Analyzes the string and extract the string delimiter
Hello
Basic questions. Is this possible with the scan of regular expression of the string to extract the string that are in the specified delimiters. Here is an example:
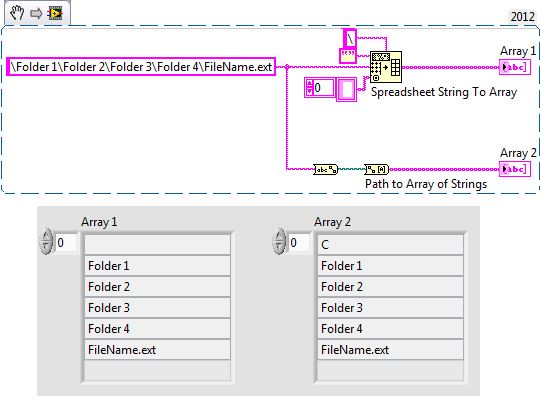
Name of the \\Name of the folder 1\Name to the folder 2\Name to the folder 3\File
Chain analysis can produce the following by specifying the regular expression on the right:
1 folder name
Name of the folder 2
Name of the folder 3
File name
I tried \\\%s\\%s\\%s\\%s but the %s stops on the first white space.
Thank you
Michel
RavensFan suggested the service appropriate for your condition, but you can also use an alternative, which is "spreadsheet of array of strings.
Tags: NI Software
Similar Questions
-
Analyze the values to a string and then place in the lines
Hi all
I need help here. I have a field called document_desc. Below is a sample of its contents:
Invoice: * 90104 * attachment document URL created in ArchiveLink content server. Number of
attachments: 3 Document ID (s): * 4FB6EB9040000ACA813, 4FB6EB924C0A2A813 *.
*, 4FB6EBB7000ACA813 * (s) URL :): http://xxxxxxxxxx
I need to do 2 things here:
1. I need to analyze the elements in bold. The number of values beginning with 4FB can vary. In this example, there are 3 of them, it could be one, there may be 10. However, they will be always between the ' ID (s):' and the ' URL (S):'
Invoice number (901825004) will always be only one and the same position, but can have different lengths.
2. I then need to format it so that it looks like:
Any suggestions?Invoice_Number Archive_ID 901825004 4FB6EB904C561491E1000000AC12A813 901825004 4FB6EB924C561491E1000000AC12A813 901825004 4FB6EBB74C561491E1000000AC12A813
Published by: dgouin on May 29, 2012 11:25
Published by: dgouin on May 29, 2012 11:26
Published by: dgouin on May 29, 2012 11:27
Published by: dgouin on May 29, 2012 11:27
Published by: dgouin on May 29, 2012 11:33Hello
Regular expressions a great help with this stuff:
WITH got_doc_id_list AS ( SELECT x_id , REGEXP_REPLACE ( str , '.*Invoice: *([^ ]+).*' , '\1' , 1 , 1 , 'n' ) AS invoice , REGEXP_REPLACE ( str , '.*Document ID\(s\):(.*)URL.*' , '\1' , 1 , 1 , 'n' ) AS doc_id_list FROM table_x ) , cntr AS ( SELECT LEVEL AS n FROM dual CONNECT BY LEVEL <= 10 -- Max number of doc_ids possible in one str ) SELECT d.x_id , d.invoice , TRIM ( REGEXP_SUBSTR ( d.doc_id_list , '[^,]+' , 1 , c.n ) ) AS archive_id FROM got_doc_id_list d JOIN cntr c ON c.n <= 1 + LENGTH (d.doc_id_list) - LENGTH (REPLACE (d.doc_id_list, ',')) ORDER BY x_id , c.n ;It works Oracl 10.1 (and higher). In Oracle 11, there are new features of regular expressions which can make it a little simpler.
I guess that your data are pretty well trained. For example, I assume that there is always something (not counting the white spaces and commas) after ' ID of Document (s): "and before"URL", and that the ID never include the substring"URL"." If these assumptions are false, then the same basic approach will work, but the details are a little messier.I hope that answers your question.
