Convert htmlspecialchars in unicode
Hello
I don't know how to convert htmlspecialchars such as
e
to
"
ect...
unicode character
Thank you
Hello!
QTextDocument document; document.setHtml(text); QString plainText = document.toPlainText();
Tags: BlackBerry Developers
Similar Questions
-
I have an ASCII file that I downloaded via FTP in a PowerShell script. Get an error when I try to convert it to Unicode.
$LocalFileFile = New - ObjectIO.FileStream ([System.IO.Path]: GetFullPath ($LocalFile), [System.IO.FileMode]: Create, [System.Text.Encoding]: Unicode)
Throw the error message:
New-Object: unable to find an overload for 'FileStream' and the number of arguments: '3 '.
U:\IBM\Report Manager\PowerShell\Script Samples\gtas08_ftp\gtas08_ftp_jh.ps1:102 char: 38
+ $LocalFileFile = new-Object IO. FileStream ([System.IO.Path]:...)
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo: InvalidOperation: (:)) [New-Object], MethodException)
+ FullyQualifiedErrorId: ConstructorInvokedThrowException, Microsoft.PowerShell.Commands.NewObjectCommand
If I remove the encoding, the script works fine.
This is the forum for PowerShell:
https://social.technet.Microsoft.com/forums/scriptcenter/en-us/home?Forum=iTCG
-
Hello, what is the best way to use the new component text to import the Arabic language via xml in flash.
In the demo with the spinning globe, I noticed that the Arabic text is unicode, the unicode string is actually LTR, then it is displayed with RTL. Obviously, this works very well with wordwrap etc.. Is there some sort of converter that I can get to convert Arabic RTL unicode LTR?
I also wonder if its possible to import the Arab police a string of XML and have things like the word wrap work correctly, I assume here (perhaps naively) that it is not a format XML of RTL and if there is flash dress not her head around it. I can't imagine writing whole paragraphs of text backwards in xml. To do that I have to use the markup code following the bidi.xml file in the examples, where it separates each row for display to face the problems of film.
Any ideas would be great, I'm sorry if my explanations are a little newby, I'm no gun.
K.
This is the application that displays the XML code as to how it will appear to you, so I can't speak to see if it the XML will look like LTR or RTL when you view it. But the idea is that Unicode characters are stored in the reading order. For TLF, it gets the Unicode in the reading order, and then the player converts them to "atoms" which are classified either RTL or LTR according to Unicode values.
The example of bidi.xml doesn't have much shorter lines, but the same principle works on longer paragraphs as well and TLF, using the player, will correctly paper wrap regardless of the orientation of the text. In order to get the order of the columns, dashes and punctuation to look right, you need to decide if your TextFlow and paragraph is mainly LTR or RTL and set the direction of appropriately attribute.
-
Project is in UNICODE format in VC6.0 MFC on windows XP
error C2440: '=': cannot convert from 'unsigned short [70]' to ' char *'
Code:MapiMessage message;
message.lpszSubject = _T ("International Translation package Attached"); Error at this stage.I would know how can I use MapiMessgae in my program using Unicode.
Suggest me any change in
Thank you and best regards,
Sanjay.
Hello Sanjay
The question you have posted is better suited to the MSDN forums. You can ask your question in the help link.
http://social.msdn.Microsoft.com/forums/en/category/vsexpress
Hope the helps of information.
Concerning
Joel S
Microsoft Answers Support Engineer
Visit our Microsoft answers feedback Forum and let us know what you think. -
Miss me the Office addin PDF update, Office 2013 Outlook I had a tab to convert messages in PDF files, I've updated for Outlook Office 2016 and tag disappeared, in order to convert, I have first to save as Unicode Outlook file, then PDF. Problem is that Outlook Office, rest of the Office programs are OK. Can you help me?
Hi peters63853633,
Acrobat XI is not compatible with Office 2016, please check compatibility doc. https://helpx.Adobe.com/Acrobat/KB/compatible-Web-browsers-PDFMaker-applications.html
Kind regards
Nicos
-
After effects error: could not convert Unicode characters. (23::46) CS6
Hello I just created a project in AE CC and wanted to also save a version for CS6.
Everything went well but when I tried to open the project in CS6 I received the following error message:
«After effects error: could not convert Unicode characters.» (23::46) »
Does anyone know what this means and how to fix it?
After effects CC is much, much better handling of the characters that are outside the defined character used by the operating system to its current settings of the language. Thus, the file names and paths (and other channels) which operate very well in after effects CC and later may fail with older versions.
