divide the data into lines
Hello
I have data like this.
Person_wid industry
111 car; Telecom
How to divide as below
Output:
Auto 111
Telecom 111
Thank you
SQL > test as
() 2
3 select person_wid 111, ' car. Telecom' double industry
4)
5. Select person_wid
regexp_substr 6, (industry, ' [^;] +', 1, rn) split
7 test
8 cross
9 join (select rownum rn
10 in (select max (length (regexp_replace (industry, ' [^;] +'))) + 1 mx)
11 test
12 )
13 connect by level<=>
14 );
SPLIT PERSON_WID
---------- ------------------
Auto 111
Telecom 111
2 selected lines.
Notes on the Oracle: split delimited by a comma the way of RegExp string, second part
Tags: Database
Similar Questions
-
Divide the data into several lines in the table
Hello
I use apex of Oracle 10 g 3.2.
I have a requirement like this.
I have a table like TableA
Col1 Col2
90 1
91 1:2:3
92 3
I want the data as
Col1 Col2
90 1
91 1
91 2
91 3
92 3
How to do this?
Thank you
Published by: user13305573 on August 3, 2010 20:16with your_data as ( select 90 as col1, '1' as col2 from dual union all select 91, '1:2:3' from dual union all select 92, '3' from dual ) select y.col1, regexp_substr(y.col2, '[^:]+', 1, t1.column_value) as col2 from your_data y, 13 table(cast(multiset(select level from dual connect by level <= length (regexp_replace(y.col2, '[^:]+')) + 1) as sys.OdciNumberList)) t1 14 / COL1 COL2 ------------------ ----- 90 1 91 1 91 2 91 3 92 3 5 rows selected. Elapsed: 00:00:00.05 ME_XE?select * from v$version; BANNER ---------------------------------------------------------------- Oracle Database 10g Express Edition Release 10.2.0.1.0 - Product PL/SQL Release 10.2.0.1.0 - Production CORE 10.2.0.1.0 Production TNS for Linux: Version 10.2.0.1.0 - Production NLSRTL Version 10.2.0.1.0 - Production 5 rows selected. Elapsed: 00:00:00.03 ME_XE? -
Divide the data into separate rows
Hi people,
I have a request, which could be simplified as:
with t as)
"name select 'John', ' 7.3.2014' date_from, ' 13.3.2014 ' date_to, 'SICK DAY' reason for the double
"" the name of Union select 'Mike', ' 28.3.2014 ' date_from, ' 2.4.2014 ' date_to, 'HOLIDAY' because of the double
"" the name of Union select 'Tom', ' 14.3.2014 ' date_from, ' 14.3.2014 ' date_to, 'HOLIDAY' because of the double
)
Select * from t
Each line includes a person's name, reason for his absence, the dates of and to.
I would like to divide these lines in separate registers (for later analysis), so an expected output would look something like:
with t as)
name select 'John', ' 7.3.2014' absence_date, 'SICK DAY' reason for the double
"the name of Union select 'John', ' 8.3.2014 ' absence_date, 'SICK DAY' reason for the double
"the name of Union select 'John', ' 9.3.2014 ' absence_date, 'SICK DAY' reason for the double
"the name of Union select 'John', ' 10.3.2014 ' absence_date, 'SICK DAY' reason for the double
"the name of Union select 'John', ' 11.3.2014 ' absence_date, 'SICK DAY' reason for the double
"the name of Union select 'John', ' 12.3.2014 ' absence_date, 'SICK DAY' reason for the double
"the name of Union select 'John', ' 13.3.2014 ' absence_date, 'SICK DAY' reason for the double
"the name of Union select 'Mike', ' 28.3.2014 ' absence_date, 'HOLIDAY' because of the double
"the name of Union select 'Mike', ' 29.3.2014 ' absence_date, 'HOLIDAY' because of the double
"the name of Union select 'Mike', ' 30.3.2014 ' absence_date, 'HOLIDAY' because of the double
"the name of Union select 'Mike', ' 31.3.2014 ' absence_date, 'HOLIDAY' because of the double
"the name of Union select 'Mike', ' 1.4.2014 ' absence_date, 'HOLIDAY' because of the double
"the name of Union select 'Mike', ' 2.4.2014 ' absence_date, 'HOLIDAY' because of the double
"the name of Union select 'Tom', ' 14.3.2014 ' absence_date, 'HOLIDAY' because of the double
)
Select * from t
Please advice, how for the first example query to obtain a required output?
