Extract values with regular Expression
How to extract the values in [] using regular expressions.With data As
(
Select 'AAAAAA[10] AAA: 19C' Txt From Dual Union all
Select 'XX[450]-10A' Txt From Dual Union all
Select '[5]AVC19C' Txt From Dual Union all
Select 'FVD[120]D2AC' Txt From Dual
) 10
450
5
120Or another:
SQL> ed
Wrote file afiedt.buf
1 With data As
2 (
3 Select 'AAAAAA[10] AAA: 19C' Txt From Dual Union all
4 Select 'XX[450]-10A' Txt From Dual Union all
5 Select '[5]AVC19C' Txt From Dual Union all
6 Select 'FVD[120]D2AC' Txt From Dual
7 )
8 --
9 select regexp_replace(txt, '^.*\[(.*)].*$','\1')
10* from data
SQL> /
REGEXP_REPLACE(TXT,'^.*\[(.*)].*$','\1')
---------------------------------------------------------
10
450
5
120
SQL>
Edit: even though I think it is misleading not escape the right hook, so I prefer:
SQL> ed
Wrote file afiedt.buf
1 With data As
2 (
3 Select 'AAAAAA[10] AAA: 19C' Txt From Dual Union all
4 Select 'XX[450]-10A' Txt From Dual Union all
5 Select '[5]AVC19C' Txt From Dual Union all
6 Select 'FVD[120]D2AC' Txt From Dual
7 )
8 --
9 select regexp_replace(txt, '^.*\[(.*)\].*$','\1')
10* from data
SQL> /
REGEXP_REPLACE(TXT,'^.*\[(.*)\].*$','\1')
---------------------------------------------------------
10
450
5
120
SQL>
just for cleanliness.
Published by: BluShadow on June 29, 2009 13:35
Tags: Database
Similar Questions
-
Mask a number with regular expressions
Hi @ll!
Is it possible to hide a given number
of "12345678" in "XXXX5678".
or '987458' to 'XX7458 '.
with Regular Expressions and without substr()? To display only the last four digits and the 'X' value for the rest. The size of the number is not always the same.Alex, I think the OP wanted the first 4 characters to hide ;)
Something like that?
select translate(substr('12345678',1,length('12345678')-4),'1234567890','XXXXXXXXXX') || substr('12345678',length('12345678')-3) from dual / TRANSLAT -------- XXXX5678More
with test_data as ( select '12345678' card_no from dual union all select '123456' from dual union all select '5678900' from dual ) -- End of test data select translate(substr(card_no,1,length(card_no)-4),'1234567890','XXXXXXXXXX') || substr(card_no,length(card_no)-3) from test_data / TRANSLATE(SUBSTR ---------------- XXXX5678 XX3456 XXX8900Arun-
-
Hello
I'm just experimenting with regular expressions
My information in table are as shown below
Now, I pulled the following query to find the rows that have 1TABLE NAME: - EMP_TEST STRUCTURE WITH DATA X_NAME --------------------- 12456com ab1245com AXM4554.com
Now, I want to do a query that will give me tose lines that do not have 1select * from emp_test where regexp_like (x_name,'[1]') RESULT AS EXPECTED : - X_NAME --------------------- 12456com ab1245com
Initially I have run the following query
After a bit of searching on Google I found an application that works as expectdselect * from emp_test where regexp_like (x_name,'[^1]') RESULT NOT AS EXPECTED : - X_NAME --------------------- 12456com ab1245com AXM4554.com
Where my basic question is that all seeking a 1 in a row we do not put the beginning ^ end $ and so on and theselect * from emp_test where regexp_like (x_name,'^[^1]*$') RESULT AS EXPECTED : - X_NAME --------------------- AXM4554.com
Works of query.
So why do [^ 1] does not work as shown, while excluding an amd why is ^ [^ 1] * $ necessary while excluding aHello
Elessar wrote:
So why do [^ 1] does not work as describedBecause regexp_like(str,'[^1]') means: search str who have at least one character that is not 1.
When regexp_like(str,'^[^1]*$') means: search str done characters that are not 1 start (^) at the end ($) -
Need help with regular expressions
Hi all
I need your help, because I have no ideas more...
I have the following problem: in the column of the database table, I have the string with the names of files already uploaded to the database. For example: + File1_V01.txt +, + File1_v02.txt +, + File1_01_v01.txt +, etc. The string _vxx * + or _Vxx * + (non-case sensitive) represents the version of the file.
Now the problem: I'll upload the file with the name + File1_v02.txt + (already exists in the table).