For example, if you run your operating system and applications in English and Chinese characters in your file names, After Effects CS6 and earlier will fail, but after effects CC and earlier will succeed.
-
After effects error: could not convert Unicode characters. (23:46)
Hey guys,.
I'm trying to change the output path for a render queue item.
But I still have this error "after effects error: could not convert Unicode characters.» (23:46) ".
Here is my code
A_char outPath [256] = "D:/test.mp4;
ERR (suites. OutputModuleSuite4()-> AEGP_SetOutputFilePath (0, 0, outPath));
What I am doing wrong? Help me please! Thank you very much!!!
You must use A_UTF16Char instead of A_char.
-
How to convert decimal unicode(UTF-32)?
refer to this example: http://www.sqlsnippets.com/en/topic-13438.html
Unicode: SLICE OF PIZZA (plan 1)
Decimal value: 127829
Hex(UTF-32): 1F355
Hex(UTF-16): \D83C\DF55
Now, I can use unistr ('\D83C\DF55') for the unicode character. But my table keep the decimal value "127829". So, how I can use this value to get the unicode character?
Thank you.
My problem is solved.
I found a decimal conversion algorithm in the UTF-16 surrogate pairs and use the unistr() function to get the unicode character.
-
AE CS6: Could not convert Unicode characters (23:46)
I am sudenlty this error message.
I I imported a native XDCAM AE Win 7 file when the error message appeared. Afterwards, simply by clicking on the button import (no file selected) gives the same error message.
It seemed "clear" by dragging an AVI file in front of the bridge. Using the same technique, I was then able to slide on the Moose XDCAM file. However, the error message occurs when I try to save the project. It will not allow him.
Then, I opened a completed project, I tried and tested - and it gives the error message when I try to "registered under. However, it will happen one 'increment and save' without dirplaying the message.
I looked to the top of the Adobe Help - about to replace the language files, folders etc., but who did not do the tour. He suggested (CS3, CS4) that whatever the language txt file is in the language of the AMT folder, is that AE has been installed with. However, ALL txt language files reside there in it! Maybe he's changed for CS6. I made the assumption that I would have used en_GB.txt. According to this hypothesis, I did the recommended procedure. No change!
My motherboard was replaced yesterday - and I had to ask Adobe for the activation of the other - as I did not know that this replacement MB was an additional computer! Therefore, I didn't have to disable the Suite beforehand. This may cause the issue?
All suggestions greatly appreciated. Thank you.
Thanks for posting these comments. I just came across the same problem and tried the steps mentioned in other threads (for earlier versions) with no luck. It wasn't until I found this thread as I was led to realize that a distinctive character was suddenly added to a folder on a removable drive name, I have access to. Perhaps not even noticed if I didn't get that.
Thank you!
-
Read/write file in Unicode (UTF-16)
Hi, I have a problem to write a file in Unicode (UTF-16)
I have to read a file with LabView, change some settings and write the new data in the same file. The file uses Unicode UTF-16.
I downloaded a few library here: https://decibel.ni.com/content/docs/DOC-10153
I can read the file, convert the data to ASCII/UNI/UNI and then write the file. But when I open the new file with an editor like Notepad ++ there is some unexpected characters at the end of the line.
Even read the file and write exactly the same doesn' data not work.
I've attached an example.
Thanks for you the kind of support.
Right click on your functions read and write text files. There is an option to "Convert End Of Line". Who turned off the two functions.
As a side not, you need not close file functions. The functions Read and Write Text File will close the file that reference output file is not connected.
-
I have Chinese characters in a queue (queues make supports Unicode)?
I am aware that there is a number of tools that allow the use of Chinese characters in LabVIEW. I have successfully built an application where I am able to switch between English and Chinese, as well as all text, buttons, screen etc multi-column list boxes are updated correctly.
However, I do all my recording of events by using queues. When I remove one point, I want to write to a log (i.e. a ".txt" file) file, but the resulting file contains waste instead of Chinese characters.
As an experiment, I created a simple VI who reads an array of Chinese and written text into a text file and it works fine. But, as I say, if I try to do that using queues, I just just get garbage.
Any help would be much appreciated.
Lee
I don't know a lot about Unicode, but the issue could be the end of the line inserted by writing to a text file. Help for this function:
This function adds characters depending on the platform end of line (EOL) to the elements of a table even if you right-click the function and remove the check mark next to the menu item Convert EOL .
