Write a Cluster of 2 tables 1 d to the worksheet
Hi, I'm pretty new to Labview and I want to write a cluster of 2 tables 1 d in a spreadsheet, the first table 1 d is for the wavelength (for example: 800, 801, 802, 803,...) and the second table 1 d is amplitude (for example: 0, 20, 100, 30,...). How can I write the cluster in a worksheet in the form:
800, 0 801, 20 802, 100 803, 30 ...
In my current attempt, I get something like:
800, 801, 802, 803 ....... 0, 20, 100, 30........

Try the entry-level transposes in the writing of VI of spreadsheet file.
Tags: NI Software
Similar Questions
-
Remove the cluster of clusters table
Hi I have this program where you have an array of clusters and when you press a Boolean 'Add' button, you can add clusters to the table up to a certain limit, and it is written in a spreadsheet file. I would like also to such a function when you click on 'Remove' Boolean you can remove the cluster from the table so that the new table takes place 1 old and cluster information are removed from the worksheet so file. How can I do?
It does not need to have the cluster, use instead to build table (for best performance initialize the array and use replaces primitive subset of table). You cannot delete items in a file, but you can read the file and remove the item and he write to the file. If it is a sub VI, you add/remove items and writing to a file each time that the sub vi is called? Do not write to the spreadsheet VI file in this case, use instead write to text file primitive. See examples of LabVIEW for some useful examples on file i/o.
-
Patterns of data record TestStand 2010 SP1 default shared this cluster in two tables stored as binary data, resulting in two graphs displayed in the report: one for data and one for X data Y. We need the elements X and Y, couples on the same graph. This cluster is marked for logging as a step output variable. It seems possible to add a table "PROP_XYGRAPH" (similar to the PROP_ANALOGWAVEFORM) to the schema to simplify the other treatment after the database record, but how can we get the Builder, to accept this type of data is displayed correctly? XY graphics come from LabVIEW 2013 SP1 exclusively as a cluster of two matrices, usually between 500 and 1,000 items long.
... Geoff.
Hello Geoff,
Had a few resources for you to check. Let us know if none of them work for you.
Inserting an image of LabVIEW Control:
<>http://www.NI.com/example/30736/en/ >
Display of graphics in TestStand:
<>https://decibel.NI.com/content/docs/doc-38945 >
Display of measurement data in the shape of graph:
<>http://zone.NI.com/reference/en-XX/help/370052J-01/tsref/infotopics/measurement_data/ >
See you soon!
-
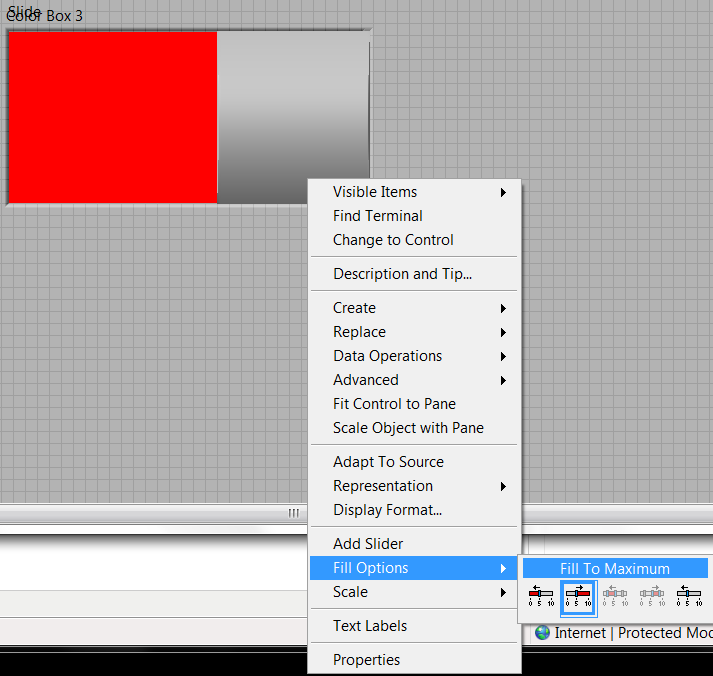
Table of clusters and the cluster is a bar counter, how can I change the color individually?
