Tip 3 - ESX4 running unusual performance of Hung VM - node cluster...
Hello community,
I use useful overview to a question we've experienced in our production environment on a cluster of 3 nodes that had a virtual computer running on it. The virtual machine is used only for printing isolate us applications running together on similar servers. The technician who was working the issue being reported a number of things, but I wasn't there so couldn't say what has been done. The end result was that he had to perform a "reset" of the virtual machine, because it could not connect via RDP and the console does not accept the CtrlaltDELETE. VMware tools is updated. It will be later tonight so I'll tell you about him for more details on the issue and what diagnosis was made. The problem occurred this morning to 01:30-02:30 am on the 'C' host (host are 1 a, 1 b, 1 c). Seeing as just two days ago, I reached my VCP, I thought I'd like to look deeper into the problem. What I found was a bit intriguing. There is no change somehow to the recenetly cluster other than adding some VM makes. At the time of the issue, that nothing has been performed we could very well connected in vCenter. I also logged on to the console and found it EXTREMELY laggy. This is partly due to the fact that we use vCenter here in our home office and all Distribution Centers to meet the vCenter here so I don't know that it's because of WAN. Anyway, finding that he was still on which I just decide to look at some statistics and performance counters in vCenter. What I've discovered, is that between the time where the problem occurred in fact there is a pretty big spike in all activities related to the disk, memory, network, and CPU. See the attached images. I thought it was very interesting, and anyone could build a helping hand in perhaps seeing what may of caused this type of spike in any army of this group which would be very useful. All virtual machines are supplied with 1vcpu and only 4 GB of memory. We use the Solutions of HP Lefthand VSA for shared iSCSI storage. Appreciate any comments!
Given, you have iSCSI storage connected to the ESX servers, it is normal to have spikes on the CPU, disk and network if you use normal NIC (not iSCSI HBAS). When ESX disks on storage iSCSI via NETWORK card normal access, it access to content on the network and uses the CPU to process the iSCSI packages. If you have iSCSI HBA, you shouldn't see peaks of the use of the processor like this.
Tags: VMware
Similar Questions
-
Is this OK to run the utility on the active node TimesTen ttMigrate?
Hello
I heard that it is not a good idea to run the utility on the active node TimesTen ttMigrate but I saw no logical technical or a document explaining why?
When you get a chance, please let me know.
Thank you
Sunil
I guess you're referring to the execution of ttMigrate - a or c - to export one or more tables in an external file?
The active node is usually much more heavily loaded than the day before and more sensitive to disturbance by activities such as an unloading of big data. In addition, according to the options that you use (or not use) with ttMigrate you will lock entire tables or hierarchies table whole even while the ttMigrate works and this could be very disruptive to applications running on the back-end database and could lead to timeout lock etc. Replication takes his retirement automatically for this kind of error if you run the ttMigrate on the starting node you will not impact on applications and you'll have only a relatively small impact on replication.
If you do not want the sensation exported 100% transactional consistency (assuming that there are DML activity going on against the exported table) then you can use instead
ttBulkCp o with the option - noForceSerializable to avoid any impact on the application to access the table.
Chris
-
Grid Infra configuration failed when running root.sh on the second node
Hello world.
