filter on extract
Hi experts,
We have two tables with columns below,
emp dept
________ ___________________________
emp_id
empid emp_name
deptname desig
area
' ' We need to filter the data during replication if employee mapped with deptname = "OCS" "then the line of the emp table should replicate to target emp table, empid is a common column on the two table.
as select * from emp e, Department d where e.empid = d.empid and d.depname = 'OCS '.
can anyone please help on how to proceed in goldengate?
Thank you.
made with below approach, thanks
filter (check24.empid), sqlexec (chk id, the query "select dept FROM empid where empid =: pempid and deptname = 'OCS'", params (pempid = empid), beforefilter ' '));
Tags: Business Intelligence
Similar Questions
-
How in the filter to extract the attachments?
I want to do the filter that will automatically extract attachments to the special folder (for example, c:\MyFolder).
The program of "The bat" I can do it easily. But in Thunderbird, I can not find how do.Maybe there are some plugins?
Best regards, Ruslan Gilmanov
Try the add-on FiltaQuilla.
https://addons.Mozilla.org/en-us/Thunderbird/addon/FiltaQuilla/
-
Problem with case when try to alter the query from siimple
Hello PL/SQL gurus and Experts.
I'm stuck with a question (can be simple), but not gettings all headsway.
value returns is as - 1.46select 365/day_num_yr Anul_Fact from Date where date_dt = trunc(sysdate -1)
need to write it in the form of case (I have to multiply it to some other outer query), I want to store variable ina and then use the same in an outside -.
but when use the following syntax, then it always returns 0 and not the same output returned by the query above without the scabbard.
Help kindly, I appericate your time and effort in advance.select (case when date_dt =trunc(sysdate -1) then 365/day_num_yr else 0 END) Anul_Factuser555994 wrote:
Problem is that I do not get the output as 1.46, even the output is coming like the 0 only if using the query - nextselect /*date_dt, sysdate - 1 prev_dt, trunc(sysdate - 1) trunc_prev_dt,*/ case when date_dt = trunc(sysdate -1) then 365/day_num_yr else 0 end num_day from date_dim;Completely, which seems to be a question of DATA. Have you checked if the table contains data for DATE_DT = SYSDATE - 1? Can you check if the data stored do not have hours and Minutes stored?
Although I have provided examples of data, which is the same as the data in my main table and once I used the previous solution you provided and then also gives the result as same as those mentioned by you.
I think it's something like -
select date_dt, sysdate - 1 prev_dt, trunc(sysdate - 1) trunc_prev_dt, case when date_dt = trunc(sysdate -1) then 366/day_num_yr where day_num_yr=(select day_num_yr from date_dim where date_dt = trunc(sysdate -1)) else 0 end num_day from date_dim;Once we get the day_num_yr then he deviding by 366/day_num_yr :(
but he does not like throwing an error ORA-95 - missing keywordYes, it does not work
-case when date_dt = trunc (sysdate-1) then 366/day_num_yr where day_num_yr = (select day_num_yr from the date_dim where date_dt = trunc (sysdate-1))
due to a syntax of alien.
I don't think that you really need. I already said, with the data in your Table, you will be having only * 1 * record with a Non - zero value. Thus, simply apply a filter to extract the corresponding record SYSDATE - 1 and you should get an output which is Non-zero. If you apply a where predicate, then would not need you a CASE statement. You can directly use something like below:select date_dt, sysdate - 1 prev_dt, trunc(sysdate - 1) trunc_prev_dt, 365 / day_num_yr num_day from t4 where date_dt = trunc(sysdate - 1);Published by: Jen K, September 7, 2012 16:00
-
Adobe PDF Ifilter 9 64-bit - files randomly on the C drive (no Cause found, resolution)
Hello, I use the format Adobe PDF ifilter 9 64-bit on Windows Server 2008 R2 and Windows 7. We have a problem where when Windows Search analyzes a PDF file that contains attachments in them, the PDF filter will extract attachments and create a "temporary folder" on the C drive that starts by ' A9 * ' for each attachment. On Windows 7, these temp folders are deleted shortly after, on Windows 2008 R2, it is not. This has been tested on several machines.
