How to optimize this query XMLDB
Hello dear community, we have two XMLType table they are very similar but not identical and we do not have the XSD for validation for this exercise.
We need to make a join between these tables and the data code example go like that
create table xmltst ( xmldata xmltype); create table xmltst2 ( xmldata xmltype); declare idata varchar2(4000); idata2 varchar2(4000); begin idata := '<?xml version="1.0" encoding="UTF-8"?> <SWs> <SW s_ID="T6B890.00-01" t_ID="T6B890.00"> <Ds> <De sX="59" sY="-57" rX="7" rY="22" m_ID="L" eTime_s="2014-12-12T02:22:11+08:00" eTime_e="2014-12-12T02:22:42+08:00" mst="0.631"/> <De sX="70" sY="-57" rX="7" rY="23" m_ID="L" eTime_s="2014-12-12T02:22:12+08:00" eTime_e="2014-12-12T02:22:33+08:00" mst="0.217"/> <De sX="69" sY="-57" rX="47" rY="1" m_ID="R" eTime_s="2014-12-12T02:22:16+08:00" eTime_e="2014-12-12T02:22:56+08:00" mst="0.974"/> </Ds> </SW> <SW s_ID="T6B890.00-02" t_ID="T6B890.00"> <Ds> <De sX="56" sY="-1" rX="72" rY="19" m_ID="R" eTime_s="2014-12-12T02:36:01+08:00" eTime_e="2014-12-12T02:36:29+08:00" mst="0.541"/> <De sX="57" sY="-1" rX="39" rY="42" m_ID="L" eTime_s="2014-12-12T02:22:12+08:00" eTime_e="2014-12-12T02:23:01+08:00" mst="0.426"/> <De sX="58" sY="-1" rX="72" rY="20" m_ID="R" eTime_s="2014-12-12T02:36:07+08:00" eTime_e="2014-12-12T02:36:18+08:00" mst="0.716"/> </Ds> </SW> </SWs>'; idata2 := '<?xml version="1.0" encoding="UTF-8"?> <SWs> <SW s_ID="T6B890.00-01" t_ID="T6B890.00"> <Ds> <De sX="59" sY="-57" rX="7" rY="22" m_ID="L" eTime_s="2014-12-12T02:22:11+08:00" eTime_e="2014-12-12T02:22:42+08:00"/> <De sX="70" sY="-57" rX="7" rY="23" m_ID="L" eTime_s="2014-12-12T02:22:12+08:00" eTime_e="2014-12-12T02:22:33+08:00"/> <De sX="69" sY="-57" rX="47" rY="1" m_ID="R" eTime_s="2014-12-12T02:22:16+08:00" eTime_e="2014-12-12T02:22:56+08:00"/> <De sX="72" sY="-57" rX="47" rY="2" armID="R" eTime_s="2014-12-12T02:22:18+08:00" eTime_e="2014-12-12T02:23:28+08:00"/> <De sX="82" sY="-57" rX="7" rY="25" armID="L" eTime_s="2014-12-12T02:22:19+08:00" eTime_e="2014-12-12T02:22:58+08:00"/> </Ds> </SW> <SW s_ID="T6B890.00-02" t_ID="T6B890.00"> <Ds> <De sX="56" sY="-1" rX="72" rY="19" m_ID="R" eTime_s="2014-12-12T02:36:01+08:00" eTime_e="2014-12-12T02:36:29+08:00"/> <De sX="57" sY="-1" rX="39" rY="42" m_ID="L" eTime_s="2014-12-12T02:22:12+08:00" eTime_e="2014-12-12T02:23:01+08:00"/> <De sX="58" sY="-1" rX="72" rY="20" m_ID="R" eTime_s="2014-12-12T02:36:07+08:00" eTime_e="2014-12-12T02:36:18+08:00"/> </Ds> </SW> </SWs>'; insert into xmltst values (idata); insert into xmltst2 values (idata2); end; commit;
The SQL code, we try to optimize:
with tt as (
SELECT /*+ materialize */
x.*
FROM xmltst t,
XMLTABLE ('/SWs/SW[@s_ID="T6B890.00-01"]/Ds/De'
PASSING t.xmldata
COLUMNS sX number PATH '@sX',
sY number PATH '@sY',
rX number PATH '@rX',
rY number PATH '@rY',
eTime_s varchar2(30) PATH '@eTime_s',
eTime_e varchar2(30) PATH '@eTime_e',
mst number PATH '@mst'
) x
)
,tt2 as (
SELECT /*+ materialize */
x.*
FROM xmltst2 t,
XMLTABLE ('/SWs/SW[@s_ID="T6B890.00-01"]/Ds/De'
PASSING t.xmldata
COLUMNS sX number PATH '@sX',
sY number PATH '@sY',
rX number PATH '@rX',
rY number PATH '@rY',
