Taken non-zero indexing in executions
If the team voted and I have to use non-zero indexing for my test sockets
I followed the guide to change the index in the batch dialog box
http://digital.NI.com/public.nsf/allkb/A6D0EF1F4FE5EC94862570AE000CE374
which is so much more important since I replaced the dialog box. What matters is the name of the executions and they correspond to the physical socket number.
Here is a more Visual example.
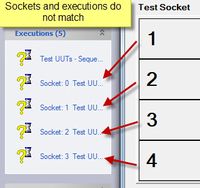
I noticed the NOTE on the
How do I Change My Test Socket numbers are not based on the zero?
Guide.
Note: This procedure will not change the numbering of the Testsockets in the process template, because it would take more changes emultiple.
I want to only change taken above executions so they correspond to the socket number no test of zero in the above dialog box. Any help would be appreciated.
Hey Taylor,
In order to change the way in which the index is displayed, you can modify the Configure ListBar VI in TS Full LabVIEW UI Dependencies.lvlib . The specific change is to change the string entry in the ExecutionListConnection node property DisplayExpression property. The entry has the default value:
"%CurrentExecution%\n" + ("%UUTSerialNumber%" == "" ? "" : (ResStr("TSUI_OI_MAIN_PANEL", "SERIAL_NUMBER") + " %UUTSerialNumber%\n")) + ("%TestSocketIndex%" == "" ? "" : ResStr("TSUI_OI_MAIN_PANEL", "SOCKET_NUMBER") + " %TestSocketIndex%\n") + "%ModelState%"
You can replace this with the following code:
"%CurrentExecution%\n" + ("%UUTSerialNumber%" == "" ? "" : (ResStr("TSUI_OI_MAIN_PANEL", "SERIAL_NUMBER") + " %UUTSerialNumber%\n")) + ("%TestSocketIndex%" == "" ? "" : ResStr("TSUI_OI_MAIN_PANEL", "SOCKET_NUMBER") + "str(val(%TestSocketIndex%)+1)\n") + "%ModelState%"
The interest is specifically: "str(val(%TestSocketIndex%)+1)\n" .
Let me know if you have any questions.
Best regards,
Tags: NI Software
Similar Questions
-
Vista 32 bit still reads zero indexed items and Outlook Office 07 willnot index I sort each difficulty I could find
Have you tried: Panel, Indexing Options, modify or advanced?
-
Client debugging flood * apfMsConnTask_0:... Update statistics: value Non-zero
Hello
We have two controllers 5508 with 7.4.100.0. When we try to debug client
this message flooding the console: Is there a way to stop it? Thank you.
I * apfMsConnTask_2: 12:17:21.729 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.754 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.756 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.758 Aug 23: update the Stats: value Non-zero
s * apfMsConnTask_0: 12:17:21.809 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.948 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.949 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.949 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.949 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.949 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.949 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.950 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.950 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.951 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.951 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.952 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.952 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_0: 12:17:21.953 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_2: 12:17:21.956 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_2: 12:17:21.958 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_2: 12:17:21.962 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_2: 12:17:21.962 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_2: 12:17:21.963 Aug 23: update the Stats: value Non-zero
* apfMsConnTask_2: 12:17:21.963 Aug 23: update the Stats: value Non-zero
This occurs only when you enable client debugging? and does not occur when you turn it off?
Rating of useful answers is more useful to say "thank you".
-
When I change a column is a primary key the associated non-unique index to become unique?
So basically I already tried this and it shows me that the associated index is not unique.
create table employees2 in select * from employees;
create index emp_idx on employees2 (employee_id);
ALTER employees2 table add primary key (employe_id) using index emp_idx;
Select * from user_indexes where index-name = "EMP_IDX";
I was wondering if I right assuming that when you change a column to a primary key or unique while using a given index that does not have the respective index become unique.
The textbooks I use are sometimes a little hard to understand because of the wording, also, I want to just ask someone with a little more experience than me.
