Creation of test data
Hi all
11.2.0.3
AIX 6
We have confidential data, such as tables with credit card, social security number, no. bankacct, etc. etc.
Our dev team needs an example of realistic data for their test UAT.
I want to create a function such that the confidential number will be converted into a format "reverse." And this is the data that I will give to developers.
How to create a function will convert numbers or characters to format reverse?
for example:
012345 = > 543210
abcDEF = > FEDcba
Thank you all,
#! / bin/bash
echo "enter the password:
read inputpassword
Tags: Database
Similar Questions
-
Creation of test data for a problem
Hello
I use this forum for a few months and it has been extremely helpful. The problem is that I really have no idea how to create some test data for a specific problem. I tried Googling, but to no avail. I had other users to create data test for some of my problems using a 'WITH' statement, but it would be great if someone could explain the logic behind it and how to address a specific problem where in the application, I use several tables.
I know this is probably a stupid question and I'm relatively new to sql, but it would help a lot if I understand the process.
Banner:
Oracle Database 11 g Release 11.2.0.2.0 - 64 bit Production
PL/SQL Release 11.2.0.2.0 - Production
"CORE 11.2.0.2.0 Production."
AMT for Linux: Version 11.2.0.2.0 - Production
NLSRTL Version 11.2.0.2.0 - ProductionWITH construction is known as factoring request void.
http://download.Oracle.com/docs/CD/E11882_01/server.112/e26088/statements_10002.htm#i2077142
(Not easy to find unless you know what it's called)
It allows you to start your request with a sub request which acts as a view definition that can then be used in your main query, just like any other view or a table.
This example declares two views on the fly - master_data and detail_data, which are then used in the example query. Each query sub emulates the data in the table by selecting literal values in the dual table a line using union all to generate multiple lines.
The two queries shows different results when an outer join is used in the second (+) {noformat} {noformat}
SQL> -- test data SQL> with 2 master_data as 3 ( 4 -- this query emulates the master data of a master detail query 5 select 1 id, 'Header 1' description from dual union all 6 select 2 id, 'Header 2' description from dual union all 7 select 3 id, 'Header 3' description from dual union all 8 select 4 id, 'Header 4' description from dual 9 ), 10 detail_data as 11 ( 12 -- this query emulates the detail data of a master detail query 13 select 1 id, 1 detail_id, 'Detail 1.1' description from dual union all 14 select 1 id, 2 detail_id, 'Detail 1.2' description from dual union all 15 select 1 id, 3 detail_id, 'Detail 1.3' description from dual union all 16 select 2 id, 1 detail_id, 'Detail 2.1' description from dual union all 17 select 2 id, 2 detail_id, 'Detail 2.2' description from dual union all 18 select 2 id, 3 detail_id, 'Detail 2.3' description from dual union all 19 select 2 id, 4 detail_id, 'Detail 2.4' description from dual union all 20 select 4 id, 2 detail_id, 'Detail 4.2' description from dual union all 21 select 4 id, 3 detail_id, 'Detail 4.3' description from dual 22 ) 23 -- main query 24 -- to select from test data 25 select 26 m.description, 27 d.description 28 from 29 master_data m, 30 detail_data d 31 where 32 m.id = d.id 33 order by 34 m.id, 35 d.detail_id; DESCRIPT DESCRIPTIO -------- ---------- Header 1 Detail 1.1 Header 1 Detail 1.2 Header 1 Detail 1.3 Header 2 Detail 2.1 Header 2 Detail 2.2 Header 2 Detail 2.3 Header 2 Detail 2.4 Header 4 Detail 4.2 Header 4 Detail 4.3 9 rows selected. SQL> edi Wrote file afiedt.buf 1 with 2 master_data as 3 ( 4 -- this query emulates the master data of a master detail query 5 select 1 id, 'Header 1' description from dual union all 6 select 2 id, 'Header 2' description from dual union all 7 select 3 id, 'Header 3' description from dual union all 8 select 4 id, 'Header 4' description from dual 9 ), 10 detail_data as 11 ( 12 -- this