eTime_s varchar2(30) PATH '@eTime_s',
eTime_e varchar2(30) PATH '@eTime_e'
) x
)
select tt2.*,tt.mst
from tt2
left outer join tt
on (tt2.sX = tt.sX and tt2.sY = tt.sY and tt2.rX = tt.rX and tt.rY=tt.rY)
CREATE INDEX xmltst_idx ON xmltst (xmldata) INDEXTYPE IS XDB.XMLIndex PARAMETERS ( 'XMLTable SW_tab ''/SWs/Sw'' COLUMNS s_ID VARCHAR2(100) PATH ''@s_ID'', sX NUMBER PATH ''Ds/De/@sX'', sY NUMBER PATH ''Ds/De/@sY'', rX NUMBER PATH ''Ds/De/@rX'', rY NUMBER PATH ''Ds/De/@rY''');
Create an index as above, but it does not seem to be used to explain the plan for the part of XML query.
and a lot of time, I also get this error but I cannot now re - produce for some reason.
I thought that its because I can't index after branch out according to s_ID
SQL Error: ORA-29879: cannot create multiple domain indexes on a column list using same indextype 29879. 00000 - "cannot create multiple domain indexes on a column list using same indextype" *Cause: An attempt was made to define multiple domain indexes on the same column list using identical indextypes. *Action: Check to see if a different indextype can be used or if the index can be defined on another column list.
and this index below seems to have choice as shown explain plan.
Why can't I see the index above in the plan to explain it?
CREATE INDEX "OE"."XMLTST_INDX01" ON "OE"."XMLTST" ("XMLDATA")
INDEXTYPE IS "XDB"."XMLINDEX" PARAMETERS ('paths (include (/SWs/SW/@s_ID))');
However, it is still the loop nest join when the join of two tables after the XML in the process... Is it possible to tell Oracle to a join index or some kind of faster join after the XML select part.
My real case got way as many lines to make the join of X - Y and it may be nice to have an index to quickly reach?
When do some small tests, the clause will eventually cause oracle core dump. It should not happen even it is a virtual machine with 3G of memory max and the max_memory_target = 800 M as all my data are not not even 50 M.
We are the team of analysts and Dev team suggest that is a little too much time to contact Oracle Support and I finally create 3 global temporary table with commit preserve rows and operate with performance much better.
Tags: Database
Similar Questions
-
Hello
I have a query like this:
Merge into the table st1
using (select * from (select pk, value, diff_value, m_date, row_number () over (PARTITION pk ORDER BY diff_value) rnk)
from (select distinct / * + Full (t1) full (t2) * / t1.pk, t2.m_date)
, Case when (t1.m_date = t2.m_date) then "CORRESPONDENCE".
When (t2.m_date BETWEEN t1.m_date-1 and t1.m_date + 1) then ' MATCHED WITH +/-1gg.
When (t2.m_date BETWEEN t1.m_date-2 and t1.m_date + 2) then "MATCHED WITH +/-2 days.
else "
end value_match
Case when (t1.m_date = t2.m_date) then 0
Where (t2.m_date BETWEEN t1.m_date + 1 and t1.m_date - 1) then 1
Where (t2.m_date BETWEEN t1.m_date + 1 and t1.m_date - 1) then 2
else "
end diff_value
of table t2, t1 table
where t1.value is null
and t1.id = t2.id)
where value_match is not null)
where rnk = 1) s
on (st1.pk = s.pk)
WHEN MATCHED THEN
Update set st1.value = s.value_match, st1.diff_value = s.diff_value, st1.up_date = s.m_date
where st1.value is null.
