Column update with random values
Hi allI have a chart in which one of the columns contains the number. I want to write a script that will update the column number with different random values.
Basically, my script should take the first line of a table and should update with a random value in the second loop, it must update the column with a random value.
I need a simple PL SQL code to do this.
Thanks in advance.
Thank you.
Kind regards
Dirasa
or
update table_name set column_name=round(dbms_random.value(1,100));
Do not loop, this single update statement will satisfy your need by your request above.
arguments passed in 1 100 are the lower and upper limit to generate random numbers. like 5,1,45,64,23 etc.
Sample of run...
PRAZY@11gR1> select * from test;
ID
----------
1
2
3
4
5
Elapsed: 00:00:00.00
PRAZY@11gR1> update test set id=round(dbms_random.value(1,100));
5 rows updated.
Elapsed: 00:00:00.00
PRAZY@11gR1> select * from test;
ID
----------
2
85
58
45
27
Elapsed: 00:00:00.00
Kind regards
Prazy
Published by: Prazy on March 17, 2010 17:35
Tags: Database
Similar Questions
-
Fill the table with random values
Another thing I've come across is this:
the table name is LOR, who has 3 fields NUMBER, DATA, TEXT with number, date and varchar2 data type.
On a page, I have a text field where if I write 3, then it would add 3 lines to the table with predefined values ("number, something like 2222, for 12 January 09, and for text, something like" Lorem ipsum dolor sit amet, 195kgs adipisicing elit"). So basically, with the number that I give, it populates the table with lines... How can I do this? Thanks for helping meINSERT INTO LOR SELECT 222 , sysdate , 'you string' FROM dual CONNECT BY level <= :Pxx_ -
Updated with the values in the same table, for other records corresponding to conditions
Hi Experts,
Sorry do not provide the structure of the table (it is a simple structure)
I have a requirement where I need to update the columns of a table based on the same table with some match empid and date values. If the date and empid match so I have these values to any other folder and update of one who is not having details of Office . I need the Update query
Before the update my array of values is as below
Sort_num Emp_id Bureau start_date
1 101 AUS 01/01/2013
2 101 01/01/2013
3 101 15/01/2013
4 103 USA 01/05/2013
5 103 01/01/2013
6 103 05/01/2013
7 104 FRA 01/10/2013
8 104 10/01/2013
9 104 01/01/2013After update my table should be as below
Sort_num Emp_id Bureau start_date
1 101 AUS 01/01/2013
2 101 AUS 01/01/2013
3 101 15/01/2013
4 103 USA 01/05/2013
5 103 01/01/2013
6 103 USA 01/05/2013
7 104 FRA 01/10/2013
8 104 FRA 01/10/2013
9 104 01/01/2013Thanks in advance
I don't have the time to create the table with the data, but basically, you should be able to code the following text
update one table
Office set = (select desktop in table b where b.emp_id = a.emp_id)
and b.start_date = a.start_date
and b.office is not null
)
where is ([as well as overall query])
and a.office is null
In my opinion, who will do the trick.
HTH - Mark D Powell.
-
Date column updated with trigger update of the geometry
Hello
I have a column named "GEO_MOD_DATE" which is supposed to be updated every time that my geometry column is updated. My trigger code is below. Currently the trigger is fired when other than my column of geometry columns are updated. I searched the forum and many other sites. As far as I know, my trigger is written correctly. But I can't understand why it is taken when the columns except my geometry column are updated. You have any ideas? Thanks in advance! Note that the trigger fires when I update the geometry column. However, it is also SHOOTING when the other columns are updated. I have also tried adding 'OF GDO_GEOMETRY' from "BEFORE UPDATE" paragraph and which did not help.
