DASYLab Write Data Module output Format
When writing the fields in an output file in ASCII mode with the option writing data Module and copy entries, entered the order in writing? Or, if the output field order can be changed? I guess the order of the output being written is 0. n. I can redraw the module so that the entry order corresponds to the order of output you want, but it makes the messy Visual design. I would like to be able to specify that the entries (copied to the outputs) are 1.n and written as 0.. n-1 and the 0th entry is written to the nth output. If I can manipulate their order in the module or do I redirect the entries to match the order of final output?
Thank you
The list of strings in the target file is determined by the entries in the module. They are always written 0... n.
There is no way to change the order inside the module. You need to link the entries in the order you want to that they have written.
The option of copy entered in any module is simply a way to keep tidy worksheet. It allows to "pass" the module. No processing is done, and the output channels are exactly the same as the input modules.
Checking the option in the module to write data does not affect the file that is created.
Tags: NI Products
Similar Questions
-
How many channels can I write to a file with the data Module write (Dasylab 12.00.00)?
I would like to write data from a large number of channels (up to 128) in the same file. Thanks to the write data module, I have up to 16 channels only! The only solution I found is to save data in different files 8... Is there a solution for this problem? I use DASYLAB V.12.00.00. Thank you
You can use the multiplexer unit, this will allow you to compress the 16 channels in 1 which saves up to 256 channels in a single file.
In the module of the file to write, you can then select options and, under the "input Type", select the values of mixed singles. You will then need to define how many channels in each entry will receive.
-
DASYLab how to write data to a file every 15 minutes
Hi all
I use dasylab and datashuttle/3000 to record data. What I want to do is to write data to a file every 15 minutes. I use the milti-file, which can write data to the file diffenret, but how do I control the timing, as the journal data every 15 minutes automatically.
The other problem is that I use FFT analysis of the frequency spectrum. How can I determine the value of frequency where the peaks that happens.
Thank you
Write less data in the file that you have collected requires the reduction of certain data.
There are three techniques to consider.
With an average or an average of block - both reduce the data by using a function of averaging, defined in the module. To accomplish the reduction of data, choose block or RHM mode in the dialog box properties, and then enter the number of samples/data values that you want to reach on average.
Average - when you reduce the data, you also should reblock data using the block length of the change in the output parameter. For example if you enjoy at 100 samples/second with a block size of 64, the average module configured on average, more than 10 samples will take 10 times longer to fill a block. The initial block represent 0.64 seconds, the output block represent 6.4 seconds at a sampling rate of 10 samples/second. If you change the size of output in one block, the program remains sensitive.
Average block - average values in a block against each subsequent block, where the average is based position. The first samples are averaged, all second samples are average... etc. The output is a block of data, where each position has been averaged over the previous blocks. This is how you will be an average data FFT or histogram, for example, because the x-axis has been transformed in Hz or bins.
Second technique - separate module. This allows to reduce the data and the effective sampling rate jumping blocks or samples. For example, to reduce the data in 1000 samples / second to 100 samples per second, configure the module to keep a sample, jumping 9, keep one, jumping 9, etc. If you configure to skip blocks, you will not reduce the sampling frequency, but will reduce the overall amount of data in a single block 9, for example. It is appropriate for the FFT data or histogram, for example, to have the context of the correct data.
Finally, you can use a relay and a synchronization module module to control. For example, to reduce a sample data every 15 seconds, configure a generator module of TTL pulses for a cycle of 15 seconds of time. Connect it to a Combi trigger module and configure it to trigger on rising and stop the outbreak directly, with a trigger value after 1. The trigger output connects to the X of the relay command input.
In addition to these techniques, you can change the third technique to allow a variable duration using a combination of other modules.
Many of these techniques are covered in the help-tutorial-Quickstart, as the data reduction is one of the most frequently asked questions.
In regards to the FFT... use the module of statistical values in order to obtain the Maximum and the Max Position. The Position of Max will be the value of the frequency associated with the Maximum value. The output of the statistics module is a single sample per block. Look at the different FFT sample installed in the worksheet calculation/examples folder.
-
How to write data from the acquisition of data in NetCDF format?
I connect to a set of data from the sensor through the DAQ assistant and want to write all data in NetCDF format. I have the required plugins installed, but still can not find how to do this.
Or the labview can only read the netcdf files, but cannot write it! Please let me know if there is any other way out. I have looked everywhere but could not find something useful!
