Add column from the moment of the execution of query UNPIVOT
11g
Hello
I used UNPIVOT to structure reorgansise my data and I would like to create a column called WORK_STATUS to place the column header original OFFICE or FIELD as an identifier of line on each record.
Something like this (WORK_STATUS is the DURATION column, I add);
ID NAME HOURS WORK_STATUS ---------- -------------------- ---------- ------------- 317 Brendan C 16 OFFICE 317 Brendan C 80 FIELD
That's what looked like the original data;
SELECT ID, NAME, OFFICE_HOURS, FIELD_HOURS FROM XM_INTERPRETATION ID NAME OFFICE_HOURS FIELD_HOURS ---------- -------------------- ------------ ----------- 325 Tony H 0 20 325 Leroy B 0 16 325 Brendan C 16 80 325 Caitlyn O 0 72 326 Tony H 2 6 326 Leroy B 2 6
It is the UNPIVOT statement;
SELECT ID , NAME , HOURS FROM XM_INTERPRETATION UNPIVOT EXCLUDE NULLS (HOURS FOR X IN (OFFICE_HOURS , FIELD_HOURS) ); ID NAME HOURS ---------- -------------------- ---------- 325 Tony H 0 325 Tony H 20 325 Leroy B 0 325 Leroy B 16 325 Brendan C 16 325 Brendan C 80 325 Caitlyn O 0 325 Caitlyn O 72 326 Tony H 2 326 Tony H 6 326 Leroy B 2 326 Leroy B 6
I hoped I could do was something like the following:
SELECT ID , NAME , HOURS , WORK_STATUS FROM XM_INTERPRETATION UNPIVOT EXCLUDE NULLS (HOURS, WORK_STATUS FOR X IN (OFFICE_HOURS, "OFFICE" , FIELD_HOURS, "FIELD") );
Ben
Hi, Ben.
Benton says:
11g
Hello
I used UNPIVOT to structure reorgansise my data and I would like to create a column called WORK_STATUS to place the column header original OFFICE or FIELD as an identifier of line on each record.
Something like this (WORK_STATUS is the DURATION column, I add);
- ID NAME HOURS WORK_STATUS
- ---------- -------------------- ---------- -------------
- OFFICE C Brendan 16 317
- Brendan FIELD 317 C 80
That's what looked like the original data;
- SELECT ID, NAME, OFFICE_HOURS, XM_INTERPRETATION FIELD_HOURS
- ID NAME OFFICE_HOURS FIELD_HOURS
- ---------- -------------------- ------------ -----------
- Tony 325 0 20 H
- Leroy B 0 16 325
- Brendan 325 C 16 80
- Caitlyn 325 0 72 O
- Tony 326 2 6 H
- Leroy B 2 6 326
It is the UNPIVOT statement;
- SELECT THE ID
- NAME
- HOURS
- OF XM_INTERPRETATION
- UNPIVOT EXCLUDE NULLS (HOURS
- FOR X
- IN (OFFICE_HOURS
- FIELD_HOURS)
- );
- ID NAME HOURS
- ---------- -------------------- ----------
- Tony 325 H 0
- Tony 325 H 20
- Leroy 325 B 0
- Leroy 325 B 16
- Brendan 325 C 16
- Brendan 325 C 80
- Caitlyn 325 O 0
- Caitlyn 325 O 72
- Tony 326 H 2
- Tony 326 H 6
- Leroy 326 B 2
- Leroy 326 B 6
I hoped I could do was something like the following:
- SELECT THE ID
- NAME
- HOURS
- WORK_STATUS
- OF XM_INTERPRETATION
- UNPIVOT EXCLUDES NULL VALUES (HOURS, WORK_STATUS
- FOR X
- IN (OFFICE_HOURS, 'OFFICE'
- FIELD_HOURS, "FIELD")
- );
Ben
Look at the syntax of the UNPIVOT operator function: http://docs.oracle.com/database/121/SQLRF/statements_10002.htm#sthref7311
SELECT id, name, hours, work_status
OF xm_interpretation
UNPIVOT (hours
FOR IN work_status (office_hours 'OFFICE'
, field_hours AS 'FIELD '.