Jeff
Triggering factor:
CREATE OR REPLACE TRIGGER OPER_ZONE_VALVE_GEO_BU_T
BEFORE THE UPDATE
ON OPER_ZONE_VALVE
REFERRING AGAIN AS NINE OLD AND OLD
FOR EACH LINE
DECLARE
v_foo NUMBER (9);
BEGIN
-Comment from below if you do not want to assign GEO_MOD_DATE
BEGIN
IF the UPDATE ("GDO_GEOMETRY") and: NEW.gdo_geometry IS NOT NULL
THEN
: NEW.geo_mod_date: = SYSDATE;
ON THE OTHER
: NEW.geo_mod_date: = NULL;
END IF;
EXCEPTION
WHILE OTHERS
THEN
raise_application_error
(- 20013,
"Cannot be autoassign field OPER ZONE VALVE".
);
END;
/*****/
NULL;
EXCEPTION
WHILE OTHERS
THEN
raise_application_error
(- 20013,
'error in executing BEFORE INSERT TRIGGER OPER_ZONE_VALVE_GEO_BU_T;'
);
END;
/
--------------------------------------------
And here is my table structure:
CREATE TABLE OPER_ZONE_VALVE
(
MSLINK NUMBER (38),
VALVE_NUMBER VARCHAR2 (8 BYTE),
ECM_NUMBER VARCHAR2 (8 BYTE),
VALVE_SIZE VARCHAR2 (4 BYTE),
CONNECTION_TYPE VARCHAR2 (100 BYTE),
HEADER_STREET VARCHAR2 (100 BYTE),
HEADER_FEET VARCHAR2 (8 BYTE),
HEADER_DIR VARCHAR2 (4 BYTE),
HEADER_PROP VARCHAR2 (4 BYTE),
SUB_STREET VARCHAR2 (100 BYTE),
SUB_FEET VARCHAR2 (8 BYTE),
SUB_DIR VARCHAR2 (4 BYTE),
SUB_PROP VARCHAR2 (4 BYTE),
PLAT_MAP_NUMBER VARCHAR2 (4 BYTE),
USER DEFAULT CREATED_BY VARCHAR2 (50 BYTES)
CREATED_DATE DATE DEFAULT SYSDATE,
MODIFIED_BY VARCHAR2 (50 BYTE),
MODIFIED_DATE DATE,
DATE OF GEO_MOD_DATE,
NOTE VARCHAR2 (40 BYTE),
MDSYS GDO_GEOMETRY. SDO_GEOMETRY
)I read that FORWARD updated TO does not work with data as CLOB types
Yes. But what does this mean for the SDO_GEOMETRY objects is that you cannot directly use a WHEN clause in the definition of the trigger and you cannot compare two geometries directly via If (: old.geom =: new.geom) then.
So, in your trigger update of your business rules conditions require the trigger to implement are not enough.
Try to check if the geometry column has actually changed.
DROP TABLE oper_zone_valve; CREATE TABLE oper_zone_valve ( mslink NUMBER (38), valve_number VARCHAR2 (8 BYTE), ecm_number VARCHAR2 (8 BYTE), valve_size VARCHAR2 (4 BYTE), connection_type VARCHAR2 (100 BYTE), header_street VARCHAR2 (100 BYTE), header_feet VARCHAR2 (8 BYTE), header_dir VARCHAR2 (4 BYTE), header_prop VARCHAR2 (4 BYTE), sub_street VARCHAR2 (100 BYTE), sub_feet VARCHAR2 (8 BYTE), sub_dir VARCHAR2 (4 BYTE), sub_prop VARCHAR2 (4 BYTE), plat_map_number VARCHAR2 (4 BYTE), created_by VARCHAR2 (50 BYTE) DEFAULT USER, created_date DATE DEFAULT SYSDATE, modified_by VARCHAR2 (50 BYTE), modified_date DATE, geo_mod_date DATE, remark VARCHAR2 (40 BYTE), gdo_geometry MDSYS.sdo_geometry ); CREATE OR REPLACE TRIGGER air_valve_geo_bu_t BEFORE UPDATE OF gdo_geometry ON oper_zone_valve REFERENCING NEW AS new OLD AS old FOR EACH ROW BEGIN IF ( NOT UPDATING('GDO_GEOMETRY') ) THEN RETURN; END IF; IF ( :old.gdo_geometry is not null and :new.gdo_geometry IS not NULL ) THEN -- Check if geometry has changed internally IF ( sdo_geom.relate(:old.gdo_geometry,'DETERMINE',:new.gdo_geometry,0.005) != 'EQUAL' ) Then :new.geo_mod_date := SYSDATE; End If; ELSIF ( ( :old.gdo_geometry is null and :new.gdo_geometry IS NOT NULL ) OR ( :old.gdo_geometry is not null and :new.gdo_geometry IS NULL ) ) THEN :new.geo_mod_date := SYSDATE; ELSE :new.geo_mod_date := NULL; END IF; END; / SHOW ERRORSSome tests
