the composite index question
If I have to create a composite index, why should we put the most selective column first?Suppose I have a table T that has columns C1, C2, C3, C4...
Suppose I have a composite index on C1, C2 and my queries always contain the C1 and C2 in the WHERE clause.
Suppose that C1 is more selective than C2.
Why should the order of 2 columns in the index, C1, C2 and C2, C1?
Is not the same height?
Or oracle is able to store the values of C2 directly inside the leaves, save a branch?
Claire wrote:
If I have to create a composite index, why should we put the most selective column first?Suppose I have a table T that has columns C1, C2, C3, C4...
Suppose I have a composite index on C1, C2 and my queries always contain the C1 and C2 in the WHERE clause.Suppose that C1 is more selective than C2.
Why should the order of 2 columns in the index, C1, C2 and C2, C1?
Is not the same height?
Or oracle is able to store the values of C2 directly inside the leaves, save a branch?
The order of the columns can make a difference.
Select * from T where C1 =: C1 and C2 =: C2;
Select * from T where C1 =: C1;
In above cases if you have a composite index as C1, C2 then this index would be better.
And
Select * from T where C2 =: C2 and C1 =: C1;
Select * from T where C2 =: C2;
Thus, the order of the columns in your index depends on HOW YOUR QUERIES are written. Nothing
another (selectivity of a or b are not at all)
Source - the author himself. http://asktom.Oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:5671539468597
Tags: Database
Similar Questions
-
Question on the composite index and index skip scan
Hello
I have a confusion.
I read the post of Burleson on the column of the composite index command (http://www.dba-oracle.com/t_composite_index_multi_column_ordering.htm) where he writes that
«.. . for composite indexes the most restrictive value of the column (the column with the highest unique values) should be made first to cut down the result set in... »
But 10g performance tuning book tells the subject INDEX SKIP SCAN:
"... Index scan Skip allows a composite index that is logically divided into smaller subindex. In Dumpster
scanning, the first column in the composite index is not specified in the query. In other words, it is ignored.
The number of logic subindex is determined by the number of distinct values in the first column.
Skip scanning is advantageous if there are few distinct values in the main column of the composite index and many distinct values in the key do not tip of the index... »
If design us a composite index according to what said Burleson, then how can we take advantage of index skip scan. These two staements to oppose each other, Don't they?
Can someone explain this?Even if you're not skip scanning, it is best to put the column with less distinct values in the main column of the index.
If a query specifies two key as predicates of equality columns, it doesn't really matter how columns are sorted in the index.
If a query specifies a range on a key column, it is most likely on the second column of the index.BTW, sometimes even a column 3 or the index of the column 4 is useful. In order to not restrict simply yourself in 2 columns. However, do not create too many clues - especially if there is overlap between the index.
Hemant K Collette
-
need advice on the composite index...
Hello
I created 2 indexes on 2 columns as prescription.
CREATE INDEX IDX_COMP_1 ON EMP (SAL, HIREDATE)
CREATE INDEX IDX_COMP_2 ON EMP (HIREDATE, SAL)
DELETE FROM PLAN_TABLE;
EXPLAIN PLAN FOR SELECT * FROM EMP WHERE SAL = 5000;
EXPLAIN PLAN FOR SELECT * FROM EMP WHERE HIREDATE = 17 NOVEMBER 1981 ';
EXPLAIN PLAN for SELECT * FROM EMP WHERE HIREDATE = December 3, 1981 ' and SAL = 950;
EXPLAIN PLAN for SELECT * FROM EMP WHERE SAL = 3000 and DATERECRUTEMENT = December 3, 1981 '.