)
)
ORDER BY id
work_status DESC
;
The columns you want to unpivot (office_hours and field_hours in this case) are separated by commas, so commas can also be used to separate the columns of their labels. In addition, the labels are literals; sttring literals are enclosed in single quotes, not double - quote.
I hope that answers your question.
If not, please post CREATE TABLE and INSERT statements for your sample data and results you like from these data (otherwise what you have already posted).
See the FAQ forum: Re: 2. How can I ask a question on the forums?
Tags: Database
Similar Questions
-
Add a network printer (add printer vs right-click-> Connect)
Hey just have a quick question that I can't find anywhere.
To add network printers is there a difference through the add printer from the Menu then opening just the print server in the Explorer, and then right-click on the printer you want and pressing on connect?
Hello Doughty08,
No, there is no difference. Both methods will install the same printer available driver and the two will work the printer even. -
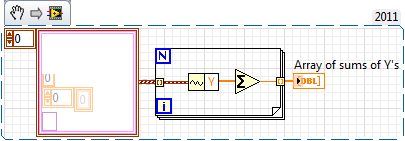
I'm having a bit of a basic problem here...
I start with a waveform D 1 from a request of data acquisition, which contains ~ 22 columns of data corresponding to the different measures. I wanted to take the first 20 columns of data and add the "column vectors" (i.e. each measure) for a 1 d table (the sum of the first 1 22 tables/measures/vectors). The logical way to proceed, it seems, is by indexing the waveform with a loop, conversion in DBL and then adding each column with a registry change.
1 d Waveform--> for (indexed) loop--> get waveform components to get the DBL table to the index column--> go to 'add block '.
And then, using a shift register, I add each column in the index.
However, I get no output once for the finished loop.
Any ideas? Examples are JPEG/png files please!
I'm a big fan of doing things the easy way.
-
Get columns from the table shown in the iterator
Hello...
I have the table in a collection of standard panel. So, I can show/hide certain columns in the table using the columns in the view menu.
Then I'm trying to do is export to excel (using apache poi) by looping through the table iterator. What I can't do is search if the column is not displayed. I don't want all the columns that are exported without worrying. How can I achieve this?
My bean is similar to the following for loop through the iterator:
BindingContext bindingContext = BindingContext.getCurrent ();
BindingContainer bindingContainer = bindingContext.getCurrentBindingsEntry ();
DCIteratorBinding dcIteratorBinding = (DCIteratorBinding) bindingContainer.get ("EmployeesIterator");
lines [] oracle.jbo.Row = dcIteratorBinding.getAllRowsInRange ();
for (oracle.jbo.Row line: lines) {}
{for (String colName: {row.getAttributeNames ())}
output to excel cell here using row.getAttribute (colName) m:System.NET.SocketAddress.ToString)
}
}
Thank you.
