Best way to index a table for display
I often do something like this for indicators on a Panel, as you can see the block diagram is messy and it takes a lot of space.
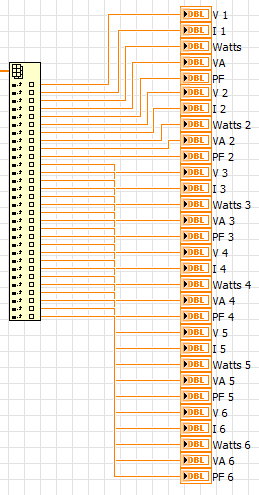
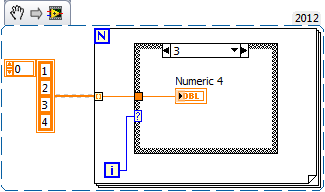
There must be a better way.
You can also use auto-indexation with a structure in case of having a cleaner schema.
Tags: NI Software
Similar Questions
-
What is the best way to store the RCS for an insert/update in this rec
Oracle on Win 64 non-conteneur 12.1.0.2
When a record in one table is inserted or updated, what would be the best way to store the RCS for this record in this folder.
I thought of a line after trigger, but did not know if this trigger to store the current_scn would still fire that trigger again (recursive trigger).
Someone at - he a good idea of what the best way is to do? The devs don't want to store the pk and the SNA in yet another table...
Yes, row_dependencies would be the best way to go. But mgmt doesn't recreate all tables for this.
3rd party applications retrieve data from tables (all data). We are looking for a way for them to just pull what is new or updated updated since their last sweater.
I suggest that you try again and give all OF THE REQUIREMENTS.
You have rejected ANY answer given and he justified using 'hidden' on what knowledge management or the devs want or do not want to. Stop making us guess what are the requirements and constraints. If you want a real answer then tell us ALL the news.
When a record in one table is inserted or updated, what would be the best way to store the RCS for this record in this folder.
Solomon answered repeatedly. If you want to add a column to a table to store the then "best" SNA is to let the Oracle to do this for you automatically by using the DEPENDENCY LINE.
As he says also re-create the table to add this clause will be MUCH MORE EFFECTIVE that everything THAT you can do it manually. It will be also more accurate because Oracle will fill the value ORA_ROWSCN with the SNA at the time the line was committed. You, as long as user, can't fill a column in function when a line is engaged since real VALIDATION belongs to a transaction, not the line or the trigger that you use.
Yes - there are two drawbacks to this method:
1. you need to re-create the table
2. you cannot add an index to this "hidden" column
The devs don't want to store the pk and the SNA in yet another table...
Then? Who cares what the devs want to do? You want the BEST solution? Next, you will need to put aside personal preferences and determine what is the 'best' solution. Why it is important that certain dev wants to do this or not?
OK, the problem of biz is now, 3rd party external users are an all-wheel drive large number of tables in the database via the API that we wrote. That was obviously interrupted OLTP during the day. To reduce to the minimum, we want for them just to extract data that has been inserted/updated since their last sweater.
It is the definition of a "replica" DB Then why don't you consider a real replicated DB? You can use DataGuard and have replicated DB which is read only that can be used to generate reports. Oracle does ALL the work to keep ALL the tables in sync. You and your developers do NOTHING!
We thought that store the RCS higher their last sweater would allow the API to extract only data with YVERT higher than their last data pull CHN.
OK - except you keep rejecting solutions actually do. Ask you questions about the SNA stored in the same table, but then reject the solution that does this. And then you add your "devs" don't want to store the info in a new table either.
Then your solutions must ONLY use the replication or Log Miner. The REDO logs have all changes, if you want to extract yourself. Replication (e.g., DataGuard) will use these logs for you to maintain a replicated database.
We thought about it, but recreate all tables in production with ROWDEPENDENCIES as well as dealing with CF and other dependencies idea this was shot.