SELECT P.PLAN_ID, P.TIMESTAMP, P.OPERATION, P.OPTIONS, P.OBJECT_NAME, P.OBJECT_TYPE, P.ACCESS_PREDICATES, P.OPTIMIZER, P.CPU_COST
FROM PLAN_TABLE P BY 1.2;
o/p-
THE ARGUMENT PLAN_ID TIMESTAMP OPERATION OPTIONS OBJECT_NAME OBJECT_TYPE ACCESS_PREDICATES OPTIMIZER CPU_COST
1 131 9/12 / 2011 22:24:12 SELECT STATEMENT ALL_ROWS 8461
2 131 9/12 / 2011 22:24:12 TABLE ACCESS BY INDEX ROWID EMP ANALYSIS 8461
3 131 9/12 / 2011 22:24:12 INDEX INDEX UNIQUE SCAN (SINGLE) 'EMPNO' PK_EMP = 1050 ANALYSED 7788
4 132 9/12 / 2011 22:24:12 SELECT STATEMENT ALL_ROWS 15223
5 132 9/12 / 2011 22:24:12 TABLE ACCESS BY INDEX ROWID EMP TABLE ANALYSIS 15223
132 9/12 6 / 2011 22:24:12 INDEX RANGE SCAN IDX_COMP_1 INDEX "SAL" = 5000 7521 ANALYSED
7 133 9/12 / 2011 22:24:12 SELECT STATEMENT ALL_ROWS 15223
133 9/12 8 / 2011 22:24:12 TABLE ACCESS BY INDEX ROWID EMP TABLE ANALYSIS 15223
133 9/12 9 / 2011 22:24:12 INDEX RANGE SCAN IDX_COMP_2 INDEX "HIREDATE" = 17 NOVEMBER 1981 ' 7521 ANALYSED
134 9/12 10 / 2011 22:24:12 SELECT STATEMENT ALL_ROWS 14733
134 9/12 11 / 2011 22:24:12 TABLE ACCESS BY INDEX ROWID EMP TABLE ANALYSIS 14733
12 134 9/12 / 2011 22:24:12 INDEX RANGE SCAN IDX_COMP_1 INDEX "SAL" = 950 AND "HIREDATE" = 3 DECEMBER 1981 ' 7321 ANALYSED
13 135 9/12 / 2011 22:24:12 SELECT STATEMENT ALL_ROWS 14733
14 135 9/12 / 2011 22:24:12 TABLE ACCESS BY INDEX ROWID EMP TABLE ANALYSIS 14733
15 135 9/12 / 2011 22:24:12 INDEX RANGE SCAN INDEX "SAL" = 3000 IDX_COMP_1 AND "HIREDATE" = 3 DECEMBER 1981 ' 7321 ANALYSED
Here, I need to know that in the query no 3.4...
(1) why oracle chose "IDX_COMP_1" in both cases, why not IDX_COMP_2?
(2) how oracle decide what indexes should be chosen that I created IDX_COMP_1 & IDX_COMP_2 on the two single column order is different.
(3) in the case of a composite key, is there any logic order also know if I created composite on col1, col2, col3, but in which clause I m help col2, then what will be the behavior of oracle to use index.
Any other information to anyone about all the above will be good for me...
thnx... PCHere, I need to know that in the query no 3.4...
(1) why oracle chose "IDX_COMP_1" in both cases, why not IDX_COMP_2?
(2) how oracle decide what indexes should be chosen that I created IDX_COMP_1 & IDX_COMP_2 on the two single column order is different.
(3) in the case of a composite key, is there any logic order also know if I created composite on col1, col2, col3, but in which clause I m help col2, then what will be the behavior of oracle to use index.Hello
This is what the CBO. Takes the lowest cost to build your execution plan.Everything depends on your data and the asymmetric nature of it. When collect you statistics, the CBO will decide which is a better path to take, what index to use, etc...
Order in the index composite shud be such that the column with the most distinct values should come first...
Kind regards
RizwanPublished by: Rizwan Sep 12, 2011 22:03
-
Index on the Composite key to solve enq: TM - contention
Version: Oracle 10g
Hello
I had enq: TM - restraints in my database, and I want to apply the index on the foreign key of one of the table column.
