Write data from a CSV to table
Hi allI have a CSV (Comma Separated Values) file and I want to write its data to the table.
How can I get data from a CSV file.
Knani suggested, you can use external Tables or Sql Loader
You can check this link for example on Sql Loader http://surachartopun.com/2007/10/example-sql-loader-some-data-into.html
Tags: Database
Similar Questions
-
Loading data from SQL to Essbase table
Hello
I'm loading data from SQL to Essbase table by using a rules file. Number of rows in the source table is 7 million. I use the SUNOPSIS MEMORY ENGINE as area transit, LKM SQL for SQL and SQL IKM for Hyperion Essbase (DATA).
Question:
1 can I not use any other LKM as MSSQL for MSSQL (PCBS) to load data to the staging instead of LKM SQL for SQL? What I have to change the transit area then? Loading data using LKM SQL for SQL seems quite slow.
2 it is mandatory to use LKM SQL for SQL, can someone please tell me what I can change to make this quick support parameters?
3. is it compulsory to use the SUNOPSIS MEMORY engine loading data from SQL server to Essbase?
Thank you...
(1) Yes, I highly recommend watching using a KM which uses native as database technology these will usually be more efficient than the generic (like LKM SQL for SQL) KM especially when large volumes of data are involved. Your staging will change depends on where you organize data for example if you are using a SQL server specific KM as - MSSQL for MSSQL (PCBS) - you must have a lay-by available on a MSSQL database and have access to the utility of PCBS.
(2) it is not mandatory to use this KM you can use a KMs supported by your database technology
(3) it is absolutely not obligatory to use the SUNOPSIS MEMORY engine. This should only be used when you have relatively small amounts of data, as well as all the processes in memory, or in the case where you have no other relational technology to perform the staging on. However, in your case to use wherever you are processesing these large volumes of data you should be staged on a physical such as SQL Server or Oracle database if they are available.
-
How to select data from a remote database table?
Hi friends,
I think I've seen before a sqlplus program that can select data from a remote database table?
Witnessed: IP, SID, PORT
The following is correct?
(I am connected to a local database)
SELECT COUNT (*) IN THE EMP@IP:SID/PORT;
Thank you very much
Ms. KSalvation;
I think, that you can create dblink wihtout any problem yet, it's a PROD. After your selection, you can drop dblink
Respect of
HELIOS -
Save and write data from table to table - easy
Hello
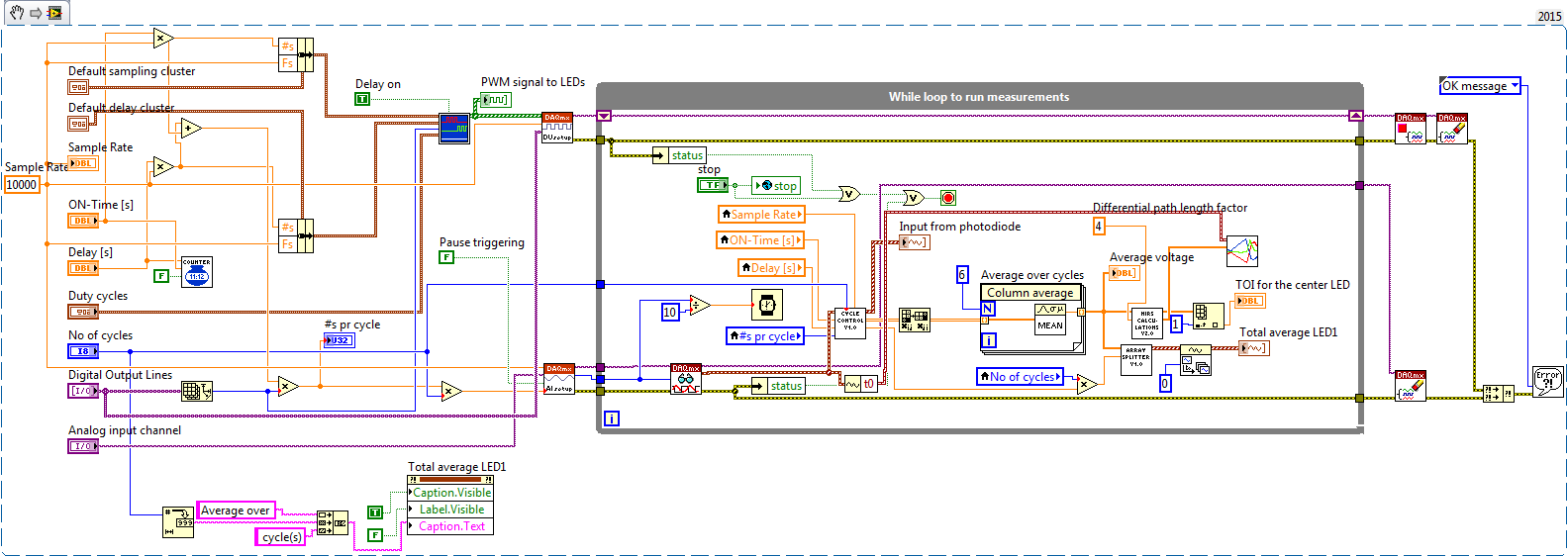
I got this system delivered to me. I'm new to LabView and just save the data from the table "average voltage" (inside the while loop) to do some additional testing of our product.
I will like to do similar to this.
(1) save in excel file.
(2) save only when a button button and save it then 5 ilteration.
(3) save and manipulate the data, so it is displayed in 6 columns (each LED 1) instead of 1 long colum.
