this control on front panel in the variant in order to access the property nodes in the consumer and to update.
I have attached photos with an example. It's simplified code where the user must perform a task of data acquisition in the analysis of certain parameters. The code increases the setting of a fixed amount to each race to help the user in its sweep.
Is there a best way to do this?
(2) when events require the same control to be plugged into the variant for the handling of the loop of consumer I create local variables or references to this control to other events. Would it be better to have a registry change that crosses the loop producer which gets updated values of façade at each time the loop iteration?
Thank you.
Because you use a loop of events such as the producer, I would use user events to update your controls. This way you are not circulate references just to set/update a control. You can make a user event and handle this event with the structure of your event. Your client sends just the event with all the necessary data. I found this configuration really useful since it retains all the GUI code centralized in a single loop.
-
When should I use the IRIS PRO that came with my 8600 instead of the built-in OCR scan-to-text?
I just bought the Premium Pro 8600. I installed the HP software, that gives me an OCR option for scanning. I also installed the second disc, IRIS PRO, which is OCR, too. When should I use each?
I would use the software OCR supplied with the printer during the formatting of the document to be scanned is simple and use the IRIS PRO when the formatting is more complex. You should expect some distortion of the two programs well formatted. Hope that helps.

-
Error: Could not insert model using the designer of ODI
I installed ODI in Windows XP. When I log in the designer of the ODI, I want to insert a new model.
Definition-> technology, I select 'Oracle', for 'Action Group', I select 'Default Oracle', but "logical schema" is shown not "defined", so I can't select anything, just select not "defined".
Reverse-> context, is showing "undefined", it's the only option I see upside-> context.
But if I want to apply and save the setting, an error message pop up and say: 'the opposite context of the field is required.
How to insert the Oracle model in the designer of the ODI?
Thank you!
Here are my steps:
1. connect to Designer
2 insert the template.
3. on the definition tab, fill in the name field.
4. in the area of technology, select the model technology. -J' I select Oracle
5. in the field of logic diagram, select the logical schema which will be the basis for your model. -No logical schema can be selected?
6. go reverse tab, and then select a context that will be used for the model reverseengineering.
Click on apply. -No context can be selected?
7. apply - mistake happens!In the topology Manager, you will need to manually create the name of the logical schema to be applied to a context for Oracle technology.
Open the topology Manager
Go to the physical architecture.
Expand the right-click Oracle Technologies, database server insert > enter the connection details. Apply test.
Select your schemas, go tab context, insert, select a frame and enter a logical schema name.
Now go to the designer and follow in your footsteps.If you have a read here he goes through the steps in the topology Manager, is for sql server, but the concept is the same for Oracle.
See you soon
See you soon
John
http://John-Goodwin.blogspot.com/ -
Is there a recovery for an Acer C720P image, or should I use the 720 recovery image?
I would like to create a USB stick recovery, but am unable to find an image for my Acer C720P. May then jeutiliser the 720 generic write on the USB recovery image I want to use for the recovery / emergency purposes? Any help apreciated.
Hi globetrotterdk,
Yes, the creation of the image in the Chrome operating system or by using the recovery utility of Chrome on a PC base with a Chrome browser will allow you to create a backup of Windows. The version of Chrome OS will be determined by what you and your material, so no reason to choose anything and for recovery of Chrome utility, they are trying to simplify this away so many different types of chromebooks, use the generic C720 will work for you.
Link to a related discussion: http://community.acer.com/t5/Chromebook/Unable-to-creat-recovery-image-for-C720/m-p/285320#U285320
Hope this helps,
Cory -
What should I use the incremental update for IKM Oracle?
IM missing some conditions before using the incremental update
I have a simple integration of an Oracle source data source table directly to another target Oracle data source table
I'd like to run a simple merger on a periodic basis
Source table that contains data, the target table is created and set in the model
Project created, put two tables in mapping
LKM specified LKM SQL for Oracle (I won't use DBLink)
Key of the target table are defined
I go to set the IKM but cannot choose the incremental update option

Probably a new problem user but can't seem to find a solution
So it's a stale issue that I have long found the answer and thought I would post it here just in case someone else is beginner and difficulties as well
For the incremental update be visible the following must be in place:
(1) the IKM that supports the update must be visible in the project, as shown in the diagram above - that's what our ODI comes with
(2) in the logical scheme of the model to the target in the context table to see its properties
(3) set a goal on the properties of incremental update
(4) now put target in context in the physical tab
(5) IKM Oracle Fusion is now visible in the knowledge of integration Module
-
utils is a packege so should I use the SQL instead of utils.