Explain the plan:

Table1 a record 3Million and table 2 has 1 million records.
I used gather stats before you run this query and 'Full' trick, even in this case, he is running for 45 minutes.
Please suggest the best solution to optimize this query.
Thanks in advance.
Remove the tips.
No need for the separate.
Get the diff by ceil (abs(t2.m_date-t1.m_date)) and the filter for that where value_diff<>
Assing the statement ".. MATCHED" lately in the update clause.
Maybe give exactly to your needs with a small example may be the query may be getting more simplified or not what you want it to do.
-
No idea how to write this query
Hi, My Data is as below
DocNum doc_date type of amount
1154 15 November 11 232501.5 invoice
200206 4 November 11 - 243672.64 credit memo
Note flow 111 5 November 555.22 11
Output must be
DocNum doc_date amount Type AmountDR AmountCR
1154 232501.5 15 November 11 Bill 232501.5
Note credit 200206 4 November 11 - 243672.64 - 243672.64
Note flow 111 5 November 555.22 11 555.22
If the amount is > 0, then it must be displayed in the value of the amount to be AmountDR
If amount < 0 then it must be displayed in the value of the sum amount CR
Can help how to write this querywith sample_table as ( select 1154 Docnum,date '2011-11-15' doc_date,232501.5 Amount,'Invoice' type from dual union all select 200206,date '2011-11-04',-243672.64,'Credit Memo' from dual union all select 111,date '2011-11-05',555.22,'Debit Memo' from dual ) select Docnum, doc_date, Amount, type, case when Amount >= 0 then Amount end AmountDR, case when Amount < 0 then Amount end AmountCR from sample_table / DOCNUM DOC_DATE AMOUNT TYPE AMOUNTDR AMOUNTCR ---------- --------- ---------- ----------- ---------- ---------- 1154 15-NOV-11 232501.5 Invoice 232501.5 200206 04-NOV-11 -243672.64 Credit Memo -243672.64 111 05-NOV-11 555.22 Debit Memo 555.22 SQL>SY.
-
How to write this query in the hierarchy
Hi gurus,
Really need your help on this query. Thank you very much in advance.
SELECT t1.key as root_key , (SELECT t2.unit_id AS unit_id level-1 AS level , t2.name, t2.creator FROM tab t2 START WITH t2.unit_id = t1.unit_id -----check each node as root CONNECT BY prior t2.unit_id = t2.parent_unit_id ) t1.name as parent_unit_name FROM tab t1
I'll write a query of the hierarchy as above, and that EACH line (node, totally more than 10200) is checked as root node to see how many sheets are accessible for her... It must be implemented in a single query.
I know inline query should NOT return multiple rows or multiple columns, but the inline elements are necessary and can certainly be made in a correct solution.
(env):
Database Oracle 12 c Enterprise Edition Release 12.1.0.2.0 - 64 bit Production
PL/SQL Release 12.1.0.2.0
)
Test data:
select 1 as unit_id, null as parent_organization_unit_id, 'U1' as name from dual union all select 2, 1, 'U2' FROM DUAL UNION ALL SELECT 3, NULL, 'U3' FROM DUAL UNION ALL SELECT 4, 3, 'U4' FROM DUAL UNION ALL SELECT 5, 2, 'U5' FROM DUAL UNION ALL SELECT 6, 5, 'U6' FROM DUAL UNION ALL SELECT 7, 6, 'U7' FROM DUAL UNION ALL SELECT 8, 5, 'U8' FROM DUAL UNION ALL SELECT 9, 5, 'U9' FROM DUAL;
Final result should be like this
key unit_id, level, name, parent_name 1 1 0 u1 u1 1 2 1 u2 u1 1 5 2 u5 u1 1 6 3 u6 u1 1 7 4 u7 u1 1 8 3 u8 u1 1 9 3 u9 u1 2 2 0 u2 u2 2 5 1 u5 u2 2 6 2 u6 u2 2 7 3 u7 u2 2 8 2 u8 u2 2 9 2 u9 u2
Don't know how get you your output, it does not match your data...
