graph power VMs
Hello
I would draw a graph showing the number of VM voltage for a certain period of time. Is there already a services integrated into vfoglight who keep track the number of power on VM that I can use to create the dashboard?
You will find a guide step by step to create this derived metric to the: http://communities.quest.com/docs/DOC-11710
Kind regards
Brian Wheeldon
Tags: Dell Tech
Similar Questions
-
Hi guys,.
Can someone share their script to get vms separated by cluster using getview turned off?
Something that gets the following information:
vmname, cluster, powerstate esxi host,
Thanks in advance.
To speed up the execution time of the cmdlet Get-View, you can use the property parameter to limit the returned data.
If you do not use the property setting that the complete object is returned.
For additional fields that you have added, you can add those property setting.
Something like that
Get-View -ViewType VirtualMachine ` -Property Name,Runtime.Host,Runtime.PowerState,Config,Summary.Config,AvailableField,CustomValue ` -Filter @{"Runtime.PowerState"="poweredOff"} |Select Name, @{N="PowerState";E={$_.Runtime.PowerState}}, @{N="Host";E={(Get-View $_.Runtime.Host -Property Name).Name}}, @{N="Cluster";E={(Get-View (Get-View $_.Runtime.Host -Property Parent).Parent -Property Name).Name}}, @{N='Guest OS';E={$_.Config.GuestFullName}}, @{N='VM Notes';E={$_.Summary.Config.Annotation}}, @{N="Contact";E={ $key = $_.AvailableField | where {$_.Name -eq "Contact"} | Select -ExpandProperty Key $_.CustomValue | where {$_.Key -eq $key} | Select -ExpandProperty Value}}, @{N="CreatedBy";E={ $key = $_.AvailableField | where {$_.Name -eq "CreatedBy"} | Select -ExpandProperty Key $_.CustomValue | where {$_.Key -eq $key} | Select -ExpandProperty Value}}, @{N="CreatedOn";E={ $key = $_.AvailableField | where {$_.Name -eq "CreatedOn"} | Select -ExpandProperty Key $_.CustomValue | where {$_.Key -eq $key} | Select -ExpandProperty Value}}|Export-Csv -NoTypeInformation -UseCulture -Path C:\test\poweredoffvm2.csv -
I analysis of the data of the PXI-5600 by DAMA. I take the signal and show the power on a graph (power vs. frequency) spectrum.
But I want to find specific points and get their frequency.
How to make a table of indata him?
What color is the terminal on the graphic block diagram?
Brown = Type of waveform data - use 'get waveform components' to get the component 'Y '.
Rose = Cluster - use of the unbundle for information y
or
Rose = Array of clusters (xy pairs) - use a loop for to treat table, in the loop for, use the unbundle for item 2 (value of y)
If no help above, please your postal code.
Charles
-
WS11 V11.1.2 update fails on Win 7 Ultimate x 64
Because the WS11 boot, VMware offers a free update, I tried to update my V11.0.0 WS11 V11.1.2 but the failed to install with error: this product cannot be installed on Windows 7 64-bit or newer operating system.

But my laptop works on Windows 7 Ultimate 64 bit!
Hello HenrytheXth,
Please follow the steps below to get the problem resolved:
Step 1: Close / off Power VMS running on my computer, and then close my computer.
Step 2: Manually download the VMware Workstation 11.1.2 from the link below:
https://my.VMware.com/group/VMware/details?downloadGroup=Wkst-1112-win&ProductID=462&rPId=8216
Step 3: Move the file of configuration of Workstation 11.1.2 downloads for desktop or any other location.
Step 4: Now run the configuration file to install the workstation 11.1.2
Please see the article below for instructions on downloading and installing VMware Workstation:
http://KB.VMware.com/kb/2057907
Kind regards
Shivakv
-
The upgrade from 5.0 to 5.5 2nd update vCenter
I need to update my vSenter v. 5.0 to VMware vCenter Server 5.5 Update 2.
The vCenter is a virtual machine running Windows Server 2008 R2 and SQL Server 10.50.1600.
The virtual machine is not a member of Active Directory.
- What should I consider before performing the update?
- Where can I find detailed documentation on the upgrade process and a list of questions that I have to answer?
- During the update the ESXi hosts will be light as well as the VM guest.
- Should I try to power VMs off as much as I can?
- I need to do anything on the side SQL?
- Should I take a snapshot and/or make a (Veeam) backup the vCenter VM in the case where something goes wrong with the update?
