Structure of the place, table 2D, several channels
I do data simultaneously on four-lane acquisition, and I need to store the data acquired from a large table 2D to 16 x 16. To save memory, that I decided to use the structure of the element In Place, I've extended it with four functions of Board Index but I'm struggling with what I put on the right side of the structure.
It is clear that I wire table 2D to all functions of Index table, row and column addresses are constantly evolving and that I have to use shift registers. But how can I tell the LabVIEW I want to modify the same table on multiple channels and do not change 4 different tables?
VI is attached.
Thank you
Kriváň
In place changes just that, in the same place of memory. The same table that you send is what you will get out, modified, even to the same memory addresses.
The 16 x 16 is intended to hold all 4 channels, or one for each? In the former, you can simply extend the Board index to 4 entries and you will get 1 output to your shift register.
In the second case you will need 4-Bay, either in the form of 4 individual tables, add a 3rd dimension to table or do an array of clusters (one for each channel) that contains this little picture of 16 x 16.
/Y
Tags: NI Software
Similar Questions
-
Crash when using table hints with structure of the place
Hello!
I have a problem with structure of the place. I want to index a matrix of waveform (16 items) and when I run or save this labview close...

I have no problem with 15 elements of waveform table or less, but I need to index items 16...

Thanks for your help!

Same 2009 don't crash after adding index up to 20. Thus, it may be a problem with Version 8.5
-
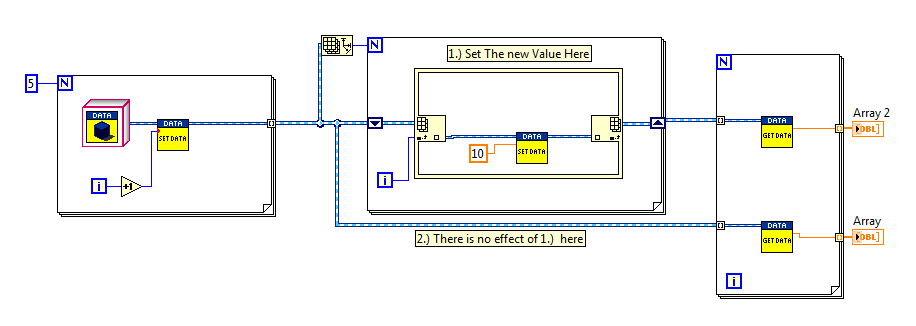
Purpose and structure of the place
Hello!
I need help!
How can I do the following?
1.) set the new value here - make some changes takes effect the entire table, above and are effective for the 2. wire?
I tried to structure of the place without success.
The reason is the reason for which I would like to make is: I want to avoid the always use get - set even when I'm working with objects, typically the array of objects.
so my goal is, how do I don't see only 10 values in the two tables?
-----
My real problem is the following:
I have an array with objects. The order of objects is very important, cannot be changed. I use a battery - algorithm on elements. Randomly to push a lot of elements in the stack and jump randomly. When I pop, I want to use a set method on the object, (some thing/property indicator). So I want this view to be taken into account memory.
(If used an enable simle - indexing in the loop, I would have lost the true order of the original array).
(maybe I can calculate the index of the item that I want to update, but I think that there is an easier alternative to do and I have to use the GET - set again...)
The native implementation of LVOOP is de-val and not of ref.as in most implementations of OOP. If you come from a background of OOP, think like: whenever you plug in a wire, it creates a clone of the object on the thread (or all the objects in the table in your case). As a general rule, this is the desired behavior in about 80% of the cases (when you use a LabVIEW). So consider if you can't do it by using an implementation of val.
There are several falvours enforcement by reference, where you will have the same objects on the two wires:
* private data inside the SEQ (single item queue, not replaced by one that follows)
* private inside DVR (reference data value) data
being inside DVR
which application you choose is up to you. From your image/code, I put the object inside the RECORDER. You could create the DVR with the obj in the first loop. In the secend for loop index your items and International preliminary examination to obtain the obj off the DVR for your get - set operation and place it at the back.
