High consistent readings
I have on a query performance problems in a production environment I can't reproduce in our test environment. Our test environment is an import of the production. Version information:Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - 64bi
PL/SQL Release 10.2.0.3.0 - Production
CORE 10.2.0.3.0 Production
TNS for Solaris: Version 10.2.0.3.0 - Production
NLSRTL Version 10.2.0.3.0 - Productioncall count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.03 0.05 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.02 0.01 241 1033 0 2
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.05 0.07 241 1033 0 2
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWScall count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.03 0.04 0 8 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 36.15 35.61 4 8187612 0 2
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 36.18 35.65 4 8187620 0 2
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWSHello
(1) obviously, the performance problem is caused by the wrong choice of conduct table
(2) this, in turn, is caused by steps 51-56 bad cardinality estimates, the production plan: the optimizer expects 4 rows where 120 k lines are returned
(3) in order to understand the reason for the inaccurate cardinality estimates, we see predicates you have not posted, and perhaps also the statistics on the columns involved in the predicate, thus the rowcounts actual and estimated
Best regards
Nikolai
Tags: Database
Similar Questions
-
high consistent readings for insert LOB
Hi all
Oracle 11.2.0.3, table with in the LOB line, 40% of lines stored offline. Three indices, ID, TAKE and CASEID, two children of a foreign key constraint.
Insert does contineously followed by application of an update on the same line (it's stupid, but a data and consequence of the use of hibernation).
DBA_HIST and 10046 trace, I often see the insert requiring thousands of consistent read gets, in track under 22cu 3140cr extract, 36cu, but also 1cr.
the insert would cause oracle to apply of course CF, but the two parent columns are indexed.
I can't explain the source of the cr gets. It may have something to do with the CONSERVATION of the LOB segment (4 hours). And if so, why is it need becomes consistent? who will help me?
Thank you, Jan-Marten Spit
PARSING IN CURSOR #140247543831072 len = 116 dep = uid 0 = 76 oct = 2 = 76 tim = hv 1380548509250682 lid = ad 2771882159 = "4cf569500" sqlid = "779p2n6kmg45g."
insert into CMFEVENT (EVENTDATA, DATEOCCURRED, EVENTTYPE, TAKE, CASEID, ID) values (: 1,: 2: 3: 4: 5: 6).
END OF STMT
ANALYSIS #140247543831072:c = 0, e = 472, p = 0, cr = 0, cu = 0, put = 1, r = 0, dep = 0, og = 1, plh = 0, tim = 1380548509250681
LINKS FOR #140247543831072:
Link #0
oacdty = 01 = 4001 (4108) mxl mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = lf2 03 = 1000010 frm = 01 csi = 873 siz = 4000 off = 0
kxsbbbfp = 7f8ded0bac48 = 4000 avl bln = 4001 flg = 25
value = "" ^ P241 ^ K355215 ^? '... "
Link #1
oacdty = 180 mxl = 11 (11) mxlc = 00 wrong = 00 = 09 = 00 pre scl
oacflg = lf2 03 = 9000000 frm = 00 csi = 00 siz = 2088 off = 0
kxsbbbfp = 7f8ded07c9b0 = 11 = 11 flg = 05 avl bln
value = 13-SEP-30 03.41.49.199000000 PM
Bind 2 #.
oacdty = 01 mxl = 2000 (496) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 03 fl2 = 1000010 frm = 01 csi = 873 siz = off 0 = 16
kxsbbbfp = 7f8ded07c9c0 = 2000 avl bln = 124 flg = 01
value = "" / IMP-Inkomensregister/3000_Inkomensregister/3200_Gebeurtenistypes/3220_IR09_Registreren_Inkomengegevens/PS11 inplannen.bixml ""
Link #3
oacdty = 02 mxl = 22 (22) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 03 fl2 = 1000000 frm = 01 csi = 873 siz = off 0 = 2016
kxsbbbfp = bln 7f8ded07d190 = 22 = 02 = 01 flg avl
value = 1
Link #4
oacdty = 02 mxl = 22 (22) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 03 fl2 = 1000000 frm = 01 csi = 873 siz = off 0 = 2040
kxsbbbfp = bln 7f8ded07d1a8 = 22 = 06 = 01 flg avl
value = 580429124
Link #5
oacdty = 02 mxl = 22 (22) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 03 fl2 = 1000000 frm = 01 csi = 873 siz = off 0 = 2064
kxsbbbfp = bln 7f8ded07d1c0 = 22 = 06 = 01 flg avl
value = 597880089
EXEC #140247543831072:c = 0, e = 1274, p = 0, cr = 1, cu = 22, SIG = 1, r = 1, dep = 0, og = 1, plh = 0, tim = 1380548509252004
"STAT #140247543831072 id = 1 cnt = 0 pid = 0 pos = 1 obj = 0 op ='LOAD TABLE CONVENTIONAL (cr = 1 pr = 0 pw = time 0 = 170 US)"
WAITING #140247543831072: nam ='SQL * Net message to client' ela = 1 driver id = 1952673792 #bytes = 1 p3 = 0 obj #=-1 tim = 1380548509252062
WAITING #140247543831072: nam ='SQL * Net client message' ela = 222 driver id = 1952673792 #bytes = 1 p3 = 0 obj #=-1 tim = 1380548509252298
OUTCOME #140247543831072:c = 0, e = 6, dep = 0, type = 0, tim = 1380548509252337
PARSING IN CURSOR #140247544075264 len = 116 dep = uid 0 = 76 oct = 2 = 76 tim = hv 1380548510409225 lid = ad 2771882159 = "4cf569500" sqlid = "779p2n6kmg45g."
insert into CMFEVENT (EVENTDATA, DATEOCCURRED, EVENTTYPE, TAKE, CASEID, ID) values (: 1,: 2: 3: 4: 5: 6).
