If/Then with several Conditions
I'd appreciate any help in getting this simple working code.
I have two variables. One with 7 options and one with 3 options. Depending on the selected combination another pre-determined value.
The following code is an example of one of the combinations that I am using, however it doesn't seem to work at all, and I'm puzzled!
If (this.getField("TICKET1").value == ' GENERAL (2011-2012 season ticket) "& & this.getField("TYPE1").value == 'ADULT') {event.value = 814.00 ;}
The quotes around the 'TYPE1' and 'ADULTS' strings are not the right type. They must be like those used with the 'TICKET' and 'GENERAL... ". »
Tags: Acrobat
Similar Questions
-
Index and MATCH with several conditions
Hi all! I hope I can explain what I'm trying to do here clearly. This is my first shot:
In the table below "Office entry Worksheet - area 1" I am trying to insert a formula in column B which will result in an answer ' true / false ' and be used for conditional highlighting

The first condition that must be met is that the checkbox in the table "Labor and material Checklist" column A or check, if it is not checked, then move to the next line. If the box is checked, then the following condition would need to index and match with column C of table "Office entry Worksheet - area 1" in column B. If there is a match in column C, then move to the next line of column B in the table 'labor and material Checklist '. This continues until there is a 'match', then highlight column B in the table "entry Office sheet - surface 1" in red (or something like "MISSING task")
It is an estimate and the idea is to ensure that the Phases that are checked in the table "Labor and material Checklist" will not miss when you use the table "entry office map - zone 1".
Thank you very much for your help!
Tim

Is it possible that I can download this spreadsheet file?
-
Dynamic with several Conditions when action
APEX 4.2 on XE
Hi all, I'm trying to create a dynamic Action based on several when conditions... The docs seem to indicate you can do, but I can't seem to trigger.
Basically I have a DA
Event: change
Selection type: item (s)
Article (s): P42_NEW_REC, P42_STATUS_ID
Condition: equality
Value N, 43
Individually, these trigger very well, but does not fire? Is it possible to have several times conditions? If so, what is the problem with the above.
Alternatively, if not, if someone could give better advice to achieve the same thing, Id be grateful...
Rgds
Richard
Hello
Use the condition list
Kind regards
Jari
-
Error exporting in the level of query with several conditions
When I run the following query to export with the result.
C:\Documents and Settings\ITL > exp scott/tiger@orcl tables = (emp) QUERY = "" WHERE deptno > 10 and sal! 2850 = "' LOG = log011.log FILE = exp.dmp"
Export: Release 10.2.0.1.0 - Production on Wed Jan 30 10:01:27 2013
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
With partitioning, OLAP and Data Mining options
Export performed WE8MSWIN1252 and AL16UTF16 NCHAR character set
About to export specified tables by conventional means...
. . export the rows in the table EMP 10 exported
EXP-00091: exporting more than questionable statistics.
EXP-00091: exporting more than questionable statistics.
Export completed successfully with warnings.
But when I run it with the following condition, then it displays the following error...
C:\Documents and Settings\ITL > exp scott/tiger@orcl tables = (emp) QUERY ='"WHERE deptno > 10 and work!" = 'CLERK' ' ' LOG = log011.log FILE = Exp01.dmp.
LRM-00111: no closing quote for value 'LOG = log01'
EXP-00019: failure of the treatment of parameters, type 'HELP EXP = Y' help
EXP-00000: export completed unsuccessfully
C:\Documents and Settings\ITL > exp scott/tiger@orcl tables = (emp) QUERY = "WHERE deptno > 10 and work! = 'CLERK' ' LOG = log5.log FILE = exp01.dmp
LRM-00112: multiple values not allowed for the parameter "query".
EXP-00019: failure of the treatment of parameters, type 'HELP EXP = Y' help
EXP-00000: export completed unsuccessfully
Please suggest a solution for this.Hello
Single quotes used for CLERKS are very probably the origin of the problem.