Felix
-
At the same time Record several channels in DAQ
I'm currently configured to play two channels in data acquisition using DAQ Assistant. I wonder what would be the best way to go on the sampling of these channels at the same time, or as close as possible. The vi that I currently use is attached.
Thank you
Sawyer
DAQmx manages the calendar under the hood and does it quite well. If you want to change advanced sync settings you can, but of course, you will have to abandon the DAQ ASSistant and write a LabVIEW code.

I assume you are using a multiplexing card right? The only real solution for true simultaneous sampling is to buy a card that has several a/d converters like the S series cards.
For the second poster: you do not have the same problem as the op. It can be implemented in multiple channels. If you want to help, you must provide further information that "it gives an error.
EDIT: I bet you are trying to use separate tasks for each entry, aren't you. If you do, you'll get a resource conflict error. You must use a SINGLE task and set up several channels in this task to collect more than one signal.
-
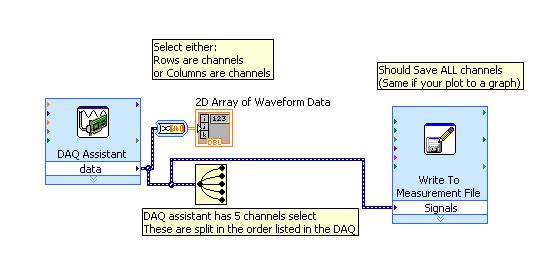
I did separate VI for reading signals from several channels on a map of NI USB-6251. I would like to combine these in a VI VI alone so that they can run that at the same time, however, there is an error if there is more that a single DAQ Assistant in the same--> error-50103 VI was held at DAQmx controls Task.vi:32 (the specified resource is reserved. The operation could not be performed as indicated.)
All the inputs of channel must then be read in with a single DAQ Assistant, but all of the data on different channels are not separated. Can save this data in a matrix or otherwise manageable which allow to facilitate the analysis of the data from the separate channel entries?
I tried to view the data in a file of measures, but then when I tried InPort data, I could all the data I wanted.
Hi AggieGirl,
Good afternoon and I hope that your well today.
First of all, you will not be able to have more than one DAQ Assistant by input analog or analog output task because the device has only one of each. So, you must have a DAQ task to HAVE and AO. (This is not the case for DIO static).
There is far from split signals using the express VI - signal splitter.
When you say you saved this file and it does not work, how it did not work? The Express VI - save a file of measures needed to manage multiple waveforms. Can send you your code & explain more about what was not OK on the file?
Thank you
-
can express us batch relationship XML structure in the database table
Hello
Please help me...
I have a lot of structure of batch XML... .can we express batch relationship XML structure in the database of tha table?
Yes... so how do?
Thank you
Amou
Published by: amu_2007 on March 25, 2010 18:57
Published by: amu_2007 on March 25, 2010 19:03But what is the problem with the original solution, given that divides the XML into the data?
I mean you could do something like that?