I tried different things with structure business T/F, which resolved the buttom-request. But I am in doubt I should use, writing to the file of the measurement or write to us to the worksheet (by using labview 15.0)-delimited according to my offer the best possible?
He also seems to be too much to handle when I try to write in txt file, because it pops up with and error that I do not know how to fix, but it says this:
Error-200279
Possible reasons:
The application is not able to cope with the acquisition of equipment.
Increase in the size of buffer, most frequently the reading of data or by specifying a fixed number of samples to read instead of reading all available samples would correct the problem.
Property: RelativeTo
Corresponding value: current playback Position
Property: Offset
Corresponding value: 0
Task name: analog channel
Thanks in advance
I agree with Taki, but want to make some additional remarks:
- LabVIEW is a data flow language. Think of the "flow" of your data. You talk about "save only when a key is pressed" and a finite set of data. You are collecting before the press the button and everything just do not save?
- Data are collected at some rate, and likely, you don't want to "Miss" data points. This means that you shouldn't do anything in the loop of the Collection that takes a long time. If your recovery rate is low and your treatment is fast, you can have everything in a single loop. Otherwise, to use the technical stream (producer/consumer is a good) to process the data in a single loop in parallel with the collection in a loop independent (and asynchronously).
- How do you write your data? You want to write "on the fly", as it is, or can you wait, collect everything, any format and then write it "all at once"?
- What do you mean by 'save the file in Excel? Do you mean a 'native' Excel file, one with the extension .xls or .xlsx? Do you mean a Comma-Separated Variable (.csv) file this reading peut of Excel (and, indeed, usually registers itself to read, change the icon of the .csv files to "look like" it is really an Excel file)? If the first case, I recommend using the report generation tool. But for the latter, you can also use write delimited spreadsheet, which can be easier to use.
Bob Schor
-
Unable to display data from a csv file data store
Hi all
I'm using ODI 11 g. I'm trying to import metadata from a csv file. To do this, I have created physical and logical diagrams corresponding. Context is global.
Then, I created a model and a data store. Now, after reverse engineering data store, I got the file headers and I changed the data type of columns to my requirement and then tried to view the data in the data store. I am not getting any error, but can't see all the data. I am able to see only the headers.
Even when I run the interface that loads data into a table, its operation without error, but no data entered...
But the data is present in the source file...
Can you please help me how to solve this problem...
Hi Phanikanth,
Thanks for your reply...
I did the same thing that you suggested...
In fact, I'm working on the ODI in UNIX environment. So I went for the record separator on UNIX option in the files of the data store tab and now its works well...
in any case, once again thank you for your response...
Thank you best regards &,.
