VI of script to read comments of block diagram
Hi people,
I have a small project to attempt to harvest comments in the block diagram, perhaps the help of scripts of VI. So, for example, when I'm checking #ToDo comments, I can get a list of the VI appearing in the #tag and collect the text. I think I found the method to get the comment, but I don't know how to recover the text in the comment. Here is a picture of how to get to observation in the block diagram (just using this as one small example VI)
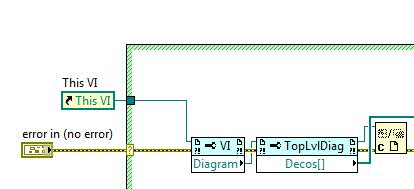
Thanks for your help!
Rik
James.Morris wrote:
Here's what you want. It is worth noting that the current code only outputs the comment outside the structure of the case because you will need to dive into the structure for what anyone inside.
Yes this will cross all GObjects, but I'm sure there's a bookmark API Manager that will return comments bookmark if this is what you are looking for.
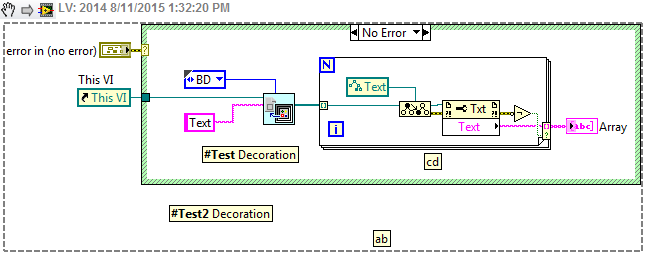
EDIT: Okay, there's an invoke node returns info bookmark on a VI but the VI reference may not be running.
Tags: NI Software
Similar Questions
-
Hi all
Could someone enlighten me please, what does this comment on the value of the ADC
"Terminals on component connector not on the block diagram of higher level of control.
This means that some terminals is hidden within certain structures of the case and does not show not not the diagram without going into the structures of the case or by 'higher level block diagram', it means
main.VI and main.vi controls must also be connected to the connector pane?
Thank you
K.Waris
On the one hand, this means that they run on your screws VI Analyzer, since it is a warning in extenso you receive. This means simply a terminal which is connected to the ConPane is not on the top level diagram, IE. within a structure of housing.
As to why he is often not a good idea to do that read this classic thread:
http://forums.NI.com/T5/LabVIEW/case-structure-parameter-efficiency/m-p/382516#M191622
-
"Physics read total multi block applications ' wrong?
Hello
The statistics "block the physical demands reading total multi" should count the number of calls to e/s over a reading block (doc here). So I expect to be equal to the 'file db scattered read' (or 'direct path read' if read series direct-path of access is used).
But this isn't what I get in the following unit test:
SQL > create table DEMO pctfree 99 as select rpad('x',1000,'x') n from dual connect by level < = 1000;
-I get the v$ filestat statistics in order to make a difference at the end:
SQL > select phyrds, phyblkrd, singleblkrds from v$ filestat when file #= 6;
PHYRDS PHYBLKRD SINGLEBLKRDS
---------- ---------- ------------
6291-96488-3286
I'm doing a table scan complete on a table of 1000 blocks, forcing sql_tracing and stamped readings
SQL > connect demo/demo
Connected.
SQL > alter session set "_serial_direct_read" = never;
Modified session.
SQL > alter session set events =' waiting sql_trace = true ";
Modified session.
SQL > select count (*) in the DEMO.
