SUMIF line is equal to the value of test and the line below is '-'
Hello
I have a spreadsheet numbers where a column has a list of names that are mixed with rehearsals and another column that has a value of profits to this name list.
Now, I want to determine the total profits from each of the names so I can see the total profit by name.
That part is easy, I just a SUMIF function that checks if the name corresponds to a specific name, and then adds the benefit altogether.
The problem I have is that in the names column, sometimes I'll have a name and then the next rows are just '-' indicating that they are of the same name. The SUMIF function that I use does not takes into account these values because they obviously do not match the name of the interest.
So my question is: is it possible to create a function that will check for a matching name and then if the next line '-', then add this value to the total as well. It has to work with several rows of '-' after the name.
The screenshot below is an example of what I mean because I realize that it does not have much sense.

So in this case, the total of Jess profit would be = 5 + 35 + 15 + 5 + 15 = 75
and the benefit of Gill = 30 + 30 + 20 + 40 = 120
I hope I did it is clear enough. Thank you in advance!
Oscar
Hi Oscar,.
Although it is possible to do, it will be a little clumsy, involving additional columns. It would be much easier to stop using the "-" and use the actual names instead. Order the popup format to create a list that makes it easy to list the names.
Quinn
Tags: iWork
Similar Questions
-
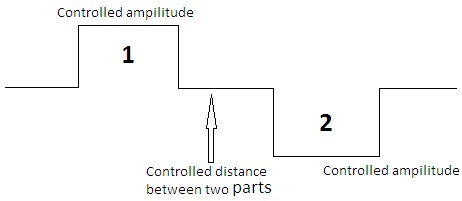
How can I design square wave which has a positive and negative values equal to the other and separated from each other by controlled time or distance, as indicated in the figure below. and enter this signal in a data acquisition.
At the time wherever you go for the beautiful diadram, you could have done the vi

Your DAQ would like a waveform (table of values and dt ak 1/sampling rate)
If you set the sampling rate you know the length of the array, create a matrix of zeros and set the values of the two amplitudes...
Because I don't want to connect other duties
here are some photosAnd it
does have a few drawbacksleaves to be desired in my solution, just think... rounding errors and what might happen if the tables are becoming more... -
Do 1 field equal to the value of the 2 fields.
How to make 1 field equal to the value of 2 text fields.
I've got text field 1 and I need to match the value in the address 1 field and the address field 2. Essentially, I need what is in the address 1 field and 2 combine into a single field, the text field 1.
Any suggestions?
Thank you
When in a field and trying to reference it, to use the «event.value "to access the value property of the field.» The value of the subject field is not updated until that leaves him the ground. I would use:
event... value = this.getField("FL052").value + this.getField("FL053").value;
For the calculation script customized.
-
Trigger - both equal to column values
Hi, I need your help once again ;)
I'm trying to create a trigger that the value of column = value in column B and columnB = column
So the values of columnA and columnB should always be equal
CREATE OR REPLACE TRIGGER tr_e_mvag_mva
AFTER
INSERT or UPDATE on buko_e_mvag
REFERRING AGAIN AS NINE OLD AND OLD
FOR EACH LINE
BEGIN
Update buko_e_mvag set: new.dummy_mvag = 1 where: new.mva = 1
Update buko_e_mvag set: new.dummy_mvag = 0 where: new.mva = 0
END;
This trigger is error, any help please?Now, there's just a few more of code necessary for relaxation.
If :Old.Col1 != :new.Col1 Then :New.Col2:= :new.Col1; ElsIf :Old.Col2 != :new.Col2 Then :New.Col1:= :new.Col2; End If;HTH
* 009 *. -
Rows for which the final quantity is equal to the initial_quantity-1
Hello
I have a table with the following columns: account_id, country_code, initial amount, final amount, unit.
For example:
unit of measure final account_id country_code transitional amount
EN 1 5 1 555
EN 6 8 1 555
EN 11 12 1 555
I want lines that the final amount is equal to the initial_quantity-1.
For this, I have the following query
Select a.country_code,
a.account_ID,
a.initial_quantity,
a.final_quantity,
a.Unit,
of tableX one
inner join tableX b
on a.final_quantity + 1 = b.initial_quantity and a.unit = b.unit
where
and a.country_code = b.country_code
and a.account_id = b.account_id
Run the query, the result is
EN 1 5 1 555
But I want it to appear also row:
EN 6 8 1 555
Because I want to eventually merge this in one line
EN 1 8 1 555
Any ideas?