SQL> create table batch (customer VARCHAR2(10) 2 ,cust_name VARCHAR2(10) 3 ,cust_type VARCHAR2(10) 4 ) 5 / Table created. SQL> SQL> create table section (customer VARCHAR2(10) 2 ,sect_name VARCHAR2(10) 3 ,sect_depend VARCHAR2(10) 4 ) 5 / Table created. SQL> create table job_sections (customer VARCHAR2(10) 2 ,sect_name VARCHAR2(10) 3 ,job_sect_name VARCHAR2(10) 4 ,job_sect_depend VARCHAR2(10) 5 ) 6 / Table created. SQL> create table job (customer VARCHAR2(10) 2 ,sect_name VARCHAR2(10) 3 ,job_sect_name VARCHAR2(10) 4 ,job_type VARCHAR2(10) 5 ,job_sub_type VARCHAR2(10) 6 ,job_depend VARCHAR2(10) 7 ) 8 / Table created. SQL> SQL> SQL> insert all 2 when batch_rn = 1 then 3 into batch (customer, cust_name, cust_type) values (customer, cust_name, cust_type) 4 when section_rn = 1 then 5 into section (customer, sect_name, sect_depend) values (customer, sect_name, sect_dependency) 6 when job_sections_rn = 1 then 7 into job_sections (customer, sect_name, job_sect_name, job_sect_depend) values (customer, sect_name, job_sect_name, job_sect_dependency) 8 when 1=1 then 9 into job (customer, sect_name, job_sect_name, job_type, job_sub_type, job_depend) values (customer, sect_name, job_sect_name, job_type, jo 10 -- 11 WITH t as (select XMLTYPE(' 1213 46 ') as xml from dual) 47 -- 48 -- END OF TEST DATA 49 -- 50 ,flat as (select a.customer, a.cust_name, a.cust_type 51 ,b.sect_name, NULLIF(b.sect_dependency,'NULL') as sect_dependency 52 ,c.job_sect_name, NULLIF(c.job_sect_dependency,'NULL') as job_sect_dependency 53 ,d.job_type, d.job_sub_type, NULLIF(d.job_dependency,'NULL') as job_dependency 54 from t 55 ,XMLTABLE('/BATCH' 56 PASSING t.xml 57 COLUMNS customer VARCHAR2(10) PATH '/BATCH/@customer' 58 ,cust_name VARCHAR2(10) PATH '/BATCH/@name' 59 ,cust_type VARCHAR2(10) PATH '/BATCH/@type' 60 ,bat_sections XMLTYPE PATH '/BATCH/BATCH_SECTIONS' 61 ) a 62 ,XMLTABLE('/BATCH_SECTIONS/SECTION' 63 PASSING a.bat_sections 64 COLUMNS sect_name VARCHAR2(10) PATH '/SECTION/@name' 65 ,sect_dependency VARCHAR2(10) PATH '/SECTION/@dependency' 66 ,section XMLTYPE PATH '/SECTION' 67 ) b 68 ,XMLTABLE('/SECTION/JOB_SECTIONS' 69 PASSING b.section 70 COLUMNS job_sect_name VARCHAR2(10) PATH '/JOB_SECTIONS/@name' 71 ,job_sect_dependency VARCHAR2(10) PATH '/JOB_SECTIONS/@dependency' 72 ,job_sections XMLTYPE PATH '/JOB_SECTIONS' 73 ) c 74 ,XMLTABLE('/JOB_SECTIONS/JOBS/JOB' 75 PASSING c.job_sections 76 COLUMNS job_type VARCHAR2(10) PATH '/JOB/@type' 77 ,job_sub_type VARCHAR2(10) PATH '/JOB/@sub_type' 78 ,job_dependency VARCHAR2(10) PATH '/JOB/@dependency' 79 ) d 80 ) 81 -- 82 select customer, cust_name, cust_type, sect_name, sect_dependency, job_sect_name, job_sect_dependency, job_type, job_sub_type, job_dependency 83 ,row_number() over (partition by customer order by 1) as batch_rn 84 ,row_number() over (partition by customer, sect_name order by 1) as section_rn 85 ,row_number() over (partition by customer, sect_name, job_sect_name order by 1) as job_sections_rn 86 from flat 87 / 16 rows created. SQL> select * from batch; CUSTOMER CUST_NAME CUST_TYPE ---------- ---------- ---------- ABC ABC1 ABC_TYPE SQL> select * from section; CUSTOMER SECT_NAME SECT_DEPEN ---------- ---------- ---------- ABC X ABC Y X ABC Z Y SQL> select * from job_sections; CUSTOMER SECT_NAME JOB_SECT_N JOB_SECT_D ---------- ---------- ---------- ---------- ABC X JOB1 ABC Y JOB2 X ABC Z JOB3 ABC Z JOB4 SQL> select * from job; CUSTOMER SECT_NAME JOB_SECT_N JOB_TYPE JOB_SUB_TY JOB_DEPEND ---------- ---------- ---------- ---------- ---------- ---------- ABC X JOB1 X xx ABC X JOB1 X yy ABC X JOB1 X zz ABC Y JOB2 Y xx X ABC Y JOB2 Y yy X ABC Y JOB2 Y zz X ABC Z JOB3 ..... .... ABC Z JOB4 .... .... 8 rows selected. SQL>14 4515 2316 2217 2118 19 20 24 3225 3126 3027 28 29 33 4434 3835 3736 39 4340 4241 But it would depend on what you are really after regarding primary keys and relationships between the tables etc.