Hello
everything in translating my MS in mssql to oracle is converted into code bit: utils
utils is a set I think so is it good to use it or do I find any equivenlent sql function.
so please tel me oracle sql function for utils.patindex ();
Yours sincerelyAn Oracle database is not delivered with a package called "utils". We have no idea what is this package. We do not know what it contains.
If someone in your organization or a tool that you use to convert the SQL Server T - SQL code to Oracle PL/SQL code created a package which simulates some T - SQL functions, you must determine if it is useful to use this package or using the built-ins Oracle. It may be wise to normalize the using the utils package if the hope is that the vast majority of the code will be converted by a tool and not touched by man so that there is consistency between the code base. It may be wise to normalize the Oracle built-in functions if the goal is to make easily understandable code for Oracle developers who do not know the T - SQL functions that are simulated. This isn't something that we can answer for you.
Justin
-
VISA SERIES termination character producer consumer model
Hello
I'm developing a HMI to receive data from a sensor.
Material sensor is built in my company and I have no flexibility with her. Only 2 RX & GND wires, no possibility of
hardware handshake.The sensor send to an RS232 com port a string hex each 1 s, 10 s, 60 years or more and I can not know the frequency.
So, I scan each data bytes to the serial port and serial port with VISA Read 20ms. At the end of the string hex sent by the sensor
There is a stop character but I don't how to use it.I use the model producer/consumer do not lose any data.
In fact, I read and concatain received data (with VISA READ) until I got the right number of bytes (because I know the size of)
the sent hexastring is 495 bytes).
But in the real work, I don't know the size of the data to be received by the sensor. (<500>So, I want to use the character of endpoint to stop the loop of producer that contain VISA READ.
Should what special function or the property node I use to do this?
I've attached a screenshot of JPEG of my code.
PS: for the development of the VI, I simulate the sensor data with another PC that sent the hex string in loop
with the stop character.CHRI = s = nour wrote:
HelloBut in the real work, I don't know the size of the data to be received by the sensor. (<500>
A method to read an unknown number of bytes: put just the bytes to the Port in the whole loop (not read). Place the output of bytes to the Port into a shift register and compare the latest iteration with the current. When the number stops change (current loop = last loop) then all bytes have arrived. Bail out of the loop so directly while reading VISA.
-
I want to use the full width of my screen at any time.
Menu bars are full-width but the content is not, in fact it is about 1/2 possible width.
I bought a large wide screen to use it without having to increase the size of all fonts.Many sites Web uses a fixed width layout and do not automatically expand to fill the available space. It is perhaps for aesthetic reasons or for readability (it is more difficult for your brain to long strings).
Firefox is not a built-in feature to change the layout, but there could be an add-on that does this.
I understand that you do not want to increase the font size, but... Firefox zoom feature also expands the page layout and the image proportionally in order to preserve the overall design of the site. This article describes this feature in detail: the font size and zoom - increase the size of the web pages.
If you find that you are constantly zooming all the sites by a comparable amount, there are modules, that you can use to set it as your default zoom level. For example:
-
OGG for java: how to use the token in a velocity model
Hello community,I need help to solve my problem.
I have an extraction process that extract data from a table only on the insert.
I want to insert this information in a jms queue. but I need more information to reproduce, so I use sqlexec and tojken to store the information in the file exttrail.
I use an extract data pump to read data from the exttrail file and place it in a jms queue using a velocity template.
My question is: how to read "user fees" in a model of speed?