Vanina
-
How to write data from the acquisition of data in NetCDF format?
I connect to a set of data from the sensor through the DAQ assistant and want to write all data in NetCDF format. I have the required plugins installed, but still can not find how to do this.
Or the labview can only read the netcdf files, but cannot write it! Please let me know if there is any other way out. I have looked everywhere but could not find something useful!
Thank you
Hey,.
Sorry, the sheet in effect only allows to read NetCDF files, not writing to the NetCDF format.
Kind regards
-Natalia
-
global variable functional to read and write data from and to the parallel loops
Hello!
Here is the following situation: I have 3 parallel while loops. I have the fire at the same time. The first loop reads the data from GPIB instruments. Second readers PID powered analog output card (software waveform static timed, cc. Update 3 seconds interval) with DAQmx features. The third argument stores the data in the case of certain conditions to the PDM file.
I create a functional global variable (FGV) with write and read options containing the measured data (30 double CC in cluster). So when I get a new reading of the GPIB loop, I put the new values in the FGV.
In parallel loops, I read the FGV when necessary. I know that, I just create a race condition, because when one of the loops reads or writes data in the FGV, no other loops can access, while they hold their race until the loop of winner completed his reading or writing on it.
In my case, it is not a problem of losing data measured, and also a few short drapes in some loops are okey. (data measured, including the temperature values, used in the loop of PID and the loop to save file, the system also has constants for a significant period, is not a problem if the PID loop reads sometimes on values previous to the FGV in case if he won the race)
What is a "barbarian way" to make such a code? (later, I want to give a good GUI to my code, so probably I would have to use some sort of event management,...)
If you recommend something more elegant, please give me some links where I can learn more.
I started to read and learn to try to expand my little knowledge in LabView, but to me, it seems I can find examples really pro and documents (http://expressionflow.com/2007/10/01/labview-queued-state-machine-architecture/ , http://forums.ni.com/t5/LabVIEW/Community-Nugget-2009-03-13-An-Event-based-messageing-framework/m-p/... ) and really simple, but not in the "middle range". This forum and other sources of NEITHER are really good, but I want to swim in a huge "info-ocean", without guidance...

I'm after course 1 Core and Core 2, do you know that some free educational material that is based on these? (to say something 'intermediary'...)
Thank you very much!
I would use queues instead of a FGV in this particular case.
A driving force that would provide a signal saying that the data is ready, you can change your FGV readme... And maybe have an array of clusters to hold values more waiting to be read, etc... Things get complicated...
A queue however will do nicely. You may have an understanding of producer/consumer. You will need to do maybe not this 3rd loop. If install you a state machine, which has (among other States): wait for the data (that is where the queue is read), writing to a file, disk PID.
Your state of inactivity would be the "waiting for data".
The PID is dependent on the data? Otherwise it must operate its own, and Yes, you may have a loop for it. Should run at a different rate from the loop reading data, you may have a different queue or other means for transmitting data to this loop.
Another tip would be to define the State of PID as the default state and check for new data at regular intervals, thus reducing to 2 loops (producer / consumer). The new data would be shared on the wires using a shift register.
There are many tricks. However, I would not recommend using a basic FGV as your solution. An Action Engine, would be okay if it includes a mechanism to flag what data has been read (ie index, etc) or once the data has been read, it is deleted from the AE.
There are many ways to implement a solution, you just have to pick the right one that will avoid loosing data. -
Hello
I want to join the two tables to retrieve the data from the columns of the two table passing parameters to the join query. Tables have primary and foreign key relationships
Details of the table
Alert-1 - AlertCode (FK), AlerID (PK)
2 AlertCode-AlertDefinition-(PK)
Help, please
----------
Hi Vincent,.
I think that you have not worked on adf 12.1.3. In adf 12.1.3 you don't have to explicitly create the association. When you create the EO to your table, Association xxxxFkAssoc, will be created by ADF12.1.3 for you automatically. Please try this and do not answer anything... You can also follow the links below. I solved the problem by using the following link
---
-
Need assistance to migrate data from XML to oracle table.
Hey Odie,
Im trying to insert data from an xml file into a table.