Thanks in advance.
Kind regardsHi Frank,.
I'm not sure that you can count on:
ORDER BY initial_quantity
Original quantity can be not necessarily increase or decrease. It can be both:
initial final ------- ----- 1 5 3 4 6 2 11 12Then LAG/LEAD will not work:
INSERT INTO tablex (account_id, country_code, initial_quantity, final_quantity, unit) VALUES (555, 'FR', 1, 5, 1); INSERT INTO tablex (account_id, country_code, initial_quantity, final_quantity, unit) VALUES (555, 'FR', 6, 2, 1); INSERT INTO tablex (account_id, country_code, initial_quantity, final_quantity, unit) VALUES (555, 'FR', 3, 4, 1); INSERT INTO tablex (account_id, country_code, initial_quantity, final_quantity, unit) VALUES (555, 'FR', 11, 12, 1); INSERT INTO tablex (account_id, country_code, initial_quantity, final_quantity, unit) VALUES (555, 'DE', 1, 2, 1); INSERT INTO tablex (account_id, country_code, initial_quantity, final_quantity, unit) VALUES (555, 'DE', 3, 5, 1); INSERT INTO tablex (account_id, country_code, initial_quantity, final_quantity, unit) VALUES (555, 'DE', 6, 8, 1); INSERT INTO tablex (account_id, country_code, initial_quantity, final_quantity, unit) VALUES (555, 'DE', 11, 12, 1); COMMIT; SQL> select * from tablex 2 / ACCOUNT_ID COUNTRY_CODE INITIAL_QUANTITY FINAL_QUANTITY UNIT ---------- ------------ ---------------- -------------- ---------- 555 FR 1 5 1 555 FR 6 2 1 555 FR 3 4 1 555 FR 11 12 1 555 DE 1 2 1 555 DE 3 5 1 555 DE 6 8 1 555 DE 11 12 1 8 rows selected. SQL> WITH got_grp_start AS 2 ( 3 SELECT account_id, country_code, initial_quantity, final_quantity, unit 4 , CASE 5 WHEN initial_quantity = 6 LAG (final_quantity) OVER ( PARTITION BY account_id 7 , country_code 8 , unit 9 ORDER BY initial_quantity 10 ) + 1 11 THEN 0 12 ELSE 1 13 END AS grp_start 14 , CASE 15 WHEN final_quantity = 16 LEAD (initial_quantity) OVER ( PARTITION BY account_id 17 , country_code 18 , unit 19 ORDER BY initial_quantity 20 ) - 1 21 THEN 0 22 ELSE 1 23 END AS grp_end 24 FROM tablex 25 -- WHERE ... -- Any filtering goes here 26 ) 27 SELECT account_id, country_code, initial_quantity, final_quantity, unit 28 FROM got_grp_start 29 WHERE grp_start = 0 30 OR grp_end = 0 31 ; ACCOUNT_ID COUNTRY_CODE INITIAL_QUANTITY FINAL_QUANTITY UNIT ---------- ------------ ---------------- -------------- ---------- 555 DE 1 2 1 555 DE 3 5 1 555 DE 6 8 1 SQL>I think that hierarchical query may be a better approach:
SELECT DISTINCT * FROM tablex START WITH ROWID IN ( SELECT a.ROWID FROM tablex a, tablex b WHERE b.account_id = a.account_id AND b.country_code = a.country_code AND b.unit = a.unit AND b.initial_quantity = a.final_quantity + 1 ) CONNECT BY NOCYCLE account_id = PRIOR account_id AND country_code = PRIOR country_code AND unit = PRIOR unit AND initial_quantity = PRIOR final_quantity + 1 ORDER BY account_id, country_code, unit, initial_quantity / ACCOUNT_ID COUNTRY_CODE INITIAL_QUANTITY FINAL_QUANTITY UNIT ---------- ------------ ---------------- -------------- ---------- 555 DE 1 2 1 555 DE 3 5 1 555 DE 6 8 1 555 FR 1 5 1 555 FR 3 4 1 555 FR 6 2 1 6 rows selected. SQL>SY.