If not, post a small example data (CREATE TABLE and only relevant columns, INSERT statements) for all of the tables involved and also publish outcomes from these data.
Point where the above query was to produce erroneous results, and explain, using specific examples, how you get these results of these data in these places.
Always tell what version of Oracle you are using. -
How cut the length of the string IE channel name here, if it exceeds 20 characters or letters. The channel name is dynamically analyzed the spreadsheet/xml file.
My Council of Europe in the .js file is
function generateHTMLMarkup (i, channel) {}
";
Alert ("this is lang" + str);
var str ="";
"Str += '.
"Str += '."+ ""+""+"";
Alert ("this is lang" + str);
return str;}
nerateHTMLMarkup: function (i, channel) {}
";
Alert ("this is lang" + str);
var str ="";
"Str += '.
"Str += '."+ "" + "";
Alert ("this is lang" + str);
return str;etc.
Give mthe rhythm and the exact code where Ihave tio get implemented.
in the code, replace change
channelName var = channel ['name'];
TO
channelName var = channel ['name'];
-
Analyze the text and identify which columns contain unpaired data
Hello world
I want to write an elegant solution in LabWindows-CVI to accomplish the same thing as what I implemented in LabVIEW.
The client does not use or do not own LabVIEW. I have to code the solution in the CVI.
Order to simpify the explanation of what it is that I try to do, I wrote a small example in LabVIEW (see below):

The code needs to parse a string to determine which data column includes unpaired. To do this, I first removed the unwanted text on the top and bottom. I also removed the extra space between the 2 groups of data by replacing the two separated by one to facilitate the next step. The result string has been converted to a table 2D-string. Only the columns you want to search for remained (total of 16 columns). Table 2D has been transposed as the table 1 d of research searched each line, I want to look in each column. 2D table transposed in its entirety was sought of all no corresponding values, which fills a table 1 d of boolean. I converted the table 1 d of boolean to a number to see if data 'no match' has been found. If none have been found, the value would be zero.
I need help to encode this in CVI.
Thank you very much
RayR
Ray, aspect string makes me think that it's a memory dump, while I designed a solution that analyzes the values of the whole of the chain and operates on them, instead of working on the string itself. Take a look at the attached example which should be what you're looking for. feel free to add comments or ask for clarification on some instructions if you need.
-
Impossible to analyze the xml.aspx contained in the main.js.Iam get the following error"could not obtain XML document, and the connection has failed: status 500
My main.js resembles
xmlDataSource var = {}
URL: 'dcds. - symbianxml.aspx", etc. (sample).
init: function() {}
URL, successful reminder, the reminder of failure
This.Connect (this.) (URL, this.responseHandler, this.failureHandler);
},
/**
* Analyzes the XML document in an array of JS objects
@param xmlDoc XML Document
* @returns {table} array of objects of the device
*/
parseResponse: {function (xmlDoc)}
var chElements = xmlDoc.getElementsByTagName ("channel");
channels of var = [];
Console.log (chElements.Length);
for (var i = 0; i)< chelements.length;="">
var channel = {};
for (var j = 0; j)< chelements[i].childnodes.length;="">
var node = Sublst.ChildNodes(1).ChildNodes(0) chElements [i] [j];
If (node.nodeType! = 1) {//not an element node}
continue;
}
Channel [node. TagName] = node.textContent;
}
Channels.push (Channel);
}
Console.log (Channels.Length);
return the strings;
},
/**
Manages the response and displays the data from device web app
@param xmlDoc
*/
responseHandler: {function (xmlDoc)}
var channel = this.parseResponse (xmlDoc);
var markup = "";
for (i = 0; i< channels.length;="">
markup += this.generateHTMLMarkup (i, channels [i]);
}
document.getElementById("accordian").innerHTML = mark-up;
},
/**
Generates HTML tags to insert in to the DOM Web App.
* @index i, index of the device
@param device, device object
*/
/*
generateHTMLMarkup: function (i, channel) {}
var str ="";
"Str += '.
' onclick =-"mwl.setGroupTarget ('#accordian ',' #items_" + i + "', 'ui-show ',' ui - hide');" + ".