Hello
It's like ask the engine in your car to what colors the seats have. The iterator doesn't know anything about the visible state of a column. If the displayed columns must be determined from the table instance (richeTableau)
The following article solves exactly the requirement that you have: Oracle ADF: Build Your Own it comes with a sample that you can download here: http://www.oracle.com/technetwork/issue-archive/2013/13-jul/o43adf-1940728.zip
Have a look at CustomPanelCollectionBean.java:
The method and code that you want to look for is:
private String getRowHtml (row rw) {}
StringBuffer rowHtmlBuf = new StringBuffer();
Read visible columns in the table of the table instance. This way the
PanelCollection can be used to show/hide columns and exclude
printing to HTML
Table richeTableau = this.getRichTable ();
the list of columns determine the print attributes
The list of columns in
= table.getChildren (); int attrCount = columns.size ();
rowHtmlBuf.append (this.addRowStart ());
for (int i = 0; i)< attrcount;="" i++)="">
for all visible columns, add columns to print
If (((RichColumn) columns.get (i)) .isVisible ()) {}
If (rw.getAttribute (i) instanceof ViewRowSetImpl) {}
ignore the collections of detail used for master/detail example
constraints in British Colombia ADF
} ElseIf (rw.getAttribute (i) instanceof oracle.jbo.domain.Timestamp) {}
shorten date to exclude the infromation times
SimpleDateFormat sdf = new SimpleDateFormat("dd-MM-yyyy");
String dateFormatString = sdf.format (((Timestamp) rw.getAttribute (i)) .getData ());
rowHtmlBuf.append (this.addDataCell (dateFormatString));
} else {}
Prnt attribute values and if sure that null values don't raise a NPE. Add a white character to NULL
attribute values
rowHtmlBuf.append (this.addDataCell (rw.getAttribute (i)! = null? rw.getAttribute (i) m:System.NET.SocketAddress.ToString ():))
" "));
}
}
}
rowHtmlBuf.append (this.addRowEnd ());
Return rowHtmlBuf.toString ();
}
You need to access the Rich Table instance (for example using the JSF component binding) to then compare the attribute in the iterator with the visibility of the column
Frank
-
Remove the column from the compressed tables
NLSRTL 11.2.0.3.0 Production Oracle Database 11g Enterprise Edition 11.2.0.3.0 64 bit Production PL/SQL 11.2.0.3.0 Production AMT for Linux: 11.2.0.3.0 Production Hello
I read on how to do to remove a compressed table column - first set unused and then drop unused columns. However, in the example below on the basis of data, I ran it, it does not work. Please, can you tell me WHEN this approach does not work. What is dependent on - settings or something else. Why can't I drop unused columns?
And the example and errors:
create table tcompressed compress in select * from all_users;
> TCOMPRESSED table created.
ALTER table tcompressed add x number;
> table TCOMPRESSED altered.
ALTER table tcompressed drop the x column;
>
Error report:
SQL error: ORA-39726: unsupported operation column add/drag on compressed tables
39726 00000 - "operation column add/drop not supported on compressed tables. ''
* Cause: Not support add/column operation move compressed tables
elapse.
* Action: When adding a column, do not specify a default value.
DELETE column is only supported in a column SET UNUSED
(remove the column metadata).
ALTER table tcompressed unused column of the set x;
> table TCOMPRESSED altered.
ALTER table tcompressed drop unused columns;
>
Error report:
SQL error: ORA-39726: unsupported operation column add/drag on compressed tables
39726 00000 - "operation column add/drop not supported on compressed tables. ''
* Cause: Not support add/column operation move compressed tables
elapse.
* Action: When adding a column, do not specify a default value.
DELETE column is only supported in a column SET UNUSED
(remove the column metadata).
As you can see even after changing the table defining the column as unused X I still can't drop by DROP UNUSED COLUMNS.
Thank you.
If you enable compression for all operations on a table, you can delete the columns in the table. If you enable compression for the only direct-path inserts, you can't remove columns.
-
Add column if the value in another column
How can I add a column as column name 'YES_OR_NO.
SELECT VALUE_ID IN THE TABLE TABLE_NAME
VALUE_ID
---
1
2
3
4
5
Now, I want to create another column in the sql query called YES_OR_NO and that if there is a value in VALUE_ID then column YES_OR_NO must say 'YES' if there is no value in the column VALUE_ID of this line YES_OR_NO must say 'NO '.
or just a way for her also to work would be to show this new column or not if a value in another column of table_name_2 (this would be ideal)
If new column yes_or_no and fill by a Yes or a no if a value is found in another tableAssuming that you are on a version that supports the CASE expression:
SELECT VALUE_ID , case when VALUE_ID is null then 'NO' else 'YES' end as YES_NO FROM TABLE_NAME -
Split columns from the table to the tabs
Hello world
I want to create an application where I retrieve data from a database table and display divided into tabs.
