Functions Autonomating
I'm trying to set up a 'writing' (inside a case structure) function when a boolean is set to true for writing certain values, however, I can't work properly. The first problem I get is that labview automatically inserts the nodes of comments. Another problem I am getting is the previous written function series instead of the most recent data points (this happens with and without comment nodes). I left the structure of the continuous wire case in attachment. Any ideas? (The background of this program is for the automation of a Lakeshore 331 Temp controller. I'm under various structures case out of a single Boolean flag called "Temp." stabilized When this indicator lights as true, loop, crosses a csv file that provides the data for this "write" function that I have a problem with. I want this car writing to write the data on temperature controller when the most recent data from the csv file). I joined the program and the csv file that I use.
Thank you
Matt
Find nodes in comments is because one branch out of something in the entrance of the same logic. It's like using x to solve for y, but x is determined by what is there. You should know Y BEFORE you can solve for X so labview trying to solve this problem by adding your comments nodes.
Specifically, you have an indexed number power of the upper part to the loop used to set the target time on the time elapsed VI, and using elapsed time? A Boolean to determine the number of iterations to perform the loop before.
Here is the simplest example of what you are doing.
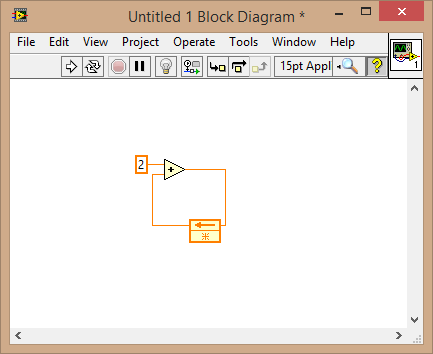
You should look for shift registers and how they work. All the data you want to save to the iteration of the loop iteration to put on a change of logic register.
Tags: NI Software
Similar Questions
-
Pipeline raised ORA-06519 function: active autonomous transaction detected
Hi all
My name is John and I have a problem I need to share with you the guru and the experts. I created the following function of pipeline under user Oracle ABC:
CREATE or replace FUNCTION SomeFunction(p_from_date DATE, p_to_date DATE) T_TAB_A RETURN pipelined
IS
PRAGMA autonomous_transaction;
BEGIN
DELETE FROM temp_rcm;
INSERT INTO temp_rcm
SELECT * FROM int.facility fd.
int. Capacity co
WHERE co.resource_name = fd.resource_name
AND co.trade_date = fd.trade_date
AND co.trade_date BETWEEN p_from_date AND p_to_date;
COMMIT;
FOR rec IN (SELECT co.*
OF temp_rcm co
o left join int.outage
WE (o.flag = 'Y')
AND o.reason_flag = 'F'
AND o.INTERVAL = co. INTERVAL OF
AND co.resource_name = o.resource_name)
ORDER OF co. MEANTIME,
Co.Name) LOOP
pipe ROW (T_A (CRE. INTERVAL, rec.trade_date,
Rec.resource_name, Rec.day_of_week_long, rec.working_day, rec.peak));
END LOOP;
RETURN;
END SomeFunction;
I could compile and create the function SomeFunction successfully, but when I executed the following command:
Select * from table (SomeFunction (to_date ('01 / 01/2010 ', to_date('01/01/2010')));)
I went with the Oracle error: ORA-06519: active autonomous transaction detected and restored
I searched on the web, such Oracle error occurs when the function has a missing "COMMIT" or "ROLLBACK" command inside an autonomous_transaction. But the fact is that I have already included the "COMMIT"; in the function. I suspected that the error was caused by the paintings that I did against (such as int.facility and int.capacity) were all the views which belonged to another schema called int. Or is it something that miss me in the service? Thank you for your time and your help.
Kind regards
JohnThis isn't how a ref cursor is used in general. See this thread: {: identifier of the thread = 886365}
I can't really answer your question without knowing what kind of client you are using (Java, c#, etc.).
However, the thread should shed a lot of light on the ref Cursor.
-
That Cisco APs autonomous work as bridges?
I was wondering Cisco autonomous APs that can function as bridges wireless (station role root and non-root)? Particularly interested in the APs 1602E and 2602E. The documentation that I have watched so far is not expressly that it is / is not supported.
Yes, these model you can set up as a Non-Root/Root as long as you have a stand-alone image loaded. The time function is based on the code of the software.
Release notes available at below URL for details of the features of each version of the software in charge/no supported.
http://www.Cisco.com/en/us/products/ps12555/prod_release_notes_list.html
Here is a basic example of configuration of Root/Non-Root using different model AP, but it can help you get the config of base for these AP model, as well.
http://mrncciew.com/2013/11/09/wireless-bridge-with-EAP-fast/
HTH
Rasika
Pls note all useful responses *.