with tab as)
Select 1 as unit_id, null as parent_organization_unit_id 'U1' as the name of double
Union of all the
Select 2, 1, 'U2' FROM DUAL
UNION ALL
SELECT 3, NULL, 'U3' FROM DUAL
UNION ALL
SELECT 4, 3, 'U4' FROM DUAL
UNION ALL
SELECT 5, 2, 'U5' OF THE DOUBLE
UNION ALL
SELECT 6, 5, 'U6' OF THE DOUBLE
UNION ALL
SELECT 7, 6, "U7" OF THE DOUBLE
UNION ALL
SELECT 8, 5, 'U8' FROM DUAL
UNION ALL
9. SELECT, 5, 'U9' FROM DUAL
)
Select dense_rank() key (order by connect_by_root unit_id), unit_id, level - 1 as 'LEVEL', connect_by_root name root_parent_name
t tab
Start with parent_organization_unit_id is null
Connect prior unit_id = parent_organization_unit_id
KEY UNIT_ID LEVEL ROOT_PARENT_NAME 1 1 0 "U1". 1 2 1 "U1". 1 5 2 "U1". 1 6 3 "U1". 1 7 4 "U1". 1 8 3 "U1". 1 9 3 "U1". 2 3 0 "U3". 2 4 1 "U3". -
Hi people,
I need to get a query in which a set of records, I get ONLY those which previous registry has a field with a value to this topic. Other values, the field can contain are not necessary.
I know that sounds easy but... I can't get it.
So, for Oracle 10 g 2... Here's my query:
SELECT a.person_id, a.person_status, a.message_id, a.order_id
OF t_HR one
WHERE a.person_status = "rejected".
AND a.id >
(SELECT max (b.id)
OF t_HR b
WHERE b.person_id = a.person_id
and b.order_id = a.order_id
AND b.person_status! "revised =".
B.ID AND < a.id)
ORDER BY desc a.id
Let me explain:
1 - HR table is a table of people. These people has serveral STATUS.
2 - ID is a sequential (each www.voyages-sncf.com has a different identification number).
3 - the application must get THAT all people "rejected".
4. - However, (subquery) I need ONLY those that previous register (the second register) holds a status of "OK". If the person holds a "revised" status he's not, he should be the next register (the third)
5.-L' ORDER ID DESC, so is the first register must have a STATUS = "rejected" and the second a 'OK '. IF the second register = "revised", then the third register must be 'OK '. And I need this query.
HOW DO?
My problem: the subquery gives you previous register of the same guy, but... it does not give you the value of the State, I need, which is 'OK '.
I tried to add to the subquery...
SELECT max (b.id)
OF mod_human_resource b
WHERE b.person_id = a.person_id
and b.order_id = a.order_id
AND b.person_status = 'OK '.
AND b.id < a.id
... but if I have 5 records of that person, the first is "rejected", the second is "accepted", the third is 'new' and the fourth is 'OK'... the subquery gives you the 4th register and which is not correct for me, it must be only the second one (prior to the first State registry).
I need to be a query, because I need to use it on a MERGER for a DWH.
If there is another way (function, or even a procedure) to make the MERGER rather than with a request, which would be ok too. I am poor DWH knowledge.
Thanks in advance.
Hello
So, you need to know if a line is the 'first' line, and you should also know what is the 'next' status, (even the 'first' and 'next' are already defined). This sounds like a job for analytical functions. ROW_NUMBER can tell you if a line is first or not, and LEAD can tell you what a value on the next row.
Since you post CREATE TABLE and INSERT statements for your own table, I'll use the table scott.emp to illustrate.
Consider these data from scott.emp:
SELECT DeptNo
ename
work
FROM scott.emp
ORDER BY deptno
ename DESC
;
Output:
DEPTNO ENAME JOB
---------- ---------- ---------
10 MILLER CLERK
PRESIDENT OF KING 10
MANAGER 10 CLARK
20 SMITH CLERK
ANALYST SCOTT 20
20 JONES MANAGER
20 FORD ANALYST
20 ADAMS CLERK
30 WARD SALESMAN
SELLER OF 30 TURNER
30 MARTIN SALESMAN
30 JAMES CLERK
MANAGER BLAKE 30
30 ALLEN SALESMAN
Now, let's say we want only who know the departments where the forefront (in order descending ename) a job = 'CLERK', and the following line (also in descending by ename order) = "ANALYST" job, and we want to know the ename of the first row. In other words, the correct output is:
DEPTNO ENAME
---------- ----------
20 SMITH
Note that deptno = 10 is not included, even if the first task is to "CLERK." that was because the second job in deptno = 10 is the "PRESIDENT", not "ANALYST."
