Avoiding the TRUNC as a condition of setting for the date of transaction
I've never noticed this before, but tonight I have tested a query and made a trunc (mmt.transaction_date) between April 1, 2012"and 20 April 2012 ' in TOAD and I noticed it was taking a long time to run.If I remove the trunk and use mmt.transaction_date > = 1 April 2012 ' and mmt.transaction_date < 21 April 2012 "the query ran a lot faster and the explain command plan was also much better."
Then I read that this truncing the date of the operation will be used the index on this field in the table when searching it.
But if I change the setting so that the condition is set to add - it to the parameter, it does not work and maybe someone can help you. This is probably an obvious solution that I just think not.
I created the discoverer as conditions:
The operation date > =: Start Date of Transaction
and
The operation date < = (: Start Date of Transaction + 1).
But I get an error "one of the arguments of the function has an invalid data type.
Or maybe I'm wasting my time trying to avoid using the TRUNK on the date of the transaction?
Kind regards
Jerry
Hello
You should be OK with the condition:
The transaction date > =: Start Date of Transaction and the Transaction Date< to_date(:transaction="" start="" date)="" +="">
Rod West
Tags: Business Intelligence
Similar Questions
-
How to set permissions for drives avoid the ORA-15063 start-up ASM?
Hello
When I try to reboot the DSO after a reboot of the server, I get
ERROR: diskgroup DATA was not mounted
ORA-15032: not all changes made
ORA-15017: diskgroup 'DATA' cannot be mounted
ORA-15063: ASM discovered an insufficient number of drives for diskgroup "DATA".
It seems the permission of disks have changed after the reboot. I guess the spfile is inside the DATA diskgroup because it can not even start ASM. When I create a file with values asm_diskgroup and asm_diskstring pfile and 777 on the drive, I managed to start the ASM.
* .asm_diskgroups = "INDX", "DATA".
* .asm_diskstring = "/ dev / *'"
$ oracleasm querydisk p - DATA
Disk 'DATA' is a valid ASM disk
/ dev/sdb4: LABEL = 'DATA' TYPE = 'oracleasm.
$ ls-la/dev/sdb *.
...
BRW - rw - 1 root disk 8, 19, 29 mai 10:42 / dev/sdb3 it
brwxrwxrwx 1 root disk 8, 20, 29 mai 15:17 / dev/sdb4
...
And when I read the documentation I see this ' that the owner of the ORACLE binary file has permissions to read/write on the discs"(so do not run required) but the problem is that this test server should have the same parameters as in production. And the production server has brw - r - for the corresponding disk. So my questions are
Can it be handled somehow in a different way? How can this have been reached production without the same settings I put in test? Is there an other way around for me in test to achieve?
The network user (who owns the infrastructue grid) belongs to the same group of test and production. Test and production have ASM version 11.2.0.3, but the different operating system.
production: 2.6.18 - 274.12.1.el5
test: 2.6.32 - 504.16.2.el6.x86_64
As this is my first ASM/grid infrastructure, I don't even know where to begin this review except the support.oracle.com search but I've not found anything except the Action for the error code (which is perhaps the only way around it)
Any help is appreciated
Thank you
/ Jenny
Remember that the permissions of the device must be configured so that the owner of the Oracle database or the process has full access to the appropriate device files. It is not enough to only give ASM full authorization for devices files. ASM provides management for volume, but the database has direct access to device files and ASM does not interfere with inputs and outputs. You can set up groups and owner accordingly. If you have a different owner for ASM, you must assign appropriate groups to give full access ASM configuring oracleasm.
-
what setting to change to avoid the "unable to allocate new log"
Hello everyone.
I'm on 9i r2 on windows server 2003 edition of the SD with attached ISCSI. I have the drive 1 recovery as well as DBF newspaper group in the data directory. 2 other groups redo are on the 2 local disks separated and archiving logs (in another folder).