Table of clusters and the cluster is a bar counter, how do I change the color of the bar individual meter for each element of the array? I just realized that you cannot change the properties of an element of the array without changing everything. For scale, I had to make digital for each graduation of the scale indicators so that each measure meter in the table in the cluster has individual scales. I also had to do some calculations for each barmeter to display the correct proportions of 0 to 100% on the scale. Now, I'm stumped on the color of the bar counter. Basically, if the value exceeds a set value, the meter bar should turn red. It must be in a table to be infinitely scalable.
Thank you
Matt
And yet anothr approach...
Right click on the bar of > Options to fill > maximum fill.
The fill color of the same color as the background color, then make the background color transparent.
Drop a box of color BEHIND the bar and the size correctly.
He has this strange background 3D with flat bar, but what the Hey, his relatives. If its important a custom color box.
Ben
-
How to transform a cluster of 3 elements in a table 1 d of the Cluster of 3 elements?
I have an output of the ".vi SVFA frequency response (Phase-Mag) ' a 'group of 3 elements' and I need this fuel parameters modal 'MP_LSCE.vi', which takes a" table of cluster of 3 elements 1 D' any help appreciated. " So...
Cluster of 3 elements---> table 1 d of the Cluster of 3 elements
Use the Array function to build with just the single entry.
Steve
-
Write only the range specified 2D table data to a string worksheet?
Hi all
My problem today is a simple, but for the life of me, I can't find an answer using search. I have a table of 2D data points (values of Y) with their corresponding index numbers. When I start my VI, I retrieve a table of 10's of thousands of values, but I want to be able to extract only a few hundred values (specifically, one or two periods of a periodic sound of the waves) at the most to display in a string of spreadsheet for further calculations in Excel.
I managed to get the data written to the string of spreadsheet easily, but I'm stumped on how to specify the range (using the index values) to allow to write in the worksheet line. I tried "delete table", but I must be missing some functionality, because I can't seem to remove all values above one index max and min specified index below (in order to simply get the values between max and min).
Help a beginner?
Appreciated.
Use the subset of the table?
-
Convert a table 1 d of the Cluster (time + data) in 2D-table time and data. How?
Hello
is there a simple way to convert a large table 1 d of the Cluster (containing a timestamp and a given) in a table 2D with time stamp and data?
I could index the table in a while loop, separate each item and put the timestamps and the data in a new table.
The format of the new table could be an array of double (then the timestamp must be converted to a double) or an array of strings.
Could I do this without a loop?
Johannes
LabVIEW 7.1 (!)
Hi Johannes,
If it is possible to manage your time as dbl-floats stamps, I suggest using a simple loop and the cluster to function array (Cluster_to_Array_Mod1.vi).
If you want to stay with time stamp data type, even once use a loop for a cluster unbundle and build the function array (cluster_to_array_Mod2.vi).
Kind regards
Thomas
-
write table 2D data in the file but the file is empty
Hello
I tried to write all reading of powermeter data to a file in two ways, I can see the output in the Arrais indicator data but when I write to "File.vi of the worksheet" or write to 'text file', the files are empty.
Please help me.
Try to remove the vi "STOP".
I suspect, it prevents the main vi before the backup occurs.
As a second point: given that you save data inside a while loop be sure you add the data from the file and not crash each time.
wire that is a 'real' terminal 'Add file '.
Kind regards
Marco
-
Extra characters when you write table 2D in the worksheet
I try to write 2D data in a spreadsheet file, but I'm getting extra characters at the beginning of the file. I only get extra characters when I have a user selected file to write data. If I let LabVIEW to create the file, then there is no additional characters in the file. I created a VI that shows the problem I encounter.
Am I missing something, or LabVIEW puts these characters there for a reason?
Thank you!
-Andrew
If I create an empty file in Excel 2010 and save as .csv, I have no problem. I have run your VI and I have 3 rows, the first is empty because the file has already been created.
If I create an empty file and save it as .xlsx, then go into windows Explorer and change the .csv extension, I get output similar to yours. It seems that when you create the file before you run your VI you could attach the .csv extensions to something that isn't actually a .csv.
-
How to replace the element in the cluster in a table?
Hello
I understood better choice is to initialize the array first and replace the items in a table instead of insert the new item in a table for example in a while loop.
So I started to evaluate since I asked where I want to read a lot of measures from a txt file and display them in a XY Chart. XY graph must show Y value and corresponding value X is red if it is out of reach and green if it is in range. I found a solution to do it with an array of clusters.
In the attached example, I have represented two different methodologies. My problem is that a superior solution does not display the contents of all measures. Can someone tell me what I am doing wrong?