Well you NEVER mentioned you "thought that" and rejected it. And you NEVER mentioned anything about FKs and other dependencies. What is FKs and other dependencies which prevents this working solution? Tell us! Give us ALL the information.
Wouldn't a trigger AFTER LINE capture the commit YVERT? Or is after really not after validation?
No - a trigger has NOT one commit. A trigger runs as a step in a transaction. Validation applies to the entire transaction. Until you, or Oracle, issues a commit, there is NO "committed SNA" to be stored as ORA_ROWSCN.
You can easily see that for yourself. Create a simple table with dependencies of the line and then update two different sessions.
create the table emp_scn rowdependencies in select * from emp where rownum<>
Select empno, emp_scn ora_rowscn
Update emp_scn set work = 'b' where empno = 7499
commit;
The first SELECT statement will show you that each row has the same SNA.
EMPNO, ORA_ROWSCN
7369,70622201
7499,70622201
7521,70622201
Now, do the update (but no commit), then SELECT it
EMPNO, ORA_ROWSCN
7369,70622201
7499,
7521,70622201
Where is the value of 7499? This session will NOT see a value for the changed lines in the current transaction. Other sessions will still see the old value.
Now do the validation, then SELECT
EMPNO, ORA_ROWSCN
7369,70622201
7499,70622301
7521,70622201
7499 now has a new and different value than the other lines. It will not be this new value until the validation occurs.
Yes, row_dependencies would be the best way to go. But mgmt doesn't recreate all tables for this.
Well, you got the answer you want. You ask the best way. Now, you say that you were told the best way. But now you don't like the answer.
How is it our fault? Your question has been answered wasn't she?
Here are the facts:
1 oracle creates a history of changes - the REDO log files
2. you can use Log Miner to extract these changes
3. you can create your own change log by adding a log file of MV to your table.
4. you can then write a custom code to use this MV log file to determine which rows to "reproduce".
So far reject you all THE POSSIBLE solutions.
Accept it or change the requirements to allow one of the solutions proposed to be used.
Personally, if I HAD to use a customized solution, I would use a MV journal to record the ROWID of the lines that have changed (for tables ROWID cannot be changed). I would then extract the appropriate lines by pulling on the lines corresponding to these row ID.
Even that has problems since a line can be changed several times and children lines can also be amended several times - these questions FK you mentioned.
I suggest you read this entire thread on AskTom a dozen years ago. It addresses ALL these issues.
https://asktom.Oracle.com/pls/Apex/f?p=100:11:0:P11_QUESTION_ID:16998677475837
Then in your next reply on this topic give us a summary of where some things with your question and what help you further expect.
-
What is the best way to refresh the table after autosubmit (10.1.3.4)
What is the best way to refresh the table after autosubmit?
I have a page that contains a table where if one of the fields is changed it autosubmitted where the view object changes some attributes, based on the field having been changed. I need these modified attributes that appear in the table. But without doing anything, the only way to see these values is to cause the iterator updated table.
I've been refreshing the table is having a method in a grain of beacking called "getSystemSettingIter.getCurrentRow ();". This seems to be a bit of a hack for me and I was wondering if there is a better way to get the table to update.
Thanks in advance!Have you tried setting between the two partial page refresh?
http://www.Oracle.com/pls/as111120/lookup?ID=ADFUI385http://download.Oracle.com/docs/CD/E15523_01/Web.1111/b31974/web_form.htm#CACEIEEI
-
What is the best way to create the layout for a single page website in Adobe Muse?
I was wondering the best way to create the layout for a single page website in Adobe Muse. Does anyone have any suggestions?
You can have access to this tutorial (and their other) a month for only $9.99. Is it too expensive for you!
