"Compression" duplicate records over time
Hi, I've been fighting with a problem for a while now and don't know how to solve. I have data that looks like this:Code1... Code2... Start_Dt... End_Dt
A.......... A......... 1/1/2000...12/31/2000
A.......... A......... 1/1/2001...12/31/2001
A.......... B......... 1/1/2002...12/31/2002
A.......... B......... 1/1/2003...12/31/2003
A.......... A......... 1/1/2004...12/31/2004
A.......... A......... 1/1/2005...12/31/2005
A.......... A......... 1/1/2006...12/31/2006
What I would do in the data store is 'compress' duplicate records, so that the final result should look like this:
Code1... Code2... Start_Dt... End_Dt
A.......... A......... 1/1/2000...12/31/2001
A.......... A......... 1/1/2002...12/31/2003
A.......... B......... 1/1/2004...12/31/2006
I can't figure a way to do it. I can just say:
Select code1, code2, min (start_dt), max (end_dt)
because I get A codes / has, from 01/01/2000 through 12/31/2006 - is not just, they have changed between the two.
Does anyone know of a way to do this (base mode GAME please... not to write PL/SQL and do a rank at a time).
Thanks in advance,
Scott
Hi Scott,.
Try this SQL
select a_code,b_code,group_id,min(start_date,max(end_date) from
(select q.*,sum(change_flag) over (partition by a_code,b_code) group_id
from
(SELECT a_code,
b_code,
start_date,
end_date,
CASE
WHEN a_code = lag(a_code,1) over (partition by a_code,b_code ORDER BY start_date)
AND b_code = lag(b_code,1) over (partition by a_code,b_code ORDER BY start_date)
THEN 0 ELSE 1 END change_flag
FROM stp_test) q
) q2 group a_code,b_code,group_id
Kind regards
Oleg
Edited by: oleg2 09/22/2009 06:30 - Add Group by at the end
Tags: Business Intelligence
Similar Questions
-
create_record, duplicate records < n > times.
HII all,.
I have a detail datablock is;
I have a button that when pressed... will bring up a block of dataicode totqty perbox boxes_required prod1 20 6 4 prod2 10 4 3 prod3 15 4 4 - boxes_required column rounded up (totalqty/perbox).
with records based on the values in column "boxes_required"... something like that...
any ideas how it is possible...icode inbox box no. prod1 6 1 prod1 6 2 prod1 6 3 prod1 2 4 prod2 4 5 prod2 4 6 prod2 2 7 prod3 4 8 prod3 4 9 prod3 4 10 prod3 3 11
Form6i, db 10g
Kind regards...Put the NEXT_RECORD after the system.last_record
-
CREATE TABLE TEST (TNO NUMBER (2), TNAME VARCHAR2 (10));
INSERT INTO TEST VALUES (1, 'TIGER');
INSERT INTO TEST VALUES (2, 'SCOTT');
INSERT INTO TEST VALUES (2, 'MILLER');
INSERT INTO TEST VALUES (2, 'JOHN');
INSERT INTO TEST VALUES (3, 'SMITH');
SELECT * FROM TEST;
NWT TNOM
----- ----------
1 TIGER
SCOTT 2
2 MILLER
2 JOHN
3 SMITH
power required:
NWT TNOM
----- ----------
SCOTT 2
2 MILLER
2 JOHN
I want duplicate records.Have you tried the forum search?
How recover duplicate records have been answered several times ;-)select tno, tname from ( select tno, tname, count(*) over (partition by tno) cnt from test ) where cnt > 1 -
Advice on the restructuring of code to avoid the downturn over time
Hi, I am a new user of LabView, you want some advice on how to better structure the program I wrote and which is used to perform a hydrostatic test arrangement. Data are collected on a module of AI cDAQ 9207 and a cDAQ 9474 module is used to control the two valves that subsequently controls pressure in and out of the test Chamber. I enclose my first version of the reference code.
What the VI is supposed to do when the user of the weapon system and strikes then the execution, the program switch will cause a transition of the test chamber through several States corresponding to the levels of different pressure for some time. Time curve vs pressure is written to a file of measures. I built using a state machine structure.