- Given a problem occurs during the update, can I just go back to the snapshot?
- Is there anything else I can do to ensure a successful update?
Concerning
Marius
- What should I consider before performing the update?
- Where can I find detailed documentation on the upgrade process and a list of questions that I have to answer?
- During the update the ESXi hosts will be light as well as the VM guest.
- Yes, vCenter upgrade will not affect ESXi or VM
- Should I try to power VMs off as much as I can?
- Not required
- I need to do anything on the side SQL?
- Make sure that you have a FULL backup. Rest will take care of vCenter 5.5 installation
- Should I take a snapshot and/or make a (Veeam) backup the vCenter VM in the case where something goes wrong with the update?
- It is recommended to have snapshot
- Given a problem occurs during the update, can I just go back to the snapshot?
- Yes, you can
- Is there anything else I can do to ensure a successful update?
- Read the guide to upgrade twice
- Make sure that you write down the name of the ESXi server, which holds your vCenter VM
- Make sure that you have the root password for the name of the ESXi server, which holds your vCenter VM
-
run a VM on vcenter workflow unique sdk connection
Hello world
I'm short vCO 5.5.1 material, connected to 13 vCenters spread around the world. Yes I know, probably not the best idea, but it doesn't seem to work properly. We're not really able to re-architect to take advantage of the cluster to the time mode.
Anyway, with that many connections of vCenter to vCO, even simple VM operations take a long time. This is due mainly to the fact that even the simple workflow that power VMs seem to rely on the questioning of ALL connections of vCO SDK. We provide a virtual machine name (or UUID) as input and vCO then queries all our vCenters until it can return an VC:VirtualMachine object, which is then used as the real input parameter to run VM-associated workflows in question.
Anyone know of a more effective and efficient to have the vCO to retrieve the VC:VirtualMachine object, instead of an iteration on all connections of the SDK?
The place where you start the workflow?
Get VM by name is a bad habit, especially if you have many vCenters / VMs.
vCO has a nice tree inventory to load in the inventory items only in containers (VM files, resource pools) you select.
If you use an external system that does not know how to interface with vCO API to get the tree view that you should get virtual machines by their ID.
You can start a workflow of vCO input the object ID (unique vCO or object of type + object ID + host vcenter) do:
moRef var = new VcManagedObjectReference();
moRef.type = ref.type;
moRef.value = ref.id;
vcObject = VcPlugin.convertToVimManagedObject (vimHost, moRef);
-
VM Variable for the virtual computer object
Hello
I am connected to multiple vcenters where we have a few VM objects that have the same name (no duplicates in the vcenter even).
and I need to run a vm - get when you are connected to the 2 vcenters and store that in a variable $vms
It is always the case for virtual machines with the same name that if a virtual machine is running in a vcenter, it is turned off in the other vcenter. (DR)
for virtual machines in this case, I need my variable to store the computer object virtual that is powered AND ignores the engine off... for other virtual machines, I need to power on and power off power vms to be included.
Here's what I do, but it doesn't work
$vms = (get - vm |) {ForEach-Object
If ($_.name - eq $null) {}
$_ = ($_ | (Where-Object {$_.powerstate-eq "réceptrices"})} else {$_}
})
Hello, max2001-
How about something like the following:
## get all VMs from all connect vCenters, and group them by name$arrAllVMs_grouped = Get-VM | Group-Object Name $arrDesiredVMs = @()## for any group of VMs where there is more than one (2, presumably), only return the PoweredOn VM in the group$arrDesiredVMs = $arrAllVMs_grouped | ?{$_.Count -gt 1} | %{$_.Group | ?{$_.PowerState -eq "PoweredOn"}}## and for the groups of VMs where there is only one VM in the group, add that VM to the DesiredVMs array$arrDesiredVMs += $arrAllVMs_grouped | ?{$_.Count -eq 1} | %{$_.Group}Who will be:
- get all virtual machines and group by name
- groups of virtual machines where there is more than one, just take those who are in the PowerState PoweredOn
- and, grab all the VMS are groups of count 1 (named unique VMs), without regard to their PowerState
What to do for you?
-
Admission control - [Sanity Check] cluster asymmetric w / no reservations of VM
I spent a time reviews the policy reduced control and just looking for a "sanity check" that the conclusions of my environment and my calculations are accurate. Currently manages an asymmetric cluster which includes 1 much more memory than the rest host (host 5). I have read from multiple sources, including 5.1 deepdive of Duncan and Frank policy "tolerate failures of the host in the cluster" to waste resources in the scenario in order to ensure the greatest Web host is protected. However, the calculation below shows that this policy is almost dead on what percentages policy would cover in a scenario N + 1 (again to ensure the greatest Web host is protected).