-
What is the best way to clear a table? (performance and resources)
Array.Length = 0;
array = [];array.splice(0);Array.Length = 0;
-
Best way to generate a PWM for a stint with LabView2010 and a laptop
Hello
as mentioned in the title, I'm looking for the best way to generate a PWM signal to a relay. I want to use a laptop computer and the LabView2010 for she. I have read through several topics, but after a time that he just got more confused. For example the NI USB-6008 OEM case seems to be a solutiion at low prices, but I don't know if I can use for the generation of PWM signals like this thread says is not possible:
http://forums.NI.com/T5/Multifunction-DAQ/using-PWM-on-NI-6008/m-p/231860/highlight/true#M13339
But then again this thread right here makes it seem as if it was doable:
http://forums.NI.com/T5/Digital-I-O/generating-a-PWM-using-USB-6008/m-p/421654/highlight/true#M5527
Once again in abbreviated form.
What I need:
-the best way to generate a PWM signal to control a relay
What I have so far:
-LabView2010
-Laptop
If possible, it would be good to have two channels for two separate signals, but it is more low importance right now.
Hey Kambra,.
The first thread you mention is correct, you can't make output PWM in any deterministic mode with a 6008. The 6008 is strictly software timed, which means that each digital writing that is done in the unit must go through the operating system and down to the device. And there is a lot of jitter of the involved BONE. The second article you mention says the same thing. They emphasized that they could reduce the jitter of some, but still can not remove it entirely. In the second thread, they mention using a M-series USB device do output PWM deterministic (timed material).
The compromise really down to your application and its requirements. If your application to control the relay requires no determinism, then you can use the 6008. If you need precise control over the relay, try the USB M series.
-
Volume: Best way to decrease the volume for a portion of a clip
I have an audio clip of speaking me - about 22 minutes. I knew it would be difficult to change because of its length, so I divided into eight sections and each section has recorded independently.
However, I made a couple of mistakes here and there. So instead of wasting time to record a whole clip again and again until I understand well, I have just re-recorded paragraphs which should be corrected.
So, imagine a master audio clip named Project1 in setting up first. In the track above, where the third paragraph starts, is another audio clip - Project1-3. I'm trying to understand the best way to kill the volume on Project1 - just for the duration of the third paragraph. So when I listen, I should hear the patch, Project1-3, instead of the main audio, Project1.
I checked a few tutorials, but I'm a bit confused. I thought it was something I have to do in the Source monitor, by using keyframes, but it does not work too well.
I put a screen shot in line @ https://www.geobop.com/images/audio.png
In the upper left corner, you can see where I created a key by clicking on the Volume and selecting the level. It was set to 0 by default, so I changed the value of-20. But when I preview the video, I can still hear the sound and changes in value-20.
Can someone tell me what I am doing wrong?
Thank you.
Rather than apply keyframes to the Volume setting, you will find may be easier to use the razor tool to split the audio clip called "Project1" into several segments in the timeline panel. Then, disable the unwanted segment (select it in the timeline panel and choose Clip > enable) or raise TI (press point comma), leaving a space.
Your tracks can be difficult to hear suddenly as the stopwatch for the effect of Volume Audio is enabled by default. If you look at the effect controls panel, while the audio is selected, you can proceed to the next and previous keyframe to see what 'level' to each key frame.
-
best way to specify a folder for a new virtual machine
Hello
I am currently working on a system that has the following file structure:
DC1
Prod
Linux
Windows
Other
Dev
Linux
Windows
Other
Beta
Linux
Windows
Other
What is the best way to specify a specific folder for a new virtual machine. At the Moment so I just say Linux it is said that there are several files with the same name. I discovered a way to get the good record, but it's very nearby. Any comments would be much appreciated.
Kobus
Perhaps the function in my folder through post might help?
-
Best way to update a table with separate values
Hi, I would really appreciate some advise:
I need to regularly perform a task where I update 1 table with all the new data that has been entered in another table. I cannot perform a complete insert because this will create data duplicated each time it works, so the only way I can think of is the use of cursors in the script below:
CREATE OR REPLACE PROCEDURE update_new_mem IS
tmpVar NUMBER;
CURSOR c_mem IS
SELECT nom_membre, member_id
OF gym.members;
CREC c_mem % ROWTYPE;
BEGIN
OPEN c_mem.