My problem is, during the initial trial, when the duration of the test was about 5 minutes or so, the program went very well. However, once I started to test the length of the actual test of 2.5 hours, I noticed the program running slower and slower as time progressed to the point where it would take several seconds for each iteration of the loop, then by accident about an hour or two in the test. After scouring the articles and messages, I suspect the main culprit is the diagram of waveform and to a lesser extent DAQ assistant.
While I need the loop structure data collection and case to run pretty quickly (preferably the order a few hundred s/s) I need the code to be able to react to changes in pressure in the room quickly enough, the actual data, that I need to store and display the graph can be as slow as a sample per second or even longer. My guess is at this point that I have to rebuild the program using some sort of architecture of producer/consumer, I'm looking for some advice on how best to structure the program.
Data acquisition obviously belongs in the producer loop that will run at a fast enough pace and there will be a consumer loop that will run at a much slower pace for the Bulletin Board writing to the extent of the file vi, but where should I put the case of structure state machine which currently controls the valves? Should put in the loop of the producer since it must run at the same fast pace as the collection of data, so it can react to changes in pressure or should I build another loop of consumer for him? What other indicators (pressure and Boolean) and controls on the front panel, they should be on another loop operating at a medium speed I want to respond to a faster pace than the data to the chart/write the loop, but they do not need to be as fast as the data acquisition loop?
Finally, I'm not quite sure what would be the best way to reduce the sampling rate of the data that I have in fact appear on the graph and the store in the file, it wouldn't make sense to create another task of measurement that samples at a rate below just for that purpose. Suggestions and advice would be greatly appreciated! Thanks in advance!
Bob
My guess is that if you monitor the use of memory over time, you see that going up, Yes? Everything is is always a good idea to get rid of the express VIs, I would look for the problem of slowdown in the structure of the case. You repeatedly open and never close tasks which are created using some DIO channels. Hnece each time that the loop more memory is allocated. Try to move creating channel screws out of the loop, then the tasks are created once before the start of the loop and then written to as required inside the loop - and don't forget to delete tasks once the loop over.
Mike...
PS: You are right with your comments regarding the structure of the producer consumer. Basically it break up as things get quickly (DAQ IO) that there is in a loop, while the user interface and the stuff that can take a long time (such as the data record) are in another loop. You can even have three loops with one for the acquisition of input data and the other for the digital output.
PPS: Finally don't forget that even if the structure of consumption of the producer is usually represented with everything in a single diagram, there no need to be. I wrote a lot where each loop is in his own VI which is run dynamically, then the application starts.
-
Matching records between 2 tables with duplicate records
Hi all
I need help in what follows.
I have 2 tables Received_bills and Send_bills.
-------------------------------------------------------
-The DOF for Table SEND_BILLS
--------------------------------------------------------
CREATE TABLE SEND_BILLS
(DATE OF "DATUM",
NUMBER OF "PAYMENT."
'CODE' VARCHAR2 (5 BYTE)
) ;
--------------------------------------------------------
-The DOF for Table RECEIVED_BILLS
--------------------------------------------------------
CREATE TABLE 'RECEIVED_BILLS '.
(DATE OF "DATUM",
NUMBER OF "PAYMENT."
'CODE' VARCHAR2 (5 BYTE),
VARCHAR2 (5 BYTE) 'STATUS' ) ;
INSERTION of REM in RECEIVED_BILLS
TOGETHER TO DEFINE
Insert. RECEIVED_BILLS (DATUM, PAYMENT, CODE, STATE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1', 'SUCCESS');
Insert into RECEIVED_BILLS (PAYMENT, CODE, DATE, STATUS) values (to_date('10-OCT-15','DD-MON-RR'), 'A5', 'SUCCESS', 25);
Insert into RECEIVED_BILLS (PAYMENT, CODE, DATE, STATUS) values (to_date('10-OCT-15','DD-MON-RR'), 47, 'A4', 'FAILED');
Insert into RECEIVED_BILLS (PAYMENT, CODE, DATE, STATUS) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1', 'FAILED');
Insert into RECEIVED_BILLS (PAYMENT, CODE, DATE, STATUS) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1', 'SUCCESS');
INSERTION of REM in SEND_BILLS
TOGETHER TO DEFINE
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 25, 'A5');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 47, 'A4');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('09-OCT-15','DD-MON-RR'), 19, 'A8');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 20, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 25, 'A5');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 25, 'A5');
I match all records of send_bills and received_bills with a status of 'SUCCESS' There is no single column in the table.
