some clues of the elements in the table 1 d
Hello to you all,.
I am a very beginner in programming and using labview, so I have my apologies for any banality, I could write.
I have a table 1 d of numbers (1600 items) and let me know (this table) indexes of all items that are <1 and="">- 1.
Are there any suggestions? I am not quite aware of all the possible functions, that I can use.
Thank you very much for your help
GIO'
It is a way to do...
You would wire your table to control "Your Array" and the output is a table 1 d with the indeces of the elements between-1 and 1
Tags: NI Software
Similar Questions
-
creating views in a new scheme to access some rows of the tables in the source schema
Hello
Oracle 10.2.0.4
We try to hide some data from some users. My suggestion is that we create a new view_schema scheme on the same instance where we said the source tables in source_schema.
We then create views in view_schema as below
CREATE VIEW AS SELECT * FROM source_schema.table where COLUMN_n = "XYZ";
We then grant SELECT on these views to a role and assign this role new users to be able to consult the data consulted.
If the questions below.
- We can create views to view the data in another schema WITHOUT giving SELECT permissions on source_schema.tanle directluy?
- It works and there is no need to create synonyms etc.
- YOU can manage users and much easilier view (s)
Is there a sense and who better than the selection seen with say table_name_view in the source schema to this effect and even the creation of synonyms for these points of view with the same name, yasmina in sourece_schema?
Thank you
905989 wrote:
Hello
Oracle 10.2.0.4
We try to hide some data from some users. My suggestion is that we create a new view_schema scheme on the same instance where we said the source tables in source_schema.
We then create views in view_schema as below
CREATE VIEW AS SELECT * FROM source_schema.table where COLUMN_n = "XYZ";
We then grant SELECT on these views to a role and assign this role new users to be able to consult the data consulted.
If the questions below.
- We can create views to view the data in another schema WITHOUT giving SELECT permissions on source_schema.tanle directluy?
- It works and there is no need to create synonyms etc.
- YOU can manage users and much easilier view (s)
Is there a sense and who better than the selection seen with say table_name_view in the source schema to this effect and even the creation of synonyms for these points of view with the same name, yasmina in sourece_schema?
Thank you
1. you can create the view in another schema (first granting of privileges to the schema of the view) without granting privileges of the schema of the source
2. you probably want to create public synonyms for the view (s). You can refer to the view as schema.view, but it's bulky
3. I'm not sure management is easy, but the extra complexity shouldn't be too bad. Write the documentation describing how everything works and the object involved.
Another, more complicated, but more powerful option is to use row-level security also known as the virtual private database - if you have the license. You create a profile for a table and a procedure to generate the WHERE clause to filter a query against the table and the columns defined in the profile. Yet once, you need license to do this.
-
@Code is:-
I have a panelCollection which is having an ADFTable (VO) and < f: toolbar > < coomandToolbarbutton > IE change by clicking on modify the selected line of the tbal adf becomes open in edit mode in a popup. Buttong ActionListner change creation popup
{} public void handleEdit (ActionEvent actionEvent)
Add the code in the event here...
Line selectedRow =
(Row) ADFUtils.evaluateEL ("#{bindings.") BtEsAwardsSchemeSetupVO1Iterator.currentRow}");
Line selectedRow =
(Row) ADFUtils.evaluateEL ("#{bindings.") BtEsAwardsSchemeSetupVO1.currentRow}");Tips RichPopup.PopupHints = new RichPopup.PopupHints ();
this.getAddEditpopup () .show (hints);
}Pupup has two buttons for Submit and cancel.
Click on Cancel button on the popup, it id hide. The question is, suppose that the table is to have 4 lines so if I first select third row and click on change that becomes open editing on a popUp, but if I click on the Cancel button and their selection a few rows of table (Say first line), the previously selected (3rd row) rank only becomes open again in popup instead of the newly selected row.
Cacel code{} public void handleCancelAwards (ActionEvent actionEvent)
Add the code in the event here...
ADFUtils.invokeEL ("#{bindings.") Rollback.Execute}");
this.getAddEditpopup (.cancel ()); [I also tried with hide and seek but not worked]
}
Thanks in advance and thanks for your time
It may be a problem with the combination of: immediate = true, rollback, and af:popup.
You can try adding af:resetActionListener to the Cancel button.