C:\Documents and Settings\ITL > exp scott/tiger@orcl tables = (emp) QUERY ='"WHERE deptno 10 > and job!" = 'CLERK' ' ' LOG = log011.log FILE = Exp01.dmp.try to replace this
C:\Documents and Settings\ITL > exp scott/tiger@orcl tables = (emp) QUERY ='"WHERE deptno 10 > and job!" = "REGISTRAR" "' LOG = log011.log FILE = Exp01.dmp.Two single quotes (no quotes) to place an apostrophe for CLERK.
Thank you
Padma... -
Conditional display with several conditions of PL/SQL
Hi guys,.
I want my chart to conditionally display 2 points, 1. a selection list is not null (TO_CHAR(:P7_DB_LIST)! = TO_CHAR (666)) and 2. the maximum value in a query is above a certain amount such as 2000. The idea is that I currently have a graphical display in MB. 40 000 MB is not something big to see so after a certain point, I want to display a graph in GB instead. So I want 2 graph both depends on the LOV is not null, but who need the value of the query less than 2000 and the upper.
I don't know if its possible to have two parolees working together in one conditional display of the APEX (PL/SQL Expression)?
Mike
Damaged by: ATD on August 11, 2009 06:20Mike,
Laughing out loud! Welcome to PL/SQL ;)
Packages are not very difficult to get, but perhaps we should start over with a stored function a package... Here's the gist:
CREATE OR REPLACE FUNCTION size_is_valid ( p_svc_app IN VARCHAR2, p_svc_app_name IN VARCHAR2 ) RETURN BOOLEAN AS CURSOR max_size_cur IS SELECT max(size_mb) AS size_mb FROM [email protected] WHERE svc_app_name = size_is_valid.p_svc_app_name AND svc_name = size_is_valid.p_svc_app; l_max_size_rec MAX_SIZE_CUR%ROWTYPE; l_retval BOOLEAN; BEGIN OPEN max_size_cur; FETCH max_size_cur INTO l_max_size_rec; CLOSE max_size_cur; l_retval := l_max_size_rec.size_mb > 500; RETURN l_retval; END size_is_valid;Then your new validation of test should be:
BEGIN RETURN size_is_valid(:P7_DB_LIST, :P7_PROJ_LIST); END;Kind regards
Danhttp://danielmcghan.us
http://sourceforge.NET/projects/tapigenYou can reward this answer by marking as being useful or correct ;-)
-
Find entries with several conditions, including the comparison
Hello
I take the edition of I v6.2.7 a ride, I'm looking at the use case is the following. I have a "table" with about 100 k records defined by this object:
@Entity public class LTROW { @PrimaryKey private Integer id = null; @SecondaryKey(relate=Relationship.MANY_TO_ONE) private Integer tableId = null; @SecondaryKey(relate = Relationship.MANY_TO_ONE) private String col0 = null; @SecondaryKey(relate = Relationship.MANY_TO_ONE) private String col1 = null; @SecondaryKey(relate = Relationship.MANY_TO_ONE) private String col2 = null; @SecondaryKey(relate = Relationship.MANY_TO_ONE) private String col3 = null; @SecondaryKey(relate = Relationship.MANY_TO_ONE) private String col4 = null; @SecondaryKey(relate = Relationship.MANY_TO_ONE) private String col5 = null; @SecondaryKey(relate = Relationship.MANY_TO_ONE) private String col6 = null; @SecondaryKey(relate = Relationship.MANY_TO_ONE) private String col7 = null; private String result0 = null; private String result1 = null; private String result2 = null; private String result3 = null; private String result4 = null; // ... }Typical research I must apply is: give me all the entries contained in tableId X where the value of co0 is equal to 7, 1112 exceeds the value of col1 and col2 value is less than 8.
I got in the definition of index for all columns defined in the class, but can't seem to understand how to combine these criteria. I looked at EntityJoin but it doesn't seem to be what I'm looking for.
Thank you!
You cannot use multiple indexes for this kind of query. Instead, create and use a single index for one of the conditions and filter on other conditions. I hear, by 'filter' select the records you want using an 'if' statement Try to choose the index that returns the smallest number of records.
See:
http://www.Oracle.com/technetwork/database/database-technologies/BerkeleyDB/performing.PDF
-mark
-
"if" with several conditions statement?