If the file name already exists in the table the pl/sql function should get the name of the file with the following version number. In my case it takes + File1_v03.txt +.
Is it possible to do this using SELECT with regular expressions?
Best regards and thanks!with t as ( select 'File_V05.txt' fn from dual union all select 'File_V04.txt' fn from dual union all select 'File2_v03.doc' fn from dual union all select 'File2_v115.doc' fn from dual union all select 'File2_v15.doc' fn from dual union all select 'File1_v03.doc' fn from dual union all select 'File1_v115.doc' fn from dual union all select 'File1_v999.doc' fn from dual union all select 'File2.doc' fn from dual union all select 'File2_v05.doc' fn from dual union all select 'File1_v01.txt' fn from dual union all select 'File1_v02.txt' fn from dual union all select 'File1_v1.txt' fn from dual union all select 'File1_v1.doc' fn from dual union all select 'File1_v2.txt' fn from dual union all select 'File2_v01.doc' fn from dual union all select 'File2_v02.doc' fn from dual union all select 'File1_ABC_v01_DEF.docx' fn from dual union all select 'File1_ABC_V02_ABC.docx' fn from dual union all select 'File1_ABC_v01_12_04_17.docx' fn from dual union all select 'ABC_V1_QWERT.pdf' fn from dual ) select fn, case when fn!=fn_new then last_value(fn_new) over(partition by regexp_replace(upper(fn),'V[[:digit:]]+','') --(.*?V0*)([1-9]+)(\..*?)$ order by nv rows between unbounded preceding and unbounded following ) else fn end fn_new from ( select case when v-1 <= 0 then fn else regexp_replace (fn, '(_v|_V)(\d*)', case when length(substr(fn,v+1,p-v-1)+1) > (p-v-1) then '\1'||to_char(substr(fn,v+1,p-v-1)+1) else '\1'||lpad(substr(fn,v+1,p-v-1)+1,p- v-1,0) end ) end fn_new ,fn ,case when v-1 <= 0 then -1 else substr(fn,v+1,p- v-1)+1 end nv from ( select fn, regexp_instr(upper(fn),'_V[[:digit:]]+',1,1,1) p, instr(upper(fn),'_V')+1 v from t ) ) order by fn FN FN_NEW ABC_V1_QWERT.pdf ABC_V2_QWERT.pdf File_V04.txt File_V06.txt File_V05.txt File_V06.txt File1_ABC_v01_DEF.docx File1_ABC_v02_DEF.docx File1_ABC_v01_12_04_17.docx File1_ABC_v02_12_04_17.docx File1_ABC_V02_ABC.docx File1_ABC_V03_ABC.docx File1_v01.txt File1_v3.txt File1_v02.txt File1_v3.txt File1_v03.doc File1_v1000.doc File1_v1.doc File1_v1000.doc File1_v1.txt File1_v3.txt File1_v115.doc File1_v1000.doc File1_v2.txt File1_v3.txt File1_v999.doc File1_v1000.doc File2.doc File2.doc File2_v01.doc File2_v116.doc File2_v02.doc File2_v116.doc File2_v03.doc File2_v116.doc File2_v05.doc File2_v116.doc File2_v115.doc File2_v116.doc File2_v15.doc File2_v116.doc -
Problem with regular Expression
Hello!!
I have a problem with the regular expression. I want to validate only one word, and second are the same. To do this, I wrote a regex
Model p=Pattern.compile("([a-z][a-zA-Z]*)\\s\1");
Matcher m = p.matcher ("nikhil nikhil");
Boolean t = m.matches ();
If (t)
System.out.println ("it's a game");
on the other
System.out.println ("is no match);
The result I get is always 'there no match. "
Your timely help will be very appreciated.
ConcerningHello.
You are missing a slash in the regex
Pattern p = Pattern.compile("([a-z][a-zA-Z]*)\\s\\1"); Matcher m = p.matcher("nikhil nikhil"); boolean t = m.matches(); if (t) { System.out.println("There is a match"); } else { System.out.println("There is no match"); } -
Need help with regular expression
I have a string like: separation by a comma as G, H, L
the table has values like this
Col1 Col2
ROW1 G
ROW2 F
ROW3 L
What is trying to achieve is to find out if G or H or L in the string of separated by commas are in col2. is it possible by using regular expressions or not we do split and the loops?
Thanks in advance.Hello
ora1001 wrote:
I have a string like: separation by a comma as G, H, Lthe table has values like this
Col1 Col2
ROW1 G
ROW2 F
ROW3 LWhat is trying to achieve is to find out if G or H or L in the string of separated by commas are in col2. is it possible by using regular expressions or not we do split and the loops?
