Fixing of capitalization of the index
I'm creating an index by working through the document, pointing out the words or phrases I want, press option 7 (CS4 on Mac). However, many of the words begin with a capital letter in the text while I'm envy them all lowercase in the index. I can fix it at registration. However, is there a way I could, once the index is finalized and I do not need to be updated more, change them to all lowercase letters as a batch? At that point, they will be just like another block of text.
Hi Mary,
If the first character in the origin of each paragraph in the story, which contains the text of the index, start with lowercase letters?
Then you can use an ExtendScript (JavaScript) to set the first character at the beginning of each paragraph of the selected lowercase text.
Select all of the text, which should be assigned, and run the following script:
app.selection[0].paragraphs.everyItem().characters[0].changecase(ChangecaseMode.LOWERCASE);
For usage, mounting and installation of ExtendScript scripts scroll down page of Peter Kahrel:
InDesign: Index of character styles. Peter Kahrel
Regrads,
Uwe
Tags: InDesign
Similar Questions
-
The Inbox file is currently 1.9 G, upward of about 0.85 G in September of this year. Probably due to a large number of parts attached. I have noticed that emails for 3/2015 for most missing although I find answers, etc., in the folder "sent" for the same period. The gap may occur after the last operation of compaction.
I tried both the 'fix' and deletion of the msf index option and rebuild. These emails are still missing, but now I have sporadic cases of multiple copies of an e-mail, 8.Inbox included 2013 as part of the day and I just moved the files from 2013 to a folder to archive but have not yet run the compaction on the Inbox to eliminate those emails that I fear that I could also inadvertently delete emails 3/2015.
Cannot open the raw file from Inbox in Notepad... get a too large file error, but it opens in wordpad even if research is extremely slow and basically unusable. Any thoughts?
More information on the compaction. It is recommended to leave Thunderbird cela automatically by setting a threshold (e.g. 1 MB). See http://kb.mozillazine.org/Compacting_folders
Also take a look at the archiving functionality.
https://support.Mozilla.org/en-us/KB/archived-messagesWhen your problem is solved, can mark the thread as "solved" Please?
Thank you. -
How to determine the index of an item in a cluster?
I have a small program that I put in place, as I'm just trying to get up to speed on Labview. I have a boolean cluster buttons and for some reason the top button of the page is coming through as Index 3. There are four buttons in the cluster, but for some reason, there has been a change. The top must be Index 0. How to do the things fixed? I do not see how to determine the index of each button through properties.
Thank you
The order of items in a cluster is the same as the order that you added them. To change the order, just right click and select "rearrange controls in the group. If you use Unbundle by name, you don't care the order.
-
How can I create the subtables based on the index positions in an array of distinct index?
Please forgive me if this question is fundamental or obvious. I'm relatively new to LabVIEW and I'm learning as I go along.
I have a table 1 d of the values of the index (the number of possible index values is not fixed, but varies between the uses of the application, it could be just {0, 1} on a day and {1, 5, 11 678} on another) and a table 1 d of the measured values (doubles). I would like to analyze measured in sub-tables for each index value, so that if my board index was:
[0 1 1 1 1 5 5 0 5 5 1 0 1 1 5]
and my table of measurement was:
[0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0.11 0.10 0.12 0.13 0.15 0.14]
I would like to return 3 sub-tables:
[0.1 0.12 0.8]
[0.2 0.3 0.4 0.5 0.11 0.13 0.14]
[0.6 0.9 0.7 0.15 0.10]
I know that there must be a simple way to do this, I guess I'm stuck just too matlab-table thinking to understand... Please help!
-jph
One of the problems is that your subsets are not of equal length and you also do not know the number of subsets in advance, you will need to decide on a suitable output structure. I suggest a picture of clusters, each element that contains the subset and, possibly, the tag.
Here's a very quick example (LabVIEW 8.0). See if it makes sense. Please check the correct operation. There could be bugs, but the concept should be clear.