-
Numbers AppleScript: paste the Clipboard as lines below
New to AppleScript in numbers...
How to use AppleScript to paste the contents of the Clipboard into an existing document of numbers (3.6.1) and additional lines, please?
The number of lines varies whenever I need to do that; they are already separated by tabs.
Thank you!
Something like this might work:
-Guess the Clipboard contains data delimited by tabs and the numbers document is open
the value theText to (Clipboard) as text
the value newRows to (count the paragraphs of theText)
point of the value oldDelimiters to AppleScript text delimiters
the value Text item of AppleScript delimiters
Repeat with j from 1 to newRows
j. paragraph set theRecord to text elements of letexte
say application "Numbers".
-indicates a reference to the table to which you want to add information
define will be used in table 1 to sheet 1 of the document 1
say where
Add the line below last line
Repeat with I 1 to the number of columns
value the value of cell of the last row I've got to the point I of theRecord
end Repeat
end say
end say
end Repeat
the value Separators to AppleScript text point oldDelimiters
-
First Max value to find and add the previous channel values
Hello, I would like to be able to parse a string to find the first maxima (inflection point) and then add channel so that all the values are equal to the maximum
the index where the maximum was found.
To explain better, in the attachment, the original channel's Ych and the channel in the annex is Ych_appended.
Any help would be appreciated.
Thank you
The feature you're looking for better using the SCRIPT of DIAdem.
First of all, you can find the first maximum in a channel by using the ChnPeakFind function. The document below explains how to use this:
http://digital.NI.com/public.nsf/allkb/DD069B95FB938C4286256FC8006A09CD?OpenDocument
The channels that you specify in the function call will contain the value x and y of the first maxima. Then, you will just need to:
- Copy the original using ChnCopy channel.
- Find the index of the value to your channel original x axis at which the peak occurs.
- Browse the newly copied channels, replacing the inside with peak values until you reach the index of the value found in step 2.
I hope this helps.
-
Simply select the values between min and max of a value accumulated during the day
Hello Forum,
a value is accumulated more a day and over a period of time. The next day, the value is reset and starts to build up again:
How should I change the select statement to ignore all data sets before the first minimum and duplicates after the maximum of a day to get such a result:with sampledata as (select to_date('09.09.2012 00:04:08', 'dd.mm.yyyy hh24:mi:ss') ts, 120 val from dual union all select to_date('09.09.2012 01:03:08', 'dd.mm.yyyy hh24:mi:ss') ts, 120 val from dual union all select to_date('09.09.2012 02:54:11', 'dd.mm.yyyy hh24:mi:ss') ts, 120 val from dual union all select to_date('09.09.2012 03:04:08', 'dd.mm.yyyy hh24:mi:ss') ts, 120 val from dual union all select to_date('09.09.2012 04:04:19', 'dd.mm.yyyy hh24:mi:ss') ts, 120 val from dual union all select to_date('09.09.2012 05:04:20', 'dd.mm.yyyy hh24:mi:ss') ts, 120 val from dual union all select to_date('09.09.2012 06:12:02', 'dd.mm.yyyy hh24:mi:ss') ts, 23 val from dual union all select to_date('09.09.2012 07:12:03', 'dd.mm.yyyy hh24:mi:ss') ts, 29 val from dual union all select to_date('09.09.2012 08:12:04', 'dd.mm.yyyy hh24:mi:ss') ts, 30 val from dual union all select to_date('09.09.2012 09:12:11', 'dd.mm.yyyy hh24:mi:ss') ts, 45 val from dual union all select to_date('09.09.2012 10:12:12', 'dd.mm.yyyy hh24:mi:ss') ts, 60 val from dual union all select to_date('09.09.2012 11:12:13', 'dd.mm.yyyy hh24:mi:ss') ts, 75 val from dual union all select to_date('09.09.2012 12:21:24', 'dd.mm.yyyy hh24:mi:ss') ts, 95 val from dual union all select to_date('09.09.2012 13:21:26', 'dd.mm.yyyy hh24:mi:ss') ts, 120 val from dual union all select to_date('09.09.2012 14:21:27', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('09.09.2012 