So I want tab1 to display columns 1 to 5, tab2 to display columns etc. from 6 to 10.
How can I do?
Thank you!user12169513,
Here's a way to do it.Let's say you have col1, col2, col3, col4 in the table. Col1 is common, and you want to show col1, col2 on Tab1, Tab2 Col3 Col1 and Col1, Col4 on tab 3.
1 create three pages, tell page 2, 3 and 4 have the queris as. Choose the position of the body region 3 (default)
Select col1, col2 from... on Pag2
Select col1, col3 from... on Pag3
Select col1, col4... on Pag4
2. next, create a list with three entries. Tab1 pointing to Page2, Tab2 pointing to page 3 and tab 3 on Page4
3. on pages 2, 3 and 4, add a list region in Boby 01 or Breadcrump (anythign above 03) on the list created
4. change the regions from the list and change the model override list to List of tabbed browsingThe other way is to use the tabs pointing to the Pages 2,3,4.
Kind regards
PS: Its nice when I know he's one human being at the other end with a name
Published by: Dominique on August 12, 2010 19:00
-
How to remove columns from the table on the master 1-0?
I have an array of 96 columns with strings. I also have the array of int 96-elemets (mask) with 1 and 0.
What I want to do is to is to remove (or hide - but I read that it is not possible) all the columns with index corresponding to 0 in the mask table.
example:
columns in the table
1 2 3 4 5
mask
0 1 0 0 1
I want to remove the columns 1, 3 and 4 and leave only 2 and 5 in my table.
How can I do?
If I create loop for with i as the index of the column, when I do DeleteTableColumns() columns number decreases, and I get an error of range out of

Or do I have an option to hide the unnecessary columns (not set their width to 1, it's very ugly-looking)?
Please help me (())
Hello rovnyart!
1. removal of columns in the table:
I suspect that the reason why you get the out-of-range error is due to fact that in your loop, you delete the columns in the table, you'll eventually end up by referring to a column that no longer exists, because the other columns before it have been deleted. While you remove each column of your table in the loop for example, the column index number will move, because you deleted the other columns in front of her.
To resolve this, even if you delete a column in your loop, make sure that you take also into account that the index of the column is moved because of the removed columns.
2 hide columns in table:
You can use the ATTR_COLUMN_VISIBLE attribute to hide columns in the table:
http://zone.NI.com/reference/en-XX/help/370051Y-01/CVI/uiref/cviattrcolumnvisible_column/
3 alternatives:
Note that another alternative would also use a tree instead, control as the tree control also supports the hidable columns:
http://forums.NI.com/T5/LabWindows-CVI/table-hide-column/TD-p/569773
Best regards!
-Johannes
-
This is a question and a suggestion...
I would like to be able to precede or add if it works, the command line in the output file that creates the order.
Example:
I run dcdiag with switches, etc. and create an output file of results that gets saved or sent to a person or just put it in a folder. Of course, it could be that someone else ran the command and then sent the file. Anyway the problem is the same - what was the exact command line that has been executed to achieve these results?
Question:
Is there a known way to do from the command line that I can apply to any command?
Suggestion:
If this isn't the case, then I would suggest MS to include this function in all the BACK and PowerShell commands able to produce text output.
If all goes well they monitor this forum and find it's a great idea and send me a check (pinky in my cheek) a meeellion of dollars. Then I and I alone will rule the world.
Here you go:
d:\>format i: / FS: NTFS > format.txt
d:\>echo i format: / FS: NTFS > format.txt -
How to dynamically add columns to the table
Hi all
I'm new to ADF and need help on sub condition.
