Max aggregate
For Oracle 10g.In addition to the following, how would I go about recovering the amount of the max (giftdate) and the date of the max (giftamt) in the form of columns? Follow these steps and everything must be separated from subqueries?
SELECT id, MAX (giftdate) AS last_gift_date,
MAX (giftamt) AS largest_gift_amount
FROM donations
GROUP BY id
SELECT id,
MAX(giftdate) AS last_gift_date,
MAX(giftamt) AS largest_gift_amount,
MAX(giftdate) KEEP(DENSE_RANK LAST ORDER BY giftamt) AS largest_gift_amount_date,
MAX(giftamt) KEEP(DENSE_RANK LAST ORDER BY giftdate) AS last_gift_date_amount
FROM gifts
GROUP BY id
/
SY.
Tags: Database
Similar Questions
-
Why the MAX aggregate function is used in SQL upon accession of the fields created in the designer?
Of course Certified Developer, you can see the left join to include the fields in the SU_EXTENTION_DATA table. Why MAX is used when retrieving these values?
! Wont start-
LEFT JOIN
(SELECT
REF_NO "REF."
MAX (CASE WHEN EXTENSION_FIELD_REF = 500033 THEN VALUE_DATE END) "DOB",.
MAX (CASE WHEN EXTENSION_FIELD_REF = VALUE_STRING END THEN 500034) "E_CONTACT."
MAX (CASE WHEN EXTENSION_FIELD_REF = 500035 THEN VALUE_STRING END) "E_CONT_NO."
MAX (CASE WHEN EXTENSION_FIELD_REF = 500036 THEN VALUE_TEXT END) "MED_HIST."
MAX (CASE WHEN EXTENSION_FIELD_REF = 500037 THEN SELECT_TEXT END) 'PREF_CONTACT '.
OF SU_EXTENSION_DATA
LEFT JOIN SU_SELECT_VALUES ON
SU_EXTENSION_DATA. VALUE_SELECT = SU_SELECT_VALUES. REF
WHERE CORE_ENTITY = 5
REF_NO GROUP) X ON AR_PERSON. REF = X.REF
! End custom-
When you do you must include all the fields that have been selected as criteria for grouping the aggregation OR use false features like MAX (more likely it's easier way when the result field is expression).
-
Select a record based on the date field MAX
I have the following query that works, but does include all the necessary columns. I need to JOIN the run_events table, which is a child of the runroute table, such that I choose not only the run_code and max event_timestamp, but also the LATITUDE, LONGITUDE columns. Each run_code has many events associated with it.
Any help or pointers would be appreciated!
Thank you
I've included descriptions of output and query table
WITH
ETV as (select run_code
-, LATITUDE, LONGITUDE
max (event_timestamp) TS
of run_events
Run_code group
)
SELECT all THE RR.run_code,
substr(PODDept.POD_NAME,1,10) DEPT,
To_char (ETD ' HH: mi: SS AM') r_ETD,.
To_char (ATD, ' HH: mi: SS AM') r_ATD,.
substr (PODDest.POD_NAME, 1, 10) Dest,
To_char (ETA, "HH: mi: SS AM'") r_ETA,.