Thank you.
your test did give the correct answer: the index is not unique if it serves to bear a unique or primary key constraint. Indeed, it is one of the benefits of the use of no unique indexes in support of UK/PK constraints (since it allows to set the unusable index before to make bulk loads; and, of course, they have also some disadvantages - for example, they need an additional logical reading to reach a line). Richard Foote explains the details in https://richardfoote.wordpress.com/2008/06/04/primary-keys-and-non-unique-indexes-whats-really-happening/ (and other items).
-
HelloI have a unique index associated with no doubt. Unique and not unique indexes are used B tree architecture. But I want to know if I create a non-unique index on a column that contains unique data.
When I query this table using this column, it scans each sheet or times found that value it scan stops and give us the result?
00125 wrote:
In a non-unique index, scans all the leaves... so what's the difference between full table scan and index ull. I went through a few articles they mentioned that a non-unique index to check with rowid. How she treated? I have clear knowledge in it.
Please help me with this.
Thanks in advance
If you go through architecture index B-tree you could easily understand how indexing works. The picture here shows how a look of column datatype NUMBER indexed as / stored internally. You can imagine that your indexed column TST_COLA this will look like in the internal process. In the B-tree indexes, you have 3 main structures 1. 2 root. Branch 3. Leaves and the database retrieves lines by browsing through the root of index-> branch-> leaves. If the photo if we wanted to retrieve the row whose value indexed column = 25. First data goes to the root and finds that plugs is set to 25, then he Stoops to this particular branch of find what block sheet retains the value 25. More far away after finding the leaves block then goes to this block of sheets and research the special value of 25.
If the index is UNIQUE, the database knows that there must be only one value, where it performs INDEX UNIQUE SCAN. If the index is NOT UNIQUE it should check all values in this block of leaves to find who all are 25 - in this case INDEX RANGE SCAN is done - as you must check not only value, but all values in this block of sheets - given that the values are not unique. As you can see it that the sheet block contains the long side of the value of the column ROWID, using this database rowid, then goes to the table to retrieve that particular line.
Full table scan is a method of access where the database just to access the table directly (bypassing index structure) and analyze the ENTIRE table to satisfy the request.
-
Accompanied by primary key to a non-unique index?
Met a weird situation today. A utility, we set up which allows analysts to restore the data in their paintings, started failed when it attempted to drop an index. The index supported a primary key. Makes sense. But our script was supposed to be only an attempt to drop/recreate the nonunique indexes. It turns out that supported on the primary key index was not unique and to the best of my knowledge has emerged as follows:
What I can't understand, is how an index is not unique is to apply oneness. I thought it was the key to this process. I thought that perhaps an index with the 'SYS_123456' has be created, perhaps, but I couldn't find a:SQL> create table junk (f number(1)); Table created. SQL> create index junk_ix on junk(f); Index created. SQL> select UNIQUENESS from DBA_INDEXES where index_name = 'JUNK_IX'; UNIQUENES --------- NONUNIQUE SQL> alter table forbesc.junk add constraint junk_pk primary key (f) using index junk_ix; Table altered. SQL> select UNIQUENESS from DBA_INDEXES where index_name = 'JUNK_IX'; UNIQUENES --------- NONUNIQUE SQL> insert into junk values (1); 1 row created. SQL> insert into junk values (1); insert into junk values (1) * ERROR at line 1: ORA-00001: unique constraint (FORBESC.JUNK_PK) violated SQL> select index_name from dba_constraints where constraint_name = 'JUNK_PK'; INDEX_NAME ------------------------------ JUNK_IX
How the uniqueness is get applied in this case? It comes in Oracle 11.1.0.7SQL> select object_name, object_type from dba_objects order by created desc; OBJECT_NAME OBJECT_TYPE ------------------------------------------- JUNK_IX INDEX JUNK TABLE ...