-
Invalidation of the index based on a function because the recompilation
Hello
one of our customers has two indices according to the functions that fall under the State "off" in some situations. After looking more closely at the situation, there are some things that my opinion are different from what I expected of a function-based index. Because I am unable to find anything about either on metalink (or I'm not asking the right question) I would appreciate a second opinion of you.
To keep things simple, I gave an example to illustrate the behavior. I use Oracle 12.1.0.2, although it can also be reproduced on versions 10.2 and 11.2.
It's my environment and three parameters that I find relevant to the discussion:
SQL> select banner from v$version; BANNER ---------------------------------------------------------------------------- Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production PL/SQL Release 12.1.0.2.0 - Production CORE 12.1.0.2.0 Production TNS for Linux: Version 12.1.0.2.0 - Production NLSRTL Version 12.1.0.2.0 - Production SQL> show parameter remote_dependencies NAME TYPE VALUE ------------------------------------ ----------- ---------- remote_dependencies_mode string TIMESTAMP SQL> show parameter query_rewrite NAME TYPE VALUE ------------------------------------ ----------- ------------- query_rewrite_enabled string TRUE query_rewrite_integrity string enforced
Test case:
SQL> CREATE OR REPLACE FUNCTION f1 (p_string IN VARCHAR2) 2 RETURN VARCHAR2 3 DETERMINISTIC 4 IS 5 BEGIN 6 RETURN lower(p_string); 7 END f1; 8 / Function created. SQL> CREATE TABLE tmp_t1 (a_string VARCHAR2(10)); Table created. SQL> INSERT INTO tmp_t1 VALUES ('a'); 1 row created. SQL> COMMIT; Commit complete. SQL> CREATE INDEX x1_tmp_t1 ON tmp_t1(f1(a_string)); Index created. SQL> set linesize 80; SQL> column index_name format a10; SQL> SELECT index_name, index_type, status, funcidx_status 2 FROM user_indexes; INDEX_NAME INDEX_TYPE STATUS FUNCIDX_ ---------- --------------------------- -------- -------- X1_TMP_T1 FUNCTION-BASED NORMAL VALID ENABLEDWe have our table and our based on an index function which basically converts the values to lowercase. From here on things, download a little weird. What happens with the index based on a function if the underlying function is recompiled? I always thought (and which is also stated in the Concepts and the use of function index (Doc ID 66277.1)) that the index would change its status to "disabled". Here is an excerpt of the said Doc ID:
The index depends on the State of the PL/SQL function. The index can be
struck down or rendered useless by changes to the function. The index is marked
People with DISABILITIES, if he is brought to the function or function is re-created.
The timestamp of the function is used to validate the index.
To allow the index after it is created, the function if the signature of the
the function is identical to the front:
ALTER INDEX ENABLE;
If the signature of functions is changed, to make the changes effective
in the index, the index must be renewed to make it valid.
ALTER INDEX REBUILD.
It seems that this is not the case, as the index remains valid and activate.
SQL> alter function f1 compile; Function altered. SQL> SELECT index_name, index_type, status, funcidx_status 2 FROM user_indexes; INDEX_NAME INDEX_TYPE STATUS FUNCIDX_ ---------- --------------------------- -------- -------- X1_TMP_T1 FUNCTION-BASED NORMAL VALID ENABLED
OK, explicitly recompiling function F1 single timestamp changed. What if we replace the function completely and we change the output of the function - for example we will switch from a LOWER function to SUPERIOR function in the body of the F1. Again, it is change that I thought would be not only to disable the index based on a function, but also force its reconstruction. At least that is my understanding of the explanation in Doc ID).
SQL> CREATE OR REPLACE FUNCTION f1 (p_string IN VARCHAR2) 2 RETURN VARCHAR2 3 DETERMINISTIC 4 IS 5 BEGIN 6 RETURN UPPER(p_string); 7 END f1; 8 / Function created. SQL> SELECT index_name, index_type, status, funcidx_status 2 FROM user_indexes; INDEX_NAME INDEX_TYPE STATUS FUNCIDX_ ---------- --------------------------- -------- -------- X1_TMP_T1 FUNCTION-BASED NORMAL VALID ENABLED
Should not be. Because of the function "create or replace" F1 never go through a "invalid" phase which may be necessary for index becomes unusable? What about queries on the TMP_T1 table? Does optimizer always uses access index or not? What about the results?
SQL> EXPLAIN PLAN SET statement_id='s1' FOR 2 SELECT a_string, f1(a_string) as f1_a_string, f1('a') as f1_literal 3 FROM tmp_t1 4 WHERE f1(a_string) = 'a'; Explained. SQL> SELECT * from table(dbms_xplan.display(statement_id=>'s1')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------ Plan hash value: 3133804460 ------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 2024 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TMP_T1 | 1 | 2024 | 2 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | X1_TMP_T1 | 1 | | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------------------------The index is used by the optimizer, see the results.