To_char (ATA, ' HH: mi: SS AM') r_ATA
-- , VTE. LATITUDE, ETV. LONGITUDE
to_char (VTE. TS, ' dd-mm-yyyy hh: mi: SS AM') TS
OF routerun RR
PADE LEFT JOIN PODDest ON RR. PODEST_CODE = PODDest.POD_ID
LEFT JOIN PADE PODDept ON RR. PODEPT_CODE = PODDept.pod_id
ETV LEFT JOIN ON RR.run_code = VTE.run_code
WHERE ATA IS NULL
ORDER BY RR. ETA, RR. RUN_CODE
/
SQL > @rpt_runroute.sql
RUN_CODE DEPT R_ETD DEST R_ETA R_ATA TS R_ATD
--------------- ---------- --------------- --------------- ------------------ --------------- --------------- ----------------------
2013432247 NORFOLK 23:39:59 CHERRY PT 02:00 07/10/2013 01:00:15
NEW YORK 20:45:03 2013432224 CRESCENT B 06:00 10/07/2013 12:52:28 AM
2013432242 BALTIMORE 22:33:23 SALISBURY 10/07/2013 12:39:28 AM
Descriptions of table
PADE
Name Null? Type
---------------------- -------- --------------------------------------------------
POD_ID NOT NULL NUMBER (10)
POD_LONGITUDE NUMBER (10.6)
POD_LATITUDE NUMBER (10.6)
POD_NAME VARCHAR2 (64)
ROUTERUN
Name Null? Type
---------------------- -------- --------------------------------------------------
RUN_CODE NOT NULL VARCHAR2 (15)
REMARKS VARCHAR2 (1024)
PODEST_CODE NUMBER (10)
PODEPT_CODE NUMBER (10)
ETD DATE
ATD DATE
ETA DATE
ATA DATE
RUN_EVENTS
Name Null? Type
---------------------- -------- --------------------------------------------------
RUN_CODE NOT NULL VARCHAR2 (15)
EVENT_TIMESTAMP NOT NULL DATE
EVENT_CODE NOT NULL VARCHAR2 (6)
LONGITUDE NUMBER (10.6)
LATITUDE NUMBER (10.6)
Hello
One way is to use the MAX function analytical rather than the MAX aggregate, like this:
WITH
ETV as (select run_code
LATITUDE, LONGITUDE
, event_timestamp-* ADDED *.
, max (event_timestamp) OVER (PARTITION BY run_code)-* CHANGED *.
as TS
of run_events
-Group by run_code-* REMOVED *.
)
SELECT all THE RR.run_code,
substr(PODDept.POD_NAME,1,10) DEPT,
To_char (ETD ' HH: mi: SS AM') r_ETD,.
To_char (ATD, ' HH: mi: SS AM') r_ATD,.
substr (PODDest.POD_NAME, 1, 10) Dest,
To_char (ETA, "HH: mi: SS AM'") r_ETA,.
To_char (ATA, ' HH: mi: SS AM') r_ATA - if ATA is NULL, what's the point?
ETV. LATITUDE, ETV. LONGITUDE
to_char (VTE. TS, ' dd-mm-yyyy hh: mi: SS AM') TS
OF routerun RR
PADE LEFT JOIN PODDest ON RR. PODEST_CODE = PODDest.POD_ID
LEFT JOIN PADE PODDept ON RR. PODEPT_CODE = PODDept.pod_id
ETV LEFT JOIN ON RR.run_code = VTE.run_code
AND VTE.event_timestamp = VTE.ts-* ADDED *.
WHERE ATA IS NULL
ORDER BY RR. ETA, RR. RUN_CODE
/
If you would care to post, CREATE TABLE and INSERT statements for some sample data and the results you want from this data, then I could test it.
What happens if there is a tie for the final event_timestamp (i.e. 2 or more lines with the same exct run_code and event_timestamp)? You can use the analytic ROW_NUMBER function instead of MAX.
-
How to get the max of an element value selected iota AF Max.
Hello community,
Let me explain the scenario.
We have a workbook of discoverer, who have several reports. These reports extract information from multiple views built specifically to retrieve information in several tables. So far, quite normal.
Like any other report you can build these views, you can select the elements (columns) that you will use to create the report. Some of these elements (columns) are selected with the function MAX aggregate for this element; is that to say, instead of the profit of the item, and then click the SUM aggregation function, select the MAX aggregate function. With this option, we can get limit the number of search results.
In our case, we have created a report that shows the items that we have in our stock, for each item, the report shows the sum of kilograms, the average price, its value (the sum of the average price x kilograms) for each element of the family, and we want the report to display for each item (remember that each element is a line in the report or folder) the largest number of transaction_id (of which there been selected using MAX aggregate function for the selected item), but a kind of transaction types.
Let's see an example:
Family | Product name | Sum of the kgs. | Units | Average price | Value of stock. Month | Year | Transaction ID | Type of transaction | Date of movement
4420 | ALUMINA PS - M BB720 | 97.680,000 | KG | 44737 | 43.699,10 | 04. 10. 7740531 | Finalización Conjunto WIP | 16/12/2009
4420 | ALUMINA PS - M BB720 | 47.760,000 | KG | 44737 | 21.366,39 | 04. 10. 8100110 | EXCESS | 31/03/2010
4420 | ALUMINA PS - M BB720 | 97.680,000 | KG | 44737 | 43.699,10 | 04. 10. 8201603 | EXCESS | 30/04/2010
Considerations:
The value you see in the Transaction id is the maximum value that the field have; is that to say, each of the types of transactions, it shows the highest (last) transaction that id. looking at the example, the problem now is that we want to pocket the result a llitle little more. We want the report to show only from each product name or transaction id higher, either the date of circulation higher (as in the example above matches the transaction id 8201603 that have the highest movement 30/04/2010 - date).