LOOP
SEEK c_mem INTO crec;
EXIT WHEN c_mem % NOTFOUND;
BEGIN
UPDATE gym.lifts
Name = crec.member_name
WHERE member_id = crec.member_id;
EXCEPTION
WHEN NO_DATA_FOUND THEN NULL;
END;
IF SQL % NOTFOUND THEN
BEGIN
INSERT INTO gym.lifts
(name, member_id)
VALUES (crec.member_name, crec.member_id);
END;
END IF;
END LOOP;
CLOSE C_mem;
END update_new_mem;
This method works, but y at - it a (faster) easier way to update another table with new data only?
Thank you very much>
This method works, but y at - it a (faster) easier way to update another table with new data only?
>
Almost anything would be better than this treatment of slow-by-slow loop.You don't need a procedure, you should just use MERGE for this. See the examples in the section of the MERGER of the doc of the SQL language
http://docs.Oracle.com/CD/B28359_01/server.111/b28286/statements_9016.htmMERGE INTO bonuses D USING (SELECT employee_id, salary, department_id FROM employees WHERE department_id = 80) S ON (D.employee_id = S.employee_id) WHEN MATCHED THEN UPDATE SET D.bonus = D.bonus + S.salary*.01 DELETE WHERE (S.salary > 8000) WHEN NOT MATCHED THEN INSERT (D.employee_id, D.bonus) VALUES (S.employee_id, S.salary*.01) WHERE (S.salary <= 8000); -
What is the best way to create a bookmark for a user to return?
Hello to all... hello again Steve... I'm back with another question - what is the best way to set up a bookmark system so return users can pick up where they left off in a lesson of AW? I tried the usual internet research, always do, but a few samples and answers I found were AW5, not a lot of help...
I have a dozen or so cards attached to my frame, I would like a user to return to the last card that he read before the close. (My AW communicates very well with database Access, so if passing a variable to access and back to AW when begins the lesson is on track, let me know...) If the answer here is too complicated, perhaps pushing me in the right direction and I'll me dive in.
Thanks in advance to all those who have some tips, I really appreciate it!
Terry
Try this overview, see if it helps...
Enter a reference to the map as you enter, then save to the database when you exit.
You want something that will give you the equivalent of a page number - if you have 7 cards hung the setting, and the user is in the 6th plan when it stops, you want to save the number 6.
There are dozens of ways to do it, but probably the easiest way is just to attach a calc to each card that has this code
(I do not have Authorwar very convenient to check the syntax, then you should check out!)
BookMarkPage = ChildIDtoNum (IconParent (IconID), IconID)<-- tells="" authorware="" to="" return="" the="" "page="" number"="" of="" the="" current="">
Save BookMarkPage in your Access database to the exit.
In return, read the bookmark in BookMarkPage, ask the user if he wants to go back to the bookmark. If so, use a calculated navigation that uses
ChildNumToID (@the of your frame name or its ID, BookMarkPage)
Note that you could argue something similar by recording the your card, the IconTitle or IconID but these two can break if never update you your file by adding or removing pages, renaming etc. With this method, all you need is a simple page County check that makes sure you don't try to nav for a page number that does not exist (use IconNumChildren).
Steve
-
What is the best way to get a Table name in Oracle Applications: 12.1.1 (web)
Hello friends...
I need your help my friends...
We are currently working on Oracle Applications: 12.1.1
I would like to know the best way to get the name of the Table to form based on a Web...
Concerning
Yas.Hello
Please see this thread and documents referenced in it.
RECORD HISTORY (or) COLUMNS in R12?
RECORD HISTORY (or) COLUMNS in R12?Kind regards
Hussein -
best way to create a table based on another table
Hello
I am trying to create a table based on another table with all the data in it. It contains important data.
create table < tablename > select * from table1.
Is the best way to do it, or is there another way. Please advice.
Thank youInsert / * + append * / in
as select * from ; It should be->
insert /*+ append */ intoselect * from ; Kind regards.
LOULOU.