I am new guy on RAC environment. When you try to install Oracle RAC on the local environment, I had this problem:
-J' have run root.sh successfully on a local first node
-After that, the first node, there are 3 cards of virtual network created to SCAN listening addresses
-After the success of action on the first node, I tried to run this script on the second node, but the error occurred:
CRS-2676: Start of 'ora.DATA.dg' on 'dbnode2' succeeded PRCR-1079 : Failed to start resource ora.scan1.vip CRS-5017: The resource action "ora.scan1.vip start" encountered the following error: CRS-5005: IP Address: 192.168.50.124 is already in use in the network . For details refer to "(:CLSN00107:)" in "/u01/app/11.2.0/grid/log/dbnode2/agent/crsd/orarootagent_root/orarootagent_root.log". CRS-2674: Start of 'ora.scan1.vip' on 'dbnode2' failed CRS-2632: There are no more servers to try to place resource 'ora.scan1.vip' on that would satisfy its placement policy PRCR-1079 : Failed to start resource ora.scan2.vip CRS-5017: The resource action "ora.scan2.vip start" encountered the following error: CRS-5005: IP Address: 192.168.50.122 is already in use in the network . For details refer to "(:CLSN00107:)" in "/u01/app/11.2.0/grid/log/dbnode2/agent/crsd/orarootagent_root/orarootagent_root.log". CRS-2674: Start of 'ora.scan2.vip' on 'dbnode2' failed CRS-2632: There are no more servers to try to place resource 'ora.scan2.vip' on that would satisfy its placement policy PRCR-1079 : Failed to start resource ora.scan3.vip CRS-5017: The resource action "ora.scan3.vip start" encountered the following error: CRS-5005: IP Address: 192.168.50.123 is already in use in the network . For details refer to "(:CLSN00107:)" in "/u01/app/11.2.0/grid/log/dbnode2/agent/crsd/orarootagent_root/orarootagent_root.log". CRS-2674: Start of 'ora.scan3.vip' on 'dbnode2' failed CRS-2632: There are no more servers to try to place resource 'ora.scan3.vip' on that would satisfy its placement policy start scan ... failed FirstNode configuration failed at /u01/app/11.2.0/grid/crs/install/crsconfig_lib.pm line 9379. /u01/app/11.2.0/grid/perl/bin/perl -I/u01/app/11.2.0/grid/perl/lib -I/u01/app/11.2.0/grid/crs/install /u01/app/11.2.0/grid/crs/install/rootcrs.pl execution failed
I tried again with several times (with left-hand) but the problem was still there. Can you explain to me?
-Why, after running root.sh on the first node, all IP SCANNER interfaces was created on this node? This is the reason why root.sh fails on the second node.
-How to solve?
I use the server for address scan local DNS resolves to 3 IPs, and I can run script runcluvfy.sh with success on both nodes.
I thank in advance
PS:
I use two virtual machines in vmware. After running root.sh on the first node, I checked and found this funny information:
[oracle@dbnode1 sshsetup] $ / sbin/ifconfig
eth0 Link encap HWaddr 00: 0C: 29:BC:43:1 B
INET addr:192.168.50.66 Bcast:192.168.50.255 mask: 255.255.255.0
ADR inet6: fe80::20c:29ff:febc:431 b / 64 Scope: link
RUNNING BROADCAST MULTICAST MTU:1500 metric: 1
Dropped packets: 249814 RX errors: 0:0 overruns: 0 frame: 0
Dropped packets: 2956882 TX errors: 0:0 overruns: 0 carrier: 0
collisions: 0 txqueuelen:1000
RX bytes: 24913472 (23.7 MiB) TX bytes: 4369984705 (4.0 GiB)
eth0: 1 link encap HWaddr 00: 0C: 29:BC:43:1 B
INET addr:192.168.50.120 Bcast:192.168.50.255 mask: 255.255.255.0
RUNNING BROADCAST MULTICAST MTU:1500 metric: 1
eth0:2 Link encap HWaddr 00: 0C: 29:BC:43:1 B
INET addr:192.168.50.122 Bcast:192.168.50.255 mask: 255.255.255.0
RUNNING BROADCAST MULTICAST MTU:1500 metric: 1
eth0:3 Link encap HWaddr 00: 0C: 29:BC:43:1 B
INET addr:192.168.50.123 Bcast:192.168.50.255 mask: 255.255.255.0
RUNNING BROADCAST MULTICAST MTU:1500 metric: 1
eth0:4 Link encap HWaddr 00: 0C: 29:BC:43:1 B
INET addr:192.168.50.124 Bcast:192.168.50.255 mask: 255.255.255.0
RUNNING BROADCAST MULTICAST MTU:1500 metric: 1
eth1 Link encap HWaddr 00: 0C: 29:BC:43:25
INET addr:192.168.29.10 Bcast:192.168.29.255 mask: 255.255.255.0
ADR inet6: fe80::20c:29ff:febc:4325 / 64 Scope: link
RUNNING BROADCAST MULTICAST MTU:1500 metric: 1
Fall of RX packets: 471 errors: 0:0 overruns: 0 frame: 0
Dropped packets: 664 TX errors: 0:0 overruns: 0 carrier: 0
collisions: 0 txqueuelen:1000
RX bytes: 82216 (80.2 KiB) TX bytes: 107920 (105.3 KiB)
eth1:1 Link encap HWaddr 00: 0C: 29:BC:43:25
INET addr:169.254.75.201 Bcast:169.254.255.255 mask: 255.255.0.0
RUNNING BROADCAST MULTICAST MTU:1500 metric: 1
Lo encap:Local Loopback link
INET addr:127.0.0.1 mask: 255.0.0.0
ADR inet6:: 1/128 Scope: host
RACE of LOOPING 16436 Metric: 1
Fall of RX packets: 10626 errors: 0:0 overruns: 0 frame: 0
Dropped packets: 10626 TX errors: 0:0 overruns: 0 carrier: 0
collisions: 0 txqueuelen:0
RX bytes: 7942626 (7.5 MiB) TX bytes: 7942626 (7.5 MiB)
I think it's because of the failure on node 2
UPDATE:
That thing is normal, I ignored it and the installation can continue normally. Thank you all for your help.