The distribution is:
Host 1
Host 2
Home 3
Home 4
Host 5
Home 6
Home 7
Totals
Memory (GB)
48
72
64
64
128
64
72
512
% Of the memory
9.38
14.06
12.5
12.5
25
12.5
14.06
CENTRAL PROCESSING UNIT
18.08 GHz
19.12 GHz
19.12 GHz
18.08 GHz
19.12 GHz
19.12 GHz
19.12 GHz
131.76
PROCESSOR: %
13.78
14.5
14.5
13.78
14.5
14.5
14.5
In an N + 1 scenario the percentages recommended would work out at 25% for memory (128 / 512) * 100 and 15% (rounded) for CPU (19.12 / 131,76) * 100 to ensure the greatest web host is protected. I realize that we can reduce waste by reducing these values, but he would go the end of the point of HA if the largest Web host has failed (I realize again it would need to be heavily used approval) and it does not have enough resources to insider HA restarts.
Use current political failures the cluster host tolerates slot sizes are default values (32 MHz CPU and 217 MB (overhead) memory) without reserves of VM. We use the reserves of RP, but they come into play with slot HA size calculation if I understand. We have currently 2210 (1540 available) number of locations within our core, given the hosts/resources provided. 138 locations are used to power VMs and 532 are reserved for failover. For the record, it works to 112,73 GB (532 * 217) / 1024). This is equivalent to 22% of the total memory in the cluster. It works for the processor to 16.63 GHz (32 MHz * 532) / 1000 round is 17% of the total CPU in the cluster.
And if I went to the policy of the percentages with best practices in mind I would reserve more memory and less than what current CPU, but only a few given the above percentages. Are there any underlying problems with this configuration, I'm missing or given configuration is my exact analysis? Or it is recommended to apply the policy of calculated percentages and lower resources reserved for values lower than the largest webhost in the cluster for available resources? It is the 'catch 22' because we obviously want to maximize the resources available to the cluster while guaranteeing adequate resources of failover.
I wrote an article about this as well: http://www.yellow-bricks.com/2012/12/11/death-to-false-myths-admission-control-lowers-consolidation-ratio/
-
Disorders before upgrading a cluster
Imagine a vSphere cluster 5 constituted by the 5.0.0.x ESXI hosts.
Update Manager is configured and download updates every hour.
The servers are never updated.
- What is advised to do before watching the update for the first time, in order to avoid potential problems?
- In order to update ESXi hosts, is it possible to update a single host every time and wait to see if everything is ok?
- In this case, the members of the cluster would go ESXi different versions for a while: can it be a problem?
- How long the update should update itself a generic ESXi host? I know that the answer cannot be provided unless specifying HW configuration, but it will take minutes, hours or days?
- Is there another suggestion to prevent possible unrest?
Concerning
Marius
What is advised to do before watching the update for the first time, in order to avoid potential problems?
First, when you talk about "update hosts", are you referring to the bundles of regular for 5.0 patches/updates or upgrade from 5.0 to 5.1?
I assume you mean the former, but the points apply generally to the latter too.
In order to update ESXi hosts, is it possible to update a single host every time and wait to see if everything is ok?
Yes, you can update only one host at a time and wait for days, or even weeks without having to patch the other hosts, while loading one patched with loads of regular work and checking all the problems (it generally won't be any notable those minor patches).
In this case, the members of the cluster would go ESXi different versions for a while: can it be a problem?
This isn't a problem at all. You can even mix different major versions of ESXi in a single Cluster (HA won't work between 4.x and 5.x however hosts).
How long the update should update itself a generic ESXi host? I know that the answer cannot be provided unless specifying HW configuration, but it will take minutes, hours or days?
Days for updating a generic ESXi host? You are about 5-7 clicks in the vSphere Client/Update Manager GUI, enter maintenance mode, waiting for the virtual machines to migrate out of the host, wait for the patches to install and the system restarted, exit maintenance mode. The whole process takes not much longer than 20 minutes for a host and is automated after clicks.
If you don't have a vMotion (which I guess is not the case, that you referred to clusters), it might be a little more complex because you must stop/power VMs manually for the restart of the host.
Is there another suggestion to prevent possible unrest?