Thank you
-= ChuckIt has always been like that. Oracle can and will use a non-unique index to apply a constraint to PK, the existing index just needs to have the columns PK as the leader or the columns in the index:
SQL> create table t (id number, id1 number, descr varchar2(10)); Table created. SQL> create index t_ids on t(id, id1); Index created. SQL> select index_name from user_indexes 2 where table_name = 'T'; INDEX_NAME ------------------------------ T_IDS SQL> alter table t add constraint t_pk 2 primary key (id); Table altered. SQL> select index_name from user_indexes 2 where table_name = 'T'; INDEX_NAME ------------------------------ T_IDS SQL> insert into t values (1, 1, 'One'); 1 row created. SQL> insert into t values (1, 2, 'Two'); insert into t values (1, 2, 'Two') * ERROR at line 1: ORA-00001: unique constraint (OPS$ORACLE.T_PK) violatedJohn
-
Hello
Why Oracle adds the rowid of a non-unique index? why each entry in the non-unique index must be unique?
Thank youhttp://asktom.Oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:2047869500346039771
Why a rowid is added to the key for a non-unique index?Please read above links. Hope may be useful.
Concerning
Girish Sharma -
Back to ErrorLevel == 1 (or non-zero) If compare does not
All,
I have several regular processes that run each week. I use a task scheduler that calls a batch file. The batch file will connect to sqlplus and runs the specified sql file. For the process in question, there is a table that has a date of report. If the date of the report does not match the date I want, I want the sql script to terminate / exit and return an errorlevel code 1 (or non-zero) and the rest of the script is not running. If the report dates are equal, I would like the script to complete. I tried to use an raise_application_error if, goto, instruction, etc... and I can get the sql script ends. However, I can't seem to return an errorlevel code 1 (or non-zero) in my batch file. She returns always an errorlevel == 0 or successful. Someone has suggestions that will run a comparison of date and error / return errorlevel == 1 (or whatever) if the dates do not match? Any help you give would be greatly appreciated.
Thank you
CCYou have instructions in the wrong order, try this:
WHENEVER oserror exit 1; WHENEVER SQLERROR EXIT 1; --/******************************************************************** --* --* Check to see if the report_date is updated if not error out --* --*********************************************************************/ DECLARE report_date1 DATE := LAST_DAY (TO_DATE (ADD_MONTHS (SYSDATE, -2), 'DD-MM-RRRR')); report_date2 DATE; BEGIN SELECT report_date INTO report_date2 FROM tablename WHERE report_flag = 16; IF (report_date1 != report_date2) THEN RAISE_APPLICATION_ERROR(-20000,'INVALID PROD NO'); END IF; END; / --/******************************************************************** --* --* Continue processing the stuff... --* --*********************************************************************/ -- rest of sql here -- COMMIT; EXIT 0;: p
-
UNIQUE compared to a NON-UNIQUE INDEX
Hello SQL gurus.
Can you tell me the difference between UNIQUE and NON-UNIQUE index?
Thank you
DaveThe fact that a UNIQUE index will not allow duplicate values in the columns in Index key so that NO SINGLE index will allow duplicates.
If I CREATE an INDEX UNIQUE MY_TABLE_UK ON MY_TABLE (NAME_COLUMN);
I can't insert the value "HEMANT" twice in the NAME_COLUMN.
If I CREATE INDEX MY_TABLE_IDX ON MY_TABLE (NAME_COLUMN);
I can "HEMANT" insert multiple lines.
NOTE: If I insert NULL values, a UNIQUE INDEX will allow several NULL values as, by definition "NULL! = NULL ". However, a definition of primary key does not allow nulls.
-
How to find three consecutive non zero number of a table
Hi, I'm trying to do a very simple program in labview but I'm stuck.
I have a table of u8 in a sequence of zeros and zeros not, but I am interested in finding the first three non-consecutive zeroes on the Board.
That is to say. 0 0 0 0 1 0 0 2 3 0 0 2 3 3 0 0...
the output would be 2 3 3
Thanks Gustavo R.
Run the table in a loop for or while loop with the auto table indexed at the entrance of the loop. Increment a counter in a shift register when the array element is different from zero and it has reset when the array element is zero. When the counter is > 2 you have three consecutive elements from scratch.