But I see there are composite foreign keys and foreign keys unique in the table.
Only foreign key I can easily create the index, but my doubt is that, for a composite foreign key,.
Do I need to create the composite indexes on each column of the composite key or composite foreign key columns, I have to apply clue to solve the enq: TM - restraints question.
For example: I have a foreign key below
"FK_RECONDATA_DRIVER" CONSTRAINT FOREIGN KEY ('NRT', 'DADDRESSTYPE', 'DADDRESSNR') REFERENCES 'COL '. "" TURN ON THE FAZGFUEHRER ' ('NRT', 'ANSCHTYP', 'ANSCHNR'), "FK_RECONDATA_PRODUCT' FOREIGN KEY ('NRT',"PRODUCTNR") CONSTRAINT REFERENCES 'COL '. "" ENABLE SORT "("FNR","SORTENNR") Here the column FNR is common in both the foreign key.
Please help me find how to create indexes on these columns.
An index defined as ind_fk (a, b, c, e, f) will cover (1) (a) FK and FK (a, b, c).
It however will not cover FK(a,e,f) because it does not start by all the columns of the FK.
You must create an additional index that begin with (a, e, f).
Best regards
Mohamed Houri
-
index composite index of single column vs?
I just wonder what are the differences between the following?
create table (test)
person_id number
name varchar2 (50).
name varchar2 (50)
);
create index my_indx on test (name);
create index my_indx2 on test (family name);
OR
create index my_indx3 on test (name, first name);
OR
create index my_indx4 on test (name, name);
What are the differences between these three index?
When to create full name in same (composite index) columns in order to scan of systematic index should I use two of them in the where clause?
My last question is, is the order for the composite index?
Thanks in advance.
Hello
the difference between the 3 case is quite simple:
(1) on the first and last name predicates can be solved through scan of the index systematic range
(2) predicates on name can be solved through systematic index scan range, predicates on names can only use indexes skip scan (which is about NDV (name) times less efficient than a scan of normal range, where NDV (name) is the number of distinct values in the name column)
((3) same as 2) with swapped name
(Not that if a query involves both a name and a surname, then box 1) would have to choose between a scan interval index 'fat' and a join of the index. (Anyway it's going to be more expensive than 2) or 3) (who are going to be just as effective in this case).
Best regards
Nikolai
-
A developer has asked an interesting question today, if we have an index on Column1 and delete us the index and create a new index on Column1, Column2 there will be a problem with queries that previously used the single column index, not using the composite index?
My first reaction was there might be, nobody knows conditions where it is likely to lead to changes in query plans, I guess there may be some problems with queries that join on Column1, but I have problems to come with a test case to prove.
ChrisExpect applications to use the new index as Column1 is the leading column of the index.
However, because the index key is now bigger and different, leaf_blocks to the index increase.
This can affect the cost of an Index Range Scan and Oracle can, in some cases, according to the cardinality expected, stop using the index.Clustering_Factor change also, and this, too, may influence the optimizer.
Because the index is two columns together, even if you need to query only the first column, Oracle is unable to 'split' the element for leaf_blocks or clustering_factor for a column only.
OTOH, distinct_keys could improve if it helps to take the direction using the index.
I guess that the biggest impact (IE, do not use the index) would be if a single-column index became an index column 3 or 4, or added or columns are very large keys, a rise in the number of leaf_blocks considerably.
Hemant K Collette
http://hemantoracledba.blogspot.com -
Question about the composition settings and make
I looked for an answer to my question, but had to ask at resort, sorry, it's pretty basic, but a direct response is needed I think.
I imported a project in Premiere pro with two layers of still images with movement and applied effects. I work for a few weeks now, with variations on these pictures and had many number of exports of EI through the render queue.
After you import the compositions of first CC my starting point; composition and other settings of composition parameters are all resolved HDTV 1080 25 but the set resolution in which I unfortunately now has, is defined as 'Half' (960 * 540)... New compositions also sets the default resolution somehow half...