The general practice for major updates and releases of "Update" (where the versions of VMware ESXi and vCenter updates at the same time) is to update vCenter, Manager Update and other components of the management first before moving the ESXi hosts.
Then use vCenter Update Manager to update the hosts
For more information, see:
- What is advised to do before watching the update for the first time, in order to avoid potential problems?
-
Doubts about cloning/migrating off the virtual machines on the network
Hello
I'm going to have some problems of connection while cloning/migration power VMs on different hosts on ESXi5 off. I don't know is this procedure for moving a VM off will use the vMotion network, or just the normal management. I have a lot of is speeds when copying VMs on several different hosts, so I wonder what I could do to make sure that the speeds are overfished? I have all the hosts that are connected on a gbit switch.
Thank you!
Yes, two links are used, even when you vMotion a single virtual machine. Here is an official KB article.
A quick test (only VM vMotion) confirms this, as evidenced by the performance tables;
Source (transmit - these two vmnic is used);

Destination (receiving -serve two vmnic);

See you soon,.
Jon
-
Dear guys,
I have 3 hosts the same size 196GB RAM and 24 CPU
I HA cluster AC 25% percentage
My hosts are very memory used 3 of them have at least 150 GB of RAM used.
Check the values HA I have this:
memory current failover capacity 96%
Current switching capacity 30% cpu
configured with failover capability 25% CPU
configured with failover capability 25% CPU
Well, I have a few concerns about the 96% = > how can this be? configured as it means I have 96-25 = 71% of the resources available to power VMS on... sounds weird, as I all hosts using more than 50% of RAM.
I understood the values?
Any help is appreciated,
Daniele
I wrote a series of articles on admission control:
http://www.yellow-bricks.com/?s=admission%20control%20reservation
In short, admission control takes reservations of memory and the memory overhead per virtual machine into account. It does this because it is what is needed to be available for a virtual machine to the market. Admission control is not a substitute for the management of resources. (http://www.yellow-bricks.com/2011/10/26/managing-resources-with-ha-admission-control/)
-
CPU E5649 and E5440 compatibility
Hi guys,.
I currently have 3 Dell Poweredge 2950 s running esxi 4.1
I want to get 3 new Dell Poweredge r710s and vMotion all my virtual machines on these 3 new servers.
The Dell Poweredge r710s have Intel Xeon E5649 2.53 GHz, 12 MB Cache, 5.86 GT/s QPI, 6 c (317-6155)
and
The Dell Poweredge 2950 s have processor Intel 80574, XDH, E5440 FCLGA6
If I read the matrix to the right http://kb.vmware.com/selfservice/microsites/search.do?language=en_US & cmd = displayKC & externalId = 1991
These processors are not compatible vMotion.
Does this mean I have to do a cold migration?
Hi Chris
Sorry for the late reply (I've upgrade to 4.1.2 campaign on my servers)
So the two different types of processors must be compatible, once they are in CVS mode?
Fix
Also, I have to bring the cluster down to activate CVS right?
I'm afraid so, but you can give a try as follows:
Activate CVS on the old cluster and after that add new guests in the old cluster and vMotion test should work without shutdown of virtual machines.
If does not mean that you turn off the virtual machines. If you'd have to power VMs back down I'd suggest to create new cluster (only R710) activate the CTS above on the new cluster and do cold vMotion of former cluster again (puts you off even when old cluster service)
-
I know that this question has been asked by many. However with a provisioning a LUN size makes a difference. I was thinking more the logic unit number would be the most effective use of thin provisioning. In the past, I always used the 500 GB LUN, but now I think about 2 TB LUN. Any thoughts would be appreciated.
The general rule is 12-15 power VMs per LUN, but depends on the workload and their needs. The use of a provisioning can certainly influence the sizes of the LUNS that you will use. You don't want to create a 800 GB VMFS volume and then put 15 virtual machines on which use 30% of the LUN. You want to put a lot of thought calculated by determining the right size for your particular installation. Also, be sure to set up your storage alarms so that if a volume is running out of space you know about it before he gets there.
-
Question on the design of multiple sites
Hi all
We currently have 2 a SAN Equallgoic in the main office and one branch office are. We have 3 ESX host to each location for a total of 6 ESX host. All virtual machines are stored on Equallogic SAN, and all hosts will bind in a virtual Center Server at Headquarters. Each site has a few virtual machines that are running for this office and replicate these VM to the other office for purposes of recovery after disaster. I have attached a diagram of ruff of how it is configured.
Now for the questions:
(1.) with the VM being spread over two sites all also how Virtual Center will handle high availability through the VPN?
