All data in the non-visible response file
Even if it seems that I am able to save the data in the response file, I can't see the data in all fields. He's here because when I export to a csv file it shows up. What I am doing wrong and how I can fix it? Thank you
Hi Mark,
Following link might help: help Acrobat | Collection and management of the PDF to form data
Kind regards
Rahul
Tags: Acrobat
Similar Questions
-
FDM erases all data outside the intersection given in file multiload-Using "replace".
Hello
I am a beginner in FDM and attempting to load a file of data to a specific member multiload in Essbase, but as soon as the loading is finished of FDM to Essbase I see that the data I have loaded but old data be wipe out other intersections of members. FDM is erase all data of all intersections that are not yet in my workload file. I use the option replace.
Please suggest how can I get rid of this. I want to just load a piece of data that is in my data file.
Thank you
VJ
Thanks SH and TOM, now, I have pretty good imposed by reading your responses! My problem is solved
In fact, I used option replace and 'R' as a tag of control in my multiload file, but after I changed the tag to control the form R, M, its working fine. old data on another intersection are there (for the same entity POV, category etc...) and new (file) data obtained also loaded successfully. It does not erase the old data except the intersection even given in the folder.
Is there a limitation, the disadvantage or precaution associated with this change?
Thank you
Vivek
-
How to clean all the non-essential DBF files in Oracle EBS
I have installed Oracle E-Business Suite 11.5.x and I would clean up (remove: remove) all the data files.
Is there a command I can run or run that remove all data and data files, table-spaces etc.
Thank you973807 wrote:
instead of making a new installation of the database only - I want to purge all data and the data of the existing database files
in this way, I'll save the time of installation, SID, settings etc etc...
This is was my question.You can't do that, and you need to clean up the previous installation according to the docs referenced in my previous answer, and then perform a new installation.
Thank you
Hussein -
export data from the table in xml files
Hello
This thread to get your opinion on how export data tables in a file xml containing the data and another (xsd) that contains a structure of the table.
For example, I have a datamart with 3 dimensions and a fact table. The idea is to have an xml file with data from the fact table, a file xsd with the structure of the fact table, an xml file that contains the data of the 3 dimensions and an xsd file that contains the definition of all the 3 dimensions. So a xml file fact table, a single file xml combining all of the dimension, the fact table in the file a xsd and an xsd file combining all of the dimension.
I never have an idea on how to do it, but I would like to have for your advise on how you would.
Thank you in advance.You are more or less in the same situation as me, I guess, about the "ORA-01426 digital infinity. I tried to export through UTL_FILE, content of the relational table with 998 columns. You get very quickly in this case in these ORA-errors, even if you work with solutions CLOB, while trying to concatinate the column into a CSV string data. Oracle has the nasty habbit in some of its packages / code to "assume" intelligent solutions and converts data types implicitly temporarily while trying to concatinate these data in the column to 1 string.
The second part in the Kingdom of PL/SQL, it is he's trying to put everything in a buffer, which has a maximum of 65 k or 32 k, so break things up. In the end I just solved it via see all as a BLOB and writing to file as such. I'm guessing that the ORA-error is related to these problems of conversion/datatype buffer / implicit in the official packages of Oracle DBMS.
Fun here is that this table 998 column came from XML source (aka "how SOA can make things very complicated and non-performing"). I have now 2 different solutions 'write data to CSV' in my packages, I use this situation to 998 column (but no idea if ever I get this performance, for example, using table collections in this scenario will explode the PGA in this case). The only solution that would work in my case is a better physical design of the environment, but currently I wonder not, engaged, as an architect so do not have a position to impose it.