Here's what I'm trying to do:
If ((condition1 == true) and (condition2 == true)) {}
run this code
}
He compiled / worked fine in AS2, but it doesn't look like AS3 like them. I get the following errors:
"Syntax error: expected rightparen before and.
"Syntax error: rightparen is unexpected.
"Syntax error: expected semicolon before leftbrace.
What gives? Is this fixed before the final release?I do not know how it is managed in AS3, but I know 'and' is deprecated since Flash 5 in favor of &. see livedocs
-
If statement several Conditions
With the help of LiveCycle, FormCalc or JavaScript.
I am trying to create an if statement with several conditions.
a Sum field calculates a set of numeric entry fields. I want the result in the amount field to determine the expression in a final field.
If the sum is < 30MM then '50000' also if the sum is > 30MM but < 60MM then '125000' also if the sum is > 60MM but < 100MM then "250000" also if the sum is > 100MM but < 300MM then '375000' also if the sum is > 300MM then "500000".
I've been able to understand one so so for the first condition, but not able to include all the conditions and multiple results.
Help would be much appreciated!
Thank you in advance.Send your form to [email protected] and I'll take a look and see what is wrong.
Paul
-
I've updated my Muse app to the latest version of July and since then my Muse forms do not work with several of my web hosting providers. Is this a case of the site not having host is not the latest version of PHP?
Please consult this document:
Troubleshooting Muse form used on the servers of third party Widgets
Thank you
Sanjit
-
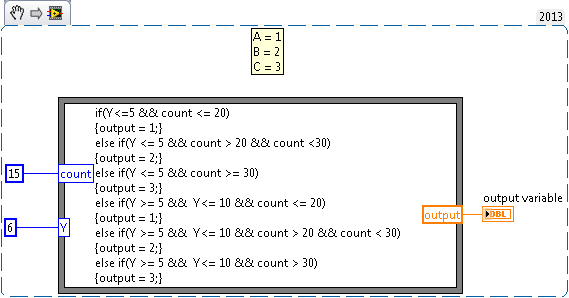
Output system are made up of several conditions by using the If Condition
Hello master. I want to create a system of products composed of several conditions using if conditions. The input of the system is derived from "counting" and the second entry is "O". Entry is in order. Then, the expected results are:
If Y<= 5="" and="" count=""><= 20,="" the="" result="" is="">
If Y<= 5="" and="" 20=""><30 result="">
If Y = outcome 30 C <= 5="" and="" count="">If <= 5="" y="">= 10 and County<= 20,="" the="" result="" is="">
If <= 5="" y="">= 10 and 20<30 result="">
If <= 5="" y="">= 10 and County > = result 30 CThank you for your attention.
Kind regards
Fajar
Assuming that 'A', 'B' and 'C' are digital issued by a calculation, you can use a node of the formula.
Here is a small example based on your rating (a bit confusing). It can be slightly changed, but it might be a starting point (assuming I understood you, and you're only dealing with the numeric data types simple as described in your example).
The case could just to do this using regular functions of comparison of LabVIEW and data flow.
-
Hi Expert...
Im trying to make if several conditions in acrobat javascript, so my problem is simple I want to draw the attention of the user and then change the value of the field if the user enters a wrong number... so my approach was what follows... but it gives me errors (in custom for the field validation scripts)
Switch (event.value) {} case '0 ': this.getField("PeriodVar").value = 20;
App.Alert ("zero not accepted");
break; case ' ': this.getField("PeriodVar").value = 20;
App.Alert ("empty not accepted");
break; 20 > case study: this.getField("PeriodVar").value = 20;
App.Alert ("more than 20 not accepted");
break; } I tried to do several condition with other, if but also I have faild, I only success in the following code in the function: function checkmaxperval() { var maxsum = getField("PeriodVar"); var usingsum = maxsum.value; if (usingsum > 20 ) { app.alert("maximum value is 20 only", 3); maxsum.value = 20; return; }Looks like you were trying to have a 'case > 20' - it is not valid JavaScript. Each case must be a distinct value.
