analyze the results of the table
Hello
I have a statement:
ANALYZE TABLE x partition VALIDATE (p)
Cascade of the complete STRUCTURE online.
x name of the table
p partition
Where can I get the test results after running the command?
R.
Which seems to be the only partitioned tables:
http://docs.Oracle.com/CD/E11882_01/server.112/e26088/statements_4005.htm#SQLRF53678
Tags: Database
Similar Questions
-
analyze the table & dbms_stats (chained lines)
Hi guys,.
Understand that dbms_stats collect statistics on (chained rows).
To get chained lines, we can use one of the below:
1. analyze the < table_name > table list chained rows;
2 analyze the table < table_name > statistical calculation;
the first lists the information chained rows in the CHAINED_ROWS table.
the 2nd is best so that the information of chain_cnt are fulfilled in dba_tables. I can easily get the percentage of channel count by diviiding with the num_rows (for example if you need to list tables with 10 > string cnt percentage it would be easy).
Right now, I'm leaving the need to collect statistics for night work by default oracle (who gather for table with variation in percentage of stale or > 10)... However, come together to string cnts.
Can advise how can I get the string cnt without risking my existing services?
And also will analyze statistics of table < table_name > estimate; replace my existing histograms?
Thank you
Published by: Chewy on March 4, 2013 02:35Can advise how can I get the string cnt without risking my existing services?
analyze the
table list chained rows in ; Select owner_name, table_name, count (*) from the
group by owner_name, table_name; CHAINED_ROWS_TABLE must be created with UTLCHAIN. SQL script
-
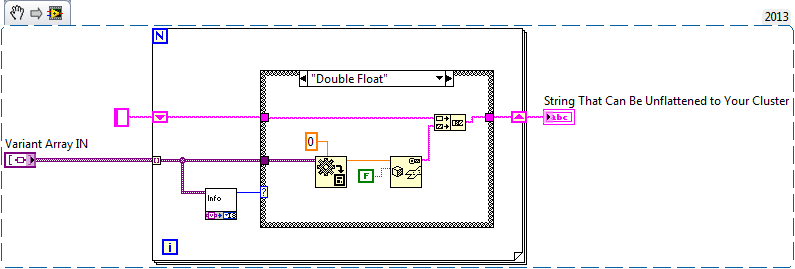
I have a request, where we read binary data by Ethernet to high speed (~ 500 Hz). This data consists of hundreds of measures and other variables of all types (floats, integers, strings, etc.). I already have the code to analyze these data and store it in an array of variant.
Now, I would like to take this array of variant and map each element to a particular variable.
Because the data is stored in a predefined sequence (element #1 = speed, element #2 = power, element #3 =...), I considered looping through the array of varying and using a structure dealing with a case for each index of the array (see attachment). However, it is very heavy because the case structure has hundreds of cases (one for each element of the array) and it is impossible to insert a new item in the structure of business without dialing manually anyway.
Can someone point me to a simpler implementation? If I was using C, I'd probably memcpy binary data directly in a structure aligned bytes. Is there any equivalent in LabVIEW, you use clusters?
(Note: using LabVIEW 2014)
Very well. I thought about such a VI came out probably somewhere in vi.lib.
However, I have also been concerned about the case where the table of variants isn't an different LabVIEW application. In this case, I don't expect that the name and information of TypeDef would be in the variants, as specific to LabVIEW, so I was thinking something like this:
-
Analyze the table after loading
Hi gurus
Let me know how we analyze the target table after loading to finish using an interface.
Concerning
SreeHi Mary,
There are two ways to do it,
1. customize your IKM own target of Analyze table step added.
2. create a procedure of ODI which will analyze the target table and can be called after the success of the loading data.
Thank you
Guru -
Analyze the table with a DEGREE = > AUTO LEVEL
I'm using the version of oracle 10g.