I used ProcMon and notice that sends Windows 7 delete operations is not the case with 2008 R2. The process that sends the delete operation is the searchfilterhost.exe. I searched Google and found many people know this problem but with no resolution.
Performed troubleshooting:
ProcMon ran to see if Windows 2008 R2 sends operations (it does not) delete
Activated for TEMP system environment variables (they are correct)
Tested on several machines (easily reproducible)
Reinstalled Ifilter 9 (same number)
Indexed only 1 file with 1 file of pd with attachmetns (reproduced)
Windows 7 always deletes the temporary files/folders
Oh sorry. I was unclear in my question, I tried all of the following methods to change the key "reg"...
1 using the regedit and trying to change just one key. => ' Cannot modify UseSystemTemp: error writing to the new content value.»
2. then I tried again, run regedit "As Admin" even if I am connected with an account admin, with the same result.
3. then I tried to export the 'Search\Gathering of HKLM\SW\Microsoft\Windows Manager' in a reg file editing and merging back-online "some keys are open by the system or any other process."
None of these answers have managed.
The last error seems to imply that another service or application is locked this key.
I do not know how to find what he.
Ritchie
-
Extract all nodes and filter them based on the WHERE clause
<?xml version="1.0" encoding="UTF-8"?> <report_repository_summary> <sql sql_id="gyn915ynqjspa" sql_exec_start="08/19/2015 22:23:02" sql_exec_id="16777217"> <status>DONE</status> <sql_text>BEGIN DBMS_STATS.GATHER_FIXED_OBJECTS_STATS; END;</sql_text> <first_refresh_time>08/19/2015 22:23:10</first_refresh_time> <last_refresh_time>08/19/2015 22:24:52</last_refresh_time> <refresh_count>54</refresh_count> <inst_id>1</inst_id> <session_id>26</session_id> <session_serial>20363</session_serial> <user_id>0</user_id> <user>SYS</user> <con_id>3</con_id> <con_name>PDB01_1</con_name> <module>sqlplus@lab (TNS V1-V3)</module> <service>1_1.up.com</service> <program>sqlplus@lab (TNS V1-V3)</program> <plan_hash>0</plan_hash> <is_cross_instance>N</is_cross_instance> <stats type="monitor"> <stat name="duration">110</stat> <stat name="elapsed_time">109822091</stat> <stat name="cpu_time">78295097</stat> <stat name="user_io_wait_time">1388002</stat> <stat name="application_wait_time">1228</stat> <stat name="concurrency_wait_time">9175702</stat> <stat name="cluster_wait_time">41691</stat> <stat name="plsql_exec_time">39369731</stat> <stat name="other_wait_time">20920371</stat> <stat name="buffer_gets">616087</stat> <stat name="read_reqs">837</stat> <stat name="read_bytes">22998016</stat> </stats> </sql> </report_repository_summary>
With above document XML stored as varchar2 (4000) in 12.1.0.2.0, how can I retrieve and display the relevant information(sql_id,session_id,plan_hash,duration,read_bytes) based on the place where condition to filter on any node. For example.
select * from ( SELECT EXTRACT (xmltype.createxml (a.report_summary), '//stats/stat[2]/text()').getstringval () AS elap_time from dba_hist_reports a WHERE component_name = 'sqlmonitor' ) where elap_time > 100000000 /
Here, I try to get sql_id, sql_exec_id, duration and other information stored in the xml document by applying the where on elapsed_time condition. But to do this, I must write the part EXTRACT for all nodes in the inline view which seems like very bad way of writing of XML query. Is there an easy way to get all the information of nodes so that I can freely apply node whatever, I want in the WHERE condition to filter the records? No better way to write the code then the code below?
