Reading a CSV with a large number of columns
Hello
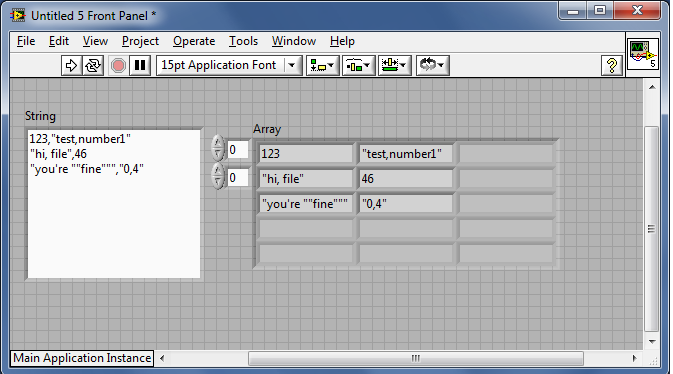
I tried to read data from files large csv with 38 columns by reading a line using readline and scan using the scan linebuffer.
The file size can be up to 100 MB.
Scan does not seem to support the large number of areas.
Suggestions to the comma separated fields 38 reading. There is a header row in the file.
Thank you
Have you considered the use of the modifier "rep"? You can find examples in help, search for 'chain with real table ASCII Comma-separated numbers '.
Tags: NI Software
Similar Questions
-
How to recover the large number of columns for all items at once
I have a table (T1) with a large number of columns (50). I am building a page on which I would like to consolidate these columns in some regions:
Region: has
Items i1 - i10
Region: B
I11 - i20 items
Region: C
I21 elements - i30
…
Etc.
The majority of the articles on this page are extracted from the same table (T1). So far, the type of each source element has the value SQL query and each item has the motion of the source is defined as:
SELECT column1 FROM t1 WHERE t1id =: global_item
What is the best practical approach to retrieve values for all items on this page? Is there a way to retrieve all the columns point at the same time, something like:
SELECT column1, Column2, Column3, column50 FROM t1 WHERE t1id is: global_item
Instead of:
I1 point source:
SELECT column1 FROM t1 WHERE t1id =: global_item
Point source i2:
SELECT Column2 FROM t1 WHERE t1id =: global_item
Point i3 source:
Column3 SELECT FROM t1 WHERE t1id =: global_item
…
Item i50 source:
SELECT column50 FROM t1 WHERE t1id =: global_item
For each item on this page, when they are displayed?
Thank you for your time.
DanielSet the source of static assignment type item and delete individual values of source of SQL query. Create a process before the header PL/SQL along the lines of
begin select column1 , column2 , column3 ... , column50 into :i1 , :i2 , :i3 ... , :i50 from t1 where t1id = :global_item; end;OR
Create an automated process line go through the wizard for the table T1, then set the Source Type of the database column and the source values for each item in the name of the corresponding column in the T1.
-
CRUD for tables with large number of columns
Hello
I work for a government agency in Colombia, and we do a poll with about 1200 variables. Our database model has few paintings, but they have a large number of columns. Our Oracle 11 g database is, and we do not use Oracle APEX. I've read about APEX and it seems to be useful to generate quick forms and reports. However, I would like to know if it is possible to generate CRUD for tables with many columns, and that would be the best way to do it.
Thanks in advance.
Carlos.
With the help of 250 point on a single page is actually really bad for the user experience. I would probably be it cut into pieces and using several pages to guide the customer through it as a workflow.
You could also add some pop-up windows which includes some elements of your table, just saved on other pages. But I probably don't like that.
Tobias
-
CC of Dreamweaver on iMac very slow to open sites with a large number of files
In recent weeks, a site I've worked regularly for several years began to take 10-15 minutes to open. A pop up says it checks the files, but the button that should allow you to escape this process does not work. The site has about 120 000 files located in different folders, and this was never a problem in the past. To access the site, the only way is to wait until the course ends and the spinning ball to go. I read the thread on the port of Skype settings, but I think that this may be a different problem because even though I have installed Skype I rarely running and only one of my sites is affected.
Any ideas?
With a large number of files, it would be a good idea to disable the cache of Dreamweaver for this site.
- Site > Manage Sites.
- Select the site, then click on the pencil icon to change site settings.
- Select Advanced settings > local news in the list on the left of the Site Setup dialog box.
- Uncheck the Enable Cache.
- Save > fact.
Another possibility is that your Dreamweaver cache is corrupted (probably with as many files). See remove a corrupt cache file.