-
When I run the "@ddl_setup.sql" on a node of the 11gr2rac getting errors
I want to open DDL replicate of the source node, so I run
SQL > @marker_setup
Marker setup script
You will be asked the name of a schema for Oracle GoldenGate database objects.
NOTE: The schema must be created before running this script.
NOTE: Stop all replication DDL before starting this installation.
Enter the Oracle GoldenGate name schema: ogg
Table marker installation script is completed, run the script to check...
Please enter the name of a schema for GoldenGate database objects:
Name of schema setting for OGG
MARKER TABLE
-------------------------------
Ok
SEQUENCE MARKER
-------------------------------
Ok
When I run the "@ddl_setup.sql" on a node of the 11gr2rac getting errors
SQL > @ddl_setup.sql
Configure Oracle GoldenGate DDL replication script
Verify that the current user has privileges to install the DDL replication...
You will be asked the name of a schema for Oracle GoldenGate database objects.
NOTE: For a source of Oracle 10 g, the basket of the system must be disabled. For Oracle 11 g and later, it can be activated.
NOTE: The schema must be created before running this script.
NOTE: Stop all replication DDL before starting this installation.
Enter the Oracle GoldenGate name schema: ogg
Working, please wait...
Line to the ddl_setup_spool.txt file
Checking the sessions that hold locks on the tables of metadata Oracle Golden Gate...
Full version.
Using OGG as Oracle GoldenGate scheme a name.
Working, please wait...
Script of DDL replication configuration has completed, run the script to check...
Please enter the name of a schema for GoldenGate database objects:
Name of schema setting for OGG
CLEAR_TRACE STATUS:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
CREATE_TRACE STATUS:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
TRACE_PUT_LINE STATUS:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
INITIAL_SETUP STATUS:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
STATUS OF THE DDLVERSIONSPECIFIC PACKAGE:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
STATUS OF THE DDLREPLICATION PACKAGE:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
DDLREPLICATION STATE OF PACKAGE BODY:
Error on line/pos
-------------------- -----------------------------------------------------------------
1453/9 PL/SQL: statement ignored
1455/23 PL/SQL: ORA-00942: table or view does not exist
1464/9 PL/SQL: statement ignored
1466/23 PL/SQL: ORA-00942: table or view does not exist
1478/9 PL/SQL: statement ignored
1480/23 PL/SQL: ORA-00942: table or view does not exist
1485/9 PL/SQL: statement ignored
1487/23 PL/SQL: ORA-00942: table or view does not exist
1492/9 PL/SQL: statement ignored
1494/23 PL/SQL: ORA-00942: table or view does not exist
1499/9 PL/SQL: statement ignored
Error on line/pos
-------------------- -----------------------------------------------------------------
1501/23 PL/SQL: ORA-00942: table or view does not exist
1581/4 PL/SQL: statement ignored
1582/18-PL/SQL: ORA-00942: table or view does not exist
1584/4 PL/SQL: statement ignored
1585/18-PL/SQL: ORA-00942: table or view does not exist
1600/25 PL/SQL: ORA-00942: table or view does not exist
1600/4 PL/SQL: statement ignored
1602/25 PL/SQL: ORA-00942: table or view does not exist
1602/4 PL/SQL: statement ignored
DDL IGNORE TABLE
-----------------------------------
FAILURE: The Table does not exist
DDL IGNORED THE JOURNAL TABLE
-----------------------------------