My XML file is as follows.
<? XML version = "1.0" encoding = "UTF-8" standalone = 'yes' ?>
< Ingredient > I3261 < / > of theingredient< DispensedQty > 0,0 < / DispensedQty >< MDispensedQty > 3.5 < / MDispensedQty >< / SubBatchDetail >
- < SubBatchDetail >< Ingredient > I3235 < / > of theingredient< DispensedQty > 0,0 < / DispensedQty >< MDispensedQty > 0,5 < / MDispensedQty >< / SubBatchDetail >
- < SubBatchDetail >< Ingredient > I3142 < / > of theingredient< DispensedQty > 0,0 < / DispensedQty >< MDispensedQty > 0,2 < / MDispensedQty >< / SubBatchDetail >
</SubBatch>
< SubBatchName > ZB97913 < / SubBatchName >< SubBatchStatus > incomplete < / SubBatchStatus >- < SubBatchDetail >< Ingredient > I3309 < / > of theingredient< DispensedQty > 0,75 < / DispensedQty >< MDispensedQty > 0,0 < / MDispensedQty >< / SubBatchDetail >
- < SubBatchDetail >< Ingredient > I3436 < / > of theingredient< DispensedQty > 0,0 < / DispensedQty >< MDispensedQty > 0,05 < / MDispensedQty >< / SubBatchDetail >
</SubBatch>
<Final>false</Final>< / TransferXML >
With the help of your previous posts I've migrated data from this xml file in a table that works perfectly well. But these data repeats instead of giving 6 lines that his return 12 lines guide please.
CREATE TABLE XXBATCH AS
SELECT A.BatchName, A.BatchStatus, B.SubBatchName, B.SubBatchStatus, C.Ingredient, C.DispensedQty, C.MDispensedQty, A.FINAL
OF (XMLTable ('/ TransferXML'))
from xmltype)
BFILENAME('APPS_DATA_FILE_DIR','HJ69240.) XML')
nls_charset_id ('AL32UTF8')
) COLUMNS
BatchName VARCHAR2 path (99) "BatchName.
, Path of the BatchStatus VARCHAR2 (999) "BatchStatus.
Path VARCHAR2 (99) final 'Final')),
(XMLTable ('/ TransferXML/SubBatch '))
from xmltype)
BFILENAME('APPS_DATA_FILE_DIR','HJ69240.) XML')
nls_charset_id ('AL32UTF8')
) COLUMNS
Path of SubBatchName VARCHAR2 (99) "SubBatch/SubBatchName".
, Path of the SubBatchStatus VARCHAR2 (99) "SubBatch/SubBatchStatus".
(B)
(XMLTable ('/ TransferXML/SubBatch/SubBatchDetail '))
from xmltype)
BFILENAME('APPS_DATA_FILE_DIR','HJ69240.) XML')
nls_charset_id ('AL32UTF8')
) COLUMNS
Path of the ingredient VARCHAR2 (99) SubBatchDetail/ingredient"."
, Path of the DispensedQty VARCHAR2 (99) "SubBatchDetail/DispensedQty".
, Path of the MDispensedQty VARCHAR2 (99) "SubBatchDetail/MDispensedQty".
(C)
I didn't test your query, but apparently it's because you have access to the same file three times instead of spend one XMLTable to another correlated nested groups.
Better, this should work:
SELECT A.BatchName
A.BatchStatus
B.SubBatchName
B.SubBatchStatus
C.Ingredient
C.DispensedQty
C.MDispensedQty
A.FINAL
FROM XMLTable ('/ TransferXML')
PASSAGE xmltype (bfilename('TEST_DIR','HJ69240.xml'), nls_charset_id ('AL32UTF8'))
Path of COLUMNS BatchName VARCHAR2 (99) "BatchName.
, Path of the BatchStatus VARCHAR2 (999) "BatchStatus.
, Path VARCHAR2 (99) final "Final."
, Path of XMLTYPE «SubBatch» SubBatchList
) AT
, XMLTable ('/ SubBatch')
PASSAGE SubBatchList
Path of COLUMNS SubBatchName VARCHAR2 (99) "SubBatchName".