Correspondence held payment of columns, the code and the scratch cards, but it may also duplicate records. But even if there are duplicates, I also need those records in the query results
the query I wrote is this:
SELECT SEND.*
REC received_bills, send_bills send
WHERE send.datum = rec.datum
AND send.payment = rec.payment
AND send.code = rec.code
AND 'rec.status =' SUCCESS
;
The query results give me this
OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 25 A5 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 25 A5 The result of the correct application would be
OCTOBER 10, 15 19 A1 OCTOBER 10, 15 25 A5 OCTOBER 10, 15 19 A1 The select statement that I need I want to use a loop to insert records in another table.
Can someone help me please?
Thanks in advance.
Best regards
Caroline
Hi, Caroline.
Caroline wrote:
Hi all
I need help in what follows.
I have 2 tables Received_bills and Send_bills.
-------------------------------------------------------
-The DOF for Table SEND_BILLS
--------------------------------------------------------
CREATE TABLE SEND_BILLS
(DATE OF "DATUM",
NUMBER OF "PAYMENT."
'CODE' VARCHAR2 (5 BYTE)
) ;
--------------------------------------------------------
-The DOF for Table RECEIVED_BILLS
--------------------------------------------------------
CREATE TABLE 'RECEIVED_BILLS '.
(DATE OF "DATUM",
NUMBER OF "PAYMENT."
'CODE' VARCHAR2 (5 BYTE),
VARCHAR2 (5 BYTE) 'STATUS');
INSERTION of REM in RECEIVED_BILLS
TOGETHER TO DEFINE
Insert. RECEIVED_BILLS (DATUM, PAYMENT, CODE, STATE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1', 'SUCCESS');
Insert into RECEIVED_BILLS (PAYMENT, CODE, DATE, STATUS) values (to_date('10-OCT-15','DD-MON-RR'), 'A5', 'SUCCESS', 25);
Insert into RECEIVED_BILLS (PAYMENT, CODE, DATE, STATUS) values (to_date('10-OCT-15','DD-MON-RR'), 47, 'A4', 'FAILED');
Insert into RECEIVED_BILLS (PAYMENT, CODE, DATE, STATUS) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1', 'FAILED');
Insert into RECEIVED_BILLS (PAYMENT, CODE, DATE, STATUS) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1', 'SUCCESS');
INSERTION of REM in SEND_BILLS
TOGETHER TO DEFINE
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 25, 'A5');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 47, 'A4');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('09-OCT-15','DD-MON-RR'), 19, 'A8');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 20, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 19, 'A1');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 25, 'A5');
Insert into SEND_BILLS (DATUM, CODE) values (to_date('10-OCT-15','DD-MON-RR'), 25, 'A5');
I match all records of send_bills and received_bills with a status of 'SUCCESS' There is no single column in the table.
Correspondence held payment of columns, the code and the scratch cards, but it may also duplicate records. But even if there are duplicates, I also need those records in the query results
the query I wrote is this:
SELECT SEND.*
REC received_bills, send_bills send
WHERE send.datum = rec.datum
AND send.payment = rec.payment
AND send.code = rec.code
AND 'rec.status =' SUCCESS
;
The query results give me this
OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 25 A5 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 19 A1 OCTOBER 10, 15 25 A5 The result of the correct application would be
OCTOBER 10, 15 19 A1 OCTOBER 10, 15 25 A5 OCTOBER 10, 15 19 A1 The select statement that I need I want to use a loop to insert records in another table.
Can someone help me please?
Thanks in advance.
Best regards
Caroline
Want to get answers that work? Then make sure that the CREATE TABLE and INSERT statements you post too much work. Test (and, if necessary, correct) your statements before committing. You have a stray "." in the first INSERT statement for received_bills and receikved_bills.status is defined as VARCHAR2 (5), but all values are 6 characters long.