I stopped at that point because I don't see how to filter the data to get the result we want.
Any suggestion or help would be appreciated, cause honestly, I don't see how.
Thanks in advance.
Luis.Hi Luis
In order to get the last day of the month, given a year and month as strings, you will need to convert the strings to a date. Assuming you have a two-digit month and, presumably, a 2 digit, with the year 2000 year and more, then you need to start with a date and let's start with the first day of the month like this:To_date ('01' |: month: year, 'DDMMYY')
You can use the ADD_MONTHS function to spend the month by one and then if you subtract 1 from that you will end up with the last day of the month.
EndofMonth = ADD_MONTHS (TO_DATE ('01' |: month |: year, 'DDMMYY'), 1)-1
You can also use the LAST_DAY function like this:
EndofMonth = LAST_DAY (TO_DATE ('01' |: month |: year, 'DDMMYY'))
Best wishes
Michael -
Hi all
My problem can be summarized as follows:
I have a human resources table that stores information from the person. I then use this table in my reports. The issue is
a person may have several registers in the table and because I need to select the disc for the person, the only record
must be selected. The thing is, by an inherent logic in which the table was developed, the only way the last drive for a person can be selected
by taking the MAX (SURRO_PERSON_ID) for this person (surrogate key is the primary key for the table and is filled by a sequence, so the max will give the last disc
for this person)
I created a complex join in the RPD and since impossible to use as MAX aggregate functions in the expression to the RPD Builder, I want to know
If there is a way by which I can achieve. It would be nice if I could do the RPD itself rather than answers, but if there is no other way
so it's good.
Please let me know if you need more info.
Thank you very much.Hello.
As I unerstood the PERSON a PERSON_ID as primary key table. Table PERSON_INFORMATION
a number of records for a single person or by a PERSON_ID so the PERSON_ID is foreign key to the PERSON table
and SURRO_PERSON_ID is the sequence (PK).Follow these steps:
Point of view is simply select analyzed a database (it is not really an extended view in the database).
Your point of view PERSON_INFORMATION_V will be something like:
Select pi.surro_person_id,
PI.person_id,
PI.*
person_information pi
where pi.surro_person_id in
(select max (pi.surro_person_id)
of person_information where person_id = pi.person_id)Of course, you must put all the columns you need in the select part.
Now you create a join view in a PERSON table FK physical layer:
PERSON_INFORMATION_V.PERSON_ID = PERSON. PERSON_IDA person may have only one line in PERSON_INFORMATION_V.
MDB, you need to create 2 logical tables.
One is for the fact table and secondly for the PERSON table.
MDB to a complex join between NO logical tables and logical (before making FK join between these)
two tables in the physical layer PERSON. PERSON_ID = DONE. PERSON_ID).In the logical table PERSON you only have a single table logic source (PERSON table) and inside in general tab, you
It should be added the physical table PERSON_INFORMATION_V and join physical it, you can do that because a person has information that one person.So in MDB, you have a FACT and one dimension (PERSON with PERSON_INFORMATION_V flakes in there.
I hope this helps.
Concerning
Goran
http://108obiee.blogspot.com -
Column not null in rows in SQL query
I have the below query,
WITH t
Did YOU (SELECT NULL col_1, col_2, 'C' FROM DUAL col_3 NULL
UNION ALL
SELECT 'A' col_1, col_2 NULL, NULL FROM DUAL col_3
UNION ALL
NULL SELECT col_1, col_2 "B", NULL FROM DUAL col_3)
SELECT *.
T;
who will pick up three rows, on which single column will have a value for each row.
And the other columns are left out as below.COL_1 COL_2 COL_3 C A B I don't need that values should be extracted in the column name that is not null.
as
COL_1 COL_2 COL_3 A B C
Please advise meYou can use the MAX aggregate function. But do not know what you are trying to reach.