SQL> column f1_a_string format a15; SQL> column f1_literal format a15; SQL> SELECT a_string, f1(a_string) as f1_a_string, f1('a') as f1_literal 2 FROM tmp_t1 3 WHERE f1(a_string) = 'a'; A_STRING F1_A_STRING F1_LITERAL ---------- --------------- --------------- a a AA_STRING = value in the table
F1_A_STRING = value of f1 (a_string) but the value is not evaluated because it comes from an index, so tiny value (remember, at the time index created the function returned small values)
F1_LITERAL = value of the function f1 newly evaluated, using literal instead of the value in the table.
Predicate f1 (a_string) = 'a' should return no rows because no character uppercase is equivalent to "a". Query with f1 (a_string) = 'A' should return a line, but it doesn't.
SQL> SELECT a_string, f1(a_string) as f1_a_string, f1('a') as f1_literal 2 FROM tmp_t1 3 WHERE f1(a_string) = 'A'; no rows selectedAnyone know if this is an expected behavior? And, is it possible to disable the index based on a function whenever the underlying function signature is changed? The parameter query_rewrite_integrity = applied from
DOC-ID 66277.1 does not seem to do the trick:
(c) session variables
~~~~~~~~~~~~~~~~~~~~
QUERY_REWRITE_ENABLED (true, false),
QUERY_REWRITE_INTEGRITY (confidence, forced, stale_tolerated)
determines the optimizer to use index based on a function with
expressions using SQL, user defined functions functions.
TRUST: Oracle allows rewrites using relationships that have
was declared.
APPLIED: Oracle ensures and guarantees consistency and integrity.
STALE_TOLERATED: Oracle allows rewrites using vessels of the relationship not applied.
Used in the case of materialized views.
Set session variable cost function optimizer to choose the
a function-based index
Kind regards
SAMO
From the Manual 11.2 ( https://docs.oracle.com/cd/E11882_01/appdev.112/e41502/adfns_indexes.htm#ADFNS254 )
"If you change the semantics of a
DETERMINISTICrun and recompile, then you must manually rebuild all addicts depending on index and materialized views." Otherwise, they report results for the previous version of the function. »This note is not that I made my initial comment well - which was based on an incorrect memory the relationship between function-oriented and autonomous pl/sql functions, so I won't try to explain it. In fact, I went back to Oracle 8i practice to see if something had changed between yesterday and today and found that I had described exactly the behavior that the OP has been seeing. It's the way it is supposed to be.
Concerning
Jonathan Lewis
-
Implementation of the functions of table (indexOf, lastIndexOf, removeDuplicates...)
Hello
I'm trying to implement some functions to manipulate tables more easily, as I would with other programming languages (Array.IndexOf exists in Javascript, but seems to be absent from ExtendScript).
First of all, I tried to add these functions using Array.prototype; Here's what I've done for two of these functions:
Array.prototype.indexOf = function (value) { for (var i = 0;i<this.length;i++) { if (this[i] == value) return i; } return -1; } Array.prototype.removeDuplicates = function () { var removed = []; for (var i = 0;i<this.length-1;i++) { for (var j=i+1;j<this.length;j++) { if (this[i] == this[j]) { removed.push(this.splice(j,)1); } } } return removed; }It seemed to work fine, but I discovered that it breaks this kind of loop:
for (var i in array) { alert(array[i]); }The loop through the values in the table and continues beyond array.length with the features added to the prototype.
As explained here, I have found a workaround, using Object.defineProperty () rather than implement functions in Array.proptotype
Object.defineProperty(Array.prototype, "indexOf", { enumerable: false, value: function(value) { for (var i = 0;i<this.length;i++) { if (this[i] == value) return i; } return -1; } });But... Object.defineProperty () is missing in ExtendScript too!
I don't know what to try next... Any idea?
Thank you!
The primary reason that some of these functions do not exist, is that ExtendScript is based on the ECMA-262 standard. Very old JavaScript and I don't think all this is implemented.
PG. 3 of the CS6 script guide (only written comprehensive guide Adobe has for the moment) after effects Developer Center | Adobe Developer Connection:
The ExtendScript language
"After Effects scripts using the Adobe ExtendScript language, which is an extended form of JavaScript used by several applications Adobe, including Photoshop, Illustrator, and InDesign. ExtendScript implements the JavaScript language according to the ECMA-262 specification. The After Effects script engine supports the 3rd edition of the ECMA-262 standard, including its conventions of notation and lexical, types, objects, expressions, and statements. ExtendScript also implements the E4X ECMA-357 specification, which defines the access to the data in XML format. »
Even though I know that many developers have made prototyping, I found it to be annoying personally, especially if your code moves outside your machine. I just made autonomous functions for all my scripts. It has been easier to reuse code and create some (not all) missing features that would be nice to have the day current Javascript.