-
RN104: 6.4.1: could not open the folder with a large number of files
Hello world.
I have a situaton that I can not open a previous file created with a large number of files stored in it.
There at least 2000 photographs, and when I try to browse, the content is never displayed.
Curiously, traversing a small file with say, 1000 records, it opens right.
I have reset the permissions without effect and I can't open it with RAIDar is.
Any suggestons? I'm about to happen for the pallets of the defibrillatior!

Thank you!
Hello Stephen
I was finally able to recover my files 3000 + using 'snapshot' and download the files on my computer!
I found a date where they were all visible.
I bought a new RN204 and move them to the new unit, as well as all my other data.
It is much faster with more memory as well.
Thank you
-
Add a large number of columns to a shape
Is there an easier way to add a large number of columns to a form of how I do it?
What happens in general I find that a bunch of columns must be added to the table, what I do in the database. So I need to get these
columns added to an existing form. As I do that is to create a new block in the form of referencing the same table, just like the old block.
Delete all the columns in the new block that were in the old block.
Move all the triggers of old block of the old block to the new block. Move old items to the old block of the newblock.
Search for old block properties where clauses or whatever and who recreate in the new block...
and then delete the old block and rename the new block to the old name of block.
Phew! A lot of potential for error here.
I need to possibly adjust the canvas for items and of course to reorganize things.
Is there a better way?
(BTW it's forms 11.1.1.4)
Published by: Lake on May 5, 2011 10:15
Published by: Lake on May 5, 2011 10:20Maybe create a routine of jdapi to compare the elements of a block known based on a table with the data dictionary ( user_tab_cols )? As each piece of information is given in the database (data type, the column name,...) should not be too difficult to implement.
http://www.Oracle.com/technetwork/Developer-Tools/Forms/documentation/jdapi904019-131445.zip
see you soon
-
How to export data to excel that has 2 tables with the same number of columns and the column names?
Hi everyone, yet once landed upward with a problem.
After trying many things to myself, finally decided to post here...
I created a form in form builder 6i in which clicking on a button, the data gets exported to the excel sheet.
It works very well with a single table. The problem now is that I cannot do the same with 2 tables.
Because the tables have the same number of columns and the columns names.
Here are the 2 tables with column names:
Table-1 (MONTHLY_PART_1) Table-2 (MONTHLY_PART_2) SL_NO SL_NO MODEL MODEL END_DATE END_DATE U-1 U-1 U-2 U-2 U-4 U-4 .......... ........ .......... ........ U-20 U-20 U-25 U-25 Given that the tables have the same column names, I get the following error :
402 error at line 103, column 4
required aliases in the SELECT list of the slider to avoid duplicate column names.
So how to export data to excel that has 2 tables with the same number of columns and the column names?
Should I paste the code? Should I publish this query in 'SQL and PL/SQL ' Forum?
Help me with this please.
Thank you.
Wait a second... is this a kind of House of partitioning? Shouldn't it is a union of two tables instead a join?
see you soon
-
How can I play files CSV lines with a different number of columns?
Hi all
I am trying to load CSV with DIAdem 2014 files, and I found there is a great tool, "use".
However, with the CSV use tool, there are critical problem with my data files. (See photo)
As you can see the CSV file attached, it includes a lot of lines with different columns.
And here, use read the number of columns of 1st line (e.g.: 4 columns) and set it as the number of columns to read.
So I can not load all of the data (e.g.: 53 columns) if first row data were lower than columns.
Can anyone recommend any approach, please?
Kind regards
Young
Admin 24/03/16 Note: files deleted by request of the user
I just add a few lines of script and fix the related use. (I just added the code to get a direct look).
The uri of the file will appear as a new kind of load in the dialog file tiara is intalled by double click
Would be nice if you could provide some information, how the data was created. Maybe we can it add as official of our web page to use plugin.