Here's a way to get these results:
WITH got_analytics AS
(
SELECT ename, deptno, job
ROW_NUMBER () OVER (PARTITION BY deptno
ORDER BY ename DESC
) AS r_num
LEAD (employment) OVER (PARTITION BY deptno
ORDER BY ename DESC
) AS next_job
FROM scott.emp
)
SELECT deptno, ename
OF got_analytics
WHERE r_num = 1
AND job = 'CLERK '.
AND next_job = 'ANALYST '.
;
I hope that answers your question.
If this isn't the case, then, as Dan (and the FAQ forum) said, post CREATE TABLE and INSERT statements for some sample data and the exact results you want from these data.
Post your query, based on the one I have posted more top and ponit out where he gets results.
Always say what version of Oracle you are using (for example, 11.2.0.2.0).
See the FAQ forum: https://forums.oracle.com/message/9362002#9362002
-
How to optimize the query with a join of virtual tables
I'm working on a query that is get the data of virtual tables 2 and b
one is formed by the Union, all say 4 queries and b is formed by the Union, all say 3 queries
then these two virtual tables and b are joined on a column common and data are extracted from their part.
Problem is that there is about 1 minutes each in the two virtual tables has and b. If individual a and b queries virtual takes about 5 seconds to retrieve data
but the join on column takes about 25 seconds to retrieve data.
Can someone guide me how to optimize the recovery of joining 2 virtual tables having large data
Thank youPlease read these:
When your query takes too long
When your query takes too long...How to post a SQL tuning request
HOW to: Validate a query of SQL statement tuning - model showing -
How to rewrite this query to get the correct results?
Friends,
DB: 9iR2
I need to get the name of the employee and the employee number that are not in the table of presence.
but this query is not the right answer.
Thank youselect e.eno,e.ename from empl e where e.eno not in (select a.eno from attendance a)Depending on your data
SQL> create table attendance( 2 ENO VARCHAR2(5), 3 TDATE VARCHAR2(10), 4 IN_TIME VARCHAR2(6), 5 OUT_TIME VARCHAR2(6), 6 SHIFT_NO NUMBER(1)); Table created. SQL> create table empl( 2 ENO VARCHAR2(5), 3 ENAME VARCHAR2(75)); Table created. SQL> insert into empl values('11','AA'); 1 row created. SQL> insert into empl values('12','AB'); 1 row created. SQL> insert into empl values('13','AC'); 1 row created. SQL> insert into empl values('14','AD'); 1 row created. SQL> insert into empl values('15','AF'); 1 row created. SQL> insert into attendance values('11','23-3-2009','9.00','6.00',1); 1 row created. SQL> insert into attendance values('14','24-3-2009','9.00','6.00',1); 1 row created. SQL> insert into attendance values('11','25-3-2009','9.00','6.00',1); 1 row created. SQL> insert into attendance values('13','23-3-2009','9.00','6.00',1); 1 row created. SQL> insert into attendance values('15','23-3-2009','9.00','6.00',1); 1 row created. SQL> commit; Commit complete. select e.eno,e.ename from empl e where not exists(select 1 from attendance a where a.eno=e.eno); ENO ENAME 12 ABTwinkle
-
some of you that it won't be easy, but for a rookie plsql is not form. Can U help?
want to find out who has max (salary) and record that information in a variable
Table: used
Select max (salary) in employee == > back 2500id salary 1 2000 2 2500 3 1800
But how to write this in a plsql and find the id is 3 and save it in a variable
my incomplete statement:
Select max (salary), in myvar to employee where id =?
can you help me?Oh and save it in a variable plsql:
declare my_var emp.empno%TYPE; begin select e1.empno into my_var from emp e1 where e1.sal = (select max(e2.sal) from emp e2) and rownum = 1; end; / -
How to simplify this query in sql simple select stmt
Hello
Please simplify the query
I want to convert this query in a single select statement. Is this possible?