I'm getting some errors "cannot allocate new logs" every two days and in Event Viewer "process Archive error: Instance ORACLE prdps - cannot allocate Journal, check-in required.
I do not know what setting I should change.
Current configuration:
db_writer_processes 1
dbwr_io_slaves 0
Here is the output from v$ sysstat:
49 8 7410575 written DBWR checkpoint buffers
50 8 7748 written DBWR transaction table
51 DBWR undo block writes 8 4600265
52 DBWR revisited being written 8 5313 buffer
DBWR 53 free ask 8 26383
54 DBWR free buffers are 8 19838373
55 DBWR lru scans 21831-8
56 DBWR summed scan depth 8 21265425
57 8 21265425 scanned DBWR buffers
58 control DBWR 8 1719 points
59 DBWR cross instance writes 40 0
60 fusion DBWR written 40 0
It's alert.log:
Fri Mar 06 00:25:52 2009
Arc0: Complete 1 thread 1 log archiving sequence 7004
Fri Mar 06 00:25:54 2009
Thread 1 Advanced for you connect to sequence 7006
Currently Journal # 3 seq # 7006 mem # 0: E:\ORACLE\ORADATA\PRDPS\REDO03A. JOURNAL
Currently Journal # 3 seq # 7006 mem # 1: F:\ORACLE\ORADATA\PRDPS\REDO03B. JOURNAL
Currently Journal # 3 seq # 7006 mem # 2: G:\ORACLE\ORADATA\PRDPS\REDO03C. JOURNAL
Fri Mar 06 00:25:54 2009
Arc1: Evaluating archive log 2 thread 1 sequence 7005
Arc1: Begins to archive log 2 thread 1 sequence 7005
Creating archives LOG_ARCHIVE_DEST_1 destination: "F:\ORACLE\ORADATA\PRDPS\ARCHIVE\PRDPS_001_07005.ARC."
Fri Mar 06 00:26:03 2009
Thread 1 Advanced for you connect to sequence 7007
Currently journal # 1, seq # 7007 mem # 0: E:\ORACLE\ORADATA\PRDPS\REDO01A. JOURNAL
Currently journal # 1, seq # 7007 mem # 1: F:\ORACLE\ORADATA\PRDPS\REDO01B. JOURNAL
Currently journal # 1, seq # 7007 mem # 2: G:\ORACLE\ORADATA\PRDPS\REDO01C. JOURNAL
Fri Mar 06 00:26:03 2009
Arc0: Assessment of the archive log 2 thread 1 sequence 7005
Arc0: Impossible to archive log 2 thread 1 sequence 7005
Newspapers archived by another process
Arc0: Assessment of the 3 thread 1 sequence 7006 log archives
Arc0: Starts to archive log 3 thread 1 sequence 7006
Creating archives LOG_ARCHIVE_DEST_1 destination: "F:\ORACLE\ORADATA\PRDPS\ARCHIVE\PRDPS_001_07006.ARC."
Fri Mar 06 00:26:15 2009
Arc1: Finished 2 thread 1 log archiving sequence 7005
Arc1: Evaluating archive log 3 thread 1 sequence 7006
Arc1: Impossible to archive log 3 thread 1 sequence 7006
Newspapers archived by another process
Fri Mar 06 00:26:16 2009
Thread 1 cannot allot of new newspapers, sequence 7008
All newspapers need to check-in online
Currently journal # 1, seq # 7007 mem # 0: E:\ORACLE\ORADATA\PRDPS\REDO01A. JOURNAL
Currently journal # 1, seq # 7007 mem # 1: F:\ORACLE\ORADATA\PRDPS\REDO01B. JOURNAL
Currently journal # 1, seq # 7007 mem # 2: G:\ORACLE\ORADATA\PRDPS\REDO01C. JOURNAL
Thread 1 Advanced for you connect to sequence 7008
Currently Journal # 2 seq # 7008 mem # 0: E:\ORACLE\ORADATA\PRDPS\REDO02A. JOURNAL
Currently Journal # 2 seq # 7008 mem # 1: F:\ORACLE\ORADATA\PRDPS\REDO02B. JOURNAL
Currently Journal # 2 seq # 7008 mem # 2: G:\ORACLE\ORADATA\PRDPS\REDO02C. JOURNAL
Fri Mar 06 00:26:16 2009
Arc1: Evaluating archive log 3 thread 1 sequence 7006
Arc1: Impossible to archive log 3 thread 1 sequence 7006
Newspapers archived by another process
Arc1: Evaluating archive log 1 thread 1 sequence 7007
Arc1: Beginning to archive journal 1-wire 1 sequence 7007
Should I just change
db_writer_processes 1
dbwr_io_slaves 2
Thank you
Any help appreciated.This message indicates that Oracle wants to re-use a redo log file, but
the
associated with corresponding control point is not over. In this case,.