Thanks in advance for your help
Concerning
JMBien
Following extracted files and model speed
-----------------------------------------------------------------------------------------------------------
X_FR2FRH
SUCH X_FR2FRH
SOURCEDB SFRH
EXTTRAIL O:\GoldenGate\OGG_FRH\LT_FRH\FR2\FR
TRANLOGOPTIONS MANAGESECONDARYTRUNCATIONPOINTGETREPLICATES
--H
TABLE "dbo." " HISTO_STATUT_WKF_MSG', COLSEXCEPT (_Timestamp),
SQLEXEC (ID performance(1), QUERY "select CrMsgId, OrdrReleaseDtTm from cmc, HISTO_STATUT_WKF_MSG hswm CORE_MSG_COMPL where hswm.") IdHistoStatutWkfMsg =? and cmc. CrMsgId = hswm. IdMsg and IdTypeWkf = 3 and IdStatutWkf = 1 ", &
PARAMS (p1 = IdHistoStatutWkfMsg)), and
CHIPS (ORDRRELEASEDT = @GETVAL (performance(1). OrdrReleaseDtTm), CRMSGID = @GETVAL (performance(1). CrMsgId)));--------------------------------------------------------------------------------------------------------------------------------------------------------------
PFR2RJMS :
EXTRACT PFR2RJMS
SOURCEDB SFRHSETENV (GGS_USEREXIT_CONF = "dirprm/PFR2RJMS.properties")
SETENV (GGS_JAVAUSEREXIT_CONF = "dirprm/PFR2RJMS.properties")
CUSEREXIT dirprm/ggjava_ue.dll CUSEREXIT-PASSTHRU - INCLUDEUPDATEBEFORES-getupdatebefores
getInserts--H
TABLE dbo. HISTO_STATUT_WKF_MSG;GET_USER_TOKEN_VALUE (OrdrReleaseDtTm, 8);
ignoreinserts
-------------------------------------------------------------------------------------------------------------------------
Velocity model :
# (This is a comment) if in "operating mode, then you can remove the outer loop,
# and have only a 'foreach' iterate over the columns in the operation.
##
< numOps transaction =' ${tx. Size}' ts =' ${tx. Timestamp} ">"
#foreach ($op in $tx)
< action type = "${op.» SqlType}"table =" ${op. " TableName} ">"
#foreach ($col in the $op)
< column name = "${col." OriginalName}"index =" ${col. " Index}", isKey =" ${col.meta.keyCol} ">
< after >$ {col. AfterValue} < / after >
< / column >
#end
< / operation >
#end
< / transaction >jmbien wrote:
...
I have an extraction process that extract data from a table only on the insert.
I want to insert this information in a jms queue. but I need more information to reproduce, so I use sqlexec and tojken to store the information in the file exttrail.
...
My question is: how to read "user fees" in a model of speed?
X_FR2FRH
...
TABLE "dbo." " HISTO_STATUT_WKF_MSG', COLSEXCEPT (_Timestamp),
SQLEXEC (ID performance(1), QUERY "select CrMsgId, OrdrReleaseDtTm from cmc, HISTO_STATUT_WKF_MSG hswm CORE_MSG_COMPL where hswm.") IdHistoStatutWkfMsg =? and cmc. CrMsgId = hswm. IdMsg and IdTypeWkf = 3 and IdStatutWkf = 1 ", &
PARAMS (p1 = IdHistoStatutWkfMsg)), &
CHIPS (ORDRRELEASEDT = @GETVAL (performance(1). OrdrReleaseDtTm), CRMSGID = @GETVAL (performance(1). CrMsgId)));--------------------------------------------------------------------------------------------------------------------------------------------------------------
PFR2RJMS:
EXTRACT PFR2RJMS
SOURCEDB SFRH
SETENV (GGS_USEREXIT_CONF = "dirprm/PFR2RJMS.properties")
SETENV (GGS_JAVAUSEREXIT_CONF = "dirprm/PFR2RJMS.properties")CUSEREXIT dirprm/ggjava_ue.dll CUSEREXIT-PASSTHRU - INCLUDEUPDATEBEFORES
-getupdatebefores
getInserts
--H
TABLE dbo. HISTO_STATUT_WKF_MSG;GET_USER_TOKEN_VALUE (OrdrReleaseDtTm, 8);
ignoreinserts
-------------------------------------------------------------------------------------------------------------------------
Velocity model:
#foreach ($op in $tx)
#foreach ($col in the $op)
${col. AfterValue}
#end
#end
In the excerpt from the source, you have two chips, ORDRRELEASEDT, and CRMSGID. On each operation on the dbo. HISTO_STATUT_WKF_MSG, these chips will be defined. (Other tables will not have these value tokens.) To use the chips in the model, use $op.getToken ("ORDRRELEASEDT") and $op.getToken ("CRMSGID"). Similarly for the "getenv" values defined by GG, $op.getEnv ("GGENVIRONMENT", "GROUPNAME")
In both cases, you can first check if the value is set, ${op.isEnvSet ("GGENVIRONMENT", "the GROUPDESCRIPTION")}, or ${op.getToken("ORDRRELEASEDT").isSet ()}; for example,.