If uarserq_choice_ind is not null then
Select ubbwbst_cust_code
From ubbwbst,utrchoi
Where utrchoi_prop_code=ubbwbst_cancel_prod
Else
Select max(utvsrvc_ranking)
From utvsrvc,ubbwbst
Where utvsrvc_code=ubbwbst_cancel_prod
End ifSelect ubbwbst_cust_code as val From ubbwbst,utrchoi Where utrchoi_prop_code=ubbwbst_cancel_prod AND uarserq_choice_ind is not null union all Select max(utvsrvc_ranking) as val From utvsrvc,ubbwbst Where utvsrvc_code=ubbwbst_cancel_prod and uarserq_choice_ind is nullWithout more information, we are unable to combine the two queries in 1 without a union.
Looks like you select values totally disperate of totally different tables -
How to solve this query in database using sqlite phone gap
am facing a problem in recent days. The problem is database. In fact, I create the mane database 'casepad '. Then I created a table because the database 'table of cases' have (ID, name, date). Now I insert the value on this table. When inserting I also create a name ("casename") .mean table if I insert the value of the case table (1, 'AB', 2/13). Then I create table AB. Now I need to get the value of the case table (I am) but I need to count the number of items in another table (AB). Here, I had to try it.
function onDeviceReady() { db = window.openDatabase("Casepad", "1.0", "Casepad", 200000); db.transaction(getallTableData, errorCB); } function insertData() { db.transaction(createTable, errorCB, afterSuccessTableCreation); } //createtableandinsertsome record function createTable(tx) { tx.executeSql('CREATE TABLE IF NOT EXISTS CaseTable (id INTEGER PRIMARY KEY AUTOINCREMENT, CaseName TEXT unique NOT NULL ,CaseDate INTEGER ,TextArea TEXT NOT NULL)'); tx.executeSql('INSERT OR IGNORE INTO CaseTable(CaseName,CaseDate,TextArea) VALUES ("' + $('.caseName_h').val() + '", "' + $('.caseDate_h').val() + '","' + $('.caseTextArea_h').val() + '")'); } //function will be called when an error occurred function errorCB(err) { navigator.notification.alert("Error processing SQL: " + err.code); } //function will be called when process succeed function afterSuccessTableCreation() { console.log("success!"); db.transaction(getallTableData, errorCB); } //select all from SoccerPlayer function getallTableData(tx) { tx.executeSql('SELECT * FROM CaseTable', [], querySuccess, errorCB); } function querySuccess(tx, result) { var len = result.rows.length; var t; $('#folderData').empty(); for (var i = 0; i < len; i++) { $('#folderData').append( ' - ' + '' + '
 ' + '
' + '' + result.rows.item(i).CaseName + t+'
' + '' + result.rows.item(i).TextArea + '
' + '' + result.rows.item(i).CaseDate + '
' + '' + i + '' + ''+' '
);
}
$('#folderData').listview('refresh');
}
-
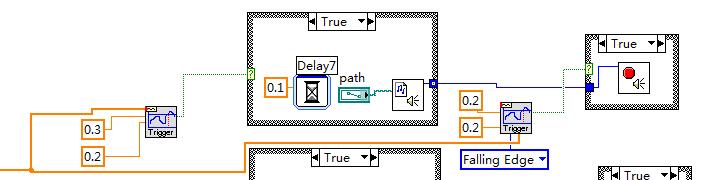
Hi all
The function I want to achieve is very simple. The reading of data from data acquisition, play the sound file if a rising edge is detected and stop playing if a front down is detected.
Attachment is my code, it works, but if I stop the program and restart it, the program will be somewhat stuck (but), so all I can do is to put an end to the task and to reopen the program. I put two structures case for each channel, I believe that the problem is caused by the second case structure.
I am a beginner of labview, could someone optimize me this code?
Thank you!
First, use the charts to your advantage. You can do this fairly simple dynamic conversion of the Data Type in a table of waveforms. Trigger detection can treat an array of waveforms. You can then process all detections of relaxation in a loop, updated what trigger (and level), that you are looking for dynamically.

-
How to run this query correctly?
Hi Sir,
I use a query that I converted from sql to oracle but in error.