-
FlowFieldManager focused on the issue of the index
I have a FlowField Manager where I added an optimization of resources that contains n labelfield bitmapfield. Now I add 5 vfms in ffm using the loop. I put touchEvent on the optimization of resources. I want that if you click on the 5th vfm, touchEvent must run one thing and vfm rest 4 clicks, click features must be the same. So I tried to get the index targeted when I click
gridVw.getFieldWithFocusIndex()
The problem I faced is that if I click on the optimization of the 5th resources first, I get a value of 5, but then if I click on any other vfms, I get 5 only instead of recovering the respective index. Help, please
Hey the error was on my side of the management of the touchEvents, I fixed it though

-
Impossible to move the index location winner 7 - he keeps back to original location
In Windows 7 64 bit Advanced Indexing Options, when I select a new location for the search index on another local hard drive, the indexing service appears to stop and restart as expected. However, when I go back to the settings of Index Options Advanced tab, it shows that the location of the current index has not changed. I looked in many places for solutions to this problem, but not much came. Any suggestions on what might be causing this and how to fix gratefully received.
This solution did not work for me. I solved it in the end as follows:
I open the Contol Panel Indexing Options and selected advanced and Options entered in the new location of the Index on a different hard drive. Before you select OK, then I have to Start Menu, Control Panel, administrative tools, Services and then stopped the Windows Search Service (right click, select shut down). Once the service has been stopped, I returned to the window from the Options/Advacned Indexing Options and select OK to confirm the new location of the Index and then selected near full operation. After a reboot, I checked again Indexing Options and confirmed that the new location was working.
-
HTML version will not browse the index subentries
Our document will mainly be used to the html version so you really have to make sure that users can search for their problem. We realized quickly that by using the ordinary serach usually does not solve the problem (especially if the keywords used are wide or the user does not know the exact term) we decided to optmize our index to display correct results.
Now, we are the most affected by the problems: If Browse us the index, it won't appear under entries. Never. It seems that it navigates only the first level.
Example: in this case, my search for "aktiver" Dozent won't show any results because it is a second entry to secondary school, only 'inquiry' (first level) is available.

Is this a bug or we can do about it? Do you have alternatives (for example, work with metadata search)?
Edit: version: FM 15
Hello
This is a problem known and surfaced recently. We are working on a fix for the same thing and it will be available soon.
Reference: Search Engine Optimization for a sensitive HTML output
~ Abhishek
-
ORA-01654: impossible to extend the index error or a bug?
Hi all
I have a question about the error "ORA-01654: impossible to extend the index schema1024 in tablespace tablespace .index '.
We use Oracle 10 g 2 (10.2.0.4.0) who has a diagram with auto extend feature enabled and more than enough space on the disk (like 130 + GB).
But still, we had this error and it is the third time that happens, what can be the cause and what can we do to fix or is this a bug?
Can you please give more information about the tbsp concerned and its data files?
Even if it's in autoextend, a small file tablespace has a maxsize, and even if you assign unlimited there a maxsize value that depends on the size of your block.
Kind regards
--
Bertrand
-
Hello
can you please explain the below topic?
That could leave gaps in the index, but the built-in function
NEXTallows you to iterate over any series of clues. -> this line- Arrays have a fixed upper bound, but the nested tables are unlimited (see Figure 5-1). Thus, the size of a nested table can increase dynamically.
Table in figure 5-1 against the nested Table
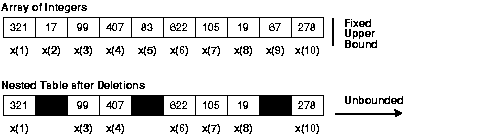
Description of the illustration pls81016_array_versus_nested_table.gif- Tables should be dense (have consecutive indices). So, you can delete individual items from a table. Initially, the nested tables are dense, but they can become sparse (have non-consecutive indexes). So, you can remove items from a table nested by using the integrated procedure
DELETE. That could leave gaps in the index, but the built-in functionNEXTallows you to iterate over any series of indexes.
Hello
Look at the second half of the Figure 5-1, the 'Nested Table after destruction". X (9), x.5 and x (2) elements have been removed, so the index values are 1, 3, 4, 6, 7, 8 and 10. There is a gap between 1 and 3, another gap between 4 and 6 and another gap between 8 and 10.
You could not use a simple FOR loop:
FOR j IN 1... 10
LOOP
...