query emulates the detail data of a master detail query 13 select 1 id, 1 detail_id, 'Detail 1.1' description from dual union all 14 select 1 id, 2 detail_id, 'Detail 1.2' description from dual union all 15 select 1 id, 3 detail_id, 'Detail 1.3' description from dual union all 16 select 2 id, 1 detail_id, 'Detail 2.1' description from dual union all 17 select 2 id, 2 detail_id, 'Detail 2.2' description from dual union all 18 select 2 id, 3 detail_id, 'Detail 2.3' description from dual union all 19 select 2 id, 4 detail_id, 'Detail 2.4' description from dual union all 20 select 4 id, 2 detail_id, 'Detail 4.2' description from dual union all 21 select 4 id, 3 detail_id, 'Detail 4.3' description from dual 22 ) 23 -- main query 24 -- to select from test data 25 select 26 m.description, 27 d.description 28 from 29 master_data m, 30 detail_data d 31 where 32 m.id = d.id (+) 33 order by 34 m.id, 35* d.detail_id SQL> / DESCRIPT DESCRIPTIO -------- ---------- Header 1 Detail 1.1 Header 1 Detail 1.2 Header 1 Detail 1.3 Header 2 Detail 2.1 Header 2 Detail 2.2 Header 2 Detail 2.3 Header 2 Detail 2.4 Header 3 Header 4 Detail 4.2 Header 4 Detail 4.3 10 rows selected. -
The monitoring of test data to write in the CSV file
Hi, I'm new to Labview. I have a state machine in my front that runs a series of tests. Every time I update the lights on the Panel with the State. My question is, how is the best way to follow the test data my indicators are loaded with during the test, as well as at the end of the test I can group test data in a cluster, and send it to an another VI to write my CSV file. I already have a VI who writes the CSV file, but the problem is followed by data with my indicators. It would be nice if you could just the data stored in the indicators, but I realize there is no exit node =) any ideas on the best painless approach to this?
Thank you, Rob
Yes, that's exactly what typedef are to:
Right-click on your control and select make typedef.
A new window will open with only your control inside. You can register this control and then use it everywhere. When you modify the typedef, all controls of this type will change also.
Basically, you create your own type as 'U8 numéric', 'boolean', or 'chain' except yours can be the 'cluster of all data on my front panel' type, "all the action my state machine can do," etc...
-
PLSQL code to generate a simple test data
Hello
We need to create some test data for a customer, and I know that a PLSQL code would do the trick here. I would like the help of the community please because I'm not a programmer, or a guy PLSQL. I know that with a few simple loops and output statement, this can be achieved
We have a holiday table that has 21 rows of data:
CREATE TABLE "PARTY" ( "PARTY_CODE" NUMBER(7,0), "PARTY_NAME" VARCHAR2(50), ) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS"
SELECT * FROM PARTY; PARTY_CODE PARTY_NAME ---------- ------------------ 2 PARTY 2 3 PARTY 3 4 PARTY 4 5 PARTY 5 8 PARTY 8 9 PARTY 9 10 PARTY 10 12 PARTY 12 13 PARTY 13 15 PARTY 15 20 PARTY 20 22 PARTY 22 23 PARTY 23 24 PARTY 24 25 PARTY 25 27 PARTY 27 28 PARTY 28 29 PARTY 29 30 PARTY 30 31 PARTY 31 32 PARTY 32
We have 107 events; each event, to create a dummy test data candidate (a candidate for each party code (to be found in the table above))
It's the example of test data:
001,100000000000, TEST001CAND01, FNCAND01, 1112223333, 2
001,100000000001, TEST001CAND02, FNCAND02, 1112223333, 3
001,100000000002, TEST001CAND03, FNCAND03, 1112223333, 4
001,100000000003, TEST001CAND04, FNCAND04, 1112223333, 5
...
...
001,100000000021, TEST001CAND21, FNCAND21, 1112223333, 32
002,100000000000, TEST002CAND01, FNCAND01, 1112223333, 2
002,100000000001, TEST002CAND02, FNCAND02, 1112223333, 3
002,100000000002, TEST002CAND03, FNCAND03, 1112223333, 4
...
...
002,100000000021, TEST002CAND21, FNCAND21, 1112223333, 32
and this goes completely to the 107 event.
I know it's trivial and with a little time, it can be done. I'm sorry asking such a simple code, and I really appreciate all the help in advance.
Concerning
I had sorted it by PLSQL.