Option Explicit
Void ReadStore (File)
File.Formatter.Delimiters = «»
File.Formatter.LineFeeds = \n
File.Formatter.DecimalPoint = '. '.Dim startLine: startLine = file. GetNextLine()
<>InStr (startLine, ' [Tenergy Bus Log Data] "" ") then
call RaiseError()
end ifAnd that not File.Position = File.Size
Dim groupName: groupName = file. GetNextStringValue (eString)
If it isn't root. ChannelGroups.Exists (groupName) then
root. ChannelGroups.Add (groupName)
end if
Dim grp: set grp = root. ChannelGroups (groupName)
Dim i: i = 1
do for real
Dim val: val = file. GetNextStringValue (eR64)
If isempty (val) then
Exit
end if
< i="">
dial the grp. Channels.Add ("Brand" & I, eR64)
end if
protected chObj: set chObj = grp. Channels (i)
chObj.Values (chObj.Size + 1) = val
i = i + 1
loop
Call File.SkipLine)
WendEnd Sub
-
Procedure with a variable number of columns
Hi, I have a procedure that looks like this:
PROCEDURE PROC (p_cursor sys_refcursor OUTPUT)
In the procedure, I build query dynamically and the number of columns varies during execution.
In the end I do
OPEN for REQUEST P_cursor
Then I do call it,.
call PROC (?)
My question is, how could I go on the running query of this procedure, and then adding lines or by modifying the existing results, then return the changed data?
I want to do is add a new rank based on a condition, so I still need to return any number of columns, but I need to modify the results before I return them.
Is it possible to do? I need to do some calculations on columns (variable columns), create a new line, insert in the result set and return this new set of results.A sys_refcursor is ideal to return to a front end gui such as .NET or Java, which can then use this cursor to retrieve data.
In PL/SQL, there is no point in using a sys_refcursor unless you know, at the time of the design/build the columns returned are going to be.
If the columns resulting are dynamic, so you have no choice but to use the package DBMS_SQL, where you can analyze and run any SQL statement you like and then use the package DBMS_SQL to describe what are the columns that result and how they are. From this, you can reference the columns by position, rather than by name.
for example
CREATE OR REPLACE PROCEDURE run_query(p_sql IN VARCHAR2) IS v_v_val VARCHAR2(4000); v_n_val NUMBER; v_d_val DATE; v_ret NUMBER; c NUMBER; d NUMBER; col_cnt INTEGER; f BOOLEAN; rec_tab DBMS_SQL.DESC_TAB; col_num NUMBER; v_rowcount NUMBER := 0; BEGIN -- create a cursor c := DBMS_SQL.OPEN_CURSOR; -- parse the SQL statement into the cursor DBMS_SQL.PARSE(c, p_sql, DBMS_SQL.NATIVE); -- execute the cursor d := DBMS_SQL.EXECUTE(c); -- -- Describe the columns returned by the SQL statement DBMS_SQL.DESCRIBE_COLUMNS(c, col_cnt, rec_tab); -- -- Bind local return variables to the various columns based on their types FOR j in 1..col_cnt LOOP CASE rec_tab(j).col_type WHEN 1 THEN DBMS_SQL.DEFINE_COLUMN(c,j,v_v_val,2000); -- Varchar2 WHEN 2 THEN DBMS_SQL.DEFINE_COLUMN(c,j,v_n_val); -- Number WHEN 12 THEN DBMS_SQL.DEFINE_COLUMN(c,j,v_d_val); -- Date ELSE DBMS_SQL.DEFINE_COLUMN(c,j,v_v_val,2000); -- Any other type return as varchar2 END CASE; END LOOP; -- -- Display what columns are being returned... DBMS_OUTPUT.PUT_LINE('-- Columns --'); FOR j in 1..col_cnt LOOP DBMS_OUTPUT.PUT_LINE(rec_tab(j).col_name||' - '||case rec_tab(j).col_type when 1 then 'VARCHAR2' when 2 then 'NUMBER' when 12 then 'DATE' else 'Other' end); END LOOP; DBMS_OUTPUT.PUT_LINE('-------------'); -- -- This part outputs the DATA LOOP -- Fetch a row of data through the cursor v_ret := DBMS_SQL.FETCH_ROWS(c); -- Exit when no more rows EXIT WHEN v_ret = 0; v_rowcount := v_rowcount + 1; DBMS_OUTPUT.PUT_LINE('Row: '||v_rowcount); DBMS_OUTPUT.PUT_LINE('--------------'); -- Fetch the value of each column from the row FOR j in 1..col_cnt LOOP -- Fetch each column into the correct data type based on the description of the column CASE rec_tab(j).col_type WHEN 1 THEN DBMS_SQL.COLUMN_VALUE(c,j,v_v_val); DBMS_OUTPUT.PUT_LINE(rec_tab(j).col_name||' : '||v_v_val); WHEN 