END LOOP;
to iterate over a collection of rare as this, but you can use a loop where you get with the FOLLOWING indices:
j: = x.FIRST;
Then j IS NOT NULL
LOOP
...
j: = (j) x.NEXT;
END LOOP;
-
Hello
I'm working on my first real site and I'm having a problem, I can not understand.
with respect to the index page. I have my page set up how I want, but I can't seem to load as I want it.
This is the site
www.pineywoodsfarming.com
and if you notice, it's not about us section. But if you go to
www.pineywoodsfarming.com/index.html
then it works as I want. I think that it is a general question, I need to learn more about because I am not satisfied by the paths I have. for example, farm manager wanted section. I would like to take off the /pages/manager/html (those in bold I would take off)
can someone direct me to a topic that I need to learn more about. Thank you
If you have the time some creative comments would also appreciated but not necessary. (my main concern is that I did the home page is not user friendly)
Thanks for watching and helping out a new guy.
Edit:
He began to appear on his own without doing me anything, so I think that fixed the problem. Perhaps no clear historical as well as I thought I did. but can someone direct me to a topic to help me with my problem of address (or what I just my layout with this in mind the structure)
Thank you
You can easily get rid of the pages folder in the structure of your site by changing all of your index.html pages and placing them into folders for each section in the root of the site, like this...
index.html
on<-->index.html<-- would="" be="" the="" old="" about="" us="">
job<>
index.html<-- would="" be="" the="" old="" manager.html="">In this way, your pages would be www.pineywoodsfarming.com/about or www.pineywoodsfarming.com/employment
-
2015 RoboHelp. Main project generated does not recognize subcategories in the keywords in the index.
I have a master project containing external links to many projects (more than 70) and all the index entries are combined to create a master index for the help system. After I upgraded to RH2015 and I generated the subproject both main project, keyword/subkeyword relationships disappeared. Entry index keywords are listed without any subcatgories although the project has them. Like this:

So now I have a giant list of keywords without the indentations to delimit groups of keywords. I did a large part of the index by hand using the properties of the section and the format "keyword\subkeyword". This delimiter has changed? Anyone know or have the same problem? Am I missing a value somewhere?
I was by the who is new and Forums here, but don't see anything.
Thanks in advance.
Hello
I tried it with the latest patch applied RoboHelp and it works very well at my end.
Index the thin air in the WebHelp output.
We have fixed this bug in the latest version of patch. Please make sure that you have updated the HR. Latest version after you apply the hotfix would be 12.0.1.338
For the application of the hotfix, see help > updates and apply the available update.
If after application of the patch also, you face this issue please post here.
Thank you
Manu of FIFA -
Swedish reference in the index, always in the order of the English alphabet
My Indesign is in English but the text is in Swedish. I can do the headers of the index in the Swedish alphabet, making, correctly, the letters A, O and has come last, but the headers are always classified in English. For example, in Swedish, starting with en subheading would go ahead starting with Fo subheading. But adobe indexing o reads like an o and it highlights the r.
Is there any help out there or will I cut and paste the index entries? Thank you, Linnea
Linnea,
You must set the default language for the document as well. The language applied to text is not serious, but a default language. To set the default language for the document, make sure that nothing is selected (press Shift + Ctrl + A or its Mac equivalent), open the character Panel, then select Swedish. Now your index will sort correctly, no need to do anything with the fields of sort order.
InDesign behavior is strange here and fix clearly. It's like this:
= To get the sorted words correctly to their first letter, you must set the header type in the Sorting Options window
= To get words sorted correctly by the rest of the letters, you must set the default language for the document.
Peter
-
INDD 6.0.6 give up when I try to delete the reference in the index
See also http://forums.Adobe.com/message/4263687 for a discussion of the same problem. Ask here, I'm starting a discussion separate from the same issue affecting someone else (me).
I am running INDD 6.0.6 on OS X 10.6.8 on a MacBook Pro (2.53 GHz Intel Core 2 Duo). I have a document. INDD that is part of a 50-page book. The document includes an index. The index was imported originally from MS Word (from another user, unknown version). I'm rewriting the index, editing and re-release strongly. I recently discovered that the index is a reference without a target. To be clear, I don't know of a reference in the text of the document. It is an index entry, created by new cross-reference... menu item in the Index pane. There is no target, because when you look at it with forwarding options, there is a first-level topic, but the referenced field (below the Type see also) is empty.