Thank you
Hey,.
Sorry, the sheet in effect only allows to read NetCDF files, not writing to the NetCDF format.
Kind regards
-Natalia
-
global variable functional to read and write data from and to the parallel loops
Hello!
Here is the following situation: I have 3 parallel while loops. I have the fire at the same time. The first loop reads the data from GPIB instruments. Second readers PID powered analog output card (software waveform static timed, cc. Update 3 seconds interval) with DAQmx features. The third argument stores the data in the case of certain conditions to the PDM file.
I create a functional global variable (FGV) with write and read options containing the measured data (30 double CC in cluster). So when I get a new reading of the GPIB loop, I put the new values in the FGV.
In parallel loops, I read the FGV when necessary. I know that, I just create a race condition, because when one of the loops reads or writes data in the FGV, no other loops can access, while they hold their race until the loop of winner completed his reading or writing on it.
In my case, it is not a problem of losing data measured, and also a few short drapes in some loops are okey. (data measured, including the temperature values, used in the loop of PID and the loop to save file, the system also has constants for a significant period, is not a problem if the PID loop reads sometimes on values previous to the FGV in case if he won the race)
What is a "barbarian way" to make such a code? (later, I want to give a good GUI to my code, so probably I would have to use some sort of event management,...)
If you recommend something more elegant, please give me some links where I can learn more.
I started to read and learn to try to expand my little knowledge in LabView, but to me, it seems I can find examples really pro and documents (http://expressionflow.com/2007/10/01/labview-queued-state-machine-architecture/ , http://forums.ni.com/t5/LabVIEW/Community-Nugget-2009-03-13-An-Event-based-messageing-framework/m-p/... ) and really simple, but not in the "middle range". This forum and other sources of NEITHER are really good, but I want to swim in a huge "info-ocean", without guidance...

I'm after course 1 Core and Core 2, do you know that some free educational material that is based on these? (to say something 'intermediary'...)
Thank you very much!
I would use queues instead of a FGV in this particular case.
A driving force that would provide a signal saying that the data is ready, you can change your FGV readme... And maybe have an array of clusters to hold values more waiting to be read, etc... Things get complicated...
A queue however will do nicely. You may have an understanding of producer/consumer. You will need to do maybe not this 3rd loop. If install you a state machine, which has (among other States): wait for the data (that is where the queue is read), writing to a file, disk PID.
Your state of inactivity would be the "waiting for data".
The PID is dependent on the data? Otherwise it must operate its own, and Yes, you may have a loop for it. Should run at a different rate from the loop reading data, you may have a different queue or other means for transmitting data to this loop.
Another tip would be to define the State of PID as the default state and check for new data at regular intervals, thus reducing to 2 loops (producer / consumer). The new data would be shared on the wires using a shift register.
There are many tricks. However, I would not recommend using a basic FGV as your solution. An Action Engine, would be okay if it includes a mechanism to flag what data has been read (ie index, etc) or once the data has been read, it is deleted from the AE.
There are many ways to implement a solution, you just have to pick the right one that will avoid loosing data. -
How can I save data in text format
How can I save data in text format in labwindows cvi
Hello
If your data is in a table, the easiest is to use the ArrayToFile function.
Automatically, it creates a file and puts your data in it depending on the size you provide.
If you have individual samples you need to write from time to time, you can either collect them in a table and then use ArrayToFile or open a file with fopen and write them as they are acquired with fwrite.