, Path of the SubBatchStatus VARCHAR2 (99) "SubBatchStatus".
, Path of XMLTYPE «SubBatchDetail» SubBatchDetailList
) B
, XMLTable ('/ SubBatchDetail')
PASSAGE SubBatchDetailList
Path VARCHAR2 (99) ingredient of COLUMNS "Ingredient."
, Path of the DispensedQty VARCHAR2 (99) "DispensedQty".
, Path of the MDispensedQty VARCHAR2 (99) "MDispensedQty".
) C
;
Post edited by: odie_63
-
How can I extract the data from a csv file and insert it into an Oracle table? (UTL_FILE)
Hi, please help me whit this query
Im trying to extrate the data in a file csv and im using the ULT_FILE package
I have this query that read the file and the first field, but if the field has a different length does not work as it shouldFor example if I had this .csv file:
1, book, laptop
2, pen, Eraser
3, notebook, paper
And in the table, I had to insert like this
ID descrption1 description2
laptop 1 book
Eraser pen 2
paper laptop 3
For now, I have this query, which displays only with DBMS:
Declare
-Variables
Cadena VARCHAR2 (32767).
Vfile UTL_FILE. TYPE_DE_FICHIER;
Dato varchar2 (200); -Date
dato1 varchar2 (200);
dato2 varchar2 (200);
Identifier varchar2 (5): = ', '; -Identifier (en)
v_ManejadorFichero UTL_FILE. TYPE_DE_FICHIER; -For exceptions
-Table variables
I_STATUS GL_INTERFACE. % OF STATUS TYPE.
I_LEDGER_ID GL_INTERFACE. TYPE % LEDGER_ID;
I_USER_JE_SOURCE_NAME GL_INTERFACE. TYPE % USER_JE_SOURCE_NAME;
I_ACCOUNTING_DATE GL_INTERFACE. TYPE % ACCOUNTING_DATE;
I_PERIOD_NAME GL_INTERFACE. TYPE % PERIOD_NAME;
I_CURRENCY_CODE GL_INTERFACE. CURRENCY_CODE % TYPE;
I_DATE_CREATED GL_INTERFACE. DATE_CREATED % TYPE;
I_CREATED_BY GL_INTERFACE. CREATED_BY % TYPE;
I_ACTUAL_FLAG GL_INTERFACE. TYPE % ACTUAL_FLAG;
I_CODE_COMBINATION_ID GL_INTERFACE. TYPE % CODE_COMBINATION_ID;
I_ENTERED_DR GL_INTERFACE. TYPE % ENTERED_DR;
I_ENTERED_CR GL_INTERFACE. TYPE % ENTERED_CR;
I_ACCOUNTED_DR GL_INTERFACE. TYPE % ACCOUNTED_DR;
I_ACCOUNTED_CR GL_INTERFACE. TYPE % ACCOUNTED_CR;
I_TRANSACTION_DATE GL_INTERFACE. TRANSACTION_DATE % TYPE;
I_REFERENCE1 GL_INTERFACE. REFERENCE1% TYPE;
I_REFERENCE2 GL_INTERFACE. REFERENCE2% TYPE;
I_REFERENCE3 GL_INTERFACE. REFERENCE3% TYPE;
I_REFERENCE4 GL_INTERFACE. REFERENCE4% TYPE;
I_REFERENCE5 GL_INTERFACE. REFERENCE5% TYPE;
I_REFERENCE10 GL_INTERFACE. REFERENCE10% TYPE;
I_GROUP_ID GL_INTERFACE. GROUP_ID % TYPE;
BEGIN
Vfile: = UTL_FILE. FOPEN ('CAPEX_ENVIO', 'comas.csv', 'R');
loop
UTL_FILE. GET_LINE(Vfile,Cadena,32767);
dato1: = substr (cadena, instr(cadena, identificador,1,1)-1, instr(cadena, identificador,1,1)-1);
dato2: = substr (cadena, instr (cadena, identifier, 1, 1) + 1, instr(cadena, identificador,3,1)-3);
dbms_output.put_line (dato1);
dbms_output.put_line (dato2);
-The evidence
-dbms_output.put_line (cadena);
-dbms_output.put_line (substr (dato, 3, instr(dato, identificador,1,1)-1));
-dbms_output.put_line (substr (dato, instr (dato, identifier, 1, 2) + 1, instr(dato, identificador,1,1)-1));
-dbms_output.put_line (substr (cadena, 1, length (cadena)-1));
end loop;
UTL_FILE. FCLOSE (Vfile);
-----------------------------------------------------------------------------------EXCEPTIONS------------------------------------------------------------------------------------------------------------------------------------------------------------
EXCEPTION
When no_data_found then
dbms_output.put_line ('Todo Correcto');