select REPORT_ID, EXTRACT (xmltype(a.report_summary), '//sql/@sql_id') "sql_id", EXTRACT (xmltype(a.report_summary), '//sql/@sql_exec_id') "sql_exec_id", EXTRACT (xmltype(a.report_summary), '//sql/@sql_id') "sql_exec_start", EXTRACT (xmltype(a.report_summary), '//status/text()') "status", EXTRACT (xmltype(a.report_summary), '//sql_text/text()') "sql_text", EXTRACT (xmltype(a.report_summary), '//first_refresh_time/text()') "first_refresh_time", EXTRACT (xmltype(a.report_summary), '//last_refresh_time/text()') "last_refresh_time", EXTRACT (xmltype(a.report_summary), '//refresh_count/text()') "refresh_count", EXTRACT (xmltype(a.report_summary), '//inst_id/text()') "inst_id", EXTRACT (xmltype(a.report_summary), '//session_id/text()') "session_id", EXTRACT (xmltype(a.report_summary), '//session_serial/text()') "session_serial", EXTRACT (xmltype(a.report_summary), '//user_id/text()') "user_id", EXTRACT (xmltype(a.report_summary), '//user/text()') "user", EXTRACT (xmltype(a.report_summary), '//con_id/text()') "con_id", EXTRACT (xmltype(a.report_summary), '//con_name/text()') "con_name", EXTRACT (xmltype(a.report_summary), '//module/text()') "module", EXTRACT (xmltype(a.report_summary), '//service/text()') "service", EXTRACT (xmltype(a.report_summary), '//program/text()') "program", EXTRACT (xmltype(a.report_summary), '//plan_hash/text()') "plan_hash", EXTRACT (xmltype(a.report_summary), '//is_cross_instance/text()') "is_cross_instance", EXTRACT (xmltype(a.report_summary), '//stat[1]/text()') "duration", EXTRACT (xmltype(a.report_summary), '//stat[2]/text()') "elapsed_time", EXTRACT (xmltype(a.report_summary), '//stat[3]/text()') "cpu_time", EXTRACT (xmltype(a.report_summary), '//stat[4]/text()') "user_io_wait_time", EXTRACT (xmltype(a.report_summary), '//stat[5]/text()') "application_wait_time", EXTRACT (xmltype(a.report_summary), '//stat[6]/text()') "concurrency_wait_time", EXTRACT (xmltype(a.report_summary), '//stat[7]/text()') "cluster_wait_time", EXTRACT (xmltype(a.report_summary), '//stat[8]/text()') "plsql_exec_time", EXTRACT (xmltype(a.report_summary), '//stat[9]/text()') "other_wait_time", EXTRACT (xmltype(a.report_summary), '//stat[10]/text()') "buffer_gets", EXTRACT (xmltype(a.report_summary), '//stat[11]/text()') "read_reqs", EXTRACT (xmltype(a.report_summary), '//stat[12]/text()') "read_bytes" from DBA_HIST_REPORTS a
Don't know why, but it pays just 1 or 0. Even in your case his statement just 0 or 1 for all X 2 columns table.
I guess I do something wrong in declaring XPATH for X 2 table but not able to find what it is.
It makes account 0 or 1 because path expressions are bad.
"For example: ' @name ="duration"
This is a Boolean expression, not a step of XPath and so gets evaluated as such, which gives 0/1 for false/true values.
What you need, it is something like this:
SELECT x1.* FROM dba_hist_reports t , xmltable('/report_repository_summary/sql' PASSING xmlparse(document t.report_summary) COLUMNS sql_id varchar2(15) path '@sql_id' , sql_exec_start varchar2(30) path '@sql_exec_start' , sql_exec_id number path '@sql_exec_id' , status varchar2(10) path 'status' , stats_duration number path 'stats/stat[@name="duration"]' , stats_elapsed_time number path 'stats/stat[@name="elapsed_time"]' , stats_cpu_time number path 'stats/stat[@name="cpu_time"]' ) x1 where sql_id = 'c1tb2666n5rfx' and sql_exec_id = 16777668 -
Hi, I upgraded from cs3 to cs 6 and can't find the extract filter, I have used many. CANY anyone help
The extract filter has been replaced by the edge to refine and improve the mask of tools that when you get used to them much better job than the extract. If you have CS3 installed you can copy the filter extracts in the filter plugins CS6 and if memory is correct it still works.