Oracle Database 10 g Enterprise Edition release 10.2.0.3.0 - production
PL/SQL version 10.2.0.3.0 - Production
CORE Production 10.2.0.3.0
AMT for 32-bit Windows: Version 10.2.0.3.0 - Production
NLSRTL Version 10.2.0.3.0 - Production
In my view, a valid value for the parameter DEGREE there in aid of the oracle. (http://download.oracle.com/docs/cd/B19306_01/appdev.102/b14258/d_stats.htm)
Degree: Degree of parallelism. The default for the level is set to NULL. The default value can be changed using the SET_PARAM procedure. NULL means use the default value of the table specified by the LEVEL clause in the CREATE TABLE or ALTER TABLE statement. Use the constant DBMS_STATS. DEFAULT_DEGREE to specify the default value based on the initialization parameters. The AUTO_DEGREE value determines the degree of parallelism automatically. It's 1 (series performance) or DEFAULT_DEGREE (the default value of the system will depend on the number of processors and initialization parameters) according to the size of the object
When I run the present, I get the error...
Oracle Database 10 g Enterprise Edition release 10.2.0.3.0 - Production
With partitioning, OLAP and Data Mining options
SQL > START
2 DBMS_STATS. () GATHER_SCHEMA_STATS
3 ownname = > 'SCOTT ',.
estimate_percent 4 = > 20,
5 block_sample = > TRUE,
6 method_opt = > ' COLUMNS SIZE 10 for ',
7 options = > "AUTO GATHER."
8 DEGREE = > "AUTO_DEGREE"
Cascade 9 = > TRUE);
10 END;
11.
BEGIN
*
ERROR on line 1:
ORA-06502: PL/SQL: digital or value error: character of number conversion error
ORA-06512: at line 2
SQL >Try to replace 'AUTO_DEGREE' with SYS. DBMS_STATS. AUTO_DEGREE
-
How can I search and return several items from the table quickly (like Matlab find)?
Hi, I'm a pretty experienced Labview programmer, and I've always wondered if there is a way to quickly search for pictures on several items that meet the selection criteria, equivalent to the Matlab find command. While my inability to do in Labview has always annoyed me, I now have an application that requires this capability and I need to find a solution.
Is the fastest way I've found to do this in labview to perform comparisons on the data vectors, then use the Boolean value that results from vector to analyze the table using a loop and shift registers. I enclose an extract vi a analysis comparative vi to one of the simple searches that I need to do. On my laptop, this research takes about 600 ms. In comparison, the equivalent in Matlab:
newArray=oldArray(find(oldArray(:,4)./oldArray(:,2)>1.5),
 ;
;runs in about 1.2ms. So, the way I am doing this in Labview is only 400 times slower
Needless to say, I need to make these types of research many times, and these additional 599 ms start to add up pretty quickly!
Thanks for your help,
Aaron
Hi Aaron,
the slow part is probably "build group" of the node in the loop.
Try this:
Define an array the same size as the input data (or simply uses a copy of it) and the wire that to the shift register. Keep a counter of lines found in the loop. Use IndexArray and ReplaceArraySubset for the loop to move rows found at the beginning of the table (overwrite the 'bad' lines). After the loop simply ReshapeArray the number of found lines...
Sorry, don't have LV (2009) on hand for editing your snippet.
-
How to check the number of lines inserted since the week last in the table
Hello
Oracle version: 11g
OS: Linux
We need to know the number of rows inserted for a table of 7 days, please can anyone suggest is all views to find that answer
BR
PMP
The function dbms_stats.diff_table_stats_in_history should give you what you need, assuming you analyze the table regularly.
-
Hello
I would like to know what is meant by the analysis of the table and how to analyze the tables?
can you please provide me steps docs about that.
Thank you
VijayThe "ANALYZE" command is obsolete and to be used only for specific purposes (for example, the keyword VALIDATE or to count the number of chained rows).
The DBMS_STATS package with its set of procedures replaces that command. These procedures, as well as the automated job/tasks already configured in 10 g and 11 g, should be used to collect optimizer statistics. Essentially of statistics on the nature of the data that is present. The SQL optimizer then uses these statistics to determine an execution plan to retrieve the data requested by the user/application.
See http://download.oracle.com/docs/cd/E11882_01/server.112/e16638/stats.htm#i37048
Hemant K Collette
-
analyse the problem of the table
Hi all
I analyzed a table and calculated statistics for the table. but when I checked the parsed date is showing as
GEDIS_CONTACT 2007-12-29 08:02:25
What could be the reason. Any idea?
Thank you
KrishnaKRIS wrote:
SQL > analyze table om_cust.gedis_contact computing statistics;Parsed table.