When utl_file.invalid_path then
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20060,'RUTA DEL ARCHIVO NULLIFIED: (');)
WHEN UTL_FILE. INVALID_OPERATION THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR ('-20061,'EL ARCHIVO NO PUDO SER ABIERTO ");
WHEN UTL_FILE. INVALID_FILEHANDLE THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20062, 'INVALIDO MANAGER');
WHEN UTL_FILE. WRITE_ERROR THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20063, 'ESCRITURA ERROR');
WHEN UTL_FILE. INVALID_MODE THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20064, 'MODO INVALIDO');
WHEN UTL_FILE. INTERNAL_ERROR THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20065, 'ERROR INTERNO');
WHEN UTL_FILE. READ_ERROR THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20066, 'LECTURA ERORR');
WHEN UTL_FILE. FILE_OPEN THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR ('-20067,'EL ARCHIVO ARE ESTA ABIERTO ");
WHEN UTL_FILE. THEN ACCESS_DENIED
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20068, 'REFUSED ACCESS');
WHEN UTL_FILE. DELETE_FAILED THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20069, 'OPERACIÓN BORRADO FALLO');
WHEN UTL_FILE. RENAME_FAILED THEN
UTL_FILE. FCLOSE (V_ManejadorFichero);
RAISE_APPLICATION_ERROR (-20070, 'OPERATION SOBREESCRITURA FALLO');
END;
Hello
Try something like this:
POS1: = INSTR (cadena, idntificador, 1, 1);
POS2: = INSTR (cadena, idntificador, 1, 2);ID: = SUBSTR (cadena, 1, pos1 - 1);
description1: = SUBSTR (cadena, pos1 + 1, (pos2 - pos1)-1);
Description2: = SUBSTR (cadena, pos2 + 1);where pos1 and pos2 are numbers.
Rather than use UTL_FILE, consider creating an external table. You won't have to write any PL/SQL, and this means that you won't be tempted to write a bad article of EXCEPTION.
-
Data from the CSV into a TABLE
Hello world...
I have the csv file in c:\city.csv (this file have 2 fields that are 'id' and 'short-term'
I have a form... There is a button on it.
and I have a table in my database of CITY and its fields are (id number, city varchar2 (50))
I want a procedure that when I press the button on the form fields CSV file copy of table
I saw the number of threads, but I did not understand...
Please make me a procedure...
don't give me links refrence...
Thanks in advance
concerning
Sani...Hoek put the right answer :) so... try next time
Here is your code:
-- Test-Table CREATE TABLE city_table ( city_id VARCHAR2(100), city_name VARCHAR2(100) ); -- Test-File 1000,Cologne 1001,Amsterdam 1002,KFC :) 1003,Blabla --Forms-Procedure to call PROCEDURE get_city_data IS file_handle text_io.file_type; seperator VARCHAR2(1) := ','; city_row VARCHAR2(32767); city_id VARCHAR2(100); city_name VARCHAR2(100); BEGIN file_handle := text_io.fopen('c:\city.csv', 'R'); BEGIN LOOP text_io.get_line(file_handle, city_row); city_id := SUBSTR(city_row, 1, INSTR(city_row, seperator) - 1); city_name := SUBSTR(city_row, INSTR(city_row, seperator) + 1); INSERT INTO city_table VALUES(city_id, city_name); END LOOP; EXCEPTION WHEN NO_DATA_FOUND THEN NULL; END; text_io.fclose(file_handle); COMMIT; EXCEPTION WHEN OTHERS THEN message('Error!!'); RAISE FORM_TRIGGER_FAILURE; END; -
How to write data from the INI file for the control of the ring
Hai,
I need to write the data read from the INI file to a control of the RING. Doing this operation using variants I get the error.