Error (4.3): PLS-00428: an INTO clause in this SELECT statement
Here's my query:
SELECT distinct Code pa.id, pa. Empcode Emp_ID, E.Emp_FirstName | ' ' || E.Emp_LastName Emp_Name, pa. Work Date1 date, pa. InPunch In_Punch, pa. OutPunch Out_Punch, pa.approve, ls. Leave_Status_text StatusText, NVL (pt.punchtype, 'day') JOIN employee E ON PunchForApproval pa e.Emp_ID punchtype is pa. Empcode LEFT JOIN Leave_status ls TO ls. Leave_Status_id = pa.approve LEFT JOIN punchtype pt ON pt.id = pa. STATUS
WHERE E.Emp_ID IN (SELECT Emp_id FROM employee) ORDER BY pa.id DESC;
Thank youHello
You run this in a PL/SQL procedure? If so, what the procedure called the request?Also, did you see the error even if you add a space to the request here.
WHERE E.Emp_ID IN (SELECT Emp_id FROM employee) ORDER BY pa.id DESC;
-implement-
WHERE E.Emp_ID IN (SELECT Emp_id FROM employee) ORDER BY pa.id DESC;
Kind regards
Mike -
How to use this query in oracle?
Hi Sir,
I use a SQL query that is
declare @date date ='2012-10-25', @date1 varchar (5)
Set @date1 = DATEPART (W, @date)
impression @date1
that its value means day 25 oct 5 back Thursday it is checking and counting from Sunday in this week so the result is 5 next.
and storing in @date1
the same result I want in oracle.
Thank youTry this...
/* Formatted on 10/5/2012 10:22:34 AM (QP5 v5.163.1008.3004) */ SELECT TO_CHAR (TO_DATE ('2012-10-25', 'yyyy-mm-dd'), 'D') FROM DUAL;gives
5HTH
Vanessa B. -
How to write this query procedure of ina
IF ((drapeau = ' n ') OR (flag = 'F') OR (FLAG =' WAS))
) THEN
SELECT CUSTOMER_ID, BUSINESS_PASSCODE, LOG ON TO V_CUSTOMER_ID, V_BUSINESS_PASSCODE, V_LOG OF THE CUSTOMER
WHERE V_BUSINESS_PASSCODE AND V_CUSTOMER_ID = & ID = & CODE AND
V_LOG IN('Y')
SO I HAVE TO RETURN THE ISP (OF TYPE VARCHAR) CAN YOU TELL HOW DOMake values flag, id, code as a parameter and an output parameter. You can have any number f settings if you want to return the results of the query.
as
create procedure (identification number, varchar2, varcahr2, out returnvalue flag code varchar2)
as
Start
-your code---
--
IF ((drapeau = ' n ') OR (flag = 'F') OR (FLAG =' WAS))
) THEN
SELECT CUSTOMER_ID, BUSINESS_PASSCODE, LOG ON TO V_CUSTOMER_ID, V_BUSINESS_PASSCODE, V_LOG OF THE CUSTOMER
WHERE V_CUSTOMER_ID = ID AND CODE = V_BUSINESS_PASSCODE AND
V_LOG IN('Y');
returnValue =; -
(notice, it is in fact a view... try to simplify my problem)
Can you help me? I'm looking for a single row of data for each student with each topic. My problem happen when student takes several subjects. Help
CREATE TABLE 'TEST '.
(ACTIVATE THE "SUB_NO" NUMBER NOT NULL,)
ACTIVATE THE "SUB_NAME' VARCHAR2 (50) NOT NULL,
ACTIVATE THE "ST_ID" NUMBER NOT NULL,
VARCHAR2 (20) "ST_FNAME."
VARCHAR2 (25) "ST_LNAME."
NUMBER (2.0) "QUARTER."