Lynn
-
clustered index and non-clustered indexes
Hi ihave read on index qqustion
in SQL Server, table has 1 clustered index and 280 (average) no clustered index.
SqlServer hold a clustered index and the data on the same location. index if cluster command firm data
but sqlserver hold index non-clustered on another file and do not directly order data.
oracle index how does this? for example, I have 3 indexes on the table. how they work? is oracle this clustered index and indexes not clustrered?Oracle has no cluster & nonclustered indexes.
Oracle has Btree, bitmap, text, index basis functionDisappeared through the link
http://www.lorentzcenter.nl/awcourse/Oracle/server.920/a96520/indexes.htm -
Count the number of zero terms between non zero terms
Hello. I have a table of data of zero and nonzero (example: {1 2 56 2 3 0 0 0 0 0 2 3 5 2 3 5 2 0 0 0 0 32 43}) I need to count the number of zeros of each string of zeros and mark that number against the first zero no term following the string of zeros (NOTE (: string is used here as a description of a series of zeros, not a string variable). So the plot which coordinates since my example would be (5.2) and (4.32).
I'm clear on the way to the path, but I am unable to store only each final count of consecutive zeros without having unnecessary data in my plot.
Thanks in advance to all those who have advice!
-Mike
Do something like that?
EDIT: Minor Correction because of the additional function of decrement.
-
Table of indexes for execution of data
Hello
I have data running in real time, and I'm reading some points with Index Board. This is for data that are already collected, or y at - it another way I can collect data that are powered?
Thank you
Andrea
-
Check the number of non zero values in each row
Hello
I have the following table
create the table attbon as
(
Select pryear 2014, 1 empid, to_date('21/11/2014','dd/mm/yyyy') prdate, 12 prmonth, 3 shortleave union double all the
Select double union all the 12 prmonth 2014 pryear, 1 empid, to_date('22/11/2014','dd/mm/yyyy') prdate shortleave 0
Select double union all the 12 prmonth 2014 pryear, 1 empid, to_date('23/11/2014','dd/mm/yyyy') prdate shortleave 0
Select double union all the 12 prmonth 2014 pryear, 1 empid, to_date('24/11/2014','dd/mm/yyyy') prdate shortleave 0
Select double union all the 12 prmonth 2014 pryear, 1 empid, to_date('25/11/2014','dd/mm/yyyy') prdate shortleave 0
Select pryear 2014, 2 empid, to_date('21/11/2014','dd/mm/yyyy') prdate, prmonth 12, 1 shortleave Union double all the
Select 2014 pryear, 2 empid, to_date('22/11/2014','dd/mm/yyyy') prdate, prmonth 12, 1 shortleave Union double all the
Select 2014 pryear, 2 empid, to_date('23/11/2014','dd/mm/yyyy') prdate, prmonth 12, 1 shortleave Union double all the
Select double union all 12 prmonth, 2014 pryear, 2 empid, to_date('24/11/2014','dd/mm/yyyy') prdate shortleave 0
Select double union all 12 prmonth, 2014 pryear, 2 empid, to_date('25/11/2014','dd/mm/yyyy') prdate shortleave 0
Select 3-shortleave, 3-empid, prmonth 12, to_date('21/11/2014','dd/mm/yyyy') prdate, 2014 pryear Union double all the
Select double union all 12 prmonth, 3 empid, to_date('22/11/2014','dd/mm/yyyy') prdate, 2014 pryear, 1 shortleave
Select double union all 12 prmonth, 3 empid, to_date('23/11/2014','dd/mm/yyyy') prdate, 2014 pryear, 0 shortleave
Select double union all 12 prmonth, 3 empid, to_date('24/11/2014','dd/mm/yyyy') prdate, 2014 pryear, 0 shortleave
Select double union all 12 prmonth, 3 empid, to_date('25/11/2014','dd/mm/yyyy') prdate, 2014 pryear, 0 shortleave
Select pryear 2014, empid 4, to_date (' 21/11/2014 ',' dd/mm/yyyy') prdate, prmonth 12, 1 shortleave Union double all the
Select 2014 pryear, 12 prmonth, 3 shortleave, 4 empid, to_date (' 22/11/2014 ',' dd/mm/yyyy') prdate of all the double union
Select double union all 12 prmonth, 2014 pryear, 4 empid, to_date('23/11/2014','dd/mm/yyyy') prdate shortleave 0
Select double union all 12 prmonth, 2014 pryear, 4 empid, to_date('24/11/2014','dd/mm/yyyy') prdate shortleave 0
Select pryear 2014, prmonth 12, shortleave 0, empid, to_date (' 25/11/2014 ',' dd/mm/yyyy') 4 prdate double
);
I want to find the eligibility of premium participation for each employee for each day
An employee is allowed to take the maximum of 3 hours as shortleave.