Version is 10.2.0.4
Do not use this command to analyze the tables so you need to use DBMS_STATS. Procedure GATHER_TABLE_STATS then check again.
-
Rename the table require re-run the stats?
OS: OEL (last) 64-bit
DB: 11 GR 1 material
I need to create a copy of a large table A in production (call of the new table B). The data are the same, but the physical layout of the tables is different (different partitioning scheme is used between table A and B).
When I go to move table B to replace table A (which will be eventually abandoned), should I raise his stats on table B?
It's
(1) table to become A_OLD
(2) table B becomes table A
I have to raise its stats on table A in step (2)? Is there something else that needs to be done?
(I do this to limit the impact to the GUI that uses this table - the name of the final table does not change so the GUI should not be affected).
See you soon!user601798 wrote:
Yes, I have to raise his stats on the 'new' A table even if it has the same data and the name (after renaming) but different partitioning scheme (physical model)? It seems to me that the answer would be 'yes '.
Otherwise, not the optimizer does not fail to recognize the new partitioning?(1) Board toys (all data) and table Toys_New (empty)
(2) the Toys_New table is loaded with toys data table (the two tables have the same data - only difference is partitioning)
(2) the toys table is renamed table Toys_Old (this will be served at a later date)
(4) table Toys_New is renamed table ToysAnd I was thinking - I forgot to talk about first-hand - Toys_New will have the same indexes, but of course the clues will have unique names from toys (to avoid the error "object already exists".
Given that the last note, I am convinced more than stats must be run on Toys_New after step (4)
See you soon!
Yes, you must.
Name of your new table is 'Toys', but this new table is totally different than the old toys. If you need to analyze the table again.
Concerning
Grosbois
-
Collect statistics on the table with indexes of text only?
I gathered statistics for a table that contains a text index
EXEC DBMS_STATS. GATHER_TABLE_STATS (USER, 'CONADDR', estimate_percent = > 10, block_sample = > TRUE, cascade = > TRUE);
There are a lot of tables/indexes not monitored (e.g. DR$ TI_CONADDR$ I). Do I have to analyse the tables there, too? The Guide Tuning Oracle text mentions just to analyze the table of "base".
Oracle DB version is 10.2.0.4.
select table_name, last_analyzed, num_rows from dba_tables where table_name like '%CONADDR%'; CONADDR 11.08.2010 10:29:37 17944660 DR$TI_CONADDR$I DR$TI_CONADDR$R DR$TI_CONADDR$K DR$TI_CONADDR$N select index_name, table_name, last_analyzed, num_rows from dba_indexes where table_name like '%CONADDR%'; SYS_IL0003730268C00004$$ CONADDR IDX_CONADDR CONADDR 11.08.2010 10:29:46 17106050 SYS_IL0003731165C00006$$ DR$TI_CONADDR$I SYS_IOT_TOP_3731168 DR$TI_CONADDR$K SYS_IL0003731170C00002$$ DR$TI_CONADDR$R SYS_IOT_TOP_3731173 DR$TI_CONADDR$N DR$TI_CONADDR$X DR$TI_CONADDR$I 11.08.2010 10:05:05 67585029 TI_CONADDR CONADDR 11.08.2010 10:29:46DR$ table do NOT need to be analysed - and should not be.
As "secondary objects", they will not be analyzed by orders based on patterns, and it is strongly recommended to not analyze manually. All commands that access these tables are set correctly without the input of the optimizer.
-
The search criteria and the result is displayed in the table in a group header. I want to get the value of the selected row and analyze the value of Vo in the next page for a variable binding. So I need to manage the value biniding to the bean tbal, but there is no option to bind the table to a bean. So, how can I get the selected value.
Kind regards
K M Krishna.
First tell us your version of jdev, please.
to get to the selected line you need not to link the table to a managed bean. You can for example drag the necessary attributes of the VO on the page and drop them as components of a inputText. the framework then generated the attribute bindings and sets the values of the current row for them. As you do not really need the inputText elements switch to source view (! it is essential!), then remove them. This will eliminate the Visual component, but attribute bindings are stored.
Know you can access the values through their EL or as you get the value of an attribute via it's mandatory.