COUNT (*)
----------
1000
SQL > alter session set events = 'off sql_trace. "
session statistics see the 30 requests for e/s, but only 14 requests for multi block:
SQL > select name, value of v$ mystat join v$ statname using(statistic#) whose name like "% phy" and the value > 0;
NAME VALUE
---------------------------------------- ----------
total read physics applications of e/s 30
physical read total multi block 14 requests
total number of physical read 8192000 bytes
physical reads 1000
physical reads cache 1000
physical read IO request 30
bytes read physical 8192000
physical reads cache prefetch 970
However, I did 30 'db file squattered read:
SQL > select event, total_waits from v$ session_evenement where sid = sys_context ('userenv', 'sid');
TOTAL_WAITS EVENT
---------------------------------------- -----------
File disk IO 1 operations
1 log file sync
db file scattered read 30
SQL * Net message to client 20
SQL * Net client message 19
V$ FILESTAT counts them as multiblock reads as follows:
SQL > Select phyrds-6291 phyrds, phyblkrd-96488 phyblkrd, singleblkrds-3286 singleblkrds in v$ filestat when file #= 6
PHYRDS PHYBLKRD SINGLEBLKRDS
---------- ---------- ------------
30 1000 0
And this is confirmed by sql_trace
SQL > column tracefile new_value by trace file
SQL > select the process trace file $ v where addr = (select paddr in session $ v where sid = sys_context ('USERENV', 'SID'));
TRACE FILE
------------------------------------------------------------------------
/U01/app/Oracle/diag/RDBMS/dbvs103/DBVS103/trace/DBVS103_ora_31822.TRC
SQL > host mv and tracefile series-live - path.trc
SQL > host grep ^ WAITING series-live - path.trc | grep read | NL
1. WAIT #139711696129328: nam = "db-scattered files reading" ela = 456 file #= 6 block #= 5723 blocks = 5 obj #= tim 95361 = 48370540177
2. WAIT #139711696129328: nam = "db-scattered files reading" ela = 397 file #= 6 block #= 5728 blocks = 8 obj #= tim 95361 = 48370542452
3. wait FOR #139711696129328: nam = "db-scattered files reading" ela = 449 file #= 6 block #= 5737 blocks = 7 obj #= tim 95361 = 48370543216
4 WAIT #139711696129328: nam = "db-scattered files reading" ela = 472 file #= 6 block #= 5744 blocks = 8 obj #= tim 95361 = 48370543816
5. WAIT #139711696129328: nam = "db-scattered files reading" ela = 334 file #= 6 block #= 5753 blocks = 7 obj #= tim 95361 = 48370544276
6 WAIT #139711696129328: nam = "db-scattered files reading" ela = 425 file #= 6 block #= 5888 blocks = 8 obj #= tim 95361 = 48370544848
7 WAIT #139711696129328: nam = "db-scattered files reading" ela = 304 case #= 6 block #= 5897 blocks = 7 obj #= tim 95361 = 48370545370
8 WAIT #139711696129328: nam = "db-scattered files reading" ela = 599 file #= 6 block #= 5904 blocks = 8 obj #= tim 95361 = 48370546190
9 WAIT #139711696129328: nam = "db-scattered files reading" ela = 361 file #= 6 block #= 5913 blocks = 7 obj #= tim 95361 = 48370546682
10 WAIT #139711696129328: nam = "db-scattered files reading" ela = 407 file #= 6 block #= 5920 blocks = 8 obj #= tim 95361 = 48370547224
11 WAIT #139711696129328: nam = "db-scattered files reading" ela = 359 file #= 6 block #= 5929 blocks = 7 obj #= tim 95361 = 48370547697
12 WAIT #139711696129328: nam = "db-scattered files reading" ela = 381 file #= 6 block #= 5936 blocks = 8 obj #= tim 95361 = 48370548287
13 WAIT #139711696129328: nam = "db-scattered files reading" ela = 362 files #= 6 block #= 6345 blocks = 7 obj #= tim 95361 = 48370548762
14 WAIT #139711696129328: nam = "db-scattered files reading" ela = 355 file #= 6 block # 6352 blocks = 8 obj #= tim 95361 = 48370549218