Hope this helps,
-
How constantly write data in a txt file
Hello
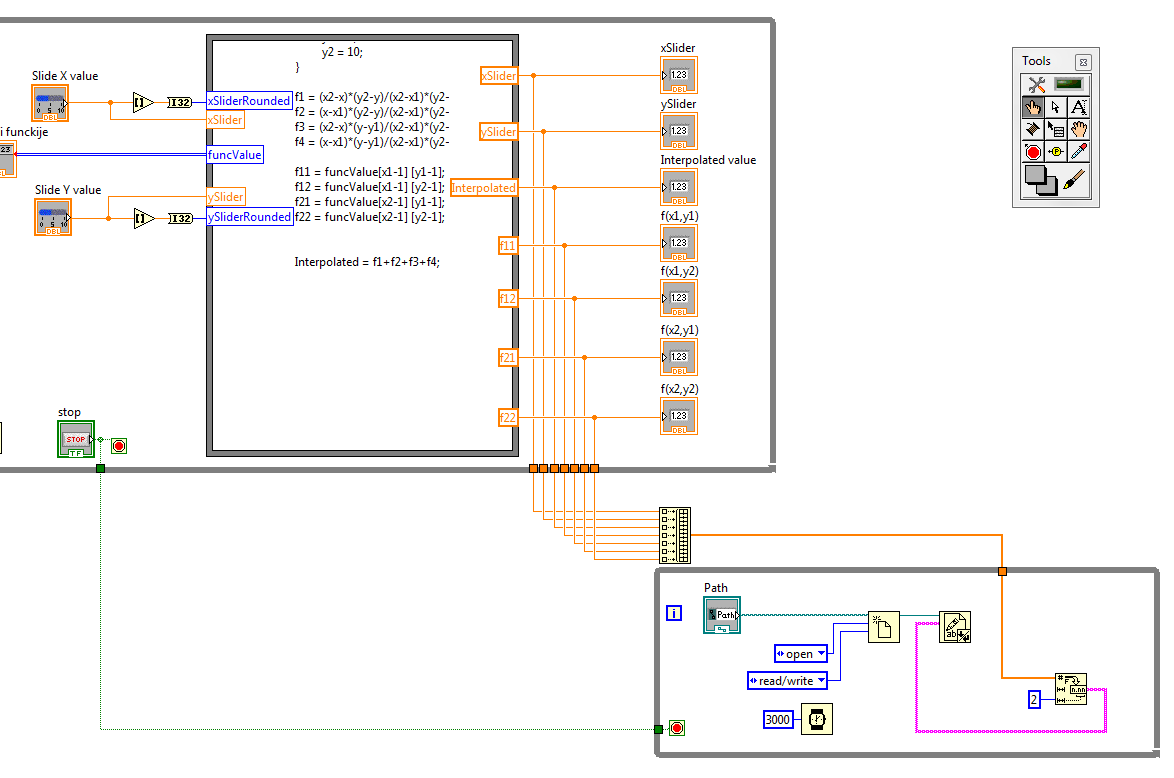
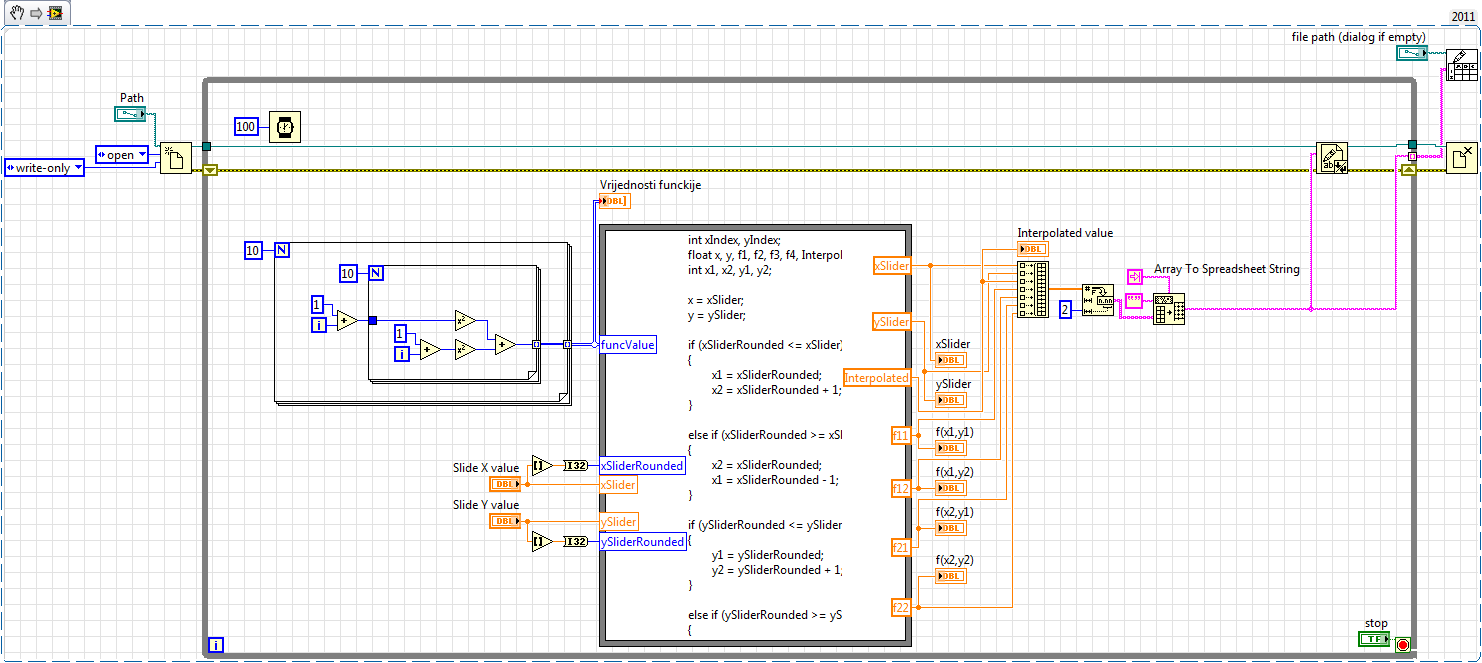
first of all, sorry for the bad English, but I have a problem to write data continuously to the txt file... I have a chart 2D with values based 2 sliders (sliders values) and some functions I want to interpolate the value by using the bilinear method... and after that the value of the sliders, interpolated value and the value of the closest points, I want to write to a file txt... for every 2-3 seconds perhaps, it would be ideal to be formatted as ::
x y f f1 f2 f3 f4
.. .. .. . .. . .. ... . ..
... ... .. ... ... ... ...but... first of all I have a problem with writing data, because every time he deletes old data and simply write a new and it is not horizontal... I am very very new to this (it's obvious) and any help will be very grateful

Thank youDiane beat me to it, I made a few changes to your code, so I'll post it anyway.
As proposed, please go through the tutorials.
I added an entry to the worksheet at the end node just to show it can be done at the end so. Table of building on a while loop is not very efficient memory, but it's just to show you what can be done. If you plan to go this route, initialize an array and use the subset to the table replace.
All the best.
-
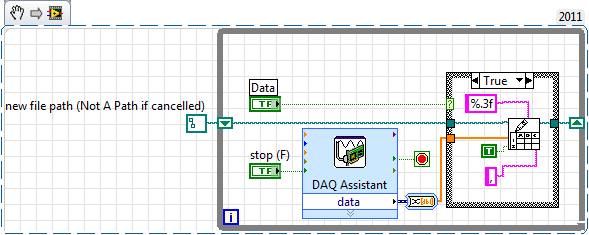
Write data to data acquisition in a .txt or .csv file
Hello
I want to write the DAQ data inot a file .csv or .txt, so I'll try to handle 'Write in a spreadsheet file', can cause I can record data in all formats. My concept is that data acquisition data will save in a file continuously when I press the button IT and when I press STOP button then it will ask the user to save the file.
I have attached the file VI.