"mwl.setGroupTarget ('#accordian ',' item_title_ #" + i + "', 'ui-open', 'ui-farm'); Returns false; \ » > » ;
"" Str += "" + channel ['name'] + ' ";
"Str += '.";";
"Str += '.";
"Str += '."+" id: "+ channel ['id'] +" ' "";
"Str += '."+" type: "+ channel ['type'] +" ' "";
"Str += '."+" language: "+ channel ['language'] +" ' "";
"Str += '.«+ "bandwidth:" + "fast" channel + "»»";
"Str += '."+" cellnapid: "+ channel ["cellnapid"] +". "";
"Str += '.«+ ' link: '+'start the video »»";
"Str += '.
return str;
},*/
generateHTMLMarkup: function (i, channel) {}
var str ="";
"Str += '.";
"Str += '.«+ ' link: '+'start the video »»";
return str;},
failureHandler: {function (reason)}
document.getElementById("accordian").innerHTML = "could not get XML document.
'+ reason;
},
/**
Retrieves a resource XML in the given URL using XMLHttpRequest.
@param url URL of the XML resource to retrieve
@param called successCb, in the XML resourece is recovered successfully. Retrieved XML document is passed as an argument.
@param failCb called, if something goes wrong. Reasons, in text format, is passed as an argument.
*/Connect: {function (url, successCb, failCb)
var XMLHTTP = new XMLHttpRequest();
XMLHTTP. Open ("GET", url, true);xmlhttp.setRequestHeader("Accept","text/xml,application/xml");
xmlhttp.setRequestHeader ("Cache-Control", "non-cache");
xmlhttp.setRequestHeader ("Pragma", "non-cache" "");
var that = this;
XMLHTTP.onreadystatechange = function() {}
If (xmlhttp.readyState == 4) {}
If (XMLHTTP. Status == 200) {}
{if (!) XMLHTTP.responseXML)}
try {}
If server has not responded with good an XML MIME type.
var domParser = new DOMParser();
var xmlDoc = domParser.parseFromString(xmlhttp.responseText,"text/xml");
successCb.call (that, xmlDoc);
} catch (e) {}
failCb.call (, "answer was not in an XML format.");
}
} else {}
successCb.call (that, xmlhttp.responseXML);
}
} else {}
failCb.call (this, "connection failed: status"+ xmlhttp.status ");
}
}
};
XMLHTTP. Send();
}
};Please see the content in main.js is fully analyzed.
Forward for the solution to my request all members of the community...
-
Call Web Service via a Java Application and analyze the response
I have currently developed a service web (http://nycews.datajump.com/ATMUtilities.asmx/GetReverseGeoCode?Lat=42.9790550&Lng=-78.7856140) as returnes an address in xml format. I need to know what is the best way to call this connection and parse the XML to display the address to the user in a popupscreen.
Here is a corrected version...
public String getAddress() { String myString = "My String"; byte[] postData = myString.getBytes(); String myAddress = null; // address to return HttpConnection httpConnection; DataOutputStream os; Document doc; String myURLString = "http://www.google.com;interface=wifi"; // use a connection method here try { httpConnection = (HttpConnection) Connector.open(myURLString); httpConnection.setRequestMethod(HttpConnection.POST); httpConnection.setRequestProperty(HttpProtocolConstants.HEADER_CONTENT_TYPE, "application / requestJson"); os = httpConnection.openDataOutputStream(); os.write(postData); int rc = httpConnection.getResponseCode(); if (rc != HttpConnection.HTTP_OK) { return ""; } httpConnection.getResponseCode(); // The following code was taken from http://www.blackberry.com/knowledgecenterpublic/livelink.exe/fetch/2000/348583/800332/800599/How_To_... DocumentBuilderFactory docBuilderFactory = DocumentBuilderFactory. newInstance(); DocumentBuilder docBuilder = docBuilderFactory.newDocumentBuilder(); docBuilder.isValidating(); doc = docBuilder.parse(httpConnection.openDataInputStream()); doc.getDocumentElement ().normalize (); NodeList list=doc.getElementsByTagName("*"); String _node = new String(""); Node tempNode = null; //this "for" loop is used to parse through the //XML document and extract all elements and their //value, so they can be displayed on the device for (int i=0;i -
Parse the XML file and extract data
I want to parse a XML file and get the data as columns.