Normally if SHORTLEAVE is greater than 1 for a day, the employee is not eligible for the bonus of participation for this day
So if an employee DISP shortleave of one hour each, on three different days or more, it is eligible for the bonus of attendance for every day.
If it make use of all three hours on a stretch as he is eligible for the bonus of presence condition no other short-term leave availed for this month.
otherwise this day where it's not eligible for the bonus of presence
That is to say.
attboneligible of a day is 1
If shortleave < = 1
or
(shortleave = 3, and County of short leave zero for the month is 1)
Required result
=============================================
EMPID PRDATE ATTBONELIGIBILITY
=============================================
21/11/2014 1, 1
22/11/2014 1, 1
23/11/2014 1, 1
24/11/2014 1, 1
25/1/11/2014 1
21/11/2014 2, 1
22/11/2014 2, 1
23/11/2014 2, 1
24/11/2014 2, 1
25/2/11/2014 1
3 21/11/2014 0
22/11/2014 3, 1
23/11/2014 3, 1
3 24/11/2014 1
25/3/11/2014 1
21/11/2014 4, 1
22/11/2014 4, 0
23/11/2014 4, 1
24/11/2014 4, 1
25/4/11/2014 1
===============================================
I use oracle 10g
Help, please
Hello Krishna,
Try this in your test data:
Update attbon set shortleave = 2 where shortleave = 3;
And compare with your expectations.
I guess, Frank or your own modiifcation will do the job...
If I understand you right...
But try Indra!
Best regards
Karlheinz
-
Can't P2V to a thin provisioned disks copied non-zero'ed crashes?
I need P2V a server that has recently had a lot of deleted data.
If a make my thin target supplied disk, will be the layout of converter for these unused space but not zero would be blocked?
As a question, making the thin target instead of thickness negatively influence the performance of the copy?
Yes. Use sdelete on Windows or dd on Linux, to zero free space before you run the P2V.
Maybe you are looking for
-
Be a problem using a charger better?
I'm using 2nd generation of bike g and it takes a lot of time to load. If the phone will face any problem if I use a more powerful charger?
-
How can I delete my computer Smilebox? I continue to be re-directed to their site.
I tried to get information regarding "smilebox" and some how now whenever I log on my computer... the search engine's to "Mystart.smilebox?" I have one sought everywhere on how to remove this annoying thing from my computer but can't find the right s
-
Can I use only a black of ink (301xl or 301) for my printer hp deskjet 2050?
Can I use only black of ink (301xl or 301) for my printer hp deskjet 2050 and not the color one (empty)?
-
Pilot missing PCI for Windows 7
I have an E machine modem and it came with windows XP. I bought windows 7 upgrade, and he tells me that my PCI driver is not installed. How can I get my PCI driver
-
Problem in creating project of blackberry using svn with eclipse
I try to import BlackBerry code in Eclipse, svn. It is not verified as a project, so I'm the control using the new project wizard. Unfortunately, it doesn't give me an empty project. How can I get around this? Microsoft Windos XP Eclipse 3.4.1 JDE 4.