I can't delete this entry. When I try to delete, INDD crashes. When INDD covers, he warns that the document is may be damaged, and if I try to delete it again, INDD breaks down. If I try to change the referenced field, INDD accepts but does not take into account the change (the closing of the shutter, but the remains of the unchanged index).
My current solution is to change the theme to ZZZ and add a new index entry (ZZZ: corrupt entry: delete this before shipping), but it is less satisfactory. What can I do to remove the corrupted index cross-reference?
The biggest problem is that even if you and someone from Adobe to be able to actually understand what that is the problem and that it is, in fact, a bug, there's nothing they can do to help you. There won't be any several bug fixes for CS4. My memory is that he had some bugs in indexing in the first version of CS4 and at least some of them are fixed, then you must install the patch...
-
Problems with the tabs (edition of the index) - CS4
I'm lle establishing a cumulative index of 136 pages for a magazine and I would like to limit the amount of handwork as much as possible. The paragraphs that are set up with a. 875 "withdrawal right and a-. 875 "final withdrawal line, which helps keep the entries to encroach on the space where manifest. However, I still see cases where the entries do not meet tab stops as I'd like (see below).
Is there a solution that will keep the text being the subject of a push into the gutter without having to manually forced line break me? Techincally, it is the last line of the paragraph, so there is nothing to make it "hang up" as I want. Ideas? Will I set up my tab stops incorrectly?

Good, I think that I have a solution that can be applied with find & change only.
1 Add a tab in the tab rule, just before indentation of law:

You must do this for all styles, if not every style is inspired by a common base style.
After that, the document goes out of whack:

2. use search and replace: GREP to search it
\t(?= *\u\l\l/\u\l\l \d\d)
and replace with this
\t\t
with the addition of the attribute of No Break.

3. now, it should be fixed - nothing extends beyond the tab that you just put

4. it creates a new problem, however. (I spotted just in time, too.) Look at the points - the "left half" is "BOLD", probably taken from the text in bold, half right is not, and there is a small amount of space between two tabs. Don't panic: apply a character style to all the tabs, using a GREP style:

-You can simply add this to your paragraph styles.
-
A SQL better to avoid increases in the index
Our developer past this code along with us as we receive some performance and behavior in our DB 9.2.0.7. Using this process, our 4 MB index rises to more than 1.5 GB and we are forced to re - org to bring him down.
1 it is with a delete and insert one after another, it will grow quickly? Would it not be better to perform all delete them first, validation and then inserts and commit?BEGIN PRETERR := 'NO ERROR'; PRETCODE := 0; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectalias'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectalias', V.PVR_ALIAS, NULL, NULL FROM T_PARTY_VERSION V, T_PARTY PT, T_PARTY_FUNCTION F WHERE PT.PTY_PARTY_ID = V.PVR_PTY_PARTY_ID AND F.PFY_PTY_PARTY_ID = PT.PTY_PARTY_ID AND SYSDATE BETWEEN PVR_EFFECTIVE_START_DATE AND PVR_EFFECTIVE_END_DATE AND PT.PTY_PARTY_STATUS <> 'D' AND V.PVR_ALIAS IS NOT NULL AND F.PFY_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectlender'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectlender', V.PVR_BUSINESS_NAME, NULL, NULL FROM