I will be happy if someone help me. I have attached the file special INI and VI.
-
How to write data in an existing database table in sql using table in lab mode
I am trying to write the data to an existing table in sql databse.but I don't know how to get it done me .plz help
The error text is clear: the data provided does not match the number of columns. Your insertion data have 3 columns, how is appointed in the control of columns?
It would be easier if you attached the VI with orders paid at the current values as default value.
/Y
-
Extract data from SQL to Pivot Table/CUBE database vFoglight?
Our CIO request hourly data so he can create a history of our virtual environment using the data collected from vFoglight the BODs to attend so that they can see ho are we utulizing the new environment, they allowed us to buy. I've created a report for him but he won't have to copy and paste data in an excel file, every hour, it's short.
It looks like this:
dnsName Name Use (%) ESXi Server 1 Memory 42 ESXi Server 2 Memory 37 So is there a way to allow Excel to connect to SQL Server and extract this data so that it can organize itself? Or can we write a report that displays data on time as follows?
I.E.
01:00 - 42%
02:00 - 39%
03:00 - 41%
Hi Morgan,.
There are a few examples of the extraction of metrics data formatted in Foglight using command-line scripts in the blog article Foglight Reporting using queries metric or Groovy to http://en.community.dell.com/techcenter/performance-monitoring/foglight-administrators/w/admins-wiki/5654.foglight-reporting-using-metric-queries-or-groovy
I hope this will give you some ideas.
Kind regards
Brian Wheeldon
-
Plot data from several sources in table of graphs
Hello! I get 1250 pixel data and I want to plot the data for each pixel in a different chart. Each time, I get a data word and one word for the address of the pixel just, how do I trace these in an array of graphics? (Or the other table 1 d of 1250 graphics or table 2D 50 25 columns x lines).
When there was less that I used a case structure and graphics I would wire the address pixel in the selector of the case, now what can I do?
Any suggestions would be helpful, thanks.
Practically speaking it is not not possible to see 1250 chart 1 shot so its no need to have a lot of graphics. What we do in this situation is usually to initialize an array of elements of 1250 and replace these items when you receive data in a particular order. At the same time have a ring to control and update the name of items in the same order as you update the table. Now pass the array of values in the index table and connect control of the ring to the terminal index and connect the output to the curve. So when you select an item, you will be able to see the value of this element in particular.
Maybe you are looking for
-
Satellite L650/1MC - WiFi and LAN connection keep dropping out
In the last two weeks, that my wifi connection dropped regularly - only a reboot solves the problem. Because it became so frequent (and boring) I returned with an ethernet cable, which worked OK for a few days, but tthat hen started making the same t
-
Sabnzbd ReadyNas Ultra 4 connection problems
This message: https://community.NETGEAR.com/T5/legacy-NETGEAR-and-partners-add/SABnzbd-performance-issues-ReadyNAS... apply to my RNUltra4, too. Has worked like a charm for many years - was able to dl through the ReadyNas Monday. Since yesterday morn
-
Satellite A100 - where can I get new display driver?
Hello I have a laptop Satellite A100-153 and I also use it for games. It is, drivers that are available on this site are DEFINITELY outdated (they are of type.. 2007) and I can't install official drivers of mobility on the ATI site. So my question is
-
HP Solution Center no longer works after update of HP Officejet J6480
HP will provide an update to fix this problem? If anyone has had the same problem (if so, how fixed?)? HP has pushed down the updates on a week earlier for my HP Pavilion Elite e9270f running Windows 7 64 bit home and domestic all-in-one Officejet J
-
typedef red dot coercion cluster with node property value
Hello! I have a project more vast, where I have parallels of DAQ and other calculations. In the project that I have spend all my relevant data between different parts of the program by using a typedef cluster control, so if I need to add the new elem