15 WAIT #139711696129328: nam = "db-scattered files reading" ela = 439 file #= 6 block #= 6361 blocks = 7 obj #= tim 95361 = 48370549765
16 WAIT #139711696129328: nam = "db-scattered files reading" ela = 370 file #= 6 block #= 6368 blocks = 8 obj #= tim 95361 = 48370550276
17 WAIT #139711696129328: nam = "db-scattered files reading" ela = 1379 file #= 6 block #= 7170 blocks = 66 obj #= tim 95361 = 48370552358
18 WAIT #139711696129328: nam = "db-scattered files reading" ela = 1205 file #= 6 block #= 7236 blocks = 60 obj #= tim 95361 = 48370554221
19 WAIT #139711696129328: nam = "db-scattered files reading" ela = 1356 file #= 6 block #= 7298 blocks = 66 obj #= tim 95361 = 48370556081
20 WAIT #139711696129328: nam = "db-scattered files reading" ela = 1385 file #= 6 block #= 7364 blocks = 60 obj #= tim 95361 = 48370557969
21 WAIT #139711696129328: nam = "db-scattered files reading" ela = 832 file #= 6 block #= 7426 blocks = 66 obj #= tim 95361 = 48370560016
22 WAITING #139711696129328: nam = "db-scattered files reading" ela = 1310 file #= 6 block #= 7492 blocks = 60 obj #= tim 95361 = 48370563004
23 WAIT #139711696129328: nam = "db-scattered files reading" ela = 1315 file #= 6 block # 9602 blocks = 66 obj #= tim 95361 = 48370564728
24 WAIT #139711696129328: nam = "db-scattered files reading" ela = 420 file #= 6 block # 9668 blocks = 60 obj #= tim 95361 = 48370565786
25 WAIT #139711696129328: nam = "db-scattered files reading" ela = 1218 file #= 6 block # 9730 blocks = 66 obj #= tim 95361 = 48370568282
26 WAIT #139711696129328: nam = "db-scattered files reading" ela = 1041 file #= 6 block #= 9796 blocks = 60 obj #= tim 95361 = 48370569809
27 WAIT #139711696129328: nam = "db-scattered files reading" ela = file No. 300 = 6 block #= 9858 blocks = 66 obj #= tim 95361 = 48370570501
28 WAIT #139711696129328: nam = "db-scattered files reading" ela = 281 file #= 6 block #= 9924 blocks = 60 obj #= tim 95361 = 48370571248
29 WAIT #139711696129328: nam = "db-scattered files reading" ela = 305 file #= 6 block #= 9986 blocks = 66 obj #= tim 95361 = 48370572021
30 WAIT #139711696129328: nam = "db-scattered files reading" ela = 347 file #= 6 block #= 10052 blocks = 60 obj #= tim 95361 = 48370573387
So, I'm sure that I did 30 reading diluvium but block total multi physical read request = 14
No idea why?
Thanks in advance,
Franck.
Couldn't leave it alone.
A ran some additional tests with sizes of different measure, with and without the SAMS.
It seems that my platform includes no readings of scattered file db less than 128KB in the physical count. (or 16 blocks, given that I was with a block size of 8 KB).
Concerning
Jonathan Lewis
-
Update of Lightroom 5.7 mentions "Support with the ability to add or read comments provided on Lightroom web" I can't find anything that explains what 'Lightroom Web '. Just curious.
This article will give you an introduction to Lightroom mobile in 5.7:
-
Why the adobe reader software is blocking all access to pdf files
software Adobe reader doesn't block my access to pdf files. Says I have to sign the contract of use I did. How can I get on it?
If you are on Mac and installed the Adobe Reader software to the deafult location.
Try this:
1. Quit Safari
2. from Finder > go > go to folder... > type in the path: /Applications/ and click 'Go '.
3. run "Adobe Reader"
4. accept the end user license
5. open a PDF file in Safari.
-
script/steps to corrupt data blocks
Please give me some script/not to corrupt data blocks (not the data files).
I need to check for the recovery test.
Thank youhttp://www.oracleflash.com/9/How-to-perform-block-media-recovery-using-RMAN.html
-
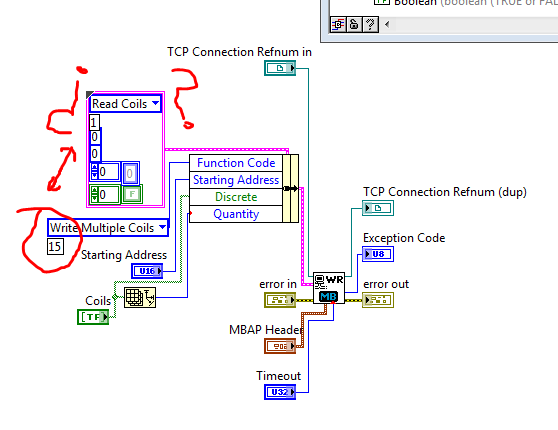
What this block diagram?