Timo
-
SQL how to use a variable and use the result as a reference for the name of the table
Hi all
I have new in the declaration of Oracle, sorry in advance if something is easy for you all. BTW, I have this scenario:
I have a table OL structured in this way:
Date - it contains dates, for example 11/01/2015
TableName - it contains strings, for example, OL1, OL2, OL3 and so on...
Then I have a different table, the name of these tables are of the same name in the table of the OL, so I have table table, OL1, OL2, OL3 table and so on. The structure of these tables is the same. And Yes.
table OL1
---------------------------------------------------------------
ID LAST NAME FIRST NAME PHONE
---------------------------------------------------------------
1 JOHN DOE 12345679
2 PAUL 111111122 TIBBS
table OL2
---------------------------------------------------------------
ID LAST NAME FIRST NAME PHONE
---------------------------------------------------------------
1 ANNA KRAIG (NULL)
NATHAN FRESHMANN 111111133 2
If the scenario is clear, I would like to retrieve the value (null), research in all the OL * tables by using the value of the OL table (tablename) max.
If I'm going to do these simple steps, I got the result:
Select max (TableName) OL
the result will be OL2
# I know not how to use the option set to avoid changing the table name in the sql statement all the time.
set mytable = 'OL2.
Select Name, family name
of & mytable
When the phone is null
Any idea?
Thank you very much in advance.
Hello
run immediately "select dt.log_id, obj.presentation_name, dl.begin_time
bulk collect into v_result_set
of ' | v_ol |' dt join internal ol_object obj on
DT.object_type_id = obj.object_type_id
inner join ol_chunk_log dl on
DT.log_id = DL.log_id
where dt.data_value is null';
dbms_output.put_line (v_ol);
end;
Correct the code such as:
run immediately "select dt.log_id, obj.presentation_name, dl.begin_time
of ' | v_ol |' dt join internal ol_object obj on
DT.object_type_id = obj.object_type_id
inner join ol_chunk_log dl on
DT.log_id = DL.log_id
where dt.data_value is null' bulk collect into v_result_set;
for i in v_result_set.first ... v_result_set. Last
loop
dbms_output.put_line ('LOG ID: ' | ) ( v_result_set.log_id (i)) ;
dbms_output.put_line (' NAME CLOSELY: ' |) v_result_set.presentation_name (i));
dbms_output.put_line (' START TIME: ' |) ( v_result_set.begin_time (i)) ;
end loop;
end;
Kind regards.
-
Hi Adobe community.
I am new to creating forms and I was wondering if there is a way to analyze the results? The tutorial presentation stops at creating forms. I searched on the analysis of messages, but found none. Looking for probably is not the right terminology.
Thank you
LF
You can merge the results of several forms in a CSV file very easily. In Acrobat XI, it is under Tools - forms - more form Options - merge data files into spreadsheet...
-
ADF Mobile | to view the results in a table
Hi allI use Jdeveloper with ADF Mobile 11.1.2.4.39.64.62 extensions 11.1.2.4
I must displya quesry results in the form of a table (I'm developing of application for tablets and iPads).
I don't see any compont to Datacontrols table to remove it as a table on page amx.
Is it possible that I can display the data in a table in ADF Mobile?
Help, please.
Thank you
Vieira
Hi Vinay,
Yes, I understand that the table showing in the window is not the best, but we develop this for the cushions and with highest 7-inch screen tablets.
I am able to achieve by droping inside the Table list item > row > component cell Format.
Don't you see the disadvantages of this approach?
Thank you
Vieira
Maybe you are looking for
-
Hey,. Is this OK to clean the outer shell of a rMBP with a Microfiber cloth and a bit of water? It could damage the aluminum or anything else on the machine? Thank you
-
HP H1W67EA #ABU: static noise in my new laptop computer
I get a low static sound in my computer hp laptop, also one of the lights on the side of the laptop (seems to be the light of the hard drive) continues to blink on and outside.
-
How to clear the print queue on a printer hp x 6420
How to clear the print queue on printer HP 4620?
-
problem of installing active sync 6.1 64-bit with active sync. you have a known issue with the compatibility. you have a work around where the way to get these two together?
-
Why need to sign up as a songbirdcloudzw? to you all, then why not only my own sign to the name?
The problem here, it's everybody wants to connect to a different neame or a different pssword, everyone should be on the same page as others so that people like me do not become confused. And lose their way. As for example, you can be one example in