With an average of data points
Hello
My setup is run by labview and wishes to reduce the noise associated with my data by taking more medium.
I would like to have the medium-sized data points and taking the average of them and save only the average at the same time the experience is
instance. For example. My experience is voltage vs field. For each field, I want three readings of voltage and the software must calculate the average, then
Enroll in the average in the data file. The reason why I do not repeat the measurement, it is that it would take some time to do it this way.
Can you advise how to do this with labview.
Thank you very much
Hi Alain,
Take a look at the attached vi. I think that this will solve your problem. It takes the average of the 3 simultaneous values of an array of random number and saves it in the txt file that you need.
Kind regards
Amine31
(Bravo to give good answers, mark it as a solution if your problem is Sloved )
)
Tags: NI Software
Similar Questions
-
What is an effective way to way logarithmic bin data with a constant number of points per decade?
Hi all
I would like to clean a logarithmic field of PSD in binning and averaging so that I have a constant number of points per decade (say 10, just for the sake of argument). Generally, means simpler and cleaner, I can think about getting this is research in the table entering all points between the frequencies A and B, with an average of these points and assigning a frequency (A + B) / 2 of the new average bin. However, I cannot find how to access frequency information, I need to achieve this. To be more clear, I can imagine if I had two tables, one who holds the frequencies calculated from my stream of incoming data, and the other which held and the amplitude of each corresponding frequency, that I might look for clues in the frequency table with values between A and B, then the average of the values in the table of amplitude which lie between the indices back put them in a new table with a new array of corresponding frequency. The process is a little more general that just on average every ten points, to say, as the number of points per decade continues to grow. My main obstacle at the moment, however, is that the amplitudes of the voltage are a set of values that receive through the operation of PSD, while the part of the frequency of the wave seems to be a DBL continues single-valued. I hope I've explained that well enough for someone to shed some light on my problem. Also, if anyone has a suggestion for a better way to approach the problem please let me know - there must be a pretty simple answer there, but it's deceiving me right now. Thanks in advance for the help.
-Alex
Hello
If I get you right. you have:
a table with the frequencies
a table with the corresponding values of amplitude
Then you want to merge parts of the data by averaging on the specific frequency ranges. I think that there is no VI 1 solution, you will need to write this on your own ():
I start to get the min/max of frequencies and then interpolate a scale from your needs (like logarythmic) mounting with the quantity of bins you want. This should be an array again.
Next step is to browse the frequency table, check (the first and) the last value in the location wanted (stop the loop, return the index). This should end up with an array of index. [I guess that's where you can save some computation time most by smart]
Finally, use these indices to browse the amplitude values and make your average. Should return an array of the length of your array of locations.
Ground in color fantasies and enjoy.
Just what you intend to do?
-
With an average of the data output.
Hello
I am a new user of Labview. I need to write a labview program that will average my output in a single data data.
Basically I have an XY graph which results in a table and the idea is to average the data points.
This is the kind of program that I use.
Thank you
Mutah
Hi Nicole,.
You can index the table and use the average function (within the mathematics - probability and statistics). Then, you will get the average value of each table. If you want to see the averages in a table, then you can combine average values in a table again...
Hope this help out you
-
Line chart of several series with staggered data points
Hello
App of Hillary graphic sample includes an examples of charts and how to handle null values.
https://Apex.Oracle.com/pls/Apex/f?p=36648:55
I came across a scenario which goes a step further. If you have a series with a set of data points and another series that overlap, where a few data points are missing, for example:
create table graph_lines (series number, thedate date, thevalue number); insert into graph_lines select 1 series ,add_months(trunc(sysdate,'yy'),rownum-1) thedate ,log(2,rownum) thevalue from dual connect by level <= 12 union all select 2 ,add_months(trunc(sysdate,'yy'),rownum-1) ,case when mod(rownum,3) =0 or rownum =2 then log(3,rownum) end from dual connect by level <= 12;
I get the case where he's going to draw a line between the points that are next to each other, but the gaps it will display just the point

Https://apex.oracle.com/pls/apex/f?p=73000:35 image
I have no doubt a single this is the expected behavior, but I would like to know if anyone has any ideas on how to connect the dots.
I thought about a snazzy model clause generates middle in my data points might work, but this seems heavy handed and a little scary.
I thought that maybe there is a graphic solution?
APEX 4.2.x
Scott
The idea of 'Null' removal was not all that possible. After testing it out, I found apex will be always generated empty points. Explicitly define the XML to have only the data points with values does nothing either.
Because I thought it was a really interesting problem, I was wasting so much time on this :-). I was side on the reference guide and the user, modify the XML again and again and again.