Match a VI Modbus Library. But I have because if the block is configured to write multiple coils in the coils because reading is set to 1?
All this work?
Sorry if the question is a beginner.
In this block diagram, 'Coils Read' and 'Write multiple coils' are enumerated values (or possibly ringtones of appeal, which is not serious for the purpose of this explanation). Enumerations assign names to numbers, to make them easier to read. The coils Read command is set to 1, the command to write multiple coils has a value of 15. You don't need to worry about this number, however, because the enumeration takes care of it for you.
The constant cluster containing coils of reading is there just to provide the correct data type (a cluster with the right items). Almost all the elements of the latter shall be replaced by the values of wired in the Bundle to node Name. For example, the value of reading coils is there as a placeholder for any function Code. the actual Code of the function is defined by plugging write multiple coils in Bundle by name.
-
Clean using SubVIs block diagram
Hi guys and welcome to my first post!
I m a bit new to labview, so be a little patient, if I do not understand everything immediately

Im working on an existing program that is used to control an MCU on BabyLin on my front, although I have a visualization to see live changes to the system. The program works very well so far, but I m trying to clean up the block diagram. This should be done by subvis, right? I ve read a lot about the size of the block diagram should not increase my screen. Well, im at a length of about 3 x 2 screens (24 "!) after trying to use subvis and to shorten the distances between structures. The only things remaining are huge amounts of local variables and references (they existed already before I got to know the program), mainly for viewing. If I create a Subvi part containing the people of the country, it will change the references that does not make the program more readable (and small), and I guess I can't put a new Subvi on references + Subvi.
You have any ideas what to do? I hope that I forgot something, otherwise, do not hesitate to ask.
Kind regards
Leo
Bob_Schor wrote:
To get a handle on the structure of your high-level code, write down (as if you were telling your boss or tell your wife - who knows, they might be the same person!) that you are trying to do. Keep it pretty General. You specified a number of steps? So maybe the top level should be a State Machine, or a message in queue manager. Describe you something that works at a constant speed, generating data that you have to manage "on the fly"? Maybe it's a design of producer/consumer.
You have a lot of initialization? Put in a Subvi, bring the 20 son out in a bundle (it's "Boss-word" for a Cluster). Your main program must have a few loops, with values that persist (possibly changing) during the program running in Shift Registers near the top of the loop, with tables and Clusters used to keep related items "consolidated".
Not too bothered by the size of your routine - I recently downloaded a monster 50-monitor the Forums (I did not even try to understand), up to 6 monitors is nothing!
Let "encapsulate the function" and "hide details" to be your guide in the reflection on the creation of the screws.
Bob Schor
To develop on the analogy of Bob, each talking point can be a Subvi. In other words, code group associate subVIs. The advantage of this is that it is much easier to solve problems because all errors will be localized to a Subvi. Errors no longer Chase around the block diagram. I guess you can use your current VI as an example of what NOT to do on the block diagram.

-
In LabVIEW 2010, I have a Def Type control i.e. a Cluster with several other controls within the Cluster. Apparently, the references to the controls in the block diagram are based on the order that the controls have been added to the Type definition command. The side effect of this is that if a control is removed from the command of Type definition, many of the done Variable reference in the block diagram or now either broken, or worse still, refer to wrong control in the Type definition. These problems are quite difficult to find and fix.
Comment: If you create a control of Type definition and make a Cluster. Now add any controls to the Cluster in an order, let's say A, B, C, D. Their types does not matter. Now use the Type definition in one or more controls on the front panel. In the block mark references to controls inside the Type Def would control on FP. Now return to the Type definition and remove the command B of the definition of Type. Now, lots of errors appear. Broken links. But worse still, you see old references to B that now refer to C and old references to C are now referring to the old references to D and D are removed altogether, etc.. This side effect is much more errors, broken links and misreferences than expected otherwise.