Thank you
Tomas
SQL > with t as)
2. Select the name of 'John '.
3, to_date ("'07.3.2014', ' dd.mm.yyyy") date_from
4, to_date ("'13.3.2014', ' dd.mm.yyyy") date_to
5, 'SICK DAY' reason
6 double
7 union select name "Mike".
8, to_date ("'28.3.2014', ' dd.mm.yyyy") date_from
9, to_date ("'02.4.2014', ' dd.mm.yyyy") date_to
10 at 'HOLIDAY '.
11 double
12 union select name of "Tom."
13, to_date ("'14.3.2014', ' dd.mm.yyyy") date_from
14, to_date ("'14.3.2014', ' dd.mm.yyyy") date_to
15, because of "HOLIDAY".
16 double
17 )
18 select name
19, date_from + (level 1) leave_date
20, reason
21 t
22 connect
23 by level<= date_to="" -="" date_from="" +="">
24 and prior name = name
25 and prior sys_guid() is not null
order 26
27 by name
28, leave_date;NAME LEAVE_DAT REASON
---- --------- --------
John 7 March 14 SICK DAYS
John 8 March 14 SICK DAYS
John 9 March 14 SICK DAYS
John 10 March 14 SICK DAYS
John 11 March 14 SICK DAYS
John 12 March 14 SICK DAYS
John 13 March 14 SICK DAYS
Mike HOLIDAY 28 March 14
Mike HOLIDAY 29 March 14
Mike HOLIDAY 30 March 14
Mike HOLIDAY March 31, 14
Mike HOLIDAY April 1, 14
Mike VACATION April 2, 14
Tom March 14 14 HOLIDAY14 selected lines.
SQL >
-
Difficulty to use indexing to divide the data into five sets of data
Hello
I'm using labview to program a mass spectrometer. I want to conduct surveillance of the multiple ion where I watch the level of five different masses over time. The five different masses correspond to five of the tensions that are sent via the DAC to my instrument. After sending each voltage, a voltage was then read AIN. The help of indexation and a for loop, I can send fill this function.
My problem is to be able to plot these data. I need a field of tension AIN (y) and the time (x) for five tension (mass) and plots to display on a single diagram. I don't know how to correlate data from indexing to separate into five different mass and then repeat the experience by adding data to each mass using all loop. When I tried I just get data tracing as a straight line as a set of data when I need five sets of data.
I enclose my vi. Any help would be great.
Your VI base design is incorrect:
- There is no reason for you to have 2 while loops. One is suffient.
- You should not open the interface in each iteration of the loop. Open outside, do your work and then close when you are finished loop.
Regarding the map, get rid of the inner loop and eliminate this Build table you have outside the loop for. In order to have a graphic draw several lines, you have need of a 2D array. Because you use a loop for to acquire a reading at the same time, you'll need create a 2D out of the loop for. To do this, put a table to build inside the loop, then a function of 2D matrix transposes outdoors. See the attached example.
-
Hi all...
Here, I use the following scripts...
create table a10 (eno number, date f, date t, number of sal)
INSERT IN A10 (ENO, F, T, SAL) VALUES)
1, TO_Date (1 July 2013 12:00:00 AM ',' DD/MM/YYYY HH: mi: SS AM'), TO_Date (June 30, 2014 12:00 ',' DD/MM/YYYY HH: mi: SS AM')
(100);
INSERT IN A10 (ENO, F, T, SAL) VALUES)
1, TO_Date (May 1, 2013 12:00:00 AM ',' DD/MM/YYYY HH: mi: SS AM'), TO_Date (April 30, 2014 12:00 ',' DD/MM/YYYY HH: mi: SS AM')
(200);
COMMIT;
entry:
ENO F T SAL
07/01/2013 2014/06/30 100 1
1 05/01/2013 30/04/2014 200
Expected results:
ENO F T SAL 1 05/01/2013 2013/06/30 200
1 30/04/2014 300 07/01/2013
1 05/01/2014 2014/06/30 100
I'm little bit confused how to divide the dates here... Any help is appreciated.