15:21:30', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('09.09.2012 16:21:32', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('09.09.2012 17:21:33', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('09.09.2012 21:21:33', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('09.09.2012 23:21:33', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('10.09.2012 00:04:08', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('10.09.2012 01:03:08', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('10.09.2012 02:54:11', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('10.09.2012 03:04:08', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('10.09.2012 04:04:19', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('10.09.2012 05:04:20', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('10.09.2012 06:12:02', 'dd.mm.yyyy hh24:mi:ss') ts, 14 val from dual union all select to_date('10.09.2012 07:12:03', 'dd.mm.yyyy hh24:mi:ss') ts, 34 val from dual union all select to_date('10.09.2012 08:12:04', 'dd.mm.yyyy hh24:mi:ss') ts, 58 val from dual union all select to_date('10.09.2012 09:12:11', 'dd.mm.yyyy hh24:mi:ss') ts, 70 val from dual union all select to_date('10.09.2012 10:12:12', 'dd.mm.yyyy hh24:mi:ss') ts, 120 val from dual union all select to_date('10.09.2012 11:12:13', 'dd.mm.yyyy hh24:mi:ss') ts, 142 val from dual union all select to_date('10.09.2012 12:21:24', 'dd.mm.yyyy hh24:mi:ss') ts, 153 val from dual union all select to_date('10.09.2012 13:21:26', 'dd.mm.yyyy hh24:mi:ss') ts, 153 val from dual union all select to_date('10.09.2012 14:21:27', 'dd.mm.yyyy hh24:mi:ss') ts, 153 val from dual union all select to_date('10.09.2012 15:21:30', 'dd.mm.yyyy hh24:mi:ss') ts, 153 val from dual union all select to_date('10.09.2012 16:21:32', 'dd.mm.yyyy hh24:mi:ss') ts, 153 val from dual union all select to_date('10.09.2012 21:21:33', 'dd.mm.yyyy hh24:mi:ss') ts, 153 val from dual) select ts, val from sampledata order by ts asc;
Thank youTS VAL 09.09.12 06:12 23 09.09.12 07:12 29 09.09.12 08:12 30 09.09.12 09:12 45 09.09.12 10:12 60 09.09.12 11:12 75 09.09.12 12:21 95 09.09.12 13:21 120 09.09.12 14:21 142 10.09.12 06:12 14 10.09.12 07:12 34 10.09.12 08:12 58 10.09.12 09:12 70 10.09.12 10:12 120 10.09.12 11:12 142 10.09.12 12:21 153Hello
msinn wrote:
Hello Forum,a value is accumulated more a day and over a period of time. The next day, the value is reset and starts to build up again:
Thanks for posting the sample data and results. Be sure to explain how you get these results from these data. For example "for each day, I just want to show the lines after the daily low was reached. For example, on September 9, the lowest val was 23, which occurred at 6:12, so I don't want to show all lines earier to 06:12 September 9. In addition, when a val is the same as or more than the previous same day val (in order by ts), then I don't want to display the line later. For example, on 9 September, there are several consecutive lines, starting at 14:21 which all have the same val, 142. I want to only display the ealiest of this group, the line of 14:21. »
Here's a way to do it, using analytical functions:
WITH got_analytics AS ( SELECT ts, val , MIN (val) OVER ( PARTITION BY TRUNC (ts) ORDER BY ts DESC ) AS min_val_after , CASE WHEN val = MIN (val) OVER (PARTITION BY TRUNC (ts)) THEN -1 -- Impossibly low val. See note below ELSE LAG (val) OVER ( PARTITION BY TRUNC (ts) ORDER BY ts ) END AS prev_val FROM sampledata ) SELECT ts , val FROM got_analytics WHERE val <= min_val_after AND val > prev_val ORDER BY ts ;This requires that val > = 0. If you don't know a lower bound for val, and then the same basic approach still works, but it's a bit messier.
-
SUMIF in a table in the expansion
Hi, I create an expense report that has a table in full expansion. You can download it using the link here.
https://www.dropbox.com/s/r7qnaegkkx7a57h/expense%20Form.PDF
All I have for now works fine. You can add as many entries as you want and it provides in total.