-- --------------------------------------------------------------------------- -- PROCEDURE CREATE_LARGE_CSV -- --------------------------------------------------------------------------- PROCEDURE create_large_csv( p_sql IN VARCHAR2 , p_dir IN VARCHAR2 , p_header_file IN VARCHAR2 , p_gen_header IN BOOLEAN := FALSE, p_prefix IN VARCHAR2 := NULL, p_delimiter IN VARCHAR2 DEFAULT '|', p_dateformat IN VARCHAR2 DEFAULT 'YYYYMMDD', p_data_file IN VARCHAR2 := NULL, p_utl_wra IN VARCHAR2 := 'wb') IS v_finaltxt CLOB; v_v_val VARCHAR2(4000); v_n_val NUMBER; v_d_val DATE; v_ret NUMBER; c NUMBER; d NUMBER; col_cnt INTEGER; f BOOLEAN; rec_tab DBMS_SQL.DESC_TAB; col_num NUMBER; v_filehandle UTL_FILE.FILE_TYPE; v_samefile BOOLEAN := (NVL(p_data_file,p_header_file) = p_header_file); v_CRLF raw(2) := HEXTORAW('0D0A'); v_chunksize pls_integer := 8191 - UTL_RAW.LENGTH( v_CRLF ); BEGIN c := DBMS_SQL.OPEN_CURSOR; DBMS_SQL.PARSE(c, p_sql, DBMS_SQL.NATIVE); DBMS_SQL.DESCRIBE_COLUMNS(c, col_cnt, rec_tab); -- FOR j IN 1..col_cnt LOOP CASE rec_tab(j).col_type WHEN 1 THEN DBMS_SQL.DEFINE_COLUMN(c,j,v_v_val,4000); WHEN 2 THEN DBMS_SQL.DEFINE_COLUMN(c,j,v_n_val); WHEN 12 THEN DBMS_SQL.DEFINE_COLUMN(c,j,v_d_val); ELSE DBMS_SQL.DEFINE_COLUMN(c,j,v_v_val,4000); END CASE; END LOOP; -- -------------------------------------- -- This part outputs the HEADER if needed -- -------------------------------------- v_filehandle := UTL_FILE.FOPEN(upper(p_dir),p_header_file,p_utl_wra,32767); -- IF p_gen_header = TRUE THEN FOR j IN 1..col_cnt LOOP v_finaltxt := ltrim(v_finaltxt||p_delimiter||lower(rec_tab(j).col_name),p_delimiter); END LOOP; -- -- Adding prefix if needed IF p_prefix IS NULL THEN UTL_FILE.PUT_LINE(v_filehandle, v_finaltxt); ELSE v_finaltxt := 'p_prefix'||p_delimiter||v_finaltxt; UTL_FILE.PUT_LINE(v_filehandle, v_finaltxt); END IF; -- -- Creating creating seperate header file if requested IF NOT v_samefile THEN UTL_FILE.FCLOSE(v_filehandle); END IF; END IF; -- -------------------------------------- -- This part outputs the DATA to file -- -------------------------------------- IF NOT v_samefile THEN v_filehandle := UTL_FILE.FOPEN(upper(p_dir),p_data_file,p_utl_wra,32767); END IF; -- d := DBMS_SQL.EXECUTE(c); LOOP v_ret := DBMS_SQL.FETCH_ROWS(c); EXIT WHEN v_ret = 0; v_finaltxt := NULL; FOR j IN 1..col_cnt LOOP CASE rec_tab(j).col_type WHEN 1 THEN -- VARCHAR2 DBMS_SQL.COLUMN_VALUE(c,j,v_v_val); v_finaltxt := v_finaltxt || p_delimiter || v_v_val; WHEN 2 THEN -- NUMBER DBMS_SQL.COLUMN_VALUE(c,j,v_n_val); v_finaltxt := v_finaltxt || p_delimiter || TO_CHAR(v_n_val); WHEN 12 THEN -- DATE DBMS_SQL.COLUMN_VALUE(c,j,v_d_val); v_finaltxt := v_finaltxt || p_delimiter || TO_CHAR(v_d_val,p_dateformat); ELSE v_finaltxt := v_finaltxt || p_delimiter || v_v_val; END CASE; END LOOP; -- v_finaltxt := p_prefix || v_finaltxt; IF SUBSTR(v_finaltxt,1,1) = p_delimiter THEN v_finaltxt := SUBSTR(v_finaltxt,2); END IF; -- FOR i IN 1 .. ceil( LENGTH( v_finaltxt ) / v_chunksize ) LOOP UTL_FILE.PUT_RAW( v_filehandle, utl_raw.cast_to_raw( SUBSTR( v_finaltxt, ( i - 1 ) * v_chunksize + 1, v_chunksize ) ), TRUE ); END LOOP; UTL_FILE.PUT_RAW( v_filehandle, v_CRLF ); -- END LOOP; UTL_FILE.FCLOSE(v_filehandle); DBMS_SQL.CLOSE_CURSOR(c); END create_large_csv; -
How to save data from the COM port to file?
Hi all
can someone tell me please how to save data from the COM port on file? I transfer 1 byte of serial port... attached is the image of the vi... very basic.
I would like to save the data in a table... I mean, 1 data--> data--> data tab 2 tab 3rd--> tab
and so on... can anyone help?
-
How can I force the Finder to show all files in a folder of Capitan 10.11?-instead of always having to click on "Show all" to see the full selection of files.
It is not often that I said ' what are you talking about"but" what are you talking about? "
I do not know of all "show all" in the Finder. Can you provide a screenshot?
-
component AF:chooseDate - how to disable all dates in the past.