Thank you all
Stéphane
Hello
Always tell what version of Oracle you are using, especially if it's so old.
In Oracle 10 (or 9, by the way) you can do this way:
WITH cntr AS
(
SELECT LEVEL AS n
OF the double
CONNECT BY LEVEL<=>
)
got_change_date AS
(
SELECT d.eno
C.n
WHEN 1 THEN f
ANOTHER t + 1
END AS change_date
C.n
WHEN 1 THEN 1
OF ANOTHER-1
END as mul
sal
BY a10 d
CROSS JOIN cntr c
-WHERE... - If you need any filtering, put it here
)
got_total_sal AS
(
SELECT eno
change_date f
Advance (change_date) OVER (PARTITION BY eno
ORDER BY change_date
) - 1 AS t
SUM (sal * mul) over (PARTITION BY eno
ORDER BY change_date
) AS total_sal
OF got_change_date
)
SELECT *.
OF got_total_sal
WHERE t IS NOT NULL
ORDER BY eno, f
;
-
ADF progress indicator to insert the data into the file table.
I have a requirement where the progress bar should indicate the percentage of completion to insert the data into the tables of database files in a given folder path. I found an article that explains how to get the progress indicator when downloading a file in
http://www.gebs.ro/blog/Oracle/Oracle-ADF-progress-indicator-in-Fusion-Middleware-11g/. I believe that I must first get the total number of files in the folder and then begin to compare with the number of files that are inserted into the table similar to what is done by downloading (getting the file size and download size), but I don't know how to do this. Can anyone help?May be that this example allows you to
* 042. Dynamically change the color of progress bar based on its current value *.
http://www.Oracle.com/technetwork/developer-tools/ADF/learnmore/index-101235.html
-
Loading the data into Essbase is slow
Loading the data into Essbase is slow.
Loading speed of 10 seconds on a record.
It is used standard KM.
How it is possible to optimize the loading of data into Essbase?
Thank you
--
GeloJust for you say the patch was released
ORACLE DATA INTEGRATOR 10.1.3.5.2_02 UNIQUE PATCH
Patch ID - 8785893
8589752: IKM SQL data Essbase - loading bulk instead of rank by rank treatment mode when an error occurs during the loading
See you soon
John
http://John-Goodwin.blogspot.com/ -
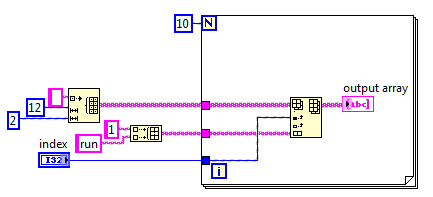
move the data by lines into a 2D array
HI, I have a question about moving the data in a 2D online table, that I was not able to do so if anyone has an answer please let me know
a picture of what im doing is attached as I said
I want '1 and run' online no column, if I change the index of the line it will work but the problem is that the 'run' under the '1' and I don't want if I change the index of the column of labview makes the data like the attached picture, but when I changed the labview index moves the data by column when want per row
Hi, I think that change your code as this will give you the behavior you're looking for.
That being said, your source code is a bit confusing. Why do you have a loop for? If you remove the loop for example, the code will do exactly the same thing.