Oracle
Wait for the control point is carried out entirely. This situation
may be encountered especially when transactional activity is
important.search for:
-Background checkpoint started.
-Control your mat point.These two statistics should not differ more than once. If it is
not true, your base weighs on the control points. LGWR does not reach
continue
next write operations that ends the control points.Three reasons may explain this difference:
-A frequency of control points which is too high.
-A control points are starting but not filling not
-One DBWR writing too slowly.How to resolve incomplete control points is through tuning
control points and
newspapers:(1) gives the checkpoint process more time to scroll through newspapers
-Add more redo log groups
-increase the size of the logs again
(2) to reduce the frequency of control points
-increase the LOG_CHECKPOINT_INTERVAL
-increase the size of newspapers in restoration online
(3) improve the effectiveness of the control points for the CKPT process
CHECKPOINT_PROCESS = TRUE
(4) set LOG_CHECKPOINT_TIMEOUT = 0. This disables the verification script
based on
time interval.
(5) another way to solve this error is for DBWR to write quickly
the dirty
buffers to disk. The parameter associated with this task is:DB_BLOCK_CHECKPOINT_BATCH.
DB_BLOCK_CHECKPOINT_BATCH specifies the number of blocks that are
dedicated
inside the batch size for writing the control points. When you want to
speed up
control points, it is necessary to increase this value. -
Extracting data from table using the date condition
Hello
I have a table structure and data as below.
create table of production
(
IPC VARCHAR2 (200),
PRODUCTIONDATE VARCHAR2 (200),
QUANTITY VARCHAR2 (2000).
PRODUCTIONCODE VARCHAR2 (2000).
MOULDQUANTITY VARCHAR2 (2000));
Insert into production
values ('1111 ', '20121119', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20121122', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20121126', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20121127', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20121128', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20121201', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20121203', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20121203', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20130103', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20130104', ' 1023', 'AAB77',' 0002');
Insert into production
values ('1111 ', '20130105', ' 1023', 'AAB77',' 0002');
Now, here I want to extract the data with condition as
PRODUCTIONDATE > = the current week Monday
so I would skip only two first rows and will need to get all the lines.
I tried to use it under condition, but it would not give the data for the values of 2013.
TO_NUMBER (to_char (to_date (PRODUCTIONDATE, 'yyyymmdd'), 'IW')) > = to_number (to_char (sysdate, 'IW'))
Any help would be appreciated.
Thank you
MaheshHello
HM wrote:
by the way: it is generally a good idea to store date values in date columns.One of the many reasons why store date information in VARCHAR2 columns (especially VARCHAR2 (200)) is a bad idea, it's that the data invalid get there, causing errors. Avoid the conversion of columns like that at times, if possible:
SELECT * FROM production WHERE productiondate >= TO_CHAR ( TRUNC (SYSDATE, 'IW') , 'YYYYMMDD' ) ; -
How to avoid the cache of the browser Mozilla Firefox?