You are better to do an if/else if/else statement:
if (event.value == 0) { // do someting } else if (event.value == "") { // do something else } else if (event.value > 20) { // do something else } else { // this catches anything that was not yet handled }That said, I would advice against searching for an empty string: the problem with this is that you cannot easily remove a value, and then replace it with valid data, or leave it blank and move on to come back later. I suggest you handle these cases later, for example when the form is submitted: have a function that checks the 'required' fields that are empty. See for example here for the code that would do this: loop through the required fields before submitting the form (JavaScript)
Your second code snippet is missing a '} '.
-
Search feature with several web languages production results in all languages
I have a question where web search in my outings with several languages results in all languages. For example, if the user enters a word that can appear in all the outputs regardless of the language, the results will display all HTML pages for each language when it appears.
Is it possible to set up the web output so that if the user displays the English content, only the HTML pages in English are displayed when you use the search function?
Thank you
Chris
Hello
Personally, I doubt that a patch would solve the problem. Maybe it will be, and it is certainly worth a try, but don't be too shocked if you find that you must apply the service release and nothing changes.
My own experience (as my little finger) is whispering in my ear (or abdomen) that probably is simple settings, that you set up before and during the build.
I didn't know any reference to the version of RoboHelp you use here, so I'll use version 11 because it is likely the most common version used at the moment. And if you have 10 or 9 or even 2015 release, the steps should be almost identical.
When you examine the presentation of single Source settings, expand your content categories and select one. Note that for each of them, you have an opportunity to choose a conditional Expression to build.

I say this because if a conditional build expression causes points to not appear in the output, the elements must also not appear in the search.
My thought here, you need to configure some conditional tags to build carefully, then associate tags with subjects that do not apply to each category. Thus, for English subjects, create and associate a label named "English". Same thing for the other languages. When you prepare to generate, consider each of the categories, click on this button to set and exclude the languages that do not apply. So if you have four languages, English, Spanish, French and German, maybe, and your category is for English, you would create a create an Expression that looks like this:

Give it a go and see how you rate.
See you soon... Rick
-
[8i] grouping with delicate conditions (follow-up)
I am posting this as a follow-up question to:
[8i] grouping with tricky conditions
This is a repeat of my version information:
Still stuck on an old database a little longer, and I'm trying out some information...
BANNER
--------------------------------------------------------------------------------
Oracle8i Enterprise Edition Release 8.1.7.2.0 - Production
PL/SQL Release 8.1.7.2.0 - Production
CORE 8.1.7.0.0-Production
AMT for HP - UX: 8.1.7.2.0 - Production Version
NLSRTL Version 3.4.1.0.0 - Production
Now for the sample data. I took an order of my real data set and cut a few columns to illustrate how the previous solution didn't find work. My real DataSet still has thousands of orders, similar to this one.
Instead of grouping all sequential steps with 'OUTPR' station, I am gathering all the sequential steps with "S9%" station, then here is the solution changed to this:CREATE TABLE test_data ( item_id CHAR(25) , ord_id CHAR(10) , step_id CHAR(4) , station CHAR(5) , act_hrs NUMBER(11,8) , q_comp NUMBER(13,4) , q_scrap NUMBER(13,4) ); INSERT INTO test_data VALUES ('abc-123','0001715683','0005','S509',0,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0010','S006',0,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0020','A501',0.85,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0026','S011',0.58,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0030','S970',0,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0040','S970',0,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0050','S003',0,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0055','S600',0,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0060','Z108',6.94,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0070','Z108',7,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0080','Z310',4.02,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0085','Z409',2.17,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0090','S500',0.85,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0095','S502',1.63,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0110','S006',0,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0112','S011',0.15,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0117','S903',0,10,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0118','S900',0,9,1); INSERT INTO test_data VALUES ('abc-123','0001715683','0119','S950',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0120','S906',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0140','S903',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0145','S950',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0150','S906',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0160','S903',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0170','S900',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0220','S902',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0230','S906',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0240','S903',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0250','S003',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0260','S006',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0270','S012',0.95,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0280','Z417',0.68,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0285','Z417',0.68,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0290','Z426',1.78,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0300','Z426',2.07,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0305','Z426',1.23,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0310','Z402',3.97,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0315','Z308',8.09,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0410','Z409',4.83,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0430','S500',3.6,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0435','S502',0.43,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0450','S002',0.35,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0460','S001',1,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0470','Z000',2.6,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0476','S011',1,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0478','S510',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0480','S903',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0490','S003',1.2,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0500','S500',1.37,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0530','B000',0.28,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0536','S011',0.65,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0538','S510',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0540','S923',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0560','S003',0,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0565','S001',0.85,0,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0570','S012',2.15,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0575','S509',0,0,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0580','B000',3.78,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0590','S011',0.27,9,0); INSERT INTO test_data VALUES ('abc-123','0001715683','0600','S510',0,9,0);