I would like to put this just for you...
H1. . If YOU PROVE to THE United States THAT OUTPUT you NEED, WE cannot GIVE YOU AN ANSWER
-
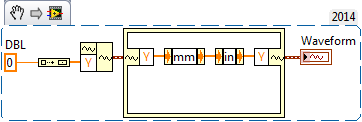
structure of the place of waveform convert units
How can I get the conversion units to work within a Structure in Place item to add elements of waveform Unbundle/Bundle. He said: 'you have connected the digital data types that have incompatible units.
Share your code please.
-
Sequential execution of the structure of the event?
Greetings,
I'm at the very beginning of the development of applications. I have a list of 10 tests (we just call test 1 test 10). I would (ideally) for a user to have the option of selecting 1 or even 10 tests, any combination basically (listbox, it was what I thought). Now the kicker is, I want a structure of event related to this list box. And run each index table selected by the user. So if the user must select test 1, test 2 and test 6, I had received a table of 0, 1, and 5, respectively. The structure of the event should run sequentially as a result. Right now I plan each event at the outbreak would run a state machine for the test itself. So if test 1 was a simple test of current draw (just for example). The user would choose 1 Test that raises the corresponding event. The event inside a state machine would execute the necessary market, TAKE the MEASURE of CURRENT, STOP says finally.
I've tried my hand at a cluster with Boolean values, but did not too far. Even though I know there is a solution somewhere within the cluster and the binder for Boolean types inside for the value change. But I need allow the user time to choose all the tests to run before launching the sequential execution of the structure of the event.
I'm sorry if I missed something, I am still drinking my coffee Sunday
 I do not have a VI to post. I tried yesterday with no luck and the best test I had too many nested loops.
I do not have a VI to post. I tried yesterday with no luck and the best test I had too many nested loops.Thanks in advance for any help in this matter. I feel I've hit a moment "DUH" in the development process. But I find it difficult to set up a structure of the event to run several events in the event generated by 1 user.
-Chazzzmd
-
logical AND with the structure of the event
Hello world
The structure of the event can manage several events at once to do the same thing: looks like an OR logical operator. But I have not found a way to sequence events to approach a logic and example: you must click on a button to draw, then enter the image would change the mouse cursor. With a structure of the event, I can handle these 2 events separately or together (i.e. change the cursor), but I can't do a sequence of events.
Is this possible to do with a structure of the event?
I hope that I am clear (sorry for English btw). And thanks in advance.
Christophe
I don't think this is possible directly. You will need to add status information to your event loop that could enforce the order of events and the rules of logic you want. Where transformation you would have to check whether the required event has occurred before this event. If that were the case, perform your treatment. If this isn't the case, ignore the event. Your first event would need set this status information. You can also include some kind of time-out for the second event were to occur within a specific period.
This type of logic may be better treated with the help of producer/consumer architecture and a state machine in the task of the consumer.
-
Since data is stored outdoors, and the definition that is stored inside, it means that a the table structure of the outer table is stored in the database as well (or a virtual table based on the definition of the external table...)
I'll hit the ORA-DOCS again once, back in the external tables read tonight on them 2 or 3 sources and it is not quite clear whether real data with structure exists outside the database or an internal table set (and stored) retrieves data from an outside source.
Since data is stored outdoors, and the definition that is stored inside, it means that a the table structure of the outer table is stored in the database as well (or a virtual table based on the definition of the external table...)
The 'definition' you refer to IS the structure of the table; they are one and the same. There is no 'table' stored in the database using space or storage. When a query on an external table is executed, the data source is read.