DECLARE
CNTR NUMBER: = 1;
BEGIN
FOR I IN 1.107 LOOP
for v_party_code in)
Select party_code order by party_code
)
loop
DBMS_OUTPUT. Put_line (LPAD (i, 3, 0) |) «, » ||' 1000000000' | LPAD (CNTR, 2, 0). «, » ||' TEST' | LPAD (i, 3, 0). "CAND' | LPAD (CNTR, 2, 0). «,, » ||' FNCAND' | LPAD (cntr, 2, 0). ', 1112223333. "| v_party_code.party_code);
CNTR: = cntr + 1;
end loop;
CNTR: = 1;
END LOOP;
END;
Thanks to all those who have been.
-
Hello
I created a few test (req.s, tests etc.) data in my OTM. Suppose that if I reinstall OATS, how can I get these test data in the new OTM. Can I export these test data to a CSV (windows) so that I can use in important in OTM.
Can someone help me in this topic?Hello
I see, well, you could do a report and export all the test cases, but I think it will be a lot of your time and you would lose another users, attachments, custom projects etc. fields...
If you need to re - install the database, the best thing to do is a back up and restore, I assume that you use the database default installed (Oracle XE), here are the instructions on how to do a back up and restore:
http://www.Oracle.com/technology/software/products/database/XE/files/install.102/b25144/TOC.htm#BABJCFBD
Concerning
Rajesh -
Need to insert test data in all the tables that were present in a schema
Hello
I use Oracle 9i.
10 tables were present in my current schema. All tables are not having all the records.
I need to insert test data in each table using a single procedure. (the table name is inparameter for the procedure)
For example, I test_emp, test_sal tables.
CREATE TABLE test_emp (ename varchar2 (40), number of sal);
CREATE TABLE test_sal (it NUMBER, rank NUMBER, will designate the NUMBER);
I need to insert some test data in these tables. I shouldn't use utl_file or sql * loader for this.
I tried below way.
I am not able to transmit these values to the collection dynamically to the INSERT statement. I tried many ways, but I am not satisfied with the code I've written.-- Incomplete code CREATE OR REPLACE PROCEDURE test_proc_insertdata(p_table_name IN VARCHAR2) IS BEGIN --Selected all the column_names, data_type, data_length into a collection variable from user_tab_columns. SELECT u.column_name, u.data_type, u.data_length --BULK COLLECT INTO l_col_tab FROM user_tab_columns u WHERE u.table_name = p_table_name; -- generated the values using below statement SELECT decode(u.DATA_TYPE,'VARCHAR2',dbms_random.string('A', u.data_length),'NUMBER',TRUNC(dbms_random.value(1, 5000)),'DATE',SYSDATE) val_list -- INTO collection varaible FROM user_tab_columns u WHERE TABLE_NAME = p_table_name; END;
Please help me if you know a better idea.
Thank you
SuriSuri wrote:
HelloI use Oracle 9i.
10 tables were present in my current schema. All tables are not having all the records.
I need to insert test data in each table using a single procedure. (the table name is inparameter for the procedure)
For example, I test_emp, test_sal tables.
CREATE TABLE test_emp (ename varchar2 (40), number of sal);
CREATE TABLE test_sal (it NUMBER, rank NUMBER, will designate the NUMBER);I need to insert some test data in these tables. I shouldn't use utl_file or sql * loader for this.
I tried below way.
-- Incomplete code CREATE OR REPLACE PROCEDURE test_proc_insertdata(p_table_name IN VARCHAR2) IS BEGIN --Selected all the column_names, data_type, data_length into a collection variable from user_tab_columns. SELECT u.column_name, u.data_type, u.data_length --BULK COLLECT INTO l_col_tab FROM user_tab_columns u WHERE u.table_name = p_table_name; -- generated the values using below statement SELECT decode(u.DATA_TYPE,'VARCHAR2',dbms_random.string('A', u.data_length),'NUMBER',TRUNC(dbms_random.value(1, 5000)),'DATE',SYSDATE) val_list -- INTO collection varaible FROM user_tab_columns u WHERE TABLE_NAME = p_table_name; END;I am not able to transmit these values to the collection dynamically to the INSERT statement. I tried many ways, but I am not satisfied with the code I've written.
Please help me if you know a better idea.