Hello
Firefox cache is driving me crazy:
-browser.cache.memory.enable
-browser.cache.disk.enable
Some reports return an incorrect value, because the browser cache is used... Firefox does not detect the changes!
I don't want to ask all users of my application to these 2 settings set to false.
Is there a way to avoid the cache?
Or to change HTTP server setting?
Thank you
ThomasHello
Yep - you might want to open a new thread with "BUG" in the title, so that a person can pick this up.
You can recreate this feature manually, if you wish:
1 create an application to the element called G_UNIQUE_ID for example
2 - create a PL/SQL application process that runs "Before Header". This could be something like:
DECLARE vID NUMBER; BEGIN vID := TRUNC(DBMS_RANDOM.VALUE(1000000, 1000000000)); :G_UNIQUE_ID := vID; END;1000000 and 1000000000 are low - and - upper limit of a random number
3, and on the branch as part of the request, put:
&G_UNIQUE_ID.Andy
-
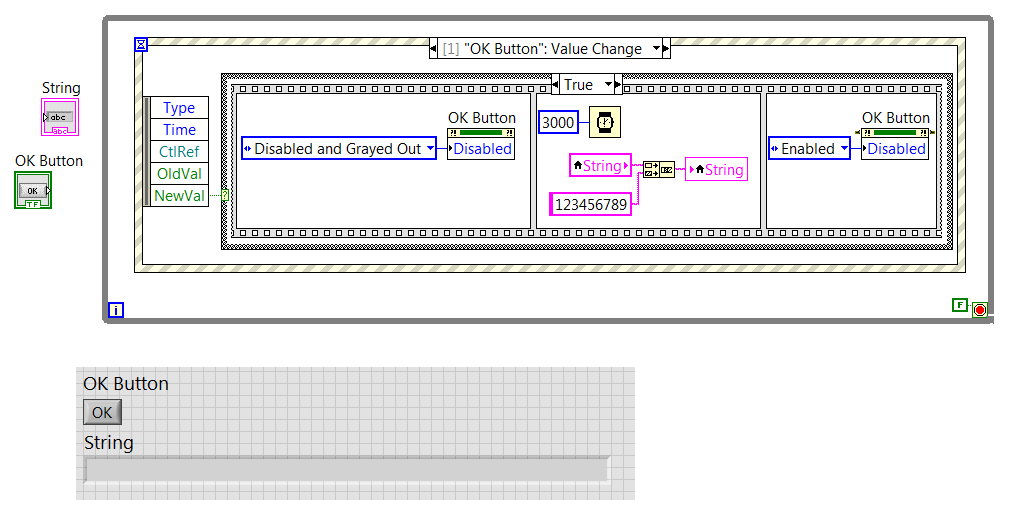
Avoid the button clicks duplicated in the structure of the event
Hello
I have an apparently easy problem that I can't solve. I enclose a VI that illustrates my problem.
My problem is this: when an event runs, the OK button is disabled, but if the user clicked the event is pending, and when the process is finished, another will start immediately. The only reason why I turn off the button is to avoid this queuing event. The mechanical action of the button is set to the switch until release (so that the button just get after that I have let go of it).
How can I avoid this?
Thank you!
First of all, your mechanical action seems wrong. By releasing latch and then move the button in the case of the event. Currently, you use the switch to exit which is contagious stocks on the top and to the bottom of the query.
Second, do not check the box that says 'Lock Front Panel until the end of the matter for this event'. Notice that it has parentheses that say "reporter treatment of the actions of the user" which means he waits until the case ends (the date at which the button was reactivated). You are basically defeating the entire purpose of the deactivation of the control because defer you the intervention of the user until the button has been reactivated.
-
How to avoid the duplicateConnection on a sql database?
I have a database of newspapers that I have access to both c ++ and QML.
While everything works correctly logs qml page complained about a double connection whenever it is open, which in turn spam log file.