END OF STMT
ANALYSIS #140247544075264:c = 0, e = 59, p = 0, cr = 0, cu = 0, set = 0, r = 0, dep = 0, og = 1, plh = 0, tim = 1380548510409225
LINKS FOR #140247544075264:
Link #0
oacdty = 01 mxl = 4001 (20724) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = lf2 03 = 1000010 frm = 01 csi = 873 siz = 4000 off = 0
kxsbbbfp = 7f8ded07c650 = 4000 avl bln = 4001 flg = 25
value = "" 270304355354215 ^? '... "
Link #1
oacdty = 180 mxl = 11 (11) mxlc = 00 wrong = 00 = 09 = 00 pre scl
oacflg = lf2 03 = 9000000 frm = 00 csi = 00 siz = 2088 off = 0
kxsbbbfp = 7f8ded0b6848 = 11 = 11 flg = 05 avl bln
value = 13-SEP-30 03.41.50.360000000 PM
Bind 2 #.
oacdty = 01 mxl = 2000 (496) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 03 fl2 = 1000010 frm = 01 csi = 873 siz = off 0 = 16
kxsbbbfp = 7f8ded0b6858 = 2000 avl bln = 124 flg = 01
value = "" / IMP-Inkomensregister/3000_Inkomensregister/3200_Gebeurtenistypes/3220_IR09_Registreren_Inkomengegevens/PS06 inplannen.bixml ""
Link #3
oacdty = 02 mxl = 22 (22) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 03 fl2 = 1000000 frm = 01 csi = 873 siz = off 0 = 2016
kxsbbbfp = bln 7f8ded0b7028 = 22 = 02 = 01 flg avl
value = 1
Link #4
oacdty = 02 mxl = 22 (22) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 03 fl2 = 1000000 frm = 01 csi = 873 siz = off 0 = 2040
kxsbbbfp = bln 7f8ded0b7040 = 22 = 06 = 01 flg avl
value = 577524323
Link #5
oacdty = 02 mxl = 22 (22) mxlc = 00 wrong = 00 = 00 = 00 pre scl
oacflg = 03 fl2 = 1000000 frm = 01 csi = 873 siz = off 0 = 2064
kxsbbbfp = bln 7f8ded0b7058 = 22 = 06 = 01 flg avl
value = 597880138
EXEC #140247544075264:c = 8001, e = 7824, p = 0, cr = 3140, cu = 36, SIG = 0, r = 1, dep = 0, og = 1, plh = 0, tim = 1380548510417087
"STAT #140247544075264 id = 1 cnt = 0 pid = 0 pos = 1 obj = 0 op ='LOAD TABLE CONVENTIONAL (cr = 3140 pr = 0 pw = time 0 = 7655 US)"
WAITING #140247544075264: nam ='SQL * Net message to client' ela = 1 driver id = 1952673792 #bytes = 1 p3 = 0 obj #=-1 tim = 1380548510417173
WAITING #140247544075264: nam ='SQL * Net client message' ela = 812 driver id = 1952673792 #bytes = 1 p3 = 0 obj #=-1 tim = 1380548510418003
OUTCOME #140247544075264:c = 0, e = 5, dep = 0, type = 0, tim = 1380548510418041
It turns out you are impratical to do track 10200, I couldn't isolate the INSERT as a single traceable statement.
but v$ tempseg_usage came to the rescue and showed that indeed the INSERT uses temporary segments to convert the varchar2 LOB, explaining the consistent readings.
-
Impossible to make the link between the consistent readings with the number of physical block reads
Hello
The issue is that we have seen consistent readings are more than the total buffers necessary to give back the results.
I emptied the buffer_cache before you execute the query and also questioned the V$ BH to know the details of the buffer for these objects... After the flush before you trigger the request that we do not have buffers about these tables. Which is expected.
We are doing sequential reads of DB file with the plan and will result in a single block, read at a time.
Please take a close look at "TABLE ACCESS BY INDEX ROWID CMPGN_DIM (cr = pr 45379 = 22949 pw = time 0 = 52434931 US)" line in the plan source line below...
Here we have only 22949 data buffers 22949 means reading physical but we are witnessing gets 45379 coherent.
Note: We have the CMPGN_DIM and AD_GRP tables in the tablespace size 4 M block and we have only the default db_cache_size. My database block size is 8192.
Can you please help me understand how the 22949 sequential reads the result in 45379 coherent takes.
Even the V$ BH query buffer details matches with physical reads.