Terri
-
Where is the filter extracts in CS4?
Where is EXTRACTED the FILTER in CS4?
Hello
You can install the plugin from the link as its not longer included in Photoshop CS4 below:
Please let us know if it helps.
~ Sarika
-
where is the filter extracted on the cc photoshop?
I can't find the extract filter that has so much need. What can I do?
He was replaced by improve the contour and is no longer available in CC.
This thread is going into more details: http://forums.adobe.com/thread/636496
Gene
-
What happened to the filter extract in CS6?
I tried the option content aware and he did reduce the image to the bottom layer.
If you happen to be on a windows machine, the extract filter of the cs5 plugins in DOWNLOAD option should work in photoshop cs6 on the version of windows.
-
The link to the extract filter is missing. No idea why?
The extract filter is not included is cs5, but you can download it here:
http://www.Adobe.com/support/downloads/detail.jsp?ftpID=4688
You should look at the new edge sharpen in cs5, which generally don't
a better job than the filter extracts.
http://help.Adobe.com/en_US/Photoshop/CS/using/WS9C5407FF-2787-400B-9930-FF44266E9168a.htm l
http://TV.Adobe.com/watch/the-Russell-Brown-show/masking-basics-in-Photoshop-CS5/
MTSTUNER
-
I tried to find the filter extracts in CS4. Is there somewhere?
Did not have to use it in a while and can't find it.
I heard it is a plug in option and it is on the installation disc, but where. I can't find.
Please point me in the right direction
Thank you
HJMann42
In the Goodies folder on the drive.
-
Extract the plug-in filter not working
I tried to install the optional extract filter in CS4 Extended dropping them in the folder of photoshop filters. When I tried to open it a message appears that says: "Could not complete your request because it is not the right kind of document." When I restart photoshop it indicates the filter is not designed to run on windows or it contains an error. Anyone know what I'm doing wrong?
You try to use the 64 bit version in a PS 32 bit or vice versa. Find the correct respective version on your drive and install it in the appropriate directories.
Mylenium
-
Using the index to extract data without filter predicate
Hello
does anyone have an explanation for the following scenario:
I have a table T1 with an OID_IX index on column (object_id) - the table is a DEC dba_objects just to fill it with data.
There are no other current index. The table and index are analysed.
When I run the following query, the table is available in FULL (without using the index)
SELECT OBJECT_ID FROM T1;
SQL > select object_id from t1;
485984 selected lines.
Elapsed time: 00:00:01.76
Execution plan
----------------------------------------------------------
Hash value of plan: 3617692013
--------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | 485K | 2372K | 1528 (1) | 00:00:19 |
| 1. TABLE ACCESS FULL | T1 | 485K | 2372K | 1528 (1) | 00:00:19 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
0 db block Gets
7396 gets coherent
0 physical reads
0 redo size
2887158 bytes sent via SQL * Net to client
5684 bytes received via SQL * Net from client
487 SQL * Net back and forth to and from the client
0 sorts (memory)
0 sorts (disk)
485984 rows processed
But if I add a predicate (even if it is useless in this case) the index is taken and that the query runs faster:
JDBC@toekb > select object_id from t1 where object_id. = - 999;
485960 selected lines.