There are 5 lines in send_bills that are similar to the
10 OCTOBER 2015 19 A1
Why do you want that 2 rows like this in the output, not 1 or 3, or 4 or 5? Is it because there are 2 matching rows in received_bills? If so, you can do something like this:
WITH rec AS
(
SELECT the reference, payment, code
, ROW_NUMBER () OVER (PARTITION BY datum, payment, code)
ORDER BY NULL
) AS r_num
OF received_bills
Situation WHERE = 'SUCCESS'
)
send AS
(
SELECT the reference, payment, code
, ROW_NUMBER () OVER (PARTITION BY datum, payment, code)
ORDER BY NULL
) AS r_num
OF send_bills
)
SELECT send.datum, send.payment, send.code
REC, send
WHERE send.datum = rec.datum
AND send.payment = rec.payment
AND send.code = rec.code
AND send.r_num = rec.r_num
;
Note that the main request is very similar to the query you posted, but the last condition has changed.
If you need to insert these lines in another table, you can use this query in an INSERT statement. There is no need of a loop, or for any PL/SQL.
-
Hi all
This is our requirement.
We must combine records with time.
for example: period = 3
TABLE: XX_SALES
---------------------------------------------
XDATE XQTY
---------------------------------------------
10 5/1/2012
20 2/5/2012
3/5/2012 30
4/5/2012 60
12 2012/5/7
8/5/2012 23
45 8/5/2012
100 12/5 / 2012
5/2012/13 55
5/2012/15 99
== >
---------------------------------------------
XDATE XQTY
---------------------------------------------
1/5/2012 10-> 5/1/2012 Group (5/1/2012 ~ 3/5/2012)
2/5/2012 20-> 5/1/2012 Group (5/1/2012 ~ 3/5/2012)
3/5/2012 30-> 5/1/2012 Group (5/1/2012 ~ 3/5/2012)
4/5/2012 60-> Group 5/2012/4 (4/5/2012 ~ 2012/5/6) *.
7/5/2012 12-> Group 5/2012/7 (5/7/2012 ~ 9/5/2012) *.
8/5/2012 23-> Group 5/2012/7 (5/7/2012 ~ 9/5/2012) *.
8/5/2012 45-> Group 5/2012/7 (5/7/2012 ~ 9/5/2012) *.
5/2012/12 100-> Group 5/12/2012 (2012/5/12 ~ 14/5/2012) *.
13/5/2012 55-> Group 5/12/2012 (2012/5/12 ~ 14/5/2012) *.
5/15/2012 99-> Group 5/15/2012 (15/5/2012 ~ 5/17/2012) *.
After amount to combine with period = 3, the result will be
---------------------------------------------
XDATE_G XQTY_G
---------------------------------------------
60 1/5/2012
4/5/2012 60
2012/5/7 80
12/5/2012 155
5/2012/15 99
Here's the example script
We can solve this problem by using the loop now:create table XX_SALES(XDATE DATE, XQTY Number); insert into XX_SALES VALUES(to_date('20120501','YYYYMMDD'),10); insert into XX_SALES VALUES(to_date('20120502','YYYYMMDD'),20); insert into XX_SALES VALUES(to_date('20120503','YYYYMMDD'),30); insert into XX_SALES VALUES(to_date('20120504','YYYYMMDD'),60); insert into XX_SALES VALUES(to_date('20120507','YYYYMMDD'),12); insert into XX_SALES VALUES(to_date('20120508','YYYYMMDD'),23); insert into XX_SALES VALUES(to_date('20120508','YYYYMMDD'),45); insert into XX_SALES VALUES(to_date('20120512','YYYYMMDD'),100); insert into XX_SALES VALUES(to_date('20120513','YYYYMMDD'),55); insert into XX_SALES VALUES(to_date('20120515','YYYYMMDD'),99);
to find the XDATE_G and it's rank in the loop and the XQTY in the range of the sum.
Is it possible to solve this problem by using analyze sql?DECLARE V_DATE_FROM DATE := NULL; V_DATE_TO DATE := NULL; V_QTY_SUM NUMBER := 0; CURSOR CUR_DATE IS SELECT DISTINCT XDATE FROM XX_SALES ORDER BY XDATE; BEGIN FOR REC IN CUR_DATE LOOP IF V_DATE_TO IS NULL OR REC.XDATE > V_DATE_TO THEN V_DATE_FROM := REC.XDATE; V_DATE_TO := REC.XDATE + 3 - 1; SELECT SUM(XQTY) INTO V_QTY_SUM FROM XX_SALES WHERE XDATE >= V_DATE_FROM AND XDATE <= V_DATE_TO; DBMS_OUTPUT.PUT_LINE(TO_CHAR(V_DATE_FROM, 'YYYYMMDD') || '-----qty: ' || TO_CHAR(V_QTY_SUM)); END IF; END LOOP; END;
Thanks in advance,
Best regards
Zhxiang
Published by: zhxiangxie on April 26, 2012 14:41 fixed the grouping expected dataThere was an article about a similar problem in Oracle Magazine recently:
http://www.Oracle.com/technetwork/issue-archive/2012/12-Mar/o22asktom-1518271.html
See the section on the 'grouping beaches '. They needed a total cumulative who started once the total reaches a certain amount.