We have created a ViewObject on the EMPLOYEE table that has under columns:
EMP_ID,
EMP_NAME,
DEPARTMENT,
COST_CENTER,
BUSINESS_UNIT
COUNTRY
GCODE
We need to create a page in the ADF with employee table to show only below the columns
EMP_ID,
EMP_NAME,
DEPARTMENT,
COST_CENTER
Later, if necessary user should be able to add other columns to the page dynamically.
Can you please advice on how to implement this feature.
Thank you.
Kind regards
Vidya
Hello.
There could be a simple solution, which is to use the component PanelCollection.
Drag ' drop your VO to a page and create a Table with all the attributes.
For columns that emp_id, emp_name, cost_center, set the Visible property to false.
Put the PanelCollection component on your page and drag your table inside.
When you run the page you will see the view menu in the upper left corner of the table above. You can show/hide columns in this menu.
-
Synchronization of the comments of the column from the relational model to the data dictionary?
I changed/added comments of column to a table in my relational model. When I try to sync the database data dictionary changes are never included the observations of the new column. In fact, I see that the values in the field 'Commentary in RDBMS' are different in the preview window to compare, but the line is not highlighted in red I guess that, in fact it is even dimmed. Also, I can not check the check box "selected".
Is there a way to get comments to synchronize? I don't miss any option that I first? Is this a bug or an expected behavior?
I use the version 4.0.3 x 64 of the Data Modeler.
Any help would be appreciated,
Charlie
Hi Charlie,
but the line is not highlighted in red I guess that in fact it is grayed out even.
"that means property is excluded from the comparison - the same dialog box click on tab -" Options > properties filters '-you can control the properties to include in compare it it is to say ' comment in RDBMS ' must be checked.
Press the button "Refresh trees" after the properties are set correctly.
Philippe
-
How to use the transformation script to add columns to the PK?
I'm working on a script transformation that:
-create a table
-Adds the columns to the table
-create a primary key for the tableSee the below script.
Now, I want to add the primary key column.
Documentation fix r: class IndexColumnUsageThe Index of the class has a getter: getIndexColumnUsageList()
and the list apply: applyIndexColumnUsageListSomeone at - it an idea how to use these methods to add the column to the PK?
I thank in advance.
relational = model.getDesign () .getFirstOpenRelationalDesign ();
table = relational.getTableSet () .createTable (null);
table.setName ("TABLE");
column = table.createColumn (null);
column.setName ("COLUMN");
index = table.createIndex (null);
index.setName ("PK");
index.setIndexState ("primary obligation");Hello
If you have the column and index (both belonging to the same table) use:
the index. Add (Column);
to remove the column:
the index. Remove (Column)
Philippe
-
Remove the column from the table compress
I try drop column from table DPRUEBA, with compression option:
Any idea?SQL>select * from v$version 2 / BANNER ---------------------------------------------------------------- Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bi PL/SQL Release 10.2.0.4.0 - Production CORE 10.2.0.4.0 Production TNS for Linux: Version 10.2.0.4.0 - Production NLSRTL Version 10.2.0.4.0 - Production 5 filas seleccionadas. Transcurrido: 00:00:00.09 SQL> SQL>CREATE TABLE DPRUEBA 2 (COL1 NUMBER, 3 COL2 NUMBER) COMPRESS 4 / Tabla creada. Transcurrido: 00:00:00.06 SQL> SQL>ALTER TABLE DPRUEBA DROP COLUMN COL2 2 / ALTER TABLE DPRUEBA DROP COLUMN COL2 * ERROR en línea 1: ORA-39726: operación de agregación/borrado de columnas no soportada en tablas comprimidas Transcurrido: 00:00:00.06You can always do something like this
SQL> CREATE TABLE DPRUEBA 2 (COL1 NUMBER, 3 COL2 NUMBER) COMPRESS 4 / Table created. SQL> SQL> ALTER TABLE DPRUEBA DROP COLUMN COL2 2 / ALTER TABLE DPRUEBA DROP COLUMN COL2 * ERROR at line 1: ORA-12996: cannot drop system-generated virtual column SQL> SQL> create table new_DPRUEBA 2 as 3 select col1 4 from DPRUEBA 5 / Table created. SQL> SQL> drop table DPRUEBA 2 / Table dropped. SQL> SQL> rename new_DPRUEBA to DPRUEBA 2 / Table renamed. SQL> SQL> desc DPRUEBA Name Null? Type ----------------------------------------- -------- ---------------------- COL1 NUMBER SQL> SQL> SQL> drop table DPRUEBA 2 / Table dropped. SQL> SQL>Note: you must take care of the constraints and triggers, and others