Kind regards
-
Loading the data into the order of series of Timestamp
I need to load data into the target table in the order of series of timestamp. How to do it.
ex:
2015-12-10 02:14:15
2015-12-10 03:14:15
2015-12-10 04:14:15
After you follow the how to use the Direct-Path INSERT ordered by your "timestamp column" series described here above, you can sort the lines in ODI (order of) this way:
- The "ORDER BY" clause in an interface - handling ODIExperts.com
- ODI KM adding order by Option - ETL and DWH Blog
- You can change your knowledge used Module and the code inside. As a best practice, keep a copy of the KM, then change the steps. (Designer-> project-> knowledge Modules) double click on the Knowledge Module, go to the tab tasks and select one, then click the button change and change...
-
dividing the dataset into regions using sdo_relate
Hi all
I have difficulties subdivision my dataset in different regions. I have the data space of the city of auckland and found the coordinates of the lower left and limited right of data. What I want to do now is to break this dataset into 9 individual regions and assign a code to each region. I tried to use subsequently issue with not much luck...
Select a.link_id in the nz_testlinks_auck where mdsys.sdo_relate (a.GEOM,
MDSYS. SDO_GEOMETRY (2003, null, null, mdsys.) SDO_ELEM_INFO_ARRAY (1,1003,3),
MDSYS. SDO_ORDINATE_ARRAY(174.7083,-37.0141,174.7910,-36.9544)), "mask = ANYINTERACT querytype = FENΩTRE") = "TRUE";
When I put the output into a table data and display the data, I notice that the rectangle has chosen a lot more data than what was actually defined in the query. I have been using the model of network data and MapBuilder Editor to check the data and contact information.
And when I try to create another rectangle for another region next to each other like that...
Select a.link_id in the nz_testlinks_auck where mdsys.sdo_relate (a.GEOM,
MDSYS. SDO_GEOMETRY (2003, null, null, mdsys.) SDO_ELEM_INFO_ARRAY (1,1003,3),
MDSYS. SDO_ORDINATE_ARRAY(174.7910,-37.0141,174.8736,-36.9544)), "mask = ANYINTERACT querytype = FENΩTRE") = "TRUE";
He again selects a rectangle more great selection of half of the data of the previous selection rectangle as well.
Please help me solve this problem.
Look forward to your responses.
AvinashAvinash,
Do you have geometries that cross your limit of rectangle, as a long line, or a large polygon? What rectangle you plan such a line or polygon to appear in?
Or would you say that the geometries that are completely disjoint from your rectangle are chosen? If you think that this is the case, try the sdo_geom.relate with the mask "determine" in order to verify the relationship between your rectangle and one of the unexpected geometries.
http://download.Oracle.com/docs/HTML/B14255_01/sdo_objgeom.htm#BGHCDIDGIf you want to be sure that nothing is selected twice by your rectangles the ANYINTERACT mask is probably not a good choice. A = INSIDE + DOMMAGESCAUSDSPAR mask mask will be better, but you still have to decide what to do with stuff that crosses.
Matt
-
Divide the string into rows according to the space
I'm using Oracle 11.2.0.3. I need a faster way to divide the organization names based on space as possible just using SQL.
with org as
(
Select 1 org_pk, org_nm 'ALL american, INC.' of any double union
Select org_pk 2, org_nm "COMPANY A.G" Union double all the
Select org_pk 3, org_nm "GROWTH FUND SPONSORS and SONS, Inc." of the double
)
Select * org;
Result, I need is
1. ALL THE
1 american
1, INC.
2 A.G
2 COMPANY
3. THE GROWTH
3 FUND
3 SPONSORS
3 and
3 WIRES,
3 INC.
Thank you very much.
You can use GROUP BY with LISTAGG or XMLAGG. And ordinalite allows to preserve order:
with org as)
Select 1 org_pk, org_nm 'ALL american, INC.' of any double union
Select 2 org_pk, 'A.G COMPANY' org_nm of all the double union
Select org_pk 3, org_nm "GROWTH FUND SPONSORS and SONS, Inc." of the double
)
Select org_pk,
x.org_nm,
x.o
org,.