How add and remove controls anywhere in a Cluster in a Type definition, at will, without creating a whole bunch of errors in program, broken links and misreferences for controls in the Type definition that have not changed?
-
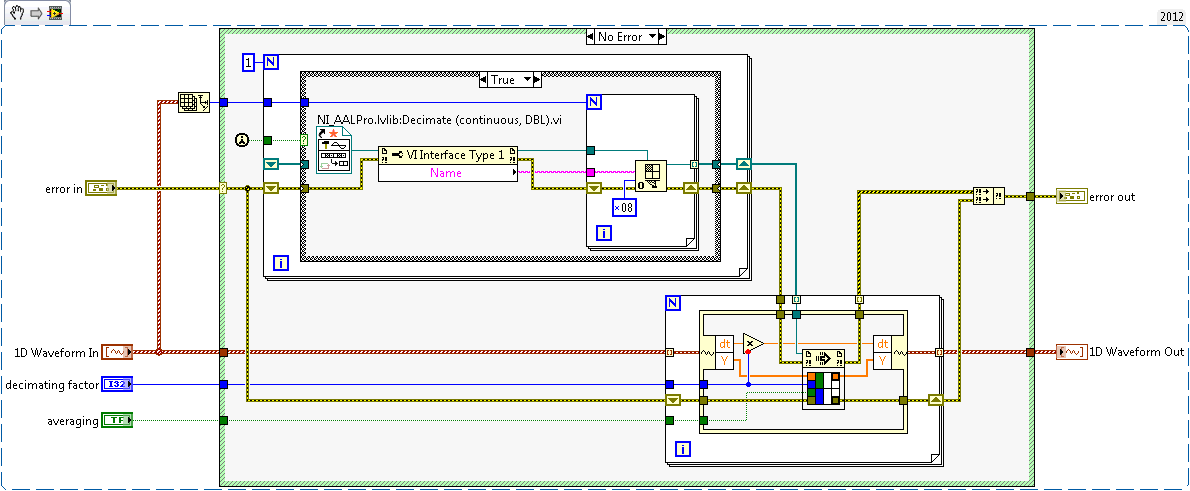
I have a double 2D chart I want to decimate continuously using the ".vi (continuous) Decimate" located in the range of Signal Processing. This VI is set on reentrant preallouee clone because it uses a FGV to save the State of the call to. What I could do, but do not want to, is having a huge index table and wire 20 + 1 table of DBL to 20 + unique VI instances decimate to ensure that each have their own data space and no 'cross-talk' doesn't happen, then 'picture of generation' all back after the fact.
I'm almost certain, there is a much cleaner way to do it with only one instance of unique block diagram of the VI decimate using techniques of the call by reference. I found my way to this link: Preallocated-Reentrant-VI-within-Parallelized-For-Loop that talks about something similar. After reading pages of four and the detailed help about the function 'Open VI référence' my head is spinning again on what option I want to spend (0x08 or 0x40 + 0x100) to ensure that whenever a slna 2D table come in, each of them is decimated by using the same clone that was used the last time it was called.
Although the DBL entry 2D array always has the same number of lines, now, it is not always in the future this number and ideal would not force me to create several references strictly typed in VI decimate that will have to change as grows the number of rows in the table 2D static DBL.
Anyone ready to set up an example VI that takes an array 2D arbitrary of DBL as input, decimating each line using the same clone independent of the "Decimate (continuous) .vi" and outputs the newly decimated 2D Array of LDM? Assume that each line uses the same factor of decimation and 'Sprawl' set to False.
Necessity is the mother of all invention and since it upsets me when I read a post that has a similar problem with no resolution, I felt compelled to post mine here. I'm sure it's better I can do within the current state of LabVIEW. The only question I have is what happens if I put the call by reference for loop be parallelizable? That trash completely the nature of 1 to 1 of what I intended?