-
want to add photos from the computer memory stick or sd card
Can't seem to find how add my files on computer images to my SD card stick or the unused memory before MemoryStick only seem to be able to transfer pictures to the computer not add them to the media or card stick
Can't seem to find how add my files on computer images to my SD card stick or the unused memory before MemoryStick only seem to be able to transfer pictures to the computer not add them to the media or card stick
===============================================
Insert the SD Card/Memory Stick in your reader of media and go... Start / computer.The drive should be recognized as one or more removable disks and
each will have a drive letter.Example:
Removable disk (e :))
Removable drive (g)
Removable disk (h :))Left-click each removable disk until you reveal the directory root of the SD.
Card/Memory Stick.OK, now that you know the letter of player if you click right one selected
Group of photos or an entire folder, you should be able to choose... Send to
/
Removable disk (? :))..) .This must copy the photos to the SD Card/Memory Stick.Make sure that the photos in a folder because the number of photos you can copy
the root directory will be very limited.Volunteer - MS - MVP - Digital Media Experience J - Notice_This is not tech support_I'm volunteer - Solutions that work for me may not work for you - * proceed at your own risk *.
-
How to add photos from the photos app to lightroom?
New to photoshop or lightroom/bridge. I'm already massively confused. What I really do is process my photos and know where they are going once I press save. Frankly, I had a lot of problems who feel extremely unnecessary. For example, I download pictures from my memory card, put them in a photo album, delete the ones I don't want and then try to edit in photoshop. First of all, all the photos I already deleted are always selectable in the album, then it sucks. Then after that I edited the picture and save it, it saves it to a file of "photoshop". I don't know what it is, but whatever it is I don't know where he's going. In the same sense as this issue, several times when I have everything just to edit a photo in the photos app, and then try to download (tell Facebook or laboratory) the photo does not keep changes. I am a huge mac hater right now b/c of this.
Using Lightroom can be confusing with how he save refers to images that have been deleted. They must be removed from the LR catalog. If you use LR, all your deleting and moving files around must be made here or it turns into a big mess. I would like to move your post on LR forum for better responses.
Maybe you are looking for
-
Why the bookmarks bar does not appear on the firefox opening?
When I open Firefox from the menu bar and the Navigation bar appear. I have to go to the menu called View, scroll to toolbars, scroll down to the bookmarks toolbar, click it to get the toolbar bookmarks shown (not all bookmarks, I want that all those
-
How to remove the partition from disk on Tecra?
Any ideas how to remove the partition that Toshiba create by default when the operating system is installed?
-
Satellite L30-134, where can I get a replacement disk restore system?
I have an old L30 and have totally messed up, it runs very slowly and I was advised to do a system restore from the original disc, which I can't find, where I can get a new one for Windows XP Home edition - I still the sticker with the code produced
-
Motorola Phone Tools install problem
HP Vista 64-bit. Can I get an installer loaded, but it will not install the program completely. I had my XP and I think that the problem has to do with Vista. Is there some kind of patch or something to make it compatible? Thank you.
-
Photos app: all photo album has not all photos
Recently, I have synced my ipad, phone and computing in the cloud. "All Photos" album includes not pictures visible at the opening to the top of the icon 'photos' at the top of the page. You're like this on all the devices. Can you tell me how to mo