XMLTable)
"ora: tokenize(.,"").
by the way ' ' | org_nm
columns
path of varchar2 (4000) to org_nm '.'.
o for the ordinalite
) x
where x.org_nm is not null
/
ORG_PK ORG_NM O
---------- ------------------------------ ----------
1 ALL 2
1 American 3
1 ,INC 5
2 A.G 2
2 COMPANY 4
3 GROWTH 2
3 FUND 3
3 4 SPONSORS
3 and 5
3 SONS, 6
3 INC. 711 selected lines.
SQL >
However, I would like to use SUBSTR/INSTR plain + CONNECT BY if the volumes are large or performance is important.
SY.
-
Hi master,
I have to use sql loader...!
The client gave the data format below.
****************************************************
21, 1-Oct-2010, 31-Oct-2010, 49573, 33048, 1000, 11860
33048 21, 1-Nov-2010, 30-Nov-2010, 49573, 1000, 9408
1000 21, 1-Dec-2010, 31-Dec-2010, 49573, 33048,
33048 21, jan-1-2011, 31-Jan-2011, 49573, 1000, 8520
When I loaded through Sql loader with TOAD...
I get lines like this...
************************************
21, 1-Oct-2010, 31-Oct-2010, 49573, 33048, 1000, 11860
TECOM Business Group,
33048 21, 1-Nov-2010, 30-Nov-2010, 49573, 1000, 9408
TECOM Business Group,
21, 1-Dec-2010, 31-Dec-2010, 49573, 33048, 1000, TECOM Business Group.
33048 21, jan-1-2011, 31-Jan-2011, 49573, 1000, 8520
TECOM Business Group,
There are so many (more than 50 columns) columns in my table.
Please advise...!
AR
You can declare the empty fields as fields of FILLING.
Scott@orcl12c > t DESC
Name Null? Type
----------------------------------------- -------- ----------------------------
COL1 NUMBER
COL2 DATE
COL3 DATE
COL9 NUMBER
Scott@orcl12c > a.ctl TYPE of HOST
load data
INFILE *.
in the t table truncate
fields ended by ',' possibly framed by "" "
TRAILING NULLCOLS
(
col1,
col2 DATE 'DD_MON-YYYY. "
COL3 DATE 'DD_MON-YYYY. "
COL4 FILLER,
col5 FILLER,
col6 FILLER,
col7 FILLER,
COL8 FILLER,
col9
)
BEGINDATA
33048 21, 1-Oct-2010, 31-Oct-2010, 49573,
33048 21, 1-Nov-2010, 30-Nov-2010, 49573,
Scott@orcl12c > HOST SQLLDR scott/tiger CONTROL = a.ctl LOG = a.log
SQL * Loader: release 12.1.0.1.0 - Production on Sun Feb 2 10:23:28 2014
Copyright (c) 1982, 2013, Oracle and/or its affiliates. All rights reserved.
Path used: classics
Commit the point reached - the number of logical records 2
Table T:
2 rows loaded successfully.
Check the log file:
a.log
For more information on the charge.
Scott@orcl12c > select * from t
2.
COL1 COL2 COL3 COL9
---------- --------------- --------------- ----------
21 Friday, October 1, 2010 Sunday, October 31, 2010 33048
21 Monday, November 1, 2010 on Tuesday, November 30, 2010 33048
2 selected lines.
-
Reading file and dump the data into the database using BPEL process
I have to read the CSV file and insert data into the database... To do this, I created some asynchronous bpel process. Adapter filed added and associated with the receive activity... Adapter DB has added and associated with the Invoke activity. Receive two total activity are available in the process when trying to Test em, receive only the first activity is complete and awaits the second receive activity. Please suggest how to proceed with...
Thanks, Maury.
Hi Maury,
There is no need in step 2 that u mentioned above. I donot find useless a webservice?
The process will be launched by the CSV file, then using the processing activity, you can put it in the DB.
There should be no way where you can manually test it by giving an entry. All you can do to test is to put the file in the folder you mentioned when configuring the file adapter.
You just need to have the composite as below:
ReadCSVFile---> BPEL--> DB adapter
And in your BPEL process:
Recieve--> Transformation activity--> call activity
Try to work on some samples listed on the oracle site and go through the below URL:
The playback of the file adapter feature using
Thank you
Deepak.