line source of 10043 trace query plan:
SORT ORDER BY 27 (cr = 92355 pr 47396 pw = time = 0 = 359030364 en)
27 WINDOW SORT (cr = 92355 pr 47396 pw = time = 0 = 359030088 en)
NESTED LOOPS EXTRA-ATMOSPHERIQUE 27 (cr = 92355 pr 47396 pw = time = 0 = 359094569 en)
NESTED LOOPS EXTRA-ATMOSPHERIQUE 27 (cr = 92276 pr 47395 pw = time = 0 = 359041825 en)
VIEW 27 (cr = 92197 pr 47393 pw = time = 0 = 358984314 en)
UNION-ALL 27 (cr = 92197 pr 47393 pw = time = 0 = 358984120 en)
HASH GROUP BY 26 (cr = 92197 pr 47393 pw = time = 0 = 358983665 en)
VIEW 9400 (cr = 92197 pr 47393 pw = time = 0 = 359094286 en)
9400 COUNT (cr = 92197 pr 47393 pw = time = 0 = 359056676 en)
VIEW 9400 (cr = 92197 pr 47393 pw = time = 0 = 359009672 en)
9400 SORT ORDER BY (cr = 92197 pr 47393 pw = time = 0 = 358972063 en)
9400 HASH JOIN EXTERNAL (cr = 92197 pr 47393 pw = time = 0 = 358954170 en)
VIEW 9400 (cr = 92191 pr 47387 pw = time = 0 = 349796124 en)
JOIN by HASH 9400 (cr = 92191 pr 47387 pw = time = 0 = 349758517 en)
94 the TABLE ACCESS BY INDEX ROWID CMPGN_DIM (cr = pr 45379 = 22949 pw = time 0 = 52434931 US)
50700 IDX_CMPGN_DIM_UK1 INDEX RANGE SCAN (cr = 351 pr = 349 pw = time 0 = 1915239 US)(object id 55617)
TABLE ACCESS BY INDEX ROWID AD_GRP 60335 (cr = 46812 pr 24438 pw = time = 0 = 208234661 en)
60335 INDEX RANGE SCAN IDX_AD_GRP2 (cr = 613 pr = 611 pw = time 0 = 13350221 US)(object id 10072801)
VIEW 7 (cr = 6 pr = 6 pw = time 0 = 72933 en)
7 HASH GROUP BY (cr = 6 pr = pw 6 = 0, time = 72898 US)
162 PARTITION SINGLE PARTITION RANGE: 4 4 (cr = 6 pr = 6 pw = time 0 = 45363 en)
162 PARTITION PARTITION UNIQUE HASH: 676 676 (cr = 6 pr = pw 6 = 0, time = 44690 US)
162 INDEX RANGE SCAN PK_AD_GRP_DTL_FACT PARTITION: 3748 3748 (cr = 6 pr = pw 6 = 0, time = 44031 US) (object id 8347241)
1 DOUBLE QUICK (cr = 0 pr = 0 pw = time 0 = US 9)
25 TABLE ACCESS BY INDEX ROWID AD_GRP (cr = 79 pr = 2 pw = time 0 = 29817 US)user622572 wrote:
Hi Charles,
In this test of problem we have not any activity on my tables other than my session. If we do not have all cancel must be applied to the brand CR.* "So, which means the above?" *-->, that means the number of times where the blocks was visited is counted as CR not the number of buffers required to respond to a request. "
* "" Why a plan of execution would change the number of makes more sense? "*--> changes in the method of access to the path and join required a different number of times the same buffer necessary visit." It means NL require more number of same buffer visits to T2, T1 and INT_T1_C2 as the hash join.
* "' Why not flush the buffer cache would result in the PR drop statistics to 0, but does not change the statistics CR?" *--> each result buffer in physics RAS reads for objects from there which is why it cannot be zero in the first 4 tests where as test5 require PI (we don't rinse prior to that in your test case). " CR cannot be changed with buffer flush. Required CR same amount of pads and tampons visits regardless of buffer flush.
It seems that we can say that "CR numbers include the number of times the block was visited in a query instead of just the number of buffers required". ""
user622572,
You deserve a lot of credit for having read and understood what I posted to correctly answer the questions I asked at the bottom of results and for your ability to answer your original question.
Charles Hooper
IT Manager/Oracle DBA
K & M-making Machine, Inc. -
The way heart rate monitor works in watch
I have been using shows since the first day he appeared in Spain. Latest operating system installed os shows 2.
I usually run, leave, for example, 4-5 days a week. Sometimes in one race track, other running the streets.
In November, I discovered something that makes that there is something wrong. The operation of the heart rate monitor. I found, specially everything by working in the rail bearing, series of facts and gestures and running at different speeds, that sometimes heart rate was 165 and, in the next step, same minute, he is 75, and then, following measures in the same minute, once again 165... I went to an apple store and gave them time to study, but they could not "recreate" the problem, so they have nothing did... Of course the problem occurs only when running, so I guess that none of the technicians used the watch to get out and run for a few kilometres.
Most of the time the measures are ok, but last night, almost 9 km, running increasing pace, I found 6 times with incorrect measures.
Attached you will find three examples of screenshot taken. In this case, the change in the average heart rate is not important, but in other cases I couldn't use the reference, the watch switches for 10 to 15 minutes of wrong measurement.
The watch was properly placed around the wrist, so it wasn't the issue. And this has not happened before, with higher temperatures. Someone might say, s all about sweat, but there are more sweat in summer than in winter. Someone might say it is because of wearing long-sleeved shirts when running in winter, but this isn't the case, as I fold the sleeves to avoid it going between the watch and the skin.
I don't mean the watch doesn't work properly, but, obviously, the results provided are not correct.
Any help will be welcome.
Kind regards



Hello
Even in ideal conditions, Apple Watch may not be able to save a reliable heart rate monitor each time reading for everyone.
For best results, it is important for your watch to fit comfortably against the top of the wrist. To help with this, Apple suggests you consider your clamping watch band before workouts and it loosen again thereafter.
More information, including other factors that can affect the performance of the heart rate sensor:
- Your heart rate. What it means, and where on Apple Watch you will find. -Apple Support
- Use of the workout on your Apple Watch - Apple Support
For more consistent readings, you wish to a heart rate monitor external matching / Bluetooth chest strap for your watch.
-
DB file sequential read and read of the direct path
Hello
Could someone please clear my doubts about 'db file sequential read' and ' path direct reading. And help me understand the tkprof report correctly.
Please suggest if my understanding for scenario below is correct.
We have a 11.2.0.1 ' cluster 2 node rac version + asm' production and environment of his test environment that is a stand-alone database.
The query performs well in production compared to the test database.
The table is to have 254 + columns (264) with many lobs coulumns however LOB is not currently selected in the query.
I read in metalink this 254 table + column a intra-line-chaining, causing "db file sequential read" full table Scan.
Here are some details on the table which is similar to the prod and test, block size is 8 k:
What I understand less tkprof in production environment for a given session is:TABLE UNUSED BLOCKS TOTAL BLOCKS HIGH WATER MARK ------------------------------ --------------- --------------- --------------- PROBSUMMARYM1 0 17408 17407
1 - the request resulted in disk 19378 readings and 145164 consistent readings.
2 19378 disc bed, 2425 reads disc has given rise to the wait event 'db file sequential read'.
This statement is correct this disc remaining readings were "db file sequential reads" but real quick so didn't wait event tied to it?