Elapsed time: 00:00:01.40
Execution plan
----------------------------------------------------------
Hash value of plan: 3555700789
-------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | 485K | 2372K | 242 (3) | 00:00:03 |
|* 1 | FULL RESTRICTED INDEX SCAN FAST | OID_IX | 485K | 2372K | 242 (3) | 00:00:03 |
-------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 Filter ("OBJECT_ID" <>-(999))
Statistics
----------------------------------------------------------
1 recursive calls
0 db block Gets
1571 gets coherent
0 physical reads
0 redo size
2766124 bytes sent via SQL * Net to client
5684 bytes received via SQL * Net from client
487 SQL * Net back and forth to and from the client
0 sorts (memory)
0 sorts (disk)
485960 rows processed
Here is my setup:
SQLsql-
drop table t1 purge;
create table t1 tablespace users in select * from dba_objects;
Insert into t1 (select * from t1);
commit;
Insert into t1 (select * from t1);
commit;
Insert into t1 (select * from t1);
commit;
create index oid_ix on t1 (object_id) tablespace users;
exec dbms_stats.gather_table_stats (null, 't1', cascade = > true, estimate_percent = > 100);
SQLsql-
In my case, the Table and the Index looks like this way:
JDBC@toekb > select table_name, NUM_ROWS, BLOCKS, AVG_SPACE from user_tables;
TABLE_NAME, NUM_ROWS BLOCKS AVG_SPACE
=======================================
485984 6944 T1 0
Elapsed time: 00:00:00.11
JDBC@toekb > select INDEX_NAME, BLEVEL, LEAF_BLOCKS, DISTINCT_KEYS, NUM_ROWS user_indexes.
INDEX_NAME BLEVEL LEAF_BLOCKS DISTINCT_KEYS NUM_ROWS
===================================================
2 1074 60745 485960 OID_IX
Elapsed time: 00:00:00.07
The table contains 7 times more than the index blocks!
any answer welcome
Best regards
Published by: guenterp on August 12, 2010 14:44The column is not defined as NOT NULL, then there may be values that are not in the index (because the index does not include null values). The useless predicate implies NOT NULL, then the index may be used.
-
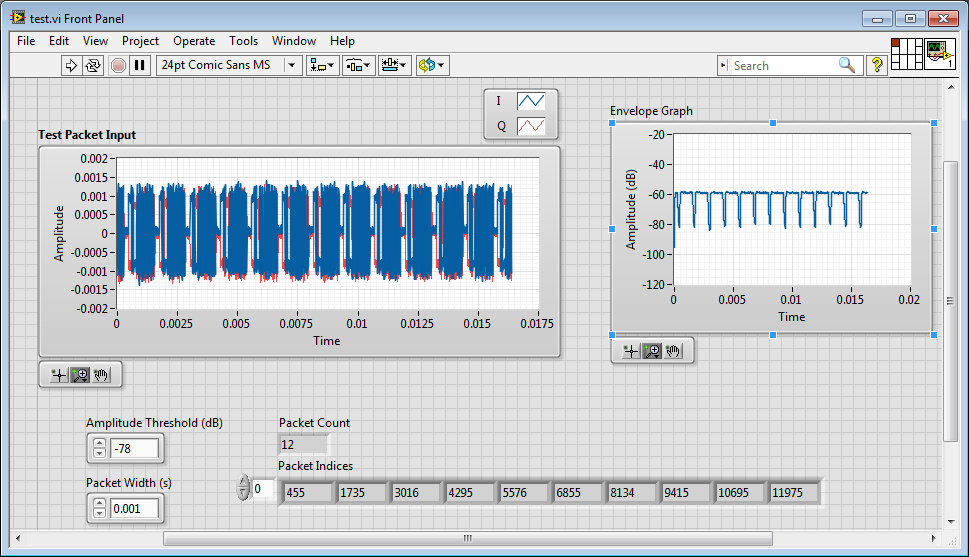
How to extract the signal from the waveform of my power level designated?
Hi all
How can I extract the signal of the waveform accroding to the power level? I read the Trigger & Gate .vi, but this vi retrieves the signal duration. I want to extract the signal depending on the power level.
As shown in the following figures, the signal I want to deal with is between 130000 to 140000, if I Zoom, I can see the useful signal is between 135400 to 138200. The question is how to extract the signal in the area?
I tried the sub_NoiseEst_And_Chop_Shell.vi in the example of Packet_based_link also, but this Subvi seems to be a bit slow. Can someone give me the best advice? Thanks in advance!
I'm working on something similar, but have not had time to fully develop.
My idea was to use an envelope detector (low pass filter) and then use a detection of energy VI on the envelope.