But my problem is that every time he asks me a new file even if I put the file append as true.
All of the suggestions.
Thank you
Chotan
Try this
-
Error in saving of the PM FASTrack.
Impossible to analyze the dayYour operating system Date and time format do not match the expected for PM FASTrack run format. The format should be mm/dd/yyyy hh: mm:. The format isIt's my complete error message. The time is set in this format on the computer. How should I do?
Hello Murphy,
Thanks for posting your question on the Forums of community of Microsoft.From the description of the question, I understand this format date and time do not match for PM FASTrack run.Let me go ahead and help you with the issue.You did changes to the computer before the show?I suggest for the link and follow the steps in the article, and check if this can help:Change the display of dates, times, currencies, and measuresAlso, check out the support links:PM FASTrack support.I hope this helps. If you have any other queries/issues related to Windows, write us and we will be happy to help you further. -
Dear all,
Select emp_no in emp;
my output is
1
2
3
4
But I want that as output format
1,2,3,4
Could you please tell me which application should I write it to achieve.
Concerning
Rajat
Hi, Rajat,
This is called the aggregation of the chain and this page:
ORACLE-BASE - String aggregation Techniques
shows several ways to do so. What sense does use? It depends on your requitrements and your version of Oracle. The LISTAGG built-in aggregate function is good for most purposes.
-
Hello
I have 4 columns, I need the output format using carriage returns between values and removing the label for nulls, such as only the columns filled with values are displayed:
Name: emp.first_name
Medium: emp.middle_name
Name: emp.last_name
Address (line 1): emp.ext_contact_addr1
for example: -.