3 - 183 'direct path read' there also. Is it because of the order by clause of the query?
The same query when ran in no no rac - asm test stand alone database has given below tkprof.SQL ID: 72tvt5h4402c9 Plan Hash: 1127048874 select "NUMBER" num from smprd.probsummarym1 where flag ='f' and affected_item = 'PAUSRWVP39486' order by num asc call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 1 0.53 4.88 19378 145164 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 3 0.53 4.88 19378 145164 0 0 Misses in library cache during parse: 0 Optimizer mode: ALL_ROWS Parsing user id: SYS Rows Row Source Operation ------- --------------------------------------------------- 0 SORT ORDER BY (cr=145164 pr=19378 pw=0 time=0 us cost=4411 size=24 card=2) 0 TABLE ACCESS FULL PROBSUMMARYM1 (cr=145164 pr=19378 pw=0 time=0 us cost=4410 size=24 card=2) Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ SQL*Net message to client 1 0.00 0.00 ges message buffer allocation 3 0.00 0.00 enq: KO - fast object checkpoint 2 0.00 0.00 reliable message 1 0.00 0.00 KJC: Wait for msg sends to complete 1 0.00 0.00 Disk file operations I/O 1 0.00 0.00 kfk: async disk IO 274 0.00 0.00 direct path read 183 0.01 0.72 db file sequential read 2425 0.05 3.71 SQL*Net message from client 1 2.45 2.45
Does this mean that:
1-here too, reads happen through "db file sequential read", but they were so fast that has failed to the wait event?
2. "direct path read," it's because of the order clause in the query. "
For trace files in the database Production and Test, I see that 'direct path read' is against the same data file that's stored table.SQL ID: 72tvt5h4402c9 Plan Hash: 1127048874 select "NUMBER" num from smprd.probsummarym1 where flag ='f' and affected_item = 'PAUSRWVP39486' order by num asc call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.06 0 0 0 0 Fetch 1 0.10 0.11 17154 17298 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 3 0.10 0.18 17154 17298 0 0 Misses in library cache during parse: 0 Optimizer mode: ALL_ROWS Parsing user id: SYS Rows Row Source Operation ------- --------------------------------------------------- 0 SORT ORDER BY (cr=17298 pr=17154 pw=0 time=0 us cost=4694 size=12 card=1) 0 TABLE ACCESS FULL PROBSUMMARYM1 (cr=17298 pr=17154 pw=0 time=0 us cost=4693 size=12 card=1) Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ SQL*Net message to client 1 0.00 0.00 Disk file operations I/O 1 0.00 0.00 db file sequential read 3 0.00 0.00 direct path read 149 0.00 0.03 SQL*Net message from client 1 2.29 2.29
Then how come 'this direct path read' because of the order by clause of the query and would have been in sort field size or pga?
Or this direct path read extracts real PGA disk data, and "db file sequential read" do not extract data?
I know, it's 'direct path read' is wait event when data are asked in PGA drive or what kind segment or temp tablespace is used.
Here is the example of trace file in the Production database:
Here are the trace file for the test database:*** 2013-01-04 13:49:15.109 WAIT #1: nam='SQL*Net message from client' ela= 11258483 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1357278555109496 CLOSE #1:c=0,e=9,dep=0,type=1,tim=1357278555109622 ===================== PARSING IN CURSOR #1 len=113 dep=0 uid=0 oct=3 lid=0 tim=1357278555109766 hv=138414473 ad='cfc02ab8' sqlid='72tvt5h4402c9' select "NUMBER" num from smprd.probsummarym1 where flag ='f' and affected_item = 'PAUSRWVP39486' order by num asc END OF STMT PARSE #1:c=0,e=98,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1127048874,tim=1357278555109765 EXEC #1:c=0,e=135,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1127048874,tim=1357278555109994 WAIT #1: nam='SQL*Net message to client' ela= 2 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1357278555110053 WAIT #1: nam='ges message buffer allocation' ela= 3 pool=0 request=1 allocated=0 obj#=-1 tim=1357278555111630 WAIT #1: nam='enq: KO - fast object checkpoint' ela= 370 name|mode=1263468550 2=65610 0=1 obj#=-1 tim=1357278555112098 WAIT #1: nam='reliable message' ela= 1509 channel context=3691837552 channel handle=3724365720 broadcast message=3692890960 obj#=-1 tim=1357278555113975 WAIT #1: nam='ges message buffer allocation' ela= 2 pool=0 request=1 allocated=0 obj#=-1 tim=1357278555114051 WAIT #1: nam='enq: KO - fast object checkpoint' ela= 364 name|mode=1263468550 2=65610 0=1 obj#=-1 tim=1357278555114464 WAIT #1: nam='KJC: Wait for msg sends to complete' ela= 9 msg=3686348728 dest|rcvr=65536 mtype=8 obj#=-1 tim=1357278555114516 WAIT #1: nam='ges message buffer allocation' ela= 2 pool=0 request=1 allocated=0 obj#=-1 tim=1357278555114680 WAIT #1: nam='Disk file operations I/O' ela= 562 FileOperation=2 fileno=6 filetype=2 obj#=85520 tim=1357278555115710 WAIT #1: nam='kfk: async disk IO' ela= 5 count=1 intr=0 timeout=4294967295 obj#=85520 tim=1357278555117332 *** 2013-01-04 13:49:15.123 WAIT #1: nam='direct path read' ela= 6243 file number=6 first dba=11051 block cnt=5 obj#=85520 tim=1357278555123628 WAIT #1: nam='db file sequential read' ela= 195 file#=6 block#=156863 blocks=1 obj#=85520 tim=1357278555123968 WAIT #1: nam='db file sequential read' ela= 149 file#=6 block#=156804 blocks=1 obj#=85520 tim=1357278555124216 WAIT #1: nam='db file sequential read' ela= 155 file#=6 block#=156816 blocks=1 obj#=85520 tim=1357278555124430 WAIT #1: nam='db file sequential read' ela= 4826 file#=6 block#=156816 