token value: (is set? '${op.getToken("MY_TOKEN").isSet()}'): MY_TOKEN= #{if}($op.getToken("MY_TOKEN").isSet()) '$op.getToken("MY_TOKEN")' #{else} (not set) #{end}There is one caveat, however: process GoldenGate trail of data as a continuous stream, a single operation (insert, update, delete) at the same time. The only way that the GG Java adapter can "loop" on the operations in a transaction is by buffering all memory operations and then loop over them at the end (Alternatively, you can write a formatter Java custom which formats the data happens, each operation individually, and not stamp anything; but that cannot be done in speed (, assuming that you do not want to set txn as a msg JMS, rather than individual operations, sent as JMS messages.)
In general, there are two ways to format data trail in JMS messages: an operation per message, or of a message transaction. Using a txn/msg may seem simple, but imagine if you have a few jobs in bulk on the DB which transforms 100 millions of rows in a table in a single txn; Then, your message JMS maybe 100 MB (or several GB) in size (there is no way to know in advance). The GG JMS client might be able to send the msg (given enough memory), but it will probably lower the JMS server, or JMS clients consume the (huge) message.
But back to what tokens: If you loop on operations in memory swabbed and make a call to "getEnv" or "getToken", these are in fact reminders of NYI "extract" and will retrieve the value of getenv/token for the current operation - that is to say, the last operation as part of the operation - which is probably not what you want. The solution is to format each operation individually - you can do this automatically using Velocity templates if sending a msg by operation; otherwise, you will need to write a custom Java trainer that formats the message that each operation is received (not at the end of the tx), and you can still run the WAD Manager "tx" mode (i.e., sending a tx by msg) If you want.
Other smaller points:
- If you use GG 11.2 adapter, then you need not of the «setenv (...)» Properties); If you extracted 'foo', while it loads of 'foo.properties' from the directory dirprm automatically.
- GET_USER_TOKEN_VALUE is not used in the file of the prm. It's a value C user-output API callback (i.e., only used if C user-output (in C) coding). (I'm surprised that the prm file that allows here.)
- You can delete the 'getInserts' and 'ignoreInserts', because even once which is not used in this case. Changes/insertions/deletions are always "obtained".
- You may need to spend in all inserts/modifications/deletions (including 'before' values) to exit user Java so that the limits of tx be properly processed; This was necessary before 11.2 Java adapter, and IIR there is a bug that prevented these filters work as expected in earlier versions of 11.2. Alternatively, you can write filters in Java, by adding them to the file property: gg.handler.my_handler.filter = com.example.custom.MyEventFilter (where MyEventFilter implements com.goldengate.atg.datasource.DsEventFilter)
It will be useful,
-Mike

Maybe you are looking for
-
Portege 7220: Clearing BIOS password
HelloI just installed WinXP on my Portege 7220. I installed the utility download, but find that I can not open the HW installation application.I need to disable the BIOS password that had created a previous user.Advice please.See you soon,.NEIL
-
Tecra A8 - sound does not work on Server 2008 x 64
Hi I tried various dirvers and can't seem to get this to work. The driver installs fine, but then there is no sound on the headphones or speakers. I tried the util_mute_off_25847B without success. I have the dual boot and the sound works in the XP in
-
need to replace drive for A495
I changed from XP to 7 and I can't find my disk for my A495. Can I download or get a replacement drive. Thank you, Dennis
-
Internet 7 notwork does very well and I'm getting rather frustrated with her
I get messages saying that internet Explorer can not dispay the page
-
Functionality of the classic report checkbox column.
My requirement isI have a classic report based on sql query in this 1st column is checkbox.When I click on this check box, the value of the 2nd column is copied in the 4th column of the same rank.Assume that the 2nd column value is 100 after you have