If just run the subquery to calculate grp_id, you can see that it sometimes affects the same number of group in two stages that are not side by side. For example, the two step 285 and 480 are they assigned group 32...SELECT item_id , ord_id , MIN (step_id) AS step_id , station , SUM (act_hrs) AS act_hrs , MIN (q_comp) AS q_comp , SUM (q_scrap) AS q_scrap FROM ( -- Begin in-line view to compute grp_id SELECT test_data.* , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id ORDER BY step_id ) - ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id , CASE WHEN station LIKE 'S9%' THEN NULL ELSE step_id END ORDER BY step_id ) AS grp_id , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id ORDER BY step_id ) AS r_num1 , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id , CASE WHEN station LIKE 'S9%' THEN NULL ELSE step_id END ORDER BY step_id ) AS r_num2 FROM test_data ) -- End in-line view to compute grp_id GROUP BY item_id , ord_id , station , grp_id ORDER BY item_id , step_id ;
I don't know if it's because my orders have many more steps that the orders of the sample I provided, or what...
I tried this version too (by replacing all the names of the stations "S9%" by "OUTPR"):
and it shows the same problem.INSERT INTO test_data VALUES ('abc-123','0009999999','0005','S509',0,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0010','S006',0,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0020','A501',0.85,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0026','S011',0.58,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0030','OUTPR',0,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0040','OUTPR',0,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0050','S003',0,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0055','S600',0,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0060','Z108',6.94,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0070','Z108',7,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0080','Z310',4.02,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0085','Z409',2.17,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0090','S500',0.85,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0095','S502',1.63,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0110','S006',0,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0112','S011',0.15,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0117','OUTPR',0,10,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0118','OUTPR',0,9,1); INSERT INTO test_data VALUES ('abc-123','0009999999','0119','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0120','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0140','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0145','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0150','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0160','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0170','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0220','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0230','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0240','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0250','S003',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0260','S006',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0270','S012',0.95,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0280','Z417',0.68,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0285','Z417',0.68,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0290','Z426',1.78,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0300','Z426',2.07,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0305','Z426',1.23,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0310','Z402',3.97,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0315','Z308',8.09,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0410','Z409',4.83,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0430','S500',3.6,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0435','S502',0.43,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0450','S002',0.35,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0460','S001',1,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0470','Z000',2.6,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0476','S011',1,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0478','S510',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0480','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0490','S003',1.2,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0500','S500',1.37,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0530','B000',0.28,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0536','S011',0.65,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0538','S510',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0540','OUTPR',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0560','S003',0,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0565','S001',0.85,0,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0570','S012',2.15,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0575','S509',0,0,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0580','B000',3.78,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0590','S011',0.27,9,0); INSERT INTO test_data VALUES ('abc-123','0009999999','0600','S510',0,9,0); SELECT item_id , ord_id , MIN (step_id) AS step_id , station , SUM (act_hrs) AS act_hrs , MIN (q_comp) AS q_comp , SUM (q_scrap) AS q_scrap FROM ( -- Begin in-line view to compute grp_id SELECT test_data.* , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id ORDER BY step_id ) - ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id , CASE WHEN station = 'OUTPR' THEN NULL ELSE step_id END ORDER BY step_id ) AS grp_id , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id ORDER BY step_id ) AS r_num1 , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id , CASE WHEN station = 'OUTPR' THEN NULL ELSE step_id END ORDER BY step_id ) AS r_num2 FROM test_data ) -- End in-line view to compute grp_id GROUP BY item_id , ord_id , station , grp_id ORDER BY item_id , step_id ;
Help?Hello
I'm glad that you understood the problem.