Thank you
SuriWith some effort, you can write dynamic insert queries. Read the data dictionary views ALL_TABLES and ALL_TAB_COLUMNS to get the data you need. You may need to limit the list to the tables you specify to hardcode the names of the tables. You can read the views for the information of table and column that you need generate the insert column orders. It will be a lot of work and it might be easier to simply hardcode values. Dynamic SQL is difficult to debug and work with: (.) Something like this (untested and totally undebugged)
declare cursor v_tab_col(p_table_name) is select * from all_tab_columns where table_name = p_table_name; v_text varchar2(32767); v_table_name varchar2(30); begin v_table_name := 'DUAL'; --chr(10) is a newline for readability when debugging v_text := 'insert into '||v_table_name||chr(10)||'('; --loop to build column list for v_tab_rec in v_tab_col loop --add comma if not first item in list if v_tab_col%rowcount > 1 then v_text := v_text ||','; end if; v_text := v_text || v_tab_rec.column_name; end loop; v_text := v_text ||') values ('|| --loop to build column values for v_tab_rec in v_tab_cur loop if (v_tab_rec.datatype = 'VARCHAR2') then --add comma if not first item in list if v_tab_col%rowcount > 1 then v_text := v_text ||','; end if; if v_tab_rec.datatype = 'NUMBER' then v_text := v_text || '9'; elsif v_tab_rec.datatype = 'VARCHAR2' then v_text := v_text ||'X'; end if; end loop; v_text := v_text || ')'; execute immediate v_text; end;This code is not effective, but shows how to do what you described. You'll have to code for all data types you need and find a way to take into account the primary/foreign keys, yourself. I leave it to you to find a way to avoid selecting the data twice ;)
Good luck!Published by: riedelme on July 24, 2012 13:58
-
How to insert 10,000 records test data into the emp table
Hi I am new to oracle can someone please help me write a program so that I can insert the test data into the emp tableSELECT LEVEL empno, DBMS_RANDOM.string ('U', 20) emp_name, TRUNC (DBMS_RANDOM.VALUE (10000, 100000), 2) sal, DBMS_RANDOM.string ('U', 10) job, TO_DATE ('1990-01-01', 'yyyy-mm-dd') + TRUNC (DBMS_RANDOM.VALUE (1, 6000), 0) hiredate, CASE WHEN LEVEL > 10 THEN TRUNC (DBMS_RANDOM.VALUE (1, 11), 0) ELSE NULL END mgr, TRUNC (DBMS_RANDOM.VALUE (1, 5), 0) deptno FROM DUAL CONNECT BY LEVEL <= 10000 -
Date of creation and the Date of importation
When you import photos or video in the Photos to a folder, the application uses the date of importation of integration rather than the original creation date. The result is that imports are all presented together under "Today." Many photos and video taken on different dates, so I would only they listed according to date of creation rather than be grouped under the date of importation. I went 'View' and checked "date of creation". Photos don't work with "SORT" because it is always grey. Any help would be greatly appreciated!
If you look in the window of Photos photos and videos are sorted by date with the oldest items at the top. This sort order cannot be change.
In the pictures window, the elements are sorted by the date imported into the library with the oldest at the top. The sort order cannot be changed here either.
So, you can use a smart album to include all your photos in the library and then sort them one of these ways:

The smart album could be created to this criterion:

that would include all the photos in the library. Now you can sort them as you like. Just make sure that the date is early enough to catch all the photos in the library.
Moments in Photos are new events, i.e. groups of photos sorted by date of catch.
When the iPhoto library has been migrated first to the pictures there is a folder created in the box titled iPhoto events and all migrated iPhoto events (which are now Moments) are represented by an album in this folder. Use the Command + Option + S key combination to open the sidebar if it is not already open.
NOTE: it has been reported by several users that if the albums of the event are moved in the iPhoto Library folder in the sidebar, they disappear. It is not widespread, but several users have reported this problem. Therefore, if you want to if ensure that you keep these event albums do not transfer out of the iPhoto events folder.
Is there a way to simulate events in pictures.
When new photos are imported in the library of Photos, go to the smart album last import , select all the photos and use the file menu option ➙ New Album or use the key combination command + N. Call it what you want. It appears just above the folder to iPhoto events where you can drag it into the events in iPhoto folder
When you click on the folder to iPhoto events, you will get a window simulated of iPhoto events.
Albums and smart albums can be sorted by title, by Date, with the oldest first and by Date with the most recent first.
Tell Apple what missing features you want restored or new features added in Photos Photo-Applefeedback.