My question is about my previous exports and subsequently. Together of the composition to "Half" resolution affect the quality of my compositions exported using the render module? So far, all my renders are 1080 p by default and no 960 * 540. These have been uprezed to 1080 of 960? ... - I have not changed any setting on the resolution in the rendering module - they all came out 1080 after.
Thank you
Together of the composition to "Half" resolution affect the quality of my compositions exported using the render module?
N ° except if you change the settings of default rendering, which is "Best settings" in "current Configuration".
-
the question of the overall index was updated
I have a partitioned table and the local partitioned indexes in 9i. In the past, when I add a new partition, partitioned indexes have become "unusable" so I have to rebuild the index to the "exploitable": State
ALTER INDEX REBUILD PARTITION myindex TYPE my_partition nologging;
I just found out that when you use the clause to UPDATE GLOBAL INDEXES, there is no need to rebuild the local index in the underlying table. It seems that updating the GLOBAL INDEX also update local index to the status of "exploitable".
create tablespace you see
ALTER TABLE my_table SPLIT PARTITION of VALUES 'TYPE_DEFAULT' ('new') INTO (PARTITION "TYPE_NEW" TABLESPACE "you see", "TYPE_DEFAULT" PARTITION) UPDATE GLOBAL INDEXES;
I wonder if UPDATE GLOBAL INDEXES also update local indexes as it appears in this case. I thought that the UPDATE GLOBAL INDEXES only updated global index.
Published by: user7435395 on March 8, 2013 14:33
Published by: user7435395 on March 8, 2013 14:36
Published by: user7435395 on March 8, 2013 15:15>
I just found out that when you use the clause to UPDATE GLOBAL INDEXES, there is no need to rebuild the local index in the underlying table. It seems that updating the GLOBAL INDEX also update local index to the status of "exploitable".
>
Interesting! Can you post the DDL that you use for the table and index, so we can try to reproduce it?This seems to contradict what said documentation, but that would not be something new.
See "Split of Partitions" in the Guide DBA 9i
http://docs.Oracle.com/CD/B10501_01/server.920/a96521/partiti.htm#6736
>
Behavior of the indexRegular (TAS)
Oracle UNUSABLE brand new partitions (there are two) in each local index.Unless you specify GLOBAL INDEXES to UPDATE, all index global, or all partitions of global partitioned indexes are marked UNUSABLE and must be rebuilt
>
Also you not "add" a partition you split one and creates two new partitions, which both can have data. These two partitions of the local index must be rebuilt.When you "add" a partition it lacks all the data so there is not need to rebuild the local index for this 'new' partition.
-
Find the exact index of maximum PNo() local and ChnFind() seem to be problematic
Good day to all experts DIAdem!
I am after some help and wonder if what I intend to do is possible, as much as tiara fucntions are concerned.
I have a few cyclical data (continuous acquired as a set of data), which I am able to identify individual events. Within each of these events, I use the StatBlockCalc, so calculate the minimum and maximum local power (in the range of the specified index). I would then use the calculated maximum, a specific channel, then 'read' effective competition on other channels.
I tried to use the ChnFind and PNo and both give results that often fall beyond the top and bottom of the index for this event. I believe that this is due to the fact that these search functions for a nearest value of the value in question and NOT the exact value for (rounding errors may also play a role). Please note this is not a criticism of the functions, because I believe that what I am asking is perhaps more by the high-performance computing (as opposed to hunting for the nearest value).
So my question is - this feasible? To calculate a local maximum, and then use this value index reading on the remaining channels (to determine the values to the maximum).
I hope that what I am asking is clear, if not so, feel free to ask away.
Kind regards
Dan
Hi Dan,.
If you want to attack this from the rounded side error, then I suggest to insert the ValEqual() function in your search expression - it has been designed to avoid rounding problems you seem like you're running. My other recommendataion would be to abandon PNo() and use instead of ChnFind() with the known since your window index the starting index. This action runs more quickly and find the extremum of right.