Thanks in advance.
You don't even need regular expressions
INSTR ( ',' || col1 || ',' , ',' || col2 || ',' )will be greater than 0 if (and only if) co12 is one of the elements of col1.
If you're curious, a way of using regular expressions is
REGEXP_LIKE ( col1 , '(^|,)' || col_2 || '($|,)' )but it will be less effective than Instr.
Published by: Frank Kulash, November 5, 2010 11:38
-
Validation with Regular Expressions
I am validating data using regular expressions.
Here is a copy of the code.
< cfinput type = "text" name = "FQID_ #ATTRIBUTES. "FQID #_officer" width = "36" validate = 'regular_expression' pattern = "^ \bna\b$ |" ^ \d * [0-9](|. \d*[0-9]|,\d*[0-9])?$» required="#ATTRIBUTES.required#» activé = «Oui» message = «0,0 à 100 ou na, requis» value = «#ATTRIBUTES.) "FQID_Response.Officer #" style = "textAlign:right"; onchange = "removeDash (FQID_ #ATTRIBUTES. FQID #_officer); "/ >
I don't get any errors, but I'm still able to I want to enter in the text box. I try to limit to a number between 0 and 100 and excludes the decimal amount. It must also accept na if not applicable. As it is now, I can enter anything.Thanks, that explains it.
-
Need help with regular Expression (RegEx)
Try to wrap your head around a regular Expression for the following format example: 0022-C-4452 OR 0022-C-4452-C
* The 4 digits are always numbers
* The last 5 digits are alpha numeric
* Last (if used) digit is always 'C' (in reference to the second structure)
Hold the dashes for "auto fill" if possible? This would be in the Custom Format? Sequence of keys? Or Validation? I appreciate any help!
I still think that you did not correctly describe your problem.
1 figures of 4 characters.
Optional separator.
Then 6 alphanumeric characters and ' - '.
OR
1 figures of 4 characters.
Optional separator.
Then 6 alphanumeric characters and ' - '.
Optional separator.
Character 'C '.
Note that the "-" is not a number and not an alphabetic character. It is a white space character.
Try:
function {MyRe (cString)
var cFormatted = "";
var RE_MyCode0 = /^(\d{4})[-.]) {0,1} ([A-Za-a0 - 9-] {6}) $/;
var RE_MyCode1 = /^(\d{4})[-.]) {0,1} ([A-Za-a0 - 9-] {6}) [-.] {0,1} ([C]) $/;
If (RE_MyCode0.test (CString) == true) {}
cFormatted = RegExp. $1 + '-' + RegExp. $2;
}
If (RE_MyCode1.test (CString) == true) {}
cFormatted = RegExp. $1 + '-' + RegExp. $2 + '-' + RegExp. $3;
}
Return cFormatted;
} / / end of MyRe function;some tests;
var MyString = "0022-C-4452; good channel;
Console.println ("Input:" + MyString);
Console.println ("result:" + MyRe (MyString));var MyString = "0022-C-4452-C; string of Goo;
Console.println ("Input:" + MyString);
Console.println ("result:" + MyRe (MyString));var MyString = "A022-C-4452" / / bad string;
Console.println ("Input:" + MyString);
Console.println ("result:" + MyRe (MyString));var MyString = '0022-4452-CZ' / / bad string;
Console.println ("Input:" + MyString);
Console.println ("result:" + MyRe (MyString)); -
Grouping and backreferences with regular expressions on the window to replace the text
I'm really appreciate the inclusion of regular Expressions in the search and replace functionality. One thing miss me that East of backreferences in the replacement expression. For example, in unix tools vi or sed, I could do something like this:
that allow me to switch the places of first and secondPart and substitute totally thirdPart. If grouping and backreferences are already present in the window replace text, how do you properly call them?s/\(firstPart\) \(secondPart\) \(oldThirdPart\)/\2 \1 newThirdPart/g
Published by: Justin.Warwick on August 23, 2011 08:26You can vote on the request for this to the exchange of SQL Developer, to add weight to the implementation as soon as possible: https://apex.oracle.com/pls/apex/f?p=43135:7:3693861354483465:NO:RP, 7:P7_ID:16761
Kind regards
K. -
Mask creditcard number with regular expressions
Hi @ll!
Is there a way to hide a number of credit card of
"1234-1324-1234-1234" to "1234-1324-1234-XXXX.
using regular expressions without using substr?
The following works on a .net Application
regexp_replace (ccnum, "[0-9] (?)") =. {} 4})', 'X')
but doesn't seem to work in a sql statement.