If the name is null then output would be
Middle: Thomas
Family name: James
Address (line 1): 10 william st
If the name is null, then output would be
First name: Tessa
Family name: James
Address (line 1): 10 william st
etc...
Please help me.
Hello
Here's a way
SELECT LTRIM (NVL2 (emp.first_name
, ' Name: '. EMP.first_name
NULL
)
|| NVL2 (emp.middle_name
, CHR (10) | ' Average: ' | EMP.middle_name
NULL
)
|| NVL2 (emp.last_name
, CHR (10) | ' Last name: ' | '. EMP.last_name
NULL
)
|| NVL2 (emp.ext_contact_addr1
, CHR (10) | ' Address (line 1): ' | EMP.ext_contact_addr1
NULL
)
, CHR (10)
) AS output_string
WCP
;
Using NVL2 like this, the label for each line gets concatenated only if there is some data to go with it.
If the name is NULL, which means that the output_string will begin with a character of new line (which is CHR (10) on my system, you may need to change this). I used LTRIM to remove this first newline character, if there be one.
You can also consider the results of unpivoting so that you have between 0 and 4 lines in the result set for each row in the emp, with 4 items on separate lines.
-
Hello community! Sorry, it's so rudimentary. Can anyone offer advice on how to better format the output of the below? As it is, it prints it just without formatting - I want out as the output format-table and I would have zero decimal places in the output of Write-Host $CurrentItemHdd.CapacityGB. Thank you!
foreach ($VmItem to $MyVms)
{
$CurrentItemHdd = get-disk hard - VM $VmItem
Write-Host $VmItem.Name $CurrentItemHdd.CapacityGB
}
To create an exit in your PowerCLI script like the Format-Table output, you must create an output object. There are several ways you can do. One way is to use the PowerShell New-Object as shown in the below script cmdlet. The properties in the New-Object cmdlet output are not classified. That's why I redirect the output to the Select-Object cmdlet to order.
Your original script will generate a table for the CapacityGB property, if a virtual machine has more than one hard drive. That's why I introduced a second foreach to browse the hard drives. Because you probably want to know that CapacityGB belongs to the hard drive, I added the property 'hard drive '.
[Math] .NET: Round() function is used to supplement the CapacityGB to zero decimal places.
The character '&' at the beginning of the script and the scriptblock around the script are necessary to allow to channel the output of the script to another cmdlet as Export-CSV. foreach is not a cmdlet, and therefor you cannot use the out of foreach in the pipeline without using this trick.
& {foreach ($VmItem to $MyVms)
{
foreach ($CurrentItemHdd in (Get-disk hard - VM $VmItem))
{
New-Object PSObject-property @ {} TypeName
VM = $VmItem.Name
"Hard drive" = $CurrentItemHdd.Name
CapacityGB = [Math]: Round($CurrentItemHdd.CapacityGB,0)
} |
Select-Object - property, CapacityGB VM, 'Hard drive'
}
}}
Post edited by: Robert van den Nieuwendijk
-
Hello
Data in TAB_DTL for an APPID using, I need to generate a report in the following format.
For the calculation of A logic) DAYS: difference in days of the next later DateCREATE TABLE TAB_DTL ( APPDATE DATE, AMOUNT NUMBER(12,2), STATUS VARCHAR2(1), RATE NUMBER(5,2) ); INSERT INTO TAB_DTL ( APPDATE, AMOUNT, STATUS, RATE ) VALUES TO_DATE( '13/09/2011 10:50:45 AM','DD/MM/YYYY HH:MI:SS AM'), 500000, 'D', 13 ); INSERT INTO TAB_DTL ( APPDATE, AMOUNT, STATUS, RATE ) VALUES TO_DATE( '09/11/2011 1:15:30 PM','DD/MM/YYYY HH:MI:SS AM'), 5000, 'R', 13 ); INSERT INTO TAB_DTL ( APPDATE, AMOUNT, STATUS, RATE ) VALUES TO_DATE( '15/12/2011 3:20:31 PM','DD/MM/YYYY HH:MI:SS AM'), 5000, 'R', 13 ); INSERT INTO TAB_DTL ( APPDATE, AMOUNT, STATUS, RATE ) VALUES TO_DATE( '05/01/2012 10:25:11 AM','DD/MM/YYYY HH:MI:SS AM'), 5000, 'R', 13 ); INSERT INTO TAB_DTL ( APPDATE, AMOUNT, STATUS, RATE ) VALUES TO_DATE( '02/02/2012 4:23:34 PM','DD/MM/YYYY HH:MI:SS AM'), 5000, 'R', 