T_PARTY_VERSION V, T_PARTY PT, T_PARTY_FUNCTION F WHERE PT.PTY_PARTY_ID = V.PVR_PTY_PARTY_ID AND F.PFY_PTY_PARTY_ID = PT.PTY_PARTY_ID AND SYSDATE BETWEEN PVR_EFFECTIVE_START_DATE AND PVR_EFFECTIVE_END_DATE AND PT.PTY_PARTY_STATUS <> 'D' AND V.PVR_BUSINESS_NAME IS NOT NULL AND F.PFY_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectlendername'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectlendername', PP.PRP_COLUMN_1, NULL, NULL FROM T_POLICY, T_POLICY_PARTY, T_POLICY_PARTY_PROPERTY PP WHERE POL_POLICY_ID = PPA_POL_POLICY_ID AND PPA_EFFECTIVE_END_DATE = TO_DATE('9999-01-01', 'RRRR-MM-DD') AND PPA_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' AND POL_POLICY_ID = PP.PRP_POL_POLICY_ID AND PP.PRP_EFFECTIVE_END_DATE = TO_DATE('9999-01-01', 'RRRR-MM-DD') AND PP.PRP_COLUMN_1 IS NOT NULL ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectinsinstcode'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectinsinstcode', V.PVR_INSTITUTION_CODE, NULL, NULL FROM T_PARTY_VERSION V, T_PARTY PT, T_PARTY_FUNCTION F WHERE PT.PTY_PARTY_ID = V.PVR_PTY_PARTY_ID AND F.PFY_PTY_PARTY_ID = PT.PTY_PARTY_ID AND SYSDATE BETWEEN PVR_EFFECTIVE_START_DATE AND PVR_EFFECTIVE_END_DATE AND PT.PTY_PARTY_STATUS <> 'D' AND V.PVR_INSTITUTION_CODE IS NOT NULL AND F.PFY_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectinstransit'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectinstransit', V.PVR_TRANSIT_NUM, NULL, NULL FROM T_PARTY_VERSION V, T_PARTY PT, T_PARTY_FUNCTION F WHERE PT.PTY_PARTY_ID = V.PVR_PTY_PARTY_ID AND F.PFY_PTY_PARTY_ID = PT.PTY_PARTY_ID AND SYSDATE BETWEEN PVR_EFFECTIVE_START_DATE AND PVR_EFFECTIVE_END_DATE AND PT.PTY_PARTY_STATUS <> 'D' AND V.PVR_TRANSIT_NUM IS NOT NULL AND F.PFY_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectSubInstCode'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectSubInstCode', V.PVR_INSTITUTION_CODE, NULL, NULL FROM T_PARTY_VERSION V, T_PARTY PT, T_PARTY_FUNCTION F WHERE PT.PTY_PARTY_ID = V.PVR_PTY_PARTY_ID AND F.PFY_PTY_PARTY_ID = PT.PTY_PARTY_ID AND SYSDATE BETWEEN PVR_EFFECTIVE_START_DATE AND PVR_EFFECTIVE_END_DATE AND PT.PTY_PARTY_STATUS <> 'D' AND V.PVR_INSTITUTION_CODE IS NOT NULL AND F.PFY_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectSubTransNum'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectSubTransNum', V.PVR_TRANSIT_NUM, NULL, NULL FROM T_PARTY_VERSION V, T_PARTY PT, T_PARTY_FUNCTION F WHERE PT.PTY_PARTY_ID = V.PVR_PTY_PARTY_ID AND F.PFY_PTY_PARTY_ID = PT.PTY_PARTY_ID AND SYSDATE BETWEEN PVR_EFFECTIVE_START_DATE AND PVR_EFFECTIVE_END_DATE AND PT.PTY_PARTY_STATUS <> 'D' AND V.PVR_TRANSIT_NUM IS NOT NULL AND F.PFY_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectFileOwner'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectFileOwner', PVR_FIRST_NAME || ' ' || DECODE(PVR_MIDDLE_NAME, NULL, '', PVR_MIDDLE_NAME || ' ') || PVR_LAST_NAME, NULL, PTY_PARTY_CODE FROM T_ROLE TR, T_USER_ROLE TUR, T_PARTY TP, T_PARTY_VERSION TPV WHERE TP.PTY_PARTY_ID = TPV.PVR_PTY_PARTY_ID AND SYSDATE BETWEEN TPV.PVR_EFFECTIVE_START_DATE AND TPV.PVR_EFFECTIVE_END_DATE AND TP.PTY_PARTY_ID = TUR.ULE_PFY_PTY_PARTY_ID AND (SYSDATE BETWEEN TUR.ULE_START_DATE AND TUR.ULE_END_DATE OR TUR.ULE_END_DATE IS NULL) AND TR.RLE_ROLE_ID = TUR.ULE_RLE_ROLE_ID AND PTY_PARTY_CODE NOT LIKE 'LTEST%' AND TR.RLE_ROLE_NAME IN ('VPOPS', /*'VPRSK2', */ 'OPSLEADER', 'TEAMLEADER', 'OPSLEVEL5', 'OPSLEVEL4', 'OPSLEVEL3', 'OPSLEVEL2', 'OPSLEVEL1', 'OPSTRNG') AND PTY_PARTY_CODE IS NOT NULL ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectbrokername'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectbrokername', PP.PPA_NAME_BROKER_TEXT, NULL, NULL