FAILURE: The Table does not exist
STATUS OF THE DDLAUX PACKAGE:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
DDLAUX STATE OF PACKAGE BODY:
Error on line/pos
-------------------- -----------------------------------------------------------------
0/0 PL/SQL: analysis of completed Compilation unit
1/21 PLS-00304: impossible to compile a body of 'DDLAUX' without sound
specification of the
1/21 PLS-00905: OGG object. DDLAUX is not valid
SYS. STATUS OF THE DDLCTXINFO PACKAGE:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
SYS. DDLCTXINFO STATE OF PACKAGE BODY:
Error on line/pos
-------------------- -----------------------------------------------------------------
No error no error
DDL HISTORY TABLE
-----------------------------------
FAILURE: The Table does not exist
DDL HISTORY TABLE (1)
-----------------------------------
FAILURE: The Table does not exist
DUMP DOF TABLES
-----------------------------------
FAILURE: The Table does not exist
COLUMNS OF DUMP DDL
-----------------------------------
FAILURE: The Table does not exist
GROUPS OF LOG DUMP DDL
-----------------------------------
FAILURE: The Table does not exist
SCORES OF DUMP DDL
-----------------------------------
FAILURE: The Table does not exist
DDL DUMP KEY PRIMARIES
-----------------------------------
FAILURE: The Table does not exist
SEQUENCE OF the DDL
-----------------------------------
FAILURE: The sequence does not exist
GGS_TEMP_COLS
-----------------------------------
FAILURE: The Table does not exist
GGS_TEMP_UK
-----------------------------------
FAILURE: The Table does not exist
STATE OF THE DDL TRIGGER CODE:
Error on line/pos
-------------------- -----------------------------------------------------------------
126/9 PL/SQL: statement ignored
128/23 PL/SQL: ORA-00942: table or view does not exist
133/21 PL/SQL: ORA-02289: sequence does not exist
133/5 PL/SQL: statement ignored
657/14 PLS-00905: OGG object. DDLAUX is not valid
657/5 PL/SQL: statement ignored
919/25 PL/SQL: ORA-00942: table or view does not exist
919/4 PL/SQL: statement ignored
DDL TRIGGER SYSTEM STATUS
-----------------------------------
Ok
STATUS OF RACE DDL TRIGGER
----------------------------------------------------------------------
ACTIVE
OF "OGG". "" GGS_SETUP ".
*
ERROR on line 2:
ORA-00942: table or view does not exist
OF "OGG". "" GGS_SETUP ".
*
ERROR on line 2:
ORA-00942: table or view does not exist
OF "OGG". "" GGS_SETUP ".
*
ERROR on line 2:
ORA-00942: table or view does not exist
LOCATION OF THE TRACE OF DDL FILE
------------------------------------------------------------------------------------------------------------------------
/Home/data/app/Oracle/diag/RDBMS/AppStore/appstore2/trace/ggs_ddl_trace.log
Analyze the status of the installation...
THE STATE OF REPLICATION DDL
------------------------------------------------------------------------------------------------------------------------
ERRORS in the installation of software components of DDL replication (6)
Complete script.
I had been struggling with the same problem for 2 days. You run the script as sysdba, how do you get the error then insufficient? I did my first test GG in February. I've been on 11.2.0.3 + patch January + patch for the integrated capture. It has worked well for me. I went back to my GG test week with 11.2.0.3 + patch of July last and ran into the same problem. The solution for me was the last version of GG. See my previous post for the patch numbers.