Brad Turpin
Tiara Product Support Engineer
National Instruments
-
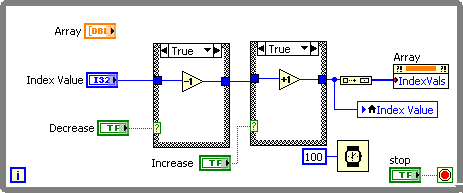
Can I use a digital control to change the illustrated index of an array?
Hey people,
This could be one of these questions, get feedback 'why would you do?', but I wonder if there is a fairly simple solution, I don't know everything...
I know that tables are not exactly gems when it comes to claims for benefits, but with my particular application, if I could get a digital control to define what the array index appears, it would be great. In addition, assuming that it is possible, then I think I could find a way to have two Boolean values which would increment/decrement the element indicated by updating the digital too...
Any ideas?
A popular entry!
THX
Is that what you wanted to achieve
-
Hello
I have a loop 'for' which can take different number of iterations according to the number of measures that the user wants to do.
Inside this loop, I'm auto-indexation four different 1 d arrays. This means that the size of the tables will be different in the different phases of the execution of the program (the size will equal the number of measures).
My question is: the auto-indexation of the tables with different sizes will affect the performance of the program? I think it slows down my Vi...
Thank you very much.
My first thought is that the compiler to the LabVIEW actually removes the Matlab node because the outputs are not used. Once you son upward, LabVIEW must then call Matlab and wait for it to run. I know from experience, the call of Matlab to run the script is SLOW. I also recommend to do the math in native LabVIEW.
-
When you use the search for a window, the files are not listed in the search index
Original title: question of Windows search
When you use windows search, records that are not not in the search index are searced. Why?
Hello
1. What is the operating system installed on your computer?
2 are there any changes made recently to the computer?
Improve Windows searches using the index: frequently asked questions: http://windows.microsoft.com/en-US/windows7/Improve-Windows-searches-using-the-index-frequently-asked-questions
You can also check:
Reconstruction of Index of Microsoft Windows 7 search: http://windows.microsoft.com/en-US/windows7/Change-advanced-indexing-options
Advanced Tips for searching in Windows
http://Windows.Microsoft.com/en-us/Windows7/advanced-tips-for-searching-in-Windows
I hope this helps.
-
ListField Get focused on the row Index
Hello
I implemented a custom ListField.
I'm looking for a way that I can get the index of the target line.
For example, if my ListField contains 10 line and line 2 number concentrates (marked in blue), I want to receive the row index.
Thank you!
I'm sorry, I'm mixed messages here. In your last post, you said this:
"... and then try to scroll down once more, the last item is projected to"separate ":
Maybe I'm just stupid, but I have no idea what it means. And it sounded like it's your problem.
Nevertheless, my logic goes like this. There should be no problem to find a ListField index. So if you have problems, then the question is in your code. You tried to explain it and I'm sorry, I don't get it. So instead of you trying to explain it, I suggest that you give us a piece of code that we can test, which illustrates the problem. Who will save trying to explain it and means that if we find a solution we can actually give you the code to fix it. To me, that seems the best way to solve this problem for all parties involved.
If you create a sample screen with a single ListField on it and allows you to demonstrate your problem? Then validate the code here so that we can try ourselves?
-
Windows 7 Search index does not maintain the sites indexed
My search indexer is not indexed parameters locations I do and after a day or two, he returns to the original setting whicgh was the Start Menu. I changed the indexed locations to include most of my C drive, and it indexes all (the search function works well for awhile) but a day or two later, when I do a search, nothing comes. I double-check the settings and find that it has been restored to the original indexed locations.
My system is updated regularly and I'm using Avast antivirus.
Thank you
Hi TomHathcoat,
Thanks for posting in the Microsoft Community.