blocks=1 obj#=85520 tim=1357278555129317 WAIT #1: nam='db file sequential read' ela= 987 file#=6 block#=156888 blocks=1 obj#=85520 tim=1357278555130427 WAIT #1: nam='db file sequential read' ela= 3891 file#=6 block#=156888 blocks=1 obj#=85520 tim=1357278555134394 WAIT #1: nam='db file sequential read' ela= 155 file#=6 block#=156912 blocks=1 obj#=85520 tim=1357278555134645 WAIT #1: nam='db file sequential read' ela= 145 file#=6 block#=156920 blocks=1 obj#=85520 tim=1357278555134866 WAIT #1: nam='db file sequential read' ela= 234 file#=6 block#=156898 blocks=1 obj#=85520 tim=1357278555135332 WAIT #1: nam='db file sequential read' ela= 204 file#=6 block#=156907 blocks=1 obj#=85520 tim=1357278555135666 WAIT #1: nam='kfk: async disk IO' ela= 4 count=1 intr=0 timeout=4294967295 obj#=85520 tim=1357278555135850 WAIT #1: nam='direct path read' ela= 6894 file number=6 first dba=72073 block cnt=15 obj#=85520 tim=1357278555142774 WAIT #1: nam='db file sequential read' ela= 4642 file#=6 block#=156840 blocks=1 obj#=85520 tim=1357278555147574 WAIT #1: nam='db file sequential read' ela= 162 file#=6 block#=156853 blocks=1 obj#=85520 tim=1357278555147859 WAIT #1: nam='db file sequential read' ela= 6469 file#=6 block#=156806 blocks=1 obj#=85520 tim=1357278555154407 WAIT #1: nam='db file sequential read' ela= 182 file#=6 block#=156826 blocks=1 obj#=85520 tim=1357278555154660 WAIT #1: nam='db file sequential read' ela= 147 file#=6 block#=156830 blocks=1 obj#=85520 tim=1357278555154873 WAIT #1: nam='db file sequential read' ela= 145 file#=6 block#=156878 blocks=1 obj#=85520 tim=135727855515
Thanks & Rgds,*** 2013-01-04 13:46:11.354 WAIT #1: nam='SQL*Net message from client' ela= 10384792 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1357278371354075 CLOSE #1:c=0,e=3,dep=0,type=3,tim=1357278371354152 ===================== PARSING IN CURSOR #1 len=113 dep=0 uid=0 oct=3 lid=0 tim=1357278371363427 hv=138414473 ad='c7bd8d00' sqlid='72tvt5h4402c9' select "NUMBER" num from smprd.probsummarym1 where flag ='f' and affected_item = 'PAUSRWVP39486' order by num asc END OF STMT PARSE #1:c=0,e=9251,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1127048874,tim=1357278371363426 EXEC #1:c=0,e=63178,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1127048874,tim=1357278371426691 WAIT #1: nam='SQL*Net message to client' ela= 2 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1357278371426766 WAIT #1: nam='Disk file operations I/O' ela= 1133 FileOperation=2 fileno=55 filetype=2 obj#=93574 tim=1357278371428069 WAIT #1: nam='db file sequential read' ela= 51 file#=55 block#=460234 blocks=1 obj#=93574 tim=1357278371428158 WAIT #1: nam='direct path read' ela= 31 file number=55 first dba=460235 block cnt=5 obj#=93574 tim=1357278371428956 WAIT #1: nam='direct path read' ela= 47 file number=55 first dba=136288 block cnt=8 obj#=93574 tim=1357278371429099 WAIT #1: nam='direct path read' ela= 80 file number=55 first dba=136297 block cnt=15 obj#=93574 tim=1357278371438529 WAIT #1: nam='direct path read' ela= 62 file number=55 first dba=136849 block cnt=15 obj#=93574 tim=1357278371438653 WAIT #1: nam='direct path read' ela= 17 file number=55 first dba=136881 block cnt=7 obj#=93574 tim=1357278371438750 WAIT #1: nam='direct path read' ela= 35 file number=55 first dba=136896 block cnt=8 obj#=93574 tim=1357278371438855 WAIT #1: nam='direct path read' ela= 22 file number=55 first dba=136913 block cnt=7 obj#=93574 tim=1357278371438936 WAIT #1: nam='direct path read' ela= 19 file number=55 first dba=137120 block cnt=8 obj#=93574 tim=1357278371439029 WAIT #1: nam='direct path read' ela= 36 file number=55 first dba=137145 block cnt=7 obj#=93574 tim=1357278371439114 WAIT #1: nam='direct path read' ela= 18 file number=55 first dba=137192 block cnt=8 obj#=93574 tim=1357278371439193 WAIT #1: nam='direct path read' ela= 16 file number=55 first dba=137201 block cnt=7 obj#=93574 tim=1357278371439252 WAIT #1: nam='direct path read' ela= 17 file number=55 first dba=137600 block cnt=8 obj#=93574 tim=1357278371439313 WAIT #1: nam='direct path read' ela= 15 file number=55 first dba=137625 block cnt=7 obj#=93574 tim=1357278371439369 WAIT #1: nam='direct path read' ela= 22 file number=55 first dba=137640 block cnt=8 obj#=93574 tim=1357278371439435 WAIT #1: nam='direct path read' ela= 702 file number=55 first dba=801026 block cnt=126 obj#=93574 tim=1357278371440188 WAIT #1: nam='direct path read' ela= 1511 file number=55 first dba=801154 block cnt=126 obj#=93574 tim=1357278371441763 WAIT #1: nam='direct path read' ela= 263 file number=55 first dba=801282 block cnt=126 obj#=93574 tim=1357278371442547 WAIT #1: nam='direct path read' ela= 259 file number=55 first dba=801410 block cnt=126 obj#=93574 tim=1357278371443315 WAIT #1: nam='direct path read' ela= 294 file number=55 first dba=801538 block cnt=126 obj#=93574 tim=1357278371444099 WAIT #1: nam='direct path read' ela= 247 file number=55 first dba=801666 block cnt=126 obj#=93574 tim=1357278371444843 WAIT #1: nam='direct path read' ela= 266 file number=55 first dba=801794 block cnt=126 obj#=93574 tim=1357278371445619
Vijay911786 wrote:
Direct path readings can be done on the series tablescans in your version of Oracle, but if you have chained rows in the table and then Oracle can read read read the beginning of the line in the path directly, but must make a single block in the cache (the db file sequential read) to get the next part of the line.