-
Best way to parse a string for use in a lookup table?
I am trying to create a system by which users can create a premade simulation and store simulations in order to easily load at their convenience. The way it works now is that when the user creates a simulation, information on the characteristics of the simulation are condensed down to a 12 string, which is written in a text file with the same name as its content. This string is then read, and ideally, I would have some sort of lookup table to convert characters in the information they have been condensed to. For example, a variable X can have possible values {650,720,851} who gets the mapping to {A, B, C} during the creation process. When loading, I would be able to send in a Sub C - VI and took her out in 851, group in a cluster. How can I perfectly realize this in LV? So far the best I have is this messy thing:

Basically, who runs the string character by character and includes the appropriate value for the character at the given offset.
You want to use the configuration VI palette.
These screws makes it stupid simple save and load the values in the file by using Sections and keys.
You can use the keys 'A', 'B' or 'C' and section 'X' to complete your example.
-
Best way to resolve this table?
Lets say you're dealing with these two tables:
CREATE TABLE VEHICLES
(
NUMBER OF VEHICLE_ID
VEHICLE_NAME VARCHAR2 (100 BYTE),
NUMBER OF MILES
);
CREATE TABLE VEHICLE_PARTS
(
NUMBER OF PART_ID,
VEHICLE_ID NUMBER OF NON-NULL,
PART_TYPE NUMBER OF NON-NULL,
PART_DESCRIPTION VARCHAR2 (1000 BYTE) NOT NULL,
START_SERVICE_DATE DATE NOT NULL,
DATE OF END_SERVICE_DATE,
PART_TYPE_NAME VARCHAR2 (100 BYTE)
);
And some data for example as follows:
Insert into VEHICLES (VEHICLE_ID, VEHICLE_NAME, MILES) Values (1, "Honda Civic", 75500);
Insert into VEHICLES (VEHICLE_ID, VEHICLE_NAME, MILES) Values (2, 'Ford Taurus', 156000);
Insert into VEHICLE_PARTS
(PART_ID, VEHICLE_ID, PART_TYPE, PART_DESCRIPTION, START_SERVICE_DATE, END_SERVICE_DATE, PART_TYPE_NAME)
Values
(1, 1, 1, "1.4 VTEC",)
TO_DATE('07/07/2009_00:00:00',_'MM/DD/YYYY_HH24:MI:SS'), TO_DATE (3 MAY 2010 00:00:00 "," MM/DD/YYYY HH24:MI:SS'), "ENGINE");
Insert into VEHICLE_PARTS
(PART_ID, VEHICLE_ID, PART_TYPE, PART_DESCRIPTION, START_SERVICE_DATE, PART_TYPE_NAME)
Values
(2, 1, 1, "1.6 VTEC",)
TO_DATE('05/03/2010 00:00:00', 'MM/DD/YYYY HH24:MI:SS'), 'ENGINE');
Insert into VEHICLE_PARTS
(PART_ID, VEHICLE_ID, PART_TYPE, PART_DESCRIPTION, START_SERVICE_DATE, END_SERVICE_DATE, PART_TYPE_NAME)
Values
(3, 1, 2, 'Happy new year all seasons',)
TO_DATE('07/07/2009_00:00:00',_'MM/DD/YYYY_HH24:MI:SS'), TO_DATE (10 AUGUST 2010 00:00:00 ',' DD/MM/YYYY HH24:MI:SS'), 'TYRES');
Insert into VEHICLE_PARTS
(PART_ID, VEHICLE_ID, PART_TYPE, PART_DESCRIPTION, START_SERVICE_DATE, PART_TYPE_NAME)
Values
(4, 1, 2, 'Bridgestone Blizzaks',)
TO_DATE('08/10/2010 00:00:00', 'MM/DD/YYYY HH24:MI:SS'), "TIRES");
Insert into VEHICLE_PARTS
(PART_ID, VEHICLE_ID, PART_TYPE, PART_DESCRIPTION, START_SERVICE_DATE, PART_TYPE_NAME)
Values
(5, 2, 1, "3.5 L Duratec",)