I am stuck at the next step. Basically, I need a list of all categories in the "type" drop-down list, and I need to do the equivalent of a SUMIF excel. So if the category of 'capture' for the 'Real spending' Table is 'accommodation', I need a box below that says housing with the subtotal for all of the items identified as such. If there were three housing entered anywhere on the table for $10 each, I want a field down that would say "accommodation: $30.
Because I myself have learned everything I know about all my forms up to this point, I'm stuck. Any help would be appreciated!
Hello
An equivalent in FormCalc SUMIF might look like;
var totalRows = LoanProposal.Table1._Item.count
var groupTotal = 0
list var = ref (LoanProposal.Table1.resolveNodes ("Item. [ItemName is "" Cottage""] »))
for i = 0 upto list.length - 1 step 1
groupTotal is groupTotal + list.item (i). Total
ENDFOR
Note the totalRows variable is not used, but is necessary for the calculate event know fire when a row is added or deleted.
This should be repeated for each category so that you can have an event code to calculate at a higher level (such as the LoanProposal subform) with JavaScript code like;
Reset all fields
xfa.host.resetData ([Mileage.somExpression, Lodging.somExpression].join(","));
var lines = Table1.resolveNodes("Item[*]");
for (var i = 0; i)< table1._item.count="" ;="">
{
var line = rows.item (i);
switch (row. ItemName.rawValue)
{
case "mileage":
Mileage.rawValue & = row. Total.rawValue;
break;
case "accommodation":
Lodging.rawValue & = row. Total.rawValue;
break;
}
}
I only did the first two categories, but you can see the model
Concerning
Bruce
-
Images alerts equal to the size of the doc.
HI forum,
Baby script to script.
I have a script which will alert you if the last frame size [RECTANGLE] is equal to the height and width of the document...
I really need a help from you, to check, IF ALL of THE CHASSIS, IS EQUAL to WIDTH AND HEIGHT OF the DOCUMENT. [not only the last item] and ALERT...
var doc = app.documents [0];
REC = doc.rectangles.lastItem ();
rectHeight = Math.round (rec.geometricBounds [2] - rec.geometricBounds [0]);
rectWidth = Math.round (rec.geometricBounds [3] - rec.geometricBounds [1]);
If (rectHeight = Math.round (app.activeDocument.documentPreferences.pageHeight) & &)
rectWidth is Math.round (app.activeDocument.documentPreferences.pageWidth))
rec.itemLayer = doc.layers.itemByName (layerName);
Alert ("FRAME SIZE IS CORRESPONDING to DOCU. SIZE');
Thank you
anthkini
Hello
Change this line:
if( Math.round(scalW) == Math.round(app.activeDocument.documentPreferences.pageHeight) ) {Jarek
-
to fill the gaps with value of lead and the delay and make average and the gap between earned
Thanks in advance
I have table as below
What I need is to fill the gaps with value of lead and the delay and make average and the gap between the valuesID TYPE NUM NAME BEG_MP END_MP VALUE 10001103N 3 1190001 WST 0.000 0.220 10001103N 3 1190002 WST 0.220 0.440 10001103N 3 1190003 WST 0.440 0.820 12800 10001103N 3 1190003 WST 0.820 1.180 12800 10001103N 3 1190004 WST 1.180 1.220 10001103N 3 1190004 WST 1.220 1.300 10001103N 3 1190005 WST 1.300 1.420 14800 10001103N 3 1190005 WST 1.420 1.550 14800 10001103N 3 1190006 WST 1.550 2.030 10001103N 3 1190006 WST 2.030 2.660 10001103N 3 1190007 WST 2.660 2.780
ID TYPE NUM NAME BEG_MP END_MP VALUE 10001103N 3 1190001 WST 0.000 0.220 12800 ---> Lag value 10001103N 3 1190002 WST 0.220 0.440 12800 ---> Lag Value 10001103N 3 1190003 WST 0.440 0.820 12800 10001103N 3 1190003 WST 0.820 1.180 12800 10001103N 3 1190004 WST 1.180 1.220 13800 ---> Avg(12800,14800) 10001103N 3 1190004 WST 1.220 1.300 13800 ---> Avg(12800,14800) 10001103N 3 1190005 WST 1.300 1.420 14800 10001103N 3 1190005 WST 1.420 1.550 14800 10001103N 3 1190006 WST 1.550 2.030 14800 ---> Lead Value 10001103N 3 1190006 WST 2.030 2.660 14800 ---> Lead Value 10001103N 3 1190007 WST 2.660 2.780 14800 ---> Lead Valuecreate table AVG_TABLE ( ID VARCHAR2(20), TYPE NUMBER, NUM NUMBER, NAME VARCHAR2(10), VALUE NUMBER, BEG_MP NUMBER(6,3), END_MP NUMBER(6,3) ) ; insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190001, 'WST', null, 0, .22); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190002, 'WST', null, .22, .44); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190003, 'WST', 12800, .44, .82); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190003, 'WST', 12800, .82, 1.18); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190004, 'WST', null, 1.18, 1.22); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190004, 'WST', null, 1.22, 1.3); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190005, 'WST', 14800, 1.3, 1.42); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190005, 'WST', 14800, 1.42, 1.55); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190006, 'WST', null, 1.55, 2.03); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190006, 'WST', null, 2.03, 2.66); insert into AVG_TABLE (ID, TYPE, NUM, NAME, VALUE, BEG_MP, END_MP) values ('10001103N', 3, 1190007, 'WST', null, 2.66, 2.78); commit;Hello
Use LEAD and LAG when you know exactly how far is the target line (for example, if you know the desired value is on the next row).