Hi, I need to disable all dates in the af:chooseDate component.
I should probably use DateListProvider for that, but don't know how.
Thank you.
KT - thank you very much.
My bad, I completely missed the af minDate property: chooseDate.
Exactly what I needed.
-
How to connect sql database to esxi to save all data from the virtual machine
How to connect sql database to esxi to save all data from the virtual machine
Please provide steps
In simple terms, you cannot connect ESXi to SQL. Connect a vCenter SQL (Windows only).
If you want to save all the data that is contained in your virtual machines, I suggest a backup solution.
Suhas
-
Add the non-visible section on data of Formulation O/P ext
Hi I am using A6.1.1 version. I get as a result of problems during the creation or modification of a record of formulation:
1. the FormulationOutput > > ExtData > > add custom button Section or add an extended attribute is not present.
2. automatically Referesh is by default active to come.
3. No Add-button option on compliance, the elements of Nutrition.
4. Similarly USD/100 g is coming as non-editable in the entries.
5. access level is not visible.
and there are countless other things am not able to see that I used to see in previous versions.
The user that I use is ProdikaAdmin have all access and checked the EnvironmentSettings, the CoreAppSettings, the BaseFeatureConfig, CustomerSettings config files but was not able to solve this problem.
I just Guide to Configuration and Guide of security and Configuration settings checked still am face this problem.
Can you please tell me what to do to put things in place.
Thanks in advance
Please ensure current state of the workflow of spec of Formulation is "Designable" tag.
-
Today, I went looking for records in my computer containing files larger than 300 MB. To my surprise, two records that presented themselves are in... / AppData/Roaming/Thunderbird/Profiles/pt66rib2.default/Mail/mail. (my server). There are 355 MB of data in the "Junk" file (which has no file extension) and 577 megabytes of data in the "Inbox" file (which has also no file extension). When I open the files in the laptop ++, I found that the data is every email that's ever been in my Inbox. (Gee, I wonder if the it Department to the IRS has never thought to check there for lack of laws Lerner emails?) For the record, I suggest all my messages in my Inbox and 'Empty junk' into the Junk folder (in the Thunderbird e-mail program) every day. Why is-all data still here? What is the fastest way to remove or erase data?
_ http://KB.mozillazine.org/Thunderbird: _Tips_:_Compacting_Folders
-
How to get a date to the timestamp of a file XML format
Hello
I'm trying to get a date from an external XML file. My XML file looks like this:
<>http://www.NI.com/LVData">
8.6.1
Date of birth
31/03/1983
I can get the system to retrieve the correct XML element that shows the
nested and elements , but I have no way to retrieve correctly the date. It seems as if she interprets my date seconds since 1904. I try to keep the "readable" for the end user XML, so it is important to keep this date in standard U.S. date format. I eventually uses this date to calculate the age of something. I labour code to subtract a timestamp in the format of the date to the current date and time, but I can't access it when I get back from XML. Starting from XML schema, it looks like the timestamp element requires a cluster... but there is no documentation on what to spend. Any ideas how to get back an XML date in this format in a simple and clean?
Here's my current VI:

Thank you
Ryan
Cambridge, MY
Quick Tip on "bundle by name. You don't need to consolidate all these constants where the values correspond to what is the constant of cluster at the top. The cluster constant defines the data structure and the starting values. Simply group the values for specific change items.
Example of tone would be a bit cleaner. Although the format string should use a capital T.

As always with dealing with the time, complications could arise due to dealing with time zones and leap years. Zones shouldn't matter for the calculation of the years since you are rounded up to years. Although you probably want to round down rather than round at most closely. (I forgot this part in my example). The problem with leap years when you would be only in a certain number of days of the anniversary, he would round up the age. The number of rounded days would depend on how much on leap days that nobody has seen in their lifetime.
-
All bookmarks are still on my mobile. I can see and access. When using the synchronization options, then clicking on the fact, absolutely nothing happens. The bookmarks are always on my mobile and not transferred to office.
Hello!
I am trying to understand the workflow in detail. Let me explain quickly what is the right process:
- Sync your phone to your desktop (you already did that)
- Clean your computer (you already did that)
- Follow these steps in the newly installed Firefox https://support.mozilla.com/en-US/kb/How%20to%20sync%20Firefox%20settings%20between%20computers?s=sync & r = 3 & as=s#w_what-if-im-not-near-my-first-computer
That of all, make sure you have the key to Firefox Sync in order to access your Firefox Sync account again. Do not create a new or if not you will remove the data from the server. If you have lost your key synchronization, you can get it from your phone by installing the add-on on your Android device: https://addons.mozilla.org/en-US/mobile/addon/aboutsynckey/
I hope this helps you.