I'll be hitting the ORA-DOCS up again, just got back into external tables tonight reading up on them from 2-3 sources and it is not quite clear if an actual data with structure exists out of the database , or an internally defined (and stored?) table draws data from an outside source.
I suggest you that start with the documentation of Oracle - including the ground provided the link to:
If any "metadata" are stored outside the database depends on if the file that is outside of the database was produced by Oracle using the robot UNLOADING discussed in this doc
Unloading of data using ORACLE_DATAPUMP Access driver
To unload data, you use the
ORACLE_DATAPUMPdriver access. The stream that is discharged is in a proprietary format and contains all of the data column for each row being unloaded.A discharge operation also creates a stream of metadata that describes the content of the data stream. The information in the metadata stream are required to load the stream. Therefore, the metadata stream is written to the file data and placed before the data stream.
If YOU provide data/files, then you MUST provide it in the format expected by the external table statement. You can, if you wish, use a preprocessor to convert ANY file (zip, encrypted, etc.) in the required format.
For YOUR files, you can the metadata stored in the same file, or elsewhere, if you choose, but Oracle will have NO knowledge of this fact and not will NOT be involved in the transformation or read any of the metadata that you provide. Your preprocessor must remove all these metadata and ONLY provide data in the format appropriate for Oracle to use.
If the file was produced by the process of UNLOADING Oracle then it will include metadata that Oracle WILL read, use, and remove as says this quote from doc above. These external metadata is added to the real external table definintion/metadata stored in the dictionary.
-
mutation in the triggers table problem (need to COUNT (col) and MAX (col) of table shot)
I was looking for the solution and find many examples, but I do not know what is the best in my option and don't understand everything.
I realized that can't do a SELECT query in the table where trigger is triggered. But I have need SELECT COUNT (col), then MAX (id) of this table, update some statistical info...
And also need to row id update, so I can't do trigger of table instead of relaxation of the line.So this is my TRIGGER:
create or replace
update_stat relaxation
AFTER UPDATE ON TABLE1 TO EACH LINE
DECLARE
juice FLOAT;
all the NUMBER;
end NUMBER;
BEGIN
IF (: old.ended <>: new.ended) THEN
SELECT COUNT (id) FROM end FROM table1 WHERE fk_table2 = new.fk_table2 AND finished = 1; -Error in the table of mutation
SELECT COUNT (id) FROM everything FROM table1 WHERE fk_table2 = new.fk_table2; -Error in the table of mutation
Juice: = ((end /all) * 100);
UPDATE table2 SET suc = success WHERE id =:new.fk_table2;
END IF;
END;
I also tried with
pragma autonomous_transaction;trigger body....ANDcommit;But don't working right when insert more records.Thanks, UrbanData and structure of the example table
SQL> create table table2 2 ( 3 id integer 4 , success number 5 , constraint table2_pk primary key (id) 6 ); Table created. SQL> create table table1 2 ( 3 id integer 4 , id_t2 integer 5 , ended integer 6 , constraint table1_pk primary key (id) 7 , constraint table1_fk_id_t2 foreign key (id_t2) references table2 8 ); Table created. SQL> insert into table2(id, success) values (1, 0); 1 row created. SQL> insert into table2(id, success) values (2, 0); 1 row created. SQL> insert into table1 2 ( 3 id 4 , id_t2 5 , ended 6 ) 7 select level 8 , ceil(level/10) 9 , 0 10 from dual 11 connect by level <= 20; 20 rows created. SQL> commit; Commit complete.