2 THEN DBMS_SQL.COLUMN_VALUE(c,j,v_n_val); DBMS_OUTPUT.PUT_LINE(rec_tab(j).col_name||' : '||v_n_val); WHEN 12 THEN DBMS_SQL.COLUMN_VALUE(c,j,v_d_val); DBMS_OUTPUT.PUT_LINE(rec_tab(j).col_name||' : '||to_char(v_d_val,'DD/MM/YYYY HH24:MI:SS')); ELSE DBMS_SQL.COLUMN_VALUE(c,j,v_v_val); DBMS_OUTPUT.PUT_LINE(rec_tab(j).col_name||' : '||v_v_val); END CASE; END LOOP; DBMS_OUTPUT.PUT_LINE('--------------'); END LOOP; -- -- Close the cursor now we have finished with it DBMS_SQL.CLOSE_CURSOR(c); END; / SQL> exec run_query('select empno, ename, deptno, sal from emp where deptno = 10'); -- Columns -- EMPNO - NUMBER ENAME - VARCHAR2 DEPTNO - NUMBER SAL - NUMBER ------------- Row: 1 -------------- EMPNO : 7782 ENAME : CLARK DEPTNO : 10 SAL : 2450 -------------- Row: 2 -------------- EMPNO : 7839 ENAME : KING DEPTNO : 10 SAL : 5000 -------------- Row: 3 -------------- EMPNO : 7934 ENAME : MILLER DEPTNO : 10 SAL : 1300 -------------- PL/SQL procedure successfully completed. SQL> exec run_query('select * from emp where deptno = 10'); -- Columns -- EMPNO - NUMBER ENAME - VARCHAR2 JOB - VARCHAR2 MGR - NUMBER HIREDATE - DATE SAL - NUMBER COMM - NUMBER DEPTNO - NUMBER ------------- Row: 1 -------------- EMPNO : 7782 ENAME : CLARK JOB : MANAGER MGR : 7839 HIREDATE : 09/06/1981 00:00:00 SAL : 2450 COMM : DEPTNO : 10 -------------- Row: 2 -------------- EMPNO : 7839 ENAME : KING JOB : PRESIDENT MGR : HIREDATE : 17/11/1981 00:00:00 SAL : 5000 COMM : DEPTNO : 10 -------------- Row: 3 -------------- EMPNO : 7934 ENAME : MILLER JOB : CLERK MGR : 7782 HIREDATE : 23/01/1982 00:00:00 SAL : 1300 COMM : DEPTNO : 10 -------------- PL/SQL procedure successfully completed. SQL> exec run_query('select * from dept where deptno = 10'); -- Columns -- DEPTNO - NUMBER DNAME - VARCHAR2 LOC - VARCHAR2 ------------- Row: 1 -------------- DEPTNO : 10 DNAME : ACCOUNTING LOC : NEW YORK -------------- PL/SQL procedure successfully completed. SQL>11 g, you can create a sys_refcursor and the DBMS_SQL package then allows you to convert this refcursor in a DBMS_SQL cursor so that you can get the description of results and do the same thing. It is not available before 11 g well.
However_ before any of this, you should really ask yourself if there is a real need to create queries dynamically. There is rarely a need to do and if you find that it is common in your application, then it is often a sign of poor design or bad defined the needs of the business (leaving the technical side to try to be 'flexible' and hence leading to unmaintainable code etc..).
-
Card reader can't read a map with a large capacity.
I have a Compaq SR1430NX under XP Home SP3. My card reader does not recognize a micro SD 8 gig used with a microSD adapter. I took the PC of a friend about three weeks ago. It was previously running a Linux platform. I have the drive formatted and installed XP. I downloaded and installed all available drivers and software on the HP/Compaq site and have updated all available on the Microsoft Update site, therefore the date of the NTDB. The card can be read by a PC similar I (home built) and a few laptops I have around. What else can I tell you? The SR1430NX works well otherwise, except this card.
rdgfx3 wrote:
BH, you mention a registry for a possible solution hack?
Hello
TI card reader asked only.
Kind regards.
-
After the upgrade to Firefox 30, on the site of Mozilla Firefox, it says that my browser is obsolete. Attachments in Gmail to "Composer Mail" button does not work. The Google search look-and-feel is that of when he was a few years before. Many modules such as "Sidebar goal" for the FIFA WC 14 says that it is not compatible with the browser.
Firefox 29 seemed to work very well, but not this!
See https://support.mozilla.org/en-US/kb/websites-say-firefox-outdated-or-incompatible
-
Recommended method to work with a large number of waveform attributes
Hello!
I want to include in my tables 1 d-waveform (as well as the TDMS files), over 20 attributes that characterize my measurement conditions.