SET NULL NULL INSERT INTO oper_zone_valve ( remark, gdo_geometry) VALUES ('remark', MDSYS.sdo_geometry(2001,NULL,SDO_POINT_TYPE(0,0,0), NULL,NULL)); COMMIT; 1 rows inserted. commited. SELECT remark, to_char(geo_mod_date,'YYYY-MM-DD HH24:MI:SS') as geo_mod_date, gdo_geometry FROM oper_zone_valve; REMARK GEO_MOD_DATE GDO_GEOMETRY ------ ------------------- ------------------------------------------------------- remark NULL SDO_GEOMETRY(2001,NULL,SDO_POINT_TYPE(0,0,0),NULL,NULL) update oper_zone_valve set gdo_geometry = sdo_geometry(2001, NULL,SDO_POINT_TYPE( 0,0,0),NULL,NULL) where remark = 'remark'; COMMIT; 1 rows updated. commited. SELECT remark, to_char(geo_mod_date,'YYYY-MM-DD HH24:MI:SS') as geo_mod_date, gdo_geometry FROM oper_zone_valve; REMARK GEO_MOD_DATE GDO_GEOMETRY ------ ------------------- ------------------------------------------------------- remark NULL SDO_GEOMETRY(2001,NULL,SDO_POINT_TYPE(0,0,0),NULL,NULL) update oper_zone_valve set gdo_geometry = sdo_geometry(2001, NULL,SDO_POINT_TYPE(10,0,0),NULL,NULL) where remark = 'remark'; COMMIT; 1 rows updated. commited. SELECT remark, to_char(geo_mod_date,'YYYY-MM-DD HH24:MI:SS') as geo_mod_date, gdo_geometry FROM oper_zone_valve; REMARK GEO_MOD_DATE GDO_GEOMETRY ------ ------------------- -------------------------------------------------------- remark 2012-10-16 09:24:53 SDO_GEOMETRY(2001,NULL,SDO_POINT_TYPE(10,0,0),NULL,NULL) execute dbms_lock.sleep(5); anonymous block completed update oper_zone_valve set gdo_geometry = NULL where remark = 'remark'; COMMIT; 1 rows updated. commited. SELECT remark, to_char(geo_mod_date,'YYYY-MM-DD HH24:MI:SS') as geo_mod_date, gdo_geometry FROM oper_zone_valve; REMARK GEO_MOD_DATE GDO_GEOMETRY ------ ------------------- -------------------------------------------------------- remark 2012-10-16 09:24:58 NULLThis seems to be the answer you are looking for or puts you on a path to achieve the correct execution of your business rules in the trigger.
Shows please!
concerning
SimonPublished by: Simon Greener on 17 October 2012 15:39, fixed a display issue does not
-
Release of updated with the value of the other Table
Hello
I need the sum there point TableB and insert/update this value in the X field in TableA. I can do this with select statements regular when I add values in my statement, but I'm getting errors now. Need help on how to code the trigger to do this, thank you.
ORA-00936: lack of expression
SELECT a.X, SUM(b.Y), INTO a.X FROM TableA a, TableB b WHERE a.PK = b.FK;Ok. I think I understand now what's going on. Think logically that you create the customer first and only then customer can create orders, right? So when you insert a customer into the table DEMO_CUSTOMERS there is no customer order in the DEMO_ORDERS table. As a result, the CREDIT_LIMIT column remains NULL.
SY.
-
The Master Table column updated based on the sum of column Table detail
With the help of JDev 11.1.1.6.I have a master-detail table based on a link to BC.