I changed it so that a string is constructed within a certain time a loop using a shift register and concatenate strings. In this way you write just a single strnig instead of an array of strings with the EOL. Yet once I don't know if that is still the question.
You should also take advantage of data flow and do not use the structure of the sequence. I modified your program to do. The cluster of queue data type specification must also be a typedef.
-
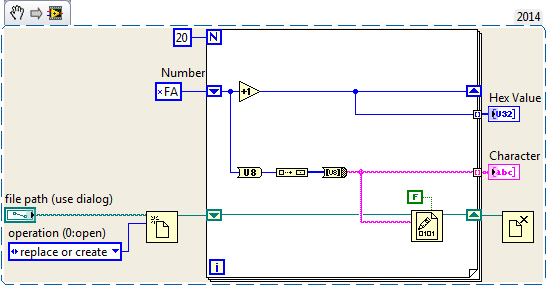
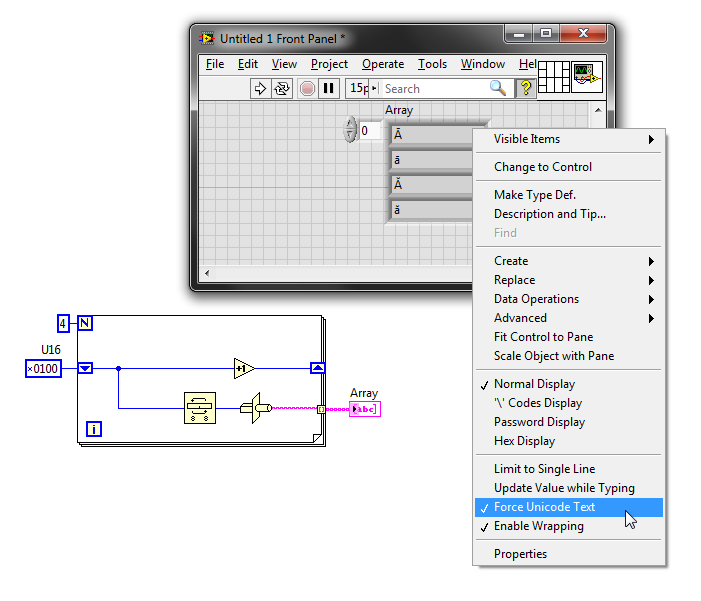
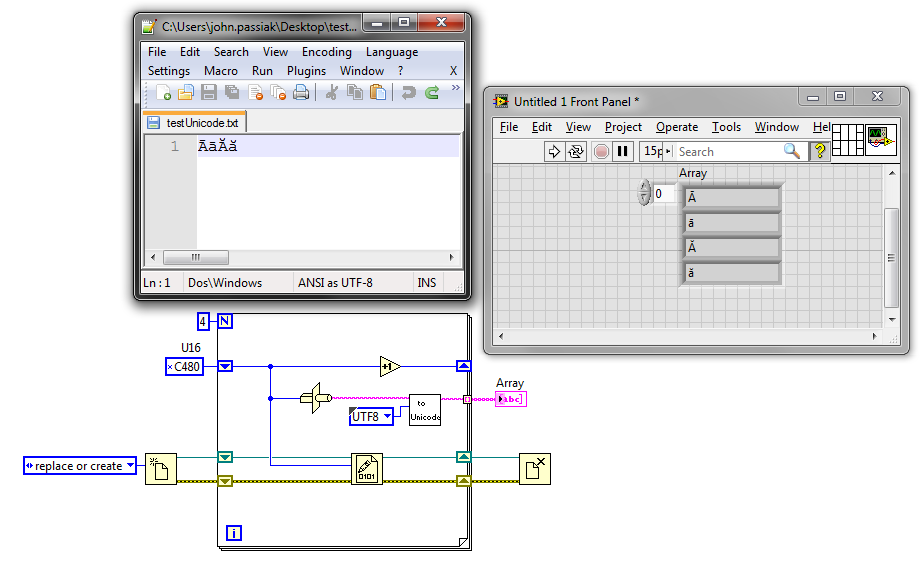
Generate and write unicode characters to file
The characters of genearted seems OK (up to x00FF), but after writing to file these characters and their values are different. Also the characters after 0x00FF are not good.
Any idea?