You need a total cumulative which starts again when the date changes to group and the dates of beginning and end of each group must be determined dynamically.
This can be done with the analytical functions.
Here is a solution-based 'code listing 5', the solution MODEL, which is recommended in the article.
SELECT FIRST_DATE, SUM(XQTY) SUM_XQTY FROM ( SELECT * FROM xx_sales MODEL DIMENSION BY(ROW_NUMBER() OVER(ORDER BY XDATE) RN) MEASURES(XDATE, XDATE FIRST_DATE, XQTY) RULES( FIRST_DATE[RN > 1] = CASE WHEN XDATE[CV()] - FIRST_DATE[CV() - 1] >= 3 THEN xdate[cv()] ELSE FIRST_DATE[CV() - 1] END ) ) GROUP BY first_date ORDER BY first_date; FIRST_DATE SUM_XQTY --------------------- -------- 2012/05/01 00:00:00 60 2012/05/04 00:00:00 60 2012/05/07 00:00:00 80 2012/05/12 00:00:00 155 2012/05/15 00:00:00 99If you 9i, there is no function model. In this case, I can give you a solution using START WITH / CONNECT BY that does not work as well.
-
ROW_NUMBER and duplicate records
Hello
Tried to delete duplicate records. The code below works, but would remove all, rather than simply the > #1 records:
(SELECT academic_period, load_week, sub_academic_period, person_uid, course_number,
course_reference_number, rowid that RID, row_number() over (partition of)
academic_period, load_week, sub_academic_period, person_uid, course_number,
order of course_reference_number of academic_period, load_week, sub_academic_period,
person_uid, course_number, course_reference_number)
Of THE cea
WHERE (academic_period, load_week, sub_academic_period, person_uid, course_number,)
IN course_reference_number)
(SELECT academic_period, load_week, sub_academic_period, person_uid, course_number,
course_reference_number
Of THE cea
GROUP of academic_period, load_week, sub_academic_period, person_uid, course_number,
course_reference_number
HAVING COUNT (*) > 1))
If I try to put 'rn' and rn > 1, I get ora-00933: Sql not correctly completed command
SELECT academic_period, load_week, sub_academic_period, person_uid, course_number,
course_reference_number, rowid that RID, row_number() over (partition of)
academic_period, load_week, sub_academic_period, person_uid, course_number,
order of course_reference_number of academic_period, load_week, sub_academic_period,
person_uid, course_number, course_reference_number): the nurse
Of THE cea
WHERE (academic_period, load_week, sub_academic_period, person_uid, course_number,)
IN course_reference_number)
(SELECT academic_period, load_week, sub_academic_period, person_uid, course_number,
course_reference_number
Of THE cea
GROUP of academic_period, load_week, sub_academic_period, person_uid, course_number,
course_reference_number
After HAVING COUNT (*) > 1)
and rn > 1
I tried to remove as"rn" and make "rn" and "rn", which gave me an error of syntax also. The '' rn > 1 and '' clause gets an error of syntax also. I gone through a bunch of different Web sites. All of this indicates the syntax I am using will work. However, any query I run into a TOAD, always error when I include the 'rn > 1.
Any ideas? Thank you!
VictoriaYou mix two ways to identify duplicates.
One way is HAVING:
SELECT academic_period, load_week, sub_academic_period, person_uid, course_number, course_reference_number FROM cea GROUP BY academic_period, load_week, sub_academic_period, person_uid, course_number, course_reference_number HAVING COUNT(*) > 1)That tells you just what combinations of your group are more than once.