-
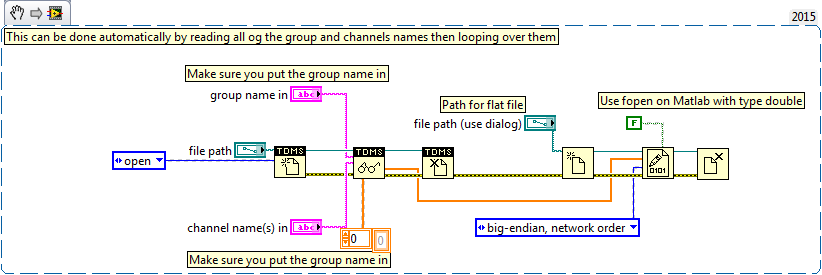
Writing data to extend the acquisition of data for the sampling rate high file
These are the tasks that I have to do to take noise measurements:
(1) take continuous data to USB 6281 Office, in a sample of 500 k (50 k samples at a time) rate.
(2) save data continuously for 3 to 6 hours in any file (any format is OK but I need to save in a series of files rather than the single file). I want to start writing again file after every 2 min.
I enclose my VI and pictures of my setup of the task. I can measure and write data to the file continuously for 15 minutes. After that, I see these errors:
(1) acquisition of equipment can't keep up with the software (something like that, also with a proposal to increase the size of the buffer...)
(2) memory is full.
Please help make my VI effective and correct. I suggest to remove him "write in the action file" loop of consumption because it takes a long time to open and close a file in a loop. You can suggest me to open the file outside the loop and write inside the loop. But I want to save my data in the new file, after every 2 min or some samples. If this can be done efficiently without using Scripture in the measurement file then please let me know.
Thank you in advance.
This example here is for a single file and a channel, you should be able to loop over that automatically. The background commentary should be the name of the channel, no group namede the name of the channel in the control.
-
4.0 ai2: wish that the export for not writing tool option date in the output of export file
Hello
The new export feature Cart in 4.0 that can be run as a command of sdcli is a very popular feature
As an improvement, I would like to see an option in the export tool where it is possible to choose whether the date should be
written in the file result of export or not. Currently, it is always written in the output of export file.
Why I don't want a line whose date is when you create one or more result export files, using the
function directly in a directory of the source code management, for example a SubVersion directory, the export of the basket sdcli
will be almost always indicated as changed because of the line with the date, even if the exported data are unchanged.
Would it not possible to add such export tool option for the new version 4.0 of SQL Developer?
With sincere friendships.
Christian
There is now a preference to determine the behavior of date. This just missed getting into ai2 but will be there in the next EA.
-
Write and read data from the user's local file system
Hello
I write my first extension for dreamweaver. My extension should backup the data on the local file system of the user. I know that I can use DWfile.read () and DWfile.write () as described in Chapter 2 of the Dreamweaver API reference. I store the data using the XML format. What is the best way to read and parse the XML data in the file? What is the best way to write the XML data in the file?
If you recommend one format other than XML, I'm open to suggestions. The data are only a few configuration information for the extension which should be persisted.
Thank you
mitzy_kitty
How will the data be used? If it is used by JavaScript, use JSON format which includes js. If you use XML, then you will need to find an XML parser to read the data.
Randy
Maybe you are looking for
-
Can I delete a profile folder if it is empty?
After update of FF 36.0.4, I did a regular maintenance; cleared the cache, history and cookies. Went to restart FF later and unfortunately it does not open. I followed the instructions to support FF to locate my profile folder, trashed the prefs.js f
-
iPhone 5 s: green screen, shut off and now won't turn on
Hi, I have reviewed to answer but didn't find any. Last night when using my iPhone, DO NOT watch a video, my screen turned green then black. I could see that he was always so I tried to reset the thing by activating the only two keys got my iPhone! H
-
Satellite A110-156 - touchpad doesn't scroll
Hi guys,. in 2007, I bought my Toshiba Satellite A110-156, shortly after I have vista home Toshiba as a gift for my new laptop.All right, only my touchpad to scroll. After a new version of the 703014 driver, it works.Only vista keeps naggin at first
-
Model Lifecam HD 5000 bought a few days before Christmas, so it has been used for a few days.
-
LaserJet Pro 200 color M27nw: Scan works in wifi and not available on USB key intermittently
I am a M27nw of Color LaserJet Pro 200 and under Mac OS X 10.10. The printer connects OK via wifi, but the analysis fails often. Sometimes it hangs and fails when parsing the preview. Sometimes the scanner window opens but nothing happens and ever