2.) if HA been trigger due to a failure of the host to one of the sites how will decide what server the virtual machine starts, and if she decides to start up on another host in another site, how will he know to use the replication data
Currently, 3) We have no site recovery manager then recovery is a manual process. What would be the best method for manual restore?
(1.) with the VM being spread over two sites all also how Virtual Center will handle high availability through the VPN?
HA will work but only within a given site. i.e. If a virtual machine is to site A and site host A fails, he feed to site A. If you want to go to site B, you should look into MRS.
*2.) If HA off due to a failure of the host to one of the site how
He will decide what server the virtual machine starts, and if she
Decides to start on another host in another site, how will he know to
Use the replication of data*.
It will not try to start on the other side and use the replicated data because the target of replication is probably read only.
**3.) We currently do not have site recovery manager so the recovery is a *.
manual process . What would be the best method for manual restore? *
A complete site failure will look like this:
1. breaking replication
2. your LUNS replicated to your able recovery read/write site
3. present the LUN being replicated to your ESX server hosts
4. configure the host ESX server to the LUNS will rescan and add data warehouses and resig (according to ESX3 or 4)
5 browse the data store or vmware-cmd to save virtual machines on the replicated LUNS
6. do a quick validation test (make sure that the vSwitch/portgroup configuration is acceptable)
7. power VMs on 1 at a time. Since its an IPSEC connection I am doubting you lasted VLAN so you'll have to re - IP as it happens
8. change DNS settings
9 adjust the upstream/downstream dependencies as needed.
SRM will automate everything up to 8 and can usually be scriped manage 9. This is not 100% complete, but should give you an idea.
Edit to add your next questions:
* should the LUNS of
the two sites be shared to all ESX servers? or would it be better to simply
have the local ESX servers to have access to its premises LUN? *
Your local ESX servers should have access to only local storage devices, unless you have a very low latency and a fast connection between sites (say < 10 ms and at least gigabit) as well as having in this respect be a layer 2 connection. In this way your VLANS/subnets/etc are always the same on the other side.
-
the power of the spectrum graph and butterworth filter
Hello
I am beginner in labview, I want to see the power spectrum of the sound samples, I want to see if there is any reason in these samples.
I use spectral measure, and then I filtered with butterworth filter samples. For output I using waveform graphs.
Before filtering the signal, I'm in the x axis of the graph between 0-22500 and the data mostly in 0-2500.
I've tried to filter using these values (fs = 1000 Hz, 0.125 hz = fl and fh = 500 hz) and the graphics almost the same thing but the axis of the graph is between 0-0, 5.
issues related to the:
What is the x axis properties? Why is different, but the graphics are the same?
Make the mistake with the program?
Hi Limavolt,
You have a problem with the bandpass filter VI, this VI generates only the signal of value i.e. table DBL. The signal is a cluster.
solution 1: you need to calculate 'dt' using the sampling frequency and use VI waveform construction to generate a signal's own scaling.
Normally, dt = sampling frequency/No. samples
Solution 2: replace the VI butterworth filter with filter VI express, this will produce signal without scaling.



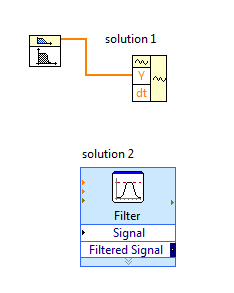
Maybe you are looking for
-
Y at - it a keyboard shortcut for "close all tabs in the right" and "close other tabs" actions? Thank you.
-
I dropped my iPad 2. It is out of warranty. When I tried to turn it on it started with a red screen with a battery symbol. After a few seconds, he would cycle to a gray, then black screen, then repeat the loop. It would not keep pressed power button
-
Need vista driver fot PX1211E - 1TVD USB DVB - T Tuner
Hi all, I need driver for the USB DVB - T Tuner, model PX1211E-1TVD I bought time ago. Fully functionaly on XP, but I need to driver Vista, 32 and 64 bits. Please, could someone link me the ultimate driver and software for vista for this USB? I check
-
Satellite L500D PSLK0A does not start after the Bios Update
I've had trouble with an "(ne répond pas) error ' while I was on IE8, so I looked up a few forums that all suggested I go to the manufacturers website and update the drivers for my computer." So I logged on the site of Toshiba Australia, put in all m
-
When I click on the "buy now" button for gift of my friend and itunes, it says that I must contact the support of itunes store to complete the transaction, what should I do?