Create objects to the suite
create or replace type update_stat_obj as object (id integer, id_t2 integer, ended integer) / create or replace type update_stat_tbl as table of update_stat_obj / create or replace package update_stat_pkg as g_table_1 update_stat_tbl; procedure load(p_id integer, p_id_t2 integer, p_ended integer); procedure updt; end; / show err create or replace package body update_stat_pkg as procedure load(p_id integer, p_id_t2 integer, p_ended integer) is begin if g_table_1 is null then g_table_1 := update_stat_tbl(); end if; g_table_1.extend; g_table_1(g_table_1.count) := update_stat_obj(p_id, p_id_t2, p_ended); end; procedure updt is begin merge into table2 t2 using ( select t1.id_t2 , (count(t2.id)/count(t1.id))*100 success from table1 t1 left join table(g_table_1) t2 on t1.id = t2.id and t2.ended = 1 group by t1.id_t2 ) t1 on (t2.id = t1.id_t2) when matched then update set t2.success = t1.success; g_table_1 := null; end; end; / show err create or replace trigger update_stat_row_trig after update on table1 for each row begin if (:old.ended <> :new.ended) then update_stat_pkg.load(:new.id, :new.id_t2, :new.ended); end if; end; / show err create or replace trigger update_stat_trig after update on table1 begin update_stat_pkg.updt; end; / show errNow look for the UPDATE.
SQL> select * from table1; ID ID_T2 ENDED ---------- ---------- ---------- 1 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 1 0 7 1 0 8 1 0 9 1 0 10 1 0 11 2 0 12 2 0 13 2 0 14 2 0 15 2 0 16 2 0 17 2 0 18 2 0 19 2 0 20 2 0 20 rows selected. SQL> select * from table2; ID SUCCESS ---------- ---------- 1 0 2 0 SQL> update table1 set ended = 1 where id between 1 and 7 or id between 11 and 19; 16 rows updated. SQL> select * from table2; ID SUCCESS ---------- ---------- 1 70 2 90 SQL> select * from table1; ID ID_T2 ENDED ---------- ---------- ---------- 1 1 1 2 1 1 3 1 1 4 1 1 5 1 1 6 1 1 7 1 1 8 1 0 9 1 0 10 1 0 11 2 1 12 2 1 13 2 1 14 2 1 15 2 1 16 2 1 17 2 1 18 2 1 19 2 1 20 2 0 20 rows selected. -
MV for replication. No PK in the source table and the LOB column
I would like to replicate tables between 2 instances in 2 different hosts. Mixed 11 GR 1 material and Oracle 10 g 2. I have my doubts:
1. some tables from the source is not PK, and I understand that MV with rowid is not supported. Is there no workaround known workaround on this case without changing the structure of the source table? Full/complete update is acceptable.
2 one of the table has the CLOB data type. Can I just ignore this column in MV? A known issue with this kind of approach?#1. You must use WITH ROWID MV and I believe it is supported up to the latest version, unless you can find any document, please give me the code of Notes.
#2. CLOB column is supported in MV, so no need to jump. -
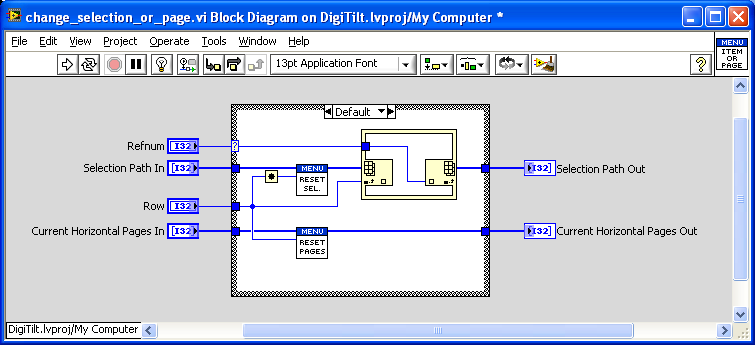
In place the structure with replacement of table element uses wrong index
Hello
I use the place in structure of elements and notice any strange behavior: if I replace elements in a Subvi and then calling VI, the index is off by one calling VI, most of the time. I saw one or two tracks where the index was correct. Searching for the forums have provided other problems with in place it the structure but not exactly it.
Attached are a couple of screws demonstrating the problem and some screenshots.
It seems that you have a problem of optimization of LabVIEW. It seems that the value of the line is get incremented in your Subvi and that it is somehow going to the main VI. If you always put a copy in your reset_selections.vi call, I was not able to get the error to occur. There was a couple of bugs similar to this one.
You can always add another copy in front of the call to reset_pages.vi, but I never had the problem to occur without it.