In c ++, the database is initialized once, with db being QSqlDatabase:
QString databaseFileName = QDir::homePath() + QDir::separator() + "logs.db"; db = QSqlDatabase::addDatabase("QSQLITE", "loggerDatabase");if (!db.open()) { printf("Critical: Error opening logs database\n");}QML, I use a very simple way to view the contents of the db: A GroupDataModel with a data source.
I have set up a query on the data source and fill in the datamodel with the result:
DataSource { id: dataSource source: loggerService.dbPath onDataLoaded: { dataModel.clear(); dataModel.insertList(data); } }I assume that the data source uses SQLDataAccess to open a connection to the db, and db already has a connection there is a complaint:
QSqlDatabasePrivate::addDatabase: duplicate connection name ' / accounts/1000/appdata/x/data/logs.db' old deleted connection.
How can I avoid this?
I've given up trying through QML and just dynamically added the groupDataModel of c ++.
I was getting the same error, without reason.
-
How to avoid the JSR 75 write alert popup with blackberry?
Hello
This is my first post for the blackberry developer forums and I'm trying to transfer my J2ME application to blackberry.
In our application, we use the JSR-75, and we got the versign certificate that we use for Nokia and Sony ericsson.
The blackberry A60_How_And_When_To_Sign_V2.pdf .i found only one way to avoid the popup is carrier signature and but I do not find any carrier specific certificate in my blackberry "BOLD" (Airtel, India).
(1) Please help me in this area.
(2) is thereany way to avoid this popup?
(3) possible Willit for blackberry partners?
I use eclipse with the component 4.6.0 Blackberry package.
Thanks in advance.
Kind regards
Samir.
I used the ApplicationPermissions class to set the permission and it works.
-
Criteria of programmatic view adding the date condition
Hi all
I use Jdev 12.1.3. I wrote a method in AMImpl to filter my viewobject based on custom search screen of the user interface.
I create the criteria for the view programmatically. I have check SMSDate field in my VO date between the criteria in the field settings start date and end date.
How to define this condition by programming
' Public Sub searchInfo (String attribut1, String fullname, startDate, endDate oracle.jbo.domain.Date oracle.jbo.domain.Date) {}
ViewObjectImpl vo = getSmsInfoVO1();
ViewCriteria vc = vo.createViewCriteria ();
ViewCriteriaRow vcRow = vc.createViewCriteriaRow ();
If (attribut1! = null & &! attribute1.isEmpty ()) {}
vcRow.setAttribute ("attribut1", attribute1);
vc.addRow (vcRow);
}
If (fullname! = null & &! fullname.isEmpty ()) {}
vcRow.setAttribute ("full name", fullname);
vc.addRow (vcRow);
}
Need a logic here set VO attribute SMSDate and check the date between the startDate and endDate parameters method
vo.applyViewCriteria (vc);
vo.executeQuery ();
}
Check this box:
-
How to avoid the report query needs a unique key to identify each line
Hello
How to avoid the error below
The report query needs a unique key to identify each row. The supplied key cannot be used for this query. Please change the report attributes to define a unique key column.
I have master-detail tables but without constraints, when I created a query as dept, emp table he gave me above the error.
Select d.deptno, e.ename
by d, e emp dept
where e.deptno = d.deptno
Thank you and best regards,
Ashish
Hi mickael,.
Work on interactive report?
You must set the column link (in the attributes report) to something other than "link to display single line." You can set it to 'Exclude the column link' or 'target link to Custom.
-
Avoiding the new line, import csv
Hi friends,
Importing csv into a temporary table file, stored in csv is divided into two rows due to "an undesirable character" or the new line.
Here is the example when I copy the unique line of csv, and while the display becomes two lines in Notepad.
' 70555129360 ',' December 10, 2014 23:51:34 ","11 December 14"," Tag #: 4708511.
Sharjah - 50253 2', 'Al Barsha', 'Abu Dhabi', '0.00 '.
You can find the unwanted character or a new line in the image. No way to avoid this, importing temporary table or can we adhere as data records.