I understand that you are facing the question with an indexer search does not maintain the indexed locations.
Method 1:
I suggest you run the troubleshooter and check if this solves the problem. See the following article to do the same thing.
Open the troubleshooter of search and indexing.
http://Windows.Microsoft.com/en-us/Windows7/open-the-search-and-indexing-Troubleshooter
Method 2:
Try to rebuild the search indexing. See the steps in the following article.
http://Windows.Microsoft.com/en-us/Windows7/change-advanced-indexing-options
See also:
Improve Windows searches using the index: frequently asked questions
http://Windows.Microsoft.com/en-us/Windows7/improve-Windows-searches-using-the-index-frequently-asked-questions -
Composite index + Plan selection
We have a table in our application (call it table t1) with a composite (with index) PK on three columns (c1, c2 and c3). We have a separate index on this table (not unique of course) on only the columns c1 and c2. We have tried to remove this second index, thinking that the optimizer would use just the KP index, but Oracle refuses to use this index when querying the table by only c1 and c2 (statistics are updated). He prefers a full table scan of ~ 25 000 000 lines. Is there a general answer as to why, or is it a more specific problem?
The numbers (in the plan and user_indexes) for N03 and PK indices are compatible with my opinion about the effect of the addition of the line_seq column. This seems to have given the optimizer indications that the lines with the same document_id and header_id are all grouped closely in a few blocks, but if you visit them in line-seq order you're going to jump everywhere around of these blocks. Roughly N03 suggests you visit 18 (= 22-4) blocks blocks while if you use PK you will jump around so it will resemble 323 (= 329-6). It is more like the effects of the SAMS who tries to data scatter XY from simultaneous session across about 16 blocks, and there is a solution to hide this effect which appeared in 11.2.0.4 with the 'set of prefs table' call to set the preference TABLE_CACHE_BLOCK to a value greater than the default value (1)-16 is a good choice if you don't know any better and you use SAMS.
This does not explain why a cost of research of 278423 must be preferred to cost of 329 PK if you drop or make invisible the index N03.
Currently on production, if you use the flag NO_INDEX(alias index_name) to tell the optimizer does NOT use the index N03 it will use analysis or some other indexes?
If research will be displayed just the thought that I have at the moment is that setting optimizer_index_cost_adj 20 has somehow confused the optimizer. (There are bugs in the past with the optimizer to make stupid with index things, like forgetting that one on the list exists - but you have to start watching the 10053 trace to determine if you have this kind of problem.)
Note If you like arithmetic:
Dividing clustering factor N03/PK: 21439882/1179975 = 18
Table of access cost (without index) (329-6) / (22-4) = 17.944 (close enough to convince)
Dividing the sheet block N03/PK: 151174/85893 = 1.76
Cost of access to index: 6 / 4 = 1.5 (lots of opportunities for rounding errors with small numbers whole, but close enough)
Concerning
Jonathan Lewis
Maybe you are looking for
-
Ho install a modem on system OS El captain
I bought a modem (Movitel, Mozambique telecommunications company), but I can't seem to install it. I went to the store and they said that the operating system OS El Captain does not support any type of modem.
-
How to uninstall optional updates in Windows Update that my wife has downloaded on the computer? I have Windows Vista Home Premium if it helps
-
Cost of Windows 7 Asus recovery install help!
Hello world I have an asus laptop comes with windows 7 starter edition. I did the anytime upgrade some time ago to windows 7 Professional. Stupidly, I played everywhere to try to create more space and deleted the recovery partition. My laptop is now
-
I'm trying to update from Windows 7 to Windows on a Dell Optiplex PC 10. For reasons of work, I have encryption software of disk full Symantech PGP (last compatible version 10) and Kaspersky (also 10 compatible) Suite installed on the PC. 10 will dow
-
Hello I have a question where I nee to close a tunnel IPSEC and GRE on my hub, is this possible? The GRE tunnel will be in the IPSEC tunnel.