Best regards.
Published by: m8r-qbkka9, November 16, 2009 05:11Alex Nuijten wrote:
regexp_replace (str, '(-[[:digit:]]{4})', '-XXXX') rstrOops, I meant:
regexp_replace (str, '([[:digit:]]{4}-)', 'XXXX-') rstr -
Please help with regular expression
Hello
With the help of my previous answers of the detachment, , I've updated the query. But I don't get the answer you want in all cases. Could you please help me? My query is based on the previous announcement. Any other way to do this?
I'd really appreciate it.
I should get:select ltrim ( regexp_substr(txt, '\[(\w+)', 1, level), '[') as id, /* id is number */ ltrim ( regexp_substr(ltrim ( regexp_substr(txt, ':[^]]+', 1, level), ':'), '\w+-*\d*', 1, 1), ':') as qid, /* Qid could be char/number/space any combination except ':' */ ltrim ( regexp_substr(ltrim ( regexp_substr(txt, ':[^]]+', 1, level), ':'), '\w+', 1, 2), ':') as num, to_date( ltrim ( regexp_substr(ltrim ( regexp_substr(txt, ':[^]]+', 1, level), ':'), '[^:]+', 1, 3), ':'),'MM/DD/YY') as effdate from ( select '[10946:M100:N:][10947:Q1222:N:][38198:PPP-2:N:][13935:PPP-6:N:][38244:QQQ-4:Y:01/01/10]' as txt from dual ) connect by level <= length(regexp_replace(txt, '[^[]'));
But, beID QID NUM EFFDATE 10946 M100 N 10947 Q1222 N 38198 PPP-2 N 13935 PPP-6 N 38244 QQQ-4 Y 01-JAN-10
Thank youID QID NUM EFFDATE 10946 M100 N 10947 Q1222 N 38198 PPP-2 2 13935 PPP-6 6 38244 QQQ-4 4 01-JAN-10Hello
If the column number is wrong, isn't it?
Describe what should be the num column. For example "num is the 3rd part of :-delimited list placed in square brackets.If this is what you want, and then change the definition of number of
... ltrim ( regexp_substr(ltrim ( regexp_substr(txt, ':[^]]+', 1, level), ':'), '\w+', 1, 2), ':') as num,TO
... REGEXP_SUBSTR ( REGEXP_SUBSTR ( txt , '[^]]+' , 1 , LEVEL ) , '[^:]+' , 1 , 3 ) AS num, -
Kind of cool thing I noticed with regular expressions
SELECT REGEXP_SUBSTR (' first pitch, second, third field, ',' [^,] *,', 1.2 ")
DOUBLE;
Looks like it's supposed to return:, third field.
but I'm null
try to run to another position later than 1
SELECT REGEXP_SUBSTR (' first pitch, second, third field, "," [^,] *,',14, 1)
DOUBLE;
output:, third field.
Now try adding 2 comma after "second field" while retaining the original code
SELECT REGEXP_SUBSTR ("first pitch, second, third field, ',' [^,] *,',1, 2")
DOUBLE;
Released:third field (as opposed to null)
I think here that oracle treats , the second field,
as first occurrence and leaves it there, so in fact there is no second occurrence because we have no comma to start the second occurrence.
The example comes from a manual I think the author meant that there is to be occurrence 2. I just thought it was sloppy. Maybe I'm wrong on my statement
"I think here that oracle treats the second field .
as first occurrence and leaves to whom, so actually there is no second occurrence because we have no comma to start the second occurrence. »
... but it seems OK for me.
other thoughts?
Hello
2776946 wrote:
...
I think here at Oracle treats, second field.
as first occurrence and leaves it there, so in fact there is no second occurrence because we have no comma to start the second occurrence.
...
Exactly! Occurrences do not overlap. Looking for a model that starts and ends with a comma 2 comma by disaster. You would need 4 commas in the chain to get a 2nd accident. If the comma after "second field" is part of the 1st appearance, then it can also be part of the 2nd event.