It is possible that your production system has a lot of chained rows, while your test system is not. As corroboration (though not convincing) indicator of what you might notice that if you take (reads disc - db file sequential reads) - who might get you close to all the blocks direct read - the numbers are very similar.
I'm not 100% convinced that it's the answer for the difference in behavior, but worth a visit. If you can force and indexed access path in the table, do something like "select / * + index (use {pk}) * / max table (last_column_in_table)" and check the number of "table fetch continued lines" could be close to the number of db file sequential reads you. (There are other options for the counting of the chained rows that could be faster).
Concerning
Jonathan Lewis -
Hear the inaccurate rate monitor
On the Apple Watch heart rate monitor is disabled by 400% each time that I exercise, which is when I want the most. I spoke to Apple and received a replacement watch, which unfortunately has the same level of inaccuracy. I tried to loosen, squeezing the band, moving the watch and get off my wrist, etc., with no obvious improvement of data. It seems pretty clear that the watch is very inaccurate in the detection of pulse given during heart rate rise.
Thoughts?
Hello
Even in ideal conditions, Apple Watch may not be able to save a reliable heart rate monitor each time reading for everyone. It may be the case, for example, that your perfusion of the skin (which can vary greatly from one person to another) is too low to get a reading accurate. Other factors can also affect the performance of the sensor, including irregular movements when they exercise.
For best results, it is important for your watch to fit comfortably against the top of the wrist. To help with this, Apple suggests you consider your clamping watch band before workouts and it loosen again thereafter.
More information:
- Your heart rate. What it means, and where on Apple Watch you will find. -Apple Support
- Use of the application of the workout on your Apple Watch - Apple Support
For more consistent readings, you wish to a heart rate monitor external matching / Bluetooth chest strap for your watch.
- Use of accessories with your Apple Watch - Support Apple Bluetooth
-
Update of movement causing problems
I developed a Machine Vision system that has worked more than 10 years without any problem of movement. I recently upgraded to Windows XP to Win7 computer; LabVIEW 7.1 to 2013; TestStand 4.2 to 2013; OR-Motion of 7.7 to 8.5.1.
Initially, the system seems to work without major modifications of the software well. But soon, he began to have problems with movement and motion control card (NI PCI-7334):
- When you move the XY Table; the vi ' check move full status "generates an error and does not expect the XY table arrive at its destination. The table always moves properly in the desired position. (do not have an account of the error right now)
- I have a LabVIEW program that constantly monitors the digital input ports on the PCI-7334 card that stops playback of the entries correctly (they are high; low readings). He also uses one of the ports as a control output turns on and he continues to work.
When one or both of these problems occur, if I check the card Max there is a! point to the icon and it says that the firmware is up to date. If I initialize the card the exclimation mark disappears and the firmware is "up-to-date". Removed it from the issues above; for awhile, then the problems will repeat.
I know it's a long shot, but any idea what could happen? I have watched closely on the screw and can't seem to find a memory leak or race condition. Is it possible that my VI which constantly monitors digital ports is to interfere with the operation of the query? As I said, it worked for 10 years without this problem before the upgrade.
I finally found the problem a few weeks ago. The error disappeared.
The problem was that the LabVIEW program that was constantly monitoring the digital input ports on the PCI-7334 map seems to conflict with VI which ensured control of the movement. Since they were operating asynchronously at any time that the two might try to access the card at the same time and cause the error. The difficulty was to eliminate the continually followed VI and replace it with digital input/outport screw the work of movement between the two calls.
I lost a bit of features making this but the system as a whole works fine.
-
PLSQL function to return the result of the query
Dear all,
Oracle Database SE1 11.2.0.1
I need to create a plsql function which should accept SQL as a parameter, execute it and return the result set.
Is this possible?
Madhu.149 wrote:
I need to create a plsql function which should accept SQL as a parameter, execute it and return the result set.
Be careful - results games indicate a set of data stored in memory. This is not what are sliders. This isn't how Oracle should be used.
Imagine that you implement such a result set function - which, on average, requires 1 MB of memory (private server) to store the results of the SQL query. A 100 users mean a 100 MB of memory required server. This is not suitable. Not at all. Never.
The correct back 'thing' is a handle to SQL cursor (called a ref cursor in this case). A SQL cursor is a "program" - that the appellant runs via the fetch command and generates one or more lines accordingly. Appellant repeatedly runs this slider through calls to fetch until this slider found and returns all rows affected (using consistent readings).
If you want an abstraction interface that the client can call via PL/SQL code in the database, so this crafting optimal SQL interface, creates the SQL cursor and returns the handle of the cursor (via the ref cursor data type) to the client.
-
Can we change primary standby Undo retention time
We set up a standby DB,.
can we undo retention target reduce the primary standby
What are the things to consider before.
hope because it is a watch - what is the significance of the undo retention target
Yes. Retention of cancellation can be reduced. The wait has no active SELECT statements (unless it is Active Data Guard, where you READ ONLY in managed recovery mode), so that consistent readings are reduced to a minimum on the day before. In addition, the phase to apply is often faster that it again is committed to primary school because there is no request pending on a user to press the "Save" button. Repeatedly, the cancellation must not be kept longer on the day before.