The main table has a column that displays an InputText or an OutputText, based on the value in another column.
If the InputText is displayed, the user can enter a value and the database will be updated with that value.
If the OutputText is displayed, it must be a sum of a column in the secondary table. Also, this value will be written in the database.
Question:
How can I fill the OutputText in the main table with the sum of the values in a column in the secondary table?
The detail table column is a manually entered InputText field.
Thank you.
Create a spike in the main table and write in its expression as follows - DetailVoAccessorName.sum ("ColumnName");
This will calculate the sum of column table detail and then you can set the value of the transient attribute to attribute DB on backup operation
Ashish
-
XMP updated with exiftool does not play
If this question is better suited in another forum, please let me know.
The following PDF example has been used in a workflow where the XMP metadata has been updated with new values ( Sub-property is set to cities).
When you open this file and looking at the meta-data for example Acrobat Pro this new updated information is not seen, but rather, the old XMP stream is read by Acrobat (pdfLib).
The update looks OK as far as I can see, the 54 object has been updated and the new xref table at the end has the byte of decent start for this new stream updated (byte 0022017676). So I can't understand why this new XMP stream is not seen in Acrobat.
Someone sees a mistake in the PDF file, or is there an obvious reason why Acrobat wouldn't read the new XMP stream?
(other software using exiftools extracted the new XMP correctly, I also tested with a tool written in java, pure and which also displays the new update of XMP metadata work as currently)
Link to test PDF (approx. 22 MB)
I think maybe it's to do with trying to do inplace editing on a signed PDF. At best, this would negate the signatures. But since Acrobat, try to maintain the integrity of the signed portion, there may be heuristics to decide to get rid of this stuff.
-
Assign a random value to column?
I have a Table with a single column, numeric field, about 1/2 million documents.
I want to add another column, VARCHAR2 and distributed way random value of ' a ',' B', 'C', has '.
The seed for Random can't be perfect, I just need to fill it with random data.
so that I can do a test in this Table for a different query, thank you!
Am on Oracle 10 g 2You can try like this,
update table_name set column_name = chr (64 + round (dbms_random.value ( 1, 4)))G.
-
Hi all
I am new in the form of Oracle, I have a question,
in oracle from(10G) now I show an entire table, when I update a line, then in that same line, there is a column named as status, must got the update automatically with the value 'NEW '.
Can someone help me how to perform this task.
If any body knows then please reply as soon as POSSIBLE.
Thank you
Ashish
1003500 wrote:
Hi all
I am new in the form of Oracle, I have a question,
in oracle from(10G) now I show an entire table, when I update a line, then in that same line, there is a column named as status, must got the update automatically with the value 'NEW '.
Can someone help me how to perform this task.
If any body knows then please reply as soon as POSSIBLE.
Thank you
Ashish
Ashish
Try this
/ * write the following code in Post-Text-Item at the block level * /.
IF: System.Record_Status IN ("MODIFIED", "INSERT") THEN
: your_block_name.column_name: = 'NEW';
END IF;
Hamid
-
Call doSubmit() with custom value does not update process
I have a page with a standard form that has a "Save" button, but also a button that I have manually created via an anonymous PL/SQL block in the source of the element of a field on the form. (I did because I was already using a PL/SQL block to display the value of the item, but wanted to update the button appear immediately next to him, rather than somewhere on the page template.)
Originally, this button was just a simple redirect to a separate detail page, but I found that if the user has made changes to the form, then click on this button, these changes would be lost. So I changed it to a call doSubmit() instead. But I had to distinguish between the user pressing the "Save" button and the custom button, the button call doSubmit ('CUSTOM'). I then created a branch that has verified the value of demand and went to the appropriate page that was pressed.
What I found was that the process to update the underlying table for the form had not shot, even if it is unconditional, and therefore updates the original form have been lost.
I eventually worked around this by changing the button so that instead of calling doSubmit with a custom value, it calls a JavaScript function that: 1) define a hidden field to '1' and 2) called doSubmit ('SAVE'). Then, I changed the direction to look at the value of this hidden field, rather than the value of the request. That has worked well.