Here's a little explanation of the approach of the fixed difference. I can refer to this page later, so I will explain some things you obviously already understand, but I jump you will find helpful.
Your problem has additional feature that, according to the station, some lines can never combine in large groups. For now, we will greatly simplify the problem. In view of the CREATE TABLE statement, you have posted and these data:INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0010', 'Z417'); INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0011', 'S906'); INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0012', 'S906'); INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0140', 'S906'); INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0170', 'Z417'); INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0175', 'Z417'); INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0200', 'S906'); INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0205', 'S906');Let's say that we want this output:
` FIRST LAST _STEP _STEP ITEM_ID ORD_ID _ID _ID STATION CNT ------- ---------- ----- ----- ------- ---- abc-123 0001715683 0010 0010 Z417 1 abc-123 0001715683 0011 0140 S906 3 abc-123 0001715683 0170 0175 Z417 2 abc-123 0001715683 0200 0205 S906 2Where each line of output represents a contiguous set of rows with the same item_id, ord_id and station. "Contguous" is determined by step_id: lines with "0200" = step_id = step_id "0205' are contiguous in this example of data because there is no step_ids between '0200' and '0205". "
The expected results include the step_id highest and lowest in the group, and the total number of original lines of the group.GROUP BY (usually) collapses the results of a query within lines. A production line can be 1, 2, 3, or any number of lines in the original. This is obviously a problem of GROUP BY: we sometimes want several lines in the original can be combined in a line of output.
GROUP BY guess, just by looking at a row, you can tell which group it belongs. Looking at all the 2 lines, you can always know whether or not they belong to the same group. This isn't quite the case in this issue. For example, these lines
INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0140', 'S906'); INSERT INTO test_data (item_id, ord_id, step_id, station) VALUES ('abc-123', '0001715683', '0200', 'S906');These 2 rows belong to the same group or not? We cannot tell. Looking at just 2 lines, what we can say is that they pourraient belonging to the same group, since they have the same item_id, ord_id and station. It is true that members of same groups will always be the same item_id, the ord_id and train station; If one of these columns differ from one line to the other, we can be sure that they belong to different groups, but if they are identical, we cannot be certain that they are in the same group, because item_id, ord_id and station only tell part of the story. A group is not just a bunch or rows that have the same item_id, ord_id and station: a group is defined as a sequence of adjacent to lines that have these columns in common. Before we can make the GROUP BY, we need to use the analytical functions to see two lines are in the same contiguous streak. Once we know that, we can store this data in a new column (which I called grp_id), and then GROUP BY all 4 columns: item_id, ord_id, station and grp_id.
First of all, let's recognize a basic difference in 3 columns in the table that will be included in the GROUP BY clause: item_id, ord_id and station.
Item_id and ord_id always identify separate worlds. There is never any point comparing lines with separate item_ids or ord_ids to the other. Different item_ids never interact; different ord_ids have nothing to do with each other. We'll call item_id and ord_id column 'separate world '. Separate planet do not touch each other.
The station is different. Sometimes, it makes sense to compare lines with different stations. For example, this problem is based on questions such as "these adjacent lines have the same station or not? We will call a "separate country" column of the station. There is certainly a difference between separate countries, but countries affect each other.The most intuitive way to identify groups of contiguous lines with the same station is to use a LAG or LEAD to look at adjacent lines. You can certainly do the job, but it happens to be a better way, using ROW_NUMBER.