-
What is the best way to keep the block diagram / cleaning of façade?
Hello
I'm relatively new to Labview so I'm not able to say if I'm overloading my programs or make my too crowded block diagram. I was wondering if there was some ways to tell if I can simplify my programming just by looking (perhaps only experience contributes to these things)?
I enclose my VI here. Currently, she is able to monitor the voltage and current of two engines. On the screen, you can see an indicator with the voltage and current values and there are cards that can display signals of different engines with a menu drop-down.
The façade is pretty clean, in my opinion of novice, but the block schema seems messy to me, just at the first glance. I foresee a problem occurring in the future however. In the future, I will have the VI to monitor 50 engines globally. All of the programming will be the same as the one I have now, but it will have 50 indicators and unfortunately 50 times just about everything. I would like to avoid this, but I don't know how I did.
I use a USB-6009. I use its four differential inputs to monitor the voltage and current of the two engines. In the future, I will get more units DAQ (25 in total because 2 motors can be monitored for each data acquisition). The new Renault will help will help with more resource space, but I think things complicate with the added option of 24 more Assistants of data acquisition (as used in my code).
Thanks for any help you might be able to provide!
Usually, it is above all the experience that will teach you the best methods for making your code to do pretty. I don't know anyone who is proud of his first application of claws. There are some resources out there to help with best practices, as that group on ni.com, but you will learn most of your own development.
Your façade is superb. FPs in general really are to you. You can do it as ugly or pretty as you want. When you have a few controls in duplicate and the Group of indicators, you should use clusters and berries to simplify. You can use a bit of cleanup in this regard, but not much. In addition, I personally hate read red text unless it is a warning any.
Your block diagram could use a little cleaning in a sense of modularity. You have a lot of repeated code, which you might consolidate in to a Subvi, which is used in multiple locations, or in a loop For. A general rule is to keep your block diagram within a single monitor. You should not scroll. Your application is quite simple, so it is difficult to BUMBLE

Here are a few details on your block diagram:
- Click with the right button on your devices on the block diagram and uncheck the "display as icon". You are welcome.
- Operations on each waveform "(x*2-4)" / 16 in double ": create a Subvi and/or run the waveforms through a loop."
- You do a lot of 2-element arrays and then indexing. Just replace the ones that have a Select node based on digital.
- All your code runs every time, including the knots of your property at the bottom, which is not necessary. As you learn LabVIEW architectures, you will learn how to get around this with the initialization and the output of code, but for now, you should put a case around those structure for only when the engine numbers change.
- I don't know how you're timing your main loop, but you should put a delay in there because you don't need the DAQmx node shoot as fast as your CPU will allow.
There are videos of intro free that you can watch to learn what OR think in terms of coding and teach you some of the basic features and such. Here's a three-hour course, and here's a six-hour course.
-
a lot of Group of variables together on block diagram
I was wondering if anyone knew a good way to organize a ton of variables on the block diagram? For example, I have 32 switches in this program and whenever I need to read or write from them that I have to use half of my screen just to install in. I can't think of a way to make it work using bundles or subvis. I have attached a picture of how I do things now, but advice on you guys how it would be greatly appreciated! Thank you
Assuming that you do not use indicators and controls in the space of the façade, you can put a cluster around the controls on the Panel (would be helpful if you included a picture of the FP). That's what I did, but I still need more controls half a dozen in the same group.
Kind regards
Michael Tracy
Synergy microwave
-
Is there a way to tell if the block diagram is open when a VI? I have a Subvi, which is defined in modal when it is opened. When troubleshooting, if I run my application, but forget to disable modal for the Subvi forcing the system to lock upward.
It would be nice if I could set the property of the VI not be modal if the schema has been opened.
Any suggestions?
I would try to do several things:
1) go to the properties of the VI > appearance of window and click on the Customize button. From there, uncheck the box for "see the front when it is called.