So this got me thinking: why my original implementation did not work?
I suspect that doSubmit() only works to the custom of the values if you have defined a real button in the designer of the ApEx and configured with a name for this custom value. The HTML code for my button seems indistinguishable from a button created by ApEx, I think that there is something that happens behind the scenes to make doSubmit() work simply with a random value.
Can anyone confirm or deny this hypothesis?Hello
Could this be your problem:
If you have a treatment of automatic line (DML), which only fires from below, if I understand correctlyValid Update Request Values: SAVE, APPLY CHANGES, UPDATE, UPDATE ROW, CHANGE, APPLY, APPLY%CHANGES%, GET_NEXT%, GET_PREV% Valid Insert Request Values: INSERT, CREATE, CREATE_AGAIN, CREATEAGAIN Valid Delete Request Values:DELETE, REMOVE, DELETE ROW, DROPAt least on Apex 3.2
BR, Jari
-
SQL: Rearrange random a column within a grouping value
10g release 2.
I have a grouping column and a column of data.
I am looking for a SELECT statement that will pull all the x 1 for a random ID given, such that every x 1 original is represented once in the new random column, but this data is not "Cross" his original group ID border.CREATE TABLE t1 ( id NUMBER , x1 VARCHAR2(10) ); INSERT INTO t1 (id, x1) VALUES (1,'A'); INSERT INTO t1 (id, x1) VALUES (1,'B'); INSERT INTO t1 (id, x1) VALUES (1,'C'); INSERT INTO t1 (id, x1) VALUES (1,'D'); INSERT INTO t1 (id, x1) VALUES (1,'E'); INSERT INTO t1 (id, x1) VALUES (2,'F'); INSERT INTO t1 (id, x1) VALUES (2,'G'); INSERT INTO t1 (id, x1) VALUES (2,'H'); INSERT INTO t1 (id, x1) VALUES (2,'I'); INSERT INTO t1 (id, x1) VALUES (3,'J'); INSERT INTO t1 (id, x1) VALUES (4,'K'); INSERT INTO t1 (id, x1) VALUES (4,'L');
So, this might be valid outputs:
.. .as would have this:ID X1 RANDOMIZED ---------- ---------- ---------- 1 A E 1 B A 1 C C 1 D B 1 E D 2 F F 2 G H 2 H G 2 I I 3 J J 4 K K 4 L L
Note how the random value never cross a line ID.ID X1 RANDOMIZED ---------- ---------- ---------- 1 A A 1 B C 1 C E 1 D D 1 E B 2 F I 2 G H 2 H G 2 I F 3 J J 4 K L 4 L K
On the other hand, the following would not be outputs valid...
because randomized 'I' is now the fifth data element to group the ID 1, whereas in the table, 'I' belongs to the group ID 2. Similarly, the randomized study "D" now appears as a line associated with the ID 2, whereas it is defined initially as belonging to ID 1.ID X1 RANDOMIZED ---------- ---------- ---------- 1 A B 1 B E 1 C C 1 D A 1 E I 2 F D 2 G G 2 H F 2 I H 3 J J 4 K K 4 L L
A solution purely SQL is possible?
Thank you.Hello
It is a different and much more interesting problem!
At the heart of the solution is always good: use two different schemes of numbering (at least one of them, based on a random number) to tell which element will be substituted for each.