-
Hello
I read conflicting information about the return type that has a table function must or may use.
First, I am a student of a book that says:
Function in pipeline returns the data types:
The main constraint for the pipeline functions, it is the return type must be a collection type autonomous which can be used in SQL - i.e. a VARRAY or table nested.
and then in the next sentence...
More precisely a pipeline function can return the following:
A stand-alone nested table or VARRAY, defined at the schema level.
A nested table or VARRAY that has been declared in a package type.
This seems to go against the first quoted sentence.
Now, before reading the above text I had done just my own test to see if a packed type would work because I thought I had read somewhere that it would not, and he does not (the test code and this output is at the end of this question). When I arrived in the text above, after my test, so I was naturally confused.
So, I'm going to PL/SQL reference that says:
RETURN data type
The data type of the value returned by a function table in pipeline must be a type collection defined either at the level of schema or within a package (therefore, it cannot be a type of associative array).
I tried to call a function that returns a collection of VARRAY type packaged in both SQL and PL/SQL (of course below is SQL all in any case) and no work.
Now I'm wondering what is a TABLE function must use a schema type and a function table in pipeline can use a packaged type? I see that I created and called a function table but examples of Oracle see the creation and use of a function table in pipeline.
Edit: I should add that I read the following sentence in the SF book on p609 in * table functions: "this type of nested table must be defined as an element of level diagram, because the SQL engine must be able to resolve a reference to a collection of this kind."
So that it begins to resemble table functions should return a schema type and pipelined table functions, perhaps because that they don't in fact return a collection, rather they return (RowSource) content, can use the schema types or types of packages. Is this correct?
Can someone clarify this for me please?
Thank you in advance,
J
CREATE OR REPLACE PACKAGE PKGP28M
VAT-type is varray (5) number;
END;
/
DISPLAY ERRORS
create or replace type VAT is varray (5) number;
/
display errors
create or replace function tabfunc1 return pkgp28m.vat as
numtab pkgp28m.vat:=pkgp28m.vat();
Start
numtab.extend (5);
because loop me in 1.5
numtab (i): = trunc (dbms_random. Value (1.5));
end loop;
Return numtab;
end;
/
display errors
create or replace function tabfunc2 as return VAT
numtab vat:=vat().
Start
numtab.extend (5);
because loop me in 1.5
numtab (i): = trunc (dbms_random. Value (1.5));
end loop;
Return numtab;
end;
/
display errors
exec dbms_output.put_line (' call tabfunc1 (returns the packaged type) :');)
Select * from table (tabfunc1)
/
exec dbms_output.put_line (' call tabfunc2 (returns the type of schema) :');)
Select * from table (tabfunc2)
/
declare
RC sys_refcursor;
number of v;
Start
dbms_output.put_line (' in anonymous block1 - open rc to select in the table (tabfunc1) (returns the packaged type) :');)
Open rc to select table column_value (tabfunc1);
loop
extract the rc in v;
When the output rc % notfound;
dbms_output.put_line (' > ' | to_char (v));
end loop;
close the rc;
end;
/
declare
RC sys_refcursor;
number of v;
Start
dbms_output.put_line (' in anonymous block2 - open rc to select in the table (tabfunc2) (returns the type of schema) :');)
Open rc to select table column_value (tabfunc2);
loop
extract the rc in v;
When the output rc % notfound;
dbms_output.put_line (' > ' | to_char (v));
end loop;
close the rc;
end;
/
Scott@ORCL > @C:\Users\J\Documents\SQL\test29.sql
Package created.
No errors.
Type of creation.
No errors.
The function is created.
No errors.
The function is created.
No errors.
the call of tabfunc1 (returns the packaged type):
PL/SQL procedure successfully completed.
Select * from table (tabfunc1)
*
ERROR on line 1:
ORA-00902: invalid data type
the call of tabfunc2 (returns the type of schema):
PL/SQL procedure successfully completed.
COLUMN_VALUE
------------
1
4
1
1
3
In anonymous block1 - open rc to select in the table (tabfunc1) (returns the packaged type):
declare
*
ERROR on line 1:
ORA-00902: invalid data type
ORA-06512: at line 6
In anonymous block2 - open rc to select in the table (tabfunc2) (returns the type of schema):
> 1
> 2
> 4
> 2
> 3
PL/SQL procedure successfully completed.
Post edited by: Jason_942375
But the compilation of the PIPELINED WILL CREATE the schematic function types automatically. And the TABLE function, applied to the PIPELINED function, use these types of hidden patterns.
-
nested to perform DML and wait function call commit
Hello world
I would like to make a few DML - one insert statement, to be precise - in function and have the function and then return the number keys on the newly added row. I call this function from a different context and woud then be able to use the newly added data to do something.
Specifically, what I do is the following: I have a graph composed of triplets source, destination and distance in a picture. A user should now be able to
1.) add a node "A" to the curve.