I hoped that, by defining a second category axis and set regional and datetime parameters, change of the shaft in one type datetime and specifying a main grid with every month, the table would be plot my data on this axis. Unfortunately, it seems as if this is ignored - a very frustrating experience. Anychart would just keep trace points with its own calculated intervals.
Ultimately if I stumpled on a sort of difficulty, although I'm not sure how good it would be. There is a setting that you can set by using the custom XML part that ignores the missing data and the values of interpolation. It works well, but it always displays labels.
https://Apex.Oracle.com/pls/Apex/f?p=11031:4 apex_demo/demo
AnyChart | [AnyChart 6.x] How to connect mind lines...
node - reference XML - AnyChart.Com Flash Chart Component With all these nodes, is it easy to miss what you need... It's a bit weird, but who "ignore the missing" points, you must set the value to "false"? :-)
-
with an average of streaming data
I take analog measurements on a module SCXI 1102C through a PXI for LV2009. I'm running the DaqMx Read 1 d Waveform to 100 samples per second in a while loop that runs every 45-50 MS, it means that I get about 5 data points per while the loop iteration. Even if the program is windows-based, it has a good amount of determinism built in. I now have to make a decision based on an average of 15 samples, preferably 25-50.
I can't slow down the while loop down because there are other channels in data that must trigger some things at the fastest rate possible in windows. I can live with the latency of 50 to 100 ms for the latter, but not the 500 ms I would get if I slowed the loop down to this new task.
Are the only two options that I came to use five registers with shift on the while loop, but I really don't like this idea. Or open the TDMS file while I write these data and read the seconde.25 block that I need a way to make a decision. Also seems to be a bad idea.
A third option, in my opinion, would be to place a Subvi who writes this string to five different functional space and constantly updates their creation of a buffer running. It seems not a bad idea, I just don't know how to implement it yet.
Any option obviously better that I'm missing?
There are two different methods that can be used. If the loop of writing runs more slowly that the loop of the acquisition, then the functional global is to keep a number of samples in it anyway. This allows more data work on when an average.
The other is to use a moving average. I have attached a VI that does this. It's a global functional on its own.
Rob
-
with an average of 5 minutes of data - is no way
I need average 5 minutes worth of data, save this average and then again on the next 5 minutes of data, with an average of this data block. I tried to use the average function pt-pt in LabVIEW, but who seems to take an average continuous market, I do not want. I probably read data once every 0.1 seconds, so I can not used stacked registers at offset, because it would be not very economical. I thought to build a table, but I don't know how to remove all the data at a time on average to it in an efficient manner, and more I'm stuck on the concept of re - create the table/clear the Board after five minutes of data has been collected, averaged and recorded.
Does anyone have a suggestion? I would really appreciate any advice or suggestions on how to go about it.
Keep a running total in a shift register. When your 5 minutes have expired, divide the sum by the number of samples taken, the sum to zero and start over.
-
With an average of groups of cells
Hi, I have a question that might be a simple, but I am struggling to find a response.
I'm looking for using blocks of cells. The goal is to take a large group of experimental data with many different reproductions by treatment and turn it into averages by treatment. Here's a simplified example: A1 to A3 contains data replication of treatment while A4 to A6 contains data for the next treatment, etc. A1: a3 must be averaged and put in a new table for his special treatment. Ditto for A4: A6, etc.. I understand how to do manually (= average(A1:A3)), (average(A4:A6) =), etc. for each cell in the new table. However, it is simply too long for this amount of data.
So I tried to set the function in the first cell export and dragging the AutoFill / the rest but this leads to a difference of 1 cell of the data sources. In this example, I need to exclude the three previous average cells next and use only three cells.
Is there a way to auto-fill the average function in groups of source cells? If so, can you recommend the procedure?
Maybe I'm looking just to the question in the wrong way.
Thank you for your help.
The f
If I understand correctly, you could do something like this:

The formula in A2 of the summary table is:
= AVERAGE (OFFSET (data: $A$ 1, 3 * ROW (−5, 0, 3)))
If your data are in groups of 4 then the formula would be:
= AVERAGE (OFFSET (data: $A$ 1, 4 * ROW (−7, 0, 4)))
Group 5:
= AVERAGE (OFFSET (data: $A$ 1, 5 * ROW (−9, 0, 5)))
etc.
The second parameter (number of data points per set) * rangee() - (a constant), must be assessed at 1 when rangee() is set to 2.
The last parameter is the number of data points per set.
The first line of the data table is a header row.