Here's one way:
WITH unpivoted_data AS ( SELECT id , address_ln_1 AS address_txt , 1 AS address_ln_num , 1 + LENGTH (address_ln_1) - LENGTH (REPLACE (address_ln_1, ' ')) AS token_cnt FROM t_addr UNION ALL SELECT id , address_ln_2 AS address_txt , 2 AS address_ln_num , 1 + LENGTH (address_ln_2) - LENGTH (REPLACE (address_ln_2, ' ')) AS token_cnt FROM t_addr ) , cntr AS ( SELECT LEVEL AS n FROM dual CONNECT BY LEVEL <= 1 + ( SELECT MAX (token_cnt) FROM unpivoted_data ) ) , got_tokens AS ( SELECT u.* , c.n AS token_num , REGEXP_SUBSTR ( u.address_txt , '[^ ]+' , 1 , c.n ) AS token_txt , ROW_NUMBER () OVER ( PARTITION BY u.address_ln_num , c.n ORDER BY dbms_random.string ('P', 10) ) AS o_num , ROW_NUMBER () OVER ( PARTITION BY u.address_ln_num , c.n ORDER BY dbms_random.value ) AS r_num FROM unpivoted_data u JOIN cntr c ON c.n <= u.token_cnt ) , got_scrambled_txt AS ( SELECT CONNECT_BY_ROOT id AS id , address_ln_num , TRIM ( SYS_CONNECT_BY_PATH ( token_txt , ' ' ) ) AS scrambled_txt , r_num FROM got_tokens WHERE CONNECT_BY_ISLEAF = 1 START WITH token_num = 1 CONNECT BY token_num = PRIOR token_num + 1 AND address_ln_num = PRIOR address_ln_num AND r_num = PRIOR r_num ) SELECT o.id , MIN (CASE WHEN r.address_ln_num = 1 THEN r.scrambled_txt END) AS scrambled_ln_1 , MIN (CASE WHEN r.address_ln_num = 2 THEN r.scrambled_txt END) AS scrambled_ln_2 FROM got_scrambled_txt r JOIN got_tokens o ON r.r_num = o.o_num WHERE o.address_ln_num = 1 AND o.token_num = 1 GROUP BY o.id ORDER BY o.id ;This assumes that address_ln_1 is not NULL.
Exit (1st time):
. ID SCRAMBLED_LN_1 SCRAMBLED_LN_2 ---- ------------------------------ ------------------------------ 101 901 ORACLE PKWY 102 1 INFINITE ROAD APT 3B 103 500 ANTONIO LOOP SUITE 100Output (2nd time: no changes to the query or table):
. ID SCRAMBLED_LN_1 SCRAMBLED_LN_2 ---- ------------------------------ ------------------------------ 101 1 ANTONIO PKWY APT 3B 102 500 INFINITE ROAD 103 901 ORACLE LOOP SUITE 100 -
I have a column with two values, separated by a space, in each line. How do I create 2 new columns with the first value in one column and the second value in another column?
Add two new columns after than the original with space separated values column.

Select cell B1 and type (or copy and paste it here) the formula:
= IF (Len (a1) > 0, LEFT (A1, FIND ("", A1) −1), ' ')
shortcut for this is:
B1 = if (Len (a1) > 0, LEFT (A1, FIND ("", A1) −1), ' ')
C1 = if (Len (a1) > 0, Member SUBSTITUTE (A1, B1 & "", ""), "")
or
the formula of the C1 could also be:
= IF (Len (a1) > 0, RIGHT (A1, LEN (A1) −FIND ("", A1)), "")
Select cells B1 and C1, copy
Select cells B1 at the end of the C column, paste
-
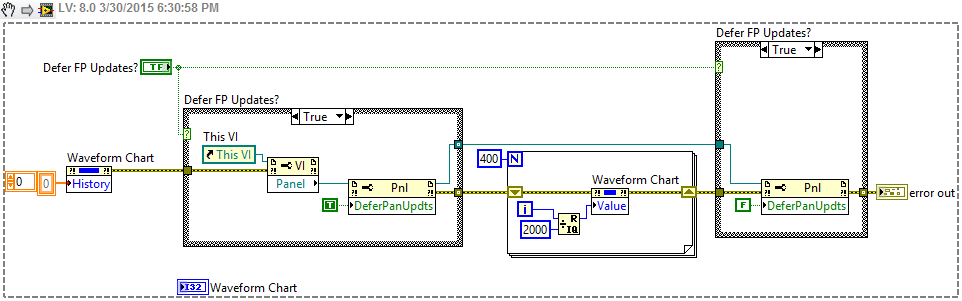
Bug in reporter Panel updated with the property Value Chart
Hi guys,.