You should probably give this page than to read a thorough if you relied on the use of Unicode in your application. Here is a relevant excerpt:
ASCII technically only sets a value of 7 bit and can therefore represent 128 different characters, including characters such as the newline (0x0A) and return (0x0D) transport. However ASCII characters in most applications including LabVIEW are stored as 8-bit values which can represent 256 different characters. The 128 additional characters in the ASCII range are defined by the code page of the operating system aka "language for programs non - Unicode. For example, on a Western system, Windows uses by default the character set defined by the Windows code page 1252 Windows-1252 is an extension of another commonly known used encoding ISO-8859-1.
Offers Windows-1252 characters up to 0xFF (ÿ) but not something higher to 8-bit (for example no 0x0100). By default, LabVIEW support these uses of 8-bit, multibyte strings characters - only interpretation is based on the current code page selected in the operating system. You can turn on Unicode, the instructions in my first link (this is not supported and can be a little buggy from time to time...) to get the support of multibyte unicode characters to multibyte codepage characters not in the operating system.
Unicode has several encodings, and the bit raw to a character depending on the encoding used. LabVIEW limited unicode support seems to use UTF-16 (little endian) encoding for whatever it will be displayed in the user interface. So to get the characters displayed on the interface user, you must enable unicode (instructions illustrated in my first link) and write the appropriate UTF-16 code:
UTF - 8 is more common and therefore easier to work with outside LabVIEW (e.g. my version of Notepad ++ obviously do not support UTF-16). I usually find myself using UTF-8 for files format strings and convert them to UTF-16 for display in LabVIEW.
Unicode in my first link library has the necessary subVIs to convert between UTF-8 and 'Unicode' (i.e. UTF-16).
Best regards
-
Clipboard - Insert Utf8/Unicode characters to the Clipboard
I wonder how to add support for unicode to the Clipboard method? Because when am copy my app textarea text, he turns to? (Arabic letters).
Here are my codes which are related only to the Clipboard (added to these files):
. Pro
LIBS += -lbbsystem
all
Q_INVOKABLE void CopyText(QByteArray text);.cpp
#include
#include using namespace bb::system; qml->setContextProperty("_app", this); void ApplicationUI::CopyText(QByteArray text) { bb::system::Clipboard clipboard; clipboard.clear(); clipboard.insert("text/plain", text); bb::system::SystemToast *toast = new SystemToast(this); toast->setBody("Copied!"); toast->show(); } The function is called. QML
import bb.system 1.0 ActionItem { title: qsTr("Copy Text") onTriggered: { _app.CopyText(txtf1.text) } imageSource: "asset:///images/ic_copy.png" }I read a lot of forum messages and all API Tunis and I lost! as the use of tr() or QString::toUtf8 etc... !
How can I solve this?
Hello
Please try changing the QString type parameter:
void ApplicationUI::CopyText(const QString &text)
In the function convert the text to UTF-8 byte array:
void Application::CopyText(const QString &text) { bb::system::Clipboard clipboard; clipboard.clear(); clipboard.insert("text/plain", text.toUtf8()); bb::system::SystemToast *toast = new SystemToast(this); toast->setBody("Copied!"); toast->show(); }I think it was not working before because the function was already taking a QByteArray and implicit conversion (default) converted the ASCII instead of UTF8 encoding string.
BTW, in function of the names Qt applications usually start lowercase letters, but this should not affect anything.
-
Unicode conversion UTF8 in ODI
Hi guys,.
I have a CSV with unicode data in it, im trying to convert it to UTF8 to load the data correctly in the table. I tried to adjust the encoding setting in the connection as a jdbc
JDBC:SNPs:DBFile? ENCODING = UTF8
The connection is successful, but I see still unicode in the model data, I tried to use the CHARSET_ENCODING as well, but it does not recognize the types UTF8. I'm using the sql lkm file
Please notify
Thank you and best regards,
Fabien Tambisetty
I managed to solve it by changing the encoding to jdbc:snps:dbfile? ENCODING = UTF16
-
How to create A PDF with text OCR invisible and no Unicode font incorporated
We have a code that converts TIFF (usually traveled and OCR'ed) in PDF format. Currently, I extend this code:
- be PDF/A compliant (or PDF/A-1b "Unicode" or PDF/A-2u).
- Add Unicode text 'behind' the image to make the PDF can be accessed, and
- while making (2), do not embed all fonts (which is allowed in PDF/A, as long as the text is invisible).
I managed to generate a PDF file that pass the test of PDF/A preflight in Adobe Acrobat 9 (we have yet a license for a newer version), and which is also consistent with other requirements above, with one of the problems during their opening in Acrobat (9) or Acrobat Reader (DC), I get the error "cannot find or create the police."