-
Subquery factoring and materialize Hint
In the example given the sub query returns just one line because of the max aggregate function. This by making a With clause that will be of any benefit? Also I assume / understand that factoring of subquery would be really useful when we try to do a sub query that returns multiple rows in a clause. Is my right to intrepration?WITH t AS (SELECT MAX (lDATE) tidate FROM rate_Master WHERE Code = 'G' AND orno > 0 AND TYPE = 'L' AND lDATE <= ':entereddate') SELECT DECODE (:p1, 'B', RateB, 'S', RateS, Rate) FROM rate_Master, t WHERE Code = 'G' AND orno > 0 AND TYPE = 'L' AND NVL (lDATE, SYSDATE) = tidate;
Then add the / * + Materialize * / reference to a query with is required or the optimizer itself will do and perform a transformation of the temporary table. In my example, I have to give the hint in the query. Please discuss and help
Thanks in advance.ramarun wrote:
WITH t AS (SELECT MAX (lDATE) tidate FROM rate_Master WHERE Code = 'G' AND orno > 0 AND TYPE = 'L' AND lDATE <= ':entereddate') SELECT DECODE (:p1, 'B', RateB, 'S', RateS, Rate) FROM rate_Master, t WHERE Code = 'G' AND orno > 0 AND TYPE = 'L' AND NVL (lDATE, SYSDATE) = tidate;In the example given the sub query returns just one line because of the max aggregate function. This by making a With clause that will be of any benefit? Also I assume / understand that factoring of subquery would be really useful when we try to do a sub query that returns multiple rows in a clause. Is my right to intrepration?
Not quite.
The subquery factoring should be used when you want to use the subquery results more than once in your query. So if you write a regular SQL statement, but find that it is necessary to write the same subquery more than once inside, then you can factor on this subquery using the WITH clause, so that it is executed once, and the results may then be referenced several times in the main query. This is what gives a performance advantage in many cases.Then add the / * + Materialize * / reference to a query with is required or the optimizer itself will do and perform a transformation of the temporary table. In my example, I have to give the hint in the query. Please discuss and help
As mentioned the suspicion of materialization is not documented so should not be used in production code. Personally, I found that it can add significant performance gain of a weighted subquery where this subquery causes a large amount of data. Don't know why the optimizer is not always materialize subqueries by default but... not really looked inside a lot.
-
A query containing a subquery and Group By all-in-one
Hi people,
Any interesting fact but nerve racking situation I have here. I have a question that I have to do counts and amounts and I also need to have a Sub inside query. When I run my application, I get an error like this:
Error in the command line column: 4:36
Error report:
SQL error: ORA-00979: not a GROUP BY expression
00979 00000 - "not a GROUP BY expression"
* Cause:
* Action:
Here's my query:
If I replace it with the acc.account_num (subquery) with a number that is in the database, then my request works well.select distinct to_char(c.start_date,'YYYY') start_date, substr(acc.account_num,1,12) account_number, ( select acc2.account_desc from student_account acc2 where acc2.account_num = acc.account_num and acc2.account_type = 'A' ), COUNT(distinct(s.student_id)) from student s, student_account acc, course c where s.course_id = c.course_id and s.account_num = acc.account_num and to_char(c.start_date, 'YYYY/MM/DD') between '2004/01/01' and '2009/12/31' group by to_char(c.start_date,'YYYY'), substr(acc.account_num,1,12) order by 1;
Published by: Roxyrollers on March 29, 2011 16:45Hello
We don't know what you want. It would really help if you posted some examples of data (CREATE TABLE and INSERT statements) and the results desired from these data.