Input country.xml file:
<?xml version="1.0" encoding="UTF-8"?> <MAS Action="Insert"> <Country ObjectId="100000000000000009" VersionId="8"><Id>1</Id><NlTexts><Name Language="de">Land1</Name><Name Language="en">Country1</Name></NlTexts></Country> <Country ObjectId="100000000000000033" VersionId="2"><Id>2</Id><NlTexts><Name Language="de">Land2</Name><Name Language="en">Country1</Name></NlTexts></Country> </MAS>
I would like to analyze the xmlfile to get the following result
Required result:
col1 col2 col3 1 Land1 Country1 2 Land2 Country2
or alternatively
col1 col2 1 Land1 1 Country1 2 Land2 2 Country2
I tried the extract function
select extract((XMLTYPE(BFILENAME('XML_DAT_DIR', 'country.xml'), NLS_CHARSET_ID('AL32UTF8'))) , '/*/*/Id') as "xdata" from dual; xdata ------------------------ <Id>1</Id><Id>2</Id>and XMLTABLE (but how can I add countries now)
SELECT * FROM XMLTABLE('/*/*/Id' PASSING XMLTYPE(BFILENAME('XML_DAT_DIR', 'country.xml'), NLS_CHARSET_ID('AL32UTF8')) ) ; COLUMN_VALUE ------------------------ <Id>1</Id> <Id>2</Id>DB version 11.2.0.3 on Windows 64-bit
Thank you
Tim
Here are a few examples.
For your output required:
SELECT *.
FROM XMLTable)
"/ MAS/country".
from XMLType (bfilename ('TEST_DIR', 'country.xml'), nls_charset_id ('AL32UTF8'))
number of columns col1 way "Id".
, col2 varchar2 (30) path "NlTexts/name [1].
, col3 varchar2 (30) path "NlTexts/name [2]»
)
;
or, if the Language attribute is significant:
SELECT *.
FROM XMLTable)
"/ MAS/country".
from XMLType (bfilename ('TEST_DIR', 'country.xml'), nls_charset_id ('AL32UTF8'))
number of columns col1 way "Id".
col2 varchar2 (30) path "NlTexts/Name[@Language="de"]"
col3 varchar2 (30) path "NlTexts/Name[@Language="en"]"
)
;
For your alternate exit:
SELECT x1.col1
x2.col2
-, x2.col3
FROM XMLTable)
"/ MAS/country".
from XMLType (bfilename ('TEST_DIR', 'country.xml'), nls_charset_id ('AL32UTF8'))
number of columns col1 way "Id".
, path of xmltype names ' NlTexts/name '.
) x 1
XMLTable)
"/ Name".
in passing x1.names
path of column col2 varchar2 (30) '.'
-, col3 to ordinalite
) x 2
;
(uncomment col3 to see what he does)
or in a shorter way:
SELECT *.
FROM XMLTable)
' for $i/MAS/country
, $j in $ NlTexts/i/name
Returns the r element {$i / Id, $j}'
from XMLType (bfilename ('TEST_DIR', 'country.xml'), nls_charset_id ('AL32UTF8'))
number of columns col1 way "Id".
, col2 varchar2 (30) path 'name '.
) ;
-
How to analyze the data of the cDAQ and Signal Express, especially after analysis?
In the first series of tests of my instrument, it took longer than expected for the race. Thus, the data was saved in 6 days. The file is too large for export to Excel. At the beginning of the project, I was as ignorant as I could go ahead and add analysis and the scaling of measures. By the scaling, I mean my data of switching current dew points or whatever it is that I record.
How to evolve the data to read the output data as expected 4mA = point of dew of-20 C or 0 PSIG? Can I pre program this to be recognized for each event?
For real analysis I am doing – I would first analyze the data I recorded and choose different points to send to Excel to graph and analyze. Is this possible?
Secondly, I would like to know how to scale and analyze my data in the project without having to do this later analysis in the future?