Post edited by: ursusca
-
error after you run root.sh on the second node
Hello
I installed the clusterware on a system with 2 nodes running on RHEL 5
I followed the prereqs and fix all the errors I've met
After the installation of clusterware, he asked me to run root.sh on all nodes
When I run root.sh on the second node
It gave this error
Vipca (silent) to configure applications running
/ Home/Oracle/CRS/Oracle/product/10/CRS/JDK/JRE / / bin/java: error loading
shared libraries: libpthread.so.0: cannot open shared object file:
No such file or directory
so I followed metalink notes 414163.1
After that I called it a day
in the morning, will receive it started both nodes
and started on the second node vipca
It gave this error
Unable to communicate with the services of crs PRKH:1010
i ran ps - ef | grep crs
root 3201 1 0 15:37? 00:00:00 / bin/sh /etc/init.d/init.crsd run
crsctl check crs gave
demon of css contact failure 1
cannot communicate with the crs
cannot communicate with evm
What should I do to start these services?raw devices ownership is changed back to the root after reboot, which is why its usual practice to add chown/chmod to /etc/rc.local for example:
chown oracle: oinstall/dev/sde1
chown oracle: oinstall/dev/sdf1
chmod 600/dev/sde1
chmod 600/dev/sdf1 -
Hello
Question: What is the best way to get a tip action to execute only once during the lifetime of an execution?
My script: I have a project with 80 slides in there to learn. Slide 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, I use onEntry event to perform actions advanced designed for each of these numbers. Given that users are allowed to go forward and backward slide, slide 10-100 event are executed several times, depending on how much time users visit these specific slides. My question is, what is the most effective way to ensure that a tip action is executed only once. Say a user reached slide 10 and advanced action "foo10" is executed. If this user has decided to return to slide 10, I don't want to foo10 advanced action to be executed again.
My solution: I would create Boolean variables for each of the advanced actions. foo10 ... foo100. If the corresponding var bool is false, do not run the action, run another action assigned.
Question: What is the best way to get a tip action to execute only once during the lifetime of an execution?
Thank you.
If it was a success (for an interactive object) event, you could disable this object with the same action as the advanced conditional action. Using the system variable LastVisitedSlide will probably exclude not all possible situations. A Boolean variable is probably the best choice. Since you're on 9 Captivate, make sure to use shared instead of shares advanced actions, you will save time (and the size of the file).
-
Composite running creates performance problems
Hi all
I have a scenario where my soa case are in working order, until the other transaction is completed. Assume that, if a purchase Transaction is blocked for days, composites would be waiting for the answer until he answers. Are these composites running creates impacts on performance, assuming that 100 instances are run daily and all are waiting for the answer.
Two hundred
KnaniAs long as your instances are dehydrate while you wait for the answer, you're good.
-
WIN7 settings can improve performance? Other forums?
Nothing you can do about it. You must be very techie trying to change a processor, it is still possible.
It is possible that some driver or setting is in Windows that causes this problem, but I don't know of one.
During the examination of a computer, always look for the first processor. Benchmark CPU Google then just the designation of the cpu.
Your is T7400 and has a score of 1260 reference. It is indeed very low. Pentium 4 has about 800. Most of the score today 7500 at least 2500 and many CPUS.
-
Intel SRCS16 on ESX4 - poor write performance
Hello world!
I need to change HD on one of my ESX hosts that have only 250 GB of total space, while we buy 5 HD 1 TB.
This weekend, I put another control (Intel SRCS16) Raid and connect a 1 TB just to copy a VM of old HD to the new.
Matrix Raid took less than 1 min.
Creation of partition on the raid drive took less than 1 min. (with fdisk)
Partition formatting took more than 3 hours (with mkfs.ext3)
Test write performance with: time dd if = / dev/zero of=/mnt/share/test.test bs = 1 M count = 1024
And took approximately 18 min. (1 Mb/s)
Research on google, I find some useful links.
On the Vmware communities, I found this: http://communities.VMware.com/thread/105552?start=0 & tstart = 0
But it does not work.
Someone has an idea?
Thanks for your help
SRCS16 Intel has some extremely poor write performance without cache enabled writable. For normal operations with write cache, you should have BBWC (battery backup). Enabling write without BBWC cache may lead to the loss of data in case of power failure.
UPD. See http://www.intel.com/support/motherboards/server/srcs16/sb/cs-020502.htm.
-
Why the DLL function performed by call library node fails when the Vi is reopened?
Development system
OS: Windows XP
LabVIEW: version 10.0
DLL: Custom
Compiler: Visual C++ 6.0
Function prototype: __declspec (dllexport) const char * test (void)
We have developed a DLL to use. Compile the DLL itself. The DLL includes a function test. The test function validates the functional capabilities of the DLL. I followed the examples online, and I used the tool to import shared library in LabVIEW. The screw created use the call library node.