Another way is to analytical functions:
select * from ( SELECT academic_period, load_week, sub_academic_period, person_uid, course_number, course_reference_number count(*) over (partition by academic_period, load_week, sub_academic_period, person_uid, course_number, course_reference_number) cnt FROM cea ) where cnt > 1This will all return duplicate records - if some combinations has three duplicates, then this will return all three lines.
If you use the ROW_NUMBER() place COUNT() analytical analytical function, you get this:
select * from ( SELECT academic_period, load_week, sub_academic_period, person_uid, course_number, course_reference_number row_number() over (partition by academic_period, load_week, sub_academic_period, person_uid, course_number, course_reference_number) rn FROM cea ) where rn > 1All of these files without duplicates will get rn = 1. Those with duplicates gets rn = 1, rn = 2... If rn > 1 Gets all "unnecessary" records - the ones you want to remove.
If a deletion might look like:
delete cea where rowid in ( select rid from ( SELECT ROWID as rid, row_number() over (partition by academic_period, load_week, sub_academic_period, person_uid, course_number, course_reference_number) rn FROM cea ) where rn > 1 )Or if you want to manually inspect before you delete ;-):
select * from cea where rowid in ( select rid from ( SELECT ROWID as rid, row_number() over (partition by academic_period, load_week, sub_academic_period, person_uid, course_number, course_reference_number) rn FROM cea ) where rn > 1 )In another answer, you can find a way to remove duplicates with HAVING.
The point is that do you it either with or with ROW_NUMBER() - not both HAVING ;-) -
update with the duplicate record
I'm working on my update page and I came across the problem where it allows to update the duplicate record. My code works for the second time when I tried to update the same name.
For example, I have the user name A, B and C of the database.
For the first time: update the username from B to A. This allowed me to do so given the A user name already in the table. (NOT RIGHT)
Second step: update the C to A user name. He stopped me because of the duplicate record
NOT QUITE RIGHT, IT SHOULD BE STOPPED ME FIRST?
Thank you
You should probably change the first query if a line with the same id is not considered:
Select user_name
users
where trim (user_name) = ' #trim (form.user_name) #
and user_id! = #user_id #.
If all the rows are returned from get_dupecheck then you don't want to do the update.
-
Since the installation on my Windows 7 64 - bit installed, Firefox has constantly gotten slow that hour passes, hangs for 10-15 seconds at a time and just gets worse over time with updates and all. It was fast when I installed first, but of the six latest mos has slown to a crawl.
upgrade your browser Firefox 8 and try
-
Can I create a spreadsheet to track events over time? If so, how?
Is it possible to use the numbers to track events over time? Dates would be the only numbers you use.
Can you give more details on what you are looking to do? Surely you don't want only a column of dates...
SG
-
Want a ramp of output voltage over time and measure input 2 analog USB-6008
Hello
I want to produce an analog voltage output signal that increases over time with a certain slope, which I'll send in a potentiostat and at the same time I want to read voltage and current (both are represented by a voltage signal) that I want to open a session and ultimately draw from each other. To do this, I have a DAQ USB-6008 system at my disposal.
Creation of the analogue output with a linear ramp signal I was possible using a while loop and a delay time (see attachment). Important here is that I can put the slope of the linear ramp (for example, 10mV/s) and size level to make a smooth inclement. However when I want to measure an analog input signal he's going poorly.
To reduce noise from the influences I want for example to measure 10 values for example within 0.1 second and he averaged (this gives reading should be equal or faster then the wrong caused by the slope and the linear ramp step size.) Example: a slope of 10 mV/s is set with a 10 step size. Each 0.1 s analog output signal amounts to 1 mV. Then I want to read the analog input in this 0.1 s 10 values)
Because I use a timer to create the linear ramp and the analog input is in the same loop, the delay time also affects the analog input and I get an error every time. Separately, in different VI-programs (analog input and output) they work fine but not combined. I searched this forum to find a way to create the ramp in a different way, but because I'm not an experienced labview user I can't find another way.
To book it now a bit more complicated I said I want to measure 2 input analog (one for the voltage of the potentiostat) signals and one for the current (also represented by a voltage signal) and they should be measured more quickly then the bad of the analog signal. I have not yet started with because I couldn't read on channel work.
I hope someone can help me with this problem
An array of index. You want to index the columns for a single channel.