-
Move the data into the new row
Hello
In the Oracle 10.1.2.0.2 report generator
I have a full line with data and more, but data whose length is > 45 just to put some... in the end, I want to take and move the data (character name) with a length > 45/new line
Priview for the NAME of the person idea got the name with more than 45 tanks Boby Bob young smar...
Search result:
Bob Boby younger Smar
TER
How can I do
TThe existing code.
Thank youCASE WHEN LENGTH (NAME) > 45 THEN SUBSTR (NAME, 0, 45) || '...' ELSE NAME END
ID
Edited by: 1D10T January 22, 2013 14:36
Edited by: 1D10T January 22, 2013 14:39
Edited by: 1D10T January 22, 2013 14:401D10T wrote:
Problem is that if I change something in the paper Layout report editor, as no line or change color, changes are not shown in priview (dissemination paper Layout program)If I change something in the layout of paper priview (dissemination paper Layout program) how to remove the line, then the changes after the replay is shown but I'm newebie in the Oracle Report Builder so maybe I'm doing something wrong. : ()
Hi ID, then you should learn first anyway...
Tutorial for Oracle reports...
Here's some link...
1 http://docs.oracle.com/html/B14364_01/title.htm
2 http://www.scribd.com/doc/3960412/Basic2-Oracle-Reports-10g-TutorialsVideo tutorial
http://www.YouTube.com/watch?v=Fum3MJm5yKUI hope this helps... :)
Take care..
Hamid
-
How to divide the data in the column based identifier
Hello
I use the oracle database.
I have data in this format in my column 1234 ~ 2345 ~ 3456 ~ 4567.
I need a motion to split the data in the column based on the identifier ' ~', so that I can choose the value after the second occurrence of the identifier.
Do I know who can do this.
Published by: 962987 on October 3, 2012 12:11Hello
Welcome to the forum!
Whenever you have any questions, please post CREATE TABLE and INSERT statements for some examples of data and the results desired from these data. For example, in view of these data
CREATE TABLE table_x ( my_column VARCHAR2 (40) ); INSERT INTO table_x (my_column) VALUES ('1234~2345~3456~4567'); INSERT INTO table_x (my_column) VALUES ('just~2 parts');I think you're asking for these results
PART_3 MY_COLUMN ---------- ---------------------------------------- 3456 1234~2345~3456~4567 just~2 partsI suppose that, if the string does not contain at least 2 ' ~ s, you want to return null. It's a good idea to explain what you want like that for special cases and include examples in your sample data and results.
Not all versions of Oracle are exactly the same. In fact, they are all different. If you want the best solution that works with your version, then say what version it is.
The following query will work in Oracle 10.1 and higher:SELECT REGEXP_SUBSTR ( my_column , '[^~]+' , 1 , 3 -- 3rd occurrence (after 2nd delimiter) ) AS part_3 , my_column -- if wanted FROM table_x ;See the FAQ forum {message identifier: = 9360002}
Published by: Frank Kulash, October 3, 2012 15:24
Adding sample data and results.
Maybe you are looking for
-
I want to stop a particular website to contact me by email.
-
Overheating Lenovo Z2 Vibe Pro
I thought that the last update solved sw overheating in this phone? I could play only 3 minutes of play and the appliance starts to heat. Example of games is real boxing and my God, the same free fall. I play these games in my old note 2 and I do not
-
Outlook express spell corrector does not
Original title: program of Outlook express my express tab (orthographic) outlook does not activate
-
Cap lock key did a glance whenever I hit this key. How can I stop this noise?
My cap key makes a shound peeping whenever I hit this key. How can I stop the sound?
-
Where can I download an earlier version of Acrobat Pro, Indesign, Bridge and Illustrator?
Hi allI'm looking to download an earlier version of Acrobat Pro, InDesign, Bridge and Illustrator? I have the serial number and spoke to license team that they were unable to help me. Help, please!