That being said, why change this setting on the eve? If it is set to match the primary school, there is no problem. And if you need to switchover to the standby, a lower undo retention can cause problems with the application.
See you soon,.
Brian -
Is there a "timing" on CR Image rebuild?
I checked v$ event_name (% of cr and cancel %) and it seems that everything regarding the reconstruction of CR is associated with cluster. Also to the search "consistent" and "CR" and "Cancel" in [url http://docs.oracle.com/cd/E11882_01/server.112/e25513/waitevents003.htm#BGGIBDJI] Descriptions of wait Events returned nothing relevant. Are there any statistics on the time needed in local / standalone instance? Or the Oracle considers is not useful to check if no statistics are kept?
Oracle: 11.2.0.3
OS: RHEL 5.6thtsang wrote:
Thanks Matthew, experience is exactly what I want.So it seems there is only a count, but not on consistent readings calendar...
That's right - it would probably be quite expensive for Oracle do calendar calls, as they could use more CPU the CPU spent acquiring and application undo records. The statistics you can look at are:
CR blocks created -- number of consistent read copies of blocks created data blocks consistent reads - undo records applied -- number of undo records used to create read consistent copies transaction tables consistent read rollbacks -- special case for read-consistent copies, this are CR copies of undo segment headers transaction tables consistent reads - undo records applied -- undo records applied to create CR copies of undo segment headers calls to kcmgcs -- calls made to determine commit times, which may result in Oracle deciding to do some CR creation, each call will result in a current get on an undo segment header block.When you play a recording cancel, you may need to do a physical exam read disk block - and in some cases, the random reads to undo blocks are the most important element of the book. This tends to be quire rare, however, that if some long updates collide with other tasks. The indicator here is statistics IO files for files in the tablespace (s) cancel it.
Concerning
Jonathan Lewis
http://jonathanlewis.WordPress.com
Author: core Oracle -
Why import data if ready schema and index create, increase in Undo TableSpace
I have a problem importing data.
When I export data don't have schema import include the index schema.
And then I import the schema ready.
When I import data, I find this Undo TableSpace increase very fast.
I have therefore two tests.
1. IMPORT of data and index, every thing ok look
2 import a schema includes index
and then import data. Undo Tablespace very rapid increaseIf you mean undo tablespace increase in order to read consisten read.
N ° cancel space use increases due to the DML. (requests for consistent readings read undo, they generate no cancellation to grow)
so you're saying that redo log appear, rollback undo segment will increase.
N ° increase in written cancellations results increase in roll forward.
IF we import large data, we must export data with the index and import data right now
If you import large data, you must create the indexes after the data is imported. If the index definitions are included in the export, the default behavior is that import will create them once the data is imported. To do this, undo lower for indexes.
Note This will generate redo for the creation (but does not cancel and therefore not generate recovery for cancellation). You can avoid this by manually running CREATE INDEX... NOLOGGING - but it means you need to get and modify the scripts CREATE INDEX.Hemant K Collette
-
Very high readings of temperature CPU of the Mac Pro 8-core 2007
I have a Mac Pro 1.1 updated to level with two Intel Xeon X 5365 CPU and firmware 2.1. The system has worked very well for months. However, I'm worried about CPU temperature readings. Assuming that the readings are correct, I have no explanation for the difference in typical 30 degree Celsius between the processor and the heat sink.
Is it possible, that the CPU exceeds their life expectancy?
During a stress test, I can see the following typical readings:
CPU core 87 C / 189 F
CPU a heatsink 58 C / 136 F
B processor 91 c/196 F
CPU radiator B C 59/138 F
I use new thermal paste Arctic MX-2 and tried various measures, including polishing of the surface of the CPU and the heatsink using sandpaper grain 1000. Nothing has so far had no effect on temperature readings. There should be enough good contact between the heatsink and processor during the installation, because they stick well enough to remove the heatsink again.
Max TCASE. According to the operating temperature -1333 http://ark.intel.com/products/30702/Intel-Xeon-Processor-X5365-8M-Cache-3_00-GHz-MHz-FSB is 63 degrees Celsius.
According to http://www.intel.com/content/dam/doc/design-guide/5400-chipset-memory-controller-moyeu-guidelines.pdf the Quad-Core Intel® Xeon® 5300 series include a function of on-chip temperature sensor. The heat sink provided by Apple has a temperature sensor, which seems to be fixed directly on the coper plate that touches the CPU head spreader.
Given the following quote from the same document:
TIM's performance is sensitive to degradation (e.g. breakdown of fat) over the life of the processor because of the temperature of the phenomena of cycling. For this reason, measuring of the processor given TCASE value can decrease over time according to the type of material of TIM.
Anyone know if the IHS on the CPU is soldered or whether they used the thermal paste between the IHS and the die of a CPU? In the case, perhaps it could explain the current temperature readings.
Any ideas? Thank you!
Your temperatures look a bit high, but not outrageous. The temperature measured on the Silicon of heat will be always higher than the temperature measured on the radiator. That's what the radiator is supposed to do, leads away from the heat to the fins, which would measure even more cool.
Your Mac allows to adjust speed of the fans to the top in a loop of feedback, founded the temperature of these measures. You can place a floor under your minimum speeds of fans. This can be done with the tool similar to some tool you already use, like the SMC fan control.
If the processors to exceed their safe operation temperature, your Mac will perform a sudden uncontrolled power off.
-
Windows 8 gives me high ping periodic and consistent spikes every 10 seconds
I'll use the League of Legends for example (but I have confirmed that this problem is not exclusive to LoL, it applies to all internet connections.)