TO_DATE('06/01/2008 00:00:00', 'MM/DD/YYYY HH24:MI:SS'), 'ENGINE');
Insert into VEHICLE_PARTS
(PART_ID, VEHICLE_ID, PART_TYPE, PART_DESCRIPTION, START_SERVICE_DATE, END_SERVICE_DATE, PART_TYPE_NAME)
Values
(6, 2, 2, 'Happy new year all seasons',)
TO_DATE('06/01/2008_00:00:00',_'MM/DD/YYYY_HH24:MI:SS'), TO_DATE (15 MARCH 2009 00:00:00 ',' DD/MM/YYYY HH24:MI:SS'), 'TYRES');
Insert into VEHICLE_PARTS
(PART_ID, VEHICLE_ID, PART_TYPE, PART_DESCRIPTION, START_SERVICE_DATE, END_SERVICE_DATE, PART_TYPE_NAME)
Values
(7, 2, 2, 'Michelin All-Seaon',)
TO_DATE('03/15/2009_00:00:00',_'MM/DD/YYYY_HH24:MI:SS'), TO_DATE (12 JANUARY 2011 00:00:00 ',' DD/MM/YYYY HH24:MI:SS'), 'TYRES');
Insert into VEHICLE_PARTS
(PART_ID, VEHICLE_ID, PART_TYPE, PART_DESCRIPTION, START_SERVICE_DATE, PART_TYPE_NAME)
Values
(8, 2, 2, "Nokian")
TO_DATE('01/12/2011 00:00:00', 'MM/DD/YYYY HH24:MI:SS'), "TIRES");
And you need produce a view that shows the flattened attached data where each vehicle has one row with columns representing their most recent part (which has a service as Start Date of null terminator).
Like this:
Car: Engine: tires:
Honda Civic 1.6 VTEC Bridgestone Blizzaks
Ford Taurus 3.5 L Duratec Nokian
There he has a fast and efficient to do that?
My current approach, which is the brute force method is to have a separate outer join for each column, I need to shoot with the condition of max (START_SERVICE_DATE) to get the current part for each type (engine, tires, etc...).
but its so slow and painful code.
I thought pivot but I don't think that Pivot help here since there is no aggregation going, right?
Anything with the partition could over aid? IM unfamiliar with this syntaxHello
Trant says:
Lets say you're dealing with these two tables:CREATE TABLE VEHICLES
(
NUMBER OF VEHICLE_ID
VEHICLE_NAME VARCHAR2 (100 BYTE),
NUMBER OF MILES
); ...Thanks for posting the CREATE TABLE and INSERT statements; It's very useful!
I thought pivot but I don't think that Pivot help here since there is no aggregation going, right?
Pivot is always aggregation; you take any number of rows in the table and only one line display. It is the aggregation.
Anything with the partition could over aid? IM unfamiliar with this syntax
Yes: ROW_NUMBER analytic function can help to identify the most recent line for each vehicle_id and part_type_name in vehicle_parts.
Here's a way to do it:
WITH got_r_num AS ( SELECT vehicle_id , part_description , part_type_name , ROW_NUMBER () OVER ( PARTITION BY vehicle_id , part_type_name ORDER BY start_service_date ) AS r_num FROM vehicle_parts WHERE end_service_date IS NULL ) SELECT v.vehicle_name , MIN (CASE WHEN r.part_type_name = 'ENGINE' THEN r.part_description END) AS engine , MIN (CASE WHEN r.part_type_name = 'TIRES' THEN r.part_description END) AS tires FROM vehicles v LEFT OUTER JOIN got_r_num r ON v.vehicle_id = r.vehicle_id WHERE r.r_num = 1 GROUP BY v.vehicle_name ORDER BY v.vehicle_name ;You must add another column in the main query for each part. It's just one line of code, not nearly as bad but to join another subquery.