BTW, your managed bean is in the package that start with uppercase ("Bean"). (if you should refactor this to "beans" (for example))
Dario
-
Fonts of different weights for some rows from the table in a tableView
Hi all
I need to add a summary in a TableView row to calculate the sum of all values above this line. For each line, I have an object called KostenDTO.
class SummCurrencyTableCellFactory implements Callback, TableCell> {private NumberFormat numFormat = null;public SummCurrencyTableCellFactory(NumberFormat numFormat) {this.numFormat = numFormat;}@Override public TableCell call(TableColumn param) {TableCell cell = new TableCell() {@Override public void updateItem(final Float item, boolean empty) {if (item != null) {setText(numFormat.format(item));setStyle(" -fx-alignment: CENTER-RIGHT;");if (item < 0.0) {this.setTextFill(Color.RED);} else {this.setTextFill(Color.BLACK);}} else {setText("");}}};return cell;}};
How can I change the font to bold amount-line?Thanks and regards Tim
You can do
String fontWeight ; if (getIndex() == getTableColumn().getTableView().getItems().size()-1) { fontWeight = "-fx-font-weight: bold;"; } else { fontWeight = "-fx-font-weight: normal;"; } setStyle("-fx-alignment: CENTER-RIGHT;\n" + fontWeight);in the updateItem method (...), assuming that the line of the somme is the last line of the table.
-
Export all the objects and only some data in the table
Hello
can we use exclude and include them both at the same time. I want to export the full scheme, but only a few required data table 5, it is possible.
Please share expdp and impdp query.
Regs,
Brijesh845712 wrote:
Hellocan we use exclude and include them both at the same time. I want to export the full scheme, but only a few required data table 5, it is possible.
Please share expdp and impdp query.
Regs,
BrijeshYou can export meta_data first and then export the tables you want to get data.
exp hr/hr rows=N file=xxxxxxxxxxx.dmp exp hr/hr file=yyyyyyyyyyy.dmp tables=(emp,dep)complete schema without data first and then import data
imp hr/hr file=xxxxxxxxxxx.dmp imp hr/hr file=yyyyyyyyyyy.dmp IGNORE=y (so it will load data to previously created tables)concerning
Gokhan Atil
-
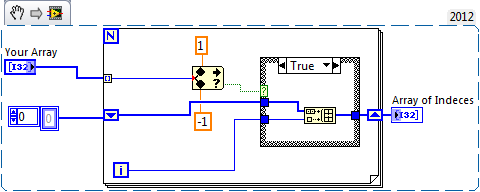
Hi all
I have an array of 10 elements, for example. I need to remove some items within the table if the elements meet a criterion. I know how to do this, but I don't know is it the effective must do it, because I will need to use the 'build' in a loop, and I know it's a big no, no, if I can help it.
I have attached an example of my problem and my approach. Note that the condition allows you to select which item to select in the input array is just an example. The State could be anything.
Replacement indicated, I thought (I guess I can code some stuff, but I'd like to hear your suggestion first):
1. I thought to use the deletion of the table, but I thought it will be messy, because once I delete a single element, indexing would spoil a little.
2. I thought to initializaing an array of fixed size and replace the element of this array with elements taken from the range on the other, but not sure it's worth it to go through the extra trouble.
3. it will be nice if there is a function that will display an array of indexes of all the items in a table of entry that correspond to a criterion. I know that there is a function that will do that but it's only for a single item.
4. in addition, I'll be more enjoyable if there is a removal of the function array that could take an array of index, remove several elements of an array at the same time.
Yik
See this discussion.
jyang72211 wrote:
4. in addition, I'll be more enjoyable if there is a removal of the function array that could take an array of index, remove several elements of an array at the same time.
-
Check the constraint on the table but to apply only to certain lines?
Hello
Using oracle 11.2.0.3
We have table and you want to put a strain of additional validation on a column on the table, but for this constarint check apply only to some lines in the table
for example, if the line has produced some type of a particular column must always be completed.
What is the best way to do this?
Thank you
Hello
More simply
CHECK (some_column IS NOT NULL
OR product_type! = « X »
)
or, depending on the expected results when product_type is NULL
CHECK (some_column IS NOT NULL
OR NVL (product_type, 'OK'). = « X »
)
-
impact of production if I reduce space on the table...
Hello experts.
I am running Oracle 11.2 and seen in OEM I have a table that is candidate to shrink the space.
According to OEM, I can gain 5 G by the decrease in the table.
The table is 16G, so if I reduce the table, then it should reduce about 11 g, right?
This table is the primary table used by our application, impact on production is very important.
Good, then I wonder what is the impact of production on the table while I shrink space on the table.
I'll test now in my test environment.
First of all, I found that I had a function based index to be deleted until I can reduce the table.