When I create a VI by calling the function in the DLL test customized by using the call library node the VI runs the test DLL function flawlessly. I close the VI. When I re - open the VI and run it, I get an error code of the DLL. However, if I go on the schema and define the path of the DLL in the library call Configuration node once again the VI then runs the test DLL function perfectly again.
I have set the path of the DLL in the library call Configuration node everytime I open the VI. The examples that I downloaded from the community don't require this. What could be the missing DLL? What Miss me?
I solved the problem.
I had create the DLL by using the following steps for VC 6.0:
1. new project
2. Select the Appwizard (DLL) MFC
3. Select the regular DLLS using the MFC shared DLLS
4 Yes for source file comments
5 finishing
The DLL must be on the VI search path. The easiest way was to have the DLL in the same directory as the VI.
-
Running the command in the remote nodes scandisks
Version of grid infrastructure: 11.2.0.4
Platform: Oracle Linux 6.4
We have a cluster of CARS in production at 3 knots. We have created a group RAC 3 - node test for cloning for purposes
We are the automation level of SAN cloning of production test. After that the guys from Hitachi, take a snapshot of diskgroup production LUNS they present LUNS to the RAC cluster test. When testing the cluster, please proceed as follows to make cloning
Step 1. In node 1, run
/etc/init.d/oracleasm scandisks
Step 2. In Node2 run
/etc/init.d/oracleasm scandisks
Step 3. In Node3, run
/etc/init.d/oracleasm scandisks
Step 4.
srvctl start diskgroup g < Name_DG > - n Node1
srvctl start diskgroup g < Name_DG > - n Node2
srvctl start diskgroup g < Name_DG > - n Node3
Step 5. Finally, start the beginning of the database the database test by using clustering
srvctl start database-d MANHPRD
Since a shell script, I would like to run the above1step,2 and 3 of Node1 in sequential order as shown above. How can I do this? I'm not worried about step 4 and 5, as it can be run from all nodes.
Page Hello,
Why not use ssh? very simple
node 1:
SSH root@node2 /etc/init.d/oracleasm scandisks
take note of the guy! Comment
edited: take a look at Tobi & #39; s Oracle DBA & amp; Blog of UNIX: Cloning ASM Diskgroup to create the database Clone
-
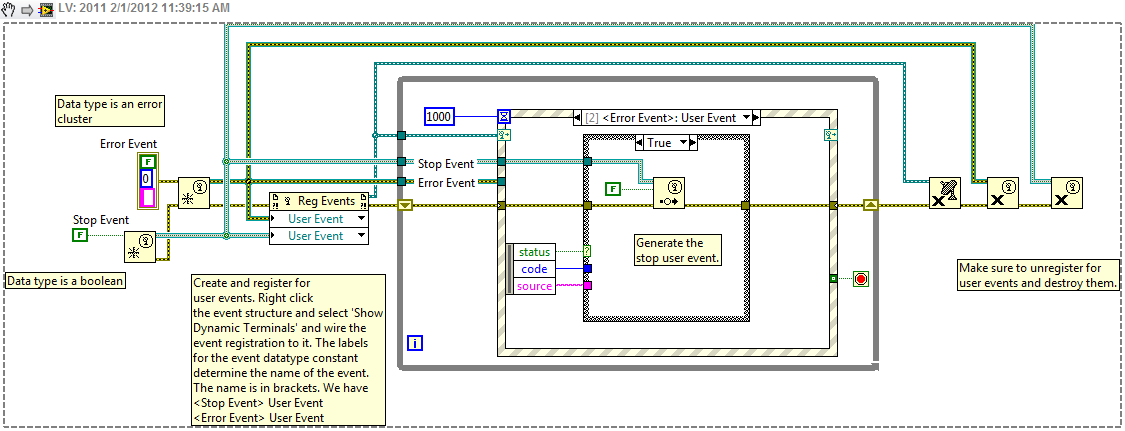
Error disables all other events
I use a property node for my STOP to fire an event in an event. Everything worked fine when I just threw it together; error handling added and cleaned things it didn't work anymore. The symptom was that my activity within the first event never seemed to fire.