'CATEGORY' NUMBER (2.0)
)
Insert test values
(102, "Math", 4, "Josse", 'C', 1, 60);
Insert test values
(101, 'Art', 1, 'Tom', 'K', 1, 90);
Insert test values
(101, 'Art', 2, 'Ken', 'G', 1, 80);
Insert test values
(102, 'Math', 3, 'Mary', ', 1, 76);
Insert test values
(101, 'Art', 1, 'Tom', 'K', 3, 87);
Insert test values
(102, 'Math', 1, 'Tom', 'K', 1, 99);
Insert test values
(101, 'Art', 1, 'Tom', 'K', 2, 92);
Use the following query
Select sub_name st_id, st_fname, st_lname,
neighborhoods of LTRIM (SYS_CONNECT_BY_PATH(Quarter,','), ',')
ranks of the LTRIM (SYS_CONNECT_BY_PATH(grade,','), ',')
from (select sub_name, st_id, st_fname, st_lname, quarter, year,
ROW_NUMBER() on rn (partition in order ST_ID by quarter)
Of
test)
where connect_by_isleaf = 1
Start by rn = 1
connect to ST_ID = prior ST_ID
and rn = rn + 1 advance
= ObjectiveSUB_NAME ST_ID ST_FNAME ST_LNAME QUARTERS GRADES Art 1 Tom K 1,1,2,3 90,90,92,87 Art 2 Ken G 1 80 Math 3 Mary T 1 76 Math 4 Janny C 1 60
TaiSUB_NAME ST_ID ST_FNAME ST_LNAME QUARTERS GRADES Art 1 Tom K 1,2,3 90,92,87 Art 2 Ken G 1 80 Math 3 Mary T 1 76 Math 4 Janny C 1 60 Math 1 Tom K 1 99Hello
Please post sample data!
Try this:
hoek&XE> select sub_name 2 , st_id 3 , st_fname 4 , st_lname 5 , ltrim(sys_connect_by_path(quarter,','),',') quarters 6 , ltrim(sys_connect_by_path(grade,','),',') grades 7 from ( select sub_name 8 , st_id 9 , st_fname 10 , st_lname 11 , quarter 12 , grade 13 , row_number() over ( partition by st_id, sub_name order by st_id) rn 14 from test 15 ) 16 where connect_by_isleaf = 1 17 start with rn = 1 18 connect by st_id= prior st_id 19 and sub_name = prior sub_name 20 and rn = prior rn+1 21 order by sub_name; SUB_NAME ST_ID ST_FNAME ST_LNAME QUARTERS GRADES ---------- ---------- -------------------- ------------------------- ---------- ---------- Art 1 Tom K 1,2,3 90,92,87 Art 2 Ken G 1 80 Math 4 Janny C 1 60 Math 3 Mary T 1 76 Math 1 Tom K 1 99Published by: hoek on November 17, 2009 22:54 included from serveroutput of sample data

Instend of show the value of 'i' in the view list, I need to show how many element in the table. I have to call synchronize because I call a query that counts the number of elements to 'result.rows.item (i). CaseName"this item... ?
Hello
If I understand correctly, you are looking for a SQL statement that you will get the count for the number of items in the table AB? If so, this can be useful:
http://www.w3schools.com/SQL/sql_func_count.asp
Please let me know if you have any other questions.
Maybe you are looking for
-
Pavilion: Support recovery - so frustrated!
My 13 month old Pavilion had a complete hard drive failure. He was replaced by Best Buy (two weeks out of warranty) so that the cost of the hard drive... but HP says I have to pay for the recovery media. I get that he died two weeks too late and th
-
Application development in 2014 LV using a Structure of the event. The target system is running LV 2011. The Structure of the event seems to run on the target system, but it only allows me to make changes to the Structure. Right-click on it, and the
-
Computer Windows XP cannot connect to the gateway of media converter where as Linux machine can.
In my office, we have 2 internet connections in the 1 come from media for Cisco router converter and then switch and 1 other comes through router dlink Media Converter and then to the same switch since 1 connection uses the gateway 1 and another 2. I
-
BlackBerry smartphones, removing multiple e-mails
Hello REC just had my second storm. ist it lasted about 2 hours. screen locked up! on my blackberry prev, I was able to delete several emails at once by thoes highling should be deleted. How can I do this on the storm? Murray
-
I have a plan with DC since CC Adobe acrobat, and I can't open the program
Hello, I have a problem to open my acrobat DC, it's an adobe creative Cloud app. I pay every month for a yeat to have this service. But when I try to open the program, told me that I have to put the serial number.Then I uninstall the program, close t