13 ); INSERT INTO TAB_DTL ( APPDATE, AMOUNT, STATUS, RATE ) VALUES TO_DATE( '05/03/2012 11:15:45 AM','DD/MM/YYYY HH:MI:SS AM'), 5000, 'R', 13 ); INSERT INTO TAB_DTL ( APPDATE, AMOUNT, STATUS, RATE ) VALUES TO_DATE( '30/03/2012 11:55:10 AM','DD/MM/YYYY HH:MI:SS AM'), 5000, 'R', 13 ); INSERT INTO TAB_DTL ( APPDATE, AMOUNT, STATUS, RATE ) VALUES TO_DATE( '31/03/2012 11:59:00 AM','DD/MM/YYYY HH:MI:SS AM'), 470000, 'B', 13 ); OUTPUT FORMAT : APPDATE DR CR BALANCE ACCAMT DAYS CUMM 13/09/2011 10:50:45 AM 5,00,000.00 0 5,00,000.00 10301 58 10301 09/11/2011 1:15:30 PM 0 5000 4,95,000.00 6330 36 16631 15/12/2011 3:20:31 PM 0 5000 4,90,000.00 3655 21 20286 05/01/2012 10:25:11 AM 0 5000 4,85,000.00 4823 28 25109 02/02/2012 4:23:34 PM 0 5000 4,80,000.00 5456 32 30565 05/03/2012 11:15:45 AM 0 5000 4,75,000.00 4218 25 34783 30/03/2012 11:55:10 AM 0 5000 4,70,000.00 334 2 35117 31/03/2012 11:59:00 AM 0 0 4,70,000.00 35117
(B) ACCAMT: Balance * (unlike in the days of the next Date) * rate / days in the year
With the help of CASE / SQLs of LEAD, the same thing can be accomplished.
Thank you
-
Hi all
We use ud32 to test service using fml32 buffer. One of the result field is a double, when the value of the field data are displayed in exponential format.
Is it possible config output format? I don't want no exponential format. Its config possible in ud32?, it's a shell config?
I thank in advance.Hello
Unfortunately, there is not a way to control the release of ud/ud32. It just uses Fprint() which uses the format string "%g" to print floats and doubles. What you're asking for sounds reasonable. As an alternative it would be not difficult to use a script (awk or other) to convert the exponential value to format numbers in no exponential format.
If you really need, I would suggest opening and enhancement with the Oracle customer support request.
Kind regards
Todd little
Chief Architect of Oracle TuxedoPS ud/ud32 is really a pretty simple utility and it reproduce yourself would not be a lot of work.
-
Charger data warehouse does not write data
Hello
I need to know which products are the most popular, I know the tables to store this information
and ARF_QUERY ARF_QUESTION. I already have the charger running data warehouse module, if anyone knows
Why data warehouse loader does not write data in the database, I thank you.
I thank.The planner should treat the logs on a daily basis (by default the calendar begins charge to 22:00 and ends at 6:00). If you want to call the treatment yourself simply call the method loadAllAvailable of the SearchQueryLoader component. You can do this via the dyn/admin.
-Andrew
Maybe you are looking for
-
I get an error msls31.dll. Also I have trouble with joints, download files and download them. Especially in an email.
-
Tecra A8 - Touchpad has stopped working
Hi all! I have a Tecra A8 (model: PTA83E) who has an ALPS touchpad. The touchpad has stopped working even if it is visible and fully operational in 'Device Manager' and also the 'Control Panel '. Apparently there is nothing wrong with it but the touc
-
Hard drive failure, had to reinstall Windows. Among other random things that are annoying, I noticed that Vista wonder is no longer for what kind of network, I connect to. I fear it may default to private even if I connect to a public network. How
-
Receipt of the possible scam email virus attached in Vista
He was supposed to be sent to my son, his speeches, but he is only 14 years, isn't working, and he swears that he didn't send it. I know it didn't. Suspected Ive someones been in our accounts for a long time. but nobody is listening. in any case, I n
-
Cannot find how to disable computer alarm
Hi I have a problem with my computer. I have an alarm that keeps going off at 6:00 in the morning. I have windows7 and there is nothing on my computer that identifies it yourself is like an alarm. Anyone know what it is and how do I get rid of him? O