Select * from test where instr(test_value,'"',1,1) = 1;
Select * from test instr(test_value,'"',1,1) <>1;
Finally, we can reach above two sets with the first line of the first query with the first line with the second query. your suggestion pls.
use utl_file.get_line (in_file, lineread);
in_file utl_file.file_type;
lineread varchar2 (4000);
Thank you.

Actually, I had an idea like, given that the single line divides into two lines in the table.
I'll do three temporary table for some data.
' 70555129360 ',' December 10, 2014 23:51:34 ","11 December 14"," Tag #: 4708511.
Sharjah - 50253 2', 'Al Barsha', 'Abu Dhabi', '0.00 '.
1. first one like that with the column one id.
Select * from test where instr(test_value,'"',1,1) = 1;
Id test_value 1 "raju, mohan. 2 "like, dikes. 3 "play, while". 4 "all right, mine. 2. the second one like this with one ID column
Select * from test instr(test_value,'"',1,1) <> 1.
id test_value 1 rain, rain ". 2 chain, wain. 3 Why not ". 4 "all, well done. and finally
3. third from combine records where id matches.
-
How to avoid the glossy look and brilliant nostrils?
I just built my first character of fuse and when I import into Photoshop, its nostrils are incandescent - as if the light shines through the back of his head!
This fuse:

Becomes this in Photoshop:

I use a brush to set the nostrils, but have no idea how fix eye - of the suggestions?
Even better - any ideas on how to avoid the glossy look and glowing nostrils?
Thank you very much
MalcolmHey, Malcolm.
Best way to explain what basically rendering 3D correctly really takes a lot of time, haha. So that you may be able to work with the real-time 3D model and make changes quickly, we use two different rendering methods.
There is an "Interactive" mode which is not like the beautiful light/shade, but is very fast - and that's what you see when you interact with the default template.
Then, there is a mode "Raytraced" which is much more advanced calculations and stuff to give you a proper lighting / shadow. Raytraced rendered may take time if so we can not use it all the time.
In order to get the lights/shadows appropriate you need to perform a path Ray would make on the document. Best way to do this:
- Select your 3D layer in the layers panel
- Make a selection in the drawing area to the area that you want to make (I recommend to test rendering of area to check the lighting/shadows before committing to make the whole layer).
- Push the button is rendered at the bottom of the properties panel (it looks like a cube in a rectangle box, right next to the delete icon).
There are other things that you must do if you want to get the best image search quality such as the addition of secondary lights! You can add more lights in the 3D Panel using the small icon of light at the bottom. Have 2-3 stage lights and adjusting their colors can make a big difference with the Assembly of your character in the scene. Here is a small image for some comparisons:

You can see the image with two lights a look much more realistic lighting and shadows and raytraced of one and two versions are much nicer and cleaner!
Hope that helps!
-
How to avoid the OutOfMemory exception in an intensive application of memory in Java?
We have developed a java application, whose goal is to read a file (input file), treat it and convert it into set of output files.
(I gave a generic description of our solution, to avoid irrelevant details).
This program works perfectly well when the input file is 4 GB, with memory settings-Xms4096m-Xmx16384m in a 32 GB of RAM
Now we need run our application with the input of size 130 GB file.
We used a linux machine with 250 GB of RAM and memory setting of - Xms40g-Xmx200g (also tried a few other variants) to run the application and click on OutOfMemory Exception.
At this stage of our project, it is very difficult to think about the redesign of the code to meet hadoop (or someother large-scale data treatment framework), the current hardware configuration which we can afford is also 250GB of RAM.
Can you please offer us ways to avoid the OutOfMemory Exceptions, what the general practice when developing applications of this kind. ?
Thanks in advance
Thanks a lot for all your quick responses.
We decided to investigate the Redis it will solve the problem that is described in the post. All hashmaps can be put in databases (secondary memory) and exceptions of memory can be managed.