2.) add a node 'B' to the chart
(3.) to get the shortest path from A to B in the graphs.
I have an internal function
adding new nodes to the chart, links, calculates distances etc. and returns a handle to the newly added node. I call this function twice function, externalfunction INSERT_NEW_NODE(node_in in sdo_geometry, graph_in in integer) return integer is pragma autonomous_transaction; cursor node_cur is select source, source_geom from graph ; cursor edge_cur is select source, destination, distance, edge_geom from graph where sdo_geom.relate(edge_geom, 'anyinteract', node_in, .005) = 'TRUE'; begin -- check if identical with any existing node for node_rec in node_cur loop if sdo_geom.relate(node_rec.source_geom, 'EQUAL', node_in, .005) = 'EQUAL' then return node_rec.source; end if; end loop; -- get edges for edge_rec in edge_cur loop -- new_node-->edge.destination and vice versa insert into graph ( ID, GRAPH, SOURCE, DESTINATION, DISTANCE, SOURCE_GEOM, DESTINATION_GEOM, EDGE_GEOM ) values ( graph_id_seq.nextval, --id graph_in, --graph morton(node_in.sdo_point.x, node_in.sdo_point.y), -- source morton key edge_rec.source, -- destination morton key sdo_geom.sdo_distance(edge_rec.source_geom_marl2000, node_in, .005, 'unit=M'), -- distance node_in, -- source geom edge_rec.source_geom, -- dest geom split_line(edge_rec.edge_geom_marl2000, node_in).segment1 -- edge geom ); commit; --new_node-->edge.source and vice versa insert into gl_graph ( ID, GRAPH, SOURCE, DESTINATION, DISTANCE, SOURCE_GEOM, DESTINATION_GEOM, EDGE_GEOM ) values ( graph_id_seq.nextval, --id graph_in, --graph edge_rec.source, -- source morton key morton(node_in.sdo_point.x, node_in.sdo_point.y), -- destination morton key sdo_geom.sdo_distance(edge_rec.source_geom, node_in, .005, 'unit=M'), -- distance edge_rec.source_geom, -- source geom node_in, -- dest geom split_line(edge_rec.edge_geom, node_in).segment2 -- edge geom ); commit; end loop ; return(morton(node_in.sdo_point.x, node_in.sdo_point.y)); end insert_new_node;
; and I think thatI have to use autonomous transaction in the internal function, so that the external function can see any changes made by the inside one. However, it doesn't work, when I call twice the function internal (i.e. remove the comment panels in front of the last two lines of code just before the return statement in the outer function.)function get_path (line_in in sdo_geometry, graph_in in integer) return sdo_geometry is source number; destination number; source_geom mdsys.sdo_geometry; destination_geom mdsys.sdo_geometry; begin source := insert_new_node(get_firstvertex(line_in), graph_in); destination := insert_new_node(get_lastvertex(line_in), graph_in); -- source := insert_new_node(get_firstvertex(line_in), graph_in); -- destination := insert_new_node(get_lastvertex(line_in), graph_in); return(get_path_geom(source, destination)); --returns a geometry which is the shortest path between source and destination end get_path;
So here are my questions: 1) why should I call the function twice to see the complete transaction? (and 2.) How can I avoid this? Is it possible to wait for the execution of the return statement in the internal function that the insert is committed and can be seen by the external function?
See you soon!OK, here's the solution: the external function
get_path()calls a functionget_path_geom(source, destination), who himself called something liketable(dijkstra(source, destination)), (omitted by me because only carefully tested and ok, my bad!) which makes the job of finding the shortest path and returns an array in pipeline. It turns out that this feature for some reason is not the scope of the external function and therefore does not see the transaction committed themselves on the graphics table. After you change thedijkstra()-function to return a list instead of a table, all works all of a sudden.If this question has been answered; I would still like to know why the table function does not have the same scope as the rest of the transaction.
Edit: removed misleading blame on application external and inserted a correct solution.
-
MO_GLOBAL. SET_ORG_ACCESS be pragma autonomous trxn
Hello
I was going through the body of MO_GLOBAL package. I could understand how SET_POLICY_CONTEXT, INIT, works etc and how they put the g_access_mode, g_current_org_id etc. But my question is on MO_GLOBAL. SET_ORG_ACCESS which is used to set the access mode to M.
Seems MO_GLOBAL. SET_ORG_ACCESS is pragma autonomous Transaction. So how is he submissive for MO_GLOBAL. SET_ORG_ACCESS to set the access mode etc. of the session it is called from? However other procedures of the viz SET_POLICY_CONTEXT, INIT etc package are not Pragma autonomous Trxn.
My question is... Suppose that I am connected to an Oracle session and from there I run MO_GLOBAL. SET_ORG_ACCESS (null, 2062, 'AR'). MO_GLOBAL. SET_ORG_ACCESS transaction autonomous pragma how it can set session variables for the session where I am connected?