So I ran dbms_metadata for syntax to recreate the FBI, then dropped the FBI.
Then I ran change movement line of table owner.tablename enable;
Then I ran alter table shrink space cascade owner.tablename;
While I'm under the table command shrink, I opened another session and I asked the table and even made some updates on the table.
I was very surprised that the table is not locked and is always accessible for update and select statements.
In fact, I don't see any noticeable impact of the retractable table command.
Obviously, I'm not in the production environment with hundreds of simultaneous users, but my question is what kind of impact should I expect see if I have it in production with people hitting this table? (No, this isn't an IOT.)
Any ideas?
Published by: 974632 on February 19, 2013 05:54
NOTE: The command table shrink took: passed: 00:43:17.19
Re-create the function based index took: passed: 00:00:28.80No, the shrinkage is invalid index.
This means that when you use the CASCADE option, index will be narrowed as much too. When you use shrink, you use the clause 'movement of table XXXX line activate edit' which can cause invalid objects such as triggers or procedures related to the XXXX table.
Also, if you issue the following statement "alter tableenable/disable row movement;" it will invalidate any stored procedure that references that table. But, once you reference that invalid stored procedure, Oracle recompiles it
from: http://asktom.oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:35203106066718
Where are the table of contents images stored?
Hello. I created an application with DPS on my Mac that I have to study.
I used some images for the table of contents chapters which stupidly I deleted but they are always visible when building/testing the application, I need to change the structure and the use of these same images. Is there a place I can find the images that I used for the table of contents?
When you preview your application on the desktop using LCA, the assets are registered in: ~/Library/Application Support/com.adobe.dmp.contentviewer/Local Store/FolioCache/YourAppName/ArticleName/StackResources/toc.png (or toc.jpg)
ODI 12 c: do I have to reimport the target tables after that I did some clues on them
Hello
I created a map after import target tables in my ODI 12 C studio. The mapping is complete and it works without any errors. Now I intend to create some clues that I have an obligation to report. SO, I have to reimport these after creating indexes.
Thank you
SM
Hello
Here's the thing. The indexes that you created, if you plan to use as a unique index, or as your key to updating ODI you can go ahead and add the template manually in or hit the table again. However, if these indices are purely to make your report more quickly and will have no impact on you data loading then it is pointless to ODI. In the future when you make changes to the table and refresh it in ODI indexes will be added automatically.
Thank you
Ajay
Disable "insert the front element / remove item ' in the table
Hello guys.
It is possible to deacitvate function "insert the front element / delete" appears after right-clicking on a table in the front?
"Description and trick" should stay.
Thank you.
Alex
You can customize the context menu to remove elements of the request and keep others:
Click on the table (and not on the array element!) in the Panel and select Advanced-> Menu contextual Run - Time-> Edit...
This brings the context Menu Editor:
Change the control drop-down menu of "Default" to "Custom".
Select it "?" line in the tree on the left control.
on the right, change the element Type of the "user position" «Application point-> Description and Tip...» »
It automatically fills the corrent name and the tag.
Save the rtm either in a file or in the control.
LV will automatically manage elements of the application in the control, any necessary events.
I sometimes find the function "Menu copies" of the context menu very useful if I want to just disable some elements.
http://zone.NI.com/reference/en-XX/help/371361G-01/lvconcepts/customizing_vis/#Customizing_Menus
How can I get the clues of the largest 40 a 1 d table data?
Hi all
I want to deal with data acquired on the fly, and there is the question. I have a 1 d table and I want to get the 40 largest data INDICES. I can sort the table to get the 40 largest data and then look for the corresponding indices of them. But the size of the table is very big and I don't think that it is an optimized method. Yes, is there a better idea? Thank you.
Best wishes
Bo
Altenbach says:
It can still be improved a bit...
OK, here's the improvements I made on a quick intuition.
For a table of 10 M from random data , it is approximately 60 x faster (100 ms vs 7000ms) than my simple solution above. (it's about 30 times faster for an array of 1 M).
Basically, here only keep us the top 40 elements in an array, and store the currently smallest element in a shift register. If the new item is greater than the currently smallest element, replace us the smallest item with the new item, sort the table of top 40 and mark out the currently smallest element. If the new item is smaller, we do nothing.
Be careful, however, because the algorithm is now data dependent and can be slow for some data pathalogical.
For example if the entry is a perfectly sorted array, the penalty is very big, so that if we have a reverse sort table algorithm is extremely fast. For random arrays of entry, the chances of finding a new top 40 item gets smaller very quickly and we win because we execute more often the case of void.