-
do the initial value of test data
Hello world
I'm testing the scale, and as the firstl value which sensors shows me is not 0, I need my first initial value.
The thing is I use digital controller and I just subtract the first value of my data to see the actual data.
The thing is I want to do this program automatically, I mean when I press the button to start the program automatically measure the first data, save it and use it as initial data.
do you have an idea, suggestion? Thank you
See below.

-
Creation of spatial data connectivity data
Hello
I have a few spatial data, which I'll try to describe the relevant aspects:
-A LineSegment table, which contains information about cables, including the ID of the area (approximately 4 million lines)
-An array of location, that contains a LineSegmentID (one by one), and a column (space) geometry (approximately 4 million lines).
What I need to do, is to create a new table containing conceptual "nodes", containing the following columns:
-NodeID (number)
-(Number) LineSegmentID
-LineSegmentEnd (1 or 2)
So I need to prepare, for each cable, which other cable it connects, by comparing its ends with the endpoints of other cables in the same sector. A box contains cables up to 464. There are a total of 160 thousand areas.
I'm working on the most effective way to achieve this, ideally by making a batch which will take less than half an hour. Oracle is relatively new to me, but I'm guessing that the right approach would be to use a series of intermediate (intermediate) tables, as I believe nested cursors would be much too slow (I ran a simple test to confirm this).
I guess I'll have to get in a temporary table, the starting point and the end point of each cable using SDO_LRS. GEOM_SEGMENT_START_PT and SDO_LRS. GEOM_SEGMENT_END_PT, as well as the area ID. Join the table to itself, and then use SDO_GEOM. SDO_DISTANCE to work on what points are close together (for example less than one meter). However, I'm fighting to describe a step by step process.
Anyone has any ideas that can help?
(Oracle 11g)
Examples of data to illustrate the problem:
create table line_location (lineid number,
geometry sdo_geometry);
create table (ID, areaid) line;
-a cable in the box 1, 2 in area 4, etc.
insert into a values (1, 1) line;
insert into values of line (2, 4);
insert into values of line (3, 4);
insert into a values (4, 3) line;
insert into values of line (5, 3);
insert into a values (6, 3) line;
insert into values of line (7, 2);
insert into values of line (8: 2);
insert into a values (9, 2) line;
insert into values of line (10, 2);
-in reality, the lines are not necessarily straight and simple as these...
insert into line_location values (1, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (10,1,10,4))); -zone 1
insert into line_location values (2, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (3,9,5,9))); -zone 4
insert into line_location values (3, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (5,9,5,10))); -zone 4
insert into line_location values (4, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (1,1,2,1))); -zone 3
insert into line_location values (5, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (2,3,2,1))); -zone 3
insert into line_location values (6, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (2,3,3,3))); -zone 3
insert into line_location values (7, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (5,3,5,4))); -zone 2
insert into line_location values (8, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (4,4,5,4))); -zone 2
insert into line_location values (9, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (5,9,6,4))); -zone 2
insert into line_location values (10, MDSYS. SDO_GEOMETRY (2002,3785, NULL, MDSYS. SDO_ELEM_INFO_ARRAY (1,2,1), MDSYS. SDO_ORDINATE_ARRAY (5,7,5,9))); -zone 2
create table node_line (node_id number,
line_id number,
endpoint_id number,--1 for starting point, 2 for the end point.
area_id number
);
-expected here. If two lines are less than 0.5, whereas they should share a node.
insert into node_line values (1, 1, 1, 1); -insulated cable in zone 1, starting point node
insert into node_line values (2, 1, 2, 1); -insulated cable in zone 1, point endpoint node
insert into node_line values (3, 2, 1, 4); -zone 4: 2, node starting point of cable
insert into node_line values (4, 2, 2, 4); -zone 4, cable 2, point endpoint node
insert into node_line values (4, 3, 1, 4); -point 2 = cable endpoint node cable 3 start knot, etc.