Whenever you have a problem, don't forget to tell what version of Oracle you are using.
The above query will work in Oracle 9 (and), but if you have Oracle 11, you'll want to use SELECT... PIVOT. -
What is the best way to move the node for virtual device to an IDE SCSI hard drive?
I used PowerCLI on vSphere 5.0 5.5.
I'm deploying VMDK that were created with a switch in Ghost from Symantec, which by default is the HDD to IDE interface. How can I change the HD of IDE, SCSI using PowerCLI?
We also seek to regenerate the VMDK with the correct setting in Ghost, but maybe it's not feasible.
I looked at the post below, which seems close, but don't tell me how to change the Type as the disk ID number.
Sort of put the virtual device node / drive SCSI ID?
When I look at the vmdk on the host for the virtual machine, I can see that the ddb.adapterType field is set to "ide" and KB 1016192 - conversion of an IDE virtual disk to a virtual SCSI disk
I need to have the value of "free", but I can't manually change the vmdk file.
In addition, the hard drive has the VM operating system already installed on it, so I don't want to just remove it.
Another related problem is that I can not put the type of SCSi LSI Logic SAS controller LSI Logic parallel (Windows VMs does not start if it has the value LSI Logic SAS). I just get an error "inconsistent backup specified for device 0.
Appreciate any ideas.
I thought that I would come back and update this post. I got it works by changing a setting when I create the VMDK.
I changed the way I created the VMDK via the Symantec ghost32.exe (version 11.5?) application by adding the following switch:
-vmdkAdapter = free
Ghost32-clone, mode = restoration, src = 'SRC %', dst = "% DEST" - vmdkAdapter free course =
It worked for my Windows 2008 VMDK, don't know what he'll do for any other type.
At the end of the day, I have never able to edit the VMX of PowerCLI file, although I got close enough.
Regarding PowerCLI, I think I have corrupted files on the ESXi server and could never get around it. The steps were roughly as follows
1. the Copy-DatastoreItem cmdlet to copy the file vm.vmx on the desktop of the local computer
"2 use Get-Content to read file and change ddb.adapterType ="ide"with ddb.adapterType. =" free ".
3. copy a ConvertTo-LinuxLineEnding cmdlet from the internet and remove CR/LF characters to the BYTE level; because nothing else has worked. I still don't think it worked 100%.
4 copy-DatastoreItem to copy the vmx file to the directory of the virtual machine.
The vmx file has the correct setting and looks ok, but I think something is broken here, because when I use the VI Client to look at the data store, there are only 2 files in the directory. I don't know which more.
5 remove-hard drive
6 New-hard drive - vm $vmObj - diskpath "[datastoreName] vm/vm.vmdk", at this point, I get "the path of the specified disc is inaccessible or does not exist. It is probably because I have damaged the structure of files on the data store.
When I delete the virtual computer in the VI Client, I can remove it with success, but I have to manually delete the directory on the data store using skip
Control data store.Maureen
{kind=link}
Maybe you are looking for
-
They had a few beers and one of them protected by my BIOS (Administrator), I was a bit unhappy about in order to know who did (if he remembers it still) could use some help on the back door, after 3 wrong attempts it shows [I 58726713] Thank you "Dam
-
The 1473R CAN be used with the real-time operating system of NOR?
Hello, I am trying to determine if I can use the OR 1473R framegrabber PCIe FPGA in a PC based computer time real OS OR. Anyone know if this is possible? So I think that it should appear to the OS in real-time as a target FPGA that can transfer the d
-
I adjusted inadvertently of my motorcycle G so that the smartphone Office now has a white background, and pictures on the phone without color. I've included a screenshot of the desktop, smartphone and a sample of photography affected as an attachment
-
Why my version 5.0.2 PES does not start after closing after a successful logon. I run on Windows 7
!
-
Hey man,I was wondering how do I make my sensitive site - so it changes in response to this device, it is used, please?I'm pretty new to all this so if anyone has recommendations here is the Web site - http://www.prime-ticket.com