Help the ROW_NUMBER, we can take the irregular you are ordering step_id and turn it into a dial of nice, regular, as shown in the column of r_num1 below:` R_ R_ GRP ITEM_ID ORD_ID STEP STATION NUM1 S906 Z417 NUM2 _ID ------- ---------- ---- ------- ---- ---- ---- ---- --- abc-123 0001715683 0010 Z417 1 1 1 0 abc-123 0001715683 0011 S906 2 1 1 1 abc-123 0001715683 0012 S906 3 2 2 1 abc-123 0001715683 0140 S906 4 3 3 1 abc-123 0001715683 0170 Z417 5 2 2 3 abc-123 0001715683 0175 Z417 6 3 3 3 abc-123 0001715683 0200 S906 7 4 4 3 abc-123 0001715683 0205 S906 8 5 5 3We could also assign consecutive integers to the lines in each station, as shown in the two columns, I called S906 and Z417.
Notice how the r_num1 increases by 1 for each line to another.
When there is a trail of several rows of S906 consectuive (for example, step_ids ' 0011 'by '0140'), the number of s906 increases by 1 each line to another. Therefore, during the duration of a streak, the difference between r_num1 and s906 will be constant. For 3 lines of the first series, this difference is being 1. Another series of S906s contiguous started step_id = '0200 '. the difference between r_num1 and s906 for this whole series is set to 3. This difference is what I called grp_id.
There is little meaning for real numbers, and, as you have noticed, streaks for different stations can have as by chance the same grp_id. (it does not happen to be examples of that in this game of small sample data.) However, two rows have the same grp_id and station if and only if they belong to the same streak.Here is the query that produced the result immediately before:
SELECT item_id , ord_id , step_id , station , r_num1 , CASE WHEN station = 'S906' THEN r_num2 END AS s906 , CASE WHEN station = 'Z417' THEN r_num2 END AS Z417 , r_num2 , grp_id FROM ( -- Begin in-line view to compute grp_id SELECT test_data.* , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id ORDER BY step_id ) - ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id, station ORDER BY step_id ) AS grp_id , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id ORDER BY step_id ) AS r_num1 , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id, station ORDER BY step_id ) AS r_num2 FROM test_data ) -- End in-line view to compute grp_id ORDER BY item_id , ord_id , step_id ;Here are a few things to note:
All analytical ORDER BY clauses are the same. In most of the problems, there will be only an ording regime that matters.
Analytical PARTITION BY clauses include the columns of 'distinct from the planet', item_id and ord_id.
The analytical PARTITION BY clauses also among the column 'split the country', station.To get the results we want in the end, we add a GROUP BY clause from the main query. Yet once, this includes the columns of the 'separate world', column 'split the country', and the column 'fixed the difference', grp_id.
Eliminating columns that have been includied just to make the output easier to understand, we get:SELECT item_id , ord_id , MIN (step_id) AS first_step_id , MAX (step_id) AS last_step_id , station , COUNT (*) AS cnt FROM ( -- Begin in-line view to compute grp_id SELECT test_data.* , ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id ORDER BY step_id ) - ROW_NUMBER () OVER ( PARTITION BY item_id, ord_id, station ORDER BY step_id ) AS grp_id FROM test_data ) -- End in-line view to compute grp_id GROUP BY item_id , ord_id , station , grp_id ORDER BY item_id , ord_id , first_step_id ;This prioduces the output displayed much earlier in this message.
This example shows the fixed difference indicated. Specific problem you is complicated a little what you should use an expression BOX based on station rather than the station iteself.