-
Plotting the amplitude of a spectral peak over time
Hello
I am creating a VI where the acquired continuously DAQ, plots and save a waveform in millisecond delay (which is already done in this case), then takes this waveform, finds a specific pic (probably the first) and trace the amplitude of this pic over time (+ 30 minutes, one point each scan which is obtained). Essentially, I have a detector quickly attached to a chromatograph, and I want to select a single ion and monitor the amplitude of this ion. I can draw the waveforms along with it in post processing, but I want to do is to have the 'slow' constantly plot to update and display when it moves through time. Joined the VI will go in, using IMS software V1.3.vi, the paragraph is the "GC" Mode it seems I should use the "peak detect.vi.", but I'm not familiar with this operation, and so I don't know how to show a constantly updated graphic or remove the amplitudes and draw. Thank you for your help,
<><>
Eric-WSU wrote:
I get an amplitude on plot of time, but it does not appear until after all the iterations are stopped
I have not watched your VI (because I'm in a previous version of LabVIEW), but it's probably because your graphic is outside the loop.
Here's how you can get a graph of the peaks (all vertices, by iteration):

Or if you want to only a certain PEAK (and how this pic changes with the number of iterations):

-
Hi, I have two decimal strings, each of them contains the numbers change over time. I want to plot them on the graph XY, a string for each axis. Can you show me how do?
This is not a formula, but a constant simple schema of a table complex. Wire remains, then do a right click of the terminal of the initializer of the feedback node and select "create constant. That should do it.

-
full waveform graph to calculate the area under the curve over time
Hello
If please find my attached VI and help me please for integration to get area undercut for my chart of waveform.
I would like to find my wave power wind energy production chart oever within one month of time.
I think I have to integrate to get the area under the curve and so I m now using tool integrated into labview attached.
As I did not wait years for my result and so I want to make sure that the tool that I m using is correct.
Please advise me what method I will use for my chart.
Dominique says:
I would like to integrate my table of power over time (table of power is on each interval of a minute) and the entire graph is one month. So, I'll put dt = 1?
You put dt at some units you want in the final result. If you want Wh, you want dt in hours. If the spacing is currently a minute, you can express in fractional hours and use the result as dt. Try dt = 1/60.
-
Get information from change of color over time
Hi all
I am new to LabView and on this forum, so I hope I'm in the right subforum. If this isn't the case, it would be nice if a mod could move this thread.
My problem is the following:
Let's say I have a white spot I want to observe with a camera. The color of the spot turns green over time and I want to acquire the photo, as well as to get the color intensity of green increase developing countries over time. I do not know what features I need to use to get there. Can someone me hint in the right direction? I think that it is at least possible in LabView.
Thank your all for your help.
Best regards
Tresdin
I don't know what the best resource for IMAQdx pilots, I think that the examples that provide OR are pretty useful. Here's a simple VI which will tell you the average value of green of all the pixels in your image.
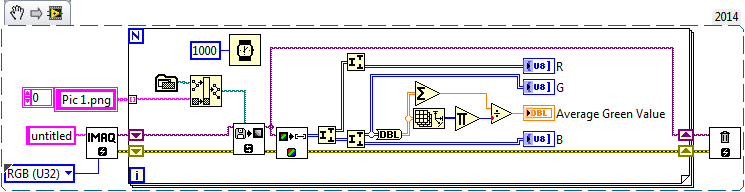
Maybe you are looking for
-
How to a duel to start my macbook pro windows after installing windows 7
I do not remember the main features of say mac OS I want to start, could someone help me?
-
Hi all I want a table to check-in, like this, using now() However, when I insert Now() in C2, all cells will change Someone help me with this? million thanks
-
Satellite A300 - no Audio device installed
Hey,. During the last week, I had trouble with my audio.The first incident occurred then that I was browsing the internet, and suddenly an error pops up and off my sound. When I checked for audio devices it says there where not installed and when I c
-
Exchange Server 2007 SBS 2008 Service Pack problems
I am server running Exchange 2007 on Small Business server 2008 (SBS 2008). I tried to install SP2, but it omits the two windows update and manually. Can someone tell me first what version I am running? Help / form displays the Exchange Management Co
-
I imported the photos directly from my camera via a slot card on my computer HP using Windows Live Photo Gallery. Then I separated pictures in files by physical location in my images. I then started to change each locale file and save it. At least