I broke it down to simple stuff and I discovered what causes this but I do not know why... as usual. Apparently, when I run a cluster of error through my property node AND I intercept a mistake (simulated by activating me / disabling the Boolean value to T as in the screencap) no other event doesn't work except one running, which is be the Application Timeout event. If no error, I can trigger events in the events throughout the day.
No other event except timeout and "stop-> change the value" in my small no sample VI. My solution was to avoid running the error via the property node cluster.
Nodes typically will not run if the error is true. There are exceptions such as the closure of the references. The help of LabVIEW will tell you if the node is running when the error is true. The property node will not run because you forced a mistake inside.
Test the user events. Of course, there is much more involved threads. But you can use the Action engine to store the references and hide the creation, registration, cancellation of registration and destruction of user events.
Time-out will continue execution. The loop has a wrong cable to the terminal if true stop. Need to wire a - 1 for the terminal to stop execution of the time-out period.
Here is something which I think is what you're trying to do. He studied with the help of open context and highlight on execution. (Also attached for LV8.2)
-
Performance difference between ESX 3.5 and ESX4?
Someone at-expirience of real-life performance difference esx 3.5 to esx 4.0?
Thanks in advance
Yes. Just having ESX4 running if your guests are 32-bit or 64-bit, we saw the best performance all around. In addition, something worth looking at are VMmark results
-
Problems running performance check
Hello my name is Luiza and I have a Dell Inspiron 3521.
A couple of weeks ago, my laptop started showing blue screens. I tried to get it back in many ways, and none of them has solved my problem.
Then, two days ago I was able to recover to factory settings, but the problem was still there (blue screen).
When running a performance test, he gave the following error message:
Error Code 2000 - 0151
Validation 106482
MSG: Hard drive 0 - S316J90DB31960 S/N, wrong state = 32
No additional sense information.
What does that mean?
Under warranty: contact Dell with exactly the code error and validation and they will replace the drive.
Out of warranty: you will need a new 2.5 "SATA laptop drive (HDD, SSD hybrid drive system) - hard drive failed.
-
My Satellite A200 - 1 GB scored 4.7 Windows Vista Performance Rating
Hi all
I run a Performance Rating in Windows Vista yesterday.
It is excellent!
Base score was 4.7 (overall rating)Under Scores as follows:
{color: #0000ff}
Processor calculations: 4.9
Memory :4.8
Aero Glass graphics: 4.7
Games graphics: 4.7
HARD drive: 4.7 {color}I'm thrilled about my new A200 - 1 GB.
I found his performance is very good with Win Vista.Thanks again for Toshiba!
Dear friends... Send comments on this...
Kind regards
Updates will not increase this Vista scores!
I noticed that each new installation of driver or the application decreases the score.I found lots of useful information on other computers and websites vista and it seems that is nothing unusual. It seems all the operating systems and the modification of the registry entry has a bad influence on this Vista partition.
Need simply s Vista ;)
Maybe you are looking for
-
Home page does not load correctly
My home page is my.yahoo.com and is listed as homepage under Options > general. This address is my custom Yahoo page. FF v. 21 (just updated yesterday) at the start of the generic version of My Yahoo begins with the URL http://my.yahoo.com/?_bc=1. So
-
Cannot start the installation of recovery for Portege M200
Hello I've used the DVD of recovery a long time ago, but now he won early t. Instructions tell you to:1 insert the disc2nd turn the pc on while keeping the key C pressed3. follow the instructions that appear on the screen I tried as indicated but not
-
cannot start.hardware unit-(Code 19)
Windows cannot start this hardware device because its information of configuration (in the registry) is incomplete or damaged. (Code 19) Model: HP Pavilion Elite e9120y Desktop PC - System Diagnostics report - warnings-errors g = compact flash Failur
-
Looking for advice, I downloaded an application, all good. My second application (based on the example of gesture) works for me on the spot, but the versions that I presented for approval keeps refusing due to "after installation on Playbook, when op
-
Vector.addElement problem to 4.6.0
I'm having a problem with addElement incoherent adding items to a vector vChecklists. When the program is run, the following code runs as I predicted for the first couple of iterations. However, on the third iteration, the addElement method adds an a