Currently, we use the following code to PDF in our output:
3 0 obj <</Type/FontDescriptor/FontName/DummyInvisibleMonospace/Flags 34 /FontBBox[0 0 600 1000]/ItalicAngle 0/Ascent 1000/Descent -300 /CapHeight 700/StemV 0/MissingWidth 600>> endobj 4 0 obj <</Type/Font/Subtype/CIDFontType2/BaseFont/DummyInvisibleMonospace /CIDSystemInfo<</Registry(Adobe)/Ordering(UCS)/Supplement 0>> /FontDescriptor 3 0 R/DW 600/CIDToGIDMap/Identity>> endobj 5 0 obj <</Length 374>> stream /CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo 3 dict dup begin /Registry (Adobe) def /Ordering (UCS) def /Supplement 0 def end def /CMapName /Adobe-Identity-UCS def /CMapType 2 def 1 begincodespacerange <0000> <ffff> endcodespacerange 1 beginbfrange <0000> <ffff> <0000> endbfrange endcmap CMapName currentdict /CMap defineresource pop end end endstream endobj 6 0 obj <</Type/Font/Subtype/Type0/Name/F1/BaseFont/DummyInvisibleMonospace /Encoding/Identity-H/ToUnicode 5 0 R/DescendantFonts[4 0 R]>> endobj 7 0 obj <</Length 266193>> stream q 591.36 0 0 775.68 0 0 cm/I2 Do Q BT/F1 12 Tf 3 Tr % ... 1.34762 0 0 0.88 308.64 576.624 Tm<0043004F004D00420049004E0045>Tj % ... ET endstream endobj 8 0 obj <</Type/Page/Parent 1 0 R/MediaBox[0 0 591.36 775.68] /Resources<</XObject<</I2 2 0 R >>/Font<</F1 6 0 R>>/ProcSet[/PDF/Text/ImageB]>>/Contents 7 0 R>> endobj
Replace the name of fancy font with that of one of the 14 standard fonts, said Courier, does not help.
Unfortunately, I was not able to find or create PDF sample files that show how to add invisible text without embedding a font. I could operate without a Unicode mapping, referring to the Courier not incorporated and using WinAnsiEncoding. However, in order to use the Unicode format, I have to add some police structures, so there's a ToUnicode mapping according to the PDF/A standard, and then I can't get rid of this warning, which of course would make it unusable PDF for our customers.
I couldn't really find in the PDF specification or the PDF/A standard what exactly "do not embed a font" meant on a technical level. I assumed that this meant "leaving aside the tag /FontFile2 and police data, to which it refers", but apparently, this isn't quite the case.
If this is not possible, I might incorporate a fake police, like empty Adobe but with (empty) glyphs that have a width, but it really shouldn't be necessary if I understand standards.
Any help or tips at least are appreciated.
Published by: Gerben your; separate long lines in the code.
Published by: Gerben your; Comment on Adobe-Blank as police.
But it's a required parameter with sense. Encoding is highly relevant for embedded and not embedded fonts. So it must be good, not just there... and it is not normal for a substitution font...


Maybe you are looking for
-
Since the installation of Sierra, trackpad stuck on slow
I upgraded to macOS Sierra yesterday, and since then, the speed of follow-up was butchered on slow. Adjustment of the speed in the preferences system by moving the cursor to 'fast' does nothing and if I go out and re-enter the system preferences and
-
MacBook Pro says hard disk is almost full, startup disk is full. What should I do to make room?
My Macbook Pro says that my disk space is low. Another notice came that my Start Up disk was almost full. I don't know if they are the same thing, but I want to know how to make room. Also, how can I get rid of the useless things I let build up becau
-
quick way to define the family first name
It is possible to select all the contacts whose first name first and change their surname first? This option is grayed out when I select more than one contact. A kind of macro, maybe? Thankd b
-
Why am I forced to constantly create a new project from an old project name?
Everytime I open a project I worked on, say yesterday, GarageBand requires me to create a new name with a number attached to the current name. So, I have to remove my old project and rename the a new back to the old. Is there a way I can work on a
-
How to set the properties of the graph XY via VI Scripting plots
Hello Is there a way to change the properties of the graph XY plots in a VI script? Main VI, I create an XY chart in another VI in a VI script. Now, I want to change caption of the field names and their styles etc. I notice that these properties can