FROM T_POLICY, T_POLICY_PARTY PP WHERE POL_POLICY_ID = PPA_POL_POLICY_ID AND PPA_EFFECTIVE_END_DATE = TO_DATE('9999-01-01', 'RRRR-MM-DD') AND PPA_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' AND TRIM(PP.PPA_NAME_BROKER_TEXT) IS NOT NULL ORDER BY 2; DELETE FROM T_TEAM_LIST_VAL WHERE LIST_DOMAIN = 'selectorg'; INSERT INTO T_TEAM_LIST_VAL (LIST_DOMAIN, LIST_VALUE_1, LIST_VALUE_2, LIST_VALUE_3) SELECT DISTINCT 'selectorg', PT.PTY_PARTY_CODE, NULL, NULL FROM T_PARTY_VERSION V, T_PARTY PT, T_PARTY_FUNCTION F WHERE PT.PTY_PARTY_ID = V.PVR_PTY_PARTY_ID AND F.PFY_PTY_PARTY_ID = PT.PTY_PARTY_ID AND SYSDATE BETWEEN PVR_EFFECTIVE_START_DATE AND PVR_EFFECTIVE_END_DATE AND PT.PTY_PARTY_STATUS <> 'D' AND PT.PTY_PARTY_CODE IS NOT NULL AND F.PFY_SHR_STAKE_HOLDER_FN_CODE = 'LENDER' ORDER BY 2; COMMIT;
Question 2 is at a high level, what method would be better. We have much that truncation, however, the developer only deletes the data of 40%.huh? wrote:
Our developer past this code along with us as we receive some performance and behavior in our DB 9.2.0.7. Using this process, our 4 MB index rises to more than 1.5 GB and we are forced to re - org to bring him down.Your table definition shows the column indexed to TANK (200) - which means the length fixed; up to 4MB is equivalent to 20,000 lines. If it grows to 1.5 GB and rebuilt to 4 MB at one point your index finger running then to about 80 KB per index entry. If, as you describe, you only remove about 40 percent of the data and re - insert a similar amount that once the you must have hit a bug.
You're on 9.2.0.7 (buggy) - were you using SAMS (also buggy). I came across a bug with the SAMS once that gave rise to a process using only 3 blocks from each measure in the index that it is returned in a pl/sql loop to change a few hundred lines. Different circumstances of yours and an earlier version - but you can beat something similar.
A few thoughts:
If it's in the SAMS move the indexes of a tablespace managed by freelist to see what is happening
If you need index could make you it unusable for the load
If you have the index at all?
This table would be partitioned list on listdomain - you can then use Exchange partition to load the data like this
Commit between delete and insert allows generally in such cases.
Between each pair of delete/insert (in the absence of bugs) should helpConcerning
Jonathan Lewis.








Maybe you are looking for
-
I reinstalled firefox on my desktop the previous one used to show my google home page when I opened a new tab in my homepage .but it doesnot open my google home page now, it's empty with a few rectangular blocks
-
Satellite Pro A100-001 - maximum capacity of a hard drive supported?
I tried looking for the Board of Directors and the Toshiba site, but have not yet found the answer. Please bear with me if the question has been answered elsewhere. I bought an old A100 on eBay - it seems to work fine, but it has a 40 GB hard drive (
-
error code 0 x 643, service pack 1 keeps failing, in my windows XP. Please help, thank you Karen
update of the Framework 1.1 service pack 1 security guard failed. error code 0 x 643. I installed the AVG Anit-Virus program. I keep trying to update, but it keeps failing. Help please, thank you, KarenPenn
-
I have the HP ENVY 17 BTO (build to order) Core i7 4700mq, 16 GB of ram ddr3. But currently no graphics (intel just hd 4600), but is too slow for a few games and want to know if can insert a new graphics mxm as nvidia 750 m. (Sorry bad English)
-
(I could not ' copy / paste ' the 'title', so it contains the question!)