Modify if needed. You should test your typical data to ensure it is appropriate.
I don't know there is still more optimized opportunities, anyone want to try?


Unable to get the elements placed at the top and bottom of the cell of the table with vertical-align
Hello
I have a three-day educational courses in the list table. In each cell, I have the title of the presentation at the top with the name of the speaker below. Because some titles are longer than others, the line grows (rightly) as longer securities are covered in Word. So far so good. Now, I want all the titles to always start at the same distance from the surface of the cell (I use padding 2px) and names of speaker all be equidistant from the lower border, (i.e. 2px).
I tried to place the title elements with < span style = "vertical-align: top" > </span > presentation title
and the name of the speaker as < span style = "vertical-align: bottom" > name </span > Speaker
and I tried the same method with < div > and < p > tags. Items don't move. Can someone tell me how to make the names of the speakers will be all aligned at the bottom of each cell?
Here is an example of the code table I've tried:
(Thanks!)
< table style = "text-align: center;" do-family: Arial; background-color: #f7d49c; "border ="2"bordercolor =" #467E9F "cellpadding ="2 ".
"cellspacing ="0"width ="900">"
< tbody >
< b >
< td width = "300" > < span style = "" vertical-align: top; "> This is a short title </span > < br / >"
< span style = "vertical-align: bottom" > name </span > < table > Speaker
< td width = "300" > < div > is the title of another presentation, which is really long because some of the presentations have titles like that < / div > < br / >
< div style = "vertical-align: bottom" > Speaker name < / div > < table >
< td width = "300" > < span style = "vertical-align: top" > This is yet another presentation with a semi-long title </span > < br / >
< span style = "vertical-align: bottom" > < table > </span > Speaker's name
< /tr >
< b >
< td > < table >
< td > < table >
< td > < table >
< /tr >
< b >
< td > < table >
< td > < table >
< td > < table >
< /tr >
< b >
< td > < table >
< td > < table >
< td > < table >
< /tr >
< / tbody >
< /table >
By default, the content of the table cell is average aligned. You need not do anything.
If you want your cell vertically aligned up or down, you can specify it in your CSS. These effects all the text inside the cell. It's all or nothing.
Some text that is aligned at the top Some bottom-aligned text Keep the order of the elements stored in the table pl.sql
Hello friends,
I'm having a type registration and for each item in the folder, I'll have the corresponding table of pl.sql type.
If I store the values in the records in a query and also the individual elements in the table of pl.sql type will be of the order of the data is stored as it is. ..
for example...
in a record type, the data is stored as (name1, years1, salary1), (name2, age2, salary2)
If I store in correspondent pl sql table type name1, name2
years1, age2
salary1, salary2
I can identify the index of the record type with that of type pl/sql table...
pls advice
Thank you/kumarKumar,
Yes, the order of the elements will be the same.
No specific reason why you want to create a collection for each attribute of the record?
You can also declare another variable of the same file and initialize it.Some other suggestions for your code:
(1) FOR 2nd loop can be changed to accommodate the request of the first slider he - by eliminating an extra iteration.
SELECT MINC.FAMID, MINC.MEMBNO, MEMB.AGE, SALARYX, SALARYBX, NONFARMX, NONFRMBX, FARMINCX, FRMINCBX, CU_CODE FROM MINC, MEMB, FMLY WHERE MINC.FAMID = MEMB.FAMID AND MINC.MEMBNO = MEMB.MEMBNO AND MINC.FAMID = FMLY.FAMID AND MEMB.FAMID = FMLY.FAMID ORDER BY MINC.FAMID(2) the collections can alternatively be initialized as follows:
v_member_rec(v_member_rec.last).FAMID := j.FAMID; max_earnings_tab(max_earnings_tab.last) := v_max_earnings;The I tried the example for confirmation below...
declare type emp_rec is record (name emp.ename%TYPE, dept emp.edept%TYPE, sal emp.esal%TYPE ); TYPE emp_rec_tab is table of emp_rec; ert emp_rec_tab := emp_rec_tab(); TYPE ename_tab is table of varchar2(20); ent ename_tab := ename_tab(); TYPE edept_tab is table of number; edt edept_tab := edept_tab(); begin for i in (select * from emp) loop ert.extend; ent.extend; edt.extend; ert(ert.last).name := i.ename; ert(ert.last).dept := i.edept; ert(ert.last).sal := i.esal; ent(ent.last) := i.ename; edt(edt.last) := i.edept; end loop; for i in 1..ert.count loop dbms_output.put_line(ert(i).name||','||ent(i)); dbms_output.put_line(ert(i).dept||','||edt(i)); dbms_output.put_line(''); end loop; end;Why the table in the output of MT complex waveform modulation FSK 255 elements missing?