Kind regards
Petri
I changed your VI top so that it works. Please take a look and see what I've done. It is also much faster.
-
How to make a table of contents reflects the document formatting?
I use a table of contents for a long document. In the document, some special words - the titles of the texts that I write about - italic. But when they appear in the Table of contents, they are not. Part of the table of contents and problematic subheadings are shown in the attached images. I can do all the headings / subheadings italics, but I don't seem to be able to reformat the individual words, I can find no option for the table of contents to reflect the formatting of the titles themselves. I'm heading to the last resort of manually typing all the senses...


V4.3 Pages ' 09, or Pages v5.6.1, will resume the paragraph/character in the body of the document style attributes in the generated TOC. To a certain extent, you can customize the table of contents thereafter.
-
sorting table, how to get the new index of the last value?
Hi all!
I use a Subvi, which adds a cluter of the parameters to an array and then sort this table by one of the parameters in clusters.
It works very well, with examples, that I found in this forum

but now, I would like to know if it is possible to obtain at the end of the new cluster index first added.
See attached VI
Thank you
You take the size of the table and insert the new element to this level is anything other than the table of construction and a simple construction would do that.
In your question, I assume you're asking on the index of the item that you inserted after the sorting of the table, right? In this case, you can compare the cluster element that you introduce to the initial with the cluster table you get after a sorting of the table. This will give you the index of the item that you insert at the start.
-
Problem reading the worksheet after you use a DLL to write on the worksheet
Hello
I have a few problems reading a sheet DLL created in LabVIEW. The DLL is written in C++.
I'll dexcribe what do the VI in the screenshots:
For DLL_INIT = the first false steps the VI (LabVIEW) values and exports in a DLL initialization.
DLL takes these values and not some und calculation, then wrote the measured values and the new calculated values in a csv file called 'filtered_values' and a file 'filtered_values_complete '.
so, I have two files like this after initialization:1.0000000000; 1.0000000000; 18.8991610737; -3.2940000000; 0.0060000000; 0.9000000000; 6.5806287097; -3.2940000000; 1.0000000000; 0.0000000000; 1.0000000000; 0.0000000000;
So now on DLL_INIT = true.
For the calculation, the next step i read the "filtered_values" - file (LabVIEW), calculate the new values and write in filtered_values (DLL)
And in the "filtered_values_complete" - file I will allways read the DLL entry first, so that I can check later, if the DLL has obtained the values to the right of the front step and then add the calculated values.For i > 0 initialization has been made:
-the VI bed sheet "filtered_values" calculation and rotted the table 1 d in its unique values
-The last seven values in the worksheet have been exported in the dll as well as five new measured values.
-This DLL is still a few calculation
- then it replaces the "filtered_values" - file and adds a new line to the 'filtered_values_complete '.This migth be a bit of confusion, so a small example, afer five steps it loooks like this:
filtered_values:
5.0625000000; 1.0000000000; 18.9300200447; -3.2870000000; 9.7320000000; 0.8997597592; 5.9159054233; -2.6533532901; 1.0000000400; 0.0000000000; 0.8078703403; 0.0000000000;filtered_values_complete:
1.0000000000; 1.0000000000; 18.8991610737; -3.2940000000; 0.0060000000; 0.9000000000; 6.5806287097; -3.2940000000; 1.0000000000; 0.0000000000; 1.0000000000; 0.0000000000;
2.0625000000; 1.0000000000; 18.8330081064; -3.2940000000; 9.7270000000; 0.9000000000; 6.5806287097; -3.2940000000; 1.0000000000; 0.0000000000; 1.0000000000; 0.0000000000;
2.0625000000; 1.0000000000; 18.8330081064; -3.2940000000; 9.7270000000; 0.8999399568; 6.4077416273; -3.1451829134; 1.0000000100; 0.0000000000; 0.9480589053; 0.0000000000;
3.0625000000; 1.0000000000; 18.7932988441; -3.2870000000; 9.7280000000; 0.8999399568; 6.4077416273; -3.1451829134; 1.0000000100; 0.0000000000; 0.9480589053; 0.0000000000;
3.0625000000; 1.0000000000; 18.7932988441; -3.2870000000; 9.7280000000; 0.8998799074; 6.2394046705; -2.9768465052; 1.0000000200; 0.0000000000; 0.8988158138; 0.0000000000;
4.0625000000; 1.0000000000; 19.0445703499; -3.2870000000; 9.7320000000; 0.8998799074; 6.2394046705; -2.9768465052; 1.0000000200; 0.0000000000; 0.8988158138; 0.0000000000;
4.0625000000; 1.0000000000; 19.0445703499; -3.2870000000; 9.7320000000; 0.8998198333; 6.0754981785; -2.8129479844; 1.0000000300; 0.0000000000; 0.8521305805; 0.0000000000;5.0625000000; 1.0000000000; 18.9300200447; -3.2870000000; 9.7320000000; 0.8998198333; 6.0754981785; -2.8129479844; 1.0000000300; 0.0000000000; 0.8521305805; 0.0000000000;
5.0625000000; 1.0000000000; 18.9300200447; -3.2870000000; 9.7320000000; 0.8997597592; 5.9159054233; -2.6533532901; 1.0000000400; 0.0000000000; 0.8078703403; 0.0000000000;So it's good enough that the VI and it works fine until some point when the just VI reads more calculation and x = sheet! There? becomes true.