-
How to avoid the FDM-command being moved files from the OpenBatch folder
Hello world
I have a little problem with Batch Processing of the FDM - I need to stop the movement of files in the folder OpenBatch - when a batch is executed.
The installer by using the Task Manager, a load a Batch Script and Script integration all works very well. However, the process must run every 3 hours, so I need the file "A_LedgerTransLocation_Actual_nov - 2013_RR.txt" to remain in the \Inbox\Batches\OpenBatch\ folder at any time.
How to avoid the file is moved?
Best regards
Frederik
PS: I noticed on the OTN Forum is it may be possible to script a solution such as:
FSO1 = CreateObject ("Scripting.FileSystemObject") set
Set File1 = FSO1. GetFile ("FDM Directory\FDM Application\Inbox\Batches\Openbatch\A_LedgerTransLocation_Actual_nov-2013_RR.txt")
The BATCHENG value. PcolFiles = BATCHENG.fFileCollectionCreate (CStr (strDelimiter), File1)
However this is not possible, as the controllers of the company need to edit the. TXT file themselves. They will not be able to edit the script too.I don't think you can prevent the FDM, move the file. I'm assuming that the file change in each period to use the last period of POV, so I think that option easiset to copy the file (based on a part of the name (location?) to a temporary location before began the FOM and write again later.)
-
spend AMM SAMS to avoid the ORA-04031?
Database is 11 GR 2 on 64-bit Server 2008, currently allocated 400 MB for target PGA and 500 MB for the total size of SGA with SAMS on and off of MSA.
Last a few days I get of "ORA-04031: unable to allocate 3896 bytes of shared memory" when a job trying to insert into a table. The error is intermittent and it happens a few times a day. This database has been used for months with these settings without error memory and nothing has changed.
I usually run with active AMM, but for some reason when the database was installed it was set active SAMS and disabled AMM. Right now the shared pool takes up to 92% of the current envelope of the SGA. PGA target 402 MB with 190 MB currently allocated.
I'd be better of allowing the AMM and give just the database of 900MB to use? If I do this should I set the same maximum memory size to the size of total memory (or slightly more than) for AMM? If I change the MMS then I need the DB, that is doable, but earlier I would not if I can avoid bouncing.
Thank you500 MB for the total SGA
It is not much in terms of a fingerprint memory decent 11 g, try to clear the pga_target and memory_target value = 1000 M or an appropriate value according to the amount of physical memory on the host, let the engine decide how to distribute the shared pool, PGA, etc. just based on the value of the memory_target.
If the box has just 2G physical memory, a memory target 1 G will be tight.




Maybe you are looking for
-
House of sharing Apple tv does not
my apple tv repeat turn on home sharing photos stream from my mac, but home sharing is turned on, connected to my apple ID?
-
I've had my Apple Watch for about 3 weeks now. I like it. However, I noticed a small tuft of condensation near sensors. I don't bathe with my watch. There are even in the bathroom. I only wear at work, during workouts of the day type stuff and the da
-
Remove indicators cursors 8.2.1
Hello I'm developing an application of HMI using LabVIEW 8.2.1. I need help with the removal of the position of the cursor to an indicator of alphanumeric text. Who is oddly enough written so let me speak otherwise: When you type on the computer, it
-
Problem with joystick in bag 1 and Vista
I have a problem of gamepad with Combat Flight Simulator 1. I have a Microsoft batoss precision 2 game controller that until recently was perfect. Then it stopped working in the CFS. I uninstalled and reinstalled several times CFS. I added the script
-
How to open the NAT for a Linksys 160N with a WRT54G2 wireless ethernet bridge?
Hello, I have a Linksys 160N2 router, and I hooked a version w / updated router Linksys WRT54G2 {v24 sp1} DD - WRT. It worked great, but now my sons xBox 360 States that the NAT is moderate and should be opened. I don't know how to open the NAT. A