For more information about this use of the OFFSET, see the second to the last example here. If you work with large tables you can select averages derived, command + c to copy, edit > paste formula results to remove the forms when you are sure to have the desired result. The reason is that the OFFSET is a so-called "volatile" function which can make your sluggish document.
SG
-
Sampling rate - too much data points
Hello community,
I use a sensor signal strength of pressure on DAQmx labview through 2014. My rate from the hardware synchronization function is 50 KHz. The samples per channel of timing and read screws are the same set to 5 Khz when the channels are a continuous sampling. The problem I'm having is that when I run labview for a few seconds, say 5 seconds, I'm half million points of data. I tried to run for 10 seconds and points were more than a million where it is difficult to analyze. I think that the vi generates too much data points and the buffer is large. Am I wrong? Can you please help me solve this problem?
Kind regards
Mike
You are now ready to learn a little of the power of LabVIEW and data flow programming. LabVIEW is an inherently parallel language - two loops can run independently and in parallel, allowing you to make time-sensitive (such as sampling data) and a lot of time (such as data logging and tracing) at the same time, using queues to pass data between the loops and ensure the buffering required.
If you open LabVIEW and click on the file menu in the toolbar, and then select new... (the points are important!), you will be able to create new ones (VI) from the model. Choose a Framework, Design Patterns, producer/consumer Design Pattern (data). It's what you want to do.
You basically set up a "pure DAQ Acquisition Loop" (without logging TDMS) as producer, creation of 5000-element arrays of data every tenth of a second (if you are sampling at 50 kHz). You create a queue of data outside the loop of producer whose elements are an array of 1 D of waveforms (the output of your Read DAQmx) and instead to send the data to a waveform graph, you put it in the queue.
You are under this loop, a parallel loop that gets the same queue and remove items. This loop will be sitting idle (no time taking CPU) until the data is queued. He then it takes away the poster and registers (logs) in a PDM file. Either way, you should open the TDMS file before entering this loop (consumer), write to the file inside the loop and close the file when the loop exits. Study the example of the VI, you create with the model and see how it works.
The beauty of this is that you can certainly 'keep up' with the writing of the data points in a TDMS file to 50 kHz. You might not be able to display all the points, but there is nothing to prevent you from data processing (by, say, decimating or "block average" it) to a more 'user-friendly' display (your eyes ' sees' a 50 KHz signal?) -you have a set of 100 msec prior to the next package arrives in the queue. Also note that the loop of producer probably takes very little time CPU - most of the time the material is waiting for its clock to 'tick', collection of points in a buffer, then transferring to the loop.
Now you can have your cake and the computer display, too.
Bob Schor
-
Hello
I'm relatively new to labview and programming.
My goal is to acquire potential of the retinal, the signal I get is accompanied by noise and is within reach of micro volt, my goal is to average noise so that I can analyze the real signal (signal without noise).
The incoming analog signal is continuous, but I need to a window of time of 25 seconds alternative to the average value, which means: medium-sized signals of 0-25 s is not an average of 26 to 50 seconds, medium from 50 to 75 seconds and so on...
I started overwhelming with getting a signal from a function generator and averaging the full signal and displays the signal averaged over a second waveform graph. If the VI show all errors I wanted to know if I'm in the right way?
If Yes, then how can I do to average the data to 25 second multiple (for 25 seconds between the starting point)?
I've also attached a diagram of what I expect to see
I was thinking about something in this direction.
You have a buffer limited on the acquisition of your data. If you read fast enough, you will lose data. Then read smaller amounts more often. So I bibliography 1 second with a value of data 25 times.
Because you must connect to both average time, rethinking configure logging it, and just use the TDMS API instead. Do a search in the finder of the example (help-> examples find) for TDMS Wruite time Domain.vi. This is a decent example of what you want to do.
-
Graphical waveform data points, the performance impact to no.
Hello
I searched the forum, but I have only partial information yet about this behavior of graphics WF.
I have a TAB control on the façade, and a TAB page contains a WaveformChart. I traced points with speed of 0.5 Hz, and I have 8 (curves) plots on the chart.
I would like to have a lot of history, so I put the length of the graphic history to 44000.
Everything works as expected, but I see some sluggish behavior, when I click on another TAB page and return to the page of the TAB where the table.
In this case, the appearance of the graph takes about 1 to 2 seconds. This isn't a big problem, since the user typically controls the last minutes of ~ 10 (X-autoscale deactivation and change left "border" time). When this small amount of data points are visible on the graph, the new TAB page is fast after the click of the mouse. When several hours of data is presented, it's slow.
I guess the main reason for this behavior, it is that, when I switch back to the graphics TAB page, the OP system has to re - draw a large amount of data points, and it takes a lot of time?