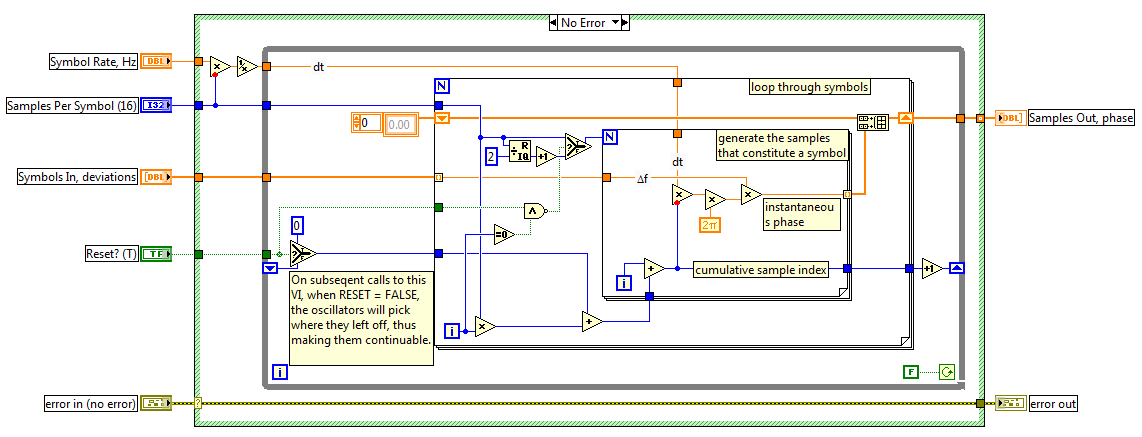
Hello! I posted my question in the LabVIEW forum but an application engineer suggested I post here. I'm new so any help would be appreciated

I use this example FSK in LabVIEW (VI is attached). As it can be seen in the block diagram, the number of samples by specified symbol is 512. If I run 2 - FSK, I have 1 bit per symbol. So I if I have 128 bits, 128 symbols. and if I have 512 samples per symbol, I expect 65536 samples/elements in the complex waveform of the MT output modulation FSK. However, I get only 65281 elements in the table. There are 255 missing items.
If I run 4 - FSK and have 128 bit or 64 symbols, I expect to 32768 in the table. But then again, I'm running out of 255 items and get 32513.
Am I missing out on something? Have I misunderstood something? Thank you very much for your help.
I get the same results as you!
I Dove a little inside, and it seems that the code that generates the symbols, two layers down, which reports an explanation to this.
If you open MT modulate FSK.vi, then mod_FSK modular Phases.vi discontinuous to generate in the discontinuous case of the structure of the case, you will see the following code.
You can see that when Reset is set to True (the default) and the external-loop for is in his first race, the inner-loop for work (samples per symbol) / 2 + 1 times (in your case, this number is 512 / 2 + 1 = 257.) Subsequently, the inner-loop for runs with 512 for each outer loop for iteration. This means that the first round fail to 512-257 = 255 samples, which causes the total to 255 less samples.
I don't know what is the motivation behind this design. As a test, you could connect in a constant False to Reset of the MT Terminal modulated FSK VI, which causes all the samples to generate.
Hope that clarifies it.
Maybe you are looking for
-
How out to authorize my computer?
I have my mail, etc on my mac at work. I added the access I have cloud to my MacBook Pro. How can I remove access to my I-cloud?
-
How do the function of table 1 d search case-insensitive for the array of strings
How do the function of table 1 d search case-insensitive for the array of strings
-
Difficulty which do not show some buttons or icons of Web pages
My Web pages are not displayed buttons or icons on pages. This details box has 9 empty square boxes and does not show what they are until I put my mouse on them. How can I fix?
-
Hello I have a laptop Lenovo G550 with processor dual-core Intel, 4 GB RAM, 320 HDD with Windows Vista Home Premium 64-bit works fine yesterday. All of a sudden all processes be losed with strength and i' received e of error messages to send informat
-
Original title - laptop be cleaned whenever I start it I recently problen with my laptop. There cannot be first start. Then it fixed itself. Now whenever I start my laptop, outlook had to be reinstalled again, Favorites, I put in Internet experor hav