-
Hi all,
How can I get the result using regexp_replace and regexp_substr?
with tab as ( Select 'TEST( XX_XXXXXX, 12 ) ; AAAA' txt from dual union all Select 'TEST( AAAAAAAAA , 67 ); 1234' txt from dual union all Select 'TEST( 92233 , 47 ); 5234' txt from dual union all Select 'TEST( AAAAAAAAA , AA ); 897' txt from dual union all Select 'TEST( CCCCC 25 );' txt from dual union all Select 'TEST CCCCC, 45 );' txt from dual union all Select 'TEST( EDCCCC, 45 ;)' txt from dual union all Select 'TEST(BBBBBBBBB,12);' txt from dual ) -- Select regexp_substr(txt, '[^.*,. *][[:digit:]][^\).*$]') from tab / -- REGEXP_SUBSTR(TXT,'[^.*,.*][[: ------------------------------ 12 67 922 897 25 45 45 8 rows selectedMandatory Criteria "TEST" And "(" And "," And ")" And ";"
Kind regardsexpected result 12 67 47 Null Null Null Null 12Something like:
with tab as ( Select 'TEST( XX_XXXXXX, 12 ) ; AAAA' txt from dual union all Select 'TEST( AAAAAAAAA , 67 ); 1234' txt from dual union all Select 'TEST( 92233 , 47 ); 5234' txt from dual union all Select 'TEST( AAAAAAAAA , AA ); 897' txt from dual union all Select 'TEST( CCCCC 25 );' txt from dual union all Select 'TEST CCCCC, 45 );' txt from dual union all Select 'TEST( EDCCCC, 45 ;)' txt from dual union all Select 'TEST(BBBBBBBBB,12);' txt from dual ) select txt, case when regexp_like(txt,'^TEST\(.+, *\d+ *\) *;.*$') then regexp_replace(txt,'(^TEST\(.+, *)(\d+)( *\) *;.*$)','\2') end expected_result from tab / TXT EXPECTED_RESULT ---------------------------- --------------- TEST( XX_XXXXXX, 12 ) ; AAAA 12 TEST( AAAAAAAAA , 67 ); 1234 67 TEST( 92233 , 47 ); 5234 47 TEST( AAAAAAAAA , AA ); 897 TEST( CCCCC 25 ); TEST CCCCC, 45 ); TEST( EDCCCC, 45 ;) TEST(BBBBBBBBB,12); 12 8 rows selected. SQL>SY.
-
Number of shaped with preg_replace Regular Expression and PHP
Hello
I would like to add a 'dash' after every 3 digits in a given number (10 digits). For example, 9785678941 became 978-567-894-1. How could I achieve this with regular expression using PHP preg_replace?
Thank you.
The next solution is based on the example of "The use of backreferences followed literals digital" published on the php.net site.
In accordance with the $string, $pattern, $replacement nomenclature which is the php.net example use, here´s my modification:
<>
$string = '9785678941';
$pattern = ' / (\\d{3})(\\d{3})(\\d{3})(\\d{1)} /';
$replacement = ' ${1}-{2}-${3}-${4}';
echo preg_replace ($pattern, $replacement, $string);
?>
-
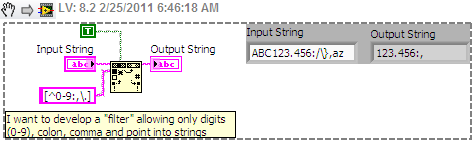
Allow specific characters - Regular Expression
Hello everyone
I am new to the regular expression and I have a very simple question. I use the function "read from the text file" to load a file delimited by tabs with 3 columns in my VI. Then, the string is converted to table and I use the values.
Nevertheless, I would like to develop a "filter" that allows only digits (0-9), colon, comma , and point to strings.
Using the function "matches regular expression", I tried a regular expression like this:
[^ 0-9] | [^\]. [|^:]| [^,]
But it does not work.
Could someone help me with this problem?
Thank you
Dan07
Use search and replace with regular Expression String selected.
Maybe you are looking for
-
I can't "Save as source" a MP4 object web page in Firefox 6 for MAC
I have MP4 download music VIMEO. When I click on the link on their website to download the video, it downloads and opens to a Web page of firefox. I used to be able to Ctrl click on Web VIMEO page window open on my MAC and then I could choose "Save a
-
How can I stop my child to get my SMS after every update?
How can I stop my child who shares my iCloud, to get my texts after every update?
-
Another question on serial port communication
Hi all! I started working with tools of communication series LV (actually, I'm a newbie in LV at all). The question is - how I effectively detect y at - he new data arrived in the read buffer VISA? I mean, in the examples I found, there is always a f
-
CANNOT RUN WINDOWS UPDATE ON VISTA
So I can't update anything on my computer that uses windows update, its been like this for about 3 days now, I tried to figure out how to solve this problem, but I do not receive either where can someone please help? Windows Security Essentials gives
-
When I turn on my laptop, the login page happens, but when I enter my password, it just re-boots. Then, he returned to the login page, where it does the same thing. So, it just goes back to the login page again and again and again. I tried restoring