I'm curious what is the 'best practice' in such a scenario? Shell I store data in a shift register and use an XY graph (I actually have data points such as the double and the corresponding time stamp, there are small fluctuations in time, so I need all THE timestamps)? Would it be useful? So I could add the new XY data point in the array in the register shift, and I redraw the graph at each new stage?
Thanks for the tips!
I don't know if this applies to your situation, but sometimes the LV refreshes no lights front panel which are not visible on a tab page that is not in front. Table has its internal buffer, but I have no idea how them redraws is managed at many points to accrue though not.
A graph redraws the data are written on it because you have to write all the data each time each time. With SHIFT register approach the graph would only see the most recent data when it becomes visible, so it seems that it needs to be adapted.
Another thing: your chart or table has no 44000 pixels along the x axis. LabVIEW will reduce the number of pixels to display the data. That takes some time too. Using the registry approach change, you can manage the data introduced to the 500-1000-2000 pixels will display your chart. This eliminates the need for BT to do and you can order the method: on average, decimate, sliding window and so on.
I'd go with the registry to offset and graph.
Lynn
-
Numbers with comma in the data Cube Viewer
Hello
I want to know what to do to display numbers with comma in the data Cube Viewer. The data type of the measure in the cube is NUMBER (4.3). The default aggregation is AVERAGE. When I load the cube with the numbers of the exactly NUMBER format (4.3) - in the data Cube Viewer I see only rounded integer values without decimal point.
If I load the test instead of cube table - the numbers are loaded in the correct format.
What should I do to load the cube with point numbers? Is this possible in OWB?
Now, I decided to use a way to go around it - simply put 1453 instead of 1.453. Then it works (but this isn't a great solution). It is the only way?
Thanks in advance for any help
PeterHi Peter
The cube data viewer has a toolbar with a lot of options... formatting, you can add and remove the numbers after the decimal point. From memory, I think you have to select the cells you want, you can click and select all the cells in the table and then use the button Add digits after the decimal point.
See you soon
David -
Covered wagon with an average of analog voltages DAQmx
I searched through screws, I can't seem to find something that will automatically average numbers of boxcar fed into it. I am trying to create a feature of my software that will allow the dynamic configuration of the car covered with an average of some inputs. I would like to avoid hard-coding tables which are filled/rotation etc etc.. Any help is appreciated
Thank you
If you use a Functional Global to store the values and call that VI of two different screws, you will access the same data. You could use two Global in the functional shift registers and use a selector to place / extract data from / to the appropriate shift register. Only VI call access one commune VI at the time, so one of the caller of the screw will be 'blocked' until the first caller is done. This does not usually work for data acquisition applications high speed.
You might consider using named queues instead of functioning overall. You might be interested in this thread on the forums of LAVA that deals with boxcar implimentations. You create a queue for each data stream and can perform functions such as "preview" queue to get all items without actually removing them from the queue. If you use a LabVIEW 8.6, there is a new feature called with loss of queues. You set an upper limit on the size of the queue and "lossy enqueue" allows to add items at the end of the queue. If the queue fills up, then the oldest data element will be lost.
-
How can, during the collection of data, start a new column in my table every 100 data points?
Hello! I have a problem with my data - I get in a wide range of 1 x 1000, but it's the repeated measures, each taking about 500 data points. I want to break this table for this data string start a new column in my table every 500 points given. I don't know how to do it-please help!
datacompiler100 wrote:
Hey thanks for the sponsor and the first off I must apologize for the State, I am attaching my VI. I put the part of the VI that I am working on (my team has access, so didn't post everything here) and also attached the data file (when just written in a spreadsheet file, not through the attached VI). I want to convert the long row of data and then start a new column every 50, 100, 5 points (user-defined).
Using the data from the file, you can reshape everything simply (as you already!), followed by transposition (since you want columns instead of rows). 2D arrays must always be rectangular, so the last column is filled with zeros if necessary. Is that what you want?

Of course if you try to add a new column in a file, that will not work. You can only add lines in an existing file because of the way the data is organized. To add columns, the entire file must be read, intertwined and all re-written new data in the file.
-
Problems with the transmission of data between the screws
Hi all.
I have a question where my program slows considerably during the race.
The program is a producer-consumer, where I have the main consumer loops and loops producer for USE comms, measure the output power, input for measuring the power, thermal control, etc..
Regarding the issue, the measures of output loop takes readings and transmits the data to a separate VI which remains running (measure of output processor). This VI summarizes and on average the data and also displays data for the operator to see details if necessary. The operator shows and hides the front panel of this VI with a button on the main program. This VI also returns the summary data to the main VI, where it is read by my loop of consumer.