Please through little light to make my best understand.
SB:-when a call of function/procedure/session a procedure autonomous trxn, will be two calls and called sharing the same session blocks? I thought that they both have different sessions.
Thank youClause autonomous transaction will launch an independent transaction, no new session as a test case below.
DECLARE
PROCEDURE A.
AS
pragma autonomous_transaction;
BEGIN
dbms_output.put_line (' autonomous transaction within my session id ' | sys_context ('USERENV', 'SID'));
ROLLBACK;
END;
BEGIN
dbms_output.put_line ('My session id' | sys_context ('USERENV', 'SID'));
one;
dbms_output.put_line (' autonomous external transaction my session id ' | sys_context ('USERENV', 'SID'));
END;OUTPUT:
My 531 session id
Inside of an autonomous transaction my id of session 531
Outside an autonomous transaction my id of session 531 -
Hello friends,
When I tell about why we can't use DOF / (dml with commit), inside a function then the following came to my mind.
(1) given that often functions are like a black box for the applicant, so if we use a function call in the middle of its transaction, then the DDl / (DML with commit) can be be very bad since the functions can be called from within sql statements, which can make a part of the transaction without knowing of the Summoner. so the alternative is doing an autonomous transaction and I fully agree to this.
(2) but why is it not valid check for a procedure. What I mean is that a procedure can be called from some other plsql block. So why slope above points is valid for both procedures. I know it's not like that, but why?
Thanks in advance and I really appreciate everyone for their response :)Rahul K wrote:
1 select statements) are only for the selection, I agree, but select can often be part of a transaction (if used in a sub query).??
and if I'm wrong, then why we can't use a validation/ddl inside a function? Oracle must have thought something before this rule.
As I have already said, you can use COMMIT inside a function...
And why no DDL?
>
The fundamental reason is that PL/SQL code is compiled and static.The language allows to give instructions to Oracle. It is converted to machine or instructions of the p-code (binary) code.
As part of this process of compilation of references. Oracle does not refer to internal to an object by name. That will be too slow. He refers to it by its unique number. So, if you are referring to the FOO object, the compiler will solve FOO and determine who/where/what FOO is.
Let's say that you code the following PL/SQL:
Start
CREATE TABLE emp (empid NUMBER, name of VARCHAR2 (20));
INSERT INTO emp (id, name) VALUES (1, 'Smith');
end;
Hmm... How the compiler can process this? He needs to create a reference to the EMP object for the CREATE TABLE statement, but there is no EMP.
All right, let's assume that the compiler needs to play dirty and do in CREATE TABLE. Now, he runs into a problem. I made a mistake with the names of columns in the INSERT. There is no such thing as the EMP table. So how did the compiler assumes to create the p-code/machine code for this?
The only way that it can treat that is dynamically. Which is exactly what is the EXECUTE IMMEDIATE statement.
>In addition, read it atAsktom
-
any questions if write us commands DML, DDL, and TCL stored functions.
Hello
Is there any problem if write us DML, DDL, and TCL commands in function stored with the help of the AUTONOMOUS_TRANSACTION PRAGMA.Hello
Yes of course. With DML statements inside the function by using the AUTONOMOUS_TRANSACTION PRAGMA is not very
recommended. It is recommended to use an AUTONOMOUS TRANSACTION for the purpose of logging error only, and
When used in a disorganized manner, it may lead to locks and we will have a problem when you look at the
Trace files.Thank you
Shankar -
From old and new details of triggering of a procedure or a generic function
Hi all.
I have an obligation to transmit all the old and new of a database trigger column information (for the purposes of this discussion, it will be a front line, insert, update and delete trigger) a procedure/function (either is fine).
My first thought was to create a separate routine for each table, I want to implement this, which has a new and old input parameter for each column, but I realized that I needed a solution where the called routine should be generic (because we'll let other developers call the same routine and we do not want that they have to create their own version of the table).
This is a problem because I want to implement this on all the tables could have a completely different columns (and dataypes). The called routine will operate under a pragma autnonmous_transaction (as will happen is committed) so I need to move all of the fields in all at once.
Another idea I had was to create an object of type (potentially) 300 generic fields that I assign the values to the and pass as a parameter, however I never know before hand what types of data are needed, CLOB, DATE, VARCHAR, etc...
I can anyone has any ideas on how achieve this with a generic routine?
Kind regards
Greg.Greg Block wrote:
The called routine will do a lot of work, writing more than to connect the tables.Then I would be seriously concerned by using autonomous transactions. Are you sure you understand all the consequences of this? What happens if the appellant transaction is cancelled, for example, while your work is committed. Are you sure that will never make the system is in an inconsistent state. Are you sure that your routine will never be on the work engaged by the appellant transaction which will be more visible to the autonomous transaction? Are you sure you're never going to generate blockages with the parent transaction?