Are you sure that the scalar subquery will return ever more than one line? If so, you can wrap in a MIN or MAX aggregate function, as I've suggested before:
select distinct to_char(c.start_date,'YYYY') start_date, substr(acc.account_num,1,12) account_number, MIN ( ( select acc2.account_desc from student_account acc2 -- Changed where acc2.account_num = acc.account_num and acc2.account_type = 'A' ) ), -- Changed COUNT(distinct(s.student_id)) from student s, student_account acc, course c where s.course_id = c.course_id and s.account_num = acc.account_num and to_char(c.start_date, 'YYYY/MM/DD') between '2004/01/01' and '2009/12/31' group by to_char(c.start_date,'YYYY'), substr(acc.acct_acc_num,1,12) order by 1;It seems that you could also simplify the query and make more fast, eliminating the scalar subquery. The table there is already part of the main query, you can do something like this:
SELECT TO_CHAR (c.start_date, 'YYYY') AS start_date , SUBSTR (acc.account_num, 1, 12) AS account_number , MIN ( CASE WHEN acc.account_type = 'A' THEN account_desc END ) AS a_desc , COUNT (DISTINCT s.student_id) AS student_id_cnt FROM student s , student_account acc , course c WHERE s.course_id = c.course_id AND s.account_num = acc.account_num AND c.start_date BETWEEN DATE '2004-01-01' AND DATE '2009-12-31' GROUP BY TO_CHAR (c.start_date, 'YYYY') , SUBSTR (acc.acct_acc_num, 1, 12) ORDER BY start_date;I guess that course.start_date is a DATE. Instead of converting each start_date to string (so you can see if it is in the right range), it is more efficient and less prone to error, compared to other DATEs, as shown above.
It is very strange that you
substr(acc.account_num,1,12)in the select clause, but
substr(acc.acct_acc_num,1,12)in the GROUP BY clause. Did you mean having the same column in both places?
Yet once, without seeing some examples of data (CREATE TABLE and INSERT statements) and the results desired from this data, I can't do much.
-
What is the difference between the 2 procedures pls. ?
What is the difference between the 2 procedures in syntax and bussiness pls.
CREATE OR REPLACE PROCEDURE Balance_quantity_update (V_STORE_ID IN NUMBER, V_ITEM_SERIAL IN NUMBER) IS BEGIN UPDATE WH_T_ITEMS A SET BALANCE_QTY = ITEM_QTY WHERE STORE_ID = V_STORE_ID AND ITEM_SERIAL = V_ITEM_SERIAL AND ITEM_QTY = (SELECT MAX(ITEM_QTY) FROM WH_T_ITEMS B WHERE A.STORE_ID = B.STORE_ID AND A.ITEM_SERIAL = B.ITEM_SERIAL); END; /
Kind regardsCREATE OR REPLACE PROCEDURE Balance_quantity_update (V_STORE_ID IN NUMBER, V_ITEM_SERIAL IN NUMBER) IS BEGIN UPDATE WH_T_ITEMS A SET BALANCE_QTY =MAX(ITEM_QTY) WHERE STORE_ID = V_STORE_ID AND ITEM_SERIAL = V_ITEM_SERIAL ; END; /
Abdetu...I don't know exactly what you're asking. The query
UPDATE WH_T_ITEMS A SET BALANCE_QTY =MAX(ITEM_QTY) WHERE STORE_ID = V_STORE_ID AND ITEM_SERIAL = V_ITEM_SERIAL ;is not valid SQL from Oracle. As MAX aggregate functions cannot be used in a query like that because Oracle has no idea what you aggregate by. There is nothing preventing Oracle to change the syntax of the SQL language to allow an aggregate be used this way, but there is usually no reason to extend the SQL language like that.
You can assign the result of a query that included a total of BALANCE_QTY column, i.e.
UPDATE WH_T_ITEMS A SET BALANCE_QTY = (SELECT MAX(ITEM_QTY) FROM <> WHERE < >) WHERE STORE_ID = V_STORE_ID AND ITEM_SERIAL = V_ITEM_SERIAL ; I think I mentioned in some of your previous discussions, a data model where you have a table of ELEMENTS that has an ITEM_QTY and the BALANCE_QTY looks suspicious. You assign the value of the ITEM_QTY column to the BALANCE_QTY on the same line does only increase anxiety.
Justin
-
Displays dimension after measures for Pivot
Hello
I have a requirement to display some of the dimension columns after the columns in pivot mode. How do I get there?
Any suggestion would be considered useful.
Thanks in advance
Concerning
RemyIf it is a text field, you must create a formula such as:
Max(Table.Column by the others columns in the pivot without the excluded columns)Then you just drag and drop this column measures
If you have excluded columns, you must set a max aggregate on this column in the pivot.
And this response must be considered useful. It's free. ;-)
See you soon
Nico -
help me with this delicate sql...
I need a sql querry that displays ename, salary, max (salary) as max (salary) should be in each column.
This should be like this...