Here is where I left
-
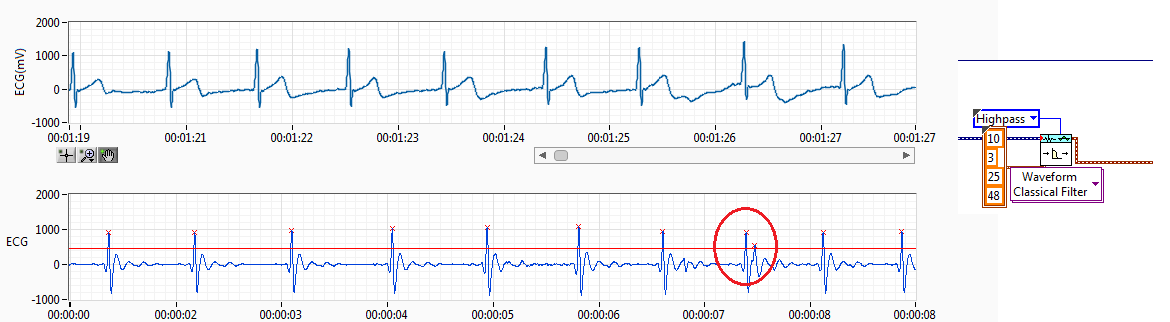
filter the peaks on the signal from ECG pulse!, help!
Hello
I have RCV of the ECG signal. I filtered the ECG signal and get the resource (interval between each pulse of ECG) records.
The source of the signal have noise I use a threshold but sometimes spikes of failure. Like the previous capture. Normally, if you get a pic of fault detected, I'll try to find this index to add to the left or right of the peak, normally I add to the lower value. This works if it has only a bad impulse between 2 good.
The problem come when I have more than a ridge between the two coupons.
Also, when the impulse of R a loss threshold I have trying to find the index and get 2 new reading making division 2 peak value.
I have attached the method I've used to adapt it. I only works if I have 1 Ridge added on real measures of R or pulse 1 loss R, when I have several pics no work.
I would like to hear an idea to make it work better. I don't like the idea of removing the value interval, I have 2 hours of reading and if I remove the values I have lower data outoput is why I tried to summarize or division of values to get the correct reading without losing any data.
Perhaps, there is any better filter for ECG of entry, so I have a R-own pulse and less noise between ECG pulses.
Any advice is welcome.
Best regards, Fred.
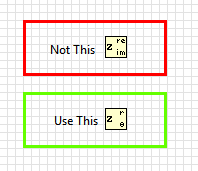
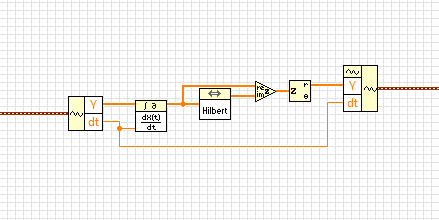
Almost. in the last step, you have extracted the real part of the complex waveform. Instead, you must retrieve the extent.
BTW, this idea isn't mine. I got from this article
http://www.ScienceDirect.com/science/article/PII/S0010482501000099


Maybe you are looking for
-
Windows experience index - how to raise the subscores lower?
OI, Hello everyone he... Index performance Windows...? Scoring? and subscores? It's something that I can up by making a few adjustments to my system or it comes to the hardware specification.I got a 3.1 as the lower under-score determined by my graph
-
120 want to cancel printing printing app
My daughter chose to print several pages from print apps (coloring pages, activities, etc.). While I don't give up my daughter, she was able to select several options until I'm able to stop him. Then, printing starts. I unplugged the printer and it s
-
Notification of wireless configuration, dll has not been registered, program will not work correctly
notification of configuration wireless dll has not been registered program will not work correctly
-
Message password incorrect on-screen even if no password login.
Hello! When I start my laptop, it shows the incorrect password and yet I didn't go the password again until I have click on the OK button and insert a password for the user account. Password error developed just a few days ago and often appear at the
-
transparent background animations
Hello!How can I put transparent background entertainment?Thank youRita