Justin
-
Can ' transaction autonomous pragma ' called from exception block?
CREATE OR REPLACE TRIGGER TRIG_EMP
AFTER UPDATE
ON EMP
FOR EACH LINE
DECLARE
NUMBER OF THE CNT: = 0;
BEGIN
UPDATE EMP_bkp
SET COMM = 999
WHERE ENAME = 'SMITH ';.
COMMIT; -It will generate the error that commit the cnt b use inside the trigger then wil code exception sommunications
exception
while others then
declare
PRAGMA AUTONOMOUS_TRANSACTION;
Start
commit;
end;
END;
Why code gives error? cant I put PRAGMA AUTONOMOUS_TRANSACTION block of exception, even if I have the rolls in declare... begin... end of block.
Could be considered to bear, but I m in delema why we cnt pragma 'use', in the exception block when an error themselves in code.as can call any proc, func via exception block then why don't we call pragma?A pragma shall apply to a set routine:
-The anonymous PL/SQL blocks higher level (not nested)
-Local, autonomous and packaged functions and procedures
-A SQL object type methods
-Database triggersBut, even if you set a pragma autonomous_transaction in the exceptions, these commit will not commit the changes maded in the body of the trigger (because the idea of a stand-alone transaction, is independent).
Perhaps (I'm not sure) you can try to trick Oracle write a function that do the validation.
In any case, what you trying to do? There may be another way to achieve your goals
I hope this helps.
Kind regards
Alfonso Vicente
http / / www.logos.com.uy/el_blog_de_alfonso -
Overloading in PL/SQL functions
Hi Guyz,
I have 2 questions about overloading of functions.
(1) is it necessary for the functions within a package to run the overloading of functions?
(2) I have 2 functions: -.
(a) function check_hello (P_INPUT1 VARCHAR2, NUMBER P_INPUT2) RETURN BOOLEAN
(b) function check_hello (P_INPUT1 VARCHAR2, NUMBER P_INPUT2) RETURN VARCHAR2
The difference is the return type. I don't think this is possible since the signing of the arguments are the same. I just need to confirm that this is not possible.
Thank you.Hello
user3913664 wrote:
Hi Guyz,I have 2 questions about overloading of functions.
(1) is it necessary for the functions within a package to run the overloading of functions?
Yes; the autonomous functions cannot be overloaded.
(2) I have 2 functions: -.
(a) function check_hello (P_INPUT1 VARCHAR2, NUMBER P_INPUT2) RETURN BOOLEAN
(b) function check_hello (P_INPUT1 VARCHAR2, NUMBER P_INPUT2) RETURN VARCHAR2
The difference is the return type. I don't think this is possible since the signing of the arguments are the same. I just need to confirm that this is not possible.
Exactly. How could you, the system or anyone else to choose one to use?
Give them different names, or add another argument if you really want that they have the same name. -
in combination with the function sequence
Hello
I have a problem with a sequence in combination with a function.
I want to generate a kind of a hardware inventory report that contains some kind of a hardware ID (a number not repetitive, auto-increment, allowed deviations). However, I have to keep track of what material ID I used to which material of the inventory, for reasons of traceability. Another important requirement is that whenever the report is run, that the returned hardware IDs are never repeated. If repeatedly runs for the same hardware in the inventory must always return new material ID.
So I was about to create a simple function from PL/SQL where I spend my data of traceability as parameters. Then the function uses internally a sequence (nextval) to generate a new hardware ID, then stores the new ID of material by related values in the input in a table (autonomous transaction) parameters and returns the new ID.
It works pretty well so far.
Now the tricky part: I want where I want to go back the same ID in different columns of a SQL statement.