I have attached the modified so VI.
-
Dynamic data of several channels in table, then save in Excel
Hello
I am acquiring data from several channels (4-5) and I'd like to collect samples at low rates (10 Hz for 3 minutes max). For various reasons I use Dynamic Data type, although I know that it is not the best way (some say it is a wrong data type
). I also want to save data to a file (the best option would be data excel file).If I acquire data 10 times per second, it is quite slow to save in excel (this is the slowest option of all types of data). So I would like to fill a table or matrix of acquired data and then write Excel file (I use scripture to measure file). But I don't know how to do - if I convert DDT in DBL, build an array and connect it to change registry, it works but I lose the information in column names and I'm wasting time. If I connect to build the table a DDT and then shift record another, it returns the table 1 d of DDT. I would like to have 2D DDT, which collects all the information loop. Is there a suggestion how to solve?
I'm sure it would be easier solved my problem with the double data type but I also use select signals VI which is the VI I am not able to replace at this time.
Good day
Lefebvre
I don't know if there is a question here, or what. Doing what you say you want to make, acquire the data of 4-5 channels at low rates (10 Hz for 3 minutes) and save the data in an Excel file (I assume you mean really Excel, i.e. a file with the extension .xls or .xlsx) is really a very easy thing to do in LabVIEW, especially if you are not using :
- DAQ Assistant
- Dynamic Data
- Write to the action file.
Indeed, you seem to realize this, but I guess you want to 'do the hard', in any case.
Good luck.
Bob Schor
-
Hello!
I tried to build a trigger that triggers a true value each 1000 milliseconds (from the first real);
which real command structure box to a value of the randomNrGen of the sample and place it in a table.
but I would like to USE this table and I can't do this beacause I can not get out of the structure of the case.
AND:
the while loop ignores samples; If you run the vi and look at the speed at which the table fills, ypu notice it is not periodic: the first few items are inserted at 1 second interval, but then it jumps one;
would it be because of the wait time 1ms?
1. How can I create a structure that does this:
If set to True, it samples a value from Genesis at random and places it in the table
OTHERWISE, it does NOTHING, without zeros sent to the table just waiting for the next true and only the values sampled at True remain in the table?
2. How can I stop it pop samples (multiples of 1000 in my case)?
In conclusion: I need to be able to take samples on the sample generator and store them in an array of 3d in a zig - zag (1.jpg) way, but able to think about it, we need to go beyond these two questions.
Please ignore the meter.
Please help me!
TibiG wrote:
Thanks, Crossrulz!
This did not omit all values and it works fine.
Is it possible to get information in a case without making use of the large loop?
My program will become very complex (I need to synchronize a magnetometer and a stepper motor to make a 3d map of the magnetic field of the magnet) and I want to do everything as simple as possible.
If there is a way to get information about a case structure, other tnan using registers with shift on the big loop, and you know it, please show me.
Thank you!
You could also use a Feedback node, just keep it out of the structure of the case.
Maybe you are looking for
-
can't the configuration of firefox when come configa: on the URL line
After I enter: config in the URL bar to access configuration and change engine default searc to "google i'm feeling lucky." Firefox answers URL invalid or cannot be found; I want to change my default URL to google engine, don't want to see 'bing' b/c
-
How do you create the recovery with Yoga 13 disc?
With all the computers I bought, I had made or received recovery disks. I have read the forums here and found that I can make a windows image (what I did) and how to use the OneKey to make a backup. My concern is after I am out of warranty and the ha
-
How to stop hotmail auto consignment with my password please?
As above. for some reason, than what is happening. I recently downloaded Windows Live Messenger. Thank you.
-
This poping up on my computer the instruction at '0x5ff3cbc2' referenced memory '0x00148cca '.
This poping up on my computer the instruction at '0x5ff3cbc2' referenced memory '0x00148cca '.
-
Hello! When I view the jpgs like 'ICONS AVERAGES' they look fine, but when I select "LARGE" or "EXTRA LARGE" some of the Corrèze of distorted images. Any ideas please?