Updated versions of Windows 8, I had 86ping perfectly fine, compatible on windows 7 while playing League of legends.After the upgrade to windows 8, all 10 seconds or if my ping would be pointing up anywhere between 300-800 ms. It might soar at this time for a little, then fall back down to 86ping front of fortification to new 10 seconds later.I have a computer running windows 7 with perfectly coherent 86ping on the League without any enrichment, and my computer of windows 8 is still doping.I can say with confidence that windows 8 has caused this problem somehow, whether directly or indirectly, as evidenced by other complaints people have had about 8 windows and games.Afflicted - computerASUS Zenbook Prime - UX31ABell fiber optics Internet 25/7 MB (download and upload respectively speeds)I have the same problem on win 10 did you find a solution?
-------------
solution found
-------------
for me, it was my wireless card.
Models:
Intel Centrino Advanced-N 6200
- Intel Centrino Advanced-N 6205
- Intel Centrino Advanced-N 6235
- Intel Centrino Advanced-N 6250
- Intel Centrino Advanced-N 6300
All models in this series have a driver problem.
To fix, please visit https://forums.lenovo.com/t5/Windows-8-and-8-1-Knowledge-Base/Debugging-latency-spikes-and-lag-on-certain-Intel-Centrino-wifi/ta-p/1471018
-
heart rate iWatch gives sporadic readings
I use my iWatch everyday to monitor my workouts and recently the watch started giving crazy readings. It will start to normal and 10 minutes in practice, it will say that my heart rate is in the 1940s. Then it will go up to 180 + and then back to normal for maybe 10 minutes. Meanwhile it greys out for maybe 3 to 5 minutes and said measure... I unpaired and reset and it never does not. It's very frustrating, because when I do a 1 hour training session I should get an average heart rate of 140-160 and now I get 80-110.
Anyone else having this problem? Are there any current patches?
Hello
Apple says that, even in ideal conditions, Apple Watch may not be able to save a reliable heart rate monitor each time reading for everyone.
For best performance of the sensor of heart rate during the training, Apple suggests you consider your clamping beforehand watch band and he loosen again thereafter.
The sensor is also likely to give better results for workouts that involve rhythmic (for example running) rather than the irregular movements (for example boxing). Other problems that can affect the performance of the sensor include the perfusion of the skin and wrist tattoos.
If your workouts involve flexing your wrists (for example what weight lifting, for example), it can help to keep your watch a little higher on your arm, the joint in flexion.
More information:
Your heart rate. What it means, and where on Apple Watch you will find. -Apple Support
Use of the workout on your Apple Watch - Apple Support
If you continue to experience problems, for more consistent measures, you may wish to a heart rate monitor external matching / Bluetooth chest strap for your watch:
Use the Bluetooth with your Apple Watch - Apple Support Accessories
-
Measurement time 4132 SMU is too high
Hello
I use PXI - 4132 DC EMS to perform some DC measurements at high speed. I just took a 1 K Ohms resistance, forced 1mA and measure 1V. I have this done configuration and code completed. I get the correct measurements. But my problem is with the measurement time. The total duration is about 45ms to complete installation and measurement, with the exception of the 'initialize and close '.
I checked the time at every step and I noticed that the maximum duration is taken during the "voltage reading. Out of the total 45ms, it takes about 34ms just for a measure. It's just a VI "Ukraine power measure" takes about 34ms, which is ridiculous compared to the Kiethleys. I tried to vary the time of "openness" and turn off the 'Auto Zero'. But the measurement time is still high. Can someone help me and let me know what is the best time of the measurement obtained with 413 x series SME?
Thank you!
Hey Phx_tech,
The amount you reduce your delay source depends very much your HAD and how regular you have to your level of tension until you start taking your measurements. If your Instrument is reactive, you can see discount gas and unintentional ringing during the transition from your output level and therefore would allow enough break-in before taking your measurement. The best thing to do is to experiment with different delays of source and see how much delay need you to get a consistent and reproducible measure. If you have a scope that is available, it will also show you the step response of the SMU with your Instrument. If your first reading is higher than your other readings, that this could very well be a problem with not enough time settling. What kind of DUT Testez_ you?
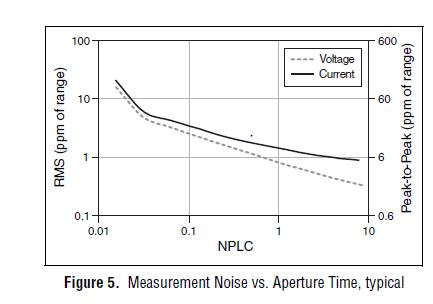
From page 4 of the specification, you can see that 1 PLC, we can expect about 1 ppm RMS noise of the range to 1 PLC. This means in the range 10 au our measurement noise would be 10 pA RMS or 60 pA pk - pk. However, your DUT + cables will pick up the extra noise and you should consider using wires of twisted shield pair to reduce noise picked up in your system. The shield can be terminated at the mass of the chassis on the side EMS of the cable to help reduce noise appearing in your measurement.
Let us know what you find after experimenting with you HAD.
Thank you!
Brandon G



Maybe you are looking for
-
Need help with uploading photos to the new macbook
I just bought a macbook pro 13 inch and had all my old files saved on a WD My Passport for Mac external hard drive. When try to import my library of photos from the external hard drive to the macbook, I receive a message reading "none of these files
-
Satellite L50 - A - unable to detect the remote device on BT
Hello I have a C50-A-1E9 Satellite, I bought with Windows 8.1 and it downgraded to Windows 7 change HARD for one SSD drive. Everything works fine except Bluetooth.I have an Atheros AR956x wireless network card. Already reinstalled battery bluetooth s
-
Windows 7 vs HP Officejet 6700 Premium
My HP Officejet 6700 Premium at work was scanning PDF and conversion to editable WORD format, as my work converted to Windows 7, the feature is no longer available. (I have the original cd for printer). This can be corrected?
-
When I try to connect directly in multiplayer FSX without gamespy, every time I get an error message saying: unable to create the connection to the host. I need help Kind regards
-
How to return the image to the entire office including the taskbar
my nephew who has 2 years managed to return my desktop screen saver screen, icons and task bar, so that it went backwards and so I have to return the computer to read and operate. Help me.