insert into node_line values (5, 3, 2, 4);
insert into node_line values (6, 4, 1, 3); -node at (1,1)
insert into node_line values (7, 4, 2, 3); -node to (2.1)
insert into node_line (8, 5, 1, 3) values; -node to (2,3)
insert into node_line values (7, 5, 2, 3); -node to (2.1)
insert into node_line (8, 6, 1, 3) values; -node to (2,3)
insert into node_line values (9, 6, 2, 3); -(3.3) node
insert into node_line values (10, 7, 1, 2); -node to (5.3)
insert into node_line values (11, 7, 2, 2); -node to (5.4)
insert into node_line (12, 7, 1, 2) values; -node to (4.4)
insert into node_line values (11, 7, 2, 2); -node to (5.4)
insert into node_line (13, 7, 1, 2) values; -node to (5.9)
insert into node_line (14, 7, 2, 2) values; -node (6.4)
insert into node_line values (15, 7, 1, 2); -node to (5,7)
insert into node_line (13, 7, 2, 2) values; -node to (5.9)
Thank youHi Ronnie
Have you had a look at the script on the old NET?
This done in a slightly different result structure, what you're after.
I took the time this morning to see a bit optimized.Below you will find the result.
With clues about a couple and the use of the SDO_JOIN rather the sdo_relate this speeds up considerably.
I had tested on a 600 k line objects (which is not 4 million I know) and is reasonable ok on my test (non optimized) environment.On the "1 metre" close to each other, I would have supported itself by setting the tolerance appropriately, so
There should be no reason to perform within the distance checking. Obviously that permitting the resolution of your data.Have a look at.
Note that the final table is different in their structure, but this needs to be easily adjusted in the script if your node_line table must be exactly like you defined.
Luke
-drop the existing SEQ_TOPO
sequence of fall SEQ_TOPO;
-create sequences with caching
CREATE SEQ_TOPO CACHE 2000 SEQUENCES;
commit;
-drop temporary table
drop table temp_nodes cascade constraints;
-create temporary table and fill it with startponts and a field saying this are implemented, as X, Y, as we use it later to remove duplicates in a nonspatial way
create the table temp_nodes
as
Select a.lineid, a.areaid, sdo_geometry (2001, a.node.sdo_srid, SDO_POINT (t.X, t.Y, null), null, null) as a node, SEQ_TOPO.nextval node_id, the from ' AS STEND, t.x, t.y
Of
(select lineid, areaid, node sdo_lrs.geom_segment_start_pt (geometry) of line_location, where the LINE line_location.lineid = line.line_id), TABLE (SDO_UTIL. GETVERTICES (a.Node)) t;
commit;
-Insert the end points in the temporary table
insert into temp_nodes
Select a.lineid, a.areaid, sdo_geometry (2001, a.node.sdo_srid, SDO_POINT (t.X, t.Y, null), null, null) as a node, SEQ_TOPO.nextval node_id, 'E' AS STEND, t.x, t.y
Of
(select lineid, areaid, node sdo_lrs.geom_segment_end_pt (geometry) of line_location, where the LINE line_location.lineid = line.line_id), TABLE (SDO_UTIL. GETVERTICES (a.Node)) t;
commit;
-insert user_sdo_geom_metadata and have created for temp_nodes index
-adjust with appropriate metadata to srid, high and lowebounds values and the tolerance of your dataset
-Here the tolerance is set at 1 meter, this way there is no need to use a distance, let tolerance help us here
-Obviously this can work if tolerance is smaller, then the distance between the start and end of the link itself.
delete from user_sdo_geom_metadata where table_name = 'TEMP_NODES ';
INSERT INTO user_sdo_geom_metadata VALUES ("TEMP_NODES", "NODE", SDO_DIM_ARRAY (SDO_DIM_ELEMENT ('X', 0, 1000000, 1), SDO_DIM_ELEMENT ('Y', 0, 100000, 1)), 3785);
-create spatial indexes with gtype = POINT to use internal optimization
Drop index node_sx;
CREATE INDEX node_sx ON temp_nodes (node) INDEXTYPE IS MDSYS. SPATIAL_INDEX PARAMETERS ('sdo_indx_dims = 2, layer_gtype = POINT');
-create indexes on X, Y combination to accelerate "eliminating duplicates" (in the group by) is actually a "select unique" rather that remove duplicates
CREATE INDEX INDEX1 ON TEMP_NODES (X, Y);
CREATE the INDEX INDEX2 ON TEMP_NODES (node_id);
-create the final node table with unique nodes of the temporary table, x, to y could be omitted
create the table node_topo
as
Select a.nodeid, t.node, t.x, t.y
Of
(
Select min (node_id) as nodeid
Of
temp_nodes
Group x, Y
) an inner join
temp_nodes t
on (a.nodeid = t.node_id)
;
commit;
-insertion of metadata information
delete from user_sdo_geom_metadata where table_name = 'NODE_TOPO ';
INSERT INTO user_sdo_geom_metadata VALUES ("NODE_TOPO", "NODE", SDO_DIM_ARRAY (SDO_DIM_ELEMENT ('X', 0, 1000000, 1), SDO_DIM_ELEMENT ('Y', 0, 100000, 1)), 3785);
-create spatial indexes on the table to end node with gtype = POINT (internal optimization)
Drop index node_topo_sx;
CREATE INDEX node_topo_sx ON NODE_TOPO (node) INDEXTYPE IS MDSYS. SPATIAL_INDEX PARAMETERS ('sdo_indx_dims = 2, layer_gtype = POINT');
-create table node_link using SDO_JOIN between end node final tables and temp
-the NAYINTERACT should take care of the "alignment" as the tolerance will be applied
create the table node_line
as
Select lineid, max (st_ID) START_NODE_ID, max (en_ID) END_NODE_ID, max (areaid) AREAID
Of
(
SELECT b.lineid, case when b.stend = s ' THEN a.nodeid 0 otherwise end st_ID,.