Ename salary (Salary) max
Smith, the 12000 18000
Robert 8000 18000
Frank 14000 18000
Walter 18000 18000
Stacy 5000 18000
Thank you
sexy...Hi, Sankar,
That's exactly what the analytical functions:
SELECT ename , salary , MAX (salary) OVER () AS max_salary FROM table_x;"OVER (
)" indicates that this is the MAX analytical function, not the MAX aggregate function.
You don't need analytical clause in this case, but the syntax always requires parentheses in "OVER (). -
Hello
I'm looking at possible solutions for data acquisition. I use 4 or 5 entries analog and two digital inputs. During the analogue entered most of them will not need sampling extremely quick rate except for one who needs the least 100ks/s. I noticed solutions cost-effective have overalls sampling rate (eg. 250 ksps / s) which extends on all channels. For these products, such that the NOR-9205 compactRIO module, is possible to distribute unevenly sampling rate between channels (ie. could I give up 100ks/s for a single channel and spread the 150ks/s rest between the remaining channels in use)? Thanks in advance for any help,
Adam
Hello Adam,.
To answer your question on the sharing of the sampling rate, it is not possible to have a single module different sampling frequencies, as described in this KB: here (http://forums.ni.com/t5/Multifunction-DAQ/Aggregate-sampling-rate-and-Multichannel-Scanning-Rate/td-....)
In the case of the 9205 this module multiplexes between all channels (32 cases set up in single ended mode or 16 in differential) this means that the sampling rate of 250 kech. / s matches total on all channels.
If you are using the differential mode then the samples per second on each channel will be 250 kech. / s divided by 16, IE 15KS/sec. However if you only specify 4 channels max sampling frequency will be 250 kech. / s divided by 4, IE 62.5 kech. / s.
One way around this is to use 2 x 9205 in one of our new CompactDAQ chassis, which has 3 engines of timing to HAVE. This allows to set different timings in 3 different modules. What is described in this KB: here (http://digital.ni.com/public.nsf/allkb/E7036C1870F6605686257528007F7A72)
I'm sorry of this reply took so long, and I hope the above information helps.
Please do not hesitate to answer questions.
If you want I could get one of our technical sales engineers to give you a call to discuss further with you data acquisition system?
Kind regards
-
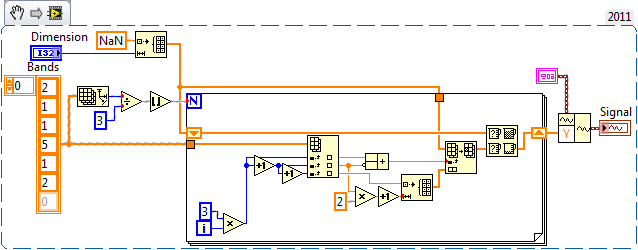
Hi all
I noticed a strange behavior in the min & Max node in the snippet below. It is set to compare items. According to the size of array, as determined by 'Dimension' the resultant y table for the 'Signal' gives different results.
It is supposed to read:
NaN, 1, 1, 1, 2, 2, 2, NaN...
But when I get a value for the 'Dimension' of 16 or more, it reads:
NaN, NaN, NaN, NaN, NaN, 2, 2, 2...
For small values of 'Dimension', the code snippet works as expected.
With the help of probes, it seems that min (NaN; x) = x for tables with 15 elements and less and larger paintings is min (NaN; x) = NaN
Certainly it is not provided for
I guess I'm missing something obvious and I'm about to learn something.

Or is it really a bug?
With the help of LV 2011 SP1
Concerning
Florian
A solution to your problem is to put a loop around the comparison. It will give consistent results.
What I find interesting, it's the result of more than 16 items of tables is the same that if you compare the aggregates.
It also has appearss to be precise to NaN. If you use a different value for your table, you don't see the value changes.
I can also confirm the same behavior in LV2012.
-
Problem with the Date Max filter in the mapping
Hello
I tried to put a filter on my mapping as mentioned below: -.
TABLE_SOURCE. DATE > (SELECT NVL (MAX (DATE),'' 01-JAN-1900) OF TARGET_TABLE)
I get the below mentioned, error in ODI 12 c performance: -.
Aggregate expression is in the filter, but no aggregate expression in the select list of the query for target: TARGET_TABLE
All I'm doing is making sure we receive only new records from the source. When I remove the NVL of the query, it works!
Please help me solve the problem.