The main measures output VI loop takes about 200mS to run when the program is first started. Less than a minute, it is 400 MS, and it's all downhill from there.
I've isolated the problem to the way I pass data back (I think). I couldn't find a way to pass the reference of the queue between two screws not connected by wires. I open a reference to the VI processor and use Ctrl Val.Set and Get to pass the data back. If I take the intersection of the Subvi data, there is no slowdown.
My questions are:
(1) why the data passing by invoking a node of the control on the target would cause the downturn?
(2) how would I get/pass information of queue between the two screws are not connected?
(3) Alternately, could I start the VI processor in my main program, run and pass data in and out of it? I want to keep it running, because it is also part of the user interface.
I don't know that I have not explained this very clearly. I took some screenshots of my code, but don't see how to download here.
Thanks in advance,
Jim
-
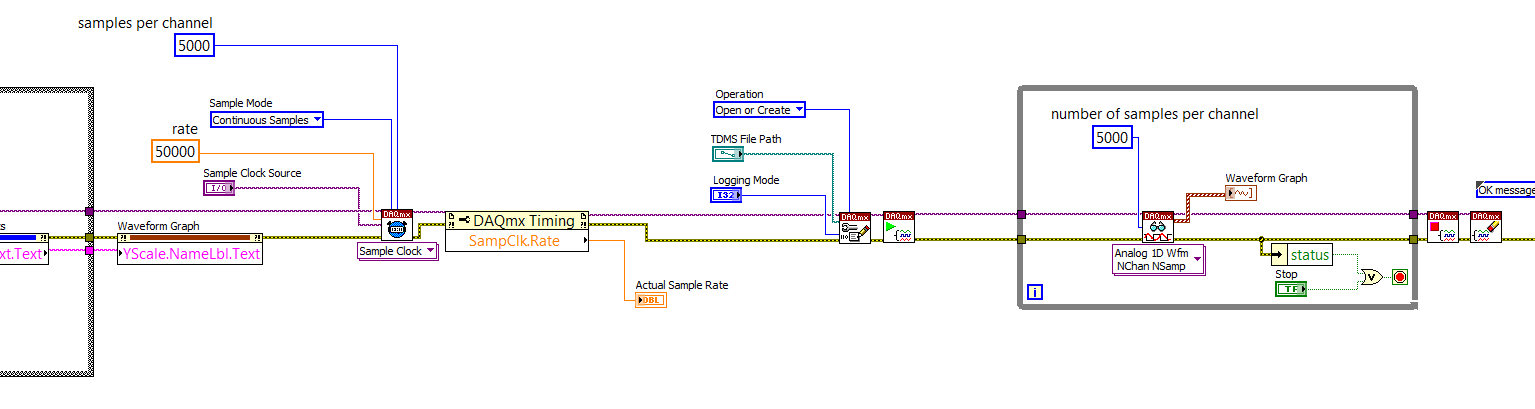
Average production data Continouse
Hello
My name is Loulou. I am a new user of Labview. I have a vi that generates a waveform by taking the input of the spectrometer data and then exports data to a file permanently during the program runs. In this process, the data generated by this program gets overwhelming, so I try to get an average of data of data points about 10 and ouput file, to decrease the amout the data being generated. How would I go to do this? Here is an attached vi which was given to me that I use at the moment.
Thank you in advace for all the help!


Maybe you are looking for
-
Why my Firefox flashed to all the time?
I installed the latest version of Firefox on the official site, I'm also re install the flash player for it but who do not have a lot.Because of flash player, I can see the videos, images GIF etc in Firefox but can't stop flashing Firefox. It is cons
-
Verify and repair permissions, El Capitan.
Anyone know if the following commands will check and fix permissions of files if the SIP is activated? Say / applications. It is displayed in several places on the web. sudo/usr/libexec/repair_packages - check - standard-pkgs /. sudo/usr/libexec/repa
-
How to remove an update that will not download
Every night my computer tries to download KB3097966 and fails. I discovered that the error code 80070490 is involved. Can someone advise please how can I fix this or how to remove this download from my system
-
move the cursor at the beginning of the file (InputStream)
Hello! I read a file (using InputStream) and necessary move the slider at the beginning of the file (to be able to search inside the file, moving at the beginning and then jump bytes). I'm targeting 4.5 OS. Is it possible to do? Can I reopen it the f
-
HelloI have a member named "is it a project": who has a smarlist attached to what ""Yes "or" NO": If Yes: we want users to enter the amount in dollars and if it didn't it must be left blank." "" However, there are some users who always enter numbers