cases where b.stend = 'E' THEN a.nodeid 0 otherwise end en_ID, areaid
TABLE (SDO_JOIN ('NODE_TOPO', 'NODE',
"TEMP_NODES", "NODE",
"(masque = ANYINTERACT')) c,"
node_topo has,
temp_nodes b
WHERE c.rowid1 = a.rowid AND c.rowid2 = b.rowid
)
Lineid group;
commit;
-items temp
drop table temp_nodes cascade constraints;
delete from user_sdo_geom_metadata where table_name = 'TEMP_NODES ';
commit;
seq_topo sequence of fall;
commit;
-
Site Web or web page of test data
How the lab browser manages the data displayed in the screenshots? They constantly change the data collected during a test session?
Thank you
Daryl
BrowserLab has 3 types of data from the screenshots and I do not know which type you average or if you ask on each of them, so I'll explain for all:
- Screenshots - screenshots are deleted immediately after that that they are returned to the client making the request. If they are not returned to the client (for example the request was cancelled), they are removed after a delay of several minutes.
- Given the local source - it's the HTML, CSS, Javascript, images and all other goods downloaded from your machine through Dreamweaver or our BrowserLab for Firebug add-on for a local Source request. This data is deleted as the screenshot is removed.
- Data cache browser - this is handled slightly differently for each browser that we support, based on the features of the individual browser. For Chrome and IE, caching settings are configured such that no data is never cached on our servers. For Firefox, the cache is erased immediately after the screenshot is generated. I'm not sure about how the Safari cache is managed, but it is likely to be one or the other of these two methods.
I hope that's clear, let me know if you have any other questions.
Mark
-
Cloning of the prod to test data (with names different ownerIDs/schema)
Hello
ID of owner or the schema of production data is different than in the Test environment; So what happens is that after cloning the database, all the tables are still owned by prod user and not the test user. So if we just update the ownerID in psdbowner, logging would not be possible because it begins to search tables in a different pattern. If we leave the entry in psdbowner as it is, then the connection is possible but is not what we want. We want owner id to be different in the TEST.
If we want to have all tables with an ID of owner different test than production; What measures should be taken?
Thank you
VikasYou must export from the user of the production and import in the test user.
IMPDP in db 10g and more, within REMAP_SCHEMA option. However, there is no real reason to have another username across different environment, it's much easier to have the same username across all the env, especially if you want to copy the data files...Nicolas.
Published by: Gasparotto N on May 31, 2010 16:46
-
Copy of the Prod to Test data forms
Hello
We have lots of data in production with business in data forms. I appreciate, is an ideal way to move these data forms of Test environment with the company data?
Thank you
Published by: user12250743 on April 14, 2010 11:47This will be the form without the data, the data is stored in essbase and no planning.
To extract the essbase data, you can use the script command DATAEXPORT calc, an MDX, excel addin, smart view report script.