-
Several conditions in a trigger
I need a trigger to perform an insert, but the values will be different according to the values inserted in the table causing relaxation. Here is the code:
What's the correct syntax to have several conditions? It compiles with errors:CREATE OR REPLACE TRIGGER users_in_roles AFTER INSERT ON users REFERENCING NEW AS new FOR EACH ROW WHEN ( new.agcy_cd = 'AA' ) BEGIN INSERT INTO users_in_roles(role_seq, user_seq) VALUES( 5, :new.user_seq ); END ; WHEN ( new.agcy_cd = 'AB' ) BEGIN INSERT INTO users_in_roles(role_seq, user_seq) VALUES( 20, :new.user_seq ); END ; WHEN ( new.agcy_cd = 'AC' ) BEGIN INSERT INTO users_in_roles(role_seq, user_seq) VALUES( 30, :new.user_seq ); END ; WHEN ( new.agcy_cd = 'AD' ) BEGIN INSERT INTO users_in_roles(role_seq, user_seq) VALUES( 40, :new.user_seq ); END ; END TRIGGER users_in_roles ; /
Error (6.1): PLS-00103: encountered the symbol "WHEN".SQL> create table users (agcy_id varchar2(2), user_seq number); Table created. SQL> create table users_in_roles (role_seq number, user_seq number); Table created. SQL> create or replace trigger users_in_roles 2 after insert on users 3 referencing new as new 4 for each row 5 when (new.agcy_id in ('AA', 'AB', 'AC', 'AD')) 6 begin 7 insert into users_in_roles (role_seq, user_seq) 8 select case 9 when :new.agcy_id = 'AA' then 5 10 when :new.agcy_id = 'AB' then 20 11 when :new.agcy_id = 'AC' then 30 12 when :new.agcy_id = 'AD' then 40 13 end 14 , :new.user_seq 15 from dual; 16 end; 17 / Trigger created. SQL> insert into users values ('AA', 12); 1 row created. SQL> select * from users_in_roles; ROLE_SEQ USER_SEQ ---------- ---------- 5 12 1 row selected. SQL> insert into users values ('$$', 1); 1 row created. SQL> select * from users_in_roles; ROLE_SEQ USER_SEQ ---------- ---------- 5 12 1 row selected. SQL> insert into users values ('AD', 10); 1 row created. SQL> select * from users_in_roles; ROLE_SEQ USER_SEQ ---------- ---------- 5 12 40 10 2 rows selected. -
Several Conditions in discoverer
Hello
I'm new to the discoverer and I am facing a problem in creating several conditions! I want to create a condition as follows:
(X not as 'External fault %') OR (X % not as "customer equipment") ET (Real time * < = * KPI hours)
- - - - - - - -
I can achieve at this stage for OR
! http://www.freeimagehosting.NET/uploads/8517f17f52.jpg!
But when I tried to add AND or, it will change OR AND
Example:
! http://www.freeimagehosting.NET/uploads/84ec85f131.jpg!
Is this possible in discoverer?
Please, I'll be happy with your comments and suggestions. Thank you!
Mohammed Rafea
Edited by: user11111046 may 3, 2009 08:19
Edited by: user11111046 may 3, 2009 08:251. define a condition containing gold
(X not as 'External fault %') OR (X not like ' % of customers own equipment ")
and give it a name, for example, condition1
2 set a condition for the part AND
(Real time<= kpi="">
and give it a name for example condition2
3. in the condition dialog box finally uncheck condition1 and condition2 conditions so that they are not selected for this worksheet.
4. create a third condition and instead selects an item, you can select a condition. Condition1 here click to add as many lines and select and. Then you select condition2 so that this condition contains
condition1 AND condition2
Rod West




Maybe you are looking for
-
Wireless printing problem: Mac OS 10.5 to HP6600 all-in-One
My customer just bought a printer all-in-one HP OfficeJet 6600. Naturally, the CD than canme with the printer is for a newer Mac OS, so it wouldn't install. I was able to locate and download the printer drivers for Mac OS 10.5 and install without any
-
can't control panal and much more Says: "windows explore has stopped working", then closes.
printer stopped working and my speakers (external) but the Explorer Windows in when I go to windows update, printers and control panel ect.
-
Two unwanted connections always connect, and I guess they are somewhere in the neighborhood. 'Delete' never appears, I read means that they have security blocks are not actually using my computer. However, they interfere in some way because wheneve
-
I am currently using CS 5.5 on an iMac. My recent .mts files do not play sound. I found a forum on the issue. One of the solutions is to uninstall CS, following cleaning, and then reinstall CS. I'm still able to reinstall CS 5.5 or it is no longer su
-
How to print part of a page? For example, a piece of technical drawing. In previous versions, I could use the snapshot tool. I'm not find this tool in version 11.Is there a similar tool in this version?