Thank you and best regards,
PV
Hello
Write your Condition of filter in this way:
SRC_DATE > NVL ((select max (TRG_DATE) in TARGET_TABLE), January 1, 1900 "")
-
Hello
I want to select the most recent record in the data below using the max (dat) and to return all registration-related values, see test script and SQL below:
create table test
(number of references,
number of Seq,
VARCHAR2 (10) UserID.
DAT date);
Insert test values (' 0067, 1, 'ABCD', January 31, 1999 ");
Insert test values (' 0067, 1, ' ABDF ", February 28, 2006 ');
Insert test values (' 0067, 2, 'JHKO', January 31, 1999 ");
Insert test values (0067, 2, 'SARAH', 1 May 2001 ');
Insert test values (0067, 3, 'JUNIOR', January 1, 2000 "");Select * test tt,.
(select refs, max (dat) dat
of the test
Group of refs) t
where tt.dat = t.dat
and tt.refs = t.refsIs there a better method to return the last disk as the above query, but without using an inline view?
Hello
sliderrules wrote:
Hello
I want to select the most recent record in the data below using the max (dat) and to return all registration-related values, see test script and SQL below:
create table test
(number of references,
number of Seq,
VARCHAR2 (10) UserID.
DAT date);Insert test values (' 0067, 1, 'ABCD', January 31, 1999 ");
Insert test values (' 0067, 1, ' ABDF ", February 28, 2006 ');
Insert test values (' 0067, 2, 'JHKO', January 31, 1999 ");
Insert test values (0067, 2, 'SARAH', 1 May 2001 ');
Insert test values (0067, 3, 'JUNIOR', January 1, 2000 "");Select * test tt,.
(select refs, max (dat) dat
of the test
Group of refs) t
where tt.dat = t.dat
and tt.refs = t.refsIs there a better method to return the last disk as the above query, but without using an inline view?
Thanks for posting the CREATE TABLE and INSERT statements; This is really useful!
Do not attempt to insert the strings (as on 31 October 1999 ') in a DATE (such as dat) column. TO_DATE to create a DATE from a string.
You should never use a posting online. What you can do with a view online, you can also do it by using a WITH clause. But what is the problem with a view online?
You can use a subquery IN or EXISTS, but all that prevents you from using a view a line might prevent you from using one of them.
You can use the function sum LAST (or FIRST) to get all the data of the last line (or first) from each group. However, like all aggregate functions, that return exactly 1 row of output for each group. The query you posted returns several production lines for the same value of the refs if there is a link to the most recent DAT. Is this right? (It seems that the arbiters of combination + dat is not unique in your sample data.)
There are many other ways to get the desired results using queries in one form or another. I can't think of who are significantly better than what you have posted.
You could try the analytical function of MAX instead of the aggreate MAX, like this:
WITH got_max_dat AS
(
SELECT test. *- or display the columns that you want to
MAX (dat) OVER (PARTITION BY refs) AS max_dat
OF the test
-WHERE - if you need any filtering, it's where to put
)
SELECT *- or display the columns that you want to
OF got_max_dat
WHERE the dat = max_dat
;
I don't know if this will work better than what you have posted (it could, you can try it), but I like it because it can easily be adapted if your needs change, for example, if you want 3 DATS past, not just the 1 last.
Maybe you are looking for
-
How will I know if my photos are backed up
Sorry for the silly question After the support for my Airport time capsule of my iMac I don't know if the photos have supported the capsule
-
Trackpad guard switching pages/windows
I don't know exactly what I'm doing, but maybe 1 out of 5 times I put my finger on the trackpad to do something on a page, he slips the page more to something completely different, as if I had to hit to swipe on the left side of the screen to bring u
-
How can I recover delected from recycle bin files?
I deleted my itunes library just when I emptied my music folder and then the trash to make the space more... I thought that itunes would not be affected, but I was wrong! Help, please!
-
QFile writing in the file and trash to the first line
Hello. Got this code, writing to the file RPL - QNetworkReply QString workingDir = QDir::currentPath(); qDebug() readAll(); qDebug()
-
Getpreferredwidth and getpreferredheight custom text field
I have a customtextfield that I have to get the width of textfields, I tried getpreferredwidth() substitution but I'm stacoverflowmethod, I can understand the reason for the error but I tried getwidth() substitution I get 10 as standard response. I a