If you don't know exactly how far is the target line, then FIRST_VALUE and LAST_VALUE are more likely to be useful.WITH got_neighbors AS ( SELECT avg_table.* , LAST_VALUE (value IGNORE NULLS) OVER (ORDER BY beg_mp) AS prev_value , LAST_VALUE (value IGNORE NULLS) OVER (ORDER BY beg_mp DESC) AS next_value FROM avg_table ) SELECT id, type, num, name, beg_mp, end_mp , COALESCE ( value , ( NVL (prev_value, next_value) + NVL (next_value, prev_value) ) / 2 ) AS value FROM got_neighbors ORDER BY beg_mp to f ;Riedelme is correct: LAG LEAD (as well as FIRST_VALUE and LAST_VALUE) can return only the values that are there (or that you give as default values). This means that you can not solve this problem with these functions alone; you need something else (as NVL, above) to provide value when the function does not find it.
-
I always use the ios 7 because I like my reviews of iphoto, ios 8 and after don't support is not iphoto, I intend to upgrade to the latest version of ios. so my question is:
Are the Photos and videos uploaded (iCloud Photo Sharing) equal to the (ios iphoto reviewed)?
-If so, I can arrange the provision in the way I want? What happens if you want to convert my old (iphoto ios log backup) to import (iCloud Photo Sharing) that it is?
-If not, what is the new equal to that with the possibility of transferring these journals?
Thank you
No they are not really the same thing and you can't convert one to the other. When / if you update, you will simply lose your logs. You cannot influence other available photos of the order appear in
-
Look for the logic find the value of m and c of this equation y = mx + c.
Hello
I have 4 points for example = 3.38276, 0.375866 xi
Yi = 3.37749, 0.281924
using this tip, I want to find the value of m and c.
You please suggest me some logic to solve this equation using labview programming.
I tried with one solution, but in this case I do not have the correct answer. Here as an attachment, there is vi help I tried to solve my equation, but in this case the value that never got as a response it is dissatisfied with the equation, means if I replace the value of m and c eqation then it must be L.H.S = R.H.S, but I don't have the right solution.
You please guide me.
Thank you very much.
Why do you think that the results are incorrect? I put your numbers in your code and the result on a XY Chart Wescott, I then bunk which with more than 20 values with a value ranging from 0.6 to 3.2 x and use factors calculated in your code to generate values of Y. The two overlap almost exactly...
Mike...
BTW: There is a linear adjustment integrated into LV VI
-
Malware, the Web Bots and Trojans is equal to the fall of DSL speed?
Ive been having some trouble DSL speed and my ISP suggested that my computer had been compromised, so I downloaded Microsoft Security Essentials and of course after a 5 hour scan he found a Trojan horse and removed, although later that night, I continued to have speed issues, the provider advised me to use CMD and run a Netstat to see what was using my DSL if anything. Im not for techies, but I found these lines a bit curious to say the least:
(TCP 192.168.254.1:49263 yx - in - f139:http TIME_WAIT)
TCP 192.168.254.1:49266 lasvegas-nv - UNOFFICIAL datacenter:http
TCP 192.168.254.1:49268 213.174.154.144:http CLOSE_WAIT)I googled the lasvegas and the yx but I have found no information in their regard. Any help to what they are or how to fix this would be appreciated.