Defer to what the Panel update property is set to true and chart is updated with the help of node "Property value", data are not updated graphics. Capture of the block diagram and VI (2014) screen gasket.
Is this a known bug, and is there any fix for it?
Thank you
Knockaert
I have not tried running your code, but here are some possible solutions:
- There is a primitive to write the value of a control by index (added in ~ 2013). This is designed to be used others live too and should work like a local.
- You can send data using another way (like a queue, etc.).
- Use the Ctl Val.Set method.
- Do not use a chart. Use a chart and manage the buffer yourself. You can find some examples if you're looking for graph XY.
-
Return only the columns with different values.
Hi all
I am trying to solve a seemingly trivial problem but can't seem to get any clear answer anywhere in any forum. Consider a single table with 5 columns and only two lines:
Assume that there is no primary key or any other constraint. Also assume that there are only and only two lines of this table. So I need basically a query that, overall above lines, would return first name and sex, because they are only different columns in two lines, as well as their values. Even if I can get sort of column names that are different and that would be enough that I can easily access the values later. It is also important to remember that I may not know the names of the columns in the columns, so basically, somehow, I use user_tab_columns in the process.row_id first_name last_name age gender 1 John doe 27 M 1 Jane doe 27 F
Any help appreciated.
Published by: 894302 on May 1, 2013 10:35Hello
894302 wrote:
The exact release could be just a varchar variable that lists all the columns that have different values with each column name separated by commas. We'll call the query you want as a QUERY. So, if I do something likeSelect the REQUEST of double; Output should be: 'first_name, equality of the sexes. Is this possible?
In this case:
SELECT RTRIM ( DECODE (a.row_id, b.row_id, NULL, 'row_id,') || DECODE (a.first_name, b.first_name, NULL, 'first_name,') || DECODE (a.last_name, b.last_name, NULL, 'last_name,') || DECODE (a.age, b.age, NULL, 'age,') || DECODE (a.gender, b.gender, NULL, 'gender,') , ',' ) AS different_columns FROM rhit_table_x a JOIN rhit_table_x b ON a.ROWID < b.ROWID ;Output:
DIFFERENT_COLUMNS --------------------------------------- first_name,genderThis assumes that you have really a table, then you can use ROWID to distinguish the lines, since there is no primary key.
If this isn't the case, you first assign ROW_NUMBER in a subquery. -
Updated several lines with different values
Hello!
I have a problem. I need to update more than 1000 lines with different values. How can I do?
For exsample I have table:
ID; color, date,
1 red
2 green
3 white
I need to update the date field.
Update table
Set date = '01.02.03'
where id = 1
Update table
Set date = '01.03.03'
where id = 2
Maybe it's how to update multiple rows in a single request?
Sorry for my bad English.
Thank you!Hello
You can try this
UPDATE TABLE SET DATE = CASE WHEN ID = 1 THEN TO_DATE('01-02-03','DD-MM-RR') WHEN ID = 2 THEN TO_DATE('01-03-03','DD-MM-RR') ENDsee you soon
VT

Maybe you are looking for
-
What happens if I disable pictures in iCloud?
Hi all! I received an Email that my iCloud storage was almost full. I checked it and the only option that has been lit and took most of the storage was "Photos." Now I turned off and a lot of storage to go. Now, here's my question: Do I lose all the
-
Satellite C50-A-138 - all USB ports do not have
Hello I have a major problem with my Satellite C50-A-138.The card reader has never worked, and one by one the USB ports have stopped working.I can connect my phone to each of them, and he will. But I can not plug any device into the port and have the
-
No sound after updating windows 8 on hp laptop
Hi, a few days ago my computer hp laptop is an automatic update of the W8 and since then I have no audio sound. He brought back several times, but he disappeared again. I did all the troubleshooting I could, etc not mute, volume etc and the said syst
-
Adjustment layer became first black. Help!
All new adjustment layers has to do the same thing I change any settings. Any ideas?
-
HelloCan someone let me know the what is the option to change the popup options in oracle applications 11i.My requirement is when I click on the options output/display the journal should it appear he himself, rather than redirect to the browser.Versi