Most of the time it happens when the csv file is about 1200 lines
Someone knows why this happens?
Best regards
Stefan
Hello
understood, that the error occurs somewhere completely else. the thread may be closed
BR
Stefan
-
Write to the worksheet only if the file name is different
Hi all
I'm trying to write some code, but to no avail. Basically I have a file name to each time interval (say 2 seconds). I built a small table for example.
The names of files in the table are repetitive and I don't want to write the data in the worksheet, if the file name is the same.
Bascially, I need to write the header and the table for the 1 c:\1.txt files and after c:\1.txt the data (more than 3) I want to only write the table only (no header) and add it to the worksheet.
That is to say for c:\1.txt file, it will consist of 1 header and 4 sets of table.
Then the process is repeated again until a newfilename (c:\2.txt) is encountered.
c:\2.txt will also include 1 header and 4 sets of data.
Can anyone help on this?
Your loop is you allowing to read beyond the end of file names in your table. This passes an empty file name write it on the spreadsheet VI which requires to ask the name of the file. You should test this condition.
-
Table of references to the different types of performance issue
Hi all
See the attached code. I use a reminder VI and must pass a few references via the user's settings. I use a table.
This is to avoid the constraint (should I care?), I type cast to more of a generic class, then in the callback function, go to a more specific class. (What is the best way to do it?)
As you can see, even if, for some reason, almost all the nodes property are reading as variants, forcing me to use data Variant, which seems inefficient. Why is this the case? If I type cast to a Boolean, the value should be a bool... Why force me to use for the data range?
Is there a better way to do this? Thanks for the comments.
If you use a cluster of istead of a table, you can maintain the rigour of the reference.
The reason why you have found variants is that you don't are not cast the ref to the same type. Try...
Hand, create a strict constant of the wire Ref. Make slide a constant in the call back VI and use it when you launch as more specific. Property nodes you adapt to the specific data type they have in hand.
Note:
You can also create references of the appropriate type by dragging the appropriate type of control in the Ref control and it will fit.
I hope that makes sense.
Ben


Maybe you are looking for
-
All-in-one OfficeJet J4550: only a fraction of the feed photo paper
I am trying to print photos of 4 * 6 using HP photo tip on an OfficeJet J4550 paper. Sometimes it works but most of the time after the initial report pull in the paper and the printer starts to print, paper only continues to fuel in about half of th
-
Drivers/software for HP Pavilion dv6-6172nr notebook PC
Hello I'll try to find the drivers and software for my HP Pavilion dv6-6172nr Entertainment Notebook PC but can't seem to find the link. Whenever I get an error that this perticular model was not found on the HP site. I try to access to that of the U
-
GPS (global positioning) will not work. Lack of USB mass storage device
When I plug my GPS device into the usb port and driver disk into a dvd, where both worked, the installation wizard gives me a notice of default. Reference to the Device Manager shows 2 yellow? mark. Use of the facility of re - install and update does
-
Original title: Family Tree Maker does not connect on the Web dashboard. My Family Tree Maker 2009 does not connect to the Internet comes up with the message which is cannot authenticate the server, but it tells me that my version is up-to-date. He
-
Recovery Copyright OS 8 times merged partitions recovery in other partitions
Could you please help me one more problem. My laptop is copyright OS 8. When I divided the 700 GB partition into 3 partitions (C, D, E) to the desired capacity (100 GB, 300 GB, 300 GB). But then the OS cannot be opened. I've converted type GPT to MBR