Hello
The suggestion recommended for this problem would be to perform a new installation.
Important: Data and the applications on the computer will be lost after a clean install. Make a backup of your data before performing any installation.
The following steps are worth a try:
Method 1: Disable the firewall (security software) software and then test to see if the problem persists. Follow the steps mentioned in the link below
Enable or disable Windows Firewall
If you use a non-Microsoft security software, you can check the documentation provided with the program to achieve this.
Important:Activate the Security (firewall program) software once everything is done.Method 2: Put the computer to point earlier in time where everything worked well until the computer has been infected by the virus and then run a virus scan again and check if that makes a difference
Follow the steps mentioned in the link below to complete the restore of the system
http://Windows.Microsoft.com/en-us/Windows-Vista/what-is-system-restoreYou can check the link below
Remove spyware from your computerThank you, and in what concerns:
Ajay K
Microsoft Answers Support Engineer
Visit ourMicrosoft answers feedback Forum and let us know what you think.
-
Hi all
I have seen under error in the tool main 2.2 Cisco infrastructure
The limit of the device must be less or equal to the limit of license of life cycle and also secondary device ISE inaccessible since premium.
Could you please suggest how we can solve your problem.
Thanks in advance...
Kind regards
Sachin
Yes. Life cycle license are by smart device managed. See this page for a good overview:
http://www.Cisco.com/c/en/us/support/docs/cloud-systems-management/Prime...
.. as well as this page:
http://www.Cisco.com/c/en/us/products/collateral/cloud-systems-Managemen...
.. who States:
Life cycle license: allows access to all the features of the life cycle, which includes the configuration of the devices, image management software, basic health and performance monitoring, fault management, troubleshooting and customer visibility on the network. The license of the life cycle is based on the number of managed devices. Life cycle of the licenses are available in sizes from package of 25, 50, 100, 500, 1000, 2500, 5000, 10,000 and 15 000 devices and can be combined as needed to reach a total number of device under license.
A device is uniquely identified through the assigned IP address and system object ID (SysOid). Routers, switches, light/unified access points and network first Cisco (NAMs) analysis Modules are charged on the number of licenses. If a switch stack is managed via a single IP address, it counts as a single device. A single frame will, however, be counted as multiple devices if the chassis is configured with several IP addresses. For example, a switch with several service cards, such as a firewall and so forth, or a stackable switch with an IP address assigned to each switch who is involved in the stack is considered multiple devices within the first Cisco Infrastructure. Cisco Wireless LAN controllers (WLCs), autonomous and peripheral access points third are not counted against the number of licenses.
When you have more devices that licenses, you will receive the error see you and prevented from adding additional devices to your inventory.
We see it more often when it is light (i.e. not independent) APs are added to a wireless controller. PI will not prevent the new APs to be added, they are managed under their association with the WLC. However, if you try to add a new switch it would prevent you to do until the deficit of licenses has been sent.
Maybe you are looking for
-
How to remove ZoneAlarm? Removed addons and Control Panel.
ZoneAlarm somehow was added to Firefox. I removed ZoneAlarm Control Panel and of Mozilla Firefox addons, but it's still there. It may have been added when I downloaded a program calling living Cookbook.
-
Yoga 900-13ISK laptop computer (ideapad) does not illuminate
Hi allI hope someone can help me with my situation of laptop. Its a laptop of Lenovo Yoga (ideapad) 900-13ISK, I got it for 3 months. I stopped him Saturday and then the minutes after the display was gone I noticed the power light was still on. I tri
-
I get this when I turn on STOP: c000021a {fatal system error}
Complete the message STOP: c000021a system {fatal system error} The Windows Logon Process ended unexpectedly with a 0 x 0000034 ststus (0x00000000 0 x 0000000) system has been turned off. I tried to boot into safe mode with command prompt and I get t
-
I can't get my HP Office jet J4580 all-in-one to work
Help can't get working printerto
-
How install manually NVIDIA nFORCE driver for PCI System management?
manually install a driver