(2) when the VI starts, read the 'Front Panel Window.State' VI property - this will tell you if the window is already open, (IE, if the window is open, the State of the window will be 'standard', "Increased" or "Reduced"). Note: This is the visibility of the front, not the block diagram
(3A) if the VI is not already open, set the 'Front Panel Window.Behaviour' property to modal and then open the front panel by using the node to invoke VI of "Front Panel.Open". It's basically imitating the behavior you describe this moment.
3 (b) if the VI is already open, set the property to the default or floating behavior to allow you to click other windows.
(4) when it is finished, if the VI is not already open, close it manually using the Panel.Close before invoking node (if it was already open, leave it open)
I've attached a screenshot of that sort of thing. I hope this helps.
Shaun
-
Programaticaly inserting block block diagram.
Hello to all 2!
I wonder if there is a way to programaticaly insert a new block in an existing diagram.
Take a look at the attached vi to see what I mean.
So... When I click on an image of the corresponding function is inserted in the block diagram, having as inputs the two controls.
Is there a way to do this or is this just wishful thinking?
)Thank you very much!
It is possible to programatically manipulate the block scheme by obtaining a reference to it and operating on it with the use of the property and call the nodes. It's scripts of VI. You can write code that uses scripts in LabVIEW 7.1, but it can be imported in more recent versions of LabVIEW. This function is not supported by National Instruments. Being that it is not supported, I would not recommend research inside if you develop a code for a customer.
This should help you get started:
http://forums.lavag.org/VI-scripting-Readme-first-t1207.html
http://forums.lavag.org/LabVIEW-VI-scripting-F29.html&s=3fea8247be8d214406abf99a30e64e94 is a forum where you can ask on the scripts, being that it's about undocumented.
Welcome to the dark side, good luck in your journey and watch the rusty nails that you rummage through the attic of NOR. (lol sry, cheesy feeling on my lucnh break)
-
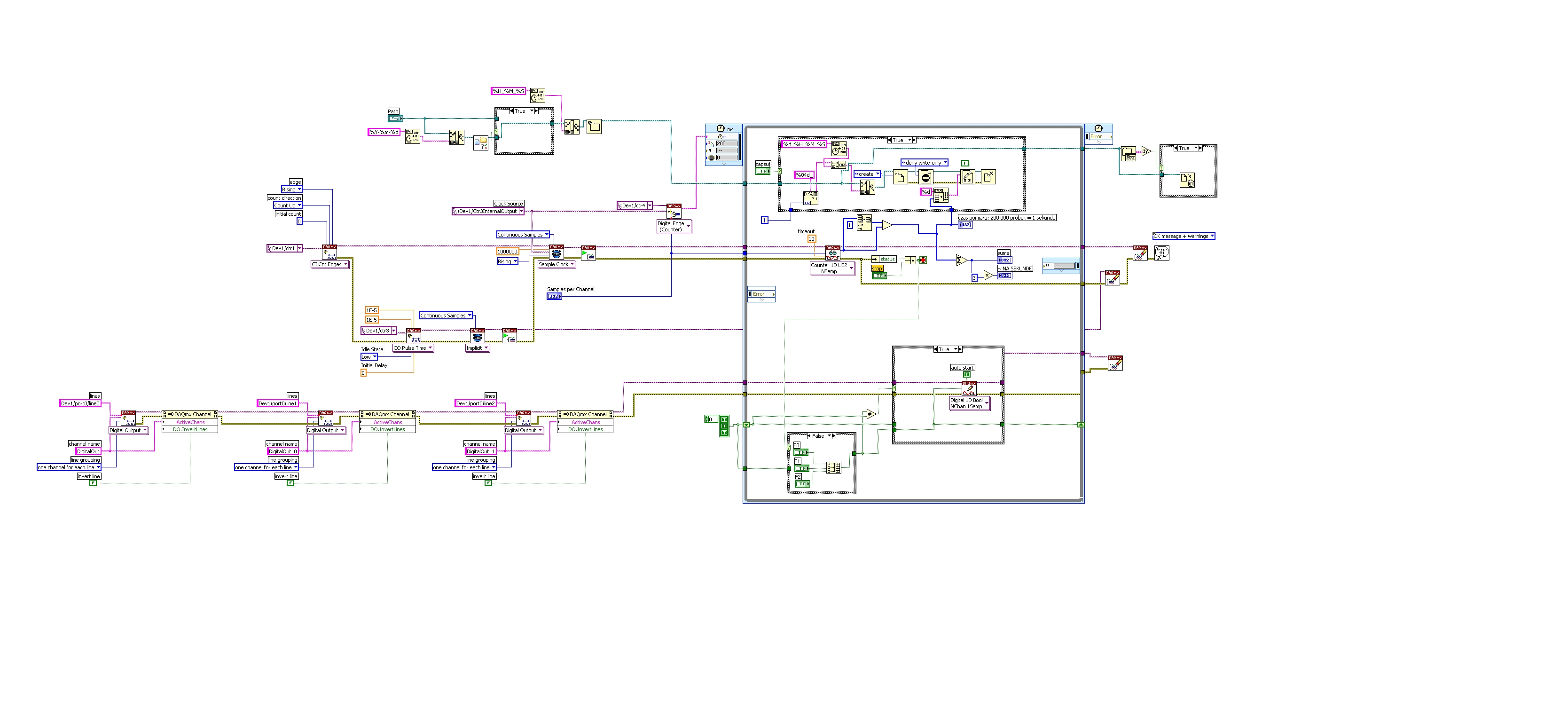
Block diagram of... block diagram
Hi, I need your help. IM the wrong person for this post, but I have to do, so I depend on your help. I need to explain how LabView (pasted below) program works, but I don't understand it myself
I would like to ask if someone can create a simplified block diagram of the pattern-block LV I paste it here. I appreciate all the help and please take considaration I am short on time
https://DL.dropbox.com/s/yd10z7yorxvbzux/LVdiagram.jpg
It is a counter. Meter of photons to be exact.