What I actually do is to build a big (comma-delimited) string, (having converted before all my settings of individual channels) and then use this great string as a single attribute (string) of my wave.
I have not found information, again, on how best to use numerous amounts of waveform. Does anyone know if a degradation in performance (speed?, size?) is noticed is such a case?
Kind regards
Dimitri
I avoid the "Great String" attribute and make individual attributes:
Attributes of a waveform to TDMS are automatically added to the file. Having just a string containing all of the values will make it more difficult for the end customer read the file. Size and speed must not be from, because the metadata is written only once. Choose the format more user-friendly user and use a value by the attribute
-
Hello
I had tough time trying to figure out how to read a CSV with quotes, I need to read a csv file in order to fill out a worksheet.
I am attaching a sample csv file to display the type of file, that I'm trying.
Thank you
After inspection, you're right, it's a trick question. You need commas that follow an even number of quotes for separators. Since my previous statement was not converted, I assume that you have an earlier version of LV, so I have attached an example of 8.6. You can get rid of the quotes if you like (exercise for the reader).
-
Best practices for the handling of data for a large number of indicators
I'm looking for suggestions or recommendations for how to better manage a user interface with a 'large' number of indicators. By big I mean enough to make schema-block big enough and ugly after that the processing of data for each indicator is added. Data must be 'unpacked' and then decoded, for example, Boolean, binary bit shifting fields, etc. The indicators are updated once / sec. I'm leanding towards a method that worked well for me before, that is, binding network shared variable for each indicator, then using several sub-vis to treat the particular piece of data, and write in the appropriate variables.
I was curious what others have done in similar circumstances.
Bill
I highly recommend that you avoid references. They are useful if you need to update the properties of an indicator (color, police visibility, etc.) or when you need to decide which indicator update when running, but are not a good general solution to write values of indicators. Do the processing in a Subvi, but aggregate data in an output of cluster and then ungroup for display. It is more efficient (writing references is slow) - and while that won't matter for a 1 Hz refresh rate, it is not always a good practice. It takes about the same amount of space of block diagram to build an array of references as it does to ungroup data, so you're not saving space. I know that I have the very categorical air about it; earlier in my career, I took over the maintenance of an application that makes excessive use of references, and it makes it very difficult to follow came data and how it got there. (By the way, this application also maintained both a pile of references and a cluster of data, the idea being that you would update the front panel indicator through reference any time you changed the associated value in the data set, unfortunately often someone complete either one or another, leading to unexpected behavior.)
-
File to change PDF to print with a larger font
I understand that with Adobe Acrobat 9 or X, we could be able to print a PDF with a larger font. Is the only way because I don't have any other software - only the free player. To retirement and visually impaired, I really want to pay the full purchase price. I got the 4K eye surgeon...
You talk about a type change function that is not part of Acrobat. Sorry, but extend the font size which would require also a reflow of the document is not appropriate in Acrobat action. If you can convert the PDF to WORD or Open OFFICE (may be able to open a PDF file in one of them - maybe but doubt actually), you could do the expansion in WORD or Open OFFICE (or free AGENCY). Another option could be to try to copy and paste from the PDF file to a word processor. Unfortunately, you often end up with a large number of symbols of paragraph at the end of each line and may have to do a reformat. Good luck.
Maybe you are looking for
-
Conintually 12 Flash freezes / crashes
Hello. Flash 12 continually freezes / crashes ("adobe flash player 12 no longer"), making it impassable Firefox. I worked through the troubleshooting guide, but it did not help. There is a quite fantastic number of incident reports; If it helps, here
-
global variables for the XML plugin problem
Hello world recently I started working on a dialog box SOUTH, where the user can load the *.xml files in DIAdem.So much my code for the button looks like this: .... Call the FileNameGet ('ALL', 'FileRead","*.xml")Call DataFileLoad (FileDlgName, "XML_
-
I lost my Nokia mobile, how do I know who use sound now
I lost my Nokia mobile, how do I know who use sound now, what mobile operator sim card using this mobile
-
Send data and receive commands by VBAI of VB or c#
Hi, anyone has examples on how to send VBAI data and receive commands by VBAI of VB or c#. I intend to hand over command to the VBAI on and outside, get the image and stop start. For the data to be send are the result of the calculation of the calcul
-
I'm going to an auto to install update. The installation is correct. But when I do a restart, he comes back in a safe mode. I don't know what to do. Any help is greatly appreciated.