Let me give you an example:
It is a simplified version of the function for demo.CREATE SEQUENCE XXX_TEST_SEQ MINVALUE 1 MAXVALUE 999999999999999999999999999 INCREMENT BY 1 START WITH 1 NOCACHE NOORDER NOCYCLE; CREATE PACKAGE XXX_TEST_PKG AUTHID CURRENT_USER AS FUNCTION get_id(p_someparameter NUMBER) RETURN NUMBER; END XXX_TEST_PKG; CREATE PACKAGE BODY XXX_TEST_PKG AS FUNCTION get_id(p_someparameter NUMBER) RETURN NUMBER IS l_new_id NUMBER; BEGIN SELECT XXX_TEST_SEQ.NEXTVAL INTO l_new_id FROM DUAL; /* do some more logic, e.g. store the freshly generated ID together with the input parameter values in some tracing table */ RETURN l_new_id; END get_id; END XXX_TEST_PKG;
We will use:
Query 3 is one who gives me headaches. I need to return the same ID in different columns. But it returns only two different pieces of identification. I know that the optimizer will merge the two select statements into one and therefore perform the function twice. Someone knows how can I avoid this?-- 1) this works as expected: select xxx_test_pkg.get_id(1) from dual; XXX_TEST_PKG.GET_ID(1) ------------------------ 1 -- 2) this returns two different numbers: select xxx_test_pkg.get_id(1) as id_one , xxx_test_pkg.get_id(1) as id_two from dual; ID_ONE ID_TWO ---------------------- ---------------------- 2 3 -- 3) This is the problematic case: I want to return the same ID two times: select my_id as id , my_id as same_id from (select xxx_test_pkg.get_id(1) as my_id from dual); ID SAME_ID ---------------------- ---------------------- 4 5 -- 4) CURVAL on these sequence does not work: select my_id as id , xxx_test_seq.curval as same_id from (select xxx_test_pkg.get_id(1) as my_id from dual); SQL Error: ORA-00904: "XXX_TEST_SEQ"."CURVAL": invalid identifier -- 5) This gives the output that I need, but why? select my_id as id , xxx_test_seq.nextval as same_id from (select xxx_test_pkg.get_id(1) as my_id from dual); ID SAME_ID ---------------------- ---------------------- 7 7
Which is a little strange to me, it's the query 5 is really what I need, but at first glance I would say that he should not do. I would say that using nextval would be me again another number sequence.
It's confusing... Can someone explain this and advise how can I build a query if I can get the same ID twice by line?
I know that I can totally get rid of the sequence in my function and use something different, but I was wondering if I can avoid to change my function.
Thank you
David.Oracle's FUSION query inline with the outer query block, which causes the function being called twice.
Instead of MATERIALIZING suspicion, or relying on ROWNUM = 1 effect predicate aside, I would explicitly tell the optimizer to not do so via the NO_MERGE indicator.
select my_id as id , my_id as same_id from (select /*+ NO_MERGE */ xxx_test_pkg.get_id(1) as my_id from dual); -
with 'PRAGMA AUTONOMOUS_TRANSACTION' function calls another function
I have the 'B' function that is marked as "PRAGMA AUTONOMOUS_TRANSACTION".
Inside the function definition of 'B', I call a function usual non-autonoumus 'C '.
No autonomous function 'A' called 'B '.
In short:
'A' called 'autonomousB '.
'autonomousB' called 'C '.
It is: function 'C' runs in a standalone transaction now?
I understand that everything that is managed or called within an autonomous framework is also running in the standalone context and so I donat must score more 'C' function as independent, is it true?
Published by: CharlesRoos on April 13, 2010 05:40Looks like you answered your own question.
Have you set up a test case?
SQL> SELECT * FROM V$VERSION; BANNER ---------------------------------------------------------------- Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bi PL/SQL Release 10.2.0.4.0 - Production CORE 10.2.0.4.0 Production TNS for 64-bit Windows: Version 10.2.0.4.0 - Production NLSRTL Version 10.2.0.4.0 - Production SQL> CREATE TABLE MSG_TEST(MSG VARCHAR2(50)) Table created. SQL> CREATE OR REPLACE PROCEDURE C 2 AS 3 BEGIN 4 INSERT INTO MSG_TEST VALUES('This is procedure C'); 5 END; 6 / Procedure created. SQL> CREATE OR REPLACE PROCEDURE B 2 AS 3 PRAGMA AUTONOMOUS_TRANSACTION; 4 BEGIN 5 INSERT INTO MSG_TEST VALUES('This is procedure B'); 6 C; 7 COMMIT; 8 END; 9 / Procedure created. SQL> CREATE OR REPLACE PROCEDURE A 2 AS 3 BEGIN 4 INSERT INTO MSG_TEST VALUES('This is procedure A'); 5 B; 6 END; 7 / Procedure created. SQL> EXEC A; PL/SQL procedure successfully completed. SQL> SELECT * FROM MSG_TEST; MSG -------------------------------------------------- This is procedure A This is procedure B This is procedure C SQL> ROLLBACK; Rollback complete. SQL> SELECT * FROM MSG_TEST; MSG -------------------------------------------------- This is procedure B This is procedure C SQL>
Maybe you are looking for
-
Norton Anti virus in Satellite L40
Hello! I am new user of L40 series and the built in Norton AntiVirus which I could not receive a product key. How can I have the product key for norton anti virus? next week's expiration.
-
Where can I download and how do I install the factory for Lenovo tab A10 image?
-
How to copy a disk in drive d to a trip by car
trying to back up data on dvd for a road trip.
-
video of window Media Player that has been saved on the side how to rotate video
How to rotate a video that was recorded on the side
-
Cursor (cursor) appears in the text box after inserting text or the position of change
I managed to change the position of the cursor in a TextArea as qml and C++ to help through the Publisher associated with the drop-down list. I checked the change to receive cursor, change of position and position again. However, the cursor does not