The fastest is to use excel addin or smart display, retrieve the data, point to the test environment and then submit.See you soon
John
http://John-Goodwin.blogspot.com/ -
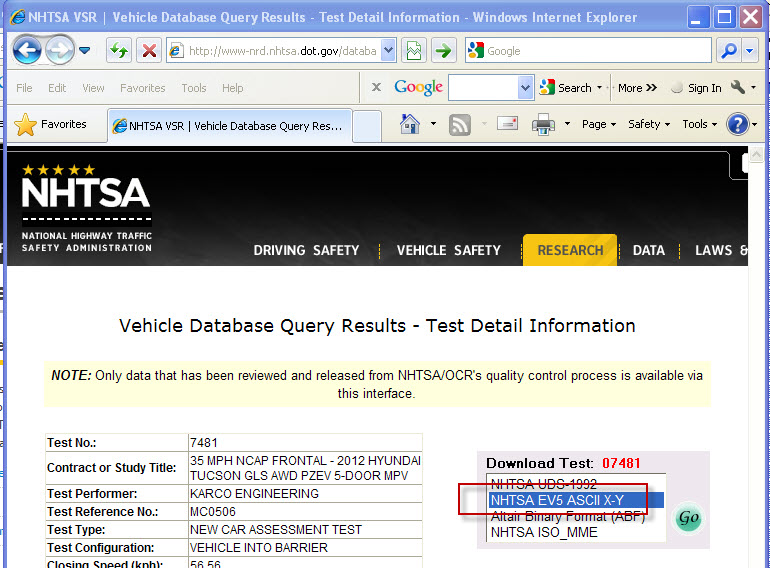
Data Plug In required format EV5 NHTSA crash test data
I was hoping that someone could make or link me to a Plug In data for this data type:
The link to the site is here:http://www-nrd.nhtsa.dot.gov/database/aspx/vehdb/testtabledetails.aspx?LJC=7481&existphoto=Y&p_tstno...
Thank you very much
Hello Wormspur,
I have attached a beta version of our NHTSA EV5 use for you.
To install:
- Please check out the attached ZIP file
- Double-click the "NHTSA_EV5.uri".
- The use will be installed and report success
- Open DIAdem, and you should be able to use the EV5 files just like any other DIAdem supported file format of data DIAdem
If you have any comments on this use, it would be much appreciated.
Best regards
Otmar
-
Creation of complex data signals
Hello
I have 2-channel audio that contains the parts real and complex of an I / Q wave. I'm trying this demodulation using block MSK modulation toolkit, but I have trouble accessing the i / Q stream in the right type. The MSK block requires a complex waveform input, but after the construction of this waveform complex, I discovered that he really had to a 'Waveform.ctl of complex data.
How can I get my data in the right format? I can't find a block which generates this 'Waveform.ctl complex data.
I have attached a picture of the situation.
Best regards
Jan
Try this
Right-click on the entry of complex waveform of this Subvi node MT demodulate MSK. Click on 'Create' > 'Constant '. Now remove the wire between the newly created constant and the Subvi. Adds a set of cluster name. Wire the constant in the top of the boot of cluster name. Left click and pull on the bottom of the boot of cluster name until 3 entries appear. Click with the right button on each entry and use the item select to get the entries you need.



Maybe you are looking for
-
I click on the star to bookmark and window, but after the passage of the mouse disappears.
I got it for a while where clicking the bookmark on any menu, even using the shortcut to just opens the box pop up for about 1 to 2 seconds before programming it disappear I tried to reboot to reinstall at a point of fitness there is an obvious probl
-
How can I make it work with just an Apple TV, AirPort Express and iPod/iPad/iPhone?
Hello people of Apple, I have some questions about a new "setup" of Apple products that I hope I can get to work between them. In other words, I need to know if what I am wanting to do in fact is possible with this new configuration. Current set up:
-
How to reset a bios password on Aspire 5570Z? I deleted mine while trying to change
I am giving my Aspire 5570Z to my neighbor and I wanted to remove the bios password. I went into the bios and delete the password and pressed on enter new password and confirm. Now I'm locked up. Help, please!
-
Download fail torch 9800 blackBerry smartphones
According to some opinions, I saw that the internet browser 2 must be abolished to solve the problem of download. My problem is that my only Internet lightBrowser 2 if deleted I can not navigate. Help, please! Need to solve the problem of download
-
White MacBook connected to hp deskjet f380 all-in-one: can print but cannot scan.
My Mac is version 10.6.8 When I insert the HP Scan Pro, it says "scanner is not found." I don't know why this is happening, please help.