Hi, Rodolphe,.
I will try to explain briefly what is this application:
Following materials may help you understand the underlying concepts:
http://www.NI.com/PDF/manuals/371022k.PDF
It is the manual of series M - chapters 6.7 and 8 explains how digital lines, meter and what is a PFI.
When you open the block diagram of your application, you can see several branches ranging from left to write.
The first one on the top is to create a path to a file. This path will be used to write data to a binary file. The data represent the number of impulses which can be counted as edges rising a signal connected to the meter to 1. This information CA be read if you follow the logic on the second branch from left to right, where the first VI is CI INT edges (edges of counter), and it will count up, on a rising edge of the signal connected to CTR1.
Later, there is another task created for counter 3, that generates impulses. The pulse seems to have 10uS length and 50% duty cycle. The signal generated by this counter is used as sample clock for measure and 1 meter. In addition, the same meter signal 3 will be used by 4 meter from the digital dashboard and create a clock which will clock the timed loop. Basically, the frequency of the timed loop is given by the task on 4 meter which counts pulses generated with meter 3.
The 3rd branch from left to right, creates three tasks on three outputs digital: Line 0, 1 and 2 where it is controlled by three buttons F0, F1 and F2. Basically, your timed loop will be a specific iteration, and every iteration buttons will be read and will be updated to the specified digital output above.
Whenver there is a mistake or the button is pressed, your application stops and closes the binary file and dealocate resources used.
I invite you to also look in the above manual.
Best regards
Ion R.
{kind=link}
Maybe you are looking for
-
When you start firefox, my home page always looks bad until I update
When Firefox is started for the first time a Web page always seems bad until I update. Target any new page navigation, the window or tab open will look fine until I have re - open and close the program. It happens to the first navigation example imag
-
Help upgrade the RAM HP Pavilion n208tx
Hello I have a model of HP Pavilion n208tx with one slot containing 4 GB 1600 MHz DDR3L SDRAM. I am the need for India to upgrade my system to 12 GB total RAM. Since I'm totally new to this sort of thing I need help regarding this. As I said, I want
-
My xbox account is linked to an account non-existent live windows, how to make a change to an existing one?
-
My computer makes a loud roaring sound whenever I load the game farmville. She does it for all the time I play so when I click on it disappears. What is the cause?