I have a cDAQ-9172 with LabVIEW signal Express 3.0 that uses four modules - 9211 2 modules of thermocouple, my 4-20 1-9201 module +/-10V module and 1-9203.
Thank you for any assistance.
Hi Patricia,
"' You can do this by adding a step Load/Save signals ' analog '
. I hope this helps! -
How to download the app and extract the brother .cod files that it contained by program
Hello
I want to download and install a new version of my application programmatically. I read the messages where all the .cod files application including .sibling .cod files are downloaded separately. Is it possible to simply download the application file, for example Main.cod and extract all the brother .cod files contained (hand - 1.cod, hand - 2.cod)?
Thank you
Not sure that understand this issue. Given that you have already unpacked all the brothers and sisters, then you know how at the server level and can provide information, your application can query. Your application can read the jad file, or as the naming convention is well known, your application could try to get cod files with a suffix growing until it breaks. Is that what you were asking?
-
Analyze the index on the machine of Dataguard and redundancy of ASM disks
Dear friends,
I have two questions regarding disc Dataguard and ASM.
(> > 1) for best performance, periodically, we rebuild the index index and analysis analyze table. What is the best periodic steps to do to get better performance?
I mean, first of all is rebuilding of index, is second index analysis and so on......
(> > 2) if I run analyze the index or the table on my PRODUCTION system he replicated this effect on statndby dataguard automatic system? If so, how it is replicated?
(> > 3) my last question related with high redundancy of the ASM disk. I have some confusion on this area.
Let's say I have 10 disks in a diskgroup '+ DATA' and I did 'HIGH' level redundancy, means 3 way redundancy. Here I know 3-way the redundancy, it writes data on 3 discs at a time. But what of the other 7 discs. In fact, I need to know the mechanism of writing?
-Each disc is identical to the other drive?
-For HIGH redundancy, how many disk failure can be tolerated for any loss of data?
Waiting for your kind reply......
"on my PRODUCTION'---> you mean"on my FIRST.
Yes, the data dictionary is updated when you run dbms_stats.gather% and updates data dictionary are through recovery that applies to the WAITING for more.
NOLOGGING surgery would not be applied to the expectation (the index would be marked corrupted to the standby) unless you have set on FORCELOGGING.
Hemant K Collette
-
I have a problem to download a Web of Muse - the following site seems to be the problem - unable to validate the specified domain is associated with the FTP server and folder. Still
In Adobe help, it tells me to download and extract the ftppefs.xml file - it's supposed to be found in the Mac/Library/Preferences/Adobe/Adobe Muse CC/20141 and paste this folder GO.
I checked this place and there is no file. I have re-installed Muse but preference file doesn't show up - where I can get it?
Daryl
Please check the used domain in the domain and the server is entered, it can be the reason for the absence of the field.
Thank you
Sanjit
-
How to compress and extract files and databases of the current site of BC?
Hello all-
It was a good race with BC, but we are under new management and start over with another CMS. I would like to extract all the data of the current site (text of all pages, images, PDF files, the media library, customer information etc). I know how to export customer relationships, but is it possible to compress and extract everything holistically?
Thanks a lot - any help would be appreciated!
Also... you should do this ASAP...
Hello
Unfortunately it is not a comprehensive approach as you might hope. You will need to export all using existing tools mentioned in the article below. It's a similar concept to a migration site to another.
- http://kb.worldsecuresystems.com/203/bc_2038.html
I'm afraid there is no function automated for this at the moment.
Kind regards
-Sidney
-
The download and extraction of version CS6 track he has not
How to download and extract the version track cs6 it fail and I gave this message; The Setup file cannot be located (erro 103). Navigate to the folder where I downloaded and start the installation manually. What should I do to successfully download this software?
Adobe Download Troubleshooting Wizard
Mylenium
-
How optimizer analyzes different plans and prefer one in the other
Hello
I'm using Oracle 10.2.03.
Some time back I read somewhere on the internet a way by which we can see how otimizer analyzes the various plans for a particular query executed at this time is the analysis & desides finally a plan to be used on other plans (based on the costs calculated for all) and finally goes by it.
I lost the link, someone has an idea how to do?
I remember, it was made using bunch of dumping etc. or he way to putting any particular trace event.
Thanks in advance.
Best regards
oratesthttp://asktom.Oracle.com/pls/Apex/f?p=100:11:0:no:P11_QUESTION_ID:63445044804318
-
Load the metadata and extract the metadata tasks EPMA hfm App not appearning
Hello
I have deployemed an application of hfm in EPMA.
But the options load metadata and extract metadata does not appear under load task and extracted.
Version of EPMA is 9.3.1.3.
Is this a limitation with this version of EPMA or I made a mistake during the installation.
The user has all privileges for this app.
Help, please.Once you create an application in EPMA these options are no longer available.
They are only available for Classic applications.
See page 121 of the Administrator's guide.
http://download.Oracle.com/docs/CD/E12825_01/EPM.111/hfm_admin.PDF
-
How to analyze the data of 10 bytes encoded in the HH306 of Omegatte data logger/thermometer?
I am trying to write a simple code for a HH306 of OMEGAETTE thermometer/travailleursduweb.com data recorder.
That is the problem. I communicate with the device via RS - 232, using Labview 8.5.1 and windows xp. I ask her for "all the coded data", which is actually the only option. He returns 10 bytes of encoded data, the manual describes the meaning of each byte and I understand that. The problem is that I can't analyze the information for use in labview, for example: I want to extract the temperature and simply display it.
on request, I get: 10bytes (read as a string from the serial port read buffer): display HEX: 02 00 A8 48 FF EF B6 49 B6 03 is perfect, and what I expect. Display codes: \02\00\A8\B6H\FF\EF\B6I\03 The Normal display is a series of special characters, I don't understand, especially since I don't think they are ascii characters that must match returned hexadecimal numbers! For the life of me, I can't understand how to extract the information (what are the 48 6 hexadecimal display) of what is returned. All string manipulation functions seem to work only on what is given in Normal view. (The 4th and 5th byte of the data are the codes of the BCD for temperature: for example the temperature was 64.8 degrees farenheight when I took this reading).
Can someone help me to analyze the data returned by this device?
Ok... I think that I thought about it. I found this: http://digital.ni.com/public.nsf/websearch/77C8F61D36F5A23086256634005ACB38?OpenDocument.
I guess the normal display garbled is corresponding to each hexadecimal ascii characters. I'm just not used to seeing characters beyond the decimal number 127 ascii or hex 7F.
So, basically, to analyze the 10 bytes of data:
(1) break the string read from the serial port in the 10 ascii characters (using String subset vi)
(2) son of each output string in the left input of 10 separate Type vi Cast.
(3) wire a constant U8 in each terminal 'type' VI Type Cast.
cables of 4) the chain of each Cast of Type vi output to the input of a number hexadecimal string vi.
(5) concatenate or use as you wish as hexadecimal numbers (now in string format) which cause.
See you soon.
Maybe you are looking for
-
Battery, specifically in the night with ios10
It happens to me all the time, when the night comes and I don my body with this sweet sleep, it's rough on my iPhone. Really difficult. I'll just go on my what happened to my phone last night... I went to bed around 01:30, my phone was 93%. Here i
-
Anyone having problems with distnoted?
A number of our machines have been touched by a runaway distnoted process after the upgrade to El Capitan. We never had a problem with it in Yosemite. Basically, the machine will become insensitive and if you are able to open the Terminal or SSH into
-
Latency of the display on the Satellite P100-324
Pls can someone tell me the latency of the display (Toshiba Satellite P100-324)? (I read somewhere that there 18ms... it's true?)
-
Example: comapq presario cq56: disabled systemics
My compaq Presario cq56 has locked me out, I forgot the bios password it say system disabled now with code 57851254 someone can help me find my lap top please
-
Computer will not start. Displays F3..., can go together to the top, but nothing else
I have a MSi U100 running Windows XP Home SP3. After the last successful stop, the machine starts but just displays F3 on the screen, windows is not booting